1027 Repositories
Python audio-recognition Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Official repository accompanying a CVPR 2022 paper EMOCA: Emotion Driven Monocular Face Capture And Animation. EMOCA takes a single image of a face as input and produces a 3D reconstruction. EMOCA sets the new standard on reconstructing highly emotional images in-the-wild
EMOCA: Emotion Driven Monocular Face Capture and Animation Radek Daněček · Michael J. Black · Timo Bolkart CVPR 2022 This repository is the official i
 339 Dec 30, 2022
339 Dec 30, 2022
This is the code for the paper "Jinkai Zheng, Xinchen Liu, Wu Liu, Lingxiao He, Chenggang Yan, Tao Mei: Gait Recognition in the Wild with Dense 3D Representations and A Benchmark. (CVPR 2022)"
Gait3D-Benchmark This is the code for the paper "Jinkai Zheng, Xinchen Liu, Wu Liu, Lingxiao He, Chenggang Yan, Tao Mei: Gait Recognition in the Wild
 82 Jan 4, 2023
82 Jan 4, 2023
![[CVPR2022] This repository contains code for the paper](https://github.com/Bazinga699/NCL/raw/main/resource/framework_English.png)
[CVPR2022] This repository contains code for the paper "Nested Collaborative Learning for Long-Tailed Visual Recognition", published at CVPR 2022
Nested Collaborative Learning for Long-Tailed Visual Recognition This repository is the official PyTorch implementation of the paper in CVPR 2022: Nes
 65 Dec 9, 2022
65 Dec 9, 2022

This repository consists of a complete guide on natural language processing (NLP) in Python where we'll learn various techniques for implementing NLP including parsing & text processing and understand how to use NLP for text feature engineering.
Python_Natural_Language_Processing This repository contains tutorials on important topics related to Natural Language Processing (NPL). No. Name 01 01
 170 Dec 13, 2022
170 Dec 13, 2022

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022

Dataset and baseline code for the VocalSound dataset (ICASSP2022).
VocalSound: A Dataset for Improving Human Vocal Sounds Recognition Introduction Citing Download VocalSound Dataset Details Baseline Experiment Contact
 58 Jan 3, 2023
58 Jan 3, 2023

Face recognition system using MTCNN, FACENET, SVM and FAST API to track participants of Big Brother Brasil in real time.
BBB Face Recognizer Face recognition system using MTCNN, FACENET, SVM and FAST API to track participants of Big Brother Brasil in real time. Instalati
 232 Dec 24, 2022
232 Dec 24, 2022

BankNote-Net: Open dataset and encoder model for assistive currency recognition
BankNote-Net: Open Dataset for Assistive Currency Recognition Millions of people around the world have low or no vision. Assistive software applicatio
 13 Oct 28, 2022
13 Oct 28, 2022

Building a real-time environment using webcam frame division in OpenCV and classify cropped images using a fine-tuned vision transformers on hybryd datasets samples for facial emotion recognition.
Visual Transformer for Facial Emotion Recognition (FER) This project has the aim to build an efficient Visual Transformer for the Facial Emotion Recog
 8 Dec 12, 2022
8 Dec 12, 2022

Automatic number plate recognition using tech: Yolo, OCR, Scene text detection, scene text recognation, flask, torch
Automatic Number Plate Recognition Automatic Number Plate Recognition (ANPR) is the process of reading the characters on the plate with various optica
 52 Dec 22, 2022
52 Dec 22, 2022

A lightweight yet powerful audio-to-MIDI converter with pitch bend detection
Basic Pitch is a Python library for Automatic Music Transcription (AMT), using lightweight neural network developed by Spotify's Audio Intelligence La
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

Optical Character Recognition + Instance Segmentation for russian and english languages
Распознавание рукописного текста в школьных тетрадях Соревнование, проводимое в рамках олимпиады НТО, разработанное Сбером. Платформа ODS. Результаты
 21 Dec 19, 2022
21 Dec 19, 2022

Arabic Car License Recognition. A solution to the kaggle competition Machathon 3.0.
Transformers Arabic licence plate recognition 🚗 Solution to the kaggle competition Machathon 3.0. Ranked in the top 6️⃣ at the final evaluation phase
 17 Dec 4, 2022
17 Dec 4, 2022
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023

Pytorch re-implementation of Paper: SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition (CVPR 2022)
SwinTextSpotter This is the pytorch implementation of Paper: SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text R
 183 Jan 3, 2023
183 Jan 3, 2023

Repo for "Benchmarking Robustness of 3D Point Cloud Recognition against Common Corruptions" https://arxiv.org/abs/2201.12296
Benchmarking Robustness of 3D Point Cloud Recognition against Common Corruptions This repo contains the dataset and code for the paper Benchmarking Ro
 168 Dec 29, 2022
168 Dec 29, 2022

Implementation of CaiT models in TensorFlow and ImageNet-1k checkpoints. Includes code for inference and fine-tuning.
CaiT-TF (Going deeper with Image Transformers) This repository provides TensorFlow / Keras implementations of different CaiT [1] variants from Touvron
 9 Jun 26, 2022
9 Jun 26, 2022

The code for our paper submitted to RAL/IROS 2022: OverlapTransformer: An Efficient and Rotation-Invariant Transformer Network for LiDAR-Based Place Recognition.
OverlapTransformer The code for our paper submitted to RAL/IROS 2022: OverlapTransformer: An Efficient and Rotation-Invariant Transformer Network for
 136 Jan 3, 2023
136 Jan 3, 2023
HF's ML for Audio study group
Hugging Face Machine Learning for Audio Study Group Welcome to the ML for Audio Study Group. Through a series of presentations, paper reading and disc
 110 Jan 1, 2023
110 Jan 1, 2023
A Traffic Sign Recognition Project which can help the driver recognise the signs via text as well as audio. Can be used at Night also.
Traffic-Sign-Recognition In this report, we propose a Convolutional Neural Network(CNN) for traffic sign classification that achieves outstanding perf
 64 Nov 19, 2022
64 Nov 19, 2022

Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
 732 Jan 8, 2023
732 Jan 8, 2023

Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
RAVE: Realtime Audio Variational autoEncoder Official implementation of RAVE: A variational autoencoder for fast and high-quality neural audio synthes
 587 Jan 1, 2023
587 Jan 1, 2023
Multilingual Emotion classification using BERT (fine-tuning). Published at the WASSA workshop (ACL2022).
XLM-EMO: Multilingual Emotion Prediction in Social Media Text Abstract Detecting emotion in text allows social and computational scientists to study h
 35 Sep 17, 2022
35 Sep 17, 2022

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
 87 Dec 21, 2022
87 Dec 21, 2022

Code for "Parallel Instance Query Network for Named Entity Recognition", accepted at ACL 2022.
README Code for Two-stage Identifier: "Parallel Instance Query Network for Named Entity Recognition", accepted at ACL 2022. For details of the model a
 45 Nov 29, 2022
45 Nov 29, 2022

Realtime micro-expression recognition using OpenCV and PyTorch
Micro-expression Recognition Realtime micro-expression recognition from scratch using OpenCV and PyTorch Try it out with a webcam or video using the e
 35 Dec 5, 2022
35 Dec 5, 2022
![[CVPR'22] Official PyTorch Implementation of Collaborative Transformers for Grounded Situation Recognition](https://user-images.githubusercontent.com/55849968/160762073-9a458795-03c1-4b2a-8945-2187b5a48aca.png)
[CVPR'22] Official PyTorch Implementation of Collaborative Transformers for Grounded Situation Recognition
[CVPR'22] Collaborative Transformers for Grounded Situation Recognition Paper | Model Checkpoint This is the official PyTorch implementation of Collab
 29 Dec 10, 2022
29 Dec 10, 2022
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
Classification models 1D Zoo - Keras and TF.Keras
Classification models 1D Zoo - Keras and TF.Keras This repository contains 1D variants of popular CNN models for classification like ResNets, DenseNet
 12 Jan 6, 2023
12 Jan 6, 2023
This library is helpful when creating accounts, it has everything you need for this
AccountGeneratorHelper Library to facilitate accounts generation. Unofficial API for temp email services. Receive SMS from free services. Parsing and
 52 Jan 7, 2023
52 Jan 7, 2023

YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Created using Python, PyTube and PySimpleGUI.
YouTube Downloader YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Disclaimer It's
 3 Dec 14, 2022
3 Dec 14, 2022

Audio-analytics for music-producers! Automate tedious tasks such as musical scale detection, BPM rate classification and audio file conversion.
Click here to be re-directed to the Beat Inspect Streamlit Web-App You are a music producer? Let's get in touch via LinkedIn Fundamental Analytics for
 11 Dec 27, 2022
11 Dec 27, 2022

Official repository of the paper Privacy-friendly Synthetic Data for the Development of Face Morphing Attack Detectors
SMDD-Synthetic-Face-Morphing-Attack-Detection-Development-dataset Official repository of the paper Privacy-friendly Synthetic Data for the Development
 10 Dec 12, 2022
10 Dec 12, 2022

This is the first released system towards complex meters` detection and recognition, which is implemented by computer vision techniques.
A three-stage detection and recognition pipeline of complex meters in wild This is the first released system towards detection and recognition of comp
 19 Nov 28, 2022
19 Nov 28, 2022

Comparison-of-OCR (KerasOCR, PyTesseract,EasyOCR)
Optical Character Recognition OCR (Optical Character Recognition) is a technology that enables the conversion of document types such as scanned paper
21 Dec 25, 2022
Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution.
convolver Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution. Created by Sean Higley [email protected]
 1 Feb 23, 2022
1 Feb 23, 2022
Code for One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022) Paper | Demo Requirements Python = 3.6 , Pytorch
 84 Jan 3, 2023
84 Jan 3, 2023
Multi-resolution SeqMatch based long-term Place Recognition
MRS-SLAM for long-term place recognition In this work, we imply an multi-resolution sambling based visual place recognition method. This work is based
 6 Dec 6, 2022
6 Dec 6, 2022

Spacy-ginza-ner-webapi - Named Entity Recognition API with spaCy and GiNZA
Named Entity Recognition API with spaCy and GiNZA I wrote a blog post about this
 3 Feb 27, 2022
3 Feb 27, 2022
Digitalizing-Prescription-Image - PIRDS - Prescription Image Recognition and Digitalizing System is a OCR make with Tensorflow
Digitalizing-Prescription-Image PIRDS - Prescription Image Recognition and Digit
 2 May 11, 2022
2 May 11, 2022
Transcript-Extractor-Bot - Yet another Telegram Voice Recognition bot but using vosk and supports 20+ languages
transcript extractor Yet another Telegram Voice Recognition bot but using vosk a
 6 Oct 21, 2022
6 Oct 21, 2022
Gesture recognition on Event Data
Event based Gesture Recognition Gesture recognition on Event Data usually involv
 2 Feb 14, 2022
2 Feb 14, 2022

SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation In this repo you can find the code of the Supervised Hybrid Audio Segmentatio
 21 Dec 20, 2022
21 Dec 20, 2022

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022
Convert PDF to AudioBook and Audio Speech to PDF
In this Python project, we will build a GUI-based PDF to Audio and Audio to PDF converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, PyPDF4, and Pydub libraries and the messagebox module of the Tkinter library.
 1 Feb 13, 2022
1 Feb 13, 2022
Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence
Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence, etc. This article aims to provide an introduction on how to make use of the SpeechRecognition and pyttsx3 library of Python.
1 Feb 13, 2022

A python package to fine-tune transformer-based models for named entity recognition (NER).
nerblackbox A python package to fine-tune transformer-based language models for named entity recognition (NER). Resources Source Code: https://github.
 13 Jul 30, 2022
13 Jul 30, 2022

Captcha Recognition
The objective of this project is to recognize the target numbers in the captcha images correctly which would tell us how good or bad a captcha system has been built.
 5 Feb 20, 2022
5 Feb 20, 2022

Handwritten Character Recognition using CNN
Handwritten Character Recognition using CNN Problem Definition The main objective of this project is to solve the problem of handwritten character rec
4 Mar 2, 2022

Real time sign language recognition
The proposed work aims at converting american sign language gestures into English that can be understood by everyone in real time.
6 Jun 13, 2022

An Optical Character Recognition system using Pytesseract/Extracting data from Blood Pressure Reports.
Optical_Character_Recognition An Optical Character Recognition system using Pytesseract/Extracting data from Blood Pressure Reports. As an IOT/Compute
 1 Feb 12, 2022
1 Feb 12, 2022
A pure PyTorch batched computation implementation of "CIF: Continuous Integrate-and-Fire for End-to-End Speech Recognition"
A pure PyTorch batched computation implementation of "CIF: Continuous Integrate-and-Fire for End-to-End Speech Recognition"
 14 Dec 2, 2022
14 Dec 2, 2022

Community and sentiment analysis based on tweets
The project has set itself the goal of analyzing the thoughts and interaction of Italian users through the social posts expressed through the Twitter platform on the day of the entry into force of the new measures. In particular, we want to research the reference hubs present on the network, but also the sentiment and emotions of peoples with respect to the new limitations.
 3 Nov 17, 2022
3 Nov 17, 2022
An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright.
Playwright nonoCAPTCHA An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright. Disclaimer This project is for educational
 69 Dec 28, 2022
69 Dec 28, 2022

Emotion Recognition from Facial Images
Reconhecimento de Emoções a partir de imagens faciais Este projeto implementa um classificador simples que utiliza técncias de deep learning e transfe
 2 Feb 9, 2022
2 Feb 9, 2022
Deepface is a lightweight face recognition and facial attribute analysis (age, gender, emotion and race) framework for python
deepface Deepface is a lightweight face recognition and facial attribute analysis (age, gender, emotion and race) framework for python. It is a hybrid
 2 Feb 10, 2022
2 Feb 10, 2022

TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
TONet Introduction The official implementation of "TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music", in ICASSP 2022 We
 29 Dec 1, 2022
29 Dec 1, 2022

Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
13 Feb 8, 2022
Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 50 Nov 12, 2022
50 Nov 12, 2022

Pytorch implementation of TailCalibX : Feature Generation for Long-tail Classification
TailCalibX : Feature Generation for Long-tail Classification by Rahul Vigneswaran, Marc T. Law, Vineeth N. Balasubramanian, Makarand Tapaswi [arXiv] [
 34 Jan 2, 2023
34 Jan 2, 2023

MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition Paper: MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition accepted fo
 64 Dec 18, 2022
64 Dec 18, 2022
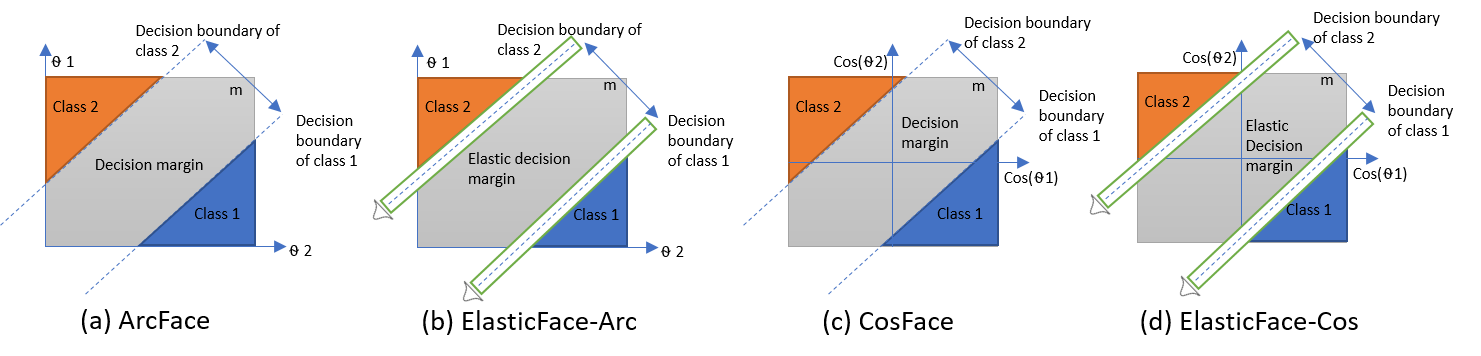
ElasticFace: Elastic Margin Loss for Deep Face Recognition
This is the official repository of the paper: ElasticFace: Elastic Margin Loss for Deep Face Recognition Paper on arxiv: arxiv Model Log file Pretrain
 113 Dec 14, 2022
113 Dec 14, 2022
This code is the implementation of Text Emotion Recognition (TER) with linguistic features
APSIPA-TER This code is the implementation of Text Emotion Recognition (TER) with linguistic features. The network model is BERT with a pretrained mod
 1 Feb 8, 2022
1 Feb 8, 2022
Speech Emotion Recognition with Fusion of Acoustic- and Linguistic-Feature-Based Decisions
APSIPA-SER-with-A-and-T This code is the implementation of Speech Emotion Recognition (SER) with acoustic and linguistic features. The network model i
3 Jan 4, 2023

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022
Python command line tool and python engine to label table fields and fields in data files.
Python command line tool and python engine to label table fields and fields in data files. It could help to find meaningful data in your tables and data files or to find Personal identifable information (PII).
 22 Dec 5, 2022
22 Dec 5, 2022
TFPNER: Exploration on the Named Entity Recognition of Token Fused with Part-of-Speech
TFPNER TFPNER: Exploration on the Named Entity Recognition of Token Fused with Part-of-Speech Named entity recognition (NER), which aims at identifyin
 1 Feb 7, 2022
1 Feb 7, 2022

Face recognition project by matching the features extracted using SIFT.
MV_FaceDetectionWithSIFT Face recognition project by matching the features extracted using SIFT. By : Aria Radmehr Professor : Ali Amiri Dependencies
 4 May 31, 2022
4 May 31, 2022
Weather Image Recognition - Python weather application using series of data
Weather Image Recognition - Python weather application using series of data
1 Feb 4, 2022
SAAVN - Sound Adversarial Audio-Visual Navigation,ICLR2022 (In PyTorch)
SAAVN SAAVN Code release for paper "Sound Adversarial Audio-Visual Navigation,IC
 10 Aug 30, 2022
10 Aug 30, 2022
YoutubeDownloader - Repo for downloading YT audio and videos
YoutubeDownloader Downloads video/playlist/audio from youtube url. install all t
 2 Feb 17, 2022
2 Feb 17, 2022
A voice control utility for Spotify
Spotify Voice Control A voice control utility for Spotify · Report Bug · Request
 27 Jan 1, 2023
27 Jan 1, 2023
The official code repo of "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
134 Jan 1, 2023

A Sign Language detection project using Mediapipe landmark detection and Tensorflow LSTM's
sign-language-detection A Sign Language detection project using Mediapipe landmark detection and Tensorflow LSTM. The project is built for a vocabular
 4 Feb 6, 2022
4 Feb 6, 2022

Automatic Number Plate Recognition using Contours and Convolution Neural Networks (CNN)
Cite our paper if you find this project useful https://www.ijariit.com/manuscripts/v7i4/V7I4-1139.pdf Abstract Image processing technology is used in
 2 Jun 28, 2022
2 Jun 28, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
327 Jan 1, 2023
![[ECE NTUA] 👁 Computer Vision - Lab Projects & Theoretical Problem Sets (2020-2021)](https://github.com/d-dimos/computer_vision_ntua/raw/master/labs/lab1/README_imgs/edge_in.jpg?raw=true)
[ECE NTUA] 👁 Computer Vision - Lab Projects & Theoretical Problem Sets (2020-2021)
Computer Vision - NTUA (2020-2021) This repository hosts the lab projects and theoretical problem sets of the Computer Vision course held by ECE NTUA
 6 Jul 21, 2022
6 Jul 21, 2022

This repository provides the official code for GeNER (an automated dataset Generation framework for NER).
GeNER This repository provides the official code for GeNER (an automated dataset Generation framework for NER). Overview of GeNER GeNER allows you to
 50 Nov 30, 2022
50 Nov 30, 2022
Hand gesture recognition model that can be used as a remote control for a smart tv.
Gesture_recognition The training data consists of a few hundred videos categorised into one of the five classes. Each video (typically 2-3 seconds lon
 1 Aug 11, 2022
1 Aug 11, 2022
This repository contains (not all) code from my project on Named Entity Recognition in philosophical text
NERphilosophy 👋 Welcome to the github repository of my BsC thesis. This repository contains (not all) code from my project on Named Entity Recognitio
 1 Jan 27, 2022
1 Jan 27, 2022
2 telegram-bots: for image recognition and for text generation
💻 📱 Telegram_Bots 🔎 & 📖 2 telegram-bots: for image recognition and for text generation. About Image recognition bot: User sends a photo and bot de
 1 Jan 27, 2022
1 Jan 27, 2022
Audio Retrieval with Natural Language Queries: A Benchmark Study
Audio Retrieval with Natural Language Queries: A Benchmark Study Paper | Project page | Text-to-audio search demo This repository is the implementatio
 21 Oct 31, 2022
21 Oct 31, 2022
PyTorch implementation of an end-to-end Handwritten Text Recognition (HTR) system based on attention encoder-decoder networks
AttentionHTR PyTorch implementation of an end-to-end Handwritten Text Recognition (HTR) system based on attention encoder-decoder networks. Scene Text
 31 Dec 22, 2022
31 Dec 22, 2022
This is the source code for the experiments related to the paper Unsupervised Audio Source Separation Using Differentiable Parametric Source Models
Unsupervised Audio Source Separation Using Differentiable Parametric Source Models This is the source code for the experiments related to the paper Un
 30 Oct 19, 2022
30 Oct 19, 2022

PyVideoAI: Action Recognition Framework
This reposity contains official implementation of: Capturing Temporal Information in a Single Frame: Channel Sampling Strategies for Action Recognitio
 22 Dec 29, 2022
22 Dec 29, 2022

Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources
Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources (e.g. just the lead vocals).
 14 Nov 7, 2022
14 Nov 7, 2022
An NVDA add-on to split screen reader and audio from other programs to different sound channels
An NVDA add-on to split screen reader and audio from other programs to different sound channels (add-on idea credit: Tony Malykh)
 7 Dec 25, 2022
7 Dec 25, 2022

Voice Gender Recognition
In this project it was used some different Machine Learning models to identify the gender of a voice (Female or Male) based on some specific speech and voice attributes.
 1 Jan 27, 2022
1 Jan 27, 2022
Paddle-Skeleton-Based-Action-Recognition - DecoupleGCN-DropGraph, ASGCN, AGCN, STGCN
Paddle-Skeleton-Action-Recognition DecoupleGCN-DropGraph, ASGCN, AGCN, STGCN. Yo
 3 Nov 2, 2022
3 Nov 2, 2022
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
TweebankNLP This repo contains the new Tweebank-NER dataset and off-the-shelf Twitter-Stanza pipeline for state-of-the-art Tweet NLP, as described in
 42 Jan 26, 2022
42 Jan 26, 2022
TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition
TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition Xue, Wenyuan, et al. "TGRNet: A Table Graph Reconstruction Network for Ta
 68 Jan 4, 2023
68 Jan 4, 2023
RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2
RoNER RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2. It is meant to be an easy to use, hi
 9 Nov 7, 2022
9 Nov 7, 2022

FocusFace: Multi-task Contrastive Learning for Masked Face Recognition
FocusFace This is the official repository of "FocusFace: Multi-task Contrastive Learning for Masked Face Recognition" accepted at IEEE International C
 21 Nov 17, 2022
21 Nov 17, 2022
Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications
Labelbox Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications. Use this github repository to help you s
 1.7k Dec 29, 2022
1.7k Dec 29, 2022
Bot by image recognition simulating (random) human clicks
bbbot22 bot por reconhecimento de imagem simulando cliques humanos (aleatórios) inb4: sim, esse é basicamente o mesmo bot de 2021 porque a Globo não t
 2 Apr 5, 2022
2 Apr 5, 2022
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022
Automated Melanoma Recognition in Dermoscopy Images via Very Deep Residual Networks
Introduction This repository contains the modified caffe library and network architectures for our paper "Automated Melanoma Recognition in Dermoscopy
 47 Nov 24, 2022
47 Nov 24, 2022
Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
ademxapp Visual applications by the University of Adelaide In designing our Model A, we did not over-optimize its structure for efficiency unless it w
 338 Dec 12, 2022
338 Dec 12, 2022