296 Repositories
Python benchmark-environments Libraries
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation (NeurIPS2021 Benchmark and Dataset Track)
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation by Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zh
 174 Dec 22, 2022
174 Dec 22, 2022

Vision-and-Language Navigation in Continuous Environments using Habitat
Vision-and-Language Navigation in Continuous Environments (VLN-CE) Project Website — VLN-CE Challenge — RxR-Habitat Challenge Official implementations
 132 Jan 2, 2023
132 Jan 2, 2023
Official code of paper: MovingFashion: a Benchmark for the Video-to-Shop Challenge
SEAM Match-RCNN Official code of MovingFashion: a Benchmark for the Video-to-Shop Challenge paper Installation Requirements: Pytorch 1.5.1 or more rec
 31 Oct 10, 2022
31 Oct 10, 2022
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English ⚖️ 🏆 🧑🎓 👩⚖️ Dataset Summary Inspired by the recent widespread use of th
 95 Dec 8, 2022
95 Dec 8, 2022

ProFuzzBench - A Benchmark for Stateful Protocol Fuzzing
ProFuzzBench - A Benchmark for Stateful Protocol Fuzzing ProFuzzBench is a benchmark for stateful fuzzing of network protocols. It includes a suite of
 155 Jan 8, 2023
155 Jan 8, 2023

Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E. Evaluated on benchmark dataset Office31.
Deep-Unsupervised-Domain-Adaptation Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E.
 49 Dec 20, 2022
49 Dec 20, 2022

Benchmark a WebSocket server's message throughput ⌛
📻 WebSocket Benchmarker ⌚ Message throughput is how fast a WebSocket server can parse and respond to a message. Some people consider this to be a goo
 24 Nov 17, 2022
24 Nov 17, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022

Benchmark for Answering Existential First Order Queries with Single Free Variable
EFO-1-QA Benchmark for First Order Query Estimation on Knowledge Graphs This repository contains an entire pipeline for the EFO-1-QA benchmark. EFO-1
 14 Oct 24, 2022
14 Oct 24, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Official code for 'Robust Siamese Object Tracking for Unmanned Aerial Manipulator' and offical introduction to UAMT100 benchmark
SiamSA: Robust Siamese Object Tracking for Unmanned Aerial Manipulator Demo video 📹 Our video on Youtube and bilibili demonstrates the evaluation of
 12 Dec 18, 2022
12 Dec 18, 2022
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files. If multiple configs are benchmarked it will output a file ranking them from fastest to slowest.
 12 May 7, 2022
12 May 7, 2022
CompilerGym is a library of easy to use and performant reinforcement learning environments for compiler tasks
CompilerGym is a library of easy to use and performant reinforcement learning environments for compiler tasks
 721 Jan 3, 2023
721 Jan 3, 2023

This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking".
SCT This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking" The spatial-channel Transformer (SCT) enhan
27 Nov 23, 2022
Audits Python environments and dependency trees for known vulnerabilities
pip-audit pip-audit is a prototype tool for scanning Python environments for packages with known vulnerabilities. It uses the Python Packaging Advisor
 701 Dec 28, 2022
701 Dec 28, 2022

Phy-Q: A Benchmark for Physical Reasoning
Phy-Q: A Benchmark for Physical Reasoning Cheng Xue*, Vimukthini Pinto*, Chathura Gamage* Ekaterina Nikonova, Peng Zhang, Jochen Renz School of Comput
 29 Dec 19, 2022
29 Dec 19, 2022

My published benchmark for a Kaggle Simulations Competition
Lux AI Working Title Bot Please refer to the Kaggle notebook for the comment section. The comment section contains my explanation on my code structure
 29 Aug 22, 2022
29 Aug 22, 2022
Conda package for artifact creation that enables offline environments. Ideal for air-gapped deployments.
Conda-Vendor Conda Vendor is a tool to create local conda channels and manifests for vendored deployments Installation To install with pip, run: pip i
 13 Nov 17, 2022
13 Nov 17, 2022
Model Quantization Benchmark
MQBench Update V0.0.2 Fix academic prepare setting. More deployable prepare process. Fix setup.py. Fix deploy on SNPE. Fix convert_deploy bug. Add Qua
 500 Jan 6, 2023
500 Jan 6, 2023

PyBullet CartPole and Quadrotor environments—with CasADi symbolic a priori dynamics—for learning-based control and reinforcement learning
safe-control-gym Physics-based CartPole and Quadrotor Gym environments (using PyBullet) with symbolic a priori dynamics (using CasADi) for learning-ba
 300 Dec 28, 2022
300 Dec 28, 2022

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 91 Nov 22, 2022
91 Nov 22, 2022
Cross Quality LFW: A database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Cross-Quality Labeled Faces in the Wild (XQLFW) Here, we release the database, evaluation protocol and code for the following paper: Cross Quality LFW
 10 Dec 12, 2022
10 Dec 12, 2022

A novel benchmark dataset for Monocular Layout prediction
AutoLay AutoLay: Benchmarking Monocular Layout Estimation Kaustubh Mani, N. Sai Shankar, J. Krishna Murthy, and K. Madhava Krishna Abstract In this pa
 39 Apr 26, 2022
39 Apr 26, 2022
Ranking Models in Unlabeled New Environments (iccv21)
Ranking Models in Unlabeled New Environments Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch 1.7.0 + torchivision 0.8.1
 14 Dec 17, 2021
14 Dec 17, 2021
CPU benchmark by calculating Pi, powered by Python3
cpu-benchmark Info: CPU benchmark by calculating Pi, powered by Python 3. Algorithm The program calculates pi with an accuracy of 10,000 decimal place
 20 Jan 3, 2023
20 Jan 3, 2023
The CLRS Algorithmic Reasoning Benchmark
Learning representations of algorithms is an emerging area of machine learning, seeking to bridge concepts from neural networks with classical algorithms.
 251 Jan 5, 2023
251 Jan 5, 2023
CARLA: A Python Library to Benchmark Algorithmic Recourse and Counterfactual Explanation Algorithms
CARLA - Counterfactual And Recourse Library CARLA is a python library to benchmark counterfactual explanation and recourse models. It comes out-of-the
 200 Dec 28, 2022
200 Dec 28, 2022
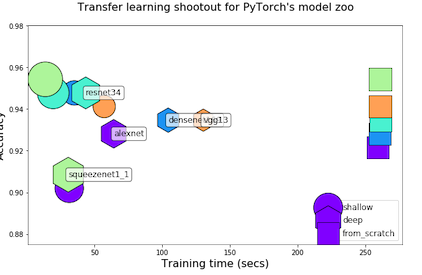
Transfer Learning Shootout for PyTorch's model zoo (torchvision)
pytorch-retraining Transfer Learning shootout for PyTorch's model zoo (torchvision). Load any pretrained model with custom final layer (num_classes) f
 169 Jun 29, 2022
169 Jun 29, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
176 Dec 28, 2022
![[Preprint]](https://github.com/VITA-Group/Deep_GCN_Benchmarking/raw/main/figs/combo.png)
[Preprint] "Bag of Tricks for Training Deeper Graph Neural Networks A Comprehensive Benchmark Study" by Tianlong Chen*, Kaixiong Zhou*, Keyu Duan, Wenqing Zheng, Peihao Wang, Xia Hu, Zhangyang Wang
Bag of Tricks for Training Deeper Graph Neural Networks: A Comprehensive Benchmark Study Codes for [Preprint] Bag of Tricks for Training Deeper Graph
 101 Dec 29, 2022
101 Dec 29, 2022
Pip-package for trajectory benchmarking from "Be your own Benchmark: No-Reference Trajectory Metric on Registered Point Clouds", ECMR'21
Map Metrics for Trajectory Quality Map metrics toolkit provides a set of metrics to quantitatively evaluate trajectory quality via estimating consiste
 31 Oct 28, 2022
31 Oct 28, 2022

HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021)
Code for HDR Video Reconstruction HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021) Guanying Chen, Cha
 64 Nov 19, 2022
64 Nov 19, 2022

FedScale: Benchmarking Model and System Performance of Federated Learning
FedScale: Benchmarking Model and System Performance of Federated Learning (Paper) This repository contains scripts and instructions of building FedSca
 268 Jan 1, 2023
268 Jan 1, 2023

ALFRED - A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
ALFRED A Benchmark for Interpreting Grounded Instructions for Everyday Tasks Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han,
 204 Dec 15, 2022
204 Dec 15, 2022
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark We propose a benchmark to evaluate different quantization algorithms on vari
494 Dec 29, 2022
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Disfl-QA is a targeted dataset for contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages. Disfl-QA builds upon the SQuAD-v2 (Rajpurkar et al., 2018) dataset, where each question in the dev set is annotated to add a contextual disfluency using the paragraph as a source of distractors.
 52 Jun 21, 2022
52 Jun 21, 2022
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022

Benchmark for evaluating open-ended generation
OpenMEVA Contributed by Jian Guan, Zhexin Zhang. Thank Jiaxin Wen for DeBugging. OpenMEVA is a benchmark for evaluating open-ended story generation me
 25 Nov 15, 2022
25 Nov 15, 2022
ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge (ManiSkill Challenge), a large-scale learning-from-demonstrations benchmark for object manipulation.
ManiSkill-Learn ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge, a large-scale learning-from-dem
 48 Dec 30, 2022
48 Dec 30, 2022
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022

SAPIEN Manipulation Skill Benchmark
ManiSkill Benchmark SAPIEN Manipulation Skill Benchmark (abbreviated as ManiSkill, pronounced as "Many Skill") is a large-scale learning-from-demonstr
107 Jan 8, 2023
Few-shot NLP benchmark for unified, rigorous eval
FLEX FLEX is a benchmark and framework for unified, rigorous few-shot NLP evaluation. FLEX enables: First-class NLP support Support for meta-training
 85 Dec 3, 2022
85 Dec 3, 2022
![[IJCAI-2021] A benchmark of data-free knowledge distillation from paper](https://github.com/zju-vipa/DataFree/raw/main/assets/cmi.png)
[IJCAI-2021] A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation"
DataFree A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation" Authors: Gongfa
 47 Jan 9, 2023
47 Jan 9, 2023

PyTorch implementations of deep reinforcement learning algorithms and environments
Deep Reinforcement Learning Algorithms with PyTorch This repository contains PyTorch implementations of deep reinforcement learning algorithms and env
 4.7k Jan 4, 2023
4.7k Jan 4, 2023
An open-access benchmark and toolbox for electricity price forecasting
epftoolbox The epftoolbox is the first open-access library for driving research in electricity price forecasting. Its main goal is to make available a
 97 Dec 5, 2022
97 Dec 5, 2022
MVP Benchmark for Multi-View Partial Point Cloud Completion and Registration
MVP Benchmark: Multi-View Partial Point Clouds for Completion and Registration [NEWS] 2021-07-12 [NEW 🎉 ] The submission on Codalab starts! 2021-07-1
 93 Dec 21, 2022
93 Dec 21, 2022

Brax is a differentiable physics engine that simulates environments made up of rigid bodies, joints, and actuators
Brax is a differentiable physics engine that simulates environments made up of rigid bodies, joints, and actuators. It's also a suite of learning algorithms to train agents to operate in these environments (PPO, SAC, evolutionary strategy, and direct trajectory optimization are implemented).
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

Motion Planner Augmented Reinforcement Learning for Robot Manipulation in Obstructed Environments (CoRL 2020)
Motion Planner Augmented Reinforcement Learning for Robot Manipulation in Obstructed Environments [Project website] [Paper] This project is a PyTorch
 49 Nov 28, 2022
49 Nov 28, 2022

gym-anm is a framework for designing reinforcement learning (RL) environments that model Active Network Management (ANM) tasks in electricity distribution networks.
gym-anm is a framework for designing reinforcement learning (RL) environments that model Active Network Management (ANM) tasks in electricity distribution networks. It is built on top of the OpenAI Gym toolkit.
 99 Dec 12, 2022
99 Dec 12, 2022
Generic Event Boundary Detection: A Benchmark for Event Segmentation
Generic Event Boundary Detection: A Benchmark for Event Segmentation We release our data annotation & baseline codes for detecting generic event bound
 47 Nov 22, 2022
47 Nov 22, 2022

Official Implement of CVPR 2021 paper “Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting”
RGBT Crowd Counting Lingbo Liu, Jiaqi Chen, Hefeng Wu, Guanbin Li, Chenglong Li, Liang Lin. "Cross-Modal Collaborative Representation Learning and a L
 37 Dec 8, 2022
37 Dec 8, 2022
Brax is a differentiable physics engine that simulates environments made up of rigid bodies, joints, and actuators
Brax is a differentiable physics engine that simulates environments made up of rigid bodies, joints, and actuators. It's also a suite of learning algorithms to train agents to operate in these environments (PPO, SAC, evolutionary strategy, and direct trajectory optimization are implemented).
1.5k Dec 31, 2022

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022

Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020)
GraspNet Baseline Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020). [paper] [dataset] [API] [do
 209 Dec 29, 2022
209 Dec 29, 2022

Manage python virtual environments on the working notebook server
notebook-environments Manage python virtual environments on the working notebook server. Installation It is recommended to use this package together w
 44 Nov 2, 2022
44 Nov 2, 2022

MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera
MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera
 494 Jan 6, 2023
494 Jan 6, 2023

NAS Benchmark in "Prioritized Architecture Sampling with Monto-Carlo Tree Search", CVPR2021
NAS-Bench-Macro This repository includes the benchmark and code for NAS-Bench-Macro in paper "Prioritized Architecture Sampling with Monto-Carlo Tree
 35 Jan 3, 2023
35 Jan 3, 2023

A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/casual, active/passive, and many more. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Styleformer A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/cas
 431 Dec 19, 2022
431 Dec 19, 2022

modelvshuman is a Python library to benchmark the gap between human and machine vision
modelvshuman is a Python library to benchmark the gap between human and machine vision. Using this library, both PyTorch and TensorFlow models can be evaluated on 17 out-of-distribution datasets with high-quality human comparison data.
 244 Jan 3, 2023
244 Jan 3, 2023
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022

Fusion-DHL: WiFi, IMU, and Floorplan Fusion for Dense History of Locations in Indoor Environments
Fusion-DHL: WiFi, IMU, and Floorplan Fusion for Dense History of Locations in Indoor Environments Paper: arXiv (ICRA 2021) Video : https://youtu.be/CC
 68 Jan 3, 2023
68 Jan 3, 2023

3D AffordanceNet is a 3D point cloud benchmark consisting of 23k shapes from 23 semantic object categories, annotated with 56k affordance annotations and covering 18 visual affordance categories.
3D AffordanceNet This repository is the official experiment implementation of 3D AffordanceNet benchmark. 3D AffordanceNet is a 3D point cloud benchma
 49 Dec 1, 2022
49 Dec 1, 2022
A list of hyperspectral image super-solution resources collected by Junjun Jiang
A list of hyperspectral image super-resolution resources collected by Junjun Jiang. If you find that important resources are not included, please feel free to contact me.
 301 Jan 5, 2023
301 Jan 5, 2023
[CVPR2021] UAV-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicles
UAV-Human Official repository for CVPR2021: UAV-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicle Paper arXiv Res
 129 Jan 4, 2023
129 Jan 4, 2023
RoboDesk A Multi-Task Reinforcement Learning Benchmark
RoboDesk A Multi-Task Reinforcement Learning Benchmark If you find this open source release useful, please reference in your paper: @misc{kannan2021ro
 66 Oct 7, 2022
66 Oct 7, 2022
The ABR Control library is a python package for the control and path planning of robotic arms in real or simulated environments.
The ABR Control library is a python package for the control and path planning of robotic arms in real or simulated environments. ABR Control provides API's for the Mujoco, CoppeliaSim (formerly known as VREP), and Pygame simulation environments, and arm configuration files for one, two, and three-joint models, as well as the UR5 and Kinova Jaco 2 arms. Users can also easily extend the package to run with custom arm configurations. ABR Control auto-generates efficient C code for generating the control signals, or uses Mujoco's internal functions to carry out the calculations.
 277 Jan 5, 2023
277 Jan 5, 2023

Visually distinguish environments in Django Admin
django-admin-env-notice Visually distinguish environments in Django Admin. Based on great advice from post: 5 ways to make Django Admin safer by hakib
 258 Nov 30, 2022
258 Nov 30, 2022
A Research-oriented Federated Learning Library and Benchmark Platform for Graph Neural Networks. Accepted to ICLR'2021 - DPML and MLSys'21 - GNNSys workshops.
FedGraphNN: A Federated Learning System and Benchmark for Graph Neural Networks A Research-oriented Federated Learning Library and Benchmark Platform
 175 Dec 1, 2022
175 Dec 1, 2022

 387 Jan 4, 2023
387 Jan 4, 2023
![[CVPR 2021 Oral] ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis](https://github.com/yinanhe/ForgeryNet/raw/main/images/abstract.png)
[CVPR 2021 Oral] ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis
ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis [arxiv|pdf|v
 78 Dec 22, 2022
78 Dec 22, 2022
OpenMMLab Pose Estimation Toolbox and Benchmark.
Introduction English | 简体中文 MMPose is an open-source toolbox for pose estimation based on PyTorch. It is a part of the OpenMMLab project. The master b
 2.8k Dec 31, 2022
2.8k Dec 31, 2022
OpenMMLab's Next Generation Video Understanding Toolbox and Benchmark
Introduction English | 简体中文 MMAction2 is an open-source toolbox for video understanding based on PyTorch. It is a part of the OpenMMLab project. The m
2.7k Jan 7, 2023
OpenMMLab Semantic Segmentation Toolbox and Benchmark.
Documentation: https://mmsegmentation.readthedocs.io/ English | 简体中文 Introduction MMSegmentation is an open source semantic segmentation toolbox based
5k Dec 31, 2022

Fast, modular reference implementation of Instance Segmentation and Object Detection algorithms in PyTorch.
Faster R-CNN and Mask R-CNN in PyTorch 1.0 maskrcnn-benchmark has been deprecated. Please see detectron2, which includes implementations for all model
9k Jan 4, 2023
A code repository associated with the paper A Benchmark for Rough Sketch Cleanup by Chuan Yan, David Vanderhaeghe, and Yotam Gingold from SIGGRAPH Asia 2020.
A Benchmark for Rough Sketch Cleanup This is the code repository associated with the paper A Benchmark for Rough Sketch Cleanup by Chuan Yan, David Va
 33 Dec 18, 2022
33 Dec 18, 2022

Open-L2O: A Comprehensive and Reproducible Benchmark for Learning to Optimize Algorithms
Open-L2O This repository establishes the first comprehensive benchmark efforts of existing learning to optimize (L2O) approaches on a number of proble
161 Jan 2, 2023
TableBank: A Benchmark Dataset for Table Detection and Recognition
TableBank TableBank is a new image-based table detection and recognition dataset built with novel weak supervision from Word and Latex documents on th
 844 Jan 4, 2023
844 Jan 4, 2023

Repository for Traffic Accident Benchmark for Causality Recognition (ECCV 2020)
Causality In Traffic Accident (Under Construction) Repository for Traffic Accident Benchmark for Causality Recognition (ECCV 2020) Overview Data Prepa
 21 Nov 20, 2022
21 Nov 20, 2022
![[ICLR 2021] HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark](https://github.com/RICE-EIC/HW-NAS-Bench/raw/main/devices.jpg?raw=true)
[ICLR 2021] HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark
HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark Accepted as a spotlight paper at ICLR 2021. Table of content File structure Prerequi
 72 Jan 3, 2023
72 Jan 3, 2023
OpenMMLab Detection Toolbox and Benchmark
MMDetection is an open source object detection toolbox based on PyTorch. It is a part of the OpenMMLab project.
22.5k Jan 5, 2023

Baselines for TrajNet++
TrajNet++ : The Trajectory Forecasting Framework PyTorch implementation of Human Trajectory Forecasting in Crowds: A Deep Learning Perspective TrajNet
 183 Jan 5, 2023
183 Jan 5, 2023
Beyond the Imitation Game collaborative benchmark for enormous language models
BIG-bench 🪑 The Beyond the Imitation Game Benchmark (BIG-bench) will be a collaborative benchmark intended to probe large language models, and extrap
1.3k Jan 1, 2023
![[ICLR 2021] Rank the Episodes: A Simple Approach for Exploration in Procedurally-Generated Environments.](https://github.com/daochenzha/rapid/raw/main/imgs/overview.png)
[ICLR 2021] Rank the Episodes: A Simple Approach for Exploration in Procedurally-Generated Environments.
[ICLR 2021] RAPID: A Simple Approach for Exploration in Reinforcement Learning This is the Tensorflow implementation of ICLR 2021 paper Rank the Episo
 48 Nov 21, 2022
48 Nov 21, 2022
Deploy tensorflow graphs for fast evaluation and export to tensorflow-less environments running numpy.
Deploy tensorflow graphs for fast evaluation and export to tensorflow-less environments running numpy. Now with tensorflow 1.0 support. Evaluation usa
 349 Aug 6, 2022
349 Aug 6, 2022
Simulation-Based Inference Benchmark
This repository contains a simulation-based inference benchmark framework, sbibm, which we describe in the associated manuscript "Benchmarking Simulation-based Inference".
 58 Oct 13, 2022
58 Oct 13, 2022

DeepMind Alchemy task environment: a meta-reinforcement learning benchmark
The DeepMind Alchemy environment is a meta-reinforcement learning benchmark that presents tasks sampled from a task distribution with deep underlying structure.
188 Dec 25, 2022
Selfplay In MultiPlayer Environments
This project allows you to train AI agents on custom-built multiplayer environments, through self-play reinforcement learning.
 200 Jan 8, 2023
200 Jan 8, 2023
Airspeed Velocity: A simple Python benchmarking tool with web-based reporting
airspeed velocity airspeed velocity (asv) is a tool for benchmarking Python packages over their lifetime. It is primarily designed to benchmark a sing
 745 Dec 28, 2022
745 Dec 28, 2022

py.test fixture for benchmarking code
Overview docs tests package A pytest fixture for benchmarking code. It will group the tests into rounds that are calibrated to the chosen timer. See c
 1k Jan 3, 2023
1k Jan 3, 2023
Install and Run Python Applications in Isolated Environments
pipx — Install and Run Python Applications in Isolated Environments Documentation: https://pipxproject.github.io/pipx/ Source Code: https://github.com
 5.8k Dec 31, 2022
5.8k Dec 31, 2022

Load and performance benchmark tool
Yandex Tank Yandextank has been moved to Python 3. Latest stable release for Python 2 here. Yandex.Tank is an extensible open source load testing tool
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
A machine learning benchmark of in-the-wild distribution shifts, with data loaders, evaluators, and default models.
WILDS is a benchmark of in-the-wild distribution shifts spanning diverse data modalities and applications, from tumor identification to wildlife monitoring to poverty mapping.
 437 Dec 30, 2022
437 Dec 30, 2022

Learning to Simulate Dynamic Environments with GameGAN (CVPR 2020)
Learning to Simulate Dynamic Environments with GameGAN PyTorch code for GameGAN Learning to Simulate Dynamic Environments with GameGAN Seung Wook Kim,
 199 Dec 26, 2022
199 Dec 26, 2022
An open source robotics benchmark for meta- and multi-task reinforcement learning
Meta-World Meta-World is an open-source simulated benchmark for meta-reinforcement learning and multi-task learning consisting of 50 distinct robotic
 823 Jan 6, 2023
823 Jan 6, 2023

Modular Deep Reinforcement Learning framework in PyTorch. Companion library of the book "Foundations of Deep Reinforcement Learning".
SLM Lab Modular Deep Reinforcement Learning framework in PyTorch. Documentation: https://slm-lab.gitbook.io/slm-lab/ BeamRider Breakout KungFuMaster M
 1.1k Dec 24, 2022
1.1k Dec 24, 2022
Safely pass trusted data to untrusted environments and back.
ItsDangerous ... so better sign this Various helpers to pass data to untrusted environments and to get it back safe and sound. Data is cryptographical
 2.6k Jan 1, 2023
2.6k Jan 1, 2023