Filter By
1361 Repositories
Python Text Data & NLP
Ukrainian TTS (text-to-speech) using Coqui TTS
title emoji colorFrom colorTo sdk app_file pinned Ukrainian TTS 🐸 green green gradio app.py false Ukrainian TTS 📢 🤖 Ukrainian TTS (text-to-speech)
 85 Dec 26, 2022
85 Dec 26, 2022

PortaSpeech - PyTorch Implementation
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
 276 Dec 26, 2022
276 Dec 26, 2022
Task-based datasets, preprocessing, and evaluation for sequence models.
SeqIO: Task-based datasets, preprocessing, and evaluation for sequence models. SeqIO is a library for processing sequential data to be fed into downst
 290 Dec 26, 2022
290 Dec 26, 2022

Making text a first-class citizen in TensorFlow.
TensorFlow Text - Text processing in Tensorflow IMPORTANT: When installing TF Text with pip install, please note the version of TensorFlow you are run
 1k Dec 26, 2022
1k Dec 26, 2022
A modular framework for vision & language multimodal research from Facebook AI Research (FAIR)
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains reference implementations of state-of-t
 5.1k Dec 26, 2022
5.1k Dec 26, 2022
texlive expressions for documents
tex2nix Generate Texlive environment containing all dependencies for your document rather than downloading gigabytes of texlive packages. Installation
 70 Dec 26, 2022
70 Dec 26, 2022
Simple, Pythonic, text processing--Sentiment analysis, part-of-speech tagging, noun phrase extraction, translation, and more.
TextBlob: Simplified Text Processing Homepage: https://textblob.readthedocs.io/ TextBlob is a Python (2 and 3) library for processing textual data. It
 8.4k Dec 26, 2022
8.4k Dec 26, 2022

Python code for ICLR 2022 spotlight paper EViT: Expediting Vision Transformers via Token Reorganizations
Expediting Vision Transformers via Token Reorganizations This repository contain
 101 Dec 26, 2022
101 Dec 26, 2022

A collection of Classical Chinese natural language processing models, including Classical Chinese related models and resources on the Internet.
GuwenModels: 古文自然语言处理模型合集, 收录互联网上的古文相关模型及资源. A collection of Classical Chinese natural language processing models, including Classical Chinese related models and resources on the Internet.
 66 Dec 26, 2022
66 Dec 26, 2022

Code for Text Prior Guided Scene Text Image Super-Resolution
Code for Text Prior Guided Scene Text Image Super-Resolution
 82 Dec 26, 2022
82 Dec 26, 2022
2021海华AI挑战赛·中文阅读理解·技术组·第三名
文字是人类用以记录和表达的最基本工具,也是信息传播的重要媒介。透过文字与符号,我们可以追寻人类文明的起源,可以传播知识与经验,读懂文字是认识与了解的第一步。对于人工智能而言,它的核心问题之一就是认知,而认知的核心则是语义理解。
 21 Dec 26, 2022
21 Dec 26, 2022
One Stop Anomaly Shop: Anomaly detection using two-phase approach: (a) pre-labeling using statistics, Natural Language Processing and static rules; (b) anomaly scoring using supervised and unsupervised machine learning.
One Stop Anomaly Shop (OSAS) Quick start guide Step 1: Get/build the docker image Option 1: Use precompiled image (might not reflect latest changes):
 148 Dec 26, 2022
148 Dec 26, 2022
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
 1.5k Dec 26, 2022
1.5k Dec 26, 2022
KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
KoGPT KoGPT (Korean Generative Pre-trained Transformer) https://github.com/kakaobrain/kogpt https://huggingface.co/kakaobrain/kogpt Model Descriptions
 797 Dec 26, 2022
797 Dec 26, 2022
Use Google's BERT for named entity recognition (CoNLL-2003 as the dataset).
For better performance, you can try NLPGNN, see NLPGNN for more details. BERT-NER Version 2 Use Google's BERT for named entity recognition (CoNLL-2003
 1.2k Dec 26, 2022
1.2k Dec 26, 2022
本插件是pcrjjc插件的重置版,可以独立于后端api运行
pcrjjc2 本插件是pcrjjc重置版,不需要使用其他后端api,但是需要自行配置客户端 本项目基于AGPL v3协议开源,由于项目特殊性,禁止基于本项目的任何商业行为 配置方法 环境需求:.net framework 4.5及以上 jre8 别忘了装jre8 别忘了装jre8 别忘了装jre8
 132 Dec 26, 2022
132 Dec 26, 2022
Code for papers "Generation-Augmented Retrieval for Open-Domain Question Answering" and "Reader-Guided Passage Reranking for Open-Domain Question Answering", ACL 2021
This repo provides the code of the following papers: (GAR) "Generation-Augmented Retrieval for Open-domain Question Answering", ACL 2021 (RIDER) "Read
 49 Dec 26, 2022
49 Dec 26, 2022
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022

Google's Meena transformer chatbot implementation
Here's my attempt at recreating Meena, a state of the art chatbot developed by Google Research and described in the paper Towards a Human-like Open-Domain Chatbot.
 94 Dec 25, 2022
94 Dec 25, 2022
Implementation of ProteinBERT in Pytorch
ProteinBERT - Pytorch (wip) Implementation of ProteinBERT in Pytorch. Original Repository Install $ pip install protein-bert-pytorch Usage import torc
 92 Dec 25, 2022
92 Dec 25, 2022
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022
A PyTorch Implementation of End-to-End Models for Speech-to-Text
speech Speech is an open-source package to build end-to-end models for automatic speech recognition. Sequence-to-sequence models with attention, Conne
 647 Dec 25, 2022
647 Dec 25, 2022

🦆 Contextually-keyed word vectors
sense2vec: Contextually-keyed word vectors sense2vec (Trask et. al, 2015) is a nice twist on word2vec that lets you learn more interesting and detaile
 1.5k Dec 25, 2022
1.5k Dec 25, 2022
Tools for curating biomedical training data for large-scale language modeling
Tools for curating biomedical training data for large-scale language modeling
 242 Dec 25, 2022
242 Dec 25, 2022

Twitter Sentiment Analysis using #tag, words and username
Twitter Sentment Analysis Web App using #tag, words and username to fetch data finds Insides of data and Tells Sentiment of the perticular #tag, words or username.
 26 Dec 25, 2022
26 Dec 25, 2022

The Internet Archive Research Assistant - Daily search Internet Archive for new items matching your keywords
The Internet Archive Research Assistant - Daily search Internet Archive for new items matching your keywords
 60 Dec 25, 2022
60 Dec 25, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
glow-speak is a fast, local, neural text to speech system that uses eSpeak-ng as a text/phoneme front-end.
Glow-Speak glow-speak is a fast, local, neural text to speech system that uses eSpeak-ng as a text/phoneme front-end. Installation git clone https://g
 8 Dec 25, 2022
8 Dec 25, 2022
Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
ConSERT Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer Requirements torch==1.6.0
 478 Dec 25, 2022
478 Dec 25, 2022
MiCECo - Misskey Custom Emoji Counter
MiCECo Misskey Custom Emoji Counter Introduction This little script counts custo
 7 Dec 25, 2022
7 Dec 25, 2022
TruthfulQA: Measuring How Models Imitate Human Falsehoods
TruthfulQA: Measuring How Models Imitate Human Falsehoods
 69 Dec 25, 2022
69 Dec 25, 2022

Learning to Rewrite for Non-Autoregressive Neural Machine Translation
RewriteNAT This repo provides the code for reproducing our proposed RewriteNAT in EMNLP 2021 paper entitled "Learning to Rewrite for Non-Autoregressiv
 20 Dec 25, 2022
20 Dec 25, 2022

SAINT PyTorch implementation
SAINT-pytorch A Simple pyTorch implementation of "Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing" based on https://arx
 63 Dec 25, 2022
63 Dec 25, 2022
Maix Speech AI lib, including ASR, chat, TTS etc.
Maix-Speech 中文 | English Brief Now only support Chinese, See 中文 Build Clone code by: git clone https://github.com/sipeed/Maix-Speech Compile x86x64 c
 267 Dec 25, 2022
267 Dec 25, 2022
Codes to pre-train Japanese T5 models
t5-japanese Codes to pre-train a T5 (Text-to-Text Transfer Transformer) model pre-trained on Japanese web texts. The model is available at https://hug
 37 Dec 25, 2022
37 Dec 25, 2022
Nested Named Entity Recognition
Nested Named Entity Recognition Training Dataset: CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark url: https://tianchi.aliyun.
 8 Dec 25, 2022
8 Dec 25, 2022

Pytorch-Named-Entity-Recognition-with-BERT
BERT NER Use google BERT to do CoNLL-2003 NER ! Train model using Python and Inference using C++ ALBERT-TF2.0 BERT-NER-TENSORFLOW-2.0 BERT-SQuAD Requi
 1.1k Dec 25, 2022
1.1k Dec 25, 2022
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task。涵盖68个领域、共计916万词的专业词典知识库,可用于文本分类、知识增强、领域词汇库扩充等自然语言处理应用。
 357 Dec 24, 2022
357 Dec 24, 2022
Translate - a PyTorch Language Library
NOTE PyTorch Translate is now deprecated, please use fairseq instead. Translate - a PyTorch Language Library Translate is a library for machine transl
 775 Dec 24, 2022
775 Dec 24, 2022

Code release for "COTR: Correspondence Transformer for Matching Across Images"
COTR: Correspondence Transformer for Matching Across Images This repository contains the inference code for COTR. We plan to release the training code
 358 Dec 24, 2022
358 Dec 24, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
 586 Dec 24, 2022
586 Dec 24, 2022
A Paper List for Speech Translation
Keyword: Speech Translation, Spoken Language Processing, Natural Language Processing
 138 Dec 24, 2022
138 Dec 24, 2022

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
Big Bird: Transformers for Longer Sequences
BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle.
 457 Dec 23, 2022
457 Dec 23, 2022
SimBERT升级版(SimBERTv2)!
RoFormer-Sim RoFormer-Sim,又称SimBERTv2,是我们之前发布的SimBERT模型的升级版。 介绍 https://kexue.fm/archives/8454 训练 tensorflow 1.14 + keras 2.3.1 + bert4keras 0.10.6 下载
 317 Dec 23, 2022
317 Dec 23, 2022
COVID-19 Chatbot with Rasa 2.0: open source conversational AI
COVID-19 chatbot implementation with Rasa open source 2.0, conversational AI framework.
 1 Dec 23, 2022
1 Dec 23, 2022
Unofficial Python library for using the Polish Wordnet (plWordNet / Słowosieć)
Polish Wordnet Python library Simple, easy-to-use and reasonably fast library for using the Słowosieć (also known as PlWordNet) - a lexico-semantic da
 12 Dec 23, 2022
12 Dec 23, 2022
Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
MLP Singer Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis. Audio samples are available on our demo page.
 103 Dec 23, 2022
103 Dec 23, 2022
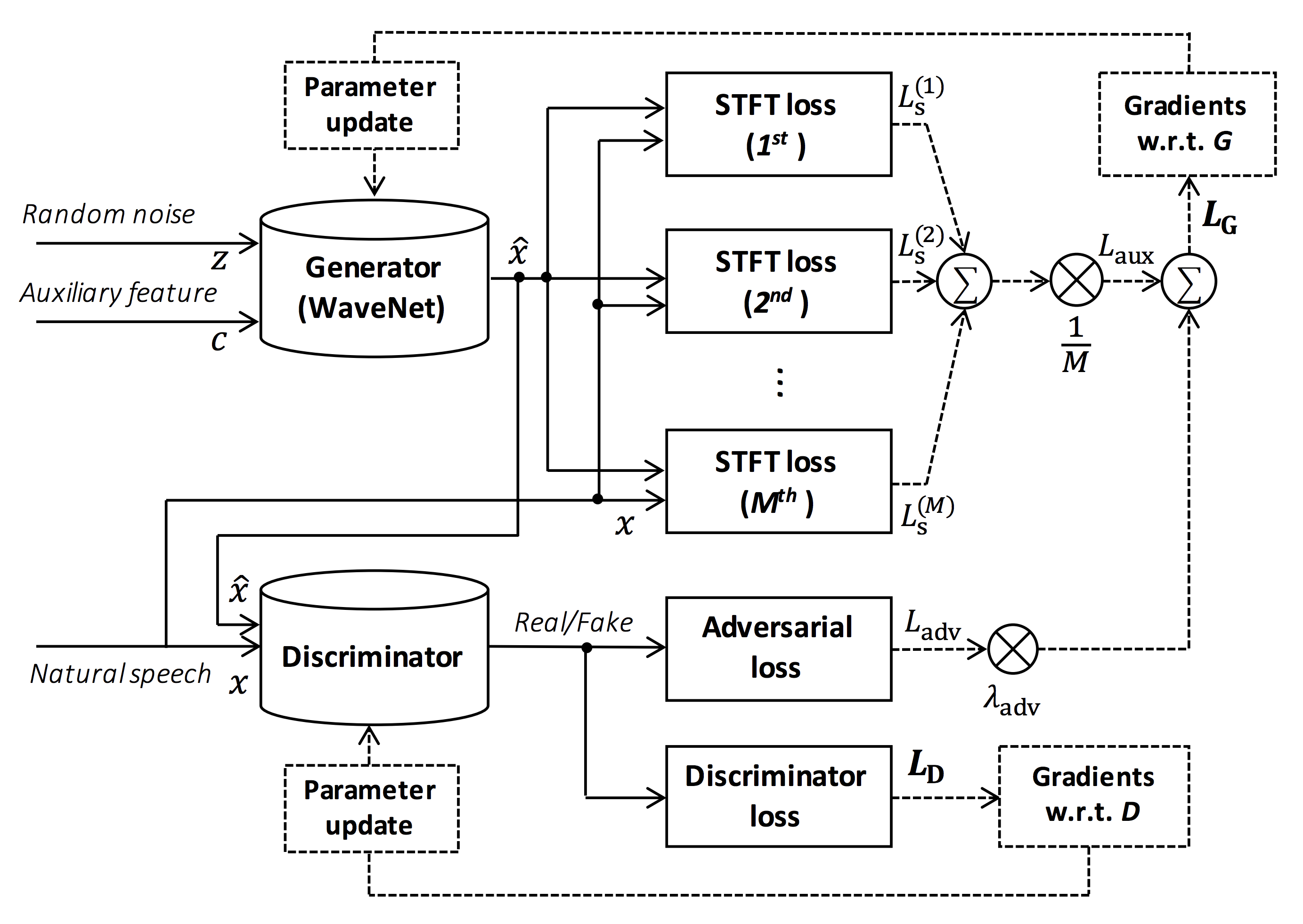
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022
Word2Wave: a framework for generating short audio samples from a text prompt using WaveGAN and COALA.
Word2Wave is a simple method for text-controlled GAN audio generation. You can either follow the setup instructions below and use the source code and CLI provided in this repo or you can have a play around in the Colab notebook provided. Note that, in both cases, you will need to train a WaveGAN model first
 91 Dec 23, 2022
91 Dec 23, 2022
Datasets of Automatic Keyphrase Extraction
This repository contains 20 annotated datasets of Automatic Keyphrase Extraction made available by the research community. Following are the datasets and the original papers that proposed them. If you know more datasets, and want to contribute, please, notify me.
 163 Dec 23, 2022
163 Dec 23, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
 99 Dec 23, 2022
99 Dec 23, 2022
Graph4nlp is the library for the easy use of Graph Neural Networks for NLP
Graph4NLP Graph4NLP is an easy-to-use library for R&D at the intersection of Deep Learning on Graphs and Natural Language Processing (i.e., DLG4NLP).
 1.5k Dec 23, 2022
1.5k Dec 23, 2022