1541 Repositories
Python Vision-Transformer-Multiprocess-DistributedDataParallel-Apex Libraries

Towards Flexible Blind JPEG Artifacts Removal (FBCNN, ICCV 2021)
Towards Flexible Blind JPEG Artifacts Removal (FBCNN, ICCV 2021)
 282 Jan 2, 2023
282 Jan 2, 2023

Official implement of Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer This repository contains the PyTorch code for Evo-ViT. This work proposes a slow-fas
 53 Dec 5, 2022
53 Dec 5, 2022

Learning based AI for playing multi-round Koi-Koi hanafuda card games. Have fun.
Koi-Koi AI Learning based AI for playing multi-round Koi-Koi hanafuda card games. Platform Python PyTorch PySimpleGUI (for the interface playing vs AI
 10 Nov 20, 2022
10 Nov 20, 2022

This is a vision-based 3d model manipulation and control UI
Manipulation of 3D Models Using Hand Gesture This program allows user to manipulation 3D models (.obj format) with their hands. The project support bo
 43 Oct 23, 2022
43 Oct 23, 2022
Natural Language Processing with transformers
we want to create a repo to illustrate usage of transformers in chinese
 763 Dec 27, 2022
763 Dec 27, 2022

A collection of SOTA Image Classification Models in PyTorch
A collection of SOTA Image Classification Models in PyTorch
 85 Dec 30, 2022
85 Dec 30, 2022

This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking".
SCT This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking" The spatial-channel Transformer (SCT) enhan
 27 Nov 23, 2022
27 Nov 23, 2022
Implementation of a Transformer, but completely in Triton
Transformer in Triton (wip) Implementation of a Transformer, but completely in Triton. I'm completely new to lower-level neural net code, so this repo
 152 Dec 22, 2022
152 Dec 22, 2022
Certifiable Outlier-Robust Geometric Perception
Certifiable Outlier-Robust Geometric Perception About This repository holds the implementation for certifiably solving outlier-robust geometric percep
 83 Dec 31, 2022
83 Dec 31, 2022

Code & Models for 3DETR - an End-to-end transformer model for 3D object detection
3DETR: An End-to-End Transformer Model for 3D Object Detection PyTorch implementation and models for 3DETR. 3DETR (3D DEtection TRansformer) is a simp
 487 Dec 31, 2022
487 Dec 31, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 341 Dec 29, 2022
341 Dec 29, 2022

Implementation of Hierarchical Transformer Memory (HTM) for Pytorch
Hierarchical Transformer Memory (HTM) - Pytorch Implementation of Hierarchical Transformer Memory (HTM) for Pytorch. This Deepmind paper proposes a si
63 Dec 29, 2022

Polyp-PVT: Polyp Segmentation with Pyramid Vision Transformers (arXiv2021)
Polyp-PVT by Bo Dong, Wenhai Wang, Deng-Ping Fan, Jinpeng Li, Huazhu Fu, & Ling Shao. This repo is the official implementation of "Polyp-PVT: Polyp Se
 102 Jan 5, 2023
102 Jan 5, 2023
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless.
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless. This is the official Roboflow python package that interfaces with the Roboflow API.
 52 Dec 23, 2022
52 Dec 23, 2022

Code and data for "Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning" (EMNLP 2021).
GD-VCR Code for Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning (EMNLP 2021). Research Questions and Aims: How well can a model perform o
 24 Oct 13, 2022
24 Oct 13, 2022
Earth Vision Foundation
EVer - A Library for Earth Vision Researcher EVer is a Pytorch-based Python library to simplify the training and inference of the deep learning model.
 34 Nov 26, 2022
34 Nov 26, 2022
![[Preprint] ConvMLP: Hierarchical Convolutional MLPs for Vision, 2021](https://github.com/SHI-Labs/Convolutional-MLPs/raw/master/images/comparison.png)
[Preprint] ConvMLP: Hierarchical Convolutional MLPs for Vision, 2021
Convolutional MLP ConvMLP: Hierarchical Convolutional MLPs for Vision Preprint link: ConvMLP: Hierarchical Convolutional MLPs for Vision By Jiachen Li
 143 Jan 3, 2023
143 Jan 3, 2023
Optimized code based on M2 for faster image captioning training
Transformer Captioning This repository contains the code for Transformer-based image captioning. Based on meshed-memory-transformer, we further optimi
 16 Dec 16, 2022
16 Dec 16, 2022
A PyTorch library for Vision Transformers
VFormer A PyTorch library for Vision Transformers Getting Started Read the contributing guidelines in CONTRIBUTING.rst to learn how to start contribut
 142 Nov 28, 2022
142 Nov 28, 2022
Tutorial to pretrain & fine-tune a 🤗 Flax T5 model on a TPUv3-8 with GCP
Pretrain and Fine-tune a T5 model with Flax on GCP This tutorial details how pretrain and fine-tune a FlaxT5 model from HuggingFace using a TPU VM ava
 41 Nov 18, 2022
41 Nov 18, 2022

Realtime Face Anti Spoofing with Face Detector based on Deep Learning using Tensorflow/Keras and OpenCV
Realtime Face Anti-Spoofing Detection 🤖 Realtime Face Anti Spoofing Detection with Face Detector to detect real and fake faces Please star this repo
 86 Aug 3, 2022
86 Aug 3, 2022

Implementation for our ICCV 2021 paper: Dual-Camera Super-Resolution with Aligned Attention Modules
DCSR: Dual Camera Super-Resolution Implementation for our ICCV 2021 oral paper: Dual-Camera Super-Resolution with Aligned Attention Modules paper | pr
 110 Dec 20, 2022
110 Dec 20, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023
MegFlow - Efficient ML solutions for long-tailed demands.
Efficient ML solutions for long-tailed demands.
 371 Dec 21, 2022
371 Dec 21, 2022
Bridging Vision and Language Model
BriVL BriVL (Bridging Vision and Language Model) 是首个中文通用图文多模态大规模预训练模型。BriVL模型在图文检索任务上有着优异的效果,超过了同期其他常见的多模态预训练模型(例如UNITER、CLIP)。 BriVL论文:WenLan: Bridgi
 235 Dec 27, 2022
235 Dec 27, 2022

CTRL-C: Camera calibration TRansformer with Line-Classification
CTRL-C: Camera calibration TRansformer with Line-Classification This repository contains the official code and pretrained models for CTRL-C (Camera ca
 57 Nov 14, 2022
57 Nov 14, 2022
nnFormer: Interleaved Transformer for Volumetric Segmentation Code for paper "nnFormer: Interleaved Transformer for Volumetric Segmentation "
nnFormer: Interleaved Transformer for Volumetric Segmentation Code for paper "nnFormer: Interleaved Transformer for Volumetric Segmentation ". Please
 610 Dec 28, 2022
610 Dec 28, 2022

CMT: Convolutional Neural Networks Meet Vision Transformers
CMT: Convolutional Neural Networks Meet Vision Transformers [arxiv] 1. Introduction This repo is the CMT model which impelement with pytorch, no refer
 83 Dec 30, 2022
83 Dec 30, 2022

Code for the paper "Reinforcement Learning as One Big Sequence Modeling Problem"
Trajectory Transformer Code release for Reinforcement Learning as One Big Sequence Modeling Problem. Installation All python dependencies are in envir
 269 Jan 5, 2023
269 Jan 5, 2023
Voxel Transformer for 3D object detection
Voxel Transformer This is a reproduced repo of Voxel Transformer for 3D object detection. The code is mainly based on OpenPCDet. Introduction We provi
 173 Dec 25, 2022
173 Dec 25, 2022

Adaptive Pyramid Context Network for Semantic Segmentation (APCNet CVPR'2019)
Adaptive Pyramid Context Network for Semantic Segmentation (APCNet CVPR'2019) Introduction Official implementation of Adaptive Pyramid Context Network
 21 Nov 9, 2022
21 Nov 9, 2022

ZSL-KG is a general-purpose zero-shot learning framework with a novel transformer graph convolutional network (TrGCN) to learn class representation from common sense knowledge graphs.
ZSL-KG is a general-purpose zero-shot learning framework with a novel transformer graph convolutional network (TrGCN) to learn class representa
 94 Nov 21, 2022
94 Nov 21, 2022

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023

Lightweight stereo matching network based on MobileNetV1 and MobileNetV2
MobileStereoNet: Towards Lightweight Deep Networks for Stereo Matching
 139 Nov 30, 2022
139 Nov 30, 2022

Train GPT-3 model on V100(16GB Mem) Using improved Transformer.
GPT-X using transformer pytorch
 24 Sep 11, 2022
24 Sep 11, 2022

Prototype for Baby Action Detection and Classification
Baby Action Detection Table of Contents About Install Run Predictions Demo About An attempt to harness the power of Deep Learning to come up with a so
 30 Dec 16, 2022
30 Dec 16, 2022

Python scripts for performing stereo depth estimation using the HITNET Tensorflow model.
HITNET-Stereo-Depth-estimation Python scripts for performing stereo depth estimation using the HITNET Tensorflow model from Google Research. Stereo de
 76 Jan 2, 2023
76 Jan 2, 2023

Code for "Searching for Efficient Multi-Stage Vision Transformers"
Searching for Efficient Multi-Stage Vision Transformers This repository contains the official Pytorch implementation of "Searching for Efficient Multi
 62 Oct 25, 2022
62 Oct 25, 2022

GeDML is an easy-to-use generalized deep metric learning library
GeDML is an easy-to-use generalized deep metric learning library
 32 Dec 5, 2022
32 Dec 5, 2022

Implementation for our ICCV 2021 paper: Dual-Camera Super-Resolution with Aligned Attention Modules
DCSR: Dual Camera Super-Resolution Implementation for our ICCV 2021 oral paper: Dual-Camera Super-Resolution with Aligned Attention Modules paper | pr
110 Dec 20, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
超轻量级bert的pytorch版本,大量中文注释,容易修改结构,持续更新
bert4pytorch 2021年8月27更新: 感谢大家的star,最近有小伙伴反映了一些小的bug,我也注意到了,奈何这个月工作上实在太忙,更新不及时,大约会在9月中旬集中更新一个只需要pip一下就完全可用的版本,然后会新添加一些关键注释。 再增加对抗训练的内容,更新一个完整的finetune
 317 Dec 18, 2022
317 Dec 18, 2022
![[ICCV 2021 Oral] NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo](https://github.com/weiyithu/NerfingMVS/raw/main/imgs/demo.gif)
[ICCV 2021 Oral] NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo
NerfingMVS Project Page | Paper | Video | Data NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo Yi Wei, Shaohui
 369 Dec 24, 2022
369 Dec 24, 2022
![[ICCV21] Self-Calibrating Neural Radiance Fields](https://github.com/POSTECH-CVLab/SCNeRF/raw/master/assets/scnerf_teaser.png)
[ICCV21] Self-Calibrating Neural Radiance Fields
Self-Calibrating Neural Radiance Fields, ICCV, 2021 Project Page | Paper | Video Author Information Yoonwoo Jeong [Google Scholar] Seokjun Ahn [Google
 381 Dec 30, 2022
381 Dec 30, 2022

Code for Blind Image Decomposition (BID) and Blind Image Decomposition network (BIDeN).
arXiv, porject page, paper Blind Image Decomposition (BID) Blind Image Decomposition is a novel task. The task requires separating a superimposed imag
 64 Dec 20, 2022
64 Dec 20, 2022
EMNLP 2021 - Frustratingly Simple Pretraining Alternatives to Masked Language Modeling
Frustratingly Simple Pretraining Alternatives to Masked Language Modeling This is the official implementation for "Frustratingly Simple Pretraining Al
 31 Nov 18, 2022
31 Nov 18, 2022

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022
Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs
Perceiver IO Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs Usage import torch from src.perceiver.
 111 Nov 15, 2022
111 Nov 15, 2022
The official repository for our paper "The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers". We significantly improve the systematic generalization of transformer models on a variety of datasets using simple tricks and careful considerations.
Codebase for training transformers on systematic generalization datasets. The official repository for our EMNLP 2021 paper The Devil is in the Detail:
 57 Nov 21, 2022
57 Nov 21, 2022

Ongoing research training transformer language models at scale, including: BERT & GPT-2
Megatron (1 and 2) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA.
 3.5k Dec 30, 2022
3.5k Dec 30, 2022

The Official Implementation of the ICCV-2021 Paper: Semantically Coherent Out-of-Distribution Detection.
SCOOD-UDG (ICCV 2021) This repository is the official implementation of the paper: Semantically Coherent Out-of-Distribution Detection Jingkang Yang,
 62 Nov 21, 2022
62 Nov 21, 2022

Deep Unsupervised 3D SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment.
(ACMMM 2021 Oral) SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment This repository shows two tasks: Face landmark detection and Fac
 51 Dec 13, 2022
51 Dec 13, 2022

(ICCV'21) Official PyTorch implementation of Relational Embedding for Few-Shot Classification
Relational Embedding for Few-Shot Classification (ICCV 2021) Dahyun Kang, Heeseung Kwon, Juhong Min, Minsu Cho [paper], [project hompage] We propose t
 82 Dec 24, 2022
82 Dec 24, 2022

The source code of CVPR 2019 paper "Deep Exemplar-based Video Colorization".
Deep Exemplar-based Video Colorization (Pytorch Implementation) Paper | Pretrained Model | Youtube video 🔥 | Colab demo Deep Exemplar-based Video Col
 253 Dec 27, 2022
253 Dec 27, 2022
Implementation of a Transformer that Ponders, using the scheme from the PonderNet paper
Ponder(ing) Transformer Implementation of a Transformer that learns to adapt the number of computational steps it takes depending on the difficulty of
65 Oct 4, 2022

LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision Project | Arxiv | Abstract It is very challenging for various visual tasks such as image
 377 Jan 7, 2023
377 Jan 7, 2023

Code for our ALiBi method for transformer language models.
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation This repository contains the code and models for our paper Tra
 211 Dec 31, 2022
211 Dec 31, 2022

CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
 100 Dec 28, 2022
100 Dec 28, 2022

Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
167 Dec 27, 2022

SwinIR: Image Restoration Using Swin Transformer
SwinIR: Image Restoration Using Swin Transformer This repository is the official PyTorch implementation of SwinIR: Image Restoration Using Shifted Win
 2.4k Jan 8, 2023
2.4k Jan 8, 2023
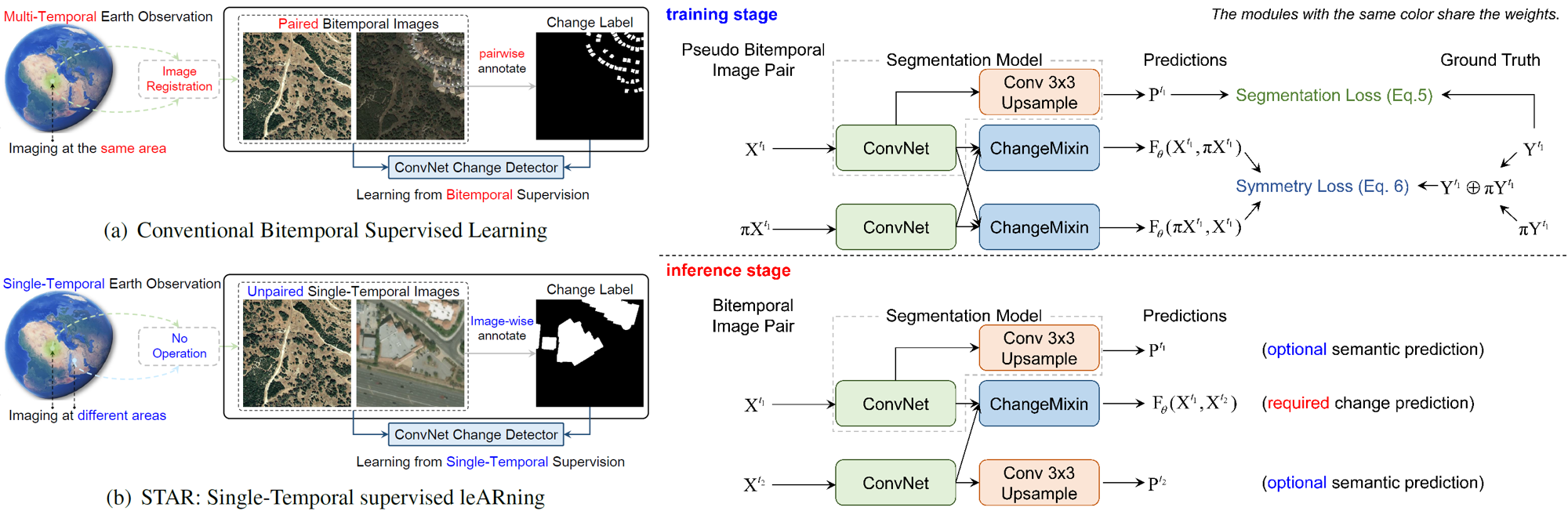
Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery (ICCV 2021)
Change is Everywhere Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery by Zhuo Zheng, Ailong Ma, Liangpei Zhang and Yanfei
125 Dec 13, 2022
CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
100 Dec 28, 2022

Robust Video Matting in PyTorch, TensorFlow, TensorFlow.js, ONNX, CoreML!
Robust Video Matting in PyTorch, TensorFlow, TensorFlow.js, ONNX, CoreML!
 6.5k Jan 4, 2023
6.5k Jan 4, 2023
Neural Message Passing for Computer Vision
Neural Message Passing for Quantum Chemistry Implementation of different models of Neural Networks on graphs as explained in the article proposed by G
 310 Nov 7, 2022
310 Nov 7, 2022

Many Class Activation Map methods implemented in Pytorch for CNNs and Vision Transformers. Including Grad-CAM, Grad-CAM++, Score-CAM, Ablation-CAM and XGrad-CAM
Class Activation Map methods implemented in Pytorch pip install grad-cam ⭐ Tested on many Common CNN Networks and Vision Transformers. ⭐ Includes smoo
 6.6k Jan 6, 2023
6.6k Jan 6, 2023
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 5, 2023
7.1k Jan 5, 2023
Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
167 Dec 27, 2022
Implementation of a Transformer that Ponders, using the scheme from the PonderNet paper
Ponder(ing) Transformer Implementation of a Transformer that learns to adapt the number of computational steps it takes depending on the difficulty of
65 Oct 4, 2022
Deep Unsupervised 3D SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment.
(ACMMM 2021 Oral) SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment This repository shows two tasks: Face landmark detection and Fac
51 Dec 13, 2022
rclip - AI-Powered Command-Line Photo Search Tool
rclip is a command-line photo search tool based on the awesome OpenAI's CLIP neural network.
 394 Dec 12, 2022
394 Dec 12, 2022
![[ICCV 2021 Oral] PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers](https://github.com/yuxumin/PoinTr/raw/master/fig/pointr.gif)
[ICCV 2021 Oral] PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers
PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers Created by Xumin Yu*, Yongming Rao*, Ziyi Wang, Zuyan Liu, Jiwen Lu, Jie Zhou
 317 Dec 26, 2022
317 Dec 26, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022

Official code for paper "Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight"
Demysitifing Local Vision Transformer, arxiv This is the official PyTorch implementation of our paper. We simply replace local self attention by (dyna
 138 Dec 28, 2022
138 Dec 28, 2022

Official code for "Focal Self-attention for Local-Global Interactions in Vision Transformers"
Focal Transformer This is the official implementation of our Focal Transformer -- "Focal Self-attention for Local-Global Interactions in Vision Transf
 486 Dec 20, 2022
486 Dec 20, 2022

Exploring Classification Equilibrium in Long-Tailed Object Detection, ICCV2021
Exploring Classification Equilibrium in Long-Tailed Object Detection (LOCE, ICCV 2021) Paper Introduction The conventional detectors tend to make imba
 52 Nov 21, 2022
52 Nov 21, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022

TOOD: Task-aligned One-stage Object Detection, ICCV2021 Oral
One-stage object detection is commonly implemented by optimizing two sub-tasks: object classification and localization, using heads with two parallel branches, which might lead to a certain level of spatial misalignment in predictions between the two tasks.
264 Jan 9, 2023
3D ResNets for Action Recognition (CVPR 2018)
3D ResNets for Action Recognition Update (2020/4/13) We published a paper on arXiv. Hirokatsu Kataoka, Tenga Wakamiya, Kensho Hara, and Yutaka Satoh,
 3.5k Jan 6, 2023
3.5k Jan 6, 2023

Transformer model implemented with Pytorch
transformer-pytorch Transformer model implemented with Pytorch Attention is all you need-[Paper] Architecture Self-Attention self_attention.py class
 12 Sep 3, 2022
12 Sep 3, 2022

Fog Simulation on Real LiDAR Point Clouds for 3D Object Detection in Adverse Weather
LiDAR fog simulation Created by Martin Hahner at the Computer Vision Lab of ETH Zurich. This is the official code release of the paper Fog Simulation
 110 Dec 30, 2022
110 Dec 30, 2022
QTool: A Low-bit Quantization Toolbox for Deep Neural Networks in Computer Vision
This project provides abundant choices of quantization strategies (such as the quantization algorithms, training schedules and empirical tricks) for quantizing the deep neural networks into low-bit counterparts.
 51 Dec 10, 2022
51 Dec 10, 2022
Extract knowledge from raw text
Extract knowledge from raw text This repository is a nearly copy-paste of "From Text to Knowledge: The Information Extraction Pipeline" with some cosm
 10 Dec 3, 2022
10 Dec 3, 2022

pix2tex: Using a ViT to convert images of equations into LaTeX code.
The goal of this project is to create a learning based system that takes an image of a math formula and returns corresponding LaTeX code.
 2.6k Dec 30, 2022
2.6k Dec 30, 2022

Official implementation of the ICCV 2021 paper "Conditional DETR for Fast Training Convergence".
The DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings and that the spatial embeddings make minor contributions, increasing the need for high-quality content embeddings and thus increasing the training difficulty.
281 Dec 30, 2022
The official code for paper "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Modeling".
R2D2 This is the official code for paper titled "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Mode
 49 Dec 17, 2022
49 Dec 17, 2022

Towards Interpretable Deep Metric Learning with Structural Matching
DIML Created by Wenliang Zhao*, Yongming Rao*, Ziyi Wang, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for paper Towards Interpr
 75 Nov 11, 2022
75 Nov 11, 2022

Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision. ICCV 2021.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision Download links and PyTorch implementation of "Towers of Ba
 40 Dec 14, 2022
40 Dec 14, 2022

This is an official implementation of the High-Resolution Transformer for Dense Prediction.
High-Resolution Transformer for Dense Prediction Introduction This is the official implementation of High-Resolution Transformer (HRT). We present a H
 403 Dec 13, 2022
403 Dec 13, 2022

Official PaddlePaddle implementation of Paint Transformer
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction [Paper] [Paddle Implementation] Update We have optimized the serial inference p
 284 Dec 31, 2022
284 Dec 31, 2022
An organized collection of tutorials and projects created for aspriring computer vision students.
A repository created with the purpose of teaching students in BME lab 308A- Hanoi University of Science and Technology
 5 Nov 24, 2021
5 Nov 24, 2021

In this project we investigate the performance of the SetCon model on realistic video footage. Therefore, we implemented the model in PyTorch and tested the model on two example videos.
Contrastive Learning of Object Representations Supervisor: Prof. Dr. Gemma Roig Institutions: Goethe University CVAI - Computational Vision & Artifici
 6 Dec 8, 2022
6 Dec 8, 2022
FastReID is a research platform that implements state-of-the-art re-identification algorithms.
FastReID is a research platform that implements state-of-the-art re-identification algorithms.
 2.8k Jan 7, 2023
2.8k Jan 7, 2023
Vision-Language Transformer and Query Generation for Referring Segmentation (ICCV 2021)
Vision-Language Transformer and Query Generation for Referring Segmentation Please consider citing our paper in your publications if the project helps
 143 Dec 23, 2022
143 Dec 23, 2022
LONG-TERM SERIES FORECASTING WITH QUERYSELECTOR – EFFICIENT MODEL OF SPARSEATTENTION
Query Selector Here you can find code and data loaders for the paper https://arxiv.org/pdf/2107.08687v1.pdf . Query Selector is a novel approach to sp
 62 Dec 17, 2022
62 Dec 17, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023

10th place solution for Google Smartphone Decimeter Challenge at kaggle.
Under refactoring 10th place solution for Google Smartphone Decimeter Challenge at kaggle. Google Smartphone Decimeter Challenge Global Navigation Sat
 12 Oct 25, 2022
12 Oct 25, 2022
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
4 Apr 6, 2022