821 Repositories
Python NLP-BERT-derived Libraries

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Original Implementation of Prompt Tuning from Lester, et al, 2021
Prompt Tuning This is the code to reproduce the experiments from the EMNLP 2021 paper "The Power of Scale for Parameter-Efficient Prompt Tuning" (Lest
 282 Dec 28, 2022
282 Dec 28, 2022
Code for the paper BERT might be Overkill: A Tiny but Effective Biomedical Entity Linker based on Residual Convolutional Neural Networks
Biomedical Entity Linking This repo provides the code for the paper BERT might be Overkill: A Tiny but Effective Biomedical Entity Linker based on Res
 24 Oct 24, 2022
24 Oct 24, 2022

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022
TweebankNLP - Pre-trained Tweet NLP Pipeline (NER, tokenization, lemmatization, POS tagging, dependency parsing) + Models + Tweebank-NER
TweebankNLP This repo contains the new Tweebank-NER dataset and Twitter-Stanza p
 84 Dec 20, 2022
84 Dec 20, 2022

Codes and scripts for "Explainable Semantic Space by Grounding Languageto Vision with Cross-Modal Contrastive Learning"
Visually Grounded Bert Language Model This repository is the official implementation of Explainable Semantic Space by Grounding Language to Vision wit
 17 Dec 17, 2022
17 Dec 17, 2022

In this project, we compared Spanish BERT and Multilingual BERT in the Sentiment Analysis task.
Applying BERT Fine Tuning to Sentiment Classification on Amazon Reviews Abstract Sentiment analysis has made great progress in recent years, due to th
 5 Jan 3, 2022
5 Jan 3, 2022
This repository contains demos I made with the Transformers library by HuggingFace.
Transformers-Tutorials Hi there! This repository contains demos I made with the Transformers library by 🤗 HuggingFace. Currently, all of them are imp
 3.5k Jan 1, 2023
3.5k Jan 1, 2023

Twitter-NLP-Analysis - Twitter Natural Language Processing Analysis
Twitter-NLP-Analysis Business Problem I got last @turk_politika 3000 tweets with
 7 Mar 12, 2022
7 Mar 12, 2022
Repositório do trabalho de introdução a NLP
Trabalho da disciplina de BI NLP Repositório do trabalho da disciplina Introdução a Processamento de Linguagem Natural da pós BI-Master da PUC-RIO. Eq
 1 Jan 18, 2022
1 Jan 18, 2022
In this Notebook I've build some machine-learning and deep-learning to classify corona virus tweets, in both multi class classification and binary classification.
Hello, This Notebook Contains Example of Corona Virus Tweets Multi Class Classification. - Classes is: Extremely Positive, Positive, Extremely Negativ
 3 Dec 6, 2022
3 Dec 6, 2022
A natural language processing model for sequential sentence classification in medical abstracts.
NLP PubMed Medical Research Paper Abstract (Randomized Controlled Trial) A natural language processing model for sequential sentence classification in
 1 Jan 17, 2022
1 Jan 17, 2022
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
 847 Dec 19, 2022
847 Dec 19, 2022

In this project, we aim to achieve the task of predicting emojis from tweets. We aim to investigate the relationship between words and emojis.
Making Emojis More Predictable by Karan Abrol, Karanjot Singh and Pritish Wadhwa, Natural Language Processing (CSE546) under the guidance of Dr. Shad
 2 Jan 17, 2022
2 Jan 17, 2022
Prompt-BERT: Prompt makes BERT Better at Sentence Embeddings
Prompt-BERT: Prompt makes BERT Better at Sentence Embeddings Results on STS Tasks Model STS12 STS13 STS14 STS15 STS16 STSb SICK-R Avg. unsup-prompt-be
 196 Jan 8, 2023
196 Jan 8, 2023
Code for ECIR'20 paper Diagnosing BERT with Retrieval Heuristics
Bert Axioms This is the repository with the code for the Paper Diagnosing BERT with Retrieval Heuristics Required Data In order to run this code, you
 5 Jan 21, 2022
5 Jan 21, 2022
An API that uses NLP and AI to let you predict possible diseases and symptoms based on a prompt of what you're feeling.
Disease detection API for MediSearch An API that uses NLP and AI to let you predict possible diseases and symptoms based on a prompt of what you're fe
 1 Jan 15, 2022
1 Jan 15, 2022
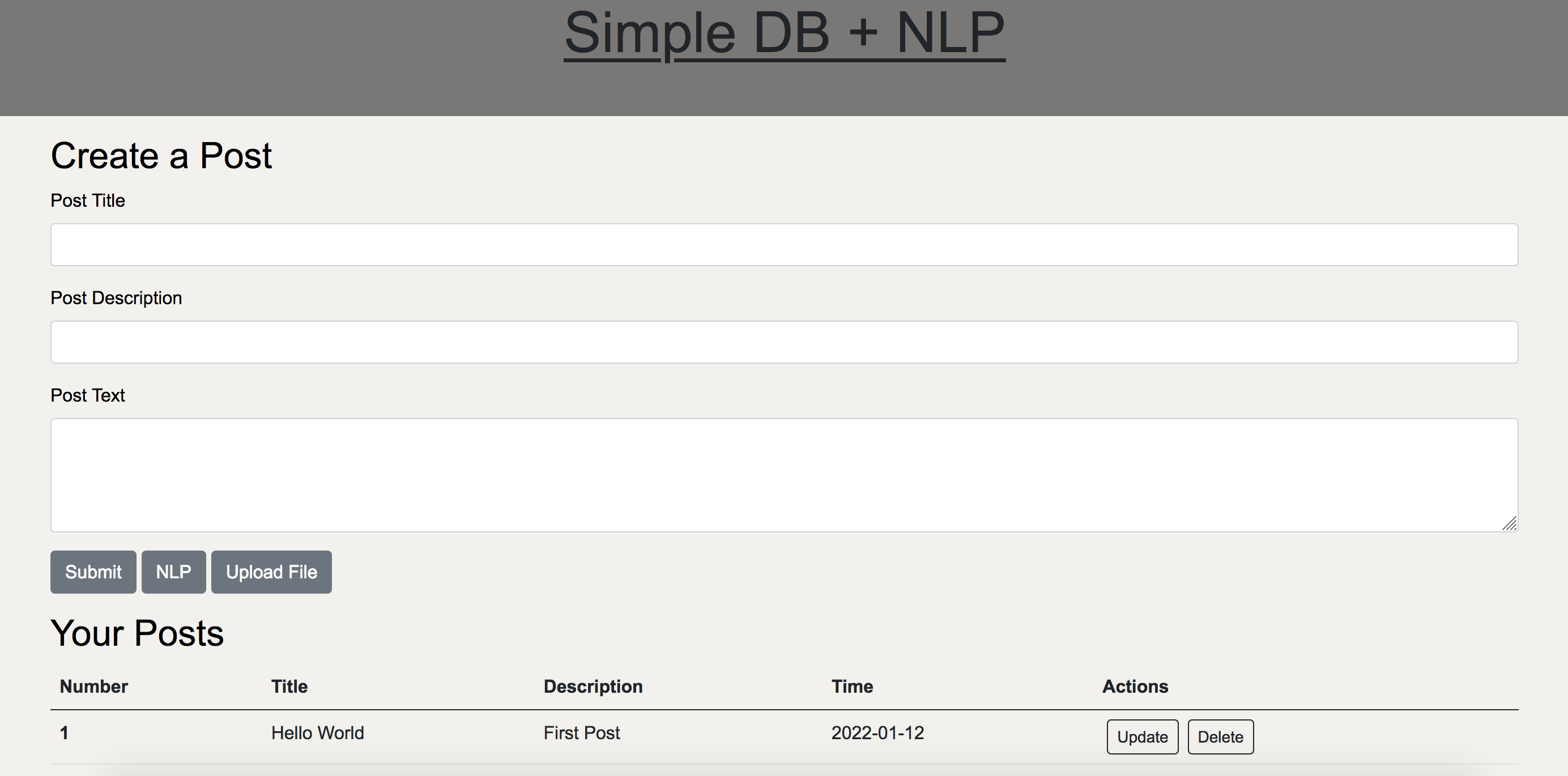
A simple Flask site that allows users to create, update, and delete posts in a database, as well as perform basic NLP tasks on the posts.
A simple Flask site that allows users to create, update, and delete posts in a database, as well as perform basic NLP tasks on the posts.
 1 Jan 15, 2022
1 Jan 15, 2022
NLP: SLU tagging
NLP: SLU tagging
 3 Jan 14, 2022
3 Jan 14, 2022

auto_code_complete is a auto word-completetion program which allows you to customize it on your need
auto_code_complete v1.3 purpose and usage auto_code_complete is a auto word-completetion program which allows you to customize it on your needs. the m
 2 Feb 22, 2022
2 Feb 22, 2022

Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021)
TDEER 🦌 🦒 Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021) Overview TDEE
 33 Dec 23, 2022
33 Dec 23, 2022

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
👄 The most accurate natural language detection library for Python, suitable for long and short text alike
1. What does this library do? Its task is simple: It tells you which language some provided textual data is written in. This is very useful as a prepr
 334 Dec 30, 2022
334 Dec 30, 2022

Sentiment-Analysis and EDA on the IMDB Movie Review Dataset
Sentiment-Analysis and EDA on the IMDB Movie Review Dataset The main part of the work focuses on the exploration and study of different approaches whi
 1 Jan 12, 2022
1 Jan 12, 2022
Mapping a variable-length sentence to a fixed-length vector using BERT model
Are you looking for X-as-service? Try the Cloud-Native Neural Search Framework for Any Kind of Data bert-as-service Using BERT model as a sentence enc
 11.1k Jan 1, 2023
11.1k Jan 1, 2023
HuSpaCy: industrial-strength Hungarian natural language processing
HuSpaCy: Industrial-strength Hungarian NLP HuSpaCy is a spaCy model and a library providing industrial-strength Hungarian language processing faciliti
 120 Dec 14, 2022
120 Dec 14, 2022
Exploration of BERT-based models on twitter sentiment classifications
twitter-sentiment-analysis Explore the relationship between twitter sentiment of Tesla and its stock price/return. Explore the effect of different BER
 2 Oct 2, 2022
2 Oct 2, 2022
End-to-end MLOps pipeline of a BERT model for emotion classification.
image source EmoBERT-MLOps The goal of this repository is to build an end-to-end MLOps pipeline based on the MLOps course from Made with ML, but this
 4 Nov 6, 2022
4 Nov 6, 2022
Natural Language Processing Best Practices & Examples
NLP Best Practices In recent years, natural language processing (NLP) has seen quick growth in quality and usability, and this has helped to drive bus
 6.1k Dec 31, 2022
6.1k Dec 31, 2022
Code and data accompanying Natural Language Processing with PyTorch
Natural Language Processing with PyTorch Build Intelligent Language Applications Using Deep Learning By Delip Rao and Brian McMahan Welcome. This is a
 1.8k Jan 1, 2023
1.8k Jan 1, 2023

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022
Auto_code_complete is a auto word-completetion program which allows you to customize it on your needs
auto_code_complete is a auto word-completetion program which allows you to customize it on your needs. the model for this program is one of the deep-learning NLP(Natural Language Process) model structure called 'GRU(gated recurrent unit)'.
2 Feb 22, 2022

Beyond Accuracy: Behavioral Testing of NLP models with CheckList
CheckList This repository contains code for testing NLP Models as described in the following paper: Beyond Accuracy: Behavioral Testing of NLP models
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch
Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch. Topics: Face detection with Detectron 2, Time Series anomaly detection with LSTM Autoencoders, Object Detection with YOLO v5, Build your first Neural Network, Time Series forecasting for Coronavirus daily cases, Sentiment Analysis with BERT.
 1.8k Dec 31, 2022
1.8k Dec 31, 2022
A Practitioner's Guide to Natural Language Processing
Learn how to process, classify, cluster, summarize, understand syntax, semantics and sentiment of text data with the power of Python! This repository contains code and datasets used in my book, Text Analytics with Python published by Apress/Springer.
 1.5k Jan 3, 2023
1.5k Jan 3, 2023
Mycroft Core, the Mycroft Artificial Intelligence platform.
Mycroft Mycroft is a hackable open source voice assistant. Table of Contents Getting Started Running Mycroft Using Mycroft Home Device and Account Man
 6.1k Jan 9, 2023
6.1k Jan 9, 2023
A list of NLP(Natural Language Processing) tutorials
NLP Tutorial A list of NLP(Natural Language Processing) tutorials built on PyTorch. Table of Contents A step-by-step tutorial on how to implement and
 1.3k Dec 25, 2022
1.3k Dec 25, 2022
A Demo server serving Bert through ONNX with GPU written in Rust with 3
Demo BERT ONNX server written in rust This demo showcase the use of onnxruntime-rs on BERT with a GPU on CUDA 11 served by actix-web and tokenized wit
 28 Jan 1, 2023
28 Jan 1, 2023
Using BERT+Bi-LSTM+CRF
Chinese Medical Entity Recognition Based on BERT+Bi-LSTM+CRF Step 1 I share the dataset on my google drive, please download the whole 'CCKS_2019_Task1
 55 Dec 21, 2022
55 Dec 21, 2022

Keras implementation of "One pixel attack for fooling deep neural networks" using differential evolution on Cifar10 and ImageNet
One Pixel Attack How simple is it to cause a deep neural network to misclassify an image if an attacker is only allowed to modify the color of one pix
 1.2k Dec 26, 2022
1.2k Dec 26, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023

This project deals with a simplified version of a more general problem of Aspect Based Sentiment Analysis.
Aspect_Based_Sentiment_Extraction Created on: 5th Jan, 2022. This project deals with an important field of Natural Lnaguage Processing - Aspect Based
 4 Jan 1, 2023
4 Jan 1, 2023
NLP techniques such as named entity recognition, sentiment analysis, topic modeling, text classification with Python to predict sentiment and rating of drug from user reviews.
This file contains the following documents sumbited for Baruch CIS9665 group 9 fall 2021. 1. Dataset: drug_reviews.csv 2. python codes for text classi
 2 Jan 4, 2023
2 Jan 4, 2023

Repository for Project Insight: NLP as a Service
Project Insight NLP as a Service Contents Introduction Features Installation Setup and Documentation Project Details Demonstration Directory Details H
 286 Dec 6, 2022
286 Dec 6, 2022
Simple translation demo showcasing our headliner package.
Headliner Demo This is a demo showcasing our Headliner package. In particular, we trained a simple seq2seq model on an English-German dataset. We didn
 16 Nov 24, 2022
16 Nov 24, 2022

Rhyme with AI
Local development Create a conda virtual environment and activate it: conda env create --file environment.yml conda activate rhyme-with-ai Install the
 28 Nov 21, 2022
28 Nov 21, 2022
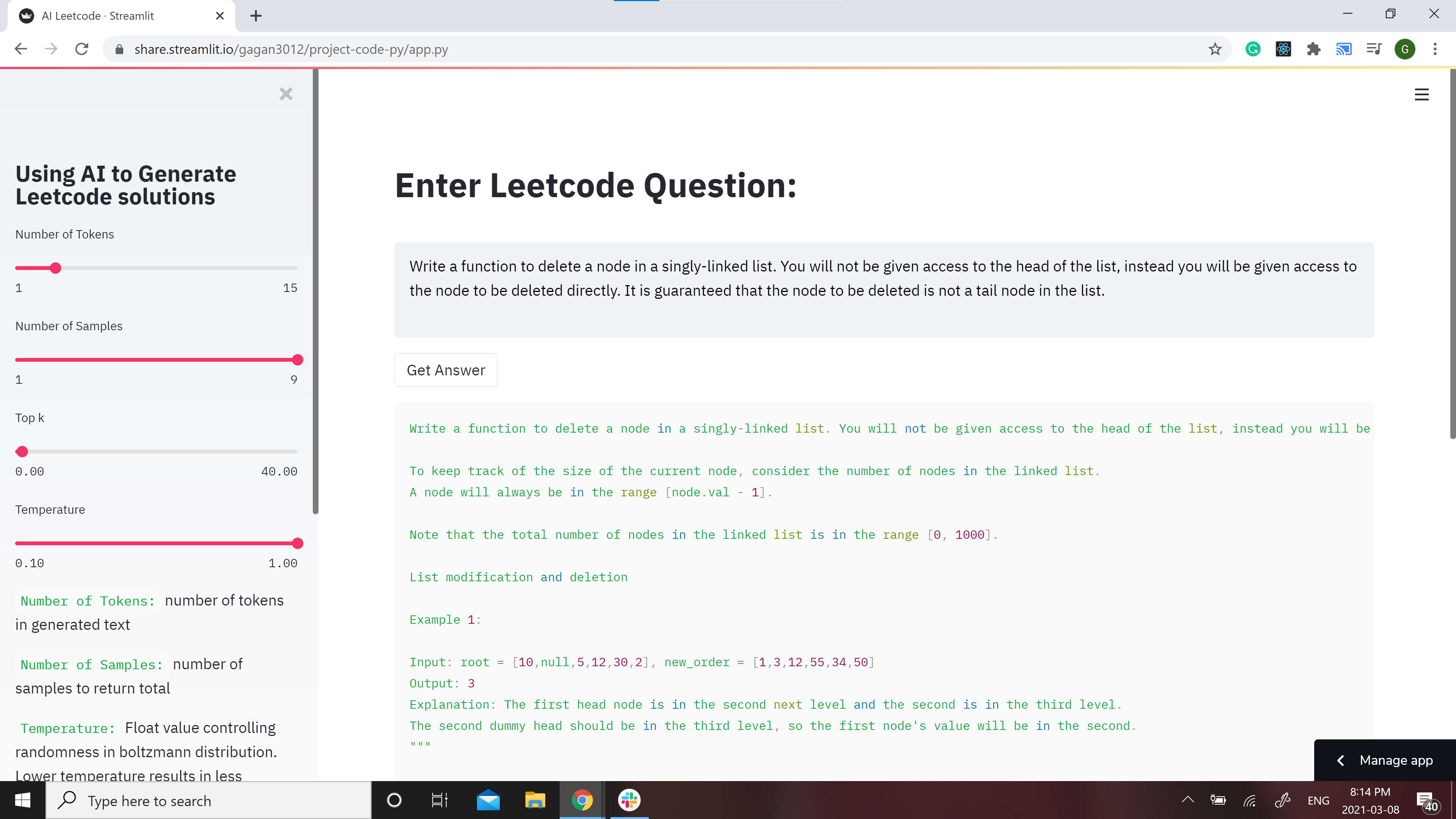
GPT-2 Model for Leetcode Questions in python
Leetcode using AI 🤖 GPT-2 Model for Leetcode Questions in python New demo here: https://huggingface.co/spaces/gagan3012/project-code-py Note: the Ans
 100 Dec 12, 2022
100 Dec 12, 2022

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
Using BERT-based models for toxic span detection
SemEval 2021 Task 5: Toxic Spans Detection: Task: Link to SemEval-2021: Task 5 Toxic Span Detection is https://competitions.codalab.org/competitions/2
 1 Jan 4, 2022
1 Jan 4, 2022
This repository focus on Image Captioning & Video Captioning & Seq-to-Seq Learning & NLP
Awesome-Visual-Captioning Table of Contents ACL-2021 CVPR-2021 AAAI-2021 ACMMM-2020 NeurIPS-2020 ECCV-2020 CVPR-2020 ACL-2020 AAAI-2020 ACL-2019 NeurI
 362 Jan 3, 2023
362 Jan 3, 2023

NLP-Project - Used an API to scrape 2000 reddit posts, then used NLP analysis and created a classification model to mixed succcess
Project 3: Web APIs & NLP Problem Statement How do r/Libertarian and r/Neoliberal differ on Biden post-inaguration? The goal of the project is to see
 2 Mar 29, 2022
2 Mar 29, 2022
NLP-SentimentAnalysis - Coursera Course ( Duration : 5 weeks ) offered by DeepLearning.AI
Coursera Natural Language Processing Specialization This repository contains material related to Coursera Natural Language Processing Specialization.
 1 Jun 5, 2022
1 Jun 5, 2022
Awesome Artificial Intelligence, Machine Learning and Deep Learning as we learn it
Awesome Artificial Intelligence, Machine Learning and Deep Learning as we learn it. Study notes and a curated list of awesome resources of such topics.
 1.2k Jan 7, 2023
1.2k Jan 7, 2023

Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning And private Server services
Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning
 4.2k Dec 29, 2022
4.2k Dec 29, 2022

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

KoBERT - Korean BERT pre-trained cased (KoBERT)
KoBERT KoBERT Korean BERT pre-trained cased (KoBERT) Why'?' Training Environment Requirements How to install How to use Using with PyTorch Using with
 1k Jan 2, 2023
1k Jan 2, 2023
News-Articles-and-Essays - NLP (Topic Modeling and Clustering)
NLP T5 Project proposal Topic Modeling and Clustering of News-Articles-and-Essays Students: Nasser Alshehri Abdullah Bushnag Abdulrhman Alqurashi OVER
 2 Jan 18, 2022
2 Jan 18, 2022
Automatic library of congress classification, using word embeddings from book titles and synopses.
Automatic Library of Congress Classification The Library of Congress Classification (LCC) is a comprehensive classification system that was first deve
 3 Oct 1, 2022
3 Oct 1, 2022
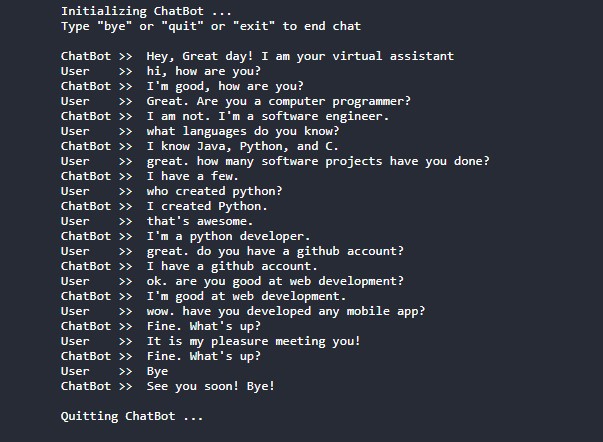
Conversational-AI-ChatBot - Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users!
Conversational AI ChatBot Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users! In this project? Thi
 6 Nov 30, 2022
6 Nov 30, 2022
A recommendation system for suggesting new books given similar books.
Book Recommendation System A recommendation system for suggesting new books given similar books. Datasets Dataset Kaggle Dataset Notebooks goodreads-E
 2 Jan 6, 2022
2 Jan 6, 2022

Search-Engine - 📖 AI based search engine
Search Engine AI based search engine that was trained on 25000 samples, feel free to train on up to 1.2M sample from kaggle dataset, link below StackS
 2 Nov 29, 2022
2 Nov 29, 2022

A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
 335 Jan 4, 2023
335 Jan 4, 2023

Natural Language Processing for Adverse Drug Reaction (ADR) Detection
Natural Language Processing for Adverse Drug Reaction (ADR) Detection This repo contains code from a project to identify ADRs in discharge summaries a
 21 Aug 5, 2022
21 Aug 5, 2022
Ecco is a python library for exploring and explaining Natural Language Processing models using interactive visualizations.
Visualize, analyze, and explore NLP language models. Ecco creates interactive visualizations directly in Jupyter notebooks explaining the behavior of Transformer-based language models (like GPT2, BERT, RoBERTA, T5, and T0).
 1.6k Dec 25, 2022
1.6k Dec 25, 2022
Python library for parsing resumes using natural language processing and machine learning
CVParser Python library for parsing resumes using natural language processing and machine learning. Setup Installation on Linux and Mac OS Follow the
 0 Jul 29, 2021
0 Jul 29, 2021

NLP project that works with news (NER, context generation, news trend analytics)
СоАвтор СоАвтор – платформа и открытый набор инструментов для редакций и журналистов-фрилансеров, который призван сделать процесс создания контента ма
 38 Jan 4, 2023
38 Jan 4, 2023

For storing the complete exploration of Visual Question Answering for our B.Tech Project
Multi-Image vqa @authors: Akhilesh, Janhavi, Harsh Paper summary, Ideas tried and their corresponding results: on wiki Other discussions: on discussio
 3 Jun 16, 2022
3 Jun 16, 2022

Source code of the "Graph-Bert: Only Attention is Needed for Learning Graph Representations" paper
Graph-Bert Source code of "Graph-Bert: Only Attention is Needed for Learning Graph Representations". Please check the script.py as the entry point. We
 14 Mar 25, 2022
14 Mar 25, 2022
Pre-training of Graph Augmented Transformers for Medication Recommendation
G-Bert Pre-training of Graph Augmented Transformers for Medication Recommendation Intro G-Bert combined the power of Graph Neural Networks and BERT (B
 101 Dec 27, 2022
101 Dec 27, 2022
Self-Guided Contrastive Learning for BERT Sentence Representations
Self-Guided Contrastive Learning for BERT Sentence Representations This repository is dedicated for releasing the implementation of the models utilize
 16 Dec 4, 2022
16 Dec 4, 2022
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
 2 Oct 22, 2022
2 Oct 22, 2022
txtai: Build AI-powered semantic search applications in Go
txtai: Build AI-powered semantic search applications in Go txtai executes machine-learning workflows to transform data and build AI-powered semantic s
 49 Dec 6, 2022
49 Dec 6, 2022
Fast, DB Backed pretrained word embeddings for natural language processing.
Embeddings Embeddings is a python package that provides pretrained word embeddings for natural language processing and machine learning. Instead of lo
 212 Nov 21, 2022
212 Nov 21, 2022

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
Utilize Korean BERT model in sentence-transformers library
ko-sentence-transformers 이 프로젝트는 KoBERT 모델을 sentence-transformers 에서 보다 쉽게 사용하기 위해 만들어졌습니다. Ko-Sentence-BERT-SKTBERT 프로젝트에서는 KoBERT 모델을 sentence-trans
 40 Dec 20, 2022
40 Dec 20, 2022
An automated program that helps customers of Pizza Palour place their pizza orders
PIzza_Order_Assistant Introduction An automated program that helps customers of Pizza Palour place their pizza orders. The program uses voice commands
 1 Dec 26, 2021
1 Dec 26, 2021
jiant is an NLP toolkit
🚨 Update 🚨 : As of 2021/10/17, the jiant project is no longer being actively maintained. This means there will be no plans to add new models, tasks,
 1.5k Dec 28, 2022
1.5k Dec 28, 2022
PyBERT is a serial communication link bit error rate tester simulator with a graphical user interface (GUI).
PyBERT PyBERT is a serial communication link bit error rate tester simulator with a graphical user interface (GUI). It uses the Traits/UI package of t
 59 Dec 23, 2022
59 Dec 23, 2022
Korean Sentence Embedding Repository
Korean-Sentence-Embedding 🍭 Korean sentence embedding repository. You can download the pre-trained models and inference right away, also it provides
 80 Jan 2, 2023
80 Jan 2, 2023
A modified Sequential and NLP based Bot
A modified Sequential and NLP based Bot I improvised this bot a bit with some implementations as a part of my own hobby project :) Note: I do not own
 2 Jan 7, 2022
2 Jan 7, 2022
A Lightweight NLP Data Loader for All Deep Learning Frameworks in Python
LineFlow: Framework-Agnostic NLP Data Loader in Python LineFlow is a simple text dataset loader for NLP deep learning tasks. LineFlow was designed to
 177 Jan 4, 2023
177 Jan 4, 2023

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022

Fast and robust date extraction from web pages, with Python or on the command-line
Find original and updated publication dates of any web page. From the command-line or within Python, all the steps needed from web page download to HTML parsing, scraping, and text analysis are included.
 60 Dec 14, 2022
60 Dec 14, 2022
Practical Natural Language Processing Tools for Humans is build on the top of Senna Natural Language Processing (NLP)
Practical Natural Language Processing Tools for Humans is build on the top of Senna Natural Language Processing (NLP) predictions: part-of-speech (POS) tags, chunking (CHK), name entity recognition (NER), semantic role labeling (SRL) and syntactic parsing (PSG) with skip-gram all in Python and still more features will be added. The website give is for downlarding Senna tool
 20 Apr 30, 2022
20 Apr 30, 2022
Simple multilingual lemmatizer for Python, especially useful for speed and efficiency
Simplemma: a simple multilingual lemmatizer for Python Purpose Lemmatization is the process of grouping together the inflected forms of a word so they
70 Dec 29, 2022
Faster, modernized fork of the language identification tool langid.py
py3langid py3langid is a fork of the standalone language identification tool langid.py by Marco Lui. Original license: BSD-2-Clause. Fork license: BSD
12 Nov 5, 2022

Quick insights from Zoom meeting transcripts using Graph + NLP
Transcript Analysis - Graph + NLP This program extracts insights from Zoom Meeting Transcripts (.vtt) using TigerGraph and NLTK. In order to run this
 7 Sep 17, 2022
7 Sep 17, 2022
Unofficial Python library for using the Polish Wordnet (plWordNet / Słowosieć)
Polish Wordnet Python library Simple, easy-to-use and reasonably fast library for using the Słowosieć (also known as PlWordNet) - a lexico-semantic da
 12 Dec 23, 2022
12 Dec 23, 2022
A Japanese tokenizer based on recurrent neural networks
Nagisa is a python module for Japanese word segmentation/POS-tagging. It is designed to be a simple and easy-to-use tool. This tool has the following
 325 Jan 5, 2023
325 Jan 5, 2023
Crawl BookCorpus
These are scripts to reproduce BookCorpus by yourself.
 590 Jan 3, 2023
590 Jan 3, 2023

⛵️The official PyTorch implementation for "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing" (EMNLP 2020).
BERT-of-Theseus Code for paper "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing". BERT-of-Theseus is a new compressed BERT by progre
 284 Nov 25, 2022
284 Nov 25, 2022
Basic yet complete Machine Learning pipeline for NLP tasks
Basic yet complete Machine Learning pipeline for NLP tasks This repository accompanies the article on building basic yet complete ML pipelines for sol
 20 Aug 22, 2022
20 Aug 22, 2022
Code for the project carried out fulfilling the course requirements for Fall 2021 NLP at NYU
Introduction Fairseq(-py) is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization,
 1 Apr 25, 2022
1 Apr 25, 2022

Sentiment Analysis web app using Streamlit - American Airlines Tweets
Analyse des sentiments à partir des Tweets L'application est développée par Streamlit L'analyse sentimentale est effectuée sur l'ensemble de données d
 2 Feb 4, 2022
2 Feb 4, 2022
The source code of "Language Models are Few-shot Multilingual Learners" (MRL @ EMNLP 2021)
Language Models are Few-shot Multilingual Learners Paper This is the source code of the paper [Arxiv] [ACL Anthology]: This code has been written usin
 45 Nov 21, 2022
45 Nov 21, 2022
Lightweight utility tools for the detection of multiple spellings, meanings, and language-specific terminology in British and American English
Breame ( British English and American English) Breame is a lightweight Python package with a number of utility tools to aid in the detection of words
 8 Oct 10, 2022
8 Oct 10, 2022
Materials (slides, code, assignments) for the NYU class I teach on NLP and ML Systems (Master of Engineering).
FREE_7773 Repo containing material for the NYU class (Master of Engineering) I teach on NLP, ML Sys etc. For context on what the class is trying to ac
 90 Dec 19, 2022
90 Dec 19, 2022