2572 Repositories
Python vision-transformer-models Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Code and pre-trained models for MultiMAE: Multi-modal Multi-task Masked Autoencoders
MultiMAE: Multi-modal Multi-task Masked Autoencoders Roman Bachmann*, David Mizrahi*, Andrei Atanov, Amir Zamir Website | arXiv | BibTeX Official PyTo
 385 Jan 6, 2023
385 Jan 6, 2023

Temporally Efficient Vision Transformer for Video Instance Segmentation, CVPR 2022, Oral
Temporally Efficient Vision Transformer for Video Instance Segmentation Temporally Efficient Vision Transformer for Video Instance Segmentation (CVPR
 203 Dec 31, 2022
203 Dec 31, 2022

TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation, CVPR2022
TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation Paper Links: TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentati
253 Dec 21, 2022

"MST++: Multi-stage Spectral-wise Transformer for Efficient Spectral Reconstruction" (CVPRW 2022) & (Winner of NTIRE 2022 Challenge on Spectral Reconstruction from RGB)
MST++: Multi-stage Spectral-wise Transformer for Efficient Spectral Reconstruction (CVPRW 2022) Yuanhao Cai, Jing Lin, Zudi Lin, Haoqian Wang, Yulun Z
 274 Jan 5, 2023
274 Jan 5, 2023

Official code for our CVPR '22 paper "Dataset Distillation by Matching Training Trajectories"
Dataset Distillation by Matching Training Trajectories Project Page | Paper This repo contains code for training expert trajectories and distilling sy
 256 Jan 5, 2023
256 Jan 5, 2023

Official MegEngine implementation of CREStereo(CVPR 2022 Oral).
[CVPR 2022] Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation This repository contains MegEngine implementation of ou
 309 Dec 30, 2022
309 Dec 30, 2022

The official repo for OC-SORT: Observation-Centric SORT on video Multi-Object Tracking. OC-SORT is simple, online and robust to occlusion/non-linear motion.
OC-SORT Observation-Centric SORT (OC-SORT) is a pure motion-model-based multi-object tracker. It aims to improve tracking robustness in crowded scenes
 325 Jan 5, 2023
325 Jan 5, 2023

BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis
Bilateral Denoising Diffusion Models (BDDMs) This is the official PyTorch implementation of the following paper: BDDM: BILATERAL DENOISING DIFFUSION M
 172 Dec 23, 2022
172 Dec 23, 2022

CVPR2022 (Oral) - Rethinking Semantic Segmentation: A Prototype View
Rethinking Semantic Segmentation: A Prototype View Rethinking Semantic Segmentation: A Prototype View, Tianfei Zhou, Wenguan Wang, Ender Konukoglu and
 239 Dec 26, 2022
239 Dec 26, 2022
![[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427](https://github.com/jiawei-ren/BalancedMSE/raw/main/figures/intro.png)
[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427
Balanced MSE Code for the paper: Balanced MSE for Imbalanced Visual Regression Jiawei Ren, Mingyuan Zhang, Cunjun Yu, Ziwei Liu CVPR 2022 (Oral) News
 267 Jan 1, 2023
267 Jan 1, 2023

Stratified Transformer for 3D Point Cloud Segmentation (CVPR 2022)
Stratified Transformer for 3D Point Cloud Segmentation Xin Lai*, Jianhui Liu*, Li Jiang, Liwei Wang, Hengshuang Zhao, Shu Liu, Xiaojuan Qi, Jiaya Jia
 195 Jan 1, 2023
195 Jan 1, 2023

Official implementation for "Style Transformer for Image Inversion and Editing" (CVPR 2022)
Style Transformer for Image Inversion and Editing (CVPR2022) https://arxiv.org/abs/2203.07932 Existing GAN inversion methods fail to provide latent co
 153 Dec 2, 2022
153 Dec 2, 2022

Implementation of Deformable Attention in Pytorch from the paper "Vision Transformer with Deformable Attention"
Deformable Attention Implementation of Deformable Attention from this paper in Pytorch, which appears to be an improvement to what was proposed in DET
 128 Dec 24, 2022
128 Dec 24, 2022
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022

PyTorch implementation of U-TAE and PaPs for satellite image time series panoptic segmentation.
Panoptic Segmentation of Satellite Image Time Series with Convolutional Temporal Attention Networks (ICCV 2021) This repository is the official implem
 71 Jan 4, 2023
71 Jan 4, 2023
I will implement Fastai in each projects present in this repository.
DEEP LEARNING FOR CODERS WITH FASTAI AND PYTORCH The repository contains a list of the projects which I have worked on while reading the book Deep Lea
 43 Dec 20, 2022
43 Dec 20, 2022

Official repository accompanying a CVPR 2022 paper EMOCA: Emotion Driven Monocular Face Capture And Animation. EMOCA takes a single image of a face as input and produces a 3D reconstruction. EMOCA sets the new standard on reconstructing highly emotional images in-the-wild
EMOCA: Emotion Driven Monocular Face Capture and Animation Radek Daněček · Michael J. Black · Timo Bolkart CVPR 2022 This repository is the official i
 339 Dec 30, 2022
339 Dec 30, 2022

Cross-view Transformers for real-time Map-view Semantic Segmentation (CVPR 2022 Oral)
Cross View Transformers This repository contains the source code and data for our paper: Cross-view Transformers for real-time Map-view Semantic Segme
 363 Dec 25, 2022
363 Dec 25, 2022

Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds (CVPR 2022)
Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds (CVPR2022)[paper] Authors: Chenhang He, Ruihuang Li, Shuai Li, L
 141 Dec 30, 2022
141 Dec 30, 2022

Implementation of the Transformer variant proposed in "Transformer Quality in Linear Time"
FLASH - Pytorch Implementation of the Transformer variant proposed in the paper Transformer Quality in Linear Time Install $ pip install FLASH-pytorch
209 Dec 28, 2022

MAT: Mask-Aware Transformer for Large Hole Image Inpainting
MAT: Mask-Aware Transformer for Large Hole Image Inpainting (CVPR2022, Oral) Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, Jiaya Jia [Paper] News This
 254 Dec 29, 2022
254 Dec 29, 2022

Entity Disambiguation as text extraction (ACL 2022)
ExtEnD: Extractive Entity Disambiguation This repository contains the code of ExtEnD: Extractive Entity Disambiguation, a novel approach to Entity Dis
 121 Jan 3, 2023
121 Jan 3, 2023

Official source code of Fast Point Transformer, CVPR 2022
Fast Point Transformer Project Page | Paper This repository contains the official source code and data for our paper: Fast Point Transformer Chunghyun
 182 Dec 23, 2022
182 Dec 23, 2022

ACL'22: Structured Pruning Learns Compact and Accurate Models
☕ CoFiPruning: Structured Pruning Learns Compact and Accurate Models This repository contains the code and pruned models for our ACL'22 paper Structur
 130 Jan 4, 2023
130 Jan 4, 2023
![[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links](https://github.com/michiyasunaga/LinkBERT/raw/main/figs/overview.png)
[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links
LinkBERT: A Knowledgeable Language Model Pretrained with Document Links This repo provides the model, code & data of our paper: LinkBERT: Pretraining
 264 Jan 1, 2023
264 Jan 1, 2023

Generate images from texts. In Russian
ruDALL-E Generate images from texts pip install rudalle==1.1.0rc0 🤗 HF Models: ruDALL-E Malevich (XL) ruDALL-E Emojich (XL) (readme here) ruDALL-E S
 1.6k Dec 31, 2022
1.6k Dec 31, 2022

Lightning ⚡️ fast forecasting with statistical and econometric models.
Nixtla Statistical ⚡️ Forecast Lightning fast forecasting with statistical and econometric models StatsForecast offers a collection of widely used uni
 2.1k Dec 29, 2022
2.1k Dec 29, 2022

This repository contains the best Data Science free hand-picked resources to equip you with all the industry-driven skills and interview preparation kit.
Best Data Science Resources Hey, Data Enthusiasts out there! Finally, after lots of requests from the community I finally came up with the best free D
 415 Dec 31, 2022
415 Dec 31, 2022

The official implementation of Autoregressive Image Generation using Residual Quantization (CVPR '22)
Autoregressive Image Generation using Residual Quantization (CVPR 2022) The official implementation of "Autoregressive Image Generation using Residual
 529 Dec 30, 2022
529 Dec 30, 2022

RuDOLPH: One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP
[Paper] [Хабр] [Model Card] [Colab] [Kaggle] RuDOLPH 🦌 🎄 ☃️ One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP Russian Diffusio
232 Jan 4, 2023
HugsVision is a easy to use huggingface wrapper for state-of-the-art computer vision
HugsVision is an open-source and easy to use all-in-one huggingface wrapper for computer vision. The goal is to create a fast, flexible and user-frien
 166 Nov 27, 2022
166 Nov 27, 2022
🤗🖼️ HuggingPics: Fine-tune Vision Transformers for anything using images found on the web.
🤗 🖼️ HuggingPics Fine-tune Vision Transformers for anything using images found on the web. Check out the video below for a walkthrough of this proje
 185 Dec 21, 2022
185 Dec 21, 2022

🙌Kart of 210+ projects based on machine learning, deep learning, computer vision, natural language processing and all. Show your support by ✨ this repository.
ML-ProjectKart 📌 Repository This kart showcases the finest collection of all projects based on machine learning, deep learning, computer vision, natu
 203 Dec 28, 2022
203 Dec 28, 2022

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022
Official codebase used to develop Vision Transformer, MLP-Mixer, LiT and more.
Big Vision This codebase is designed for training large-scale vision models on Cloud TPU VMs. It is based on Jax/Flax libraries, and uses tf.data and
 701 Jan 3, 2023
701 Jan 3, 2023

BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training By Likun Cai, Zhi Zhang, Yi Zhu, Li Zhang, Mu Li, Xiangyang Xue. This
 290 Dec 29, 2022
290 Dec 29, 2022
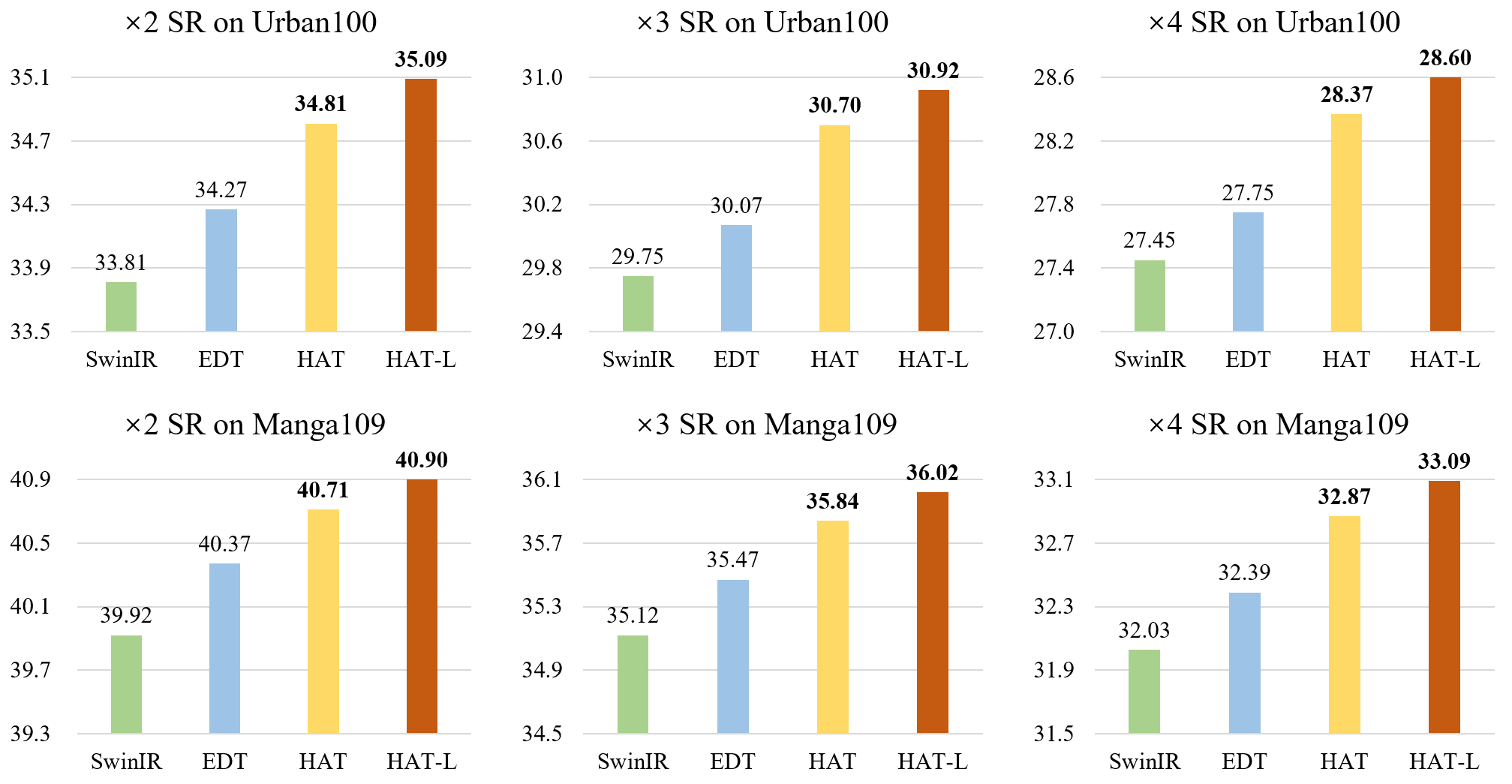
Activating More Pixels in Image Super-Resolution Transformer
HAT [Paper Link] Activating More Pixels in Image Super-Resolution Transformer Xiangyu Chen, Xintao Wang, Jiantao Zhou and Chao Dong BibTeX @article{ch
 270 Dec 27, 2022
270 Dec 27, 2022

Building a real-time environment using webcam frame division in OpenCV and classify cropped images using a fine-tuned vision transformers on hybryd datasets samples for facial emotion recognition.
Visual Transformer for Facial Emotion Recognition (FER) This project has the aim to build an efficient Visual Transformer for the Facial Emotion Recog
 8 Dec 12, 2022
8 Dec 12, 2022

Automatic number plate recognition using tech: Yolo, OCR, Scene text detection, scene text recognation, flask, torch
Automatic Number Plate Recognition Automatic Number Plate Recognition (ANPR) is the process of reading the characters on the plate with various optica
 52 Dec 22, 2022
52 Dec 22, 2022
An easy-to-use framework for BERT models, with trainers, various NLP tasks and detailed annonations
FantasyBert English | 中文 Introduction An easy-to-use framework for BERT models, with trainers, various NLP tasks and detailed annonations. You can imp
 137 Oct 26, 2022
137 Oct 26, 2022

RITA is a family of autoregressive protein models, developed by LightOn in collaboration with the OATML group at Oxford and the Debora Marks Lab at Harvard.
RITA: a Study on Scaling Up Generative Protein Sequence Models RITA is a family of autoregressive protein models, developed by a collaboration of Ligh
 69 Dec 22, 2022
69 Dec 22, 2022
Video Frame Interpolation with Transformer (CVPR2022)
VFIformer Official PyTorch implementation of our CVPR2022 paper Video Frame Interpolation with Transformer Dependencies python = 3.8 pytorch = 1.8.0
63 Dec 16, 2022
SurfEmb (CVPR 2022) - SurfEmb: Dense and Continuous Correspondence Distributions
SurfEmb SurfEmb: Dense and Continuous Correspondence Distributions for Object Pose Estimation with Learnt Surface Embeddings Rasmus Laurvig Haugard, A
 56 Nov 19, 2022
56 Nov 19, 2022

Adaptive FNO transformer - official Pytorch implementation
Adaptive Fourier Neural Operators: Efficient Token Mixers for Transformers This repository contains PyTorch implementation of the Adaptive Fourier Neu
 77 Dec 29, 2022
77 Dec 29, 2022

Official repository for the paper "Self-Supervised Models are Continual Learners" (CVPR 2022)
Self-Supervised Models are Continual Learners This is the official repository for the paper: Self-Supervised Models are Continual Learners Enrico Fini
 73 Dec 18, 2022
73 Dec 18, 2022

SeqTR: A Simple yet Universal Network for Visual Grounding
SeqTR This is the official implementation of SeqTR: A Simple yet Universal Network for Visual Grounding, which simplifies and unifies the modelling fo
 76 Dec 24, 2022
76 Dec 24, 2022

Code for "Neural 3D Scene Reconstruction with the Manhattan-world Assumption" CVPR 2022 Oral
News 05/10/2022 To make the comparison on ScanNet easier, we provide all quantitative and qualitative results of baselines here, including COLMAP, COL
 365 Dec 30, 2022
365 Dec 30, 2022
A Python library that enables ML teams to share, load, and transform data in a collaborative, flexible, and efficient way :chestnut:
Squirrel Core Share, load, and transform data in a collaborative, flexible, and efficient way What is Squirrel? Squirrel is a Python library that enab
 249 Dec 7, 2022
249 Dec 7, 2022

ConvMAE: Masked Convolution Meets Masked Autoencoders
ConvMAE ConvMAE: Masked Convolution Meets Masked Autoencoders Peng Gao1, Teli Ma1, Hongsheng Li2, Jifeng Dai3, Yu Qiao1, 1 Shanghai AI Laboratory, 2 M
 345 Jan 8, 2023
345 Jan 8, 2023

Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch
CoCa - Pytorch Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch. They were able to elegantly fit in contras
565 Dec 30, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023
Unified API to facilitate usage of pre-trained "perceptor" models, a la CLIP
mmc installation git clone https://github.com/dmarx/Multi-Modal-Comparators cd 'Multi-Modal-Comparators' pip install poetry poetry build pip install d
 37 Nov 25, 2022
37 Nov 25, 2022

Repo for "Benchmarking Robustness of 3D Point Cloud Recognition against Common Corruptions" https://arxiv.org/abs/2201.12296
Benchmarking Robustness of 3D Point Cloud Recognition against Common Corruptions This repo contains the dataset and code for the paper Benchmarking Ro
 168 Dec 29, 2022
168 Dec 29, 2022

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022

Implementation of ETSformer, state of the art time-series Transformer, in Pytorch
ETSformer - Pytorch Implementation of ETSformer, state of the art time-series Transformer, in Pytorch Install $ pip install etsformer-pytorch Usage im
121 Dec 30, 2022

code for TCL: Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022
Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022 News (03/16/2022) upload retrieval checkpoints finetuned on COCO and Flickr T
 187 Jan 2, 2023
187 Jan 2, 2023

Convert scikit-learn models to PyTorch modules
sk2torch sk2torch converts scikit-learn models into PyTorch modules that can be tuned with backpropagation and even compiled as TorchScript. Problems
 101 Dec 16, 2022
101 Dec 16, 2022

Developing and Comparing Vision-based Algorithms for Vision-based Agile Flight
DodgeDrone: Vision-based Agile Drone Flight (ICRA 2022 Competition) Would you like to push the boundaries of drone navigation? Then participate in the
 115 Dec 10, 2022
115 Dec 10, 2022
Interactive class notebooks for ECE4076 Computer Vision, weeks 1 - 6
ECE4076 Interactive class notebooks for ECE4076 Computer Vision, weeks 1 - 6. ECE4076 is a computer vision unit at Monash University, covering both cl
 9 Jun 16, 2022
9 Jun 16, 2022

SentimentArcs: a large ensemble of dozens of sentiment analysis models to analyze emotion in text over time
SentimentArcs - Emotion in Text An end-to-end pipeline based on Jupyter notebooks to detect, extract, process and anlayze emotion over time in text. E
 14 Dec 19, 2022
14 Dec 19, 2022

Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (CVPR2022)
Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding by Qiaole Dong*, Chenjie Cao*, Yanwei Fu Paper and Supple
 190 Dec 27, 2022
190 Dec 27, 2022

Instance-wise Occlusion and Depth Orders in Natural Scenes (CVPR 2022)
Instance-wise Occlusion and Depth Orders in Natural Scenes Official source code. Appears at CVPR 2022 This repository provides a new dataset, named In
27 Dec 27, 2022

Code for intrusion detection system (IDS) development using CNN models and transfer learning
Intrusion-Detection-System-Using-CNN-and-Transfer-Learning This is the code for the paper entitled "A Transfer Learning and Optimized CNN Based Intrus
 38 Dec 12, 2022
38 Dec 12, 2022

Implementation of CaiT models in TensorFlow and ImageNet-1k checkpoints. Includes code for inference and fine-tuning.
CaiT-TF (Going deeper with Image Transformers) This repository provides TensorFlow / Keras implementations of different CaiT [1] variants from Touvron
 9 Jun 26, 2022
9 Jun 26, 2022

The code for our paper submitted to RAL/IROS 2022: OverlapTransformer: An Efficient and Rotation-Invariant Transformer Network for LiDAR-Based Place Recognition.
OverlapTransformer The code for our paper submitted to RAL/IROS 2022: OverlapTransformer: An Efficient and Rotation-Invariant Transformer Network for
 136 Jan 3, 2023
136 Jan 3, 2023

Implementation of GeoDiff: a Geometric Diffusion Model for Molecular Conformation Generation (ICLR 2022).
GeoDiff: a Geometric Diffusion Model for Molecular Conformation Generation [OpenReview] [arXiv] [Code] The official implementation of GeoDiff: A Geome
 155 Dec 26, 2022
155 Dec 26, 2022

A Persian Image Captioning model based on Vision Encoder Decoder Models of the transformers🤗.
Persian-Image-Captioning We fine-tuning the Vision Encoder Decoder Model for the task of image captioning on the coco-flickr-farsi dataset. The implem
 15 Aug 25, 2022
15 Aug 25, 2022
An official repository for tutorials of Probabilistic Modelling and Reasoning (2021/2022) - a University of Edinburgh master's course.
PMR computer tutorials on HMMs (2021-2022) This is a repository for computer tutorials of Probabilistic Modelling and Reasoning (2021/2022) - a Univer
 10 Dec 6, 2022
10 Dec 6, 2022
![[CVPR 2022] TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing](https://github.com/BillyXYB/TransEditor/raw/main/resources/teaser_change_order.png)
[CVPR 2022] TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing
TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing (CVPR 2022) This repository provides the official PyTorch impleme
 128 Jan 3, 2023
128 Jan 3, 2023

As-ViT: Auto-scaling Vision Transformers without Training
As-ViT: Auto-scaling Vision Transformers without Training [PDF] Wuyang Chen, Wei Huang, Xianzhi Du, Xiaodan Song, Zhangyang Wang, Denny Zhou In ICLR 2
 68 Sep 5, 2022
68 Sep 5, 2022

PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI
data2vec-pytorch PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI (F
 105 Jan 4, 2023
105 Jan 4, 2023

Guide to using pre-trained large language models of source code
Large Models of Source Code I occasionally train and publicly release large neural language models on programs, including PolyCoder. Here, I describe
 947 Dec 28, 2022
947 Dec 28, 2022

QuadTree Attention for Vision Transformers (ICLR2022)
This repository contains codes for quadtree attention. This repo contains codes for feature matching, image classficiation, object detection and seman
 222 Dec 28, 2022
222 Dec 28, 2022

(CVPR 2022) Pytorch implementation of "Self-supervised transformers for unsupervised object discovery using normalized cut"
(CVPR 2022) TokenCut Pytorch implementation of Tokencut: Self-supervised Transformers for Unsupervised Object Discovery using Normalized Cut Yangtao W
 200 Jan 2, 2023
200 Jan 2, 2023
AI Summer's complete catalog of articles
Learn Deep Learning with AI Summer A collection of all articles (almost 100) written for the AI Summer blog organized by topic. Deep Learning Theory M
 95 Dec 29, 2022
95 Dec 29, 2022

CLIP (Contrastive Language–Image Pre-training) for Italian
Italian CLIP CLIP (Radford et al., 2021) is a multimodal model that can learn to represent images and text jointly in the same space. In this project,
 114 Dec 29, 2022
114 Dec 29, 2022
ICON: Implicit Clothed humans Obtained from Normals (CVPR 2022)
ICON: Implicit Clothed humans Obtained from Normals Yuliang Xiu · Jinlong Yang · Dimitrios Tzionas · Michael J. Black CVPR 2022 News 🚩 [2022/04/26] H
 1.1k Jan 4, 2023
1.1k Jan 4, 2023

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023
Official code for the CVPR 2022 (oral) paper "Extracting Triangular 3D Models, Materials, and Lighting From Images".
nvdiffrec Joint optimization of topology, materials and lighting from multi-view image observations as described in the paper Extracting Triangular 3D
1.4k Jan 1, 2023
KoCLIP: Korean port of OpenAI CLIP, in Flax
KoCLIP This repository contains code for KoCLIP, a Korean port of OpenAI's CLIP. This project was conducted as part of Hugging Face's Flax/JAX communi
 100 Jan 2, 2023
100 Jan 2, 2023
Includes PyTorch - Keras model porting code for ConvNeXt family of models with fine-tuning and inference notebooks.
ConvNeXt-TF This repository provides TensorFlow / Keras implementations of different ConvNeXt [1] variants. It also provides the TensorFlow / Keras mo
87 Dec 6, 2022
An ever-growing playground of notebooks showcasing CLIP's impressive zero-shot capabilities.
Playground for CLIP-like models Demo Colab Link GradCAM Visualization Naive Zero-shot Detection Smarter Zero-shot Detection Captcha Solver Changelog 2
 101 Dec 30, 2022
101 Dec 30, 2022

This is a pytorch implementation for the BST model from Alibaba https://arxiv.org/pdf/1905.06874.pdf
Behavior-Sequence-Transformer-Pytorch This is a pytorch implementation for the BST model from Alibaba https://arxiv.org/pdf/1905.06874.pdf This model
 83 Jan 5, 2023
83 Jan 5, 2023
Course about deep learning for computer vision and graphics co-developed by YSDA and Skoltech.
Deep Vision and Graphics This repo supplements course "Deep Vision and Graphics" taught at YSDA @fall'21. The course is the successor of "Deep Learnin
 160 Jan 2, 2023
160 Jan 2, 2023

In this tutorial, you will perform inference across 10 well-known pre-trained object detectors and fine-tune on a custom dataset. Design and train your own object detector.
Object Detection Object detection is a computer vision task for locating instances of predefined objects in images or videos. In this tutorial, you wi
 62 Dec 25, 2022
62 Dec 25, 2022
PyTorch implementation of Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy
Anomaly Transformer in PyTorch This is an implementation of Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy. This pape
 160 Dec 19, 2022
160 Dec 19, 2022

A collection of educational notebooks on multi-view geometry and computer vision.
Multiview notebooks This is a collection of educational notebooks on multi-view geometry and computer vision. Subjects covered in these notebooks incl
 65 Dec 9, 2022
65 Dec 9, 2022

Code for Ditto: Building Digital Twins of Articulated Objects from Interaction
Ditto: Building Digital Twins of Articulated Objects from Interaction Zhenyu Jiang, Cheng-Chun Hsu, Yuke Zhu CVPR 2022, Oral Project | arxiv News 2022
 78 Dec 22, 2022
78 Dec 22, 2022
Ego4d dataset repository. Download the dataset, visualize, extract features & example usage of the dataset
Ego4D EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated v
 118 Jan 7, 2023
118 Jan 7, 2023
Repo for the Tutorials of Day1-Day3 of the Nordic Probabilistic AI School 2021 (https://probabilistic.ai/)
ProbAI 2021 - Probabilistic Programming and Variational Inference Tutorial with Pryo Day 1 (June 14) Slides Notebook: students_PPLs_Intro Notebook: so
 46 Nov 1, 2022
46 Nov 1, 2022

Fast SHAP value computation for interpreting tree-based models
FastTreeSHAP FastTreeSHAP package is built based on the paper Fast TreeSHAP: Accelerating SHAP Value Computation for Trees published in NeurIPS 2021 X
 369 Jan 4, 2023
369 Jan 4, 2023

Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology (LMRL Workshop, NeurIPS 2021)
Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology Self-Supervised Vision Transformers Learn Visual Concepts in Histopatholog
 95 Dec 24, 2022
95 Dec 24, 2022
.png)
Contextual Attention Network: Transformer Meets U-Net
Contextual Attention Network: Transformer Meets U-Net Contexual attention network for medical image segmentation with state of the art results on skin
 67 Nov 28, 2022
67 Nov 28, 2022
Package towards building Explainable Forecasting and Nowcasting Models with State-of-the-art Deep Neural Networks and Dynamic Factor Model on Time Series data sets with single line of code. Also, provides utilify facility for time-series signal similarities matching, and removing noise from timeseries signals.
DeepXF: Explainable Forecasting and Nowcasting with State-of-the-art Deep Neural Networks and Dynamic Factor Model Also, verify TS signal similarities
 88 Dec 27, 2022
88 Dec 27, 2022

🚀 RocketQA, dense retrieval for information retrieval and question answering, including both Chinese and English state-of-the-art models.
In recent years, the dense retrievers based on pre-trained language models have achieved remarkable progress. To facilitate more developers using cutt
 475 Jan 4, 2023
475 Jan 4, 2023
SciFive: a text-text transformer model for biomedical literature
SciFive SciFive provided a Text-Text framework for biomedical language and natural language in NLP. Under the T5's framework and desrbibed in the pape
 54 Dec 24, 2022
54 Dec 24, 2022

GARCH and Multivariate LSTM forecasting models for Bitcoin realized volatility with potential applications in crypto options trading, hedging, portfolio management, and risk management
Bitcoin Realized Volatility Forecasting with GARCH and Multivariate LSTM Author: Chi Bui This Repository Repository Directory ├── README.md
 113 Dec 29, 2022
113 Dec 29, 2022
TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
TorchMultimodal (Alpha Release) Introduction TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
663 Jan 6, 2023
![[CVPR 2022] Pytorch implementation of](https://github.com/nv-nguyen/template-pose/raw/main/figures/method.png)
[CVPR 2022] Pytorch implementation of "Templates for 3D Object Pose Estimation Revisited: Generalization to New objects and Robustness to Occlusions" paper
template-pose Pytorch implementation of "Templates for 3D Object Pose Estimation Revisited: Generalization to New objects and Robustness to Occlusions
 92 Dec 28, 2022
92 Dec 28, 2022