535 Repositories
Python audio-features Libraries
Ridogram is an advanced multi-featured Telegram UserBot.
Ridogram Ridogram is an advanced multi-featured Telegram UserBot. String Session Collect String Session by running python3 stringsession.py locally or
 102 May 26, 2022
102 May 26, 2022

Seaborn is one of the go-to tools for statistical data visualization in python. It has been actively developed since 2012 and in July 2018, the author released version 0.9. This version of Seaborn has several new plotting features, API changes and documentation updates which combine to enhance an already great library. This article will walk through a few of the highlights and show how to use the new scatter and line plot functions for quickly creating very useful visualizations of data.
12_Python_Seaborn_Module Introduction 👋 From the website, “Seaborn is a Python data visualization library based on matplotlib. It provides a high-lev
 192 Dec 16, 2022
192 Dec 16, 2022

Dataset and baseline code for the VocalSound dataset (ICASSP2022).
VocalSound: A Dataset for Improving Human Vocal Sounds Recognition Introduction Citing Download VocalSound Dataset Details Baseline Experiment Contact
 58 Jan 3, 2023
58 Jan 3, 2023
StorSeismic: An approach to pre-train a neural network to store seismic data features
StorSeismic: An approach to pre-train a neural network to store seismic data features This repository contains codes and resources to reproduce experi
 11 Dec 5, 2022
11 Dec 5, 2022

A lightweight yet powerful audio-to-MIDI converter with pitch bend detection
Basic Pitch is a Python library for Automatic Music Transcription (AMT), using lightweight neural network developed by Spotify's Audio Intelligence La
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022
Ridogram is an advanced multi-featured Telegram UserBot.
Ridogram Ridogram is an advanced multi-featured Telegram UserBot. String Session Collect String Session by running python3 stringsession.py locally or
134 Dec 29, 2022
Unsupervised phone and word segmentation using dynamic programming on self-supervised VQ features.
Unsupervised Phone and Word Segmentation using Vector-Quantized Neural Networks Overview Unsupervised phone and word segmentation on speech data is pe
 13 Dec 11, 2022
13 Dec 11, 2022
Telegram Group Calls Streaming bot with some useful features, written in Python with Pyrogram and Py-Tgcalls. Supporting platforms like Youtube, Spotify, Resso, AppleMusic, Soundcloud and M3u8 Links.
Yukki Music Bot Yukki Music Bot is a Powerful Telegram Music+Video Bot written in Python using Pyrogram and Py-Tgcalls by which you can stream songs,
 996 Dec 28, 2022
996 Dec 28, 2022
HF's ML for Audio study group
Hugging Face Machine Learning for Audio Study Group Welcome to the ML for Audio Study Group. Through a series of presentations, paper reading and disc
 110 Jan 1, 2023
110 Jan 1, 2023
A Traffic Sign Recognition Project which can help the driver recognise the signs via text as well as audio. Can be used at Night also.
Traffic-Sign-Recognition In this report, we propose a Convolutional Neural Network(CNN) for traffic sign classification that achieves outstanding perf
 64 Nov 19, 2022
64 Nov 19, 2022

Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
 732 Jan 8, 2023
732 Jan 8, 2023
Ego4d dataset repository. Download the dataset, visualize, extract features & example usage of the dataset
Ego4D EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated v
 118 Jan 7, 2023
118 Jan 7, 2023

Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
RAVE: Realtime Audio Variational autoEncoder Official implementation of RAVE: A variational autoencoder for fast and high-quality neural audio synthes
 587 Jan 1, 2023
587 Jan 1, 2023

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
87 Dec 21, 2022

Official page of Struct-MDC (RA-L'22 with IROS'22 option); Depth completion from Visual-SLAM using point & line features
Struct-MDC (click the above buttons for redirection!) Official page of "Struct-MDC: Mesh-Refined Unsupervised Depth Completion Leveraging Structural R
 37 Dec 22, 2022
37 Dec 22, 2022
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
Classification models 1D Zoo - Keras and TF.Keras
Classification models 1D Zoo - Keras and TF.Keras This repository contains 1D variants of popular CNN models for classification like ResNets, DenseNet
 12 Jan 6, 2023
12 Jan 6, 2023
A Open source Discord Token Grabber with several very useful features coded in python 3.9
Kiwee-Grabber A Open source Discord Token Grabber with several very useful features coded in python 3.9 This only works on any python 3.9 versions. re
 40 Jan 1, 2023
40 Jan 1, 2023

YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Created using Python, PyTube and PySimpleGUI.
YouTube Downloader YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Disclaimer It's
 3 Dec 14, 2022
3 Dec 14, 2022

Audio-analytics for music-producers! Automate tedious tasks such as musical scale detection, BPM rate classification and audio file conversion.
Click here to be re-directed to the Beat Inspect Streamlit Web-App You are a music producer? Let's get in touch via LinkedIn Fundamental Analytics for
 11 Dec 27, 2022
11 Dec 27, 2022
PyTorch Implementation of "Bridging Pre-trained Language Models and Hand-crafted Features for Unsupervised POS Tagging" (Findings of ACL 2022)
Feature_CRF_AE Feature_CRF_AE provides a implementation of Bridging Pre-trained Language Models and Hand-crafted Features for Unsupervised POS Tagging
 6 Apr 29, 2022
6 Apr 29, 2022
Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution.
convolver Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution. Created by Sean Higley [email protected]
 1 Feb 23, 2022
1 Feb 23, 2022
Code for One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022) Paper | Demo Requirements Python = 3.6 , Pytorch
 84 Jan 3, 2023
84 Jan 3, 2023

Adversarial-Information-Bottleneck - Distilling Robust and Non-Robust Features in Adversarial Examples by Information Bottleneck (NeurIPS21)
NeurIPS 2021 Title: Distilling Robust and Non-Robust Features in Adversarial Exa
 35 Dec 26, 2022
35 Dec 26, 2022
A simple chatbot based on chatterbot that you can use for anything has basic features
Chatbotium A simple chatbot based on chatterbot that you can use for anything has basic features. I have some errors Read the paragraph below: Known b
 1 Feb 16, 2022
1 Feb 16, 2022

SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation In this repo you can find the code of the Supervised Hybrid Audio Segmentatio
 21 Dec 20, 2022
21 Dec 20, 2022
Convert PDF to AudioBook and Audio Speech to PDF
In this Python project, we will build a GUI-based PDF to Audio and Audio to PDF converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, PyPDF4, and Pydub libraries and the messagebox module of the Tkinter library.
 1 Feb 13, 2022
1 Feb 13, 2022

Learning Features with Parameter-Free Layers, ICLR 2022
Learning Features with Parameter-Free Layers (ICLR 2022) Dongyoon Han, YoungJoon Yoo, Beomyoung Kim, Byeongho Heo | Paper NAVER AI Lab, NAVER CLOVA Up
 41 Feb 11, 2022
41 Feb 11, 2022
Learning Features with Parameter-Free Layers (ICLR 2022)
Learning Features with Parameter-Free Layers (ICLR 2022) Dongyoon Han, YoungJoon Yoo, Beomyoung Kim, Byeongho Heo | Paper NAVER AI Lab, NAVER CLOVA Up
65 Dec 7, 2022

To build a regression model to predict the concrete compressive strength based on the different features in the training data.
Cement-Strength-Prediction Problem Statement To build a regression model to predict the concrete compressive strength based on the different features
 4 Jun 11, 2022
4 Jun 11, 2022
An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright.
Playwright nonoCAPTCHA An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright. Disclaimer This project is for educational
 69 Dec 28, 2022
69 Dec 28, 2022

TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
TONet Introduction The official implementation of "TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music", in ICASSP 2022 We
 29 Dec 1, 2022
29 Dec 1, 2022
PyTorch implementation of the paper: Label Noise Transition Matrix Estimation for Tasks with Lower-Quality Features
Label Noise Transition Matrix Estimation for Tasks with Lower-Quality Features Estimate the noise transition matrix with f-mutual information. This co
 1 Jun 5, 2022
1 Jun 5, 2022
Finding Biological Plausibility for Adversarially Robust Features via Metameric Tasks
Adversarially-Robust-Periphery Code + Data from the paper "Finding Biological Plausibility for Adversarially Robust Features via Metameric Tasks" by A
 2 Feb 7, 2022
2 Feb 7, 2022

Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
13 Feb 8, 2022
To classify the News into Real/Fake using Features from the Text Content of the article
Hoax-Detector Authenticity of news has now become a major problem. The Idea is to classify the News into Real/Fake using Features from the Text Conten
 1 Feb 9, 2022
1 Feb 9, 2022
Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 50 Nov 12, 2022
50 Nov 12, 2022
This code is the implementation of Text Emotion Recognition (TER) with linguistic features
APSIPA-TER This code is the implementation of Text Emotion Recognition (TER) with linguistic features. The network model is BERT with a pretrained mod
 1 Feb 8, 2022
1 Feb 8, 2022
This is a survey of python's async concurrency features by example.
Survey of Python's Async Features This is a survey of python's async concurrency features by example. The purpose of this survey is to demonstrate tha
 4 Feb 10, 2022
4 Feb 10, 2022

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022

Face recognition project by matching the features extracted using SIFT.
MV_FaceDetectionWithSIFT Face recognition project by matching the features extracted using SIFT. By : Aria Radmehr Professor : Ali Amiri Dependencies
 4 May 31, 2022
4 May 31, 2022
SAAVN - Sound Adversarial Audio-Visual Navigation,ICLR2022 (In PyTorch)
SAAVN SAAVN Code release for paper "Sound Adversarial Audio-Visual Navigation,IC
 10 Aug 30, 2022
10 Aug 30, 2022
YoutubeDownloader - Repo for downloading YT audio and videos
YoutubeDownloader Downloads video/playlist/audio from youtube url. install all t
 2 Feb 17, 2022
2 Feb 17, 2022
The official code repo of "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
134 Jan 1, 2023
Learning Super-Features for Image Retrieval
Learning Super-Features for Image Retrieval This repository contains the code for running our FIRe model presented in our ICLR'22 paper: @inproceeding
 101 Dec 28, 2022
101 Dec 28, 2022
An experimental script to perform bulk parsing of arbitrary file features with YARA and console logging.
RonnieColemanYARAParser This script is named after Ronnie Coleman, and peforms bulk lifts on arbitary file features using YARA console logging. Requir
 20 Dec 13, 2022
20 Dec 13, 2022
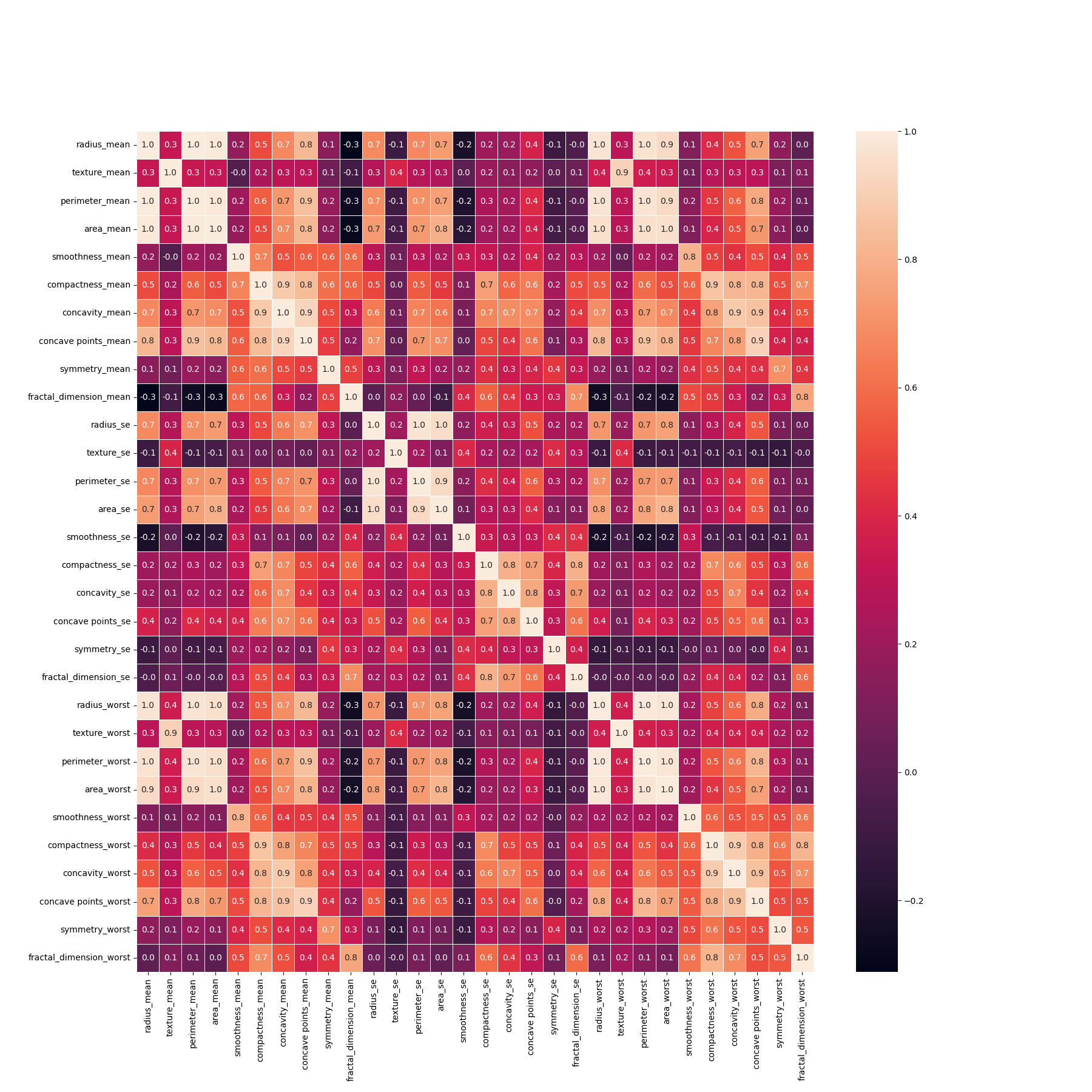
Breast-Cancer-Classification - Using SKLearn breast cancer dataset which contains 569 examples and 32 features classifying has been made with 6 different algorithms
Breast-Cancer-Classification - Using SKLearn breast cancer dataset which contains 569 examples and 32 features classifying has been made with 6 different algorithms
 1 Jan 31, 2022
1 Jan 31, 2022

Deep ViT Features as Dense Visual Descriptors
dino-vit-features [paper] [project page] Official implementation of the paper "Deep ViT Features as Dense Visual Descriptors". We demonstrate the effe
 113 Dec 24, 2022
113 Dec 24, 2022
Audio Retrieval with Natural Language Queries: A Benchmark Study
Audio Retrieval with Natural Language Queries: A Benchmark Study Paper | Project page | Text-to-audio search demo This repository is the implementatio
 21 Oct 31, 2022
21 Oct 31, 2022
This is the source code for the experiments related to the paper Unsupervised Audio Source Separation Using Differentiable Parametric Source Models
Unsupervised Audio Source Separation Using Differentiable Parametric Source Models This is the source code for the experiments related to the paper Un
 30 Oct 19, 2022
30 Oct 19, 2022
Implementation for "Conditional entropy minimization principle for learning domain invariant representation features"
Implementation for "Conditional entropy minimization principle for learning domain invariant representation features". The code is reproduced from thi
 1 Nov 2, 2022
1 Nov 2, 2022

Hyperparameters tuning and features selection are two common steps in every machine learning pipeline.
shap-hypetune A python package for simultaneous Hyperparameters Tuning and Features Selection for Gradient Boosting Models. Overview Hyperparameters t
 422 Jan 8, 2023
422 Jan 8, 2023

Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources
Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources (e.g. just the lead vocals).
 14 Nov 7, 2022
14 Nov 7, 2022
An NVDA add-on to split screen reader and audio from other programs to different sound channels
An NVDA add-on to split screen reader and audio from other programs to different sound channels (add-on idea credit: Tony Malykh)
 7 Dec 25, 2022
7 Dec 25, 2022
Savecontentbot - Telegram Save Content Bot With Same more Features
Save Restricted Content Bot A simple telegram bot to save restricted content wit
 3 Jan 26, 2022
3 Jan 26, 2022
PyTorch source code for Distilling Knowledge by Mimicking Features
LSHFM.detection This is the PyTorch source code for Distilling Knowledge by Mimicking Features. And this project contains code for object detection wi
 4 Dec 17, 2022
4 Dec 17, 2022
Allows you to email people wordle spoilers. Very beta, not as many features
wordlespoiler Allows you to email people wordle spoilers. Very beta, not as many features How to Use 1.) Make a new gmail account. Go to settings (Man
 0 Jan 4, 2023
0 Jan 4, 2023
Repository features UNet inspired architecture used for segmenting lungs on chest X-Ray images
Lung Segmentation (2D) Repository features UNet inspired architecture used for segmenting lungs on chest X-Ray images. Demo See the application of the
 163 Sep 21, 2022
163 Sep 21, 2022
Static Features Classifier - A static features classifier for Point-Could clusters using an Attention-RNN model
Static Features Classifier This is a static features classifier for Point-Could
 1 Jan 25, 2022
1 Jan 25, 2022
The purpose is to have a fairly simple python assignment that introduces the basic features and tools of python
This repository contains the code for the python introduction lab. The purpose is to have a fairly simple python assignment that introduces the basic
 1 Jan 24, 2022
1 Jan 24, 2022
A tool for retrieving audio in the past
Rewinder A tool for retrieving audio in the past. Ever felt like, I need to remember that discussion which happened 10 min back. Now you can! Rewind a
 1 Jan 24, 2022
1 Jan 24, 2022
A Telegram Bot with(Forwarder Bot + User Bot + More Features )
A Telegram Bot with(Forwarder Bot + User Bot + More Features )
 3 Feb 16, 2022
3 Feb 16, 2022

Cylinder volume calculator features the calculations of the volume of a Right /oblique full cylinder
Cylinder-Volume-Calculator Cylinder volume calculator features the calculations of the volume of a Right /oblique full cylinder. Size : 10.5 mb compat
 4 Nov 7, 2022
4 Nov 7, 2022
Telegram Url Upload Bot With Same more Features ✨
Telegram Url Upload Bot With Same more Features ✨
4 Feb 12, 2022
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features | paper | Official PyTorch implementation for Mul
 48 Dec 28, 2022
48 Dec 28, 2022

Autofilterv5 With Same more Features
Autofilterv5 With Same more Features ✨ Imbd + Index +.....
 8 Oct 21, 2022
8 Oct 21, 2022
This is an analysis and prediction project for house prices in King County, USA based on certain features of the house
This is a project for analysis and estimation of House Prices in King County USA The .csv file contains the data of the house and the .ipynb file con
 1 Jan 21, 2022
1 Jan 21, 2022
JSONx - Easy JSON wrapper packed with features.
🈷️ JSONx Easy JSON wrapper packed with features. This was made for small discord bots, for big bots you should not use this JSON wrapper. 📥 Usage Cl
 2 Dec 25, 2022
2 Dec 25, 2022

Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution
Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution Figure: Example visualization of the method and baseline as a
 16 Dec 23, 2022
16 Dec 23, 2022

Audio2Face - Audio To Face With Python
Audio2Face Discription We create a project that transforms audio to blendshape w
724 Dec 26, 2022
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning My
 3 Apr 10, 2022
3 Apr 10, 2022
ChaozzDBPy - A python implementation based on the original ChaozzDB from Chaozznl with some new features
ChaozzDBPy About ChaozzDBPy is a python implementation based on the original Cha
 1 May 25, 2022
1 May 25, 2022
TikTok - TikTok Bot to download video or audio from TikTok
TikTok - TikTok Bot to download video or audio from TikTok
 51 Mar 4, 2022
51 Mar 4, 2022
A2DP agent for promiscuous/permissive audio sinc.
Promiscuous Bluetooth audio sinc A2DP agent for promiscuous/permissive audio sinc for Linux. Once installed, a Bluetooth client, such as a smart phone
 4 May 27, 2022
4 May 27, 2022

Animal Sound Classification (Cats Vrs Dogs Audio Sentiment Classification)
this is a simple artificial neural network model using deep learning and torch-audio to classify cats and dog sounds.
 3 Dec 5, 2022
3 Dec 5, 2022

This is just a funny project that we want to see AutoEncoder (AE) can actually work to enhance the features we want
Funny_muscle_enhancer :) 1.Discription: This is just a funny project that we want to see AutoEncoder (AE) can actually work on the some features. We w
 8 Oct 1, 2022
8 Oct 1, 2022

Terminal-based music player written in Python for the best music in the world 🎵 🎧 💻
audius-terminal-player Terminal-based music player written in Python for the best music in the world 🎵 🎧 💻 Browse and listen to Audius from the com
 21 Jul 23, 2022
21 Jul 23, 2022
Public release of Telepathy, an OSINT toolkit for investigating Telegram groups. Enhanced features and improvements will be added over time.
Telepathy Welcome to Telepathy, an OSINT toolkit for scraping Telegram data to help investigate shady goings on. Currently, the tool is limited to scr
 484 Jan 1, 2023
484 Jan 1, 2023
Kanata Bot - a modular bot running on python3 with anime theme and have a lot features
Kanata Bot Kanata Bot is a modular bot running on python3 with anime theme and have a lot features. Easiest Way To Deploy On Heroku This Bot is Create
 2 Jan 16, 2022
2 Jan 16, 2022
InfiniPy has some neat features - like the endpoint for function
InfiniPy has some neat features - like the endpoint for function
 7 Nov 20, 2022
7 Nov 20, 2022

Using the provided dataset which includes various book features, in order to predict the price of books, using various proposed methods and models.
Using the provided dataset which includes various book features, in order to predict the price of books, using various proposed methods and models.
 1 Jan 13, 2022
1 Jan 13, 2022
Fully Automated YouTube Channel ▶️with Added Extra Features.
Fully Automated Youtube Channel ▒█▀▀█ █▀▀█ ▀▀█▀▀ ▀▀█▀▀ █░░█ █▀▀▄ █▀▀ █▀▀█ ▒█▀▀▄ █░░█ ░░█░░ ░▒█░░ █░░█ █▀▀▄ █▀▀ █▄▄▀ ▒█▄▄█ ▀▀▀▀ ░░▀░░ ░▒█░░ ░▀▀▀ ▀▀▀░
 249 Jan 2, 2023
249 Jan 2, 2023

ELSED: Enhanced Line SEgment Drawing
ELSED: Enhanced Line SEgment Drawing This repository contains the source code of ELSED: Enhanced Line SEgment Drawing the fastest line segment detecto
 125 Dec 31, 2022
125 Dec 31, 2022
API Server for VoIP analysis (CDR + Audio CODECs)
Swagger generated server Overview This server was generated by the swagger-codegen project. By using the OpenAPI-Spec from a remote server, you can ea
 1 Jan 11, 2022
1 Jan 11, 2022
A wrapper around ffmpeg to make it work in a concurrent and memory-buffered fashion.
Media Fixer Have you ever had a film or TV show that your TV wasn't able to play its audio? Well this program is for you. Media Fixer is a program whi
 3 May 4, 2022
3 May 4, 2022
Plone Interface contracts, plus basic features and utilities
plone.base This package is the base package of the CMS Plone https://plone.org. It contains only interface contracts and basic features and utilitie
 1 Oct 3, 2022
1 Oct 3, 2022
A Python package for time series augmentation
tsaug tsaug is a Python package for time series augmentation. It offers a set of augmentation methods for time series, as well as a simple API to conn
 278 Jan 1, 2023
278 Jan 1, 2023
An intuitive library to extract features from time series
Time Series Feature Extraction Library Intuitive time series feature extraction This repository hosts the TSFEL - Time Series Feature Extraction Libra
 589 Jan 4, 2023
589 Jan 4, 2023
This is Minesweeper coded in Python. It has almost all features from the main game
Minesweeper This is Minesweeper coded in Python. It has almost all features from the main game Use right click to open tile, right click on an open ti
 3 Jul 12, 2022
3 Jul 12, 2022
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi.
Spchcat Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that read
 279 Jan 3, 2023
279 Jan 3, 2023

A self-supervised learning framework for audio-visual speech
AV-HuBERT (Audio-Visual Hidden Unit BERT) Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction Robust Self-Supervised A
431 Jan 7, 2023
a web-remote minecraft server wrapper with some unique features
Canceled here, continued as Semoxy MCWeb - a Minecraft Server Web Interface MCWeb is a web-remote Minecraft Server Wrapper for controlling your Minecr
 1 Jul 12, 2021
1 Jul 12, 2021
An Anime Theme Telegram group management bot. With lot of features.
Emilia Project Emilia-Prjkt is a modular bot running on python3 with anime theme and have a lot features. Easiest Way To Deploy On Heroku This Bot is
 3 Feb 3, 2022
3 Feb 3, 2022
I was sick of having to hand my friends my phone, so I gave my Spotify some SMS features!
SMSpotifY Just a little tool so that my friends can text a phone number and add to my spotify queue for parties and such:) Features Roles / Access Con
 2 Jan 17, 2022
2 Jan 17, 2022
BART aids transcribe tasks by taking a source audio file and creating automatic repeated loops, allowing transcribers to listen to fragments multiple times
BART (Beyond Audio Replay Technology) aids transcribe tasks by taking a source audio file and creating automatic repeated loops, allowing transcribers to listen to fragments multiple times (with possible overlap between segments).
 2 Feb 4, 2022
2 Feb 4, 2022

Attention-based Transformation from Latent Features to Point Clouds (AAAI 2022)
Attention-based Transformation from Latent Features to Point Clouds This repository contains a PyTorch implementation of the paper: Attention-based Tr
 12 Nov 11, 2022
12 Nov 11, 2022

Vehicle detection using machine learning and computer vision techniques for Udacity's Self-Driving Car Engineer Nanodegree.
Vehicle Detection Video demo Overview Vehicle detection using these machine learning and computer vision techniques. Linear SVM HOG(Histogram of Orien
 1.1k Dec 18, 2022
1.1k Dec 18, 2022

Automagically synchronize subtitles with video.
FFsubsync Language-agnostic automatic synchronization of subtitles with video, so that subtitles are aligned to the correct starting point within the
 5.7k Jan 6, 2023
5.7k Jan 6, 2023
Code for the paper "Jukebox: A Generative Model for Music"
Status: Archive (code is provided as-is, no updates expected) Jukebox Code for "Jukebox: A Generative Model for Music" Paper Blog Explorer Colab Insta
 6k Jan 2, 2023
6k Jan 2, 2023