515 Repositories
Python yolov5-format-datasets Libraries

An API built to format given addresses using Python and Flask.
An API built to format given addresses using Python and Flask. About The API returns properly formatted data, i.e. removing duplicate fields, distingu
 1 Feb 27, 2022
1 Feb 27, 2022
Download Youtube videos in mp4 format in a fast, easy, convenient way made with Python!
yt_downloader Download Youtube videos in mp4 format in a fast, easy, convenient way made with Python! Required Modules pytube os time colorama Errors
 3 Jul 2, 2022
3 Jul 2, 2022
convert-to-opus-cli is a Python CLI program for converting audio files to opus audio format.
convert-to-opus-cli convert-to-opus-cli is a Python CLI program for converting audio files to opus audio format. Installation Must have installed ffmp
 4 Dec 21, 2022
4 Dec 21, 2022

A tutorial for people to run synthetic data replica's from source healthcare datasets
Synthetic-Data-Replica-for-Healthcare Description What is this? A tailored hands-on tutorial showing how to use Python to create synthetic data replic
 11 Mar 22, 2022
11 Mar 22, 2022

Official Datasets and Implementation from our Paper "Video Class Agnostic Segmentation in Autonomous Driving".
Video Class Agnostic Segmentation [Method Paper] [Benchmark Paper] [Project] [Demo] Official Datasets and Implementation from our Paper "Video Class A
 26 Oct 24, 2022
26 Oct 24, 2022

Spatial Interpolation Toolbox is a Python-based GUI that is able to interpolate spatial data in vector format.
Spatial Interpolation Toolbox This is the home to Spatial Interpolation Toolbox, a graphical user interface (GUI) for interpolating geographic vector
 2 Nov 1, 2021
2 Nov 1, 2021
YOLOv5 Series Multi-backbone, Pruning and quantization Compression Tool Box.
YOLOv5-Compression Update News Requirements 环境安装 pip install -r requirements.txt Evaluation metric Visdrone Model mAP mAP@50 Parameters(M) GFLOPs FPS@
 719 Jan 2, 2023
719 Jan 2, 2023

HW 2: Visualizing interesting datasets
HW 2: Visualizing interesting datasets Check out the project instructions here! Mean Earnings per Hour for Males and Females My first graph uses data
 7 Oct 27, 2021
7 Oct 27, 2021

Asterisk is a framework to generate high-quality training datasets at scale
Asterisk is a framework to generate high-quality training datasets at scale
 44 Apr 25, 2022
44 Apr 25, 2022
A dataset handling library for computer vision datasets in LOST-fromat
A dataset handling library for computer vision datasets in LOST-fromat
 8 Dec 15, 2022
8 Dec 15, 2022

HM02: Visualizing Interesting Datasets
HM02: Visualizing Interesting Datasets This is a homework assignment for CSCI 40 class at Claremont McKenna College. Go to the project page to learn m
 11 Oct 26, 2021
11 Oct 26, 2021
Multiple Object Tracking with Yolov5!
Tracking with yolov5 This implementation is for who need to tracking multi-object only with detector. You can easily track mult-object with your well
 9 Nov 8, 2022
9 Nov 8, 2022
🎵 A repository for manually annotating files to create labeled acoustic datasets for machine learning.
🎵 A repository for manually annotating files to create labeled acoustic datasets for machine learning.
 28 Dec 22, 2022
28 Dec 22, 2022

Efficient Training of Visual Transformers with Small Datasets
Official codes for "Efficient Training of Visual Transformers with Small Datasets", NerIPS 2021.
 112 Dec 25, 2022
112 Dec 25, 2022
This python module allows to extract data from the RAW-file-format produces by devices from Thermo Fisher Scientific.
fisher_py This Python module allows access to Thermo Orbitrap raw mass spectrometer files. Using this library makes it possible to automate the analys
 8 Oct 14, 2022
8 Oct 14, 2022

Repo for "Physion: Evaluating Physical Prediction from Vision in Humans and Machines" submission to NeurIPS 2021 (Datasets & Benchmarks track)
Physion: Evaluating Physical Prediction from Vision in Humans and Machines This repo contains code and data to reproduce the results in our paper, Phy
 38 Jan 6, 2023
38 Jan 6, 2023
利用yolov5和TensorRT从0到1实现目标检测的模型训练到模型部署全过程
写在前面 利用TensorRT加速推理速度是以时间换取精度的做法,意味着在推理速度上升的同时将会有精度的下降,不过不用太担心,精度下降微乎其微。此外,要有NVIDIA显卡,经测试,CUDA10.2可以支持20系列显卡及以下,30系列显卡需要CUDA11.x的支持,并且目前有bug。 默认你已经完成了
 6 Jul 28, 2022
6 Jul 28, 2022
Croniter provides iteration for the datetime object with a cron like format
Introduction Contents Introduction Travis badge Usage About DST About second repeats Testing if a date matches a crontab Gaps between date matches Ite
 152 Dec 30, 2022
152 Dec 30, 2022
an elegant datasets factory
rawbuilder an elegant datasets factory Free software: MIT license Documentation: https://rawbuilder.readthedocs.io. Features Schema oriented datasets
 7 Nov 12, 2022
7 Nov 12, 2022

使用yolov5训练自己数据集(详细过程)并通过flask部署
使用yolov5训练自己的数据集(详细过程)并通过flask部署 依赖库 torch torchvision numpy opencv-python lxml tqdm flask pillow tensorboard matplotlib pycocotools Windows,请使用 pycoc
 19 Dec 28, 2022
19 Dec 28, 2022
Extremely simple and fast extreme multi-class and multi-label classifiers.
napkinXC napkinXC is an extremely simple and fast library for extreme multi-class and multi-label classification, that focus of implementing various m
 43 Nov 14, 2022
43 Nov 14, 2022
This repository contains various tools useful for offensive operations (reversing, etc) regarding the PE (Portable Executable) format
PE-Tools This repository contains various tools useful for offensive operations (reversing, etc) regarding the PE (Portable Executable) format Install
 4 Oct 13, 2022
4 Oct 13, 2022
Code and datasets for the paper "KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction"
KnowPrompt Code and datasets for our paper "KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction" Requireme
 137 Dec 31, 2022
137 Dec 31, 2022

Pytorch implementation for "Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets" (ECCV 2020 Spotlight)
Distribution-Balanced Loss [Paper] The implementation of our paper Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets (
 304 Dec 22, 2022
304 Dec 22, 2022

QuakeLabeler is a Python package to create and manage your seismic training data, processes, and visualization in a single place — so you can focus on building the next big thing.
QuakeLabeler Quake Labeler was born from the need for seismologists and developers who are not AI specialists to easily, quickly, and independently bu
 15 Nov 4, 2022
15 Nov 4, 2022

The "breathing k-means" algorithm with datasets and example notebooks
The Breathing K-Means Algorithm (with examples) The Breathing K-Means is an approximation algorithm for the k-means problem that (on average) is bette
 75 Nov 17, 2022
75 Nov 17, 2022
Gradient-free global optimization algorithm for multidimensional functions based on the low rank tensor train format
ttopt Description Gradient-free global optimization algorithm for multidimensional functions based on the low rank tensor train (TT) format and maximu
 5 May 23, 2022
5 May 23, 2022
This repo is a C++ version of yolov5_deepsort_tensorrt. Packing all C++ programs into .so files, using Python script to call C++ programs further.
yolov5_deepsort_tensorrt_cpp Introduction This repo is a C++ version of yolov5_deepsort_tensorrt. And packing all C++ programs into .so files, using P
 41 Dec 27, 2022
41 Dec 27, 2022
1st ranked 'driver careless behavior detection' for AI Online Competition 2021, hosted by MSIT Korea.
2021AICompetition-03 본 repo 는 mAy-I Inc. 팀으로 참가한 2021 인공지능 온라인 경진대회 중 [이미지] 운전 사고 예방을 위한 운전자 부주의 행동 검출 모델] 태스크 수행을 위한 레포지토리입니다. mAy-I 는 과학기술정보통신부가 주최하
 9 Dec 1, 2022
9 Dec 1, 2022
Documentation for the lottie file format
Lottie Documentation This repository contains both human-readable and machine-readable documentation about the Lottie format The documentation is avai
 25 Jan 5, 2023
25 Jan 5, 2023
A pure python implementation of the GIMP XCF image format. Use this to interact with GIMP image formats
Pure Python implementation of the GIMP image formats (.xcf projects as well as brushes, patterns, etc)
 8 Dec 30, 2022
8 Dec 30, 2022

Glue is a python project to link visualizations of scientific datasets across many files.
Glue Glue is a python project to link visualizations of scientific datasets across many files. Click on the image for a quick demo: Features Interacti
 675 Dec 9, 2022
675 Dec 9, 2022
A raw implementation of the nearest insertion algorithm to resolve TSP problems in a TXT format.
TSP-Nearest-Insertion A raw implementation of the nearest insertion algorithm to resolve TSP problems in a TXT format. Instructions Load a txt file wi
 1 Dec 2, 2021
1 Dec 2, 2021
Nintendo Game Boy music assembly files parser into musicxml format
GBMusicParser Nintendo Game Boy music assembly files parser into musicxml format This python code will get an file.asm from the disassembly of a Game
 1 Dec 11, 2021
1 Dec 11, 2021

A Discord bot to easily and quickly format your JSON data
Invite PrettyJSON to your Discord server Table of contents About the project What is JSON? What is pretty printing? How to use Input options Command I
 4 Jan 24, 2022
4 Jan 24, 2022

YOLOv5 detection interface - PyQt5 implementation
所有代码已上传,直接clone后,运行yolo_win.py即可开启界面。 2021/9/29:加入置信度选择 界面是在ultralytics的yolov5基础上建立的,界面使用pyqt5实现,内容较简单,娱乐而已。 功能: 模型选择 本地文件选择(视频图片均可) 开关摄像头
 487 Dec 27, 2022
487 Dec 27, 2022
This repository contains a set of benchmarks of different implementations of Parquet (storage format) - Arrow (in-memory format).
Parquet benchmarks This repository contains a set of benchmarks of different implementations of Parquet (storage format) - Arrow (in-memory format).
 11 Dec 21, 2022
11 Dec 21, 2022
Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
Tensor2Tensor Tensor2Tensor, or T2T for short, is a library of deep learning models and datasets designed to make deep learning more accessible and ac
 12.9k Jan 9, 2023
12.9k Jan 9, 2023
The first online catalogue for Arabic NLP datasets.
Masader The first online catalogue for Arabic NLP datasets. This catalogue contains 200 datasets with more than 25 metadata annotations for each datas
 94 Dec 26, 2022
94 Dec 26, 2022

Fuzzy box is a quick program I wrote to fuzz a URL that is in the format https:// url 20characterstring.
What is this? Fuzzy box is a quick program I wrote to fuzz a URL that is in the format https://url/20characterstring.extension. I have redacted th
 1 Oct 19, 2021
1 Oct 19, 2021
Benchmark datasets, data loaders, and evaluators for graph machine learning
Overview The Open Graph Benchmark (OGB) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Datasets cover
 1.5k Jan 5, 2023
1.5k Jan 5, 2023
Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers.
ConditionalQA Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers. Disclaimer This dataset
 2 Oct 14, 2021
2 Oct 14, 2021
A torch.Tensor-like DataFrame library supporting multiple execution runtimes and Arrow as a common memory format
TorchArrow (Warning: Unstable Prototype) This is a prototype library currently under heavy development. It does not currently have stable releases, an
 536 Jan 6, 2023
536 Jan 6, 2023
Python Package for DataHerb: create, search, and load datasets.
The Python Package for DataHerb A DataHerb Core Service to Create and Load Datasets.
 4 Feb 11, 2022
4 Feb 11, 2022
HyperSpy is an open source Python library for the interactive analysis of multidimensional datasets
HyperSpy is an open source Python library for the interactive analysis of multidimensional datasets that can be described as multidimensional arrays o
 411 Dec 27, 2022
411 Dec 27, 2022
Python suite to construct benchmark machine learning datasets from the MIMIC-III clinical database.
MIMIC-III Benchmarks Python suite to construct benchmark machine learning datasets from the MIMIC-III clinical database. Currently, the benchmark data
 6 Jan 2, 2023
6 Jan 2, 2023

A simple tool to move and rename Nvidia Share recordings to a more sensible format.
A simple tool to move and rename Nvidia Share recordings to a more sensible format.
 8 Dec 23, 2022
8 Dec 23, 2022

This book will take you on an exploratory journey through the PDF format, and the borb Python library.
This book will take you on an exploratory journey through the PDF format, and the borb Python library.
 281 Jan 1, 2023
281 Jan 1, 2023
produces PCA on genotypes from fasta files (popPhyl's ID format)
popPhyl_PCA Performs PCA of genotypes. Works in two steps. 1. Input file A single fasta file containing different loci, in different populations/speci
 2 Oct 8, 2021
2 Oct 8, 2021
Python bytecode manipulation and import process customization to do evil stuff with format strings. Nasty!
formathack Python bytecode manipulation and import process customization to do evil stuff with format strings. Nasty! This is an answer to a StackOver
 5 Jan 18, 2022
5 Jan 18, 2022
A set of examples around hub for creating and processing datasets
Examples for Hub - Dataset Format for AI A repository showcasing examples of using Hub Uploading Dataset Places365 Colab Tutorials Notebook Link Getti
 11 Dec 14, 2022
11 Dec 14, 2022
TorchXRayVision: A library of chest X-ray datasets and models.
torchxrayvision A library for chest X-ray datasets and models. Including pre-trained models. ( 🎬 promo video about the project) Motivation: While the
 575 Jan 8, 2023
575 Jan 8, 2023
IDAPatternSearch adds a capability of finding functions according to bit-patterns into the well-known IDA Pro disassembler based on Ghidra’s function patterns format.
IDA Pattern Search by Argus Cyber Security Ltd. The IDA Pattern Search plugin adds a capability of finding functions according to bit-patterns into th
 48 Dec 29, 2022
48 Dec 29, 2022

A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You can find two approaches for achieving this in this repo.
multitask-learning-transformers A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You
 48 Jan 2, 2023
48 Jan 2, 2023

This YoloV5 based model is fit to detect people and different types of land vehicles, and displaying their density on a fitted map, according to their coordinates and detected labels.
This YoloV5 based model is fit to detect people and different types of land vehicles, and displaying their density on a fitted map, according to their
 8 May 22, 2022
8 May 22, 2022

C++ Implementation of PyTorch Tutorials for Everyone
C++ Implementation of PyTorch Tutorials for Everyone OS (Compiler)\LibTorch 1.9.0 macOS (clang 10.0, 11.0, 12.0) Linux (gcc 8, 9, 10, 11) Windows (msv
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
Translating symbolicated Apple JSON format crash log into our old friends :)
CrashTranslation Translating symbolicated Apple JSON format crash log into our old friends :) Usage python3 translation.py -i {input_sybolicated_json_
 11 May 16, 2022
11 May 16, 2022
Create Fast and easy image datasets using reddit
Reddit-Image-Scraper Reddit Reddit is an American Social news aggregation, web content rating, and discussion website. Reddit has been devided by topi
 4 Apr 27, 2022
4 Apr 27, 2022
Command line parser for common log format (Nginx default).
Command line parser for common log format (Nginx default).
 138 Dec 19, 2022
138 Dec 19, 2022
A Domain Specific Language (DSL) for building language patterns. These can be later compiled into spaCy patterns, pure regex, or any other format
RITA DSL This is a language, loosely based on language Apache UIMA RUTA, focused on writing manual language rules, which compiles into either spaCy co
 60 Sep 26, 2022
60 Sep 26, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
 138 Jan 3, 2023
138 Jan 3, 2023

Django-Audiofield is a simple app that allows Audio files upload, management and conversion to different audio format (mp3, wav & ogg), which also makes it easy to play audio files into your Django application.
Django-Audiofield Description: Django Audio Management Tools Maintainer: Areski Contributors: list of contributors Django-Audiofield is a simple app t
 167 Nov 10, 2022
167 Nov 10, 2022
The best way to have DRY Django forms. The app provides a tag and filter that lets you quickly render forms in a div format while providing an enormous amount of capability to configure and control the rendered HTML.
django-crispy-forms The best way to have Django DRY forms. Build programmatic reusable layouts out of components, having full control of the rendered
 4.6k Jan 7, 2023
4.6k Jan 7, 2023

A program to recognize fruits on pictures or videos using yolov5
Yolov5 Fruits Detector Requirements Either Linux or Windows. We recommend Linux for better performance. Python 3.6+ and PyTorch 1.7+. Installation To
 30 Jan 6, 2023
30 Jan 6, 2023

Vehicle Detection Using Deep Learning and YOLO Algorithm
VehicleDetection Vehicle Detection Using Deep Learning and YOLO Algorithm Dataset take or find vehicle images for create a special dataset for fine-tu
 96 Jan 5, 2023
96 Jan 5, 2023
FireFlyer Record file format, writer and reader for DL training samples.
FFRecord The FFRecord format is a simple format for storing a sequence of binary records developed by HFAiLab, which supports random access and Linux
 77 Jan 4, 2023
77 Jan 4, 2023
A set of tools for converting a darknet dataset to COCO format working with YOLOX
darknet格式数据→COCO darknet训练数据目录结构(详情参见dataset/darknet): darknet ├── class.names ├── gen_config.data ├── gen_train.txt ├── gen_valid.txt └── images
 148 Jan 3, 2023
148 Jan 3, 2023
Add gui for YoloV5 using PyQt5
HEAD 更新2021.08.16 **添加图片和视频保存功能: 1.图片和视频按照当前系统时间进行命名 2.各自检测结果存放入output文件夹 3.摄像头检测的默认设备序号更改为0,减少调试报错 温馨提示: 1.项目放置在全英文路径下,防止项目报错 2.默认使用cpu进行检测,自
 65 Dec 27, 2022
65 Dec 27, 2022
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless.
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless. This is the official Roboflow python package that interfaces with the Roboflow API.
 52 Dec 23, 2022
52 Dec 23, 2022
BOLT12 Lightning Address Format
BOLT12 Address Support (DRAFT!) Inspired by the awesome lightningaddress.com, except for BOLT12: Supports BOLT12 Allows BOLT12 vendor string authentic
 28 Sep 14, 2022
28 Sep 14, 2022
yolov5目标检测模型的知识蒸馏(基于响应的蒸馏)
代码地址: https://github.com/Sharpiless/yolov5-knowledge-distillation 教师模型: python train.py --weights weights/yolov5m.pt \ --cfg models/yolov5m.ya
 52 Dec 4, 2022
52 Dec 4, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022

Iranian Cars Detection using Yolov5s, PyTorch
Iranian Cars Detection using Yolov5 Train 1- git clone https://github.com/ultralytics/yolov5 cd yolov5 pip install -r requirements.txt 2- Dataset ../
 22 Dec 5, 2022
22 Dec 5, 2022
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
23 Nov 30, 2022
An easy way to build PyTorch datasets. Modularly build datasets and automatically cache processed results
EasyDatas An easy way to build PyTorch datasets. Modularly build datasets and automatically cache processed results Installation pip install git+https
 4 Dec 14, 2021
4 Dec 14, 2021

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023
Django API that scrapes and provides the last news of the city of Carlos Casares by semantic way (RDF format).
"Casares News" API Api that scrapes and provides the last news of the city of Carlos Casares by semantic way (RDF format). Usage Consume the articles
 6 May 12, 2022
6 May 12, 2022

OpenCVのGrabCut()を利用したセマンティックセグメンテーション向けアノテーションツール(Annotation tool using GrabCut() of OpenCV. It can be used to create datasets for semantic segmentation.)
[Japanese/English] GrabCut-Annotation-Tool GrabCut-Annotation-Tool.mp4 OpenCVのGrabCut()を利用したアノテーションツールです。 セマンティックセグメンテーション向けのデータセット作成にご使用いただけます。 ※Grab
 30 Nov 18, 2022
30 Nov 18, 2022

A data parser for the internal syncing data format used by Fog of World.
A data parser for the internal syncing data format used by Fog of World. The parser is not designed to be a well-coded library with good performance, it is more like a demo for showing the data structure.
 40 Dec 12, 2022
40 Dec 12, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022

🍅🍅🍅YOLOv5-Lite: lighter, faster and easier to deploy. Evolved from yolov5 and the size of model is only 1.7M (int8) and 3.3M (fp16). It can reach 10+ FPS on the Raspberry Pi 4B when the input size is 320×320~
YOLOv5-Lite:lighter, faster and easier to deploy Perform a series of ablation experiments on yolov5 to make it lighter (smaller Flops, lower memory, a
 1.5k Jan 5, 2023
1.5k Jan 5, 2023
The official repository for our paper "The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers". We significantly improve the systematic generalization of transformer models on a variety of datasets using simple tricks and careful considerations.
Codebase for training transformers on systematic generalization datasets. The official repository for our EMNLP 2021 paper The Devil is in the Detail:
 57 Nov 21, 2022
57 Nov 21, 2022
GraphGT: Machine Learning Datasets for Graph Generation and Transformation
GraphGT: Machine Learning Datasets for Graph Generation and Transformation Dataset Website | Paper Installation Using pip To install the core environm
 50 Aug 18, 2022
50 Aug 18, 2022
Base pretrained models and datasets in pytorch (MNIST, SVHN, CIFAR10, CIFAR100, STL10, AlexNet, VGG16, VGG19, ResNet, Inception, SqueezeNet)
This is a playground for pytorch beginners, which contains predefined models on popular dataset. Currently we support mnist, svhn cifar10, cifar100 st
 2.4k Dec 28, 2022
2.4k Dec 28, 2022
Minimal But Practical Image Classifier Pipline Using Pytorch, Finetune on ResNet18, Got 99% Accuracy on Own Small Datasets.
PyTorch Image Classifier Updates As for many users request, I released a new version of standared pytorch immage classification example at here: http:
 106 Nov 6, 2022
106 Nov 6, 2022
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023

This repository is based on Ultralytics/yolov5, with adjustments to enable rotate prediction boxes.
Rotate-Yolov5 This repository is based on Ultralytics/yolov5, with adjustments to enable rotate prediction boxes. Section I. Description The codes are
 90 Dec 13, 2022
90 Dec 13, 2022
shufflev2-yolov5:lighter, faster and easier to deploy
shufflev2-yolov5: lighter, faster and easier to deploy. Evolved from yolov5 and the size of model is only 1.7M (int8) and 3.3M (fp16). It can reach 10+ FPS on the Raspberry Pi 4B when the input size is 320×320~
1.5k Jan 5, 2023

Easy compression and extraction for any compression or archival format.
Tzar: Tar, Zip, Anything Really Easy compression and extraction for any compression or archival format. Usage/Examples tzar compress large-dir compres
 37 Nov 2, 2022
37 Nov 2, 2022

A graphical Semi-automatic annotation tool based on labelImg and Yolov5
💕YOLOV5 semi-automatic annotation tool (Based on labelImg)
 247 Jan 5, 2023
247 Jan 5, 2023

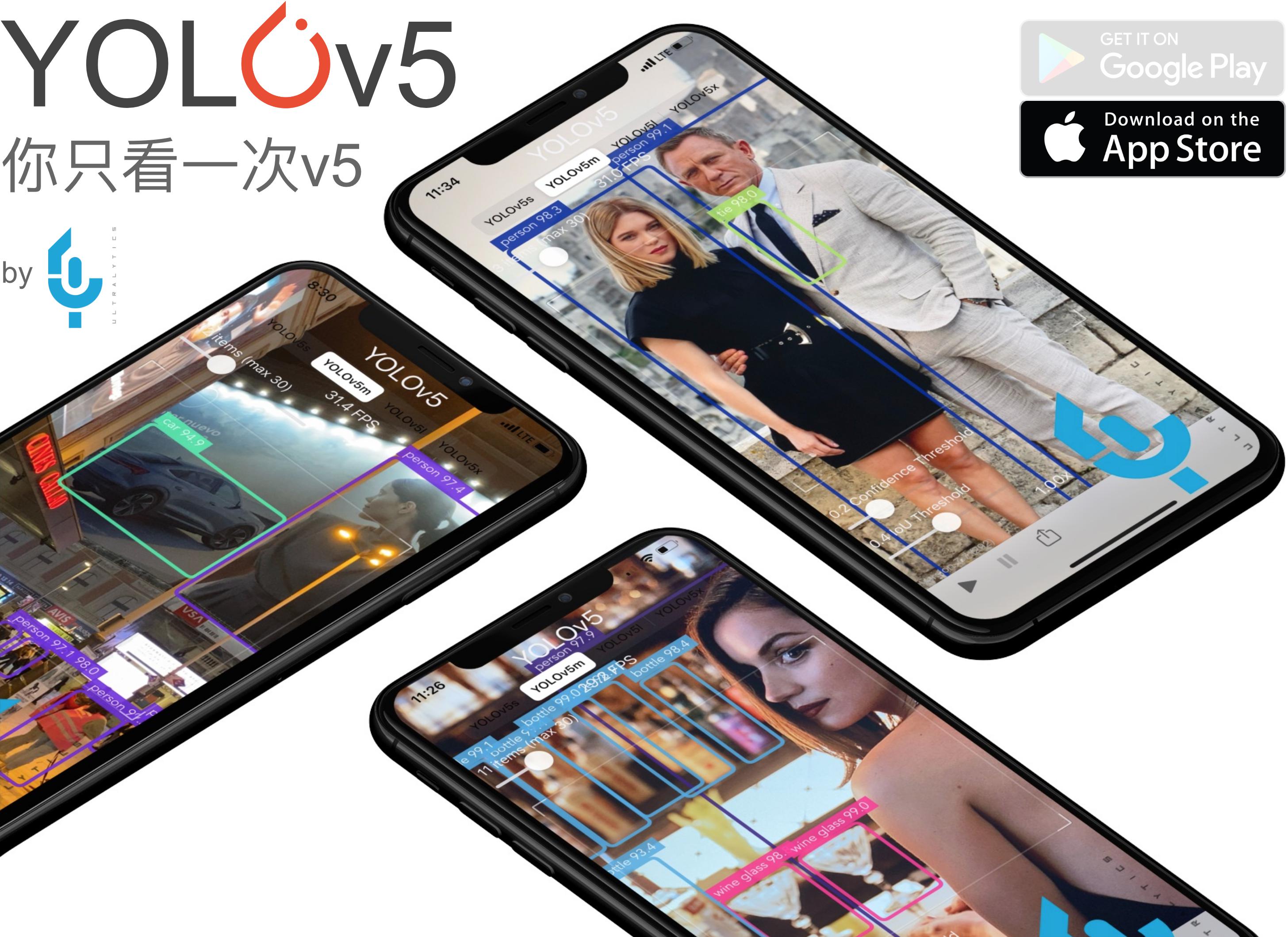
YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset
YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics open-source research int
 73 Dec 16, 2022
73 Dec 16, 2022

We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering Papers with code | Paper Nikola Zubić Pietro Lio University
 213 Dec 27, 2022
213 Dec 27, 2022

Codes for processing meeting summarization datasets AMI and ICSI.
Meeting Summarization Dataset Meeting plays an essential part in our daily life, which allows us to share information and collaborate with others. Wit
 39 Dec 14, 2022
39 Dec 14, 2022
Code Repo for the ACL21 paper "Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning"
Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning This is the Github repository of our paper, "Common S
 19 Nov 30, 2022
19 Nov 30, 2022
![[IJCAI'21] Deep Automatic Natural Image Matting](https://github.com/JizhiziLi/AIM/raw/master/demo/network.png)
[IJCAI'21] Deep Automatic Natural Image Matting
Deep Automatic Natural Image Matting [IJCAI-21] This is the official repository of the paper Deep Automatic Natural Image Matting. Introduction | Netw
 316 Jan 6, 2023
316 Jan 6, 2023
using yolox+deepsort for object-tracker
YOLOX_deepsort_tracker yolox+deepsort实现目标跟踪 最新的yolox尝尝鲜~~(yolox正处在频繁更新阶段,因此直接链接yolox仓库作为子模块) Install Clone the repository recursively: git clone --rec
 245 Dec 26, 2022
245 Dec 26, 2022
A curated list of amazingly awesome Cybersecurity datasets
A curated list of amazingly awesome Cybersecurity datasets
 758 Dec 28, 2022
758 Dec 28, 2022