1440 Repositories
Python video-recognition Libraries
Awesome Video Datasets
Awesome Video Datasets
 462 Jan 2, 2023
462 Jan 2, 2023
Espresso: A Fast End-to-End Neural Speech Recognition Toolkit
Espresso Espresso is an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit based on the deep learning libra
 919 Jan 3, 2023
919 Jan 3, 2023
pytorch-kaldi is a project for developing state-of-the-art DNN/RNN hybrid speech recognition systems. The DNN part is managed by pytorch, while feature extraction, label computation, and decoding are performed with the kaldi toolkit.
The PyTorch-Kaldi Speech Recognition Toolkit PyTorch-Kaldi is an open-source repository for developing state-of-the-art DNN/HMM speech recognition sys
 2.3k Dec 27, 2022
2.3k Dec 27, 2022

Pytorch-Named-Entity-Recognition-with-BERT
BERT NER Use google BERT to do CoNLL-2003 NER ! Train model using Python and Inference using C++ ALBERT-TF2.0 BERT-NER-TENSORFLOW-2.0 BERT-SQuAD Requi
 1.1k Dec 25, 2022
1.1k Dec 25, 2022
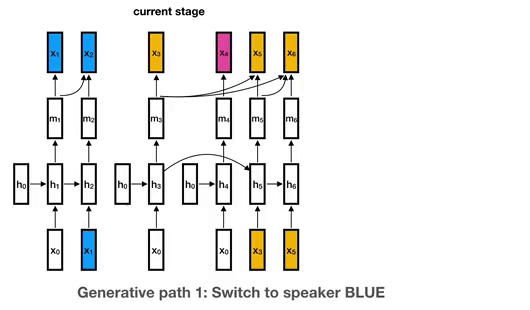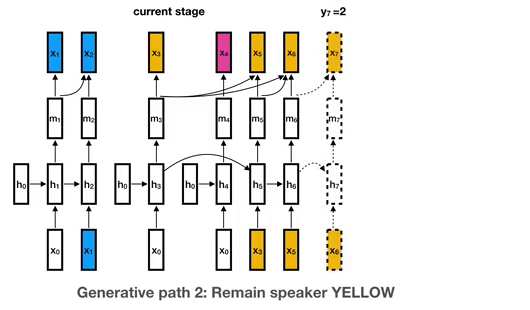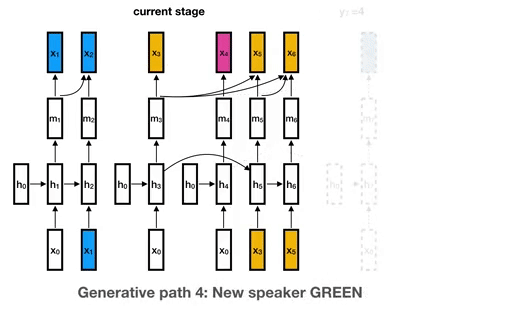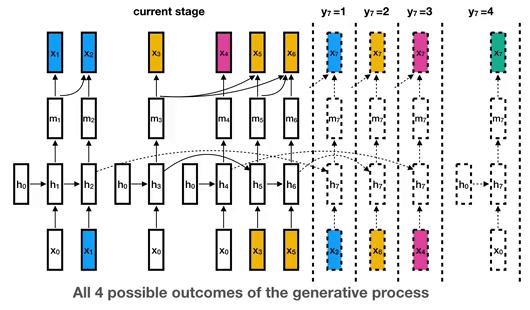
This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization.
UIS-RNN Overview This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm. UIS-RNN solves the problem of s
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.0.1 1.1.0 1.2.0 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 ubuntu18/python3.8/pip ubuntu18
 5.9k Jan 3, 2023
5.9k Jan 3, 2023
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
 2.2k Jan 9, 2023
2.2k Jan 9, 2023
Sequence-to-Sequence Framework in PyTorch
nmtpytorch allows training of various end-to-end neural architectures including but not limited to neural machine translation, image captioning and au
 395 Nov 21, 2022
395 Nov 21, 2022
An easier way to build neural search on the cloud
Jina is geared towards building search systems for any kind of data, including text, images, audio, video and many more. With the modular design & multi-layer abstraction, you can leverage the efficient patterns to build the system by parts, or chaining them into a Flow for an end-to-end experience.
 17k Jan 1, 2023
17k Jan 1, 2023
Learning Representational Invariances for Data-Efficient Action Recognition
Learning Representational Invariances for Data-Efficient Action Recognition Official PyTorch implementation for Learning Representational Invariances
 27 Nov 22, 2022
27 Nov 22, 2022
An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models.
DeepNER An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models. This repository contains complex Deep
 9 May 30, 2022
9 May 30, 2022

A simple image/video to Desmos graph converter run locally
Desmos Bezier Renderer A simple image/video to Desmos graph converter run locally Sample Result Setup Install dependencies apt update apt install git
 339 Dec 23, 2022
339 Dec 23, 2022

All in one Search Engine Scrapper for used by API or Python Module. It's Free!
All in one Search Engine Scrapper for used by API or Python Module. How to use: Video Documentation Senginta is All in one Search Engine Scrapper. Wit
 33 Nov 21, 2022
33 Nov 21, 2022

Location-Sensitive Visual Recognition with Cross-IOU Loss
The trained models are temporarily unavailable, but you can train the code using reasonable computational resource. Location-Sensitive Visual Recognit
 146 Dec 25, 2022
146 Dec 25, 2022
Implementation of "Efficient Regional Memory Network for Video Object Segmentation" (Xie et al., CVPR 2021).
RMNet This repository contains the source code for the paper Efficient Regional Memory Network for Video Object Segmentation. Cite this work @inprocee
 76 Dec 14, 2022
76 Dec 14, 2022
[CVPR 2021] MiVOS - Mask Propagation module. Reproduced STM (and better) with training code :star2:. Semi-supervised video object segmentation evaluation.
MiVOS (CVPR 2021) - Mask Propagation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [arXiv] [Paper PDF] [Project Page] [Papers with Code] This repo impleme
 106 Jan 3, 2023
106 Jan 3, 2023

Official Pytorch implementation of "Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video", CVPR 2021
TCMR: Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video Qualtitative result Paper teaser video Introduction This r
 215 Jan 6, 2023
215 Jan 6, 2023
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
 107 Dec 2, 2022
107 Dec 2, 2022
Semi-supervised Video Deraining with Dynamical Rain Generator (CVPR, 2021, Pytorch)
S2VD Semi-supervised Video Deraining with Dynamical Rain Generator (CVPR, 2021) Requirements and Dependencies Ubuntu 16.04, cuda 10.0 Python 3.6.10, P
 53 Nov 23, 2022
53 Nov 23, 2022

Improving Calibration for Long-Tailed Recognition (CVPR2021)
Improving Calibration for Long-Tailed Recognition (CVPR2021)
 19 Apr 28, 2021
19 Apr 28, 2021
This is a simple collection of instructions and scripts to accompany the computerphile video about mininet and openflow.
How to get going. This project should work on Linux or MacOS. I used Ubuntu 20.04 and provide some notes here. Note, this is certainly not intended as
 70 Jan 2, 2023
70 Jan 2, 2023

An official implementation for "CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval"
The implementation of paper CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval. CLIP4Clip is a video-text retrieval model based
 456 Jan 6, 2023
456 Jan 6, 2023
[TIP2020] Adaptive Graph Representation Learning for Video Person Re-identification
Introduction This is the PyTorch implementation for Adaptive Graph Representation Learning for Video Person Re-identification. Get started git clone h
 41 Dec 12, 2022
41 Dec 12, 2022
The official pytorch implemention of the CVPR paper "Temporal Modulation Network for Controllable Space-Time Video Super-Resolution".
This is the official PyTorch implementation of TMNet in the CVPR 2021 paper "Temporal Modulation Network for Controllable Space-Time VideoSuper-Resolu
 95 Oct 24, 2022
95 Oct 24, 2022
Improving Calibration for Long-Tailed Recognition (CVPR2021)
MiSLAS Improving Calibration for Long-Tailed Recognition Authors: Zhisheng Zhong, Jiequan Cui, Shu Liu, Jiaya Jia [arXiv] [slide] [BibTeX] Introductio
116 Dec 20, 2022

This repo contains the official code of our work SAM-SLR which won the CVPR 2021 Challenge on Large Scale Signer Independent Isolated Sign Language Recognition.
Skeleton Aware Multi-modal Sign Language Recognition By Songyao Jiang, Bin Sun, Lichen Wang, Yue Bai, Kunpeng Li and Yun Fu. Smile Lab @ Northeastern
 128 Dec 8, 2022
128 Dec 8, 2022

Implementation of "Distribution Alignment: A Unified Framework for Long-tail Visual Recognition"(CVPR 2021)
Implementation of "Distribution Alignment: A Unified Framework for Long-tail Visual Recognition"(CVPR 2021)
 105 Nov 7, 2022
105 Nov 7, 2022

Training code of Spatial Time Memory Network. Semi-supervised video object segmentation.
Training-code-of-STM This repository fully reproduces Space-Time Memory Networks Performance on Davis17 val set&Weights backbone training stage traini
 128 Dec 11, 2022
128 Dec 11, 2022
SpikeX - SpaCy Pipes for Knowledge Extraction
SpikeX is a collection of pipes ready to be plugged in a spaCy pipeline. It aims to help in building knowledge extraction tools with almost-zero effort.
 384 Dec 12, 2022
384 Dec 12, 2022
Activity image-based video retrieval
Cross-modal-retrieval Our approach is focus on Activity Image-to-Video Retrieval (AIVR) task. The compared methods are state-of-the-art single modalit
 75 Oct 21, 2021
75 Oct 21, 2021
Syntax-Aware Action Targeting for Video Captioning
Syntax-Aware Action Targeting for Video Captioning Code for SAAT from "Syntax-Aware Action Targeting for Video Captioning" (Accepted to CVPR 2020). Th
 59 Oct 13, 2022
59 Oct 13, 2022

TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks
TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks [Paper] [Project Website] This repository holds the source code, pretra
 83 Dec 21, 2022
83 Dec 21, 2022

VideoGPT: Video Generation using VQ-VAE and Transformers
VideoGPT: Video Generation using VQ-VAE and Transformers [Paper][Website][Colab][Gradio Demo] We present VideoGPT: a conceptually simple architecture
 470 Dec 30, 2022
470 Dec 30, 2022
DVG-Face: Dual Variational Generation for Heterogeneous Face Recognition, TPAMI 2021
DVG-Face: Dual Variational Generation for HFR This repo is a PyTorch implementation of DVG-Face: Dual Variational Generation for Heterogeneous Face Re
 52 Dec 30, 2022
52 Dec 30, 2022
PyTorch Lightning implementation of Automatic Speech Recognition
lasr Lightening Automatic Speech Recognition An MIT License ASR research library, built on PyTorch-Lightning, for developing end-to-end ASR models. In
 40 Sep 19, 2022
40 Sep 19, 2022

It is a simple python package to play videos in the terminal using characters as pixels
It is a simple python package to play videos in the terminal using characters as pixels
 1.4k Jan 7, 2023
1.4k Jan 7, 2023
OpenMMLab Text Detection, Recognition and Understanding Toolbox
Introduction English | 简体中文 MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the correspondi
 3k Jan 7, 2023
3k Jan 7, 2023

This repository allows you to anonymize sensitive information in images/videos. The solution is fully compatible with the DL-based training/inference solutions that we already published/will publish for Object Detection and Semantic Segmentation.
BMW-Anonymization-Api Data privacy and individuals’ anonymity are and always have been a major concern for data-driven companies. Therefore, we design
 148 Dec 21, 2022
148 Dec 21, 2022

Diffgram - Supervised Learning Data Platform
Data Annotation, Data Labeling, Annotation Tooling, Training Data for Machine Learning
 1.6k Jan 7, 2023
1.6k Jan 7, 2023
The official pytorch implementation of our paper "Is Space-Time Attention All You Need for Video Understanding?"
TimeSformer This is an official pytorch implementation of Is Space-Time Attention All You Need for Video Understanding?. In this repository, we provid
 1k Dec 31, 2022
1k Dec 31, 2022
Official implementation of ACTION-Net: Multipath Excitation for Action Recognition (CVPR'21).
ACTION-Net Official implementation of ACTION-Net: Multipath Excitation for Action Recognition (CVPR'21). Getting Started EgoGesture data folder struct
 171 Dec 26, 2022
171 Dec 26, 2022

MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images
Main repo for ECCV 2020 paper MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images. visual.cs.brown.edu/matryodshka
 75 Dec 13, 2022
75 Dec 13, 2022
OpenMMLab's Next Generation Video Understanding Toolbox and Benchmark
Introduction English | 简体中文 MMAction2 is an open-source toolbox for video understanding based on PyTorch. It is a part of the OpenMMLab project. The m
2.7k Jan 7, 2023
OpenMMLab Image and Video Editing Toolbox
Introduction MMEditing is an open source image and video editing toolbox based on PyTorch. It is a part of the OpenMMLab project. The master branch wo
3.9k Jan 4, 2023
An end-to-end PyTorch framework for image and video classification
What's New: March 2021: Added RegNetZ models November 2020: Vision Transformers now available, with training recipes! 2020-11-20: Classy Vision v0.5 R
1.5k Dec 31, 2022

Pretrained Pytorch face detection (MTCNN) and recognition (InceptionResnet) models
Face Recognition Using Pytorch Python 3.7 3.6 3.5 Status This is a repository for Inception Resnet (V1) models in pytorch, pretrained on VGGFace2 and
 3.3k Jan 4, 2023
3.3k Jan 4, 2023

Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
 176 Nov 28, 2022
176 Nov 28, 2022

Official PyTorch implementation of "IntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos", CVPRW 2021
IntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos Introduction This repo is official PyTorch implementatio
 29 Sep 24, 2022
29 Sep 24, 2022

PRTR: Pose Recognition with Cascade Transformers
PRTR: Pose Recognition with Cascade Transformers Introduction This repository is the official implementation for Pose Recognition with Cascade Transfo
 133 Dec 30, 2022
133 Dec 30, 2022
Code for the paper "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021)
MASTER-PyTorch PyTorch reimplementation of "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021). This projec
 255 Dec 29, 2022
255 Dec 29, 2022
A Paper List for Speech Translation
Keyword: Speech Translation, Spoken Language Processing, Natural Language Processing
 138 Dec 24, 2022
138 Dec 24, 2022
PyTorchVideo is a deeplearning library with a focus on video understanding work
PyTorchVideo is a deeplearning library with a focus on video understanding work. PytorchVideo provides resusable, modular and efficient components needed to accelerate the video understanding research. PyTorchVideo is developed using PyTorch and supports different deeplearning video components like video models, video datasets, and video-specific transforms.
2.7k Jan 7, 2023

3D ResNet Video Classification accelerated by TensorRT
Activity Recognition TensorRT Perform video classification using 3D ResNets trained on Kinetics-400 dataset and accelerated with TensorRT P.S Click on
 39 Nov 21, 2022
39 Nov 21, 2022
PyTorch reimplementation of the paper Involution: Inverting the Inherence of Convolution for Visual Recognition [CVPR 2021].
Involution: Inverting the Inherence of Convolution for Visual Recognition Unofficial PyTorch reimplementation of the paper Involution: Inverting the I
 100 Dec 1, 2022
100 Dec 1, 2022

FireDM is a python open source (Internet Download Manager) with multi-connections, high speed engine, it downloads general files and videos from youtube and tons of other streaming websites .
python open source (Internet Download Manager) with multi-connections, high speed engine, based on python, LibCurl, and youtube_dl https://github.com/firedm/FireDM
 1.6k Apr 12, 2022
1.6k Apr 12, 2022
Bulk Downloader for Reddit
saveddit is a bulk media downloader for reddit pip3 install saveddit Setting up authorization Register an application with Reddit Write down your clie
 136 Jan 3, 2023
136 Jan 3, 2023

Implementation of ViViT: A Video Vision Transformer
ViViT: A Video Vision Transformer Unofficial implementation of ViViT: A Video Vision Transformer. Notes: This is in WIP. Model 2 is implemented, Model
 297 Jan 6, 2023
297 Jan 6, 2023

Learning recognition/segmentation models without end-to-end training. 40%-60% less GPU memory footprint. Same training time. Better performance.
InfoPro-Pytorch The Information Propagation algorithm for training deep networks with local supervision. (ICLR 2021) Revisiting Locally Supervised Lea
 78 Dec 27, 2022
78 Dec 27, 2022
![[AAAI 2021] MVFNet: Multi-View Fusion Network for Efficient Video Recognition](https://github.com/whwu95/MVFNet/raw/main/mvfnet.png)
[AAAI 2021] MVFNet: Multi-View Fusion Network for Efficient Video Recognition
MVFNet: Multi-View Fusion Network for Efficient Video Recognition (AAAI 2021) Overview We release the code of the MVFNet (Multi-View Fusion Network).
 114 Nov 27, 2022
114 Nov 27, 2022
Spontaneous Facial Micro Expression Recognition using 3D Spatio-Temporal Convolutional Neural Networks
Spontaneous Facial Micro Expression Recognition using 3D Spatio-Temporal Convolutional Neural Networks Abstract Facial expression recognition in video
 103 Dec 29, 2022
103 Dec 29, 2022

Official implementation for NIPS'17 paper: PredRNN: Recurrent Neural Networks for Predictive Learning Using Spatiotemporal LSTMs.
PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning The predictive learning of spatiotemporal sequences aims to generate future
 243 Dec 26, 2022
243 Dec 26, 2022

Code for "NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video", CVPR 2021 oral
NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video Project Page | Paper NeuralRecon: Real-Time Coherent 3D Reconstruction from Mon
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

SimDeblur is a simple framework for image and video deblurring, implemented by PyTorch
SimDeblur (Simple Deblurring) is an open source framework for image and video deblurring toolbox based on PyTorch, which contains most deep-learning based state-of-the-art deblurring algorithms. It is easy to implement your own image or video deblurring or other restoration algorithms.
 220 Jan 7, 2023
220 Jan 7, 2023
Official implementation of "An Image is Worth 16x16 Words, What is a Video Worth?" (2021 paper)
An Image is Worth 16x16 Words, What is a Video Worth? paper Official PyTorch Implementation Gilad Sharir, Asaf Noy, Lihi Zelnik-Manor DAMO Academy, Al
 213 Nov 12, 2022
213 Nov 12, 2022
Command-line program to download videos from YouTube.com and other video sites
youtube-dl - download videos from youtube.com or other video platforms
 116.4k Jan 7, 2023
116.4k Jan 7, 2023

This is the official PyTorch implementation of the paper "TransFG: A Transformer Architecture for Fine-grained Recognition" (Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, Changhu Wang, Alan Yuille).
TransFG: A Transformer Architecture for Fine-grained Recognition Official PyTorch code for the paper: TransFG: A Transformer Architecture for Fine-gra
 307 Jan 3, 2023
307 Jan 3, 2023

Implementation of STAM (Space Time Attention Model), a pure and simple attention model that reaches SOTA for video classification
STAM - Pytorch Implementation of STAM (Space Time Attention Model), yet another pure and simple SOTA attention model that bests all previous models in
 109 Dec 28, 2022
109 Dec 28, 2022
This is the official PyTorch implementation of the paper "TransFG: A Transformer Architecture for Fine-grained Recognition" (Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, Changhu Wang, Alan Yuille).
TransFG: A Transformer Architecture for Fine-grained Recognition Official PyTorch code for the paper: TransFG: A Transformer Architecture for Fine-gra
307 Jan 3, 2023
A Telegram Video Watermark Adder Bot in Pyrogram by @AbirHasan2005
Watermark-Bot A Telegram Video Watermark Adder Bot by @AbirHasan2005 Features: Save Custom Watermark Image. Auto Resize Watermark According to Video q
 95 Nov 20, 2022
95 Nov 20, 2022
Hybrid Neural Fusion for Full-frame Video Stabilization
FuSta: Hybrid Neural Fusion for Full-frame Video Stabilization Project Page | Video | Paper | Google Colab Setup Setup environment for [Yu and Ramamoo
 430 Jan 4, 2023
430 Jan 4, 2023

Polaris is a Face recognition attendance system .
Support Me 🚀 About Polaris 📄 Polaris is a system based on facial recognition with a futuristic GUI design, Can easily find people informations store
 215 Dec 26, 2022
215 Dec 26, 2022

This code extends the neural style transfer image processing technique to video by generating smooth transitions between several reference style images
Neural Style Transfer Transition Video Processing By Brycen Westgarth and Tristan Jogminas Description This code extends the neural style transfer ima
 110 Jan 7, 2023
110 Jan 7, 2023

Tracking Progress in Natural Language Processing
Repository to track the progress in Natural Language Processing (NLP), including the datasets and the current state-of-the-art for the most common NLP tasks.
 21.2k Dec 30, 2022
21.2k Dec 30, 2022
Streamlink is a CLI utility which pipes video streams from various services into a video player
Streamlink is a CLI utility which pipes video streams from various services into a video player
 8.2k Dec 26, 2022
8.2k Dec 26, 2022
Implementation of LambdaNetworks, a new approach to image recognition that reaches SOTA with less compute
Lambda Networks - Pytorch Implementation of λ Networks, a new approach to image recognition that reaches SOTA on ImageNet. The new method utilizes λ l
1.5k Jan 7, 2023

Rembg Video Virtual Green Screen Edition
Rembg Virtual Greenscreen Edition is a tool to create a green screen matte for videos
 61 Mar 28, 2021
61 Mar 28, 2021
An easier way to build neural search on the cloud
An easier way to build neural search on the cloud Jina is a deep learning-powered search framework for building cross-/multi-modal search systems (e.g
17k Jan 2, 2023
Conversion of Image, video, text into ASCII format
asciju Python package that converts image to ascii Free software: MIT license
 11 Aug 22, 2022
11 Aug 22, 2022
![[CVPR2021 Oral] FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation.](https://github.com/ethnhe/FFB6D/raw/master/figs/FFB6D_overview.png)
[CVPR2021 Oral] FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation.
FFB6D This is the official source code for the CVPR2021 Oral work, FFB6D: A Full Flow Biderectional Fusion Network for 6D Pose Estimation. (Arxiv) Tab
 201 Dec 28, 2022
201 Dec 28, 2022

Source code of our TPAMI'21 paper Dual Encoding for Video Retrieval by Text and CVPR'19 paper Dual Encoding for Zero-Example Video Retrieval.
Dual Encoding for Video Retrieval by Text Source code of our TPAMI'21 paper Dual Encoding for Video Retrieval by Text and CVPR'19 paper Dual Encoding
 81 Dec 1, 2022
81 Dec 1, 2022

When Age-Invariant Face Recognition Meets Face Age Synthesis: A Multi-Task Learning Framework (CVPR 2021 oral)
MTLFace This repository contains the PyTorch implementation and the dataset of the paper: When Age-Invariant Face Recognition Meets Face Age Synthesis
 120 Jan 5, 2023
120 Jan 5, 2023

Convolutional Recurrent Neural Networks(CRNN) for Scene Text Recognition
CRNN_Tensorflow This is a TensorFlow implementation of a Deep Neural Network for scene text recognition. It is mainly based on the paper "An End-to-En
 1000 Dec 27, 2022
1000 Dec 27, 2022
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023

Text recognition (optical character recognition) with deep learning methods.
What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis | paper | training and evaluation data | failure cases and cle
 3.2k Jan 4, 2023
3.2k Jan 4, 2023
A curated list of awesome synthetic data for text location and recognition
awesome-SynthText A curated list of awesome synthetic data for text location and recognition and OCR datasets. Text location SynthText SynthText_Chine
 283 Jan 5, 2023
283 Jan 5, 2023

A synthetic data generator for text recognition
TextRecognitionDataGenerator A synthetic data generator for text recognition What is it for? Generating text image samples to train an OCR software. N
 2.5k Jan 4, 2023
2.5k Jan 4, 2023
Geometric Augmentation for Text Image
Text Image Augmentation A general geometric augmentation tool for text images in the CVPR 2020 paper "Learn to Augment: Joint Data Augmentation and Ne
 440 Jan 5, 2023
440 Jan 5, 2023

Total Text Dataset. It consists of 1555 images with more than 3 different text orientations: Horizontal, Multi-Oriented, and Curved, one of a kind.
Total-Text-Dataset (Official site) Updated on April 29, 2020 (Detection leaderboard is updated - highlighted E2E methods. Thank you shine-lcy.) Update
 671 Dec 27, 2022
671 Dec 27, 2022
OCR, Scene-Text-Understanding, Text Recognition
Scene-Text-Understanding Survey [2015-PAMI] Text Detection and Recognition in Imagery: A Survey paper [2014-Front.Comput.Sci] Scene Text Detection and
 354 Dec 12, 2022
354 Dec 12, 2022
Tracking the latest progress in Scene Text Detection and Recognition: Must-read papers well organized
SceneTextPapers Tracking the latest progress in Scene Text Detection and Recognition: must-read papers well organized Information about this repositor
 763 Jan 1, 2023
763 Jan 1, 2023
A collection of resources (including the papers and datasets) of OCR (Optical Character Recognition).
OCR Resources This repository contains a collection of resources (including the papers and datasets) of OCR (Optical Character Recognition). Contents
 363 Jan 3, 2023
363 Jan 3, 2023
A curated list of papers and resources for scene text detection and recognition
Awesome Scene Text A curated list of papers and resources for scene text detection and recognition The year when a paper was first published, includin
 43 Mar 15, 2022
43 Mar 15, 2022

A curated list of resources for text detection/recognition (optical character recognition ) with deep learning methods.
awesome-deep-text-detection-recognition A curated list of awesome deep learning based papers on text detection and recognition. Text Detection Papers
 2.4k Jan 8, 2023
2.4k Jan 8, 2023
A curated list of resources dedicated to scene text localization and recognition
Scene Text Localization & Recognition Resources A curated list of resources dedicated to scene text localization and recognition. Any suggestions and
 1.6k Dec 22, 2022
1.6k Dec 22, 2022
A general list of resources to image text localization and recognition 场景文本位置感知与识别的论文资源与实现合集 シーンテキストの位置認識と識別のための論文リソースの要約
Scene Text Localization & Recognition Resources Read this institute-wise: English, 简体中文. Read this year-wise: English, 简体中文. Tags: [STL] (Scene Text L
 901 Dec 11, 2022
901 Dec 11, 2022
Go package for OCR (Optical Character Recognition), by using Tesseract C++ library
gosseract OCR Golang OCR package, by using Tesseract C++ library. OCR Server Do you just want OCR server, or see the working example of this package?
 1.9k Dec 28, 2022
1.9k Dec 28, 2022
Provides OCR (Optical Character Recognition) services through web applications
OCR4all As suggested by the name one of the main goals of OCR4all is to allow basically any given user to independently perform OCR on a wide variety
 174 Dec 31, 2022
174 Dec 31, 2022
A Tensorflow model for text recognition (CNN + seq2seq with visual attention) available as a Python package and compatible with Google Cloud ML Engine.
Attention-based OCR Visual attention-based OCR model for image recognition with additional tools for creating TFRecords datasets and exporting the tra
 933 Dec 29, 2022
933 Dec 29, 2022

make a better chinese character recognition OCR than tesseract
deep ocr See README_en.md for English installation documentation. 只在ubuntu下面测试通过,需要virtualenv安装,安装路径可自行调整: git clone https://github.com/JinpengLI/deep
 1.5k Dec 28, 2022
1.5k Dec 28, 2022