548 Repositories
Python audio-datasets Libraries
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022

MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts (ICLR 2022)
MetaShift: A Dataset of Datasets for Evaluating Distribution Shifts and Training Conflicts This repo provides the PyTorch source code of our paper: Me
 88 Jan 4, 2023
88 Jan 4, 2023

Dataset and baseline code for the VocalSound dataset (ICASSP2022).
VocalSound: A Dataset for Improving Human Vocal Sounds Recognition Introduction Citing Download VocalSound Dataset Details Baseline Experiment Contact
 58 Jan 3, 2023
58 Jan 3, 2023
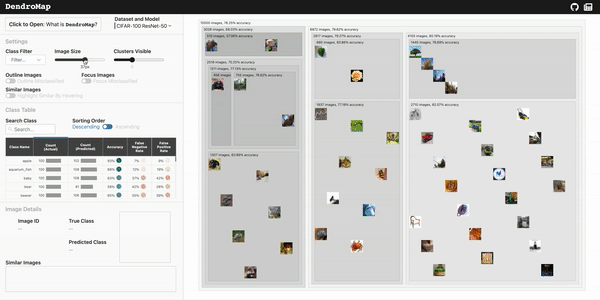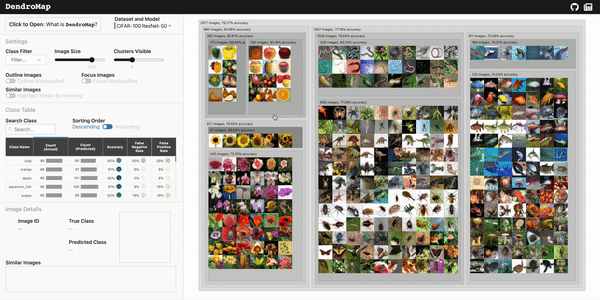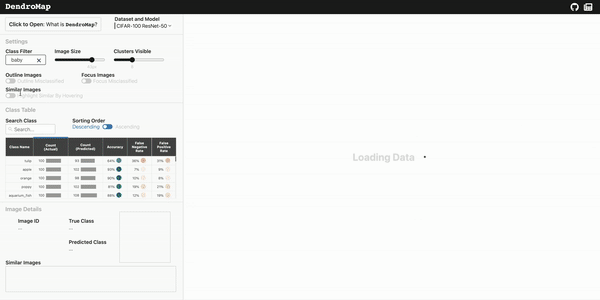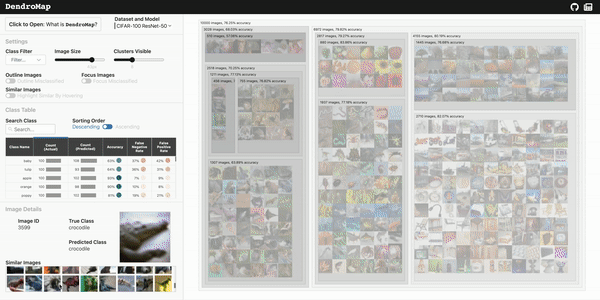
This repository contains the DendroMap implementation for scalable and interactive exploration of image datasets in machine learning.
DendroMap DendroMap is an interactive tool to explore large-scale image datasets used for machine learning. A deep understanding of your data can be v
 33 Dec 30, 2022
33 Dec 30, 2022

Building a real-time environment using webcam frame division in OpenCV and classify cropped images using a fine-tuned vision transformers on hybryd datasets samples for facial emotion recognition.
Visual Transformer for Facial Emotion Recognition (FER) This project has the aim to build an efficient Visual Transformer for the Facial Emotion Recog
 8 Dec 12, 2022
8 Dec 12, 2022

A lightweight yet powerful audio-to-MIDI converter with pitch bend detection
Basic Pitch is a Python library for Automatic Music Transcription (AMT), using lightweight neural network developed by Spotify's Audio Intelligence La
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
A Python library that enables ML teams to share, load, and transform data in a collaborative, flexible, and efficient way :chestnut:
Squirrel Core Share, load, and transform data in a collaborative, flexible, and efficient way What is Squirrel? Squirrel is a Python library that enab
 249 Dec 7, 2022
249 Dec 7, 2022
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022

A large-scale (194k), Multiple-Choice Question Answering (MCQA) dataset designed to address realworld medical entrance exam questions.
MedMCQA MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering A large-scale, Multiple-Choice Question Answe
 24 Nov 30, 2022
24 Nov 30, 2022
HF's ML for Audio study group
Hugging Face Machine Learning for Audio Study Group Welcome to the ML for Audio Study Group. Through a series of presentations, paper reading and disc
 110 Jan 1, 2023
110 Jan 1, 2023
Framework for evaluating ANNS algorithms on billion scale datasets.
Billion-Scale ANN http://big-ann-benchmarks.com/ Install The only prerequisite is Python (tested with 3.6) and Docker. Works with newer versions of Py
 132 Dec 24, 2022
132 Dec 24, 2022
A Traffic Sign Recognition Project which can help the driver recognise the signs via text as well as audio. Can be used at Night also.
Traffic-Sign-Recognition In this report, we propose a Convolutional Neural Network(CNN) for traffic sign classification that achieves outstanding perf
 64 Nov 19, 2022
64 Nov 19, 2022

Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
 732 Jan 8, 2023
732 Jan 8, 2023
![[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets](https://github.com/autonomousvision/stylegan_xl/raw/main/media/banner.png)
[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
[Project] [PDF] This repository contains code for our SIGGRAPH'22 paper "StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets" by Axel Sauer, Katja
 742 Jan 4, 2023
742 Jan 4, 2023

APEACH: Attacking Pejorative Expressions with Analysis on Crowd-generated Hate Speech Evaluation Datasets
APEACH - Korean Hate Speech Evaluation Datasets APEACH is the first crowd-generated Korean evaluation dataset for hate speech detection. Sentences of
 70 Dec 6, 2022
70 Dec 6, 2022

CLIPfa: Connecting Farsi Text and Images
CLIPfa: Connecting Farsi Text and Images OpenAI released the paper Learning Transferable Visual Models From Natural Language Supervision in which they
 66 Dec 14, 2022
66 Dec 14, 2022
Implementation of Basic Machine Learning Algorithms on small datasets using Scikit Learn.
Basic Machine Learning Algorithms All the basic Machine Learning Algorithms are implemented in Python using libraries Acknowledgements Machine Learnin
 47 Oct 16, 2022
47 Oct 16, 2022

Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
RAVE: Realtime Audio Variational autoEncoder Official implementation of RAVE: A variational autoencoder for fast and high-quality neural audio synthes
 587 Jan 1, 2023
587 Jan 1, 2023

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
 87 Dec 21, 2022
87 Dec 21, 2022
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
Classification models 1D Zoo - Keras and TF.Keras
Classification models 1D Zoo - Keras and TF.Keras This repository contains 1D variants of popular CNN models for classification like ResNets, DenseNet
 12 Jan 6, 2023
12 Jan 6, 2023
Helping data scientists better understand their datasets and models in text classification. With love from ServiceNow.
Azimuth, an open-source dataset and error analysis tool for text classification, with love from ServiceNow. Overview Azimuth is an open source applica
 145 Dec 23, 2022
145 Dec 23, 2022
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets.
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets. It makes dataset creation more effective and helps find essential insights from training results and improves AI performance.
 27 Oct 22, 2022
27 Oct 22, 2022

YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Created using Python, PyTube and PySimpleGUI.
YouTube Downloader YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Disclaimer It's
 3 Dec 14, 2022
3 Dec 14, 2022

Audio-analytics for music-producers! Automate tedious tasks such as musical scale detection, BPM rate classification and audio file conversion.
Click here to be re-directed to the Beat Inspect Streamlit Web-App You are a music producer? Let's get in touch via LinkedIn Fundamental Analytics for
 11 Dec 27, 2022
11 Dec 27, 2022

In this project we predict the forest cover type using the cartographic variables in the training/test datasets.
Kaggle Competition: Forest Cover Type Prediction In this project we predict the forest cover type (the predominant kind of tree cover) using the carto
 1 Mar 15, 2022
1 Mar 15, 2022
An extension package of 🤗 Datasets that provides support for executing arbitrary SQL queries on HF datasets
datasets_sql A 🤗 Datasets extension package that provides support for executing arbitrary SQL queries on HF datasets. It uses DuckDB as a SQL engine
 19 Dec 15, 2022
19 Dec 15, 2022
Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution.
convolver Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution. Created by Sean Higley [email protected]
 1 Feb 23, 2022
1 Feb 23, 2022
Code for One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022) Paper | Demo Requirements Python = 3.6 , Pytorch
 84 Jan 3, 2023
84 Jan 3, 2023
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
 2 Feb 14, 2022
2 Feb 14, 2022

SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation In this repo you can find the code of the Supervised Hybrid Audio Segmentatio
 21 Dec 20, 2022
21 Dec 20, 2022
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data"
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data" You can download the pretrained
 3 May 7, 2022
3 May 7, 2022
Convert PDF to AudioBook and Audio Speech to PDF
In this Python project, we will build a GUI-based PDF to Audio and Audio to PDF converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, PyPDF4, and Pydub libraries and the messagebox module of the Tkinter library.
 1 Feb 13, 2022
1 Feb 13, 2022
Crowd-Kit is a powerful Python library that implements commonly-used aggregation methods for crowdsourced annotation and offers the relevant metrics and datasets
Crowd-Kit: Computational Quality Control for Crowdsourcing Documentation Crowd-Kit is a powerful Python library that implements commonly-used aggregat
 125 Dec 30, 2022
125 Dec 30, 2022

Datasets and pretrained Models for StyleGAN3 ...
Datasets and pretrained Models for StyleGAN3 ... Dear arfiticial friend, this is a collection of artistic datasets and models that we have put togethe
 34 Oct 6, 2022
34 Oct 6, 2022
Notebook and code to synthesize complex and highly dimensional datasets using Gretel APIs.
Gretel Trainer This code is designed to help users successfully train synthetic models on complex datasets with high row and column counts. The code w
 24 Nov 3, 2022
24 Nov 3, 2022
An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright.
Playwright nonoCAPTCHA An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright. Disclaimer This project is for educational
 69 Dec 28, 2022
69 Dec 28, 2022
PyTorch implementation of the ExORL: Exploratory Data for Offline Reinforcement Learning
ExORL: Exploratory Data for Offline Reinforcement Learning This is an original PyTorch implementation of the ExORL framework from Don't Change the Alg
 52 Jan 1, 2023
52 Jan 1, 2023

The pyrelational package offers a flexible workflow to enable active learning with as little change to the models and datasets as possible
pyrelational is a python active learning library developed by Relation Therapeutics for rapidly implementing active learning pipelines from data management, model development (and Bayesian approximation), to creating novel active learning strategies.
 95 Dec 27, 2022
95 Dec 27, 2022

I³ Tracker for Essential Open Innovation Datasets
I³ Tracker for Essential Open Innovation Datasets This repository is set up to track, version, and contribute updates to the I³ Essential Open Innovat
 1 Feb 8, 2022
1 Feb 8, 2022

BCI datasets and algorithms
Brainda Welcome! First and foremost, Welcome! Thank you for visiting the Brainda repository which was initially released at this repo and reorganized
 52 Jan 4, 2023
52 Jan 4, 2023

Complete* list of autonomous driving related datasets
AD Datasets Complete* and curated list of autonomous driving related datasets Contributing Contributions are very welcome! To add or update a dataset:
 13 Dec 19, 2022
13 Dec 19, 2022

TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
TONet Introduction The official implementation of "TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music", in ICASSP 2022 We
 29 Dec 1, 2022
29 Dec 1, 2022

Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
13 Feb 8, 2022
Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 50 Nov 12, 2022
50 Nov 12, 2022

Pytorch implementation of TailCalibX : Feature Generation for Long-tail Classification
TailCalibX : Feature Generation for Long-tail Classification by Rahul Vigneswaran, Marc T. Law, Vineeth N. Balasubramanian, Makarand Tapaswi [arXiv] [
 34 Jan 2, 2023
34 Jan 2, 2023

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022
/samples.jpg)
A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution.
Awesome Pretrained StyleGAN2 A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution. Note the readme is a
 1.1k Dec 24, 2022
1.1k Dec 24, 2022

An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to art and design.
Awesome AI for Art & Design An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to a
 20 Dec 21, 2022
20 Dec 21, 2022
SAAVN - Sound Adversarial Audio-Visual Navigation,ICLR2022 (In PyTorch)
SAAVN SAAVN Code release for paper "Sound Adversarial Audio-Visual Navigation,IC
 10 Aug 30, 2022
10 Aug 30, 2022
YoutubeDownloader - Repo for downloading YT audio and videos
YoutubeDownloader Downloads video/playlist/audio from youtube url. install all t
 2 Feb 17, 2022
2 Feb 17, 2022
The official code repo of "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
134 Jan 1, 2023
List of Land Cover datasets in the GEE Catalog
List of Land Cover datasets in the GEE Catalog A list of all the Land Cover (or discrete) datasets in Google Earth Engine. Values, Colors and Descript
 5 Aug 24, 2022
5 Aug 24, 2022
Audio Retrieval with Natural Language Queries: A Benchmark Study
Audio Retrieval with Natural Language Queries: A Benchmark Study Paper | Project page | Text-to-audio search demo This repository is the implementatio
 21 Oct 31, 2022
21 Oct 31, 2022
Annotate datasets with a semi-trained or fully trained YOLOv5 model
YOLOv5 Auto Annotator Annotate datasets with a semi-trained or fully trained YOLOv5 model Prerequisites Ubuntu =20.04 Python =3.7 System dependencie
 3 May 14, 2022
3 May 14, 2022
This is the source code for the experiments related to the paper Unsupervised Audio Source Separation Using Differentiable Parametric Source Models
Unsupervised Audio Source Separation Using Differentiable Parametric Source Models This is the source code for the experiments related to the paper Un
 30 Oct 19, 2022
30 Oct 19, 2022
A notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository
We provide a notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository. The notebook also shows how to segment the corpus using BPE tokenization which can be used to train an English-Hindi MT System.
 9 Oct 13, 2022
9 Oct 13, 2022

Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources
Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources (e.g. just the lead vocals).
 14 Nov 7, 2022
14 Nov 7, 2022
An NVDA add-on to split screen reader and audio from other programs to different sound channels
An NVDA add-on to split screen reader and audio from other programs to different sound channels (add-on idea credit: Tony Malykh)
 7 Dec 25, 2022
7 Dec 25, 2022

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023
Graviti-python-sdk - Graviti Data Platform Python SDK
Graviti Python SDK Graviti Python SDK is a python library to access Graviti Data
 13 Dec 15, 2022
13 Dec 15, 2022

🛰️ Awesome Satellite Imagery Datasets
Awesome Satellite Imagery Datasets List of aerial and satellite imagery datasets with annotations for computer vision and deep learning. Newest datase
 3k Jan 3, 2023
3k Jan 3, 2023
A tool for retrieving audio in the past
Rewinder A tool for retrieving audio in the past. Ever felt like, I need to remember that discussion which happened 10 min back. Now you can! Rewind a
 1 Jan 24, 2022
1 Jan 24, 2022

Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution
Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution Figure: Example visualization of the method and baseline as a
 16 Dec 23, 2022
16 Dec 23, 2022
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
 3 Jan 24, 2022
3 Jan 24, 2022

Audio2Face - Audio To Face With Python
Audio2Face Discription We create a project that transforms audio to blendshape w
724 Dec 26, 2022
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning My
 3 Apr 10, 2022
3 Apr 10, 2022
Awesome AI Learning with +100 AI Cheat-Sheets, Free online Books, Top Courses, Best Videos and Lectures, Papers, Tutorials, +99 Researchers, Premium Websites, +121 Datasets, Conferences, Frameworks, Tools
All about AI with Cheat-Sheets(+100 Cheat-sheets), Free Online Books, Courses, Videos and Lectures, Papers, Tutorials, Researchers, Websites, Datasets
 1.2k Jan 1, 2023
1.2k Jan 1, 2023

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022
TikTok - TikTok Bot to download video or audio from TikTok
TikTok - TikTok Bot to download video or audio from TikTok
 51 Mar 4, 2022
51 Mar 4, 2022

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022
A2DP agent for promiscuous/permissive audio sinc.
Promiscuous Bluetooth audio sinc A2DP agent for promiscuous/permissive audio sinc for Linux. Once installed, a Bluetooth client, such as a smart phone
 4 May 27, 2022
4 May 27, 2022

Animal Sound Classification (Cats Vrs Dogs Audio Sentiment Classification)
this is a simple artificial neural network model using deep learning and torch-audio to classify cats and dog sounds.
 3 Dec 5, 2022
3 Dec 5, 2022

Terminal-based music player written in Python for the best music in the world 🎵 🎧 💻
audius-terminal-player Terminal-based music player written in Python for the best music in the world 🎵 🎧 💻 Browse and listen to Audius from the com
 21 Jul 23, 2022
21 Jul 23, 2022

A Unified Framework and Analysis for Structured Knowledge Grounding
UnifiedSKG 📚 : Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models Code for paper UnifiedSKG: Unifying and Mu
 370 Dec 21, 2022
370 Dec 21, 2022

NeWT: Natural World Tasks
NeWT: Natural World Tasks This repository contains resources for working with the NeWT dataset. ❗ At this time the binary tasks are not publicly avail
 26 Oct 18, 2022
26 Oct 18, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022
Few-Shot-Intent-Detection includes popular challenging intent detection datasets with/without OOS queries and state-of-the-art baselines and results.
Few-Shot-Intent-Detection Few-Shot-Intent-Detection is a repository designed for few-shot intent detection with/without Out-of-Scope (OOS) intents. It
 73 Dec 26, 2022
73 Dec 26, 2022

Python Auto-ML Package for Tabular Datasets
Tabular-AutoML AutoML Package for tabular datasets Tabular dataset tuning is now hassle free! Run one liner command and get best tuning and processed
 18 Nov 20, 2022
18 Nov 20, 2022
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes The codes for simu
 1 Jan 12, 2022
1 Jan 12, 2022
[ WSDM '22 ] On Sampling Collaborative Filtering Datasets
On Sampling Collaborative Filtering Datasets This repository contains the implementation of many popular sampling strategies, along with various expli
 17 Dec 8, 2022
17 Dec 8, 2022
A curated list of awesome game datasets, and tools to artificial intelligence in games
🎮 Awesome Game Datasets In computer science, Artificial Intelligence (AI) is intelligence demonstrated by machines. Its definition, AI research as th
 454 Jan 3, 2023
454 Jan 3, 2023
Cl datasets - PyTorch image dataloaders and utility functions to load datasets for supervised continual learning
Continual learning datasets Introduction This repository contains PyTorch image
 5 Aug 28, 2022
5 Aug 28, 2022
API Server for VoIP analysis (CDR + Audio CODECs)
Swagger generated server Overview This server was generated by the swagger-codegen project. By using the OpenAPI-Spec from a remote server, you can ea
 1 Jan 11, 2022
1 Jan 11, 2022
Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis
Introduction This is an implementation of our paper Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis.
 24 Dec 6, 2022
24 Dec 6, 2022
This is the source code for generating the ASL-Skeleton3D and ASL-Phono datasets. Check out the README.md for more details.
ASL-Skeleton3D and ASL-Phono Datasets Generator The ASL-Skeleton3D contains a representation based on mapping into the three-dimensional space the coo
 5 Nov 20, 2022
5 Nov 20, 2022

A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets
HOW TO USE THIS PROJECT A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets Based on DeepLabCut toolbox, we run wit
 1 Jan 10, 2022
1 Jan 10, 2022
![[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021](https://github.com/hasanirtiza/Pedestron/raw/master/gifs/1.gif)
[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021
Pedestron Pedestron is a MMdetection based repository, that focuses on the advancement of research on pedestrian detection. We provide a list of detec
 594 Jan 5, 2023
594 Jan 5, 2023
A wrapper around ffmpeg to make it work in a concurrent and memory-buffered fashion.
Media Fixer Have you ever had a film or TV show that your TV wasn't able to play its audio? Well this program is for you. Media Fixer is a program whi
 3 May 4, 2022
3 May 4, 2022

A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
 65 Dec 19, 2022
65 Dec 19, 2022
Jupyter notebook and datasets from the pandas Q&A video series
Python pandas Q&A video series Read about the series, and view all of the videos on one page: Easier data analysis in Python with pandas. Jupyter Note
 2k Jan 5, 2023
2k Jan 5, 2023
A Python package for time series augmentation
tsaug tsaug is a Python package for time series augmentation. It offers a set of augmentation methods for time series, as well as a simple API to conn
 278 Jan 1, 2023
278 Jan 1, 2023
A general and strong 3D object detection codebase that supports more methods, datasets and tools (debugging, recording and analysis).
ALLINONE-Det ALLINONE-Det is a general and strong 3D object detection codebase built on OpenPCDet, which supports more methods, datasets and tools (de
 5 Nov 3, 2022
5 Nov 3, 2022
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi.
Spchcat Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that read
 279 Jan 3, 2023
279 Jan 3, 2023

A self-supervised learning framework for audio-visual speech
AV-HuBERT (Audio-Visual Hidden Unit BERT) Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction Robust Self-Supervised A
431 Jan 7, 2023

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

Customer Service Requests Analysis is one of the practical life problems that an analyst may face. This Project is one such take. The project is a beginner to intermediate level project. This repository has a Source Code, README file, Dataset, Image and License file.
Customer Service Requests Analysis Project 1 DESCRIPTION Background of Problem Statement : NYC 311's mission is to provide the public with quick and e
 7 Sep 19, 2022
7 Sep 19, 2022
BART aids transcribe tasks by taking a source audio file and creating automatic repeated loops, allowing transcribers to listen to fragments multiple times
BART (Beyond Audio Replay Technology) aids transcribe tasks by taking a source audio file and creating automatic repeated loops, allowing transcribers to listen to fragments multiple times (with possible overlap between segments).
 2 Feb 4, 2022
2 Feb 4, 2022

Automagically synchronize subtitles with video.
FFsubsync Language-agnostic automatic synchronization of subtitles with video, so that subtitles are aligned to the correct starting point within the
 5.7k Jan 6, 2023
5.7k Jan 6, 2023

Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
 5.3k Dec 30, 2022
5.3k Dec 30, 2022