91 Repositories
Python sound-separation Libraries
Sound-guided Semantic Image Manipulation - Official Pytorch Code (CVPR 2022)
🔉 Sound-guided Semantic Image Manipulation (CVPR2022) Official Pytorch Implementation Sound-guided Semantic Image Manipulation IEEE/CVF Conference on
 58 Dec 28, 2022
58 Dec 28, 2022
Plays air warning sound when detects a certain phrase or a word in a specified Telegram chat.
Tryvoha Bot Disclaimer: this is more a convenient naming, rather than a real bot. It is designed to play air warning sound when detects a certain phra
 2 Mar 2, 2022
2 Mar 2, 2022

Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
 13 Feb 8, 2022
13 Feb 8, 2022
SAAVN - Sound Adversarial Audio-Visual Navigation,ICLR2022 (In PyTorch)
SAAVN SAAVN Code release for paper "Sound Adversarial Audio-Visual Navigation,IC
 10 Aug 30, 2022
10 Aug 30, 2022
Library for working with sound files of the format: .ogg, .mp3, .wav
Library for working with sound files of the format: .ogg, .mp3, .wav. By work is meant - playing sound files in a straight line and in the background, obtaining information about the sound file (author, performer, duration, bitrate, and so on). Playing goes through the pygame, and getting information through the mutagen.
 2 Dec 15, 2022
2 Dec 15, 2022
The official code repo of "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
134 Jan 1, 2023
This is the source code for the experiments related to the paper Unsupervised Audio Source Separation Using Differentiable Parametric Source Models
Unsupervised Audio Source Separation Using Differentiable Parametric Source Models This is the source code for the experiments related to the paper Un
 30 Oct 19, 2022
30 Oct 19, 2022
PatrikZero's CS:GO Hearing protection
Program that lowers volume when you die and get flashed in CS:GO. It aims to lower the chance of hearing damage by reducing overall sound exposure. Uses game state integration. Anti-cheat safe.
 224 Dec 4, 2022
224 Dec 4, 2022

Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources
Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources (e.g. just the lead vocals).
 14 Nov 7, 2022
14 Nov 7, 2022
An NVDA add-on to split screen reader and audio from other programs to different sound channels
An NVDA add-on to split screen reader and audio from other programs to different sound channels (add-on idea credit: Tony Malykh)
 7 Dec 25, 2022
7 Dec 25, 2022

Separation of Mainlobes and Sidelobes in the Ultrasound Image Based on the Spatial Covariance (MIST) and Aperture-Domain Spectrum of Received Signals
Separation of Mainlobes and Sidelobes in the Ultrasound Image Based on the Spatial Covariance (MIST) and Aperture-Domain Spectrum of Received Signals
 3 Jan 3, 2023
3 Jan 3, 2023

Animal Sound Classification (Cats Vrs Dogs Audio Sentiment Classification)
this is a simple artificial neural network model using deep learning and torch-audio to classify cats and dog sounds.
 3 Dec 5, 2022
3 Dec 5, 2022
Code release for "MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound"
merlot_reserve Code release for "MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound" MERLOT Reserve (in submission) is a mo
 92 Dec 11, 2022
92 Dec 11, 2022
Code for "Unsupervised Source Separation via Bayesian inference in the latent domain"
LQVAE-separation Code for "Unsupervised Source Separation via Bayesian inference in the latent domain" Paper Samples GT Compressed Separated Drums GT
 30 Oct 25, 2022
30 Oct 25, 2022
A menu for pygame. Simple, and easy to use
pygame-menu Source repo on GitHub, and run it on Repl.it Introduction Pygame-menu is a python-pygame library for creating menus and GUIs. It supports
 411 Dec 27, 2022
411 Dec 27, 2022

Sound-Equalizer- This is a Sound Equalizer GUI App Using Python's PyQt5
Sound-Equalizer- This is a Sound Equalizer GUI App Using Python's PyQt5. It gives you the ability to play, pause, and Equalize any one-channel wav audio file and play 3 different instruments.
 1 Jan 10, 2022
1 Jan 10, 2022
A simple program to make MSI Modern 15 speaker and microphone mute led work.
MSI Modern 15 sound led fixup for linux A simple program to fix the MSI Modern 15 speaker and microphone mute LEDs. Installation Requirements pulsectl
 4 Oct 18, 2022
4 Oct 18, 2022
🎵 Python sound notifications made easy
chime Python sound notifications made easy. Table of contents Table of contents Motivation Installation Basic usage Theming IPython/Jupyter magic Exce
 231 Jan 9, 2023
231 Jan 9, 2023

Codebase for ECCV18 "The Sound of Pixels"
Sound-of-Pixels Codebase for ECCV18 "The Sound of Pixels". *This repository is under construction, but the core parts are already there. Environment T
 318 Dec 20, 2022
318 Dec 20, 2022
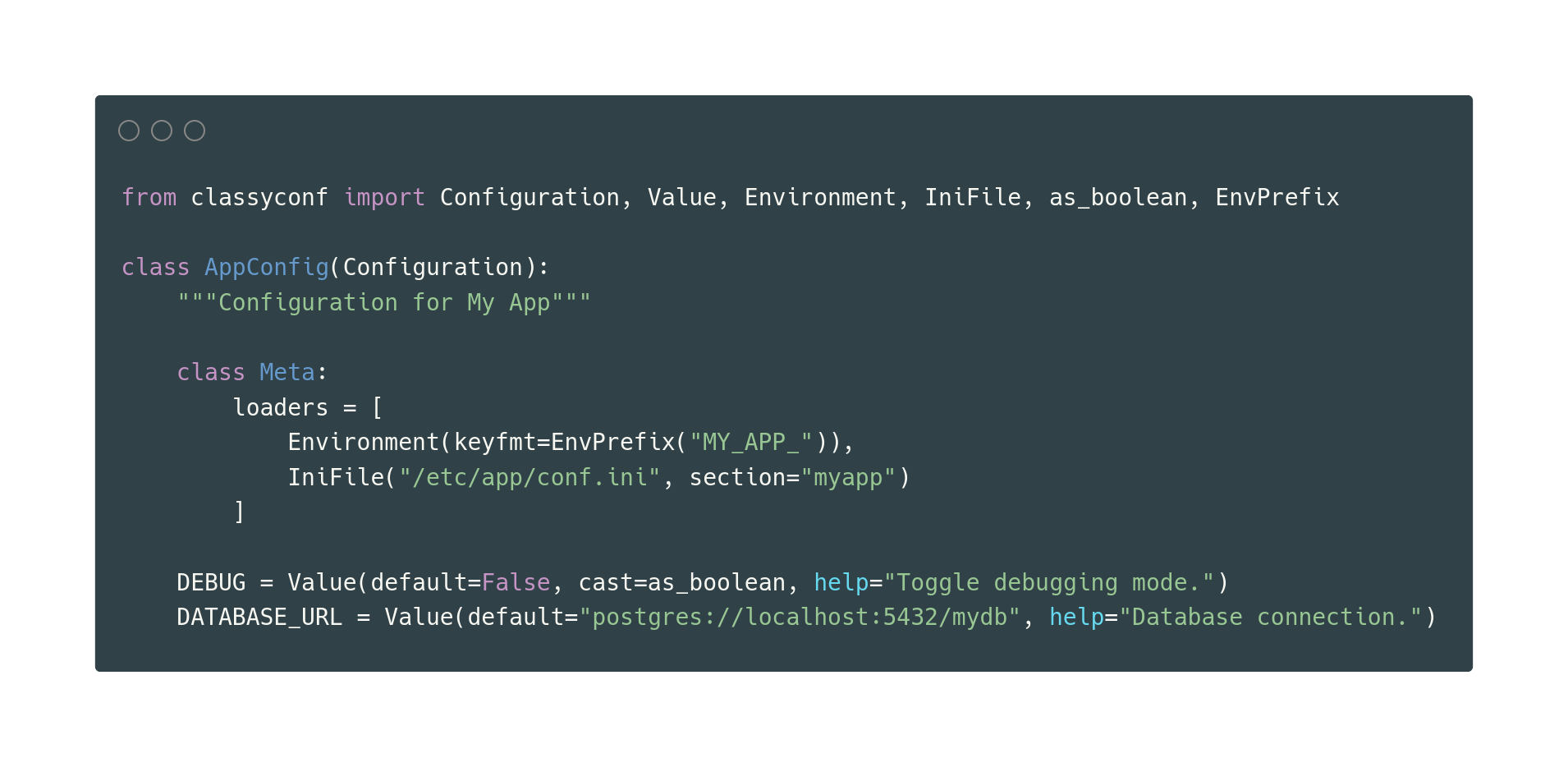
Declarative and extensible library for configuration & code separation
ClassyConf ClassyConf is the configuration architecture solution for perfectionists with deadlines. It provides a declarative way to define settings f
 83 Dec 7, 2022
83 Dec 7, 2022
SuperCollider library for Python
SuperCollider library for Python This project is a port of core features of SuperCollider's language to Python 3. It is intended to be the same librar
 65 Dec 22, 2022
65 Dec 22, 2022
Sound Source Localization for AI Grand Challenge 2021
Sound-Source-Localization Sound Source Localization study for AI Grand Challenge 2021 (sponsored by NC Soft Vision Lab) Preparation 1. Place the data-
 19 Mar 29, 2022
19 Mar 29, 2022
Sub-Cluster AdaCos: Learning Representations for Anomalous Sound Detection.
Accompanying code for the paper Sub-Cluster AdaCos: Learning Representations for Anomalous Sound Detection.
 6 Dec 1, 2022
6 Dec 1, 2022
pyo is a Python module written in C to help digital signal processing script creation.
pyo is a Python module written in C to help digital signal processing script creation.
 1.1k Jan 1, 2023
1.1k Jan 1, 2023

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: WavLM (arXiv): WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing UniSpeech (ICML 202
 281 Dec 15, 2022
281 Dec 15, 2022

PyAbsorp is a python module that has the main focus to help estimate the Sound Absorption Coefficient.
This is a package developed to be use to find the Sound Absorption Coefficient through some implemented models, like Biot-Allard, Johnson-Champoux and
 8 Oct 19, 2022
8 Oct 19, 2022
A `Neural = Symbolic` framework for sound and complete weighted real-value logic
Logical Neural Networks LNNs are a novel Neuro = symbolic framework designed to seamlessly provide key properties of both neural nets (learning) and s
 138 Dec 19, 2022
138 Dec 19, 2022

Analyze, visualize and process sound field data recorded by spherical microphone arrays.
Sound Field Analysis toolbox for Python The sound_field_analysis toolbox (short: sfa) is a Python port of the Sound Field Analysis Toolbox (SOFiA) too
 69 Nov 23, 2022
69 Nov 23, 2022

Music Source Separation; Train & Eval & Inference piplines and pretrained models we used for 2021 ISMIR MDX Challenge.
Introduction 1. Usage (For MSS) 1.1 Prepare running environment 1.2 Use pretrained model 1.3 Train new MSS models from scratch 1.3.1 How to train 1.3.
 100 Dec 25, 2022
100 Dec 25, 2022

Classify music genre from a 10 second sound stream using a Neural Network.
MusicGenreClassification Academic research in the field of Deep Learning (Deep Neural Networks) and Sound Processing, Tel Aviv University. Featured in
 453 Dec 27, 2022
453 Dec 27, 2022
Python project to take sound as input and output as RGB + Brightness values suitable for DMX
sound-to-light Python project to take sound as input and output as RGB + Brightness values suitable for DMX Current goals: Get one pixel working: Vary
 1 Nov 17, 2021
1 Nov 17, 2021

Disables the chat in League of Legends for Windows.
Disables the chat in League of Legends for Windows. If you simply can't stop yourself from typing LeagueStop will play KEKW.mp3 each time you try. The sound will stack & becomes horribly annoying.
 1 Nov 24, 2021
1 Nov 24, 2021
extract unpack asset file (form unreal engine 4 pak) with extenstion *.uexp which contain awb/acb (cri/cpk like) sound or music resource
Uexp2Awb extract unpack asset file (form unreal engine 4 pak) with extenstion .uexp which contain awb/acb (cri/cpk like) sound or music resource. i ju
 6 Jun 22, 2022
6 Jun 22, 2022
Convert text to morse code and play morse code sound.
Convert text(english) to morse codes and play morse sound!
 5 Jul 15, 2022
5 Jul 15, 2022

Code for the paper Hybrid Spectrogram and Waveform Source Separation
Demucs Music Source Separation This is the 3rd release of Demucs (v3), featuring hybrid source separation. For the waveform only Demucs (v2): Go this
 4.8k Jan 4, 2023
4.8k Jan 4, 2023
Open-Source Tools & Data for Music Source Separation: A Pragmatic Guide for the MIR Practitioner
Open-Source Tools & Data for Music Source Separation: A Pragmatic Guide for the MIR Practitioner
 0 Nov 12, 2021
0 Nov 12, 2021

A python script to acquire multiple aws ec2 instances in a forensically sound-ish way
acquire_ec2.py The script acquire_ec2.py is used to automatically acquire AWS EC2 instances. The script needs to be run on an EC2 instance in the same
 31 Sep 10, 2022
31 Sep 10, 2022

Pre-1.0 door/chest sound injector for Minecraft
doorjector Pre-1.0 door/chest sound injector for Minecraft. While the game is running, doorjector hotswaps the new sounds for the old right before the
 1 Nov 20, 2021
1 Nov 20, 2021
[ICCV 2021] Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation
ADDS-DepthNet This is the official implementation of the paper Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation I
 52 Nov 24, 2022
52 Nov 24, 2022
Code for sound field predictions in domains with impedance boundaries. Used for generating results from the paper
Code for sound field predictions in domains with impedance boundaries. Used for generating results from the paper
 11 Dec 17, 2022
11 Dec 17, 2022
Distort a video using Seam Carving (video) and Vibrato effect (sound)
Distort videos Applies a Seam Carving algorithm (aka liquid rescale) on every frame of a video, and a vibrato effect on the audio to distort the video
 6 Dec 6, 2022
6 Dec 6, 2022
An 8D music player made to enjoy Halloween this year!🤘
HAPPY HALLOWEEN buddy! Split Player Hello There! Welcome to SplitPlayer... Supposed To Be A 8DPlayer.... You Decide.... It can play the ordinary audio
 1 Nov 4, 2021
1 Nov 4, 2021
A simple python script to play bell sound in your system infinitely, just for fun and experimental purposes
A simple python script to play bell sound in your system infinitely, just for fun and experimental purposes
 1 Oct 29, 2021
1 Oct 29, 2021

My first Minecraft CPU. Created in collaboration with Peer Carnes as a final project in CS 281: Architecture and Assembly at the University of Puget Sound
Minecraft CPU This is my first ever Minecraft CPU, created in collaboration with Peer Carnes. We created a custom assembly language, including an asse
 4 Oct 10, 2022
4 Oct 10, 2022
Code Release for the paper "TriBERT: Full-body Human-centric Audio-visual Representation Learning for Visual Sound Separation"
TriBERT This repository contains the code for the NeurIPS 2021 paper titled "TriBERT: Full-body Human-centric Audio-visual Representation Learning for
 8 Aug 31, 2022
8 Aug 31, 2022
SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch.
The SpeechBrain Toolkit SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch. The goal is to create a single, flexible, and us
 5.1k Jan 2, 2023
5.1k Jan 2, 2023
🎵 A repository for manually annotating files to create labeled acoustic datasets for machine learning.
🎵 A repository for manually annotating files to create labeled acoustic datasets for machine learning.
 28 Dec 22, 2022
28 Dec 22, 2022

Offical implementation for "Trash or Treasure? An Interactive Dual-Stream Strategy for Single Image Reflection Separation".
Trash or Treasure? An Interactive Dual-Stream Strategy for Single Image Reflection Separation (NeurIPS 2021) by Qiming Hu, Xiaojie Guo. Dependencies P
 31 Dec 20, 2022
31 Dec 20, 2022
Offical implementation for "Trash or Treasure? An Interactive Dual-Stream Strategy for Single Image Reflection Separation".
Trash or Treasure? An Interactive Dual-Stream Strategy for Single Image Reflection Separation (NeurIPS 2021) by Qiming Hu, Xiaojie Guo. Dependencies P
31 Dec 20, 2022
A python script that can play .mp3 URLs upon the ringing or motion detection of a Ring doorbell. The sound plays through Sonos speakers.
Ring x Sonos A python script that plays .mp3 files whenever a doorbell is rung or a doorbell detects motion. Features Music! Authors @braden Running T
 0 Nov 12, 2021
0 Nov 12, 2021

Source code for "Taming Visually Guided Sound Generation" (Oral at the BMVC 2021)
Taming Visually Guided Sound Generation • [Project Page] • [ArXiv] • [Poster] • • Listen for the samples on our project page. Overview We propose to t
 226 Jan 3, 2023
226 Jan 3, 2023
Transform-Invariant Non-Negative Matrix Factorization
Transform-Invariant Non-Negative Matrix Factorization A comprehensive Python package for Non-Negative Matrix Factorization (NMF) with a focus on learn
 6 Jul 1, 2022
6 Jul 1, 2022
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 1.9.0 ubuntu20/python3.9/pip ubuntu20/python3.8/p
 5.9k Jan 4, 2023
5.9k Jan 4, 2023
KUIELAB-MDX-Net got the 2nd place on the Leaderboard A and the 3rd place on the Leaderboard B in the MDX-Challenge ISMIR 2021
KUIELAB-MDX-Net got the 2nd place on the Leaderboard A and the 3rd place on the Leaderboard B in the MDX-Challenge ISMIR 2021
74 Dec 28, 2022

GUI for a Vocal Remover that uses Deep Neural Networks.
GUI for a Vocal Remover that uses Deep Neural Networks.
 4.4k Jan 7, 2023
4.4k Jan 7, 2023
UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: UniSpeech (ICML 2021): Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR UniSpeech-
33 Oct 14, 2021

A fast implementation of bss_eval metrics for blind source separation
fast_bss_eval Do you have a zillion BSS audio files to process and it is taking days ? Is your simulation never ending ? Fear no more! fast_bss_eval i
 99 Dec 13, 2022
99 Dec 13, 2022
fast_bss_eval is a fast implementation of the bss_eval metrics for the evaluation of blind source separation.
fast_bss_eval Do you have a zillion BSS audio files to process and it is taking days ? Is your simulation never ending ? Fear no more! fast_bss_eval i
99 Dec 13, 2022

Sound Event Detection with FilterAugment
Sound Event Detection with FilterAugment Official implementation of Heavily Augmented Sound Event Detection utilizing Weak Predictions (DCASE2021 Chal
 43 Aug 28, 2022
43 Aug 28, 2022

Speech Separation Using an Asynchronous Fully Recurrent Convolutional Neural Network
Speech Separation Using an Asynchronous Fully Recurrent Convolutional Neural Network This repository is the official implementation of Speech Separati
 116 Nov 9, 2022
116 Nov 9, 2022

Sound and Cost-effective Fuzzing of Stripped Binaries by Incremental and Stochastic Rewriting
StochFuzz: A New Solution for Binary-only Fuzzing StochFuzz is a (probabilistically) sound and cost-effective fuzzing technique for stripped binaries.
 164 Dec 5, 2022
164 Dec 5, 2022
A Django starter template with a sound foundation.
SOS Django Template SOS Django Tempalate is a Django starter template that has opinionated and good solutions while starting your new Django project.
 19 Oct 30, 2022
19 Oct 30, 2022

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
 883 Jan 7, 2023
883 Jan 7, 2023
Strict separation of config from code.
Python Decouple: Strict separation of settings from code Decouple helps you to organize your settings so that you can change parameters without having
 2.3k Jan 4, 2023
2.3k Jan 4, 2023
Music source separation is a task to separate audio recordings into individual sources
Music Source Separation Music source separation is a task to separate audio recordings into individual sources. This repository is an PyTorch implmeme
 958 Jan 3, 2023
958 Jan 3, 2023

harmonic-percussive-residual separation algorithm wrapped as a VST3 plugin (iPlug2)
Harmonic-percussive-residual separation plug-in This work is a study on the plausibility of a sines-transients-noise decomposition inspired algorithm
 9 Sep 1, 2022
9 Sep 1, 2022

Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library.
GI-Pi Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library. The SP0
 8 Dec 15, 2021
8 Dec 15, 2021
Reading list for research topics in sound event detection
Sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene.
 64 Jan 5, 2023
64 Jan 5, 2023
Code for the ICASSP-2021 paper: Continuous Speech Separation with Conformer.
Continuous Speech Separation with Conformer Introduction We examine the use of the Conformer architecture for continuous speech separation. Conformer
 81 Nov 28, 2022
81 Nov 28, 2022

Using a raspberry pi, we listen to the coffee machine and count the number of coffee consumption
A typical datarootsian consumes high-quality fresh coffee in their office environment. The board of dataroots had a very critical decision by the end of 2021-Q2 regarding coffee consumption.
 51 Nov 21, 2022
51 Nov 21, 2022
Music Source Separation; Train & Eval & Inference piplines and pretrained models we used for 2021 ISMIR MDX Challenge.
Music Source Separation with Channel-wise Subband Phase Aware ResUnet (CWS-PResUNet) Introduction This repo contains the pretrained Music Source Separ
100 Dec 25, 2022

Easy to use Audio Tagging in PyTorch
Audio Classification, Tagging & Sound Event Detection in PyTorch Progress: Fine-tune on audio classification Fine-tune on audio tagging Fine-tune on s
 15 Dec 22, 2022
15 Dec 22, 2022
![[NeurIPS 2020] Official repository for the project](https://github.com/henryxrl/Listening-to-Sound-of-Silence-for-Speech-Denoising/raw/main/assets/network.png)
[NeurIPS 2020] Official repository for the project "Listening to Sound of Silence for Speech Denoising"
Listening to Sounds of Silence for Speech Denoising Introduction This is the repository of the "Listening to Sounds of Silence for Speech Denoising" p
 40 Dec 20, 2022
40 Dec 20, 2022
spafe: Simplified Python Audio-Features Extraction
spafe aims to simplify features extractions from mono audio files. The library can extract of the following features: BFCC, LFCC, LPC, LPCC, MFCC, IMFCC, MSRCC, NGCC, PNCC, PSRCC, PLP, RPLP, Frequency-stats etc. It also provides various filterbank modules (Mel, Bark and Gammatone filterbanks) and other spectral statistics.
 310 Jan 1, 2023
310 Jan 1, 2023
Starter kit for getting started in the Music Demixing Challenge.
Music Demixing Challenge - Starter Kit 👉 Challenge page This repository is the Music Demixing Challenge Submission template and Starter kit! Clone th
 106 Dec 20, 2022
106 Dec 20, 2022
Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
881 Jan 3, 2023
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.0.1 1.1.0 1.2.0 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 ubuntu18/python3.8/pip ubuntu18
5.9k Jan 3, 2023

audioLIME: Listenable Explanations Using Source Separation
audioLIME This repository contains the Python package audioLIME, a tool for creating listenable explanations for machine learning models in music info
 27 Dec 1, 2022
27 Dec 1, 2022

Code for the paper "Unsupervised Contrastive Learning of Sound Event Representations", ICASSP 2021.
Unsupervised Contrastive Learning of Sound Event Representations This repository contains the code for the following paper. If you use this code or pa
 81 Dec 22, 2022
81 Dec 22, 2022
A PyTorch Implementation of the paper - Choi, Woosung, et al. "Investigating u-nets with various intermediate blocks for spectrogram-based singing voice separation." 21th International Society for Music Information Retrieval Conference, ISMIR. 2020.
Investigating U-NETS With Various Intermediate Blocks For Spectrogram-based Singing Voice Separation A Pytorch Implementation of the paper "Investigat
 63 Nov 14, 2022
63 Nov 14, 2022
Open Sound Strip, Sequence or Record in Audacity
Audacity Tools For Blender Sound editing in Blender Video Sequence Editor with Audacity integrated. Send/receive the full edited sequence or single st
 64 Dec 31, 2022
64 Dec 31, 2022
C++ library for audio and music analysis, description and synthesis, including Python bindings
Essentia Essentia is an open-source C++ library for audio analysis and audio-based music information retrieval released under the Affero GPL license.
 2.3k Jan 3, 2023
2.3k Jan 3, 2023
a library for audio and music analysis
aubio aubio is a library to label music and sounds. It listens to audio signals and attempts to detect events. For instance, when a drum is hit, at wh
 2.9k Dec 30, 2022
2.9k Dec 30, 2022

Graphical interface to control granular sound synthesis.
Granular sound synthesis interface SoundGrain is a graphical interface where users can draw and edit trajectories to control granular sound synthesis
122 Dec 10, 2022

GNOME powered sound conversion
SoundConverter A simple sound converter application for the GNOME environment. It reads anything the GStreamer library can read, and writes Ogg Vorbis
 188 Dec 17, 2022
188 Dec 17, 2022
:sound: Play and Record Sound with Python :snake:
Play and Record Sound with Python This Python module provides bindings for the PortAudio library and a few convenience functions to play and record Nu
 750 Dec 31, 2022
750 Dec 31, 2022
Inner ear models for Python
cochlea cochlea is a collection of inner ear models. All models are easily accessible as Python functions. They take sound signal as input and return
 98 Jan 5, 2023
98 Jan 5, 2023
A Python library for audio data augmentation. Inspired by albumentations. Useful for machine learning.
Audiomentations A Python library for audio data augmentation. Inspired by albumentations. Useful for deep learning. Runs on CPU. Supports mono audio a
 1.2k Jan 7, 2023
1.2k Jan 7, 2023

PyTorch implementation of "A Full-Band and Sub-Band Fusion Model for Real-Time Single-Channel Speech Enhancement."
FullSubNet This Git repository for the official PyTorch implementation of "A Full-Band and Sub-Band Fusion Model for Real-Time Single-Channel Speech E
 357 Jan 4, 2023
357 Jan 4, 2023
Strict separation of config from code.
Python Decouple: Strict separation of settings from code Decouple helps you to organize your settings so that you can change parameters without having
2.3k Dec 30, 2022
?️ Open Source Audio Matching and Mastering
Matching + Mastering = ❤️ Matchering 2.0 is a novel Containerized Web Application and Python Library for audio matching and mastering. It follows a si
 781 Jan 5, 2023
781 Jan 5, 2023