499 Repositories
Python Listening-to-Sound-of-Silence-for-Speech-Denoising Libraries

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

VQMIVC - Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion (Interspeech
 262 Dec 31, 2022
262 Dec 31, 2022

SpecAugmentPyTorch - A Pytorch (support batch and channel) implementation of GoogleBrain's SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
SpecAugment An implementation of SpecAugment for Pytorch How to use Install pytorch, version=1.9.0 (new feature (torch.Tensor.take_along_dim) is used
 3 Oct 11, 2022
3 Oct 11, 2022
Minimal diffusion models - Minimal code and simple experiments to play with Denoising Diffusion Probabilistic Models (DDPMs)
Minimal code and simple experiments to play with Denoising Diffusion Probabilist
 16 Oct 6, 2022
16 Oct 6, 2022

The codebase for Data-driven general-purpose voice activity detection.
Data driven GPVAD Repository for the work in TASLP 2021 Voice activity detection in the wild: A data-driven approach using teacher-student training. S
 75 Nov 27, 2022
75 Nov 27, 2022
基于百度的语音识别,用python实现,pyaudio+pyqt
Speech-recognition 基于百度的语音识别,python3.8(conda)+pyaudio+pyqt+baidu-aip 百度有面向python
 1 Jan 3, 2022
1 Jan 3, 2022
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022
Autoregressive Predictive Coding: An unsupervised autoregressive model for speech representation learning
Autoregressive Predictive Coding This repository contains the official implementation (in PyTorch) of Autoregressive Predictive Coding (APC) proposed
 173 Dec 18, 2022
173 Dec 18, 2022

Codebase for ECCV18 "The Sound of Pixels"
Sound-of-Pixels Codebase for ECCV18 "The Sound of Pixels". *This repository is under construction, but the core parts are already there. Environment T
 318 Dec 20, 2022
318 Dec 20, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 2, 2023
1.1k Jan 2, 2023

🚀Clone a voice in 5 seconds to generate arbitrary speech in real-time
English | 中文 Features 🌍 Chinese supported mandarin and tested with multiple datasets: aidatatang_200zh, magicdata, aishell3, data_aishell, and etc. ?
 25.6k Dec 31, 2022
25.6k Dec 31, 2022

TE-dependent analysis (tedana) is a Python library for denoising multi-echo functional magnetic resonance imaging (fMRI) data
tedana: TE Dependent ANAlysis TE-dependent analysis (tedana) is a Python library for denoising multi-echo functional magnetic resonance imaging (fMRI)
 136 Dec 22, 2022
136 Dec 22, 2022

CVPR2021 Workshop - HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization.
HDRUNet [Paper Link] HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization By Xiangyu Chen, Yihao Liu, Zhengwen Zhang, Yu Qiao an
 105 Dec 20, 2022
105 Dec 20, 2022
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger In this project, our aim is to tune, compare, and contrast the perf
 0 Dec 25, 2021
0 Dec 25, 2021
The ability of computer software to identify words and phrases in spoken language and convert them to human-readable text
speech-recognition-py Speech recognition is the ability of computer software to identify words and phrases in spoken language and convert them to huma
 1 Apr 3, 2022
1 Apr 3, 2022

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
 76 Nov 30, 2022
76 Nov 30, 2022

Prososdy Morph: A python library for manipulating pitch and duration in an algorithmic way, for resynthesizing speech.
ProMo (Prosody Morph) Questions? Comments? Feedback? Chat with us on gitter! A library for manipulating pitch and duration in an algorithmic way, for
 71 Jan 2, 2023
71 Jan 2, 2023
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021

ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python)
ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python) 日本語は以下に続きます (Japanese follows) English: This book is written in Japanese and primaril
 189 Dec 29, 2022
189 Dec 29, 2022
SuperCollider library for Python
SuperCollider library for Python This project is a port of core features of SuperCollider's language to Python 3. It is intended to be the same librar
 65 Dec 22, 2022
65 Dec 22, 2022
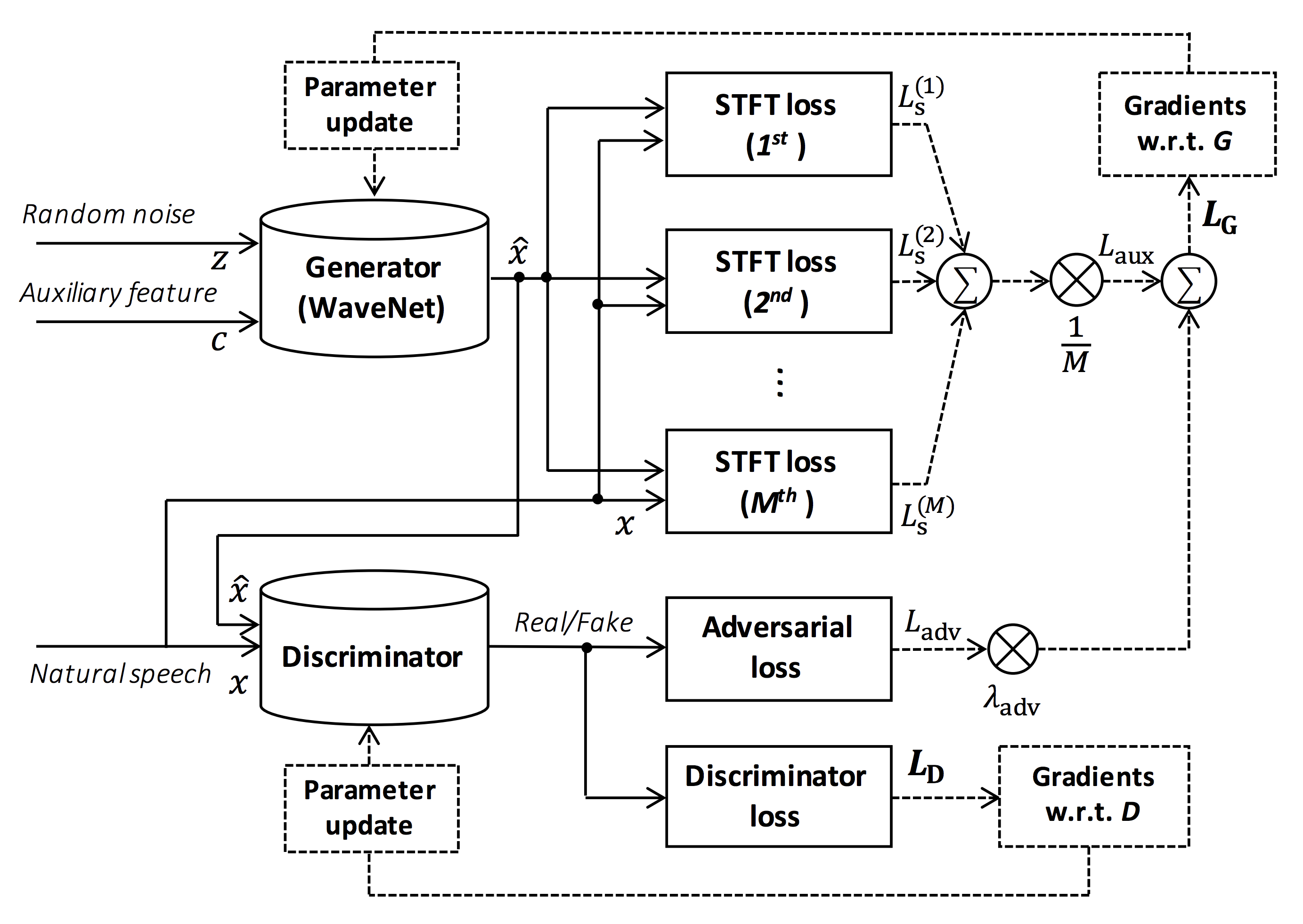
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022

Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition"
Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition" Pre-trained Deep Convo
 5 Nov 11, 2022
5 Nov 11, 2022

This is a really simple text-to-speech app made with python and tkinter.
Tkinter Text-to-Speech App by Souvik Roy This is a really simple tkinter app which converts the text you have entered into a speech. It is created wit
 1 Dec 21, 2021
1 Dec 21, 2021
A Python module made to simplify the usage of Text To Speech and Speech Recognition.
Nav Module The solution for voice related stuff in Python Nav is a Python module which simplifies voice related stuff in Python. Just import the Modul
 1 Dec 20, 2021
1 Dec 20, 2021

DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022; Official code
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
 803 Dec 28, 2022
803 Dec 28, 2022
Sound Source Localization for AI Grand Challenge 2021
Sound-Source-Localization Sound Source Localization study for AI Grand Challenge 2021 (sponsored by NC Soft Vision Lab) Preparation 1. Place the data-
 19 Mar 29, 2022
19 Mar 29, 2022

J.A.R.V.I.S is an AI virtual assistant made in python.
J.A.R.V.I.S is an AI virtual assistant made in python. Running JARVIS Without Python To run JARVIS without python: 1. Head over to our installation pa
 16 Dec 29, 2022
16 Dec 29, 2022
Wav2Vec for speech recognition, classification, and audio classification
Soxan در زبان پارسی به نام سخن This repository consists of models, scripts, and notebooks that help you to use all the benefits of Wav2Vec 2.0 in your
 140 Dec 15, 2022
140 Dec 15, 2022
Arabic speech recognition, classification and text-to-speech.
klaam Arabic speech recognition, classification and text-to-speech using many advanced models like wave2vec and fastspeech2. This repository allows tr
 177 Dec 27, 2022
177 Dec 27, 2022
Contains links to publicly available datasets for modeling health outcomes using speech and language.
speech-nlp-datasets Contains links to publicly available datasets for modeling various health outcomes using speech and language. Speech-based Corpora
 77 Dec 7, 2022
77 Dec 7, 2022

Create light scenes , voice control, ifttt, fuzzywuzzy speech correction and much more with Tuya light bulbs.
LightBox Features: Auto discover tuya lights Set and create moods (aka: light profiles) Change moods via IFTTT List moods via IFTTT FuzzyWuzzy, speech
 1 Dec 20, 2021
1 Dec 20, 2021
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
829 Jan 7, 2023
Sub-Cluster AdaCos: Learning Representations for Anomalous Sound Detection.
Accompanying code for the paper Sub-Cluster AdaCos: Learning Representations for Anomalous Sound Detection.
 6 Dec 1, 2022
6 Dec 1, 2022
pyo is a Python module written in C to help digital signal processing script creation.
pyo is a Python module written in C to help digital signal processing script creation.
 1.1k Jan 1, 2023
1.1k Jan 1, 2023

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: WavLM (arXiv): WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing UniSpeech (ICML 202
 281 Dec 15, 2022
281 Dec 15, 2022
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
Malaya-Speech is a Speech-Toolkit library for bahasa Malaysia, powered by Deep Learning Tensorflow.
Malaya-Speech is a Speech-Toolkit library for bahasa Malaysia, powered by Deep Learning Tensorflow. Documentation Proper documentation is available at
 151 Jan 5, 2023
151 Jan 5, 2023
Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks
wav2vec_finetune Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks Initial test: gender recognition on this dat
 8 Aug 11, 2022
8 Aug 11, 2022
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023
Pytorch implementation NORESQA A Framework for Speech Quality Assessment using Non-Matching References.
NORESQA: Speech Quality Assessment using Non-Matching References This is a Pytorch implementation for using NORESQA. It contains minimal code to predi
 11 Dec 14, 2021
11 Dec 14, 2021
Silence mypy by adding or removing code comments
mypy-silent Automatically add or remove # type: ignore commends to silence mypy. Inspired by pylint-silent Why? Imagine you want to add type check for
 8 Nov 30, 2022
8 Nov 30, 2022
CYGNUS, the Cynical AI, combines snarky responses with uncanny aggression.
New & (hopefully) Improved CYGNUS with several API updates, user updates, and online/offline operations added!!!
 0 Mar 28, 2022
0 Mar 28, 2022

A voice assistant which can be used to interact with your computer and controls your pc operations
Introduction 👨💻 It is a voice assistant which can be used to interact with your computer and also you have been seeing it in Iron man movies, but t
 84 Dec 22, 2022
84 Dec 22, 2022

PyAbsorp is a python module that has the main focus to help estimate the Sound Absorption Coefficient.
This is a package developed to be use to find the Sound Absorption Coefficient through some implemented models, like Biot-Allard, Johnson-Champoux and
 8 Oct 19, 2022
8 Oct 19, 2022
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022
A `Neural = Symbolic` framework for sound and complete weighted real-value logic
Logical Neural Networks LNNs are a novel Neuro = symbolic framework designed to seamlessly provide key properties of both neural nets (learning) and s
 138 Dec 19, 2022
138 Dec 19, 2022

Analyze, visualize and process sound field data recorded by spherical microphone arrays.
Sound Field Analysis toolbox for Python The sound_field_analysis toolbox (short: sfa) is a Python port of the Sound Field Analysis Toolbox (SOFiA) too
 69 Nov 23, 2022
69 Nov 23, 2022
Self-Supervised Image Denoising via Iterative Data Refinement
Self-Supervised Image Denoising via Iterative Data Refinement Yi Zhang1, Dasong Li1, Ka Lung Law2, Xiaogang Wang1, Hongwei Qin2, Hongsheng Li1 1CUHK-S
 8 Dec 11, 2021
8 Dec 11, 2021
A complete speech segmentation system using Kaldi and x-vectors for voice activity detection (VAD) and speaker diarisation.
bbc-speech-segmenter: Voice Activity Detection & Speaker Diarization A complete speech segmentation system using Kaldi and x-vectors for voice activit
 16 Oct 27, 2022
16 Oct 27, 2022
Code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language"
The repository provides the source code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language" submitted to HA
 3 Aug 4, 2022
3 Aug 4, 2022
The world's largest toxicity dataset.
The Toxicity Dataset by Surge AI Saving the internet is fun. Combing through thousands of online comments to build a toxicity dataset isn't. That's wh
 134 Dec 19, 2022
134 Dec 19, 2022
An end to end ASR Transformer model training repo
END TO END ASR TRANSFORMER 本项目基于transformer 6*encoder+6*decoder的基本结构构造的端到端的语音识别系统 Model Instructions 1.数据准备: 自行下载数据,遵循文件结构如下: ├── data │ ├── train │
 10 Jul 19, 2022
10 Jul 19, 2022
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone In our recent paper we propose the YourTTS model. YourTTS bri
 390 Dec 29, 2022
390 Dec 29, 2022
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks - Official Project Page This repository contains the code develope
 1.7k Dec 18, 2022
1.7k Dec 18, 2022

Classify music genre from a 10 second sound stream using a Neural Network.
MusicGenreClassification Academic research in the field of Deep Learning (Deep Neural Networks) and Sound Processing, Tel Aviv University. Featured in
 453 Dec 27, 2022
453 Dec 27, 2022
This github repo is for Neurips 2021 paper, NORESQA A Framework for Speech Quality Assessment using Non-Matching References.
NORESQA: Speech Quality Assessment using Non-Matching References This is a Pytorch implementation for using NORESQA. It contains minimal code to predi
36 Dec 8, 2022
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
 76 Dec 30, 2022
76 Dec 30, 2022
Adaptive Denoising Training (ADT) for Recommendation.
DenoisingRec Adaptive Denoising Training for Recommendation. This is the pytorch implementation of our paper at WSDM 2021: Denoising Implicit Feedback
 51 Dec 30, 2022
51 Dec 30, 2022

Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
 47 Dec 25, 2022
47 Dec 25, 2022

SingleVC performs any-to-one VC, which is an important component of MediumVC project.
SingleVC performs any-to-one VC, which is an important component of MediumVC project. Here is the official implementation of the paper, MediumVC.
26 Dec 28, 2022

Implementation of Google Brain's WaveGrad high-fidelity vocoder
WaveGrad Implementation (PyTorch) of Google Brain's high-fidelity WaveGrad vocoder (paper). First implementation on GitHub with high-quality generatio
 363 Dec 27, 2022
363 Dec 27, 2022
DiffWave is a fast, high-quality neural vocoder and waveform synthesizer.
DiffWave DiffWave is a fast, high-quality neural vocoder and waveform synthesizer. It starts with Gaussian noise and converts it into speech via itera
 498 Jan 3, 2023
498 Jan 3, 2023

Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models Jonathan Ho, Ajay Jain, Pieter Abbeel Paper: https://arxiv.org/abs/2006.11239 Website: https://hojonathanho.g
 1.5k Jan 8, 2023
1.5k Jan 8, 2023
Denoising Diffusion Implicit Models
Denoising Diffusion Implicit Models (DDIM) Jiaming Song, Chenlin Meng and Stefano Ermon, Stanford Implements sampling from an implicit model that is t
 465 Jan 5, 2023
465 Jan 5, 2023

Score-Based Point Cloud Denoising (ICCV'21)
Score-Based Point Cloud Denoising (ICCV'21) [Paper] https://arxiv.org/abs/2107.10981 Installation Recommended Environment The code has been tested in
 79 Dec 26, 2022
79 Dec 26, 2022
Neural HMMs are all you need (for high-quality attention-free TTS)
Neural HMMs are all you need (for high-quality attention-free TTS) Shivam Mehta, Éva Székely, Jonas Beskow, and Gustav Eje Henter This is the official
 0 Oct 28, 2022
0 Oct 28, 2022

End-2-end speech synthesis with recurrent neural networks
Introduction New: Interactive demo using Google Colaboratory can be found here TTS-Cube is an end-2-end speech synthesis system that provides a full p
 214 Dec 7, 2022
214 Dec 7, 2022

Text to speech for Vietnamese, ez to use, ez to update
Chào mọi người, đây là dự án mở nhằm giúp việc đọc được trở nên dễ dàng hơn. Rất cảm ơn đội ngũ Zalo đã cung cấp hạ tầng để mình có thể tạo ra app này
 32 Jul 29, 2022
32 Jul 29, 2022
An 16kHz implementation of HiFi-GAN for soft-vc.
HiFi-GAN An 16kHz implementation of HiFi-GAN for soft-vc. Relevant links: Official HiFi-GAN repo HiFi-GAN paper Soft-VC repo Soft-VC paper Example Usa
 42 Dec 27, 2022
42 Dec 27, 2022
Simple Python library, distributed via binary wheels with few direct dependencies, for easily using wav2vec 2.0 models for speech recognition
Wav2Vec2 STT Python Beta Software Simple Python library, distributed via binary wheels with few direct dependencies, for easily using wav2vec 2.0 mode
 22 Dec 29, 2022
22 Dec 29, 2022
Self-Supervised Image Denoising via Iterative Data Refinement
Self-Supervised Image Denoising via Iterative Data Refinement Yi Zhang1, Dasong Li1, Ka Lung Law2, Xiaogang Wang1, Hongwei Qin2, Hongsheng Li1 1CUHK-S
72 Jan 1, 2023
Denoising Normalizing Flow
Denoising Normalizing Flow Christian Horvat and Jean-Pascal Pfister 2021 We combine Normalizing Flows (NFs) and Denoising Auto Encoder (DAE) by introd
 17 Oct 15, 2022
17 Oct 15, 2022
OpenL3: Open-source deep audio and image embeddings
OpenL3 OpenL3 is an open-source Python library for computing deep audio and image embeddings. Please refer to the documentation for detailed instructi
 326 Jan 2, 2023
326 Jan 2, 2023

Official Pytorch Implementation of Unsupervised Image Denoising With Frequency Domain Knowledge (BMVC2021 Oral Accepted Paper)
Unsupervised Image Denoising with Frequency Domain Knowledge (BMVC 2021 Oral) : Official Project Page This repository provides the official PyTorch im
 3 Nov 25, 2021
3 Nov 25, 2021
Official Pytorch Implementation of Unsupervised Image Denoising with Frequency Domain Knowledge
Unsupervised Image Denoising with Frequency Domain Knowledge (BMVC 2021 Oral) : Official Project Page This repository provides the official PyTorch im
12 Sep 26, 2022

Fast mesh denoising with data driven normal filtering using deep variational autoencoders
Fast mesh denoising with data driven normal filtering using deep variational autoencoders This is an implementation for the paper entitled "Fast mesh
 9 Dec 2, 2022
9 Dec 2, 2022
Combine Tacotron2 and Hifi GAN to generate speech from text
EndToEndTextToSpeech Combine Tacotron2 and Hifi GAN to generate speech from text Download weights Hifi GAN - hifi_gan/checkpoint/ : pretrain 2.5M ste
 1 Dec 18, 2021
1 Dec 18, 2021

SwinIR: Image Restoration Using Swin Transformer
SwinIR: Image Restoration Using Swin Transformer This repository is the official PyTorch implementation of SwinIR: Image Restoration Using Shifted Win
 2.4k Jan 5, 2023
2.4k Jan 5, 2023

Conversational text Analysis using various NLP techniques
PyConverse Let me try first Installation pip install pyconverse Usage Please try this notebook that demos the core functionalities: basic usage noteb
 158 Dec 25, 2022
158 Dec 25, 2022
Simple virtual assistant using pyttsx3 and speech recognition optionally with pywhatkit and pther libraries.
VirtualAssistant Simple virtual assistant using pyttsx3 and speech recognition optionally with pywhatkit and pther libraries. Third Party Libraries us
 1 Nov 27, 2021
1 Nov 27, 2021
Text-to-Speech for Belarusian language
title emoji colorFrom colorTo sdk app_file pinned Belarusian TTS 🐸 green green gradio app.py false Belarusian TTS 📢 🤖 Belarusian TTS (text-to-speec
 1 Nov 27, 2021
1 Nov 27, 2021

A python gui program to generate reddit text to speech videos from the id of any post.
Reddit text to speech generator A python gui program to generate reddit text to speech videos from the id of any post. Current functionality Generate
 17 Dec 19, 2022
17 Dec 19, 2022
Romanian Automatic Speech Recognition from the ROBIN project
RobinASR This repository contains Robin's Automatic Speech Recognition (RobinASR) for the Romanian language based on the DeepSpeech2 architecture, tog
 10 Jan 1, 2023
10 Jan 1, 2023

Repository for paper "Non-intrusive speech intelligibility prediction from discrete latent representations"
Non-Intrusive Speech Intelligibility Prediction from Discrete Latent Representations Official repository for paper "Non-Intrusive Speech Intelligibili
 5 Oct 25, 2022
5 Oct 25, 2022

The project is associated with the recently-launched ICASSP 2022 Multi-channel Multi-party Meeting Transcription Challenge (M2MeT) to provide participants with baseline systems for speech recognition and speaker diarization in conference scenario.
M2MeT challenge baseline -- AliMeeting This project provides the baseline system recipes for the ICASSP 2020 Multi-channel Multi-party Meeting Transcr
 81 Dec 8, 2022
81 Dec 8, 2022
DivNoising is an unsupervised denoising method to generate diverse denoised samples for any noisy input image. This repository contains the code to reproduce the results reported in the paper https://openreview.net/pdf?id=agHLCOBM5jP
DivNoising: Diversity Denoising with Fully Convolutional Variational Autoencoders Mangal Prakash1, Alexander Krull1,2, Florian Jug2 1Authors contribut
 33 Dec 30, 2022
33 Dec 30, 2022

Efficient Speech Processing Tookit for Automatic Speaker Recognition
Sugar Efficient Speech Processing Tookit for Automatic Speaker Recognition | HuggingFace | What's New EfficientTDNN: Efficient Architecture Search for
 14 Sep 14, 2022
14 Sep 14, 2022
German Text-To-Speech Engine using Tacotron and Griffin-Lim
jotts JoTTS is a German text-to-speech engine using tacotron and griffin-lim. The synthesizer model has been trained on my voice using Tacotron1. Due
 6 Aug 28, 2022
6 Aug 28, 2022
Official repository for "Restormer: Efficient Transformer for High-Resolution Image Restoration". SOTA for motion deblurring, image deraining, denoising (Gaussian/real data), and defocus deblurring.
Restormer: Efficient Transformer for High-Resolution Image Restoration Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan,
 906 Dec 30, 2022
906 Dec 30, 2022
A denoising autoencoder + adversarial losses and attention mechanisms for face swapping.
faceswap-GAN Adding Adversarial loss and perceptual loss (VGGface) to deepfakes'(reddit user) auto-encoder architecture. Updates Date Update 2018-08-2
 3.2k Dec 30, 2022
3.2k Dec 30, 2022
A desktop GUI providing an audio interface for GPT3.
Jabberwocky neil_degrasse_tyson_with_audio.mp4 Project Description This GUI provides an audio interface to GPT-3. My main goal was to provide a conven
 16 Nov 27, 2022
16 Nov 27, 2022
A CSRankings-like index for speech researchers
Speech Rankings This project mimics CSRankings to generate an ordered list of researchers in speech/spoken language processing along with their possib
 19 Nov 26, 2022
19 Nov 26, 2022
Official repository for "Restormer: Efficient Transformer for High-Resolution Image Restoration". SOTA results for single-image motion deblurring, image deraining, image denoising (synthetic and real data), and dual-pixel defocus deblurring.
Restormer: Efficient Transformer for High-Resolution Image Restoration Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan,
906 Dec 30, 2022
Python project to take sound as input and output as RGB + Brightness values suitable for DMX
sound-to-light Python project to take sound as input and output as RGB + Brightness values suitable for DMX Current goals: Get one pixel working: Vary
 1 Nov 17, 2021
1 Nov 17, 2021

Disables the chat in League of Legends for Windows.
Disables the chat in League of Legends for Windows. If you simply can't stop yourself from typing LeagueStop will play KEKW.mp3 each time you try. The sound will stack & becomes horribly annoying.
 1 Nov 24, 2021
1 Nov 24, 2021

Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition | paper | dataset | pretrained detection model | Authors: Yi-Chang Che
 1 Aug 23, 2022
1 Aug 23, 2022
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL, and utterance id
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL
 3 Dec 26, 2022
3 Dec 26, 2022