1440 Repositories
Python video-recognition Libraries
Robust Consistent Video Depth Estimation
[CVPR 2021] Robust Consistent Video Depth Estimation This repository contains Python and C++ implementation of Robust Consistent Video Depth, as descr
 213 Dec 17, 2022
213 Dec 17, 2022

Code for Two-stage Identifier: "Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition"
Code for Two-stage Identifier: "Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition", accepted at ACL 2021. For details of the model and experiments, please see our paper.
 87 Dec 16, 2022
87 Dec 16, 2022

Attention mechanism with MNIST dataset
[TensorFlow] Attention mechanism with MNIST dataset Usage $ python run.py Result Training Loss graph. Test Each figure shows input digit, attention ma
 12 Jun 10, 2022
12 Jun 10, 2022
Implementation of FitVid video prediction model in JAX/Flax.
FitVid Video Prediction Model Implementation of FitVid video prediction model in JAX/Flax. If you find this code useful, please cite it in your paper:
 62 Nov 25, 2022
62 Nov 25, 2022
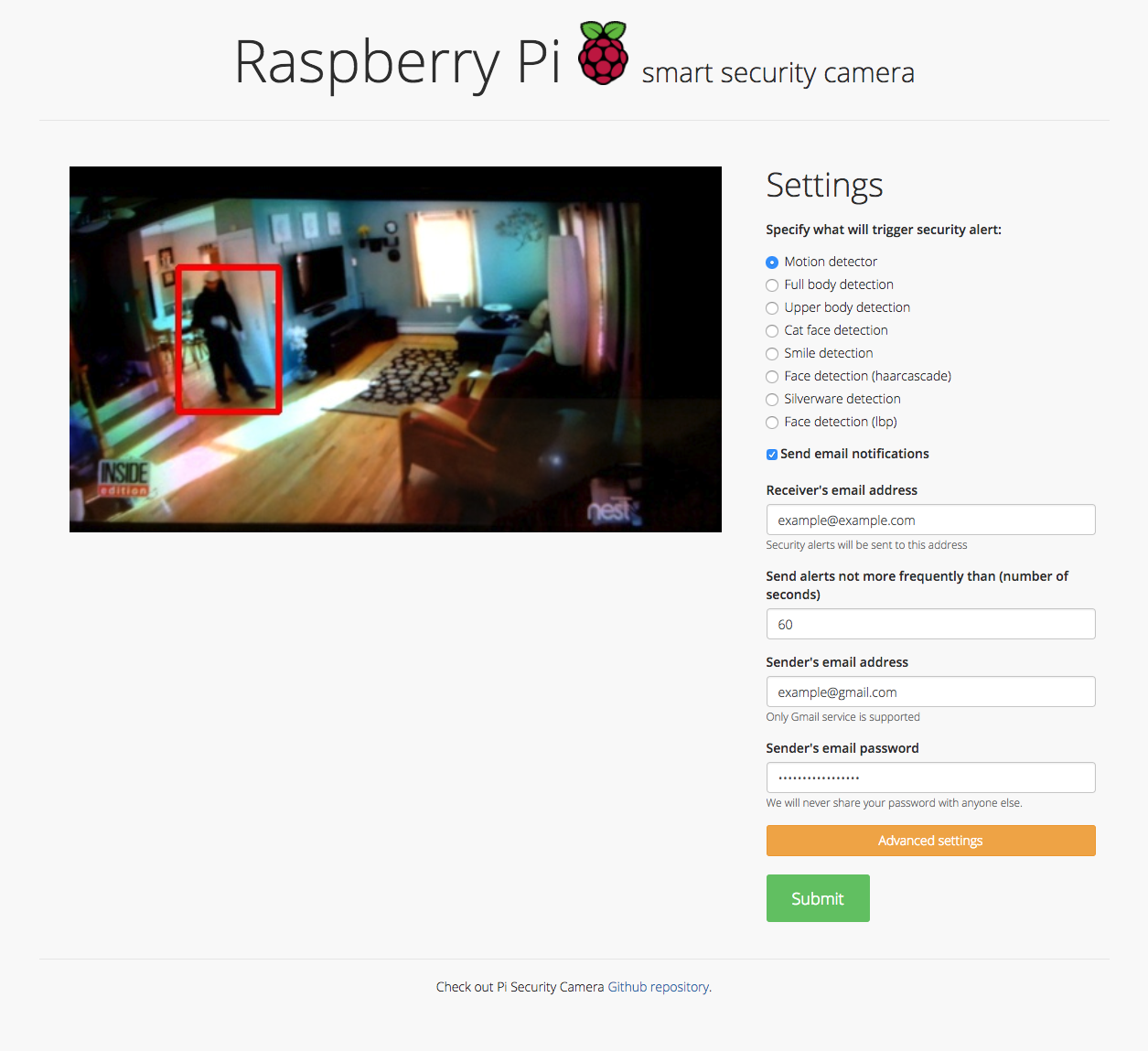
Motion detector, Full body detection, Upper body detection, Cat face detection, Smile detection, Face detection (haar cascade), Silverware detection, Face detection (lbp), and Sending email notifications
Security camera running OpenCV for object and motion detection. The camera will send email with image of any objects it detects. It also runs a server that provides web interface with live stream video.
 10 Jun 30, 2021
10 Jun 30, 2021
Some Boring Research About Products Recognition 、Duplicate Img Detection、Img Stitch、OCR
Products Recognition 介绍 商品识别,围绕在复杂的商场零售场景中,识别出货架图像中的商品信息。主要组成部分: 重复图像检测。【更新进度 4/10】 图像拼接。【更新进度 0/10】 目标检测。【更新进度 0/10】 商品识别。【更新进度 1/10】 OCR。【更新进度 1/10】
 18 Jan 27, 2022
18 Jan 27, 2022
Playing videos through S3 buckets (Wasabi, AWS, etc.) through client-side VideoJS player
Playing videos through S3 buckets (Wasabi, AWS, etc.) through client-side VideoJS player without incurring ingress/egree traffic on EC2 Instance.
 8 Mar 28, 2022
8 Mar 28, 2022

Orthogonal Over-Parameterized Training
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is of great importance. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. See our previous work -- MHE for an in-depth introduction.
 11 Apr 18, 2022
11 Apr 18, 2022
The repository for my video "Playing MINECRAFT with a WEBCAM"
This is the official repo for my video "Playing MINECRAFT with a WEBCAM" on YouTube Original video can be found here: https://youtu.be/701TPxL0Skg Red
 27 Jun 7, 2022
27 Jun 7, 2022

MLP-Like Vision Permutator for Visual Recognition (PyTorch)
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition (arxiv) This is a Pytorch implementation of our paper. We present Vision
 162 Nov 28, 2022
162 Nov 28, 2022

VOLO: Vision Outlooker for Visual Recognition
VOLO: Vision Outlooker for Visual Recognition, arxiv This is a PyTorch implementation of our paper. We present Vision Outlooker (VOLO). We show that o
 876 Dec 9, 2022
876 Dec 9, 2022

This is an official implementation for "Video Swin Transformers".
Video Swin Transformer By Ze Liu*, Jia Ning*, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin and Han Hu. This repo is the official implementation of "V
 981 Jan 3, 2023
981 Jan 3, 2023

Code for the RA-L (ICRA) 2021 paper "SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition"
SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition [ArXiv+Supplementary] [IEEE Xplore RA-L 2021] [ICRA 2021 YouTube Video]
 63 Dec 12, 2022
63 Dec 12, 2022
PyTorch implementation of the paper The Lottery Ticket Hypothesis for Object Recognition
LTH-ObjectRecognition The Lottery Ticket Hypothesis for Object Recognition Sharath Girish*, Shishira R Maiya*, Kamal Gupta, Hao Chen, Larry Davis, Abh
 16 Feb 6, 2022
16 Feb 6, 2022

Code for the CVPR2021 paper "Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition"
Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition This repository contains code for the CVPR2021 paper "Patch-NetV
 368 Jan 6, 2023
368 Jan 6, 2023
Code for "Primitive Representation Learning for Scene Text Recognition" (CVPR 2021)
Primitive Representation Learning Network (PREN) This repository contains the code for our paper accepted by CVPR 2021 Primitive Representation Learni
 76 Jan 2, 2023
76 Jan 2, 2023

Code for "LASR: Learning Articulated Shape Reconstruction from a Monocular Video". CVPR 2021.
LASR Installation Build with conda conda env create -f lasr.yml conda activate lasr # install softras cd third_party/softras; python setup.py install;
 157 Dec 26, 2022
157 Dec 26, 2022
The implementation of CVPR2021 paper Temporal Query Networks for Fine-grained Video Understanding, by Chuhan Zhang, Ankush Gupta and Andrew Zisserman.
Temporal Query Networks for Fine-grained Video Understanding 📋 This repository contains the implementation of CVPR2021 paper Temporal_Query_Networks
 55 Dec 21, 2022
55 Dec 21, 2022

Towards Long-Form Video Understanding
Towards Long-Form Video Understanding Chao-Yuan Wu, Philipp Krähenbühl, CVPR 2021 [Paper] [Project Page] [Dataset] Citation @inproceedings{lvu2021,
 69 Dec 26, 2022
69 Dec 26, 2022

Senginta is All in one Search Engine Scrapper for used by API or Python Module. It's Free!
Senginta is All in one Search Engine Scrapper. With traditional scrapping, Senginta can be powerful to get result from any Search Engine, and convert to Json. Now support only for Google Product Search Engine (GShop, GVideo and many too) and Baidu Search Engine.
 33 Nov 21, 2022
33 Nov 21, 2022
Speech Recognition for Uyghur using Speech transformer
Speech Recognition for Uyghur using Speech transformer Training: this model using CTC loss and Cross Entropy loss for training. Download pretrained mo
 11 Nov 17, 2022
11 Nov 17, 2022

PyTorch implementation of "ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context" (INTERSPEECH 2020)
ContextNet ContextNet has CNN-RNN-transducer architecture and features a fully convolutional encoder that incorporates global context information into
 24 Nov 24, 2022
24 Nov 24, 2022

Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models
Patch-Rotation(PatchRot) Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models Submitted to Neurips2021 To
 4 Jul 12, 2021
4 Jul 12, 2021
VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning
This is a release of our VIMPAC paper to illustrate the implementations. The pretrained checkpoints and scripts will be soon open-sourced in HuggingFace transformers.
 74 Dec 3, 2022
74 Dec 3, 2022

Isearch (OSINT) 🔎 Face recognition reverse image search on Instagram profile feed photos.
isearch is an OSINT tool on Instagram. Offers a face recognition reverse image search on Instagram profile feed photos.
 20 Oct 25, 2022
20 Oct 25, 2022
pygamevideo module helps developer to embed videos into their Pygame display
pygamevideo module helps developer to embed videos into their Pygame display. Audio playback doesn't use pygame.mixer.
 10 Dec 28, 2022
10 Dec 28, 2022
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021

This repository is an open-source implementation of the ICRA 2021 paper: Locus: LiDAR-based Place Recognition using Spatiotemporal Higher-Order Pooling.
Locus This repository is an open-source implementation of the ICRA 2021 paper: Locus: LiDAR-based Place Recognition using Spatiotemporal Higher-Order
 96 Dec 15, 2022
96 Dec 15, 2022

Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition The official code of ABINet (CVPR 2021, Oral).
 334 Dec 31, 2022
334 Dec 31, 2022
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022
![[CVPR 21] Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting, IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2021.](https://github.com/AyanKumarBhunia/Self-Supervised-Learning-for-Sketch/raw/main/sample_images/outline.png)
[CVPR 21] Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting, IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2021.
Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting, CVPR 2021. Ayan Kumar Bhunia, Pinaki nath Chowdhury, Yongxin Yan
 44 Dec 12, 2022
44 Dec 12, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
 544 Dec 19, 2022
544 Dec 19, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022

A gesture recognition system powered by OpenPose, k-nearest neighbours, and local outlier factor.
OpenHands OpenHands is a gesture recognition system powered by OpenPose, k-nearest neighbours, and local outlier factor. Currently the system can iden
 12 Jan 10, 2022
12 Jan 10, 2022

CT-Net: Channel Tensorization Network for Video Classification
[ICLR2021] CT-Net: Channel Tensorization Network for Video Classification @inproceedings{ li2021ctnet, title={{\{}CT{\}}-Net: Channel Tensorization Ne
 33 Nov 15, 2022
33 Nov 15, 2022

AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
4.6k Jan 9, 2023
easySpeech is an open-source Python wrapper for google speech to text API that doesn't require PyAudio(So you especially windows user don't have to deal with the errors while installing PyAudio) and also works with hugging face transformers
easySpeech easySpeech is an open source python wrapper for google speech to text api that doesn't require PyAaudio(So you specially windows user don't
 14 May 24, 2022
14 May 24, 2022

Official PyTorch code for CVPR 2020 paper "Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision"
Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision https://arxiv.org/abs/2003.00393 Abstract Active learning (AL) aims to min
 29 Nov 21, 2022
29 Nov 21, 2022

This is the official repository of XVFI (eXtreme Video Frame Interpolation)
XVFI This is the official repository of XVFI (eXtreme Video Frame Interpolation), https://arxiv.org/abs/2103.16206 Last Update: 20210607 We provide th
 195 Dec 29, 2022
195 Dec 29, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
544 Dec 19, 2022
A Telegram Video Merge Bot by @AbirHasan2005
VideoMerge-Bot This is very simple Telegram Videos Merge Bot by @AbirHasan2005. Using FFmpeg for Merging Videos. Features: Merge Multiple Videos. User
 57 Nov 12, 2022
57 Nov 12, 2022
Hand gesture recognition based whiteboard that allows you to write on live webcam. This is the first version and has features like 4 different colors, eraser and a recording option that records your session and saves it in a "recordings" folder. Use index finger to draw and two or more fingers to move around and select items. Future version will contain more functionalities like changeable thickness, color palette, integration with zoom and google meet etc.
hand-write Hand gesture recognition based whiteboard that allows you to write on live webcam. This is the first version and has features like 4 differ
 27 Dec 16, 2022
27 Dec 16, 2022
learn how to use Gesture Control to change the volume of a computer
Volume-Control-using-gesture In this project we are going to learn how to use Gesture Control to change the volume of a computer. We first look into h
 49 Sep 22, 2022
49 Sep 22, 2022
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
192 Dec 23, 2022

A lightweight deep network for fast and accurate optical flow estimation.
FastFlowNet: A Lightweight Network for Fast Optical Flow Estimation The official PyTorch implementation of FastFlowNet (ICRA 2021). Authors: Lingtong
 161 Jan 3, 2023
161 Jan 3, 2023
Towards End-to-end Video-based Eye Tracking
Towards End-to-end Video-based Eye Tracking The code accompanying our ECCV 2020 publication and dataset, EVE. Authors: Seonwook Park, Emre Aksan, Xuco
 76 Dec 12, 2022
76 Dec 12, 2022

SpanNER: Named EntityRe-/Recognition as Span Prediction
SpanNER: Named EntityRe-/Recognition as Span Prediction Overview | Demo | Installation | Preprocessing | Prepare Models | Running | System Combination
 104 Dec 17, 2022
104 Dec 17, 2022
It's final year project of Diploma Engineering. This project is based on Computer Vision.
Face-Recognition-Based-Attendance-System It's final year project of Diploma Engineering. This project is based on Computer Vision. Brief idea about ou
 10 Nov 2, 2022
10 Nov 2, 2022
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
STCN Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [a
 456 Dec 12, 2022
456 Dec 12, 2022

Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers.
Less is More: Pay Less Attention in Vision Transformers Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers. By
 73 Jan 1, 2023
73 Jan 1, 2023
Face recognition. Redefined.
FaceFinder Use a powerful CNN to identify faces in images! TABLE OF CONTENTS About The Project Built With Getting Started Prerequisites Installation U
 20 Jun 16, 2021
20 Jun 16, 2021

Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file
Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file. VISD can also perform vehicle speed detection on a video. All these features of VSID are provided to the user using a Web Application which is created using Flask
 6 Feb 22, 2022
6 Feb 22, 2022

InsightFace: 2D and 3D Face Analysis Project on MXNet and PyTorch
InsightFace: 2D and 3D Face Analysis Project on MXNet and PyTorch
 13.2k Jan 6, 2023
13.2k Jan 6, 2023

Open-Source Toolkit for End-to-End Speech Recognition leveraging PyTorch-Lightning and Hydra.
OpenSpeech provides reference implementations of various ASR modeling papers and three languages recipe to perform tasks on automatic speech recogniti
 86 Jun 11, 2021
86 Jun 11, 2021
Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. This Neural Network (NN) model recognizes the text contained in the images of segmented words.
Handwritten-Text-Recognition Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. T
 27 Jan 8, 2023
27 Jan 8, 2023
Open-Source Toolkit for End-to-End Speech Recognition leveraging PyTorch-Lightning and Hydra.
OpenSpeech provides reference implementations of various ASR modeling papers and three languages recipe to perform tasks on automatic speech recogniti
26 Dec 14, 2022

Official PyTorch implementation of "Adversarial Reciprocal Points Learning for Open Set Recognition"
Adversarial Reciprocal Points Learning for Open Set Recognition Official PyTorch implementation of "Adversarial Reciprocal Points Learning for Open Se
 78 Dec 28, 2022
78 Dec 28, 2022
Synthetic Humans for Action Recognition, IJCV 2021
SURREACT: Synthetic Humans for Action Recognition from Unseen Viewpoints Gül Varol, Ivan Laptev and Cordelia Schmid, Andrew Zisserman, Synthetic Human
 59 Dec 14, 2022
59 Dec 14, 2022
Ecommerce product title recognition package
revizor This package solves task of splitting product title string into components, like type, brand, model and article (or SKU or product code or you
 16 Mar 3, 2022
16 Mar 3, 2022

An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicity.
Fast Face Classification (F²C) This is the code of our paper An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicit
 33 Jun 27, 2021
33 Jun 27, 2021
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022

This is the research repository for Vid2Doppler: Synthesizing Doppler Radar Data from Videos for Training Privacy-Preserving Activity Recognition.
Vid2Doppler: Synthesizing Doppler Radar Data from Videos for Training Privacy-Preserving Activity Recognition This is the research repository for Vid2
 26 Dec 24, 2022
26 Dec 24, 2022

Avatarify Python - Avatars for Zoom, Skype and other video-conferencing apps.
Avatarify Python - Avatars for Zoom, Skype and other video-conferencing apps.
 15.3k Jan 5, 2023
15.3k Jan 5, 2023

Self-Learned Video Rain Streak Removal: When Cyclic Consistency Meets Temporal Correspondence
In this paper, we address the problem of rain streaks removal in video by developing a self-learned rain streak removal method, which does not require any clean groundtruth images in the training process.
 44 Dec 6, 2022
44 Dec 6, 2022
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions (CVPR2021)
NExT-QA We reproduce some SOTA VideoQA methods to provide benchmark results for our NExT-QA dataset accepted to CVPR2021 (with 1 'Strong Accept' and 2
 50 Nov 24, 2022
50 Nov 24, 2022

Anonymize BLM Protest Images
Anonymize BLM Protest Images This repository automates @BLMPrivacyBot, a Twitter bot that shows the anonymized images to help keep protesters safe. Us
 40 Oct 13, 2022
40 Oct 13, 2022
This is an official implementation for "ResT: An Efficient Transformer for Visual Recognition".
ResT By Qing-Long Zhang and Yu-Bin Yang [State Key Laboratory for Novel Software Technology at Nanjing University] This repo is the official implement
 222 Dec 13, 2022
222 Dec 13, 2022
Rest API Written In Python To Classify NSFW Images.
✨ NSFW Classifier API ✨ Rest API Written In Python To Classify NSFW Images. Fastest Solution If you don't want to selfhost it, there's already an inst
 23 Dec 30, 2022
23 Dec 30, 2022
Github project for Attention-guided Temporal Coherent Video Object Matting.
Attention-guided Temporal Coherent Video Object Matting This is the Github project for our paper Attention-guided Temporal Coherent Video Object Matti
 71 Dec 19, 2022
71 Dec 19, 2022

Official implementation of the network presented in the paper "M4Depth: A motion-based approach for monocular depth estimation on video sequences"
M4Depth This is the reference TensorFlow implementation for training and testing depth estimation models using the method described in M4Depth: A moti
 76 Jan 3, 2023
76 Jan 3, 2023
Conformer: Local Features Coupling Global Representations for Visual Recognition
Conformer: Local Features Coupling Global Representations for Visual Recognition (arxiv) This repository is built upon DeiT and timm Usage First, inst
 378 Jan 8, 2023
378 Jan 8, 2023

Repo for the Video Person Clustering dataset, and code for the associated paper
Video Person Clustering Repo for the Video Person Clustering dataset, and code for the associated paper. This reporsitory contains the Video Person Cl
 47 Nov 2, 2022
47 Nov 2, 2022

SiamMOT is a region-based Siamese Multi-Object Tracking network that detects and associates object instances simultaneously.
SiamMOT: Siamese Multi-Object Tracking
 432 Dec 17, 2022
432 Dec 17, 2022
Music and video downloader, Made with love by Bryan Herrera
Python-Mp3Mp4-Downloader Music and video downloader, Made with love by Bryan Herrera Requirements CHOCOLATELY windows command If your system does not
 104 Dec 27, 2022
104 Dec 27, 2022
Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification"
hypergraph_reid Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification" If you find this help your research,
 62 Dec 21, 2022
62 Dec 21, 2022

PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficient Scene Text Recognition (ViTSTR)
Vision Transformer for Fast and Efficient Scene Text Recognition (ICDAR 2021) ViTSTR is a simple single-stage model that uses a pre-trained Vision Tra
 198 Dec 27, 2022
198 Dec 27, 2022
The implemention of Video Depth Estimation by Fusing Flow-to-Depth Proposals
Flow-to-depth (FDNet) video-depth-estimation This is the implementation of paper Video Depth Estimation by Fusing Flow-to-Depth Proposals Jiaxin Xie,
 32 Jun 14, 2022
32 Jun 14, 2022

A Joint Video and Image Encoder for End-to-End Retrieval
Frozen️ in Time ❄️ ️️️️ ⏳ A Joint Video and Image Encoder for End-to-End Retrieval (arXiv) Repository to contain the code, models, data for end-to-end
 225 Dec 25, 2022
225 Dec 25, 2022

Face Transformer for Recognition
Face-Transformer This is the code of Face Transformer for Recognition (https://arxiv.org/abs/2103.14803v2). Recently there has been great interests of
 153 Nov 30, 2022
153 Nov 30, 2022

voice2json is a collection of command-line tools for offline speech/intent recognition on Linux
Command-line tools for speech and intent recognition on Linux
 988 Jan 4, 2023
988 Jan 4, 2023

Code for ECCV 2020 paper "Contacts and Human Dynamics from Monocular Video".
Contact and Human Dynamics from Monocular Video This is the official implementation for the ECCV 2020 spotlight paper by Davis Rempe, Leonidas J. Guib
 207 Jan 5, 2023
207 Jan 5, 2023
Inference code for "StylePeople: A Generative Model of Fullbody Human Avatars" paper. This code is for the part of the paper describing video-based avatars.
NeuralTextures This is repository with inference code for paper "StylePeople: A Generative Model of Fullbody Human Avatars" (CVPR21). This code is for
 18 Oct 6, 2022
18 Oct 6, 2022
A Telegram bot to convert videos into x265/x264 format via ffmpeg.
Video Encoder Bot A Telegram bot to convert videos into x265/x264 format via ffmpeg. Configuration Add values in environment variables or add them in
 82 Jan 3, 2023
82 Jan 3, 2023
Deep learning (neural network) based remote photoplethysmography: how to extract pulse signal from video using deep learning tools
Deep-rPPG: Camera-based pulse estimation using deep learning tools Deep learning (neural network) based remote photoplethysmography: how to extract pu
 138 Dec 17, 2022
138 Dec 17, 2022

Keeping it safe - AI Based COVID-19 Tracker using Deep Learning and facial recognition
Keeping it safe - AI Based COVID-19 Tracker using Deep Learning and facial recognition
 15 Jun 17, 2021
15 Jun 17, 2021
Implementation of Stochastic Image-to-Video Synthesis using cINNs.
Stochastic Image-to-Video Synthesis using cINNs Official PyTorch implementation of Stochastic Image-to-Video Synthesis using cINNs accepted to CVPR202
 135 Dec 28, 2022
135 Dec 28, 2022

EQFace: An implementation of EQFace: A Simple Explicit Quality Network for Face Recognition
EQFace: A Simple Explicit Quality Network for Face Recognition The first face recognition network that generates explicit face quality online.
 141 Dec 31, 2022
141 Dec 31, 2022
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
RepMLP RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition Released the code of RepMLP together with an example o
 260 Jan 3, 2023
260 Jan 3, 2023
TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition.
TraND This is the code for the paper "Jinkai Zheng, Xinchen Liu, Chenggang Yan, Jiyong Zhang, Wu Liu, Xiaoping Zhang and Tao Mei: TraND: Transferable
 32 Apr 4, 2022
32 Apr 4, 2022

Radar-to-Lidar: Heterogeneous Place Recognition via Joint Learning
radar-to-lidar-place-recognition This page is the coder of a pre-print, implemented by PyTorch. If you have some questions on this project, please fee
 37 Oct 9, 2022
37 Oct 9, 2022
A list of papers about point cloud based place recognition, also known as loop closure detection in SLAM (processing)
A list of papers about point cloud based place recognition, also known as loop closure detection in SLAM (processing)
 17 May 16, 2021
17 May 16, 2021

Face Detection & Age Gender & Expression & Recognition
Face Detection & Age Gender & Expression & Recognition
 188 Dec 28, 2022
188 Dec 28, 2022

Code for paper 'Audio-Driven Emotional Video Portraits'.
Audio-Driven Emotional Video Portraits [CVPR2021] Xinya Ji, Zhou Hang, Kaisiyuan Wang, Wayne Wu, Chen Change Loy, Xun Cao, Feng Xu [Project] [Paper] G
 197 Dec 31, 2022
197 Dec 31, 2022
Modular and extensible speech recognition library leveraging pytorch-lightning and hydra.
Lightning ASR Modular and extensible speech recognition library leveraging pytorch-lightning and hydra What is Lightning ASR • Installation • Get Star
40 Sep 19, 2022
Identify the emotion of multiple speakers in an Audio Segment
MevonAI - Speech Emotion Recognition
 111 Jan 7, 2023
111 Jan 7, 2023

QueryInst: Parallelly Supervised Mask Query for Instance Segmentation
QueryInst is a simple and effective query based instance segmentation method driven by parallel supervision on dynamic mask heads, which outperforms previous arts in terms of both accuracy and speed.
 386 Jan 8, 2023
386 Jan 8, 2023

Code for "ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on", accepted at WACV 2021 Generation of Human Behavior Workshop.
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on [ Paper ] [ Project Page ] This repository contains the code fo
 97 Dec 13, 2022
97 Dec 13, 2022
![[NeurIPS 2020] Blind Video Temporal Consistency via Deep Video Prior](https://github.com/yzxing87/pytorch-deep-video-prior/raw/main/example/example_in.gif)
[NeurIPS 2020] Blind Video Temporal Consistency via Deep Video Prior
pytorch-deep-video-prior (DVP) Official PyTorch implementation for NeurIPS 2020 paper: Blind Video Temporal Consistency via Deep Video Prior TensorFlo
 90 Oct 19, 2022
90 Oct 19, 2022