535 Repositories
Python audio-features Libraries
![[CVPR 2021] Generative Hierarchical Features from Synthesizing Images](https://github.com/genforce/ghfeat/raw/master/docs/assets/framework.jpg)
[CVPR 2021] Generative Hierarchical Features from Synthesizing Images
[CVPR 2021] Generative Hierarchical Features from Synthesizing Images
 148 Dec 9, 2022
148 Dec 9, 2022
Official implementation of the paper Chunked Autoregressive GAN for Conditional Waveform Synthesis
Chunked Autoregressive GAN (CARGAN) Official implementation of the paper Chunked Autoregressive GAN for Conditional Waveform Synthesis [paper] [compan
 150 Dec 6, 2022
150 Dec 6, 2022

PaSST: Efficient Training of Audio Transformers with Patchout
PaSST: Efficient Training of Audio Transformers with Patchout This is the implementation for Efficient Training of Audio Transformers with Patchout Pa
 165 Dec 26, 2022
165 Dec 26, 2022
Identify the emotion of multiple speakers in an Audio Segment
MevonAI - Speech Emotion Recognition Identify the emotion of multiple speakers in a Audio Segment Report Bug · Request Feature Try the Demo Here Table
 110 Dec 3, 2022
110 Dec 3, 2022
The description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts.
FMFCC-A This project is the description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts. The FMFCC-A dataset is shared through BaiduCl
 2 Oct 20, 2021
2 Oct 20, 2021
Deep Learning Based EDM Subgenre Classification using Mel-Spectrogram and Tempogram Features"
EDM-subgenre-classifier This repository contains the code for "Deep Learning Based EDM Subgenre Classification using Mel-Spectrogram and Tempogram Fea
 11 Dec 20, 2022
11 Dec 20, 2022
Demystifying How Self-Supervised Features Improve Training from Noisy Labels
Demystifying How Self-Supervised Features Improve Training from Noisy Labels This code is a PyTorch implementation of the paper "[Demystifying How Sel
 4 Oct 14, 2022
4 Oct 14, 2022

Repository for the NeurIPS 2021 paper: "Exploiting Domain-Specific Features to Enhance Domain Generalization".
meta-Domain Specific-Domain Invariant (mDSDI) Source code implementation for the paper: Manh-Ha Bui, Toan Tran, Anh Tuan Tran, Dinh Phung. "Exploiting
 12 Nov 25, 2022
12 Nov 25, 2022
The description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts.
FMFCC-A This project is the description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts. The FMFCC-A dataset is shared through BaiduCl
18 Dec 24, 2022

Source code for "Taming Visually Guided Sound Generation" (Oral at the BMVC 2021)
Taming Visually Guided Sound Generation • [Project Page] • [ArXiv] • [Poster] • • Listen for the samples on our project page. Overview We propose to t
 226 Jan 3, 2023
226 Jan 3, 2023
Powerful and Advance Telegram Bot with soo many features😋🔥❤
Chat-Bot Reach this bot on Telegram Chat Bot New Features 🔥 ✨ Improved Chat Experience ✨ Removed Some Unnecessary Commands ✨ Added Facility to downlo
 10 Oct 21, 2022
10 Oct 21, 2022
Official implementation of A cappella: Audio-visual Singing VoiceSeparation, from BMVC21
Y-Net Official implementation of A cappella: Audio-visual Singing VoiceSeparation, British Machine Vision Conference 2021 Project page: ipcv.github.io
 12 Oct 22, 2022
12 Oct 22, 2022
Transform-Invariant Non-Negative Matrix Factorization
Transform-Invariant Non-Negative Matrix Factorization A comprehensive Python package for Non-Negative Matrix Factorization (NMF) with a focus on learn
 6 Jul 1, 2022
6 Jul 1, 2022
Audio Steganography is a technique used to transmit hidden information by modifying an audio signal in an imperceptible manner.
Audio Steganography Audio Steganography is a technique used to transmit hidden information by modifying an audio signal in an imperceptible manner. Ab
 1 Oct 17, 2021
1 Oct 17, 2021
Acoustic mosquito detection code with Bayesian Neural Networks
HumBugDB Acoustic mosquito detection with Bayesian Neural Networks. Extract audio or features from our large-scale dataset on Zenodo. This repository
 31 Nov 28, 2022
31 Nov 28, 2022
Unofficial PyTorch Implementation of "DOLG: Single-Stage Image Retrieval with Deep Orthogonal Fusion of Local and Global Features"
Pytorch Implementation of Deep Orthogonal Fusion of Local and Global Features (DOLG) This is the unofficial PyTorch Implementation of "DOLG: Single-St
 96 Jan 6, 2023
96 Jan 6, 2023
A MCPI hack with many features.
Morpheus 2.0 A MCPI hack with many features To Use: You will need to install the keyboard, pysimplegui, and MCPI python modules and you will need to e
 11 Oct 11, 2022
11 Oct 11, 2022
Official implementation of A cappella: Audio-visual Singing VoiceSeparation, from BMVC21
Y-Net Official implementation of A cappella: Audio-visual Singing VoiceSeparation, British Machine Vision Conference 2021 Project page: ipcv.github.io
12 Oct 22, 2022
A Python framework to build Slack apps in a flash with the latest platform features.
Bolt for Python A Python framework to build Slack apps in a flash with the latest platform features. Read the getting started guide and look at our co
 684 Jan 9, 2023
684 Jan 9, 2023
Download videos and audio with a graphical interface in python
Youtube-Downloader Download videos and audio with a graphical interface in python Windows To run windows using Command Prompt python main.py linux To
 2 Jan 7, 2022
2 Jan 7, 2022

GUI for a Vocal Remover that uses Deep Neural Networks.
GUI for a Vocal Remover that uses Deep Neural Networks.
 4.4k Jan 7, 2023
4.4k Jan 7, 2023
A youtube-dl fork with additional features and fixes
yt-dlp is a youtube-dl fork based on the now inactive youtube-dlc. The main focus of this project is adding new features and patches while also keepin
 37.1k Jan 3, 2023
37.1k Jan 3, 2023
Telegram bot to download tiktok video/audio
TikTokDL (Bot) Telegram RoBot to Download Tiktok video/audio. Features: 👉 Download TikTok Video without Watermark 👉 Download TikTok Video with Water
 23 Nov 21, 2022
23 Nov 21, 2022
This bot can stream audio or video files and urls in telegram voice chats :)
Voice Chat Streamer This bot can stream audio or video files and urls in telegram voice chats :) 🎯 Follow me and star this repo for more telegram bot
 63 Dec 25, 2022
63 Dec 25, 2022

Youtube Downloader is a Graphic User Interface(GUI) that lets users download a Youtube Video or Audio through a URL
Youtube Downloader This Python and Tkinter based GUI allows users to directly download the Best Resolution Videos and Audios from Youtube. Pa-fy Insta
 2 Jun 25, 2022
2 Jun 25, 2022

A fast implementation of bss_eval metrics for blind source separation
fast_bss_eval Do you have a zillion BSS audio files to process and it is taking days ? Is your simulation never ending ? Fear no more! fast_bss_eval i
 99 Dec 13, 2022
99 Dec 13, 2022

Audio media crawler for lbry.
Audio media crawler for lbry. Requirements Python 3.8 Poetry 1.1.7 Elasticsearch 7.14.0 Lbry-sdk 0.99.0 Development This project uses poetry as a depe
 4 Dec 3, 2022
4 Dec 3, 2022
African language Speech Recognition - Speech-to-Text
Swahili-Speech-To-Text Table of Contents Swahili-Speech-To-Text Overview Scenario Approach Project Structure data: models: notebooks: scripts tests: l
 2 Jan 5, 2023
2 Jan 5, 2023
Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021)
Pano-AVQA Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021) [Paper] [Poster] [Video] Getting Starte
 9 Dec 23, 2022
9 Dec 23, 2022

University of Rochester 2021 Summer REU focusing on music sentiment transfer using CycleGAN
Music-Sentiment-Transfer University of Rochester 2021 Summer REU focusing on music sentiment transfer using CycleGAN Poster: Music Sentiment Transfer
 2 Jan 24, 2022
2 Jan 24, 2022
A Low Complexity Speech Enhancement Framework for Full-Band Audio (48kHz) based on Deep Filtering.
DeepFilterNet A Low Complexity Speech Enhancement Framework for Full-Band Audio (48kHz) based on Deep Filtering. libDF contains Rust code used for dat
 292 Dec 25, 2022
292 Dec 25, 2022

High performance Python GLMs with all the features!
High performance Python GLMs with all the features!
 200 Dec 14, 2022
200 Dec 14, 2022

Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation
Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation The code repository for "Audio-Visual Generalized Few-Shot Learning with
 3 Jun 27, 2022
3 Jun 27, 2022
Official PyTorch implementation of "AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks"
AASIST This repository provides the overall framework for training and evaluating audio anti-spoofing systems proposed in 'AASIST: Audio Anti-Spoofing
 56 Jan 2, 2023
56 Jan 2, 2023

The official implementation of the paper, "SubTab: Subsetting Features of Tabular Data for Self-Supervised Representation Learning"
SubTab: Author: Talip Ucar ([email protected]) The official implementation of the paper, SubTab: Subsetting Features of Tabular Data for Self-Supervis
 98 Dec 29, 2022
98 Dec 29, 2022

Pytorch implementation for our ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visual Question Answering".
TRAnsformer Routing Networks (TRAR) This is an official implementation for ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visu
 49 Nov 10, 2022
49 Nov 10, 2022
An audio-solving python funcaptcha solving module
funcapsolver funcapsolver is a funcaptcha audio-solving module, which allows captchas to be interacted with and solved with the use of google's speech
 8 Nov 21, 2022
8 Nov 21, 2022

Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
 47 Dec 25, 2022
47 Dec 25, 2022
Time-stretch audio clips quickly with PyTorch (CUDA supported)! Additional utilities for searching efficient transformations are included.
Time-stretch audio clips quickly with PyTorch (CUDA supported)! Additional utilities for searching efficient transformations are included.
 22 Jul 7, 2022
22 Jul 7, 2022

text to speech toolkit. 好用的中文语音合成工具箱,包含语音编码器、语音合成器、声码器和可视化模块。
ttskit Text To Speech Toolkit: 语音合成工具箱。 安装 pip install -U ttskit 注意 可能需另外安装的依赖包:torch,版本要求torch=1.6.0,=1.7.1,根据自己的实际环境安装合适cuda或cpu版本的torch。 ttskit的
 483 Jan 4, 2023
483 Jan 4, 2023
SelfBot, a lots of features: Mass DM , Nuke, Raid... and more!
SelfBot, a lots of features: Mass DM , Nuke, Raid... and more!
 2 Nov 10, 2021
2 Nov 10, 2021
A graph neural network (GNN) model to predict protein-protein interactions (PPI) with no sample features
A graph neural network (GNN) model to predict protein-protein interactions (PPI) with no sample features
 2 Jul 25, 2022
2 Jul 25, 2022
Simple bot to receive feedback,same as livegram bot but with more features & full control over bot
Kontak Simple bot to receive feedback,same as livegram bot but with more features & full control over bot Deploy to VPS
 2 Dec 16, 2021
2 Dec 16, 2021
A simple but useful Discord Selfbot with essential features, made with discord.py-self.
Discord Selfbot Xyno Discord Selfbot Xyno is a simple but useful selfbot for Discord. It has currently limited useful features but it will be updated
 7 Apr 24, 2022
7 Apr 24, 2022

An URL Shortener with Basic Features.
Simple Url Shortener What is that? Yet another url shortener built with Django framework. Preview HOW TO RUN? 1. Virtual Environment First create a vi
 6 Jan 25, 2022
6 Jan 25, 2022

Satellite labelling tool for manual labelling of storm top features such as overshooting tops, above-anvil plumes, cold U/Vs, rings etc.
Satellite labelling tool About this app A tool for manual labelling of storm top features such as overshooting tops, above-anvil plumes, cold U/Vs, ri
 10 Sep 14, 2022
10 Sep 14, 2022

A simple but complete full-attention transformer with a set of promising experimental features from various papers
x-transformers A concise but fully-featured transformer, complete with a set of promising experimental features from various papers. Install $ pip ins
 2.3k Jan 3, 2023
2.3k Jan 3, 2023

Unofficial Implementation of Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration This repo contains only model Implementation of Zero-Shot Text-to-Speech for Text
 33 Sep 22, 2022
33 Sep 22, 2022
django social media app with real time features
django-social-media django social media app with these features: signup, login and old registered users are saved by cookies posts, comments, replies,
 8 Apr 30, 2022
8 Apr 30, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 287 Dec 21, 2022
287 Dec 21, 2022

PyTorch implementation of SIFT descriptor
This is an differentiable pytorch implementation of SIFT patch descriptor. It is very slow for describing one patch, but quite fast for batch. It can
 150 Dec 24, 2022
150 Dec 24, 2022

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
 883 Jan 7, 2023
883 Jan 7, 2023
A link shortner telegram bot version 2 with advanced features
URL-Shortner-Bot-V2 A link shortner telegram bot version 2 with advanced features Made with Python3 (C) @FayasNoushad Copyright permission under MIT L
 18 Dec 29, 2022
18 Dec 29, 2022
Train a deep learning net with OpenStreetMap features and satellite imagery.
DeepOSM Classify roads and features in satellite imagery, by training neural networks with OpenStreetMap (OSM) data. DeepOSM can: Download a chunk of
 1.3k Nov 24, 2022
1.3k Nov 24, 2022
Official implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT This repository is the official implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. ArXiv If
 168 Dec 29, 2022
168 Dec 29, 2022
A Multilingual Latent Dirichlet Allocation (LDA) Pipeline with Stop Words Removal, n-gram features, and Inverse Stemming, in Python.
Multilingual Latent Dirichlet Allocation (LDA) Pipeline This project is for text clustering using the Latent Dirichlet Allocation (LDA) algorithm. It
 74 Oct 7, 2022
74 Oct 7, 2022

Django-Audiofield is a simple app that allows Audio files upload, management and conversion to different audio format (mp3, wav & ogg), which also makes it easy to play audio files into your Django application.
Django-Audiofield Description: Django Audio Management Tools Maintainer: Areski Contributors: list of contributors Django-Audiofield is a simple app t
 167 Nov 10, 2022
167 Nov 10, 2022
Django-MySQL extends Django's built-in MySQL and MariaDB support their specific features not available on other databases.
Django-MySQL The dolphin-pony - proof that cute + cute = double cute. Django-MySQL extends Django's built-in MySQL and MariaDB support their specific
 504 Jan 4, 2023
504 Jan 4, 2023
Music source separation is a task to separate audio recordings into individual sources
Music Source Separation Music source separation is a task to separate audio recordings into individual sources. This repository is an PyTorch implmeme
 958 Jan 3, 2023
958 Jan 3, 2023
This is a Innexia Group Manager Bot with many features
⚡ Innexia ⚡ A Powerful, Smart And Simple Group Manager ... Written with AioGram , Pyrogram and Telethon... Available on Telegram as @Innexia ❤️ Suppor
 84 Jun 4, 2022
84 Jun 4, 2022
“Hey there 👋 I'm szrosebot .A Powerful, Smart And Simple Group Manager with some extra features..
A Powerful, Smart And Simple Group Manager szrose bot This is the clone of DewmiBotit is a Powerful, Smart And Simple Group Manager bot made by hiruna
 36 Oct 30, 2022
36 Oct 30, 2022
Telegram bot which has truecaller and smsbomber features
Truecaller-telegram_bot Add your telegram bot api key in main.py and you are good to go To get a api key Goto telegram and search BotFather From the c
 32 Dec 5, 2022
32 Dec 5, 2022
Gateware for the Terasic/Arrow DECA board, to become a USB2 high speed audio interface
DECA USB Audio Interface DECA based USB 2.0 High Speed audio interface Status / current limitations enumerates as class compliant audio device on Linu
 16 Mar 21, 2022
16 Mar 21, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
git-partial-submodule is a command-line script for setting up and working with submodules while enabling them to use git's partial clone and sparse checkout features.
Partial Submodules for Git git-partial-submodule is a command-line script for setting up and working with submodules while enabling them to use git's
 15 Sep 22, 2022
15 Sep 22, 2022

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022
A tool to fuck a video/audio quality using FFmpeg
Media quality fucker A tool to fuck a video/audio quality using FFmpeg How to use Download the source Download Python Extract FFmpeg Put what you want
 8 Jan 25, 2022
8 Jan 25, 2022
Reading list for research topics in sound event detection
Sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene.
 64 Jan 5, 2023
64 Jan 5, 2023

pedalboard is a Python library for adding effects to audio.
pedalboard is a Python library for adding effects to audio. It supports a number of common audio effects out of the box, and also allows the use of VST3® and Audio Unit plugin formats for third-party effects.
 3.9k Jan 2, 2023
3.9k Jan 2, 2023

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
A Telegram Bot to manage your music channel with some cool features.
Music Channel Manager V2 A Telegram Bot to manage your music channel with some cool features like appending your predefined username to the musics tag
 11 Oct 21, 2022
11 Oct 21, 2022
praudio provides audio preprocessing framework for Deep Learning audio applications
praudio provides objects and a script for performing complex preprocessing operations on entire audio datasets with one command.
 105 Dec 26, 2022
105 Dec 26, 2022
Based Telegram Bot and Userbot To Play Music in Your Telegram Groups With Some Cool Extra Features! 🥰
CallMusicPlus69 This Repo base on! 🤗️ A CallsMusic Based Telegram Bot and Userbot To Play Music in Your Telegram Groups With Some Cool Extra Features
 6 Jun 26, 2022
6 Jun 26, 2022
The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution.
WSRGlow The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution. Audio sa
 96 Jan 3, 2023
96 Jan 3, 2023
PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
samplernn-pytorch A PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model. It's based on the reference implem
 261 Dec 14, 2022
261 Dec 14, 2022

Oriented Response Networks, in CVPR 2017
Oriented Response Networks [Home] [Project] [Paper] [Supp] [Poster] Torch Implementation The torch branch contains: the official torch implementation
 217 Dec 12, 2022
217 Dec 12, 2022

Simple torch.nn.module implementation of Alias-Free-GAN style filter and resample
Alias-Free-Torch Simple torch module implementation of Alias-Free GAN. This repository including Alias-Free GAN style lowpass sinc filter @filter.py A
 64 Dec 22, 2022
64 Dec 22, 2022

Using a raspberry pi, we listen to the coffee machine and count the number of coffee consumption
A typical datarootsian consumes high-quality fresh coffee in their office environment. The board of dataroots had a very critical decision by the end of 2021-Q2 regarding coffee consumption.
 51 Nov 21, 2022
51 Nov 21, 2022
This Binance trading bot detects new coins as soon as they are listed on the Binance exchange and automatically places sell and buy orders. It comes with trailing stop loss and other features. If you like this project please consider donating via Brave.
binance-trading-bot-new-coins This Binance trading bot detects new coins as soon as they are listed on the Binance exchange and automatically places s
 1.4k Dec 24, 2022
1.4k Dec 24, 2022
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022

Easy to use Audio Tagging in PyTorch
Audio Classification, Tagging & Sound Event Detection in PyTorch Progress: Fine-tune on audio classification Fine-tune on audio tagging Fine-tune on s
 15 Dec 22, 2022
15 Dec 22, 2022
FPGA based USB 2.0 high speed audio interface featuring multiple optical ADAT inputs and outputs
ADAT USB Audio Interface FPGA based USB 2.0 High Speed audio interface featuring multiple optical ADAT inputs and outputs Status / current limitations
78 Dec 31, 2022

PRIN/SPRIN: On Extracting Point-wise Rotation Invariant Features
PRIN/SPRIN: On Extracting Point-wise Rotation Invariant Features Overview This repository is the Pytorch implementation of PRIN/SPRIN: On Extracting P
 17 Mar 2, 2022
17 Mar 2, 2022
HtmlWebShot - A python3 package which Can Create Images From url, Html-CSS, Svg and from any readable file and texts with many setup features.
A python3 package which Can Create Images From url, Html-CSS, Svg and from any readable file and texts with many setup features
 24 Dec 14, 2022
24 Dec 14, 2022
This app converts an pdf file into the audio file.
PDF-to-Audio This app takes an pdf as an input and convert it into audio, and the library text-to-speech starts speaking the preffered page given in t
 3 Aug 4, 2021
3 Aug 4, 2021
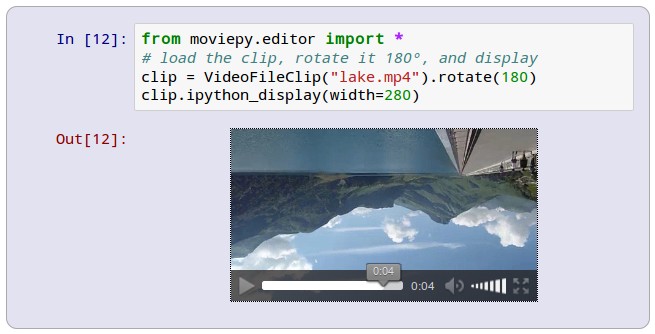
MoviePy is a Python library for video editing, can read and write all the most common audio and video formats
MoviePy is a Python library for video editing: cutting, concatenations, title insertions, video compositing (a.k.a. non-linear editing), video processing, and creation of custom effects. See the gallery for some examples of use.
 10k Jan 8, 2023
10k Jan 8, 2023
A Telegram Bot to Play Audio in Voice Chats With Youtube and Deezer support. Supports Live streaming from youtube Supports Mega Radio Fm Streamings
Bot To Stream Musics on PyTGcalls with Channel Support. A Telegram Bot to Play Audio in Voice Chats With Supports Live streaming from youtube and Mega
 37 Dec 15, 2022
37 Dec 15, 2022

Code for the Interspeech 2021 paper "AST: Audio Spectrogram Transformer".
AST: Audio Spectrogram Transformer Introduction Citing Getting Started ESC-50 Recipe Speechcommands Recipe AudioSet Recipe Pretrained Models Contact I
 603 Jan 7, 2023
603 Jan 7, 2023

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022
Kaldi-compatible feature extraction with PyTorch, supporting CUDA, batch processing, chunk processing, and autograd
Kaldi-compatible feature extraction with PyTorch, supporting CUDA, batch processing, chunk processing, and autograd
 119 Jan 3, 2023
119 Jan 3, 2023
improvement of CLIP features over the traditional resnet features on the visual question answering, image captioning, navigation and visual entailment tasks.
CLIP-ViL In our paper "How Much Can CLIP Benefit Vision-and-Language Tasks?", we show the improvement of CLIP features over the traditional resnet fea
 310 Dec 28, 2022
310 Dec 28, 2022
efficient neural audio synthesis in the waveform domain
neural waveshaping synthesis real-time neural audio synthesis in the waveform domain paper • website • colab • audio by Ben Hayes, Charalampos Saitis,
 169 Dec 23, 2022
169 Dec 23, 2022
This is an differentiable pytorch implementation of SIFT patch descriptor.
This is an differentiable pytorch implementation of SIFT patch descriptor. It is very slow for describing one patch, but quite fast for batch. It can
150 Dec 24, 2022
A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
286 Jan 2, 2023
Telegram Radio - A User-bot who continuously play random audio files (from the famous telegram music channel @mveargasm) in the intended voice chat.
MvEargasmDJ: This is my submission for the Telegram Radio Project of Baivaru. Which required a userbot to continiously play random audio files from th
 24 Nov 12, 2022
24 Nov 12, 2022

NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling @ INTERSPEECH 2021 Accepted
NU-Wave — Official PyTorch Implementation NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling Junhyeok Lee, Seungu Han @ MINDsLab Inc
242 Dec 23, 2022

Implemented fully documented Particle Swarm Optimization algorithm (basic model with few advanced features) using Python programming language
Implemented fully documented Particle Swarm Optimization (PSO) algorithm in Python which includes a basic model along with few advanced features such as updating inertia weight, cognitive, social learning coefficients and maximum velocity of the particle.
 9 Nov 29, 2022
9 Nov 29, 2022

Classify bird species based on their songs using SIamese Networks and 1D dilated convolutions.
The goal is to classify different birds species based on their songs/calls. Spectrograms have been extracted from the audio samples and used as features for classification.
9 Dec 27, 2022
[ACL 20] Probing Linguistic Features of Sentence-level Representations in Neural Relation Extraction
REval Table of Contents Introduction Overview Requirements Installation Probing Usage Citation License 🎓 Introduction REval is a simple framework for
 13 Jan 6, 2023
13 Jan 6, 2023
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
93 Dec 17, 2022