604 Repositories
Python unsupervised-document-retrieval Libraries

🏆 The 1st Place Submission to AICity Challenge 2021 Natural Language-Based Vehicle Retrieval Track (Alibaba-UTS submission)
AI City 2021: Connecting Language and Vision for Natural Language-Based Vehicle Retrieval 🏆 The 1st Place Submission to AICity Challenge 2021 Natural
 82 Dec 29, 2022
82 Dec 29, 2022

An official implementation for "CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval"
The implementation of paper CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval. CLIP4Clip is a video-text retrieval model based
 456 Jan 6, 2023
456 Jan 6, 2023

Code for Dual Contrastive Learning for Unsupervised Image-to-Image Translation, NTIRE, CVPRW 2021.
arXiv Dual Contrastive Learning Adversarial Generative Networks (DCLGAN) We provide our PyTorch implementation of DCLGAN, which is a simple yet powerf
 119 Dec 4, 2022
119 Dec 4, 2022
Code for "Learning the Best Pooling Strategy for Visual Semantic Embedding", CVPR 2021
Learning the Best Pooling Strategy for Visual Semantic Embedding Official PyTorch implementation of the paper Learning the Best Pooling Strategy for V
 106 Jan 6, 2023
106 Jan 6, 2023

code for paper "Does Unsupervised Architecture Representation Learning Help Neural Architecture Search?"
Does Unsupervised Architecture Representation Learning Help Neural Architecture Search? Code for paper: Does Unsupervised Architecture Representation
 39 Dec 17, 2022
39 Dec 17, 2022

(CVPR 2021) ST3D: Self-training for Unsupervised Domain Adaptation on 3D Object Detection
ST3D Code release for the paper ST3D: Self-training for Unsupervised Domain Adaptation on 3D Object Detection, CVPR 2021 Authors: Jihan Yang*, Shaoshu
 224 Dec 28, 2022
224 Dec 28, 2022
Activity image-based video retrieval
Cross-modal-retrieval Our approach is focus on Activity Image-to-Video Retrieval (AIVR) task. The compared methods are state-of-the-art single modalit
 75 Oct 21, 2021
75 Oct 21, 2021

Code repository for paper `Skeleton Merger: an Unsupervised Aligned Keypoint Detector`.
Skeleton Merger Skeleton Merger, an Unsupervised Aligned Keypoint Detector. The paper is available at https://arxiv.org/abs/2103.10814. A map of the r
 48 Nov 14, 2022
48 Nov 14, 2022
Scene Text Retrieval via Joint Text Detection and Similarity Learning
This is the code of "Scene Text Retrieval via Joint Text Detection and Similarity Learning". For more details, please refer to our CVPR2021 paper.
 79 Nov 29, 2022
79 Nov 29, 2022

PyTorch code for SENTRY: Selective Entropy Optimization via Committee Consistency for Unsupervised DA
PyTorch Code for SENTRY: Selective Entropy Optimization via Committee Consistency for Unsupervised Domain Adaptation Viraj Prabhu, Shivam Khare, Deeks
 46 Dec 24, 2022
46 Dec 24, 2022

Python library containing BART query generation and BERT-based Siamese models for neural retrieval.
Neural Retrieval Embedding-based Zero-shot Retrieval through Query Generation leverages query synthesis over large corpuses of unlabeled text (such as
 35 Apr 14, 2022
35 Apr 14, 2022
Proto-RL: Reinforcement Learning with Prototypical Representations
Proto-RL: Reinforcement Learning with Prototypical Representations This is a PyTorch implementation of Proto-RL from Reinforcement Learning with Proto
 74 Dec 6, 2022
74 Dec 6, 2022
Use unsupervised and supervised learning to predict stocks
AIAlpha: Multilayer neural network architecture for stock return prediction This project is meant to be an advanced implementation of stacked neural n
 1.5k Dec 26, 2022
1.5k Dec 26, 2022

Layout Parser is a deep learning based tool for document image layout analysis tasks.
A Python Library for Document Layout Understanding
 3.4k Dec 30, 2022
3.4k Dec 30, 2022
xeuledoc - Fetch information about a public Google document.
xeuledoc - Fetch information about a public Google document.
 651 Dec 27, 2022
651 Dec 27, 2022
Adversarial Adaptation with Distillation for BERT Unsupervised Domain Adaptation
Knowledge Distillation for BERT Unsupervised Domain Adaptation Official PyTorch implementation | Paper Abstract A pre-trained language model, BERT, ha
 29 Nov 30, 2022
29 Nov 30, 2022

Codes for NAACL 2021 Paper "Unsupervised Multi-hop Question Answering by Question Generation"
Unsupervised-Multi-hop-QA This repository contains code and models for the paper: Unsupervised Multi-hop Question Answering by Question Generation (NA
 70 Nov 27, 2022
70 Nov 27, 2022

《Improving Unsupervised Image Clustering With Robust Learning》(2020)
Improving Unsupervised Image Clustering With Robust Learning This repo is the PyTorch codes for "Improving Unsupervised Image Clustering With Robust L
 129 Dec 27, 2022
129 Dec 27, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023

UniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning
UniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning This is the official PyTorch implementation for UniMoCo pape
 49 Jan 2, 2023
49 Jan 2, 2023

source code and pre-trained/fine-tuned checkpoint for NAACL 2021 paper LightningDOT
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval This repository contains source code and pre-trained/fine-tun
 65 Dec 26, 2022
65 Dec 26, 2022
Code for CVPR 2021 paper: Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning This is the PyTorch companion code for the paper: A
 69 Jan 3, 2023
69 Jan 3, 2023
![《Unsupervised 3D Human Pose Representation with Viewpoint and Pose Disentanglement》(ECCV 2020) GitHub: [fig9]](https://github.com/NIEQiang001/unsupervised-human-pose/raw/master/assets/intro.png)
《Unsupervised 3D Human Pose Representation with Viewpoint and Pose Disentanglement》(ECCV 2020) GitHub: [fig9]
Unsupervised 3D Human Pose Representation [Paper] The implementation of our paper Unsupervised 3D Human Pose Representation with Viewpoint and Pose Di
 42 Nov 24, 2022
42 Nov 24, 2022
![[CVPR 2021] Unsupervised Degradation Representation Learning for Blind Super-Resolution](https://github.com/LongguangWang/DASR/raw/main/Figs/fig.1.png)
[CVPR 2021] Unsupervised Degradation Representation Learning for Blind Super-Resolution
DASR Pytorch implementation of "Unsupervised Degradation Representation Learning for Blind Super-Resolution", CVPR 2021 [arXiv] Overview Requirements
 318 Dec 24, 2022
318 Dec 24, 2022
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2021 Links Doc
 4.2k Dec 28, 2022
4.2k Dec 28, 2022
The easiest way to use deep metric learning in your application. Modular, flexible, and extensible. Written in PyTorch.
News March 3: v0.9.97 has various bug fixes and improvements: Bug fixes for NTXentLoss Efficiency improvement for AccuracyCalculator, by using torch i
 5k Jan 2, 2023
5k Jan 2, 2023
A Python toolkit for rule-based/unsupervised anomaly detection in time series
Anomaly Detection Toolkit (ADTK) Anomaly Detection Toolkit (ADTK) is a Python package for unsupervised / rule-based time series anomaly detection. As
 888 Dec 30, 2022
888 Dec 30, 2022
Fetch information about a public Google document.
xeuledoc Fetch information about any public Google document. It's working on : Google Docs Google Spreadsheets Google Slides Google Drawning Google My
655 Jan 3, 2023

Source code of our TPAMI'21 paper Dual Encoding for Video Retrieval by Text and CVPR'19 paper Dual Encoding for Zero-Example Video Retrieval.
Dual Encoding for Video Retrieval by Text Source code of our TPAMI'21 paper Dual Encoding for Video Retrieval by Text and CVPR'19 paper Dual Encoding
 81 Dec 1, 2022
81 Dec 1, 2022
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023

document image degradation
ocrodeg The ocrodeg package is a small Python library implementing document image degradation for data augmentation for handwriting recognition and OC
 134 Nov 18, 2022
134 Nov 18, 2022

Binarize document images
Binarization Binarization for document images Examples Introduction This tool performs document image binarization (i.e. transform colour/grayscale to
 48 Jan 2, 2023
48 Jan 2, 2023
A selectional auto-encoder approach for document image binarization
The code of this repository was used for the following publication. If you find this code useful please cite our paper: @article{Gallego2019, title =
 89 Nov 18, 2022
89 Nov 18, 2022
PAGE XML format collection for document image page content and more
PAGE-XML PAGE XML format collection for document image page content and more For an introduction, please see the following publication: http://www.pri
 46 Nov 14, 2022
46 Nov 14, 2022
Python-based tools for document analysis and OCR
ocropy OCRopus is a collection of document analysis programs, not a turn-key OCR system. In order to apply it to your documents, you may need to do so
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Packaged, Pytorch-based, easy to use, cross-platform version of the CRAFT text detector
CRAFT: Character-Region Awareness For Text detection Packaged, Pytorch-based, easy to use, cross-platform version of the CRAFT text detector | Paper |
 188 Dec 28, 2022
188 Dec 28, 2022
This repository provides train&test code, dataset, det.&rec. annotation, evaluation script, annotation tool, and ranking.
SCUT-CTW1500 Datasets We have updated annotations for both train and test set. Train: 1000 images [images][annos] Additional point annotation for each
 600 Dec 18, 2022
600 Dec 18, 2022

Unofficial implementation of "TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images"
TableNet Unofficial implementation of ICDAR 2019 paper : TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from
 243 Dec 30, 2022
243 Dec 30, 2022
Detect textlines in document images
Textline Detection Detect textlines in document images Introduction This tool performs border, region and textline detection from document image data
70 Jun 30, 2022

Document Layout Analysis
Eynollah Document Layout Analysis Introduction This tool performs document layout analysis (segmentation) from image data and returns the results as P
198 Dec 29, 2022
Page to PAGE Layout Analysis Tool
P2PaLA Page to PAGE Layout Analysis (P2PaLA) is a toolkit for Document Layout Analysis based on Neural Networks. 💥 Try our new DEMO for online baseli
 180 Nov 24, 2022
180 Nov 24, 2022
A simple document layout analysis using Python-OpenCV
Run the application: python main.py *Note: For first time running the application, create a folder named "output". The application is a simple documen
 109 Dec 12, 2022
109 Dec 12, 2022
Document Layout Analysis Projects
Layout_Analysis Introduction This is an implementation of RLSA and X-Y Cut with OpenCV Dependencies OpenCV 3.0+ How to use Compile with g++ : g++ -std
 22 Dec 8, 2022
22 Dec 8, 2022
Generic framework for historical document processing
dhSegment dhSegment is a tool for Historical Document Processing. Its generic approach allows to segment regions and extract content from different ty
 343 Dec 24, 2022
343 Dec 24, 2022
Detect textlines in document images
Textline Detection Detect textlines in document images Introduction This tool performs border, region and textline detection from document image data
70 Jun 30, 2022

Code for the paper "DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regression Networks" (ICCV '19)
DewarpNet This repository contains the codes for DewarpNet training. Recent Updates [May, 2020] Added evaluation images and an important note about Ma
 354 Jan 1, 2023
354 Jan 1, 2023

Document Image Dewarping
Document image dewarping using text-lines and line Segments Abstract Conventional text-line based document dewarping methods have problems when handli
 268 Dec 23, 2022
268 Dec 23, 2022

Library used to deskew a scanned document
Deskew //Note: Skew is measured in degrees. Deskewing is a process whereby skew is removed by rotating an image by the same amount as its skew but in
 273 Jan 6, 2023
273 Jan 6, 2023
An application of high resolution GANs to dewarp images of perturbed documents
Docuwarp This project is focused on dewarping document images through the usage of pix2pixHD, a GAN that is useful for general image to image translat
 97 Dec 25, 2022
97 Dec 25, 2022

Code for the paper "Training GANs with Stronger Augmentations via Contrastive Discriminator" (ICLR 2021)
Training GANs with Stronger Augmentations via Contrastive Discriminator (ICLR 2021) This repository contains the code for reproducing the paper: Train
 174 Dec 29, 2022
174 Dec 29, 2022
Learning Intents behind Interactions with Knowledge Graph for Recommendation, WWW2021
Learning Intents behind Interactions with Knowledge Graph for Recommendation This is our PyTorch implementation for the paper: Xiang Wang, Tinglin Hua
 158 Dec 15, 2022
158 Dec 15, 2022
A generic JSON document store with sharing and synchronisation capabilities.
Kinto Kinto is a minimalist JSON storage service with synchronisation and sharing abilities. Online documentation Tutorial Issue tracker Contributing
 4.2k Dec 26, 2022
4.2k Dec 26, 2022

Parse Robinhood 1099 Tax Document from PDF into CSV
Robinhood 1099 Parser This project converts Robinhood Securities 1099 tax document from PDF to CSV file. This tool will be helpful for those who need
 52 Jun 10, 2022
52 Jun 10, 2022

Official PyTorch Implementation of Unsupervised Learning of Scene Flow Estimation Fusing with Local Rigidity
UnRigidFlow This is the official PyTorch implementation of UnRigidFlow (IJCAI2019). Here are two sample results (~10MB gif for each) of our unsupervis
 28 Nov 16, 2022
28 Nov 16, 2022
![[CVPR2021 Oral] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers](https://github.com/dddzg/up-detr/raw/master/.github/UP-DETR.png)
[CVPR2021 Oral] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers This is the official PyTorch implementation and models for UP-DETR paper: @a
430 Dec 23, 2022

Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning, CVPR 2021
Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning By Zhenda Xie*, Yutong Lin*, Zheng Zhang, Yue Ca
 293 Dec 20, 2022
293 Dec 20, 2022
Python audio and music signal processing library
madmom Madmom is an audio signal processing library written in Python with a strong focus on music information retrieval (MIR) tasks. The library is i
 1k Dec 26, 2022
1k Dec 26, 2022
Marsyas - Music Analysis, Retrieval and Synthesis for Audio Signals
Welcome to MARSYAS. MARSYAS is a software framework for rapid prototyping of audio applications, with flexibility and extensibility as primary concer
 364 Oct 31, 2022
364 Oct 31, 2022
C++ library for audio and music analysis, description and synthesis, including Python bindings
Essentia Essentia is an open-source C++ library for audio analysis and audio-based music information retrieval released under the Affero GPL license.
 2.3k Jan 3, 2023
2.3k Jan 3, 2023

Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs (CIKM 2020)
Karate Club is an unsupervised machine learning extension library for NetworkX. Please look at the Documentation, relevant Paper, Promo Video, and Ext
 1.8k Jan 3, 2023
1.8k Jan 3, 2023
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2021 Links Doc
4.2k Dec 29, 2022
:mag: Ambar: Document Search Engine
🔍 Ambar: Document Search Engine Ambar is an open-source document search engine with automated crawling, OCR, tagging and instant full-text search. Am
 1.9k Jan 9, 2023
1.9k Jan 9, 2023
UnsupervisedR&R: Unsupervised Pointcloud Registration via Differentiable Rendering
UnsupervisedR&R: Unsupervised Pointcloud Registration via Differentiable Rendering This repository holds all the code and data for our recent work on
 118 Dec 6, 2022
118 Dec 6, 2022
Python-based tools for document analysis and OCR
ocropy OCRopus is a collection of document analysis programs, not a turn-key OCR system. In order to apply it to your documents, you may need to do so
3.2k Jan 4, 2023
Official PyTorch code for ClipBERT, an efficient framework for end-to-end learning on image-text and video-text tasks
Official PyTorch code for ClipBERT, an efficient framework for end-to-end learning on image-text and video-text tasks. It takes raw videos/images + text as inputs, and outputs task predictions. ClipBERT is designed based on 2D CNNs and transformers, and uses a sparse sampling strategy to enable efficient end-to-end video-and-language learning.
 612 Jan 4, 2023
612 Jan 4, 2023

Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals.
Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals This repo contains the Pytorch implementation of our paper: Unsupervised Seman
 335 Dec 28, 2022
335 Dec 28, 2022
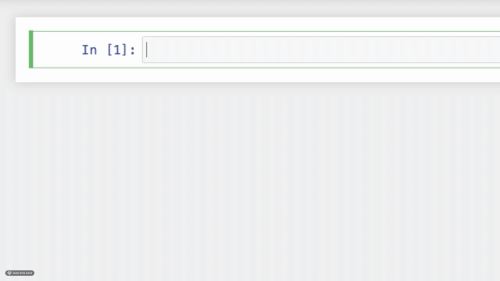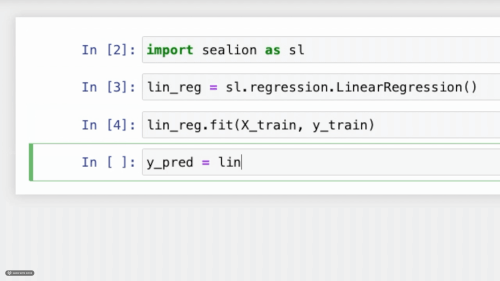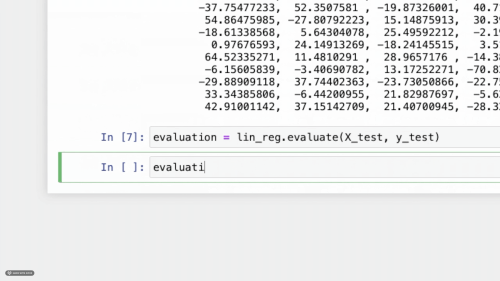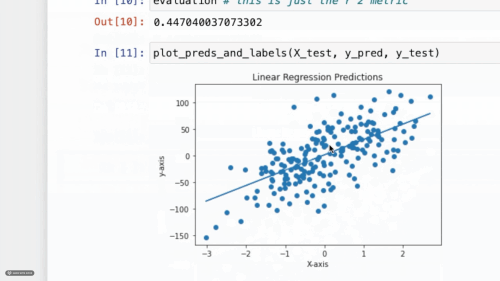
The first machine learning framework that encourages learning ML concepts instead of memorizing class functions.
SeaLion is designed to teach today's aspiring ml-engineers the popular machine learning concepts of today in a way that gives both intuition and ways of application. We do this through concise algorithms that do the job in the least jargon possible and examples to guide you through every step of the way.
 324 Dec 27, 2022
324 Dec 27, 2022
Knowledge Management for Humans using Machine Learning & Tags
HyperTag HyperTag helps humans intuitively express how they think about their files using tags and machine learning.
 165 Nov 4, 2022
165 Nov 4, 2022
Dockerized iCloud drive
iCloud-drive-docker is a simple iCloud drive client in Docker environment. It uses pyiCloud python library to interact with iCloud
 376 Jan 1, 2023
376 Jan 1, 2023
Knowledge Management for Humans using Machine Learning & Tags
HyperTag helps humans intuitively express how they think about their files using tags and machine learning. Represent how you think using tags. Find what you look for using semantic search for your text documents (yes, even PDF's) and images.
166 Jan 7, 2023
Generate modern Python clients from OpenAPI
openapi-python-client Generate modern Python clients from OpenAPI 3.x documents. This generator does not support OpenAPI 2.x FKA Swagger. If you need
 558 Jan 7, 2023
558 Jan 7, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 11.7k Feb 18, 2021
11.7k Feb 18, 2021

NeuralQA: A Usable Library for Question Answering on Large Datasets with BERT
NeuralQA: A Usable Library for (Extractive) Question Answering on Large Datasets with BERT Still in alpha, lots of changes anticipated. View demo on n
 184 Feb 10, 2021
184 Feb 10, 2021
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
 718 Feb 18, 2021
718 Feb 18, 2021

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 1.5k Feb 17, 2021
1.5k Feb 17, 2021
:mag: End-to-End Framework for building natural language search interfaces to data by utilizing Transformers and the State-of-the-Art of NLP. Supporting DPR, Elasticsearch, HuggingFace’s Modelhub and much more!
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
 1.4k Feb 18, 2021
1.4k Feb 18, 2021
Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabu
 4.8k Feb 18, 2021
4.8k Feb 18, 2021
A Python tool to automate some dorking stuff to find information disclosures.
WebDork v1.0.3 A open-source tool to find publicly available sensitive information about Companies/Organisations! WebDork A Python tool to automate so
 123 Jan 8, 2023
123 Jan 8, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
11.7k Feb 12, 2021
NeuralQA: A Usable Library for Question Answering on Large Datasets with BERT
NeuralQA: A Usable Library for (Extractive) Question Answering on Large Datasets with BERT Still in alpha, lots of changes anticipated. View demo on n
220 Dec 11, 2022
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
847 Dec 19, 2022
Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
2k Dec 27, 2022
Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabu
6.4k Jan 1, 2023

Learning embeddings for classification, retrieval and ranking.
StarSpace StarSpace is a general-purpose neural model for efficient learning of entity embeddings for solving a wide variety of problems: Learning wor
 3.8k Dec 22, 2022
3.8k Dec 22, 2022
Async ODM (Object Document Mapper) for MongoDB based on python type hints
ODMantic Documentation: https://art049.github.io/odmantic/ Asynchronous ODM(Object Document Mapper) for MongoDB based on standard python type hints. I
 732 Dec 31, 2022
732 Dec 31, 2022
A Python Object-Document-Mapper for working with MongoDB
MongoEngine Info: MongoEngine is an ORM-like layer on top of PyMongo. Repository: https://github.com/MongoEngine/mongoengine Author: Harry Marr (http:
 3.9k Jan 8, 2023
3.9k Jan 8, 2023
flask-apispec MIT flask-apispec (🥉24 · ⭐ 520) - Build and document REST APIs with Flask and apispec. MIT
flask-apispec flask-apispec is a lightweight tool for building REST APIs in Flask. flask-apispec uses webargs for request parsing, marshmallow for res
 617 Dec 30, 2022
617 Dec 30, 2022
Web Content Retrieval for Humans™
Lassie Lassie is a Python library for retrieving basic content from websites. Usage import lassie lassie.fetch('http://www.youtube.com/watch?v
 570 Dec 19, 2022
570 Dec 19, 2022
The awesome document factory
The Awesome Document Factory WeasyPrint is a smart solution helping web developers to create PDF documents. It turns simple HTML pages into gorgeous s
 5.4k Jan 7, 2023
5.4k Jan 7, 2023

CCKS-Title-based-large-scale-commodity-entity-retrieval-top1
- 基于标题的大规模商品实体检索top1 一、任务介绍 CCKS 2020:基于标题的大规模商品实体检索,任务为对于给定的一个商品标题,参赛系统需要匹配到该标题在给定商品库中的对应商品实体。 输入:输入文件包括若干行商品标题。 输出:输出文本每一行包括此标题对应的商品实体,即给定知识库中商品 ID,
 43 Nov 11, 2022
43 Nov 11, 2022
Web Content Retrieval for Humans™
Lassie Lassie is a Python library for retrieving basic content from websites. Usage import lassie lassie.fetch('http://www.youtube.com/watch?v
571 Dec 29, 2022
Universal Office Converter - Convert between any document format supported by LibreOffice/OpenOffice.
Automated conversion and styling using LibreOffice Universal Office Converter (unoconv) is a command line tool to convert any document format that Lib
 2.4k Jan 3, 2023
2.4k Jan 3, 2023
Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs (CIKM 2020)
Karate Club is an unsupervised machine learning extension library for NetworkX. Please look at the Documentation, relevant Paper, Promo Video, and Ext
1.8k Jan 9, 2023
A Python Object-Document-Mapper for working with MongoDB
MongoEngine Info: MongoEngine is an ORM-like layer on top of PyMongo. Repository: https://github.com/MongoEngine/mongoengine Author: Harry Marr (http:
3.9k Dec 30, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 2, 2023
A Python package implementing a new model for text classification with visualization tools for Explainable AI :octocat:
A Python package implementing a new model for text classification with visualization tools for Explainable AI 🍣 Online live demos: http://tworld.io/s
 285 Jan 2, 2023
285 Jan 2, 2023
Accelerated deep learning R&D
Accelerated deep learning R&D PyTorch framework for Deep Learning research and development. It focuses on reproducibility, rapid experimentation, and
 3.1k Jan 6, 2023
3.1k Jan 6, 2023
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2020 Links Doc
4.2k Jan 2, 2023
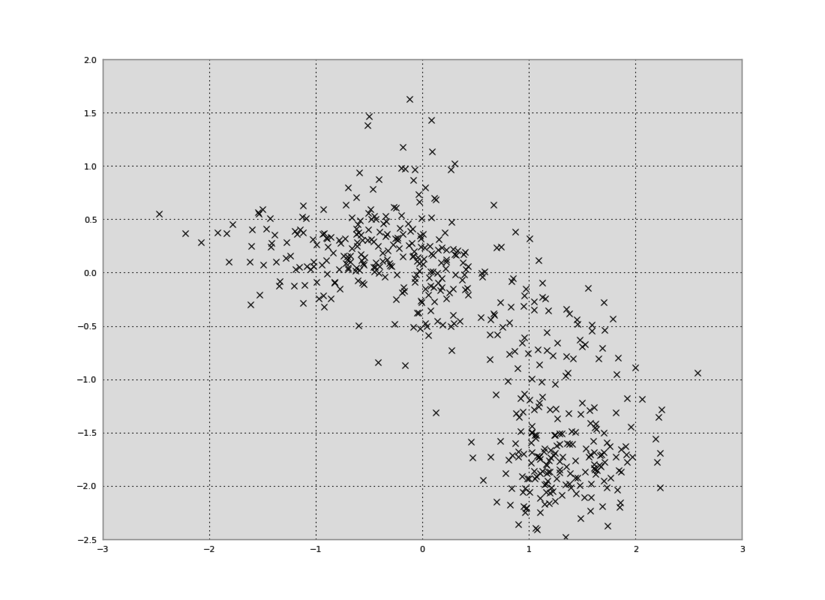
pyhsmm - library for approximate unsupervised inference in Bayesian Hidden Markov Models (HMMs) and explicit-duration Hidden semi-Markov Models (HSMMs), focusing on the Bayesian Nonparametric extensions, the HDP-HMM and HDP-HSMM, mostly with weak-limit approximations.
Bayesian inference in HSMMs and HMMs This is a Python library for approximate unsupervised inference in Bayesian Hidden Markov Models (HMMs) and expli
 527 Dec 4, 2022
527 Dec 4, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 3, 2023