1182 Repositories
Python AI-DAY-WORKSHOP-NLP-TRANSFORMERS Libraries
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 2, 2023
77.2k Jan 2, 2023
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
This is a fork of Fairseq(-py) with implementations of the following models: Pervasive Attention - 2D Convolutional Neural Networks for Sequence-to-Se
 490 Dec 15, 2022
490 Dec 15, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
 166 Dec 11, 2022
166 Dec 11, 2022

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022

Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
 730 Jan 9, 2023
730 Jan 9, 2023

Labelling platform for text using distant supervision
With DataQA, you can label unstructured text documents using rule-based distant supervision.
 245 Aug 5, 2022
245 Aug 5, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 4, 2023
7.1k Jan 4, 2023
Recurrent Variational Autoencoder that generates sequential data implemented with pytorch
Pytorch Recurrent Variational Autoencoder Model: This is the implementation of Samuel Bowman's Generating Sentences from a Continuous Space with Kim's
 347 Nov 14, 2022
347 Nov 14, 2022
A Domain Specific Language (DSL) for building language patterns. These can be later compiled into spaCy patterns, pure regex, or any other format
RITA DSL This is a language, loosely based on language Apache UIMA RUTA, focused on writing manual language rules, which compiles into either spaCy co
 60 Sep 26, 2022
60 Sep 26, 2022
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022

TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP
TextAttack 🐙 Generating adversarial examples for NLP models [TextAttack Documentation on ReadTheDocs] About • Setup • Usage • Design About TextAttack
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
A2T: Towards Improving Adversarial Training of NLP Models (EMNLP 2021 Findings)
A2T: Towards Improving Adversarial Training of NLP Models This is the source code for the EMNLP 2021 (Findings) paper "Towards Improving Adversarial T
17 Oct 15, 2022

Official implement of Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer This repository contains the PyTorch code for Evo-ViT. This work proposes a slow-fas
 53 Dec 5, 2022
53 Dec 5, 2022

💛 Code and Dataset for our EMNLP 2021 paper: "Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes"
Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes Official PyTorch implementation and EmoCause evaluatio
 50 Dec 21, 2022
50 Dec 21, 2022
Code for evaluating Japanese pretrained models provided by NTT Ltd.
japanese-dialog-transformers 日本語の説明文はこちら This repository provides the information necessary to evaluate the Japanese Transformer Encoder-decoder dialo
 216 Dec 22, 2022
216 Dec 22, 2022
Natural Language Processing with transformers
we want to create a repo to illustrate usage of transformers in chinese
 763 Dec 27, 2022
763 Dec 27, 2022

Search Git commits in natural language
NaLCoS - NAtural Language COmmit Search Search commit messages in your repository in natural language. NaLCoS (NAtural Language COmmit Search) is a co
 50 Mar 22, 2022
50 Mar 22, 2022
IndoBERTweet is the first large-scale pretrained model for Indonesian Twitter. Published at EMNLP 2021 (main conference)
IndoBERTweet 🐦 🇮🇩 1. Paper Fajri Koto, Jey Han Lau, and Timothy Baldwin. IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effe
 40 Nov 30, 2022
40 Nov 30, 2022
Implementation of a Transformer, but completely in Triton
Transformer in Triton (wip) Implementation of a Transformer, but completely in Triton. I'm completely new to lower-level neural net code, so this repo
 152 Dec 22, 2022
152 Dec 22, 2022
Code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
This repository contains the code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
 28 Nov 10, 2022
28 Nov 10, 2022

Polyp-PVT: Polyp Segmentation with Pyramid Vision Transformers (arXiv2021)
Polyp-PVT by Bo Dong, Wenhai Wang, Deng-Ping Fan, Jinpeng Li, Huazhu Fu, & Ling Shao. This repo is the official implementation of "Polyp-PVT: Polyp Se
 102 Jan 5, 2023
102 Jan 5, 2023
Augmenty is an augmentation library based on spaCy for augmenting texts.
Augmenty: The cherry on top of your NLP pipeline Augmenty is an augmentation library based on spaCy for augmenting texts. Besides a wide array of high
 124 Dec 29, 2022
124 Dec 29, 2022

PyTorch Implementation of "Light Field Image Super-Resolution with Transformers"
LFT PyTorch implementation of "Light Field Image Super-Resolution with Transformers", arXiv 2021. [pdf]. Contributions: We make the first attempt to a
 62 Nov 28, 2022
62 Nov 28, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE 以数据为中心的AI测评(DataCLUE) DataCLUE: A Chinese Data-centric Language Evaluation Benchmark 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE)的背景 任务描述 任务描述 实验结果
 135 Dec 22, 2022
135 Dec 22, 2022
Code for lyric-section-to-comment generation based on huggingface transformers.
CommentGeneration Code for lyric-section-to-comment generation based on huggingface transformers. Migrate Guyu model and code (both 12-layers and 24-l
 8 Sep 4, 2021
8 Sep 4, 2021
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
 7.6k Jan 1, 2023
7.6k Jan 1, 2023
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
[ICCV 2021] Instance-level Image Retrieval using Reranking Transformers
Instance-level Image Retrieval using Reranking Transformers Fuwen Tan, Jiangbo Yuan, Vicente Ordonez, ICCV 2021. Abstract Instance-level image retriev
 86 Dec 28, 2022
86 Dec 28, 2022
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

Document processing using transformers
Doc Transformers Document processing using transformers. This is still in developmental phase, currently supports only extraction of form data i.e (ke
 13 Dec 21, 2022
13 Dec 21, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
A PyTorch library for Vision Transformers
VFormer A PyTorch library for Vision Transformers Getting Started Read the contributing guidelines in CONTRIBUTING.rst to learn how to start contribut
 142 Nov 28, 2022
142 Nov 28, 2022
Tutorial to pretrain & fine-tune a 🤗 Flax T5 model on a TPUv3-8 with GCP
Pretrain and Fine-tune a T5 model with Flax on GCP This tutorial details how pretrain and fine-tune a FlaxT5 model from HuggingFace using a TPU VM ava
 41 Nov 18, 2022
41 Nov 18, 2022

official Pytorch implementation of ICCV 2021 paper FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting.
FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting By Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu
 77 Dec 27, 2022
77 Dec 27, 2022
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022
Code for EMNLP 2021 paper Contrastive Out-of-Distribution Detection for Pretrained Transformers.
Contra-OOD Code for EMNLP 2021 paper Contrastive Out-of-Distribution Detection for Pretrained Transformers. Requirements PyTorch Transformers datasets
 27 Oct 28, 2022
27 Oct 28, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

Data augmentation for NLP, accepted at EMNLP 2021 Findings
AEDA: An Easier Data Augmentation Technique for Text Classification This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Techni
 81 Dec 9, 2022
81 Dec 9, 2022

CMT: Convolutional Neural Networks Meet Vision Transformers
CMT: Convolutional Neural Networks Meet Vision Transformers [arxiv] 1. Introduction This repo is the CMT model which impelement with pytorch, no refer
 83 Dec 30, 2022
83 Dec 30, 2022
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks A Transformer-based library for SocialNLP classification tasks. Currently
 298 Jan 7, 2023
298 Jan 7, 2023

"3D Human Texture Estimation from a Single Image with Transformers", ICCV 2021
Texformer: 3D Human Texture Estimation from a Single Image with Transformers This is the official implementation of "3D Human Texture Estimation from
 193 Dec 5, 2022
193 Dec 5, 2022

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022

Workshop for student hackathons focused on IoT dev
Scenario: The Mutt Matcher (IoT version) According to the World Health Organization there are more than 200 million stray dogs worldwide. The American
15 Aug 10, 2022
RCE 0-day for GhostScript 9.50 - Payload generator
RCE-0-day-for-GhostScript-9.50 PoC for RCE 0-day for GhostScript 9.50 - Payload generator The PoC in python generates payload when exploited for a 0-d
 534 Dec 14, 2022
534 Dec 14, 2022
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
297 Dec 29, 2022

Materi workshop "Light up your Python!" Himpunan Mahasiswa Sistem Informasi Fakultas Ilmu Komputer Universitas Singaperbangsa Karawang, 4 September 2021 (Online via Zoom).
Workshop Python UNSIKA 2021 Materi workshop "Light up your Python!" Himpunan Mahasiswa Sistem Informasi Fakultas Ilmu Komputer Universitas Singaperban
 20 Mar 24, 2022
20 Mar 24, 2022

Code for "Searching for Efficient Multi-Stage Vision Transformers"
Searching for Efficient Multi-Stage Vision Transformers This repository contains the official Pytorch implementation of "Searching for Efficient Multi
 62 Oct 25, 2022
62 Oct 25, 2022
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022
Ray-based parallel data preprocessing for NLP and ML.
Wrangl Ray-based parallel data preprocessing for NLP and ML. pip install wrangl # for latest pip install git+https://github.com/vzhong/wrangl See exa
 33 Dec 27, 2022
33 Dec 27, 2022

An implementation of Fastformer: Additive Attention Can Be All You Need in TensorFlow
Fast Transformer This repo implements Fastformer: Additive Attention Can Be All You Need by Wu et al. in TensorFlow. Fast Transformer is a Transformer
 139 Dec 28, 2022
139 Dec 28, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
超轻量级bert的pytorch版本,大量中文注释,容易修改结构,持续更新
bert4pytorch 2021年8月27更新: 感谢大家的star,最近有小伙伴反映了一些小的bug,我也注意到了,奈何这个月工作上实在太忙,更新不及时,大约会在9月中旬集中更新一个只需要pip一下就完全可用的版本,然后会新添加一些关键注释。 再增加对抗训练的内容,更新一个完整的finetune
 317 Dec 18, 2022
317 Dec 18, 2022
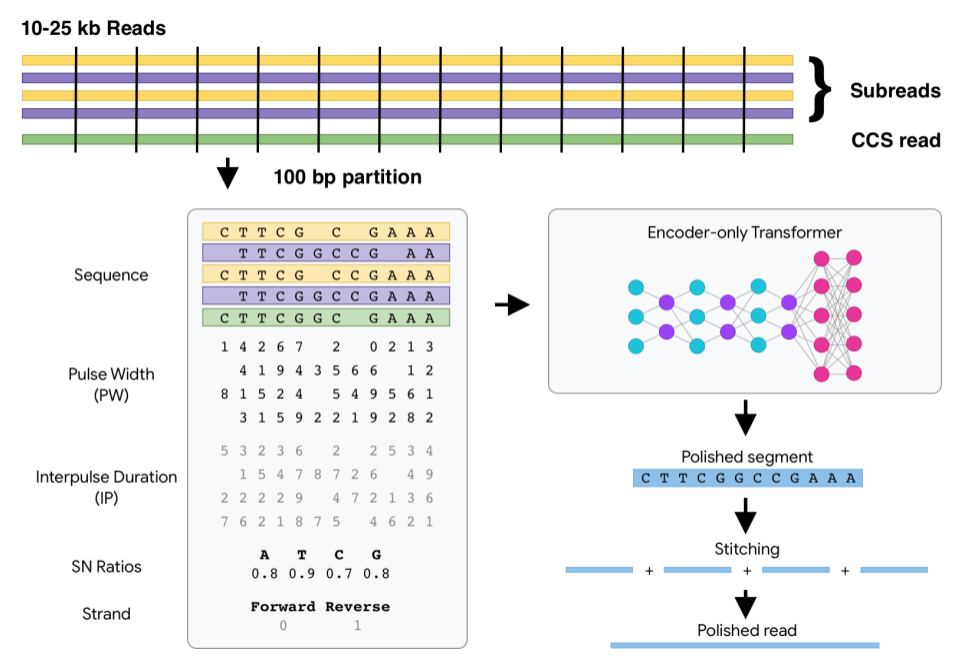
DeepConsensus uses gap-aware sequence transformers to correct errors in Pacific Biosciences (PacBio) Circular Consensus Sequencing (CCS) data.
DeepConsensus DeepConsensus uses gap-aware sequence transformers to correct errors in Pacific Biosciences (PacBio) Circular Consensus Sequencing (CCS)
 149 Dec 19, 2022
149 Dec 19, 2022
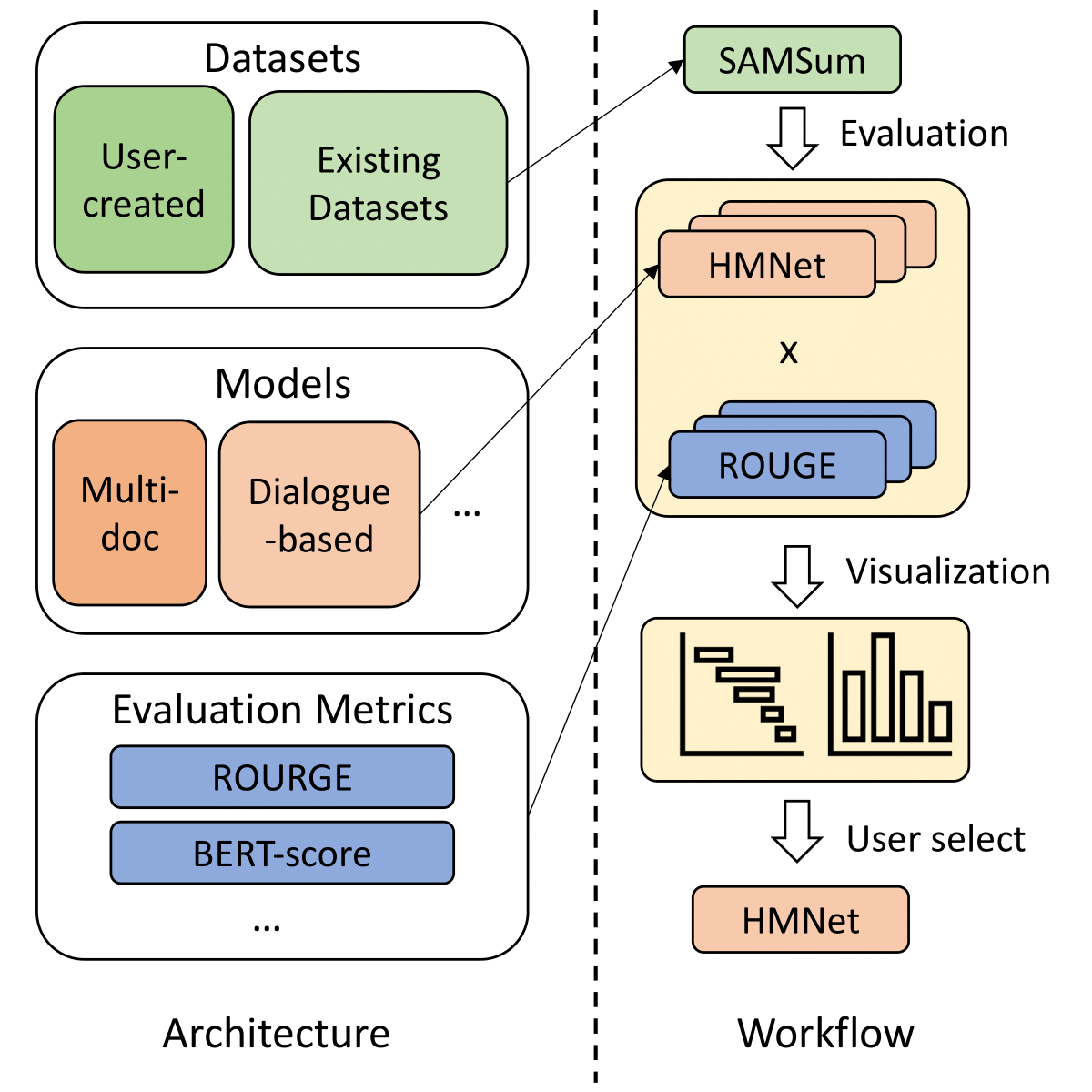
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

Türkçe küfürlü içerikleri bulan bir yapay zeka kütüphanesi / An ML library for profanity detection in Turkish sentences
"Kötü söz sahibine aittir." -Anonim Nedir? sinkaf uygunsuz yorumların bulunmasını sağlayan bir python kütüphanesidir. Farkı nedir? Diğer algoritmalard
 4 Feb 18, 2022
4 Feb 18, 2022
Ask for weather information like a human
weather-nlp About Ask for weather information like a human. Goals Understand typical questions like: Hourly temperatures in Potsdam on 2020-09-15. Rai
 5 Oct 29, 2022
5 Oct 29, 2022
Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs
Perceiver IO Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs Usage import torch from src.perceiver.
 111 Nov 15, 2022
111 Nov 15, 2022
The official repository for our paper "The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers". We significantly improve the systematic generalization of transformer models on a variety of datasets using simple tricks and careful considerations.
Codebase for training transformers on systematic generalization datasets. The official repository for our EMNLP 2021 paper The Devil is in the Detail:
 57 Nov 21, 2022
57 Nov 21, 2022
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
 230 Nov 22, 2022
230 Nov 22, 2022
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022
Implementation of a Transformer that Ponders, using the scheme from the PonderNet paper
Ponder(ing) Transformer Implementation of a Transformer that learns to adapt the number of computational steps it takes depending on the difficulty of
65 Oct 4, 2022

Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
167 Dec 27, 2022
⚖️ A Statutory Article Retrieval Dataset in French.
A Statutory Article Retrieval Dataset in French This repository contains the Belgian Statutory Article Retrieval Dataset (BSARD), as well as the code
 19 Nov 17, 2022
19 Nov 17, 2022

Many Class Activation Map methods implemented in Pytorch for CNNs and Vision Transformers. Including Grad-CAM, Grad-CAM++, Score-CAM, Ablation-CAM and XGrad-CAM
Class Activation Map methods implemented in Pytorch pip install grad-cam ⭐ Tested on many Common CNN Networks and Vision Transformers. ⭐ Includes smoo
 6.6k Jan 6, 2023
6.6k Jan 6, 2023
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
7.1k Jan 5, 2023
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
166 Dec 11, 2022
Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
167 Dec 27, 2022
Implementation of a Transformer that Ponders, using the scheme from the PonderNet paper
Ponder(ing) Transformer Implementation of a Transformer that learns to adapt the number of computational steps it takes depending on the difficulty of
65 Oct 4, 2022
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023
![SOTR: Segmenting Objects with Transformers [ICCV 2021]](https://github.com/easton-cau/SOTR/raw/main/images/overview.png)
SOTR: Segmenting Objects with Transformers [ICCV 2021]
SOTR: Segmenting Objects with Transformers [ICCV 2021] By Ruohao Guo, Dantong Niu, Liao Qu, Zhenbo Li Introduction This is the official implementation
 186 Dec 20, 2022
186 Dec 20, 2022
![[ICCV 2021 Oral] PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers](https://github.com/yuxumin/PoinTr/raw/master/fig/pointr.gif)
[ICCV 2021 Oral] PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers
PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers Created by Xumin Yu*, Yongming Rao*, Ziyi Wang, Zuyan Liu, Jiwen Lu, Jie Zhou
 317 Dec 26, 2022
317 Dec 26, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022

Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions
Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions To learn more about this project: medium blog post The goal of this proje
 60 Dec 17, 2022
60 Dec 17, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022

Official code for "Focal Self-attention for Local-Global Interactions in Vision Transformers"
Focal Transformer This is the official implementation of our Focal Transformer -- "Focal Self-attention for Local-Global Interactions in Vision Transf
486 Dec 20, 2022

Composed Image Retrieval using Pretrained LANguage Transformers (CIRPLANT)
CIRPLANT This repository contains the code and pre-trained models for Composed Image Retrieval using Pretrained LANguage Transformers (CIRPLANT) For d
 29 Nov 17, 2022
29 Nov 17, 2022

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022
Refactoring dalle-pytorch and taming-transformers for TPU VM
Text-to-Image Translation (DALL-E) for TPU in Pytorch Refactoring Taming Transformers and DALLE-pytorch for TPU VM with Pytorch Lightning Requirements
 61 Nov 7, 2022
61 Nov 7, 2022

A complete NLP guideline for enthusiasts
NLP-NINJA A complete guide for Natural Language Processing in Python Table of Contents S.No. Topic Level Meaning 1 Tokenization 🤍 Beginner 2 Stemming
 22 Dec 27, 2022
22 Dec 27, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
65 Sep 13, 2022

This is the official implementation for "Do Transformers Really Perform Bad for Graph Representation?".
Graphormer By Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng*, Guolin Ke, Di He*, Yanming Shen and Tie-Yan Liu. This repo is the official impl
1.3k Dec 26, 2022
Source code for "Progressive Transformers for End-to-End Sign Language Production" (ECCV 2020)
Progressive Transformers for End-to-End Sign Language Production Source code for "Progressive Transformers for End-to-End Sign Language Production" (B
 58 Dec 21, 2022
58 Dec 21, 2022
Sign Language Translation with Transformers (COLING'2020, ECCV'20 SLRTP Workshop)
transformer-slt This repository gathers data and code supporting the experiments in the paper Better Sign Language Translation with STMC-Transformer.
 107 Dec 27, 2022
107 Dec 27, 2022
Sign Language Transformers (CVPR'20)
Sign Language Transformers (CVPR'20) This repo contains the training and evaluation code for the paper Sign Language Transformers: Sign Language Trans
 164 Dec 30, 2022
164 Dec 30, 2022

This is an official implementation for "Self-Supervised Learning with Swin Transformers".
Self-Supervised Learning with Vision Transformers By Zhenda Xie*, Yutong Lin*, Zhuliang Yao, Zheng Zhang, Qi Dai, Yue Cao and Han Hu This repo is the
 529 Jan 2, 2023
529 Jan 2, 2023
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Dec 29, 2022
1.3k Dec 29, 2022

DeLighT: Very Deep and Light-Weight Transformers
DeLighT: Very Deep and Light-weight Transformers This repository contains the source code of our work on building efficient sequence models: DeFINE (I
 440 Dec 18, 2022
440 Dec 18, 2022

FairyTailor: Multimodal Generative Framework for Storytelling
FairyTailor: Multimodal Generative Framework for Storytelling
 172 Dec 30, 2022
172 Dec 30, 2022
Code for ACL 21: Generating Query Focused Summaries from Query-Free Resources
marge This repository releases the code for Generating Query Focused Summaries from Query-Free Resources. Please cite the following paper [bib] if you
 28 Nov 10, 2022
28 Nov 10, 2022
This repository contains the code for "Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP".
Self-Diagnosis and Self-Debiasing This repository contains the source code for Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based
 62 Dec 12, 2022
62 Dec 12, 2022
open-information-extraction-system, build open-knowledge-graph(SPO, subject-predicate-object) by pyltp(version==3.4.0)
中文开放信息抽取系统, open-information-extraction-system, build open-knowledge-graph(SPO, subject-predicate-object) by pyltp(version==3.4.0)
7 Nov 2, 2022
Code for "Finetuning Pretrained Transformers into Variational Autoencoders"
transformers-into-vaes Code for Finetuning Pretrained Transformers into Variational Autoencoders (our submission to NLP Insights Workshop 2021). Gathe
 22 Nov 26, 2022
22 Nov 26, 2022

Zero-Shot Text-to-Image Generation VQGAN+CLIP Dockerized
VQGAN-CLIP-Docker About Zero-Shot Text-to-Image Generation VQGAN+CLIP Dockerized This is a stripped and minimal dependency repository for running loca
 73 Sep 11, 2022
73 Sep 11, 2022
Machine learning models from Singapore's NLP research community
SG-NLP Machine learning models from Singapore's natural language processing (NLP) research community. sgnlp is a Python package that allows you to eas
 21 Dec 17, 2022
21 Dec 17, 2022