390 Repositories
Python bert-embeddings Libraries
Language Models for the legal domain in Spanish done @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish legal domain Language Model ⚖️ This repository contains the page for two main resources for the Spanish legal domain: A RoBERTa model: https:/
 12 Nov 14, 2022
12 Nov 14, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrai
 77.4k Jan 5, 2023
77.4k Jan 5, 2023

PyABSA - Open & Efficient for Framework for Aspect-based Sentiment Analysis
PyABSA - Open & Efficient for Framework for Aspect-based Sentiment Analysis
 567 Jan 7, 2023
567 Jan 7, 2023

Example Of Fine-Tuning BERT For Named-Entity Recognition Task And Preparing For Cloud Deployment Using Flask, React, And Docker
Example Of Fine-Tuning BERT For Named-Entity Recognition Task And Preparing For Cloud Deployment Using Flask, React, And Docker This repository contai
 12 Dec 14, 2022
12 Dec 14, 2022
Solución al reto BBVA Contigo, Hack BBVA 2021
Solution Solución propuesta para el reto BBVA Contigo del Hackathon BBVA 2021. Equipo Mexdapy. Integrantes: David Pedroza Segoviano Regina Priscila Ba
 2 Dec 6, 2021
2 Dec 6, 2021
Bootstrapped Unsupervised Sentence Representation Learning (ACL 2021)
Install first pip3 install -e . Training python3 training/unsupervised_tuning.py python3 training/supervised_tuning.py python3 training/multilingual_
 26 Jul 22, 2022
26 Jul 22, 2022
BERT model training impelmentation using 1024 A100 GPUs for MLPerf Training v1.1
Pre-trained checkpoint and bert config json file Location of checkpoint and bert config json file This MLCommons members Google Drive location contain
 12 Apr 27, 2022
12 Apr 27, 2022

Code for reproducing our paper: LMSOC: An Approach for Socially Sensitive Pretraining
LMSOC: An Approach for Socially Sensitive Pretraining Code for reproducing the paper LMSOC: An Approach for Socially Sensitive Pretraining to appear a
 11 Dec 20, 2022
11 Dec 20, 2022
A Word Level Transformer layer based on PyTorch and 🤗 Transformers.
Transformer Embedder A Word Level Transformer layer based on PyTorch and 🤗 Transformers. How to use Install the library from PyPI: pip install transf
 27 Nov 20, 2022
27 Nov 20, 2022
[EMNLP 2021] Mirror-BERT: Converting Pretrained Language Models to universal text encoders without labels.
[EMNLP 2021] Mirror-BERT: Converting Pretrained Language Models to universal text encoders without labels.
 61 Dec 10, 2022
61 Dec 10, 2022

Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
 794 Dec 31, 2022
794 Dec 31, 2022
Vector AI — A platform for building vector based applications. Encode, query and analyse data using vectors.
Vector AI is a framework designed to make the process of building production grade vector based applications as quickly and easily as possible. Create
 267 Dec 23, 2022
267 Dec 23, 2022

EMNLP'2021: SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
 2.5k Dec 29, 2022
2.5k Dec 29, 2022

An NLP library with Awesome pre-trained Transformer models and easy-to-use interface, supporting wide-range of NLP tasks from research to industrial applications.
简体中文 | English News [2021-10-12] PaddleNLP 2.1版本已发布!新增开箱即用的NLP任务能力、Prompt Tuning应用示例与生成任务的高性能推理! 🎉 更多详细升级信息请查看Release Note。 [2021-08-22]《千言:面向事实一致性的生
 6.9k Jan 1, 2023
6.9k Jan 1, 2023

Mengzi Pretrained Models
中文 | English Mengzi 尽管预训练语言模型在 NLP 的各个领域里得到了广泛的应用,但是其高昂的时间和算力成本依然是一个亟需解决的问题。这要求我们在一定的算力约束下,研发出各项指标更优的模型。 我们的目标不是追求更大的模型规模,而是轻量级但更强大,同时对部署和工业落地更友好的模型。
 424 Jan 4, 2023
424 Jan 4, 2023
pytorch bert intent classification and slot filling
pytorch_bert_intent_classification_and_slot_filling 基于pytorch的中文意图识别和槽位填充 说明 基本思路就是:分类+序列标注(命名实体识别)同时训练。 使用的预训练模型:hugging face上的chinese-bert-wwm-ext 依
 33 Dec 15, 2022
33 Dec 15, 2022
Open & Efficient for Framework for Aspect-based Sentiment Analysis
PyABSA - Open & Efficient for Framework for Aspect-based Sentiment Analysis Fast & Low Memory requirement & Enhanced implementation of Local Context F
567 Jan 7, 2023
Code for ICML2019 Paper "Compositional Invariance Constraints for Graph Embeddings"
Dependencies NOTE: This code has been updated, if you were using this repo earlier and experienced issues that was due to an outaded codebase. Please
 43 Nov 25, 2022
43 Nov 25, 2022
SciBERT is a BERT model trained on scientific text.
SciBERT is a BERT model trained on scientific text.
 1.2k Dec 24, 2022
1.2k Dec 24, 2022
Converting CPT to bert form for use
cpt-encoder 将CPT转成bert形式使用 说明 刚刚刷到又出了一种模型:CPT,看论文显示,在很多中文任务上性能比mac bert还好,就迫不及待想把它用起来。 根据对源码的研究,发现该模型在做nlu建模时主要用的encoder部分,也就是bert,因此我将这部分权重转为bert权重类型
 1 Oct 14, 2021
1 Oct 14, 2021
Using contrastive learning and OpenAI's CLIP to find good embeddings for images with lossy transformations
Creating Robust Representations from Pre-Trained Image Encoders using Contrastive Learning Sriram Ravula, Georgios Smyrnis This is the code for our pr
 26 Dec 10, 2022
26 Dec 10, 2022
Implementation of BI-RADS-BERT & The Advantages of Section Tokenization.
BI-RADS BERT Implementation of BI-RADS-BERT & The Advantages of Section Tokenization. This implementation could be used on other radiology in house co
 1 May 17, 2022
1 May 17, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
Pre-training BERT masked language models with custom vocabulary
Pre-training BERT Masked Language Models (MLM) This repository contains the method to pre-train a BERT model using custom vocabulary. It was used to p
 14 Nov 2, 2022
14 Nov 2, 2022
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022

Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
 730 Jan 9, 2023
730 Jan 9, 2023
Pre-trained BERT Models for Ancient and Medieval Greek, and associated code for LaTeCH 2021 paper titled - "A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek"
Ancient Greek BERT The first and only available Ancient Greek sub-word BERT model! State-of-the-art post fine-tuning on Part-of-Speech Tagging and Mor
 22 Dec 8, 2022
22 Dec 8, 2022

Implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTorch
Neural Distance Embeddings for Biological Sequences Official implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTo
 56 Dec 23, 2022
56 Dec 23, 2022
Code and data form the paper BERT Got a Date: Introducing Transformers to Temporal Tagging
BERT Got a Date: Introducing Transformers to Temporal Tagging Satya Almasian*, Dennis Aumiller*, and Michael Gertz Heidelberg University Contact us vi
 54 Dec 4, 2022
54 Dec 4, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
77.2k Jan 2, 2023

A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
 488 Nov 28, 2022
488 Nov 28, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
 586 Dec 24, 2022
586 Dec 24, 2022

PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
 1.6k Dec 25, 2022
1.6k Dec 25, 2022
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
730 Jan 9, 2023
Original implementation of the pooling method introduced in "Speaker embeddings by modeling channel-wise correlations"
Speaker-Embeddings-Correlation-Pooling This is the original implementation of the pooling method introduced in "Speaker embeddings by modeling channel
 10 Apr 30, 2022
10 Apr 30, 2022
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
Applying "Load What You Need: Smaller Versions of Multilingual BERT" to LaBSE
smaller-LaBSE LaBSE(Language-agnostic BERT Sentence Embedding) is a very good method to get sentence embeddings across languages. But it is hard to fi
 13 Sep 2, 2022
13 Sep 2, 2022
Natural Language Processing with transformers
we want to create a repo to illustrate usage of transformers in chinese
 763 Dec 27, 2022
763 Dec 27, 2022

Embeddinghub is a database built for machine learning embeddings.
Embeddinghub is a database built for machine learning embeddings.
 1.2k Jan 1, 2023
1.2k Jan 1, 2023
Pytorch-version BERT-flow: One can apply BERT-flow to any PLM within Pytorch framework.
Pytorch-version BERT-flow: One can apply BERT-flow to any PLM within Pytorch framework.
 59 Dec 1, 2022
59 Dec 1, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
 30 Dec 12, 2022
30 Dec 12, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
超轻量级bert的pytorch版本,大量中文注释,容易修改结构,持续更新
bert4pytorch 2021年8月27更新: 感谢大家的star,最近有小伙伴反映了一些小的bug,我也注意到了,奈何这个月工作上实在太忙,更新不及时,大约会在9月中旬集中更新一个只需要pip一下就完全可用的版本,然后会新添加一些关键注释。 再增加对抗训练的内容,更新一个完整的finetune
 317 Dec 18, 2022
317 Dec 18, 2022

Ongoing research training transformer language models at scale, including: BERT & GPT-2
Megatron (1 and 2) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA.
 3.5k Dec 30, 2022
3.5k Dec 30, 2022
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022

A BERT-based reverse dictionary of Korean proverbs
Wisdomify A BERT-based reverse-dictionary of Korean proverbs. 김유빈 : 모델링 / 데이터 수집 / 프로젝트 설계 / back-end 김종윤 : 데이터 수집 / 프로젝트 설계 / front-end / back-end 임용
 94 Dec 8, 2022
94 Dec 8, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

Learning Compatible Embeddings, ICCV 2021
LCE Learning Compatible Embeddings, ICCV 2021 by Qiang Meng, Chixiang Zhang, Xiaoqiang Xu and Feng Zhou Paper: Arxiv We cannot release source codes pu
 25 Dec 17, 2022
25 Dec 17, 2022
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023
Large scale embeddings on a single machine.
Marius Marius is a system under active development for training embeddings for large-scale graphs on a single machine. Training on large scale graphs
 107 Jan 3, 2023
107 Jan 3, 2023

Using VideoBERT to tackle video prediction
VideoBERT This repo reproduces the results of VideoBERT (https://arxiv.org/pdf/1904.01766.pdf). Inspiration was taken from https://github.com/MDSKUL/M
 75 Dec 14, 2022
75 Dec 14, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023

Punctuation Restoration using Transformer Models for High-and Low-Resource Languages
Punctuation Restoration using Transformer Models This repository contins official implementation of the paper Punctuation Restoration using Transforme
 142 Jan 1, 2023
142 Jan 1, 2023
Versatile Generative Language Model
Versatile Generative Language Model This is the implementation of the paper: Exploring Versatile Generative Language Model Via Parameter-Efficient Tra
 17 Dec 2, 2022
17 Dec 2, 2022
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
 14 Dec 17, 2022
14 Dec 17, 2022
PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
1.6k Dec 29, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
586 Dec 24, 2022
A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
488 Nov 28, 2022
Implementing SimCSE(paper, official repository) using TensorFlow 2 and KR-BERT.
KR-BERT-SimCSE Implementing SimCSE(paper, official repository) using TensorFlow 2 and KR-BERT. Training Unsupervised python train_unsupervised.py --mi
27 Dec 12, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022

Learned Token Pruning for Transformers
LTP: Learned Token Pruning for Transformers Check our paper for more details. Installation We follow the same installation procedure as the original H
 52 Dec 29, 2022
52 Dec 29, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
77.2k Jan 3, 2023

A PyTorch Implementation of "Watch Your Step: Learning Node Embeddings via Graph Attention" (NeurIPS 2018).
Attention Walk ⠀⠀ A PyTorch Implementation of Watch Your Step: Learning Node Embeddings via Graph Attention (NIPS 2018). Abstract Graph embedding meth
 303 Dec 9, 2022
303 Dec 9, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
203 Dec 20, 2022
DRIFT is a tool for Diachronic Analysis of Scientific Literature.
About DRIFT is a tool for Diachronic Analysis of Scientific Literature. The application offers user-friendly and customizable utilities for two modes:
 108 Dec 12, 2022
108 Dec 12, 2022

A heterogeneous entity-augmented academic language model based on Open Academic Graph (OAG)
Library | Paper | Slack We released two versions of OAG-BERT in CogDL package. OAG-BERT is a heterogeneous entity-augmented academic language model wh
 58 Dec 17, 2022
58 Dec 17, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 43 Nov 21, 2022
43 Nov 21, 2022

Official repository for the paper, MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding.
MidiBERT-Piano Authors: Yi-Hui (Sophia) Chou, I-Chun (Bronwin) Chen Introduction This is the official repository for the paper, MidiBERT-Piano: Large-
 137 Dec 15, 2022
137 Dec 15, 2022
Implementation of Rotary Embeddings, from the Roformer paper, in Pytorch
Rotary Embeddings - Pytorch A standalone library for adding rotary embeddings to transformers in Pytorch, following its success as relative positional
 110 Dec 30, 2022
110 Dec 30, 2022
🤖 A Python library for learning and evaluating knowledge graph embeddings
PyKEEN PyKEEN (Python KnowlEdge EmbeddiNgs) is a Python package designed to train and evaluate knowledge graph embedding models (incorporating multi-m
 1.1k Jan 9, 2023
1.1k Jan 9, 2023

VD-BERT: A Unified Vision and Dialog Transformer with BERT
VD-BERT: A Unified Vision and Dialog Transformer with BERT PyTorch Code for the following paper at EMNLP2020: Title: VD-BERT: A Unified Vision and Dia
 44 Nov 1, 2022
44 Nov 1, 2022
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022
VD-BERT: A Unified Vision and Dialog Transformer with BERT
VD-BERT: A Unified Vision and Dialog Transformer with BERT PyTorch Code for the following paper at EMNLP2020: Title: VD-BERT: A Unified Vision and Dia
44 Nov 1, 2022
Shared code for training sentence embeddings with Flax / JAX
flax-sentence-embeddings This repository will be used to share code for the Flax / JAX community event to train sentence embeddings on 1B+ training pa
 23 Dec 30, 2022
23 Dec 30, 2022
Huggingface Transformers + Adapters = ❤️
adapter-transformers A friendly fork of HuggingFace's Transformers, adding Adapters to PyTorch language models adapter-transformers is an extension of
 1.2k Jan 9, 2023
1.2k Jan 9, 2023
The source codes for ACL 2021 paper 'BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data'
BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data This repository provides the implementation details for
 124 Dec 27, 2022
124 Dec 27, 2022
PyTorch impelementations of BERT-based Spelling Error Correction Models
PyTorch impelementations of BERT-based Spelling Error Correction Models
 59 Jun 29, 2021
59 Jun 29, 2021
PyTorch impelementations of BERT-based Spelling Error Correction Models.
PyTorch impelementations of BERT-based Spelling Error Correction Models. 基于BERT的文本纠错模型,使用PyTorch实现。
209 Dec 30, 2022

A BERT-based reverse-dictionary of Korean proverbs
Wisdomify A BERT-based reverse-dictionary of Korean proverbs. 김유빈 : 모델링 / 데이터 수집 / 프로젝트 설계 / back-end 김종윤 : 데이터 수집 / 프로젝트 설계 / front-end Quick Start C
 94 Dec 8, 2022
94 Dec 8, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
 99 Dec 23, 2022
99 Dec 23, 2022
LV-BERT: Exploiting Layer Variety for BERT (Findings of ACL 2021)
LV-BERT Introduction In this repo, we introduce LV-BERT by exploiting layer variety for BERT. For detailed description and experimental results, pleas
 14 Aug 24, 2022
14 Aug 24, 2022
LV-BERT: Exploiting Layer Variety for BERT (Findings of ACL 2021)
LV-BERT Introduction In this repo, we introduce LV-BERT by exploiting layer variety for BERT. For detailed description and experimental results, pleas
14 Aug 24, 2022

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022

UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus
UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus General info This is
 71 Oct 25, 2022
71 Oct 25, 2022

Reliable probability face embeddings
ProbFace, arxiv This is a demo code of training and testing [ProbFace] using Tensorflow. ProbFace is a reliable Probabilistic Face Embeddging (PFE) me
 34 Dec 31, 2022
34 Dec 31, 2022
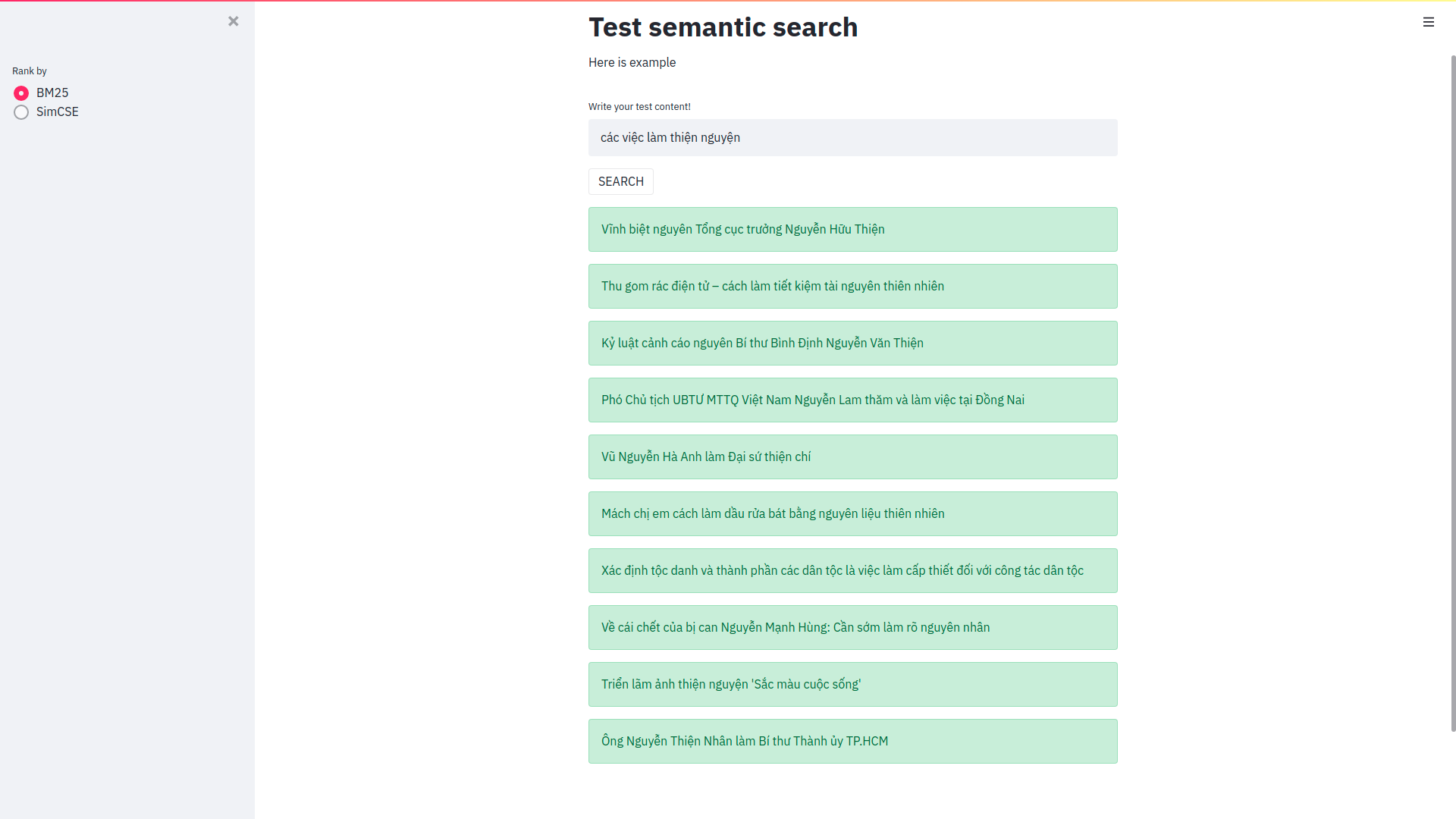
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings Trong bài viết này mình sẽ sử dụng pretrain model SimCS
 18 Nov 25, 2022
18 Nov 25, 2022
Python Implementation of ``Modeling the Influence of Verb Aspect on the Activation of Typical Event Locations with BERT'' (Findings of ACL: ACL 2021)
BERT-for-Surprisal Python Implementation of ``Modeling the Influence of Verb Aspect on the Activation of Typical Event Locations with BERT'' (Findings
 7 Dec 5, 2022
7 Dec 5, 2022
Baseline code for Korean open domain question answering(ODQA)
Open-Domain Question Answering(ODQA)는 다양한 주제에 대한 문서 집합으로부터 자연어 질의에 대한 답변을 찾아오는 task입니다. 이때 사용자 질의에 답변하기 위해 주어지는 지문이 따로 존재하지 않습니다. 따라서 사전에 구축되어있는 Knowl
 69 Nov 4, 2022
69 Nov 4, 2022
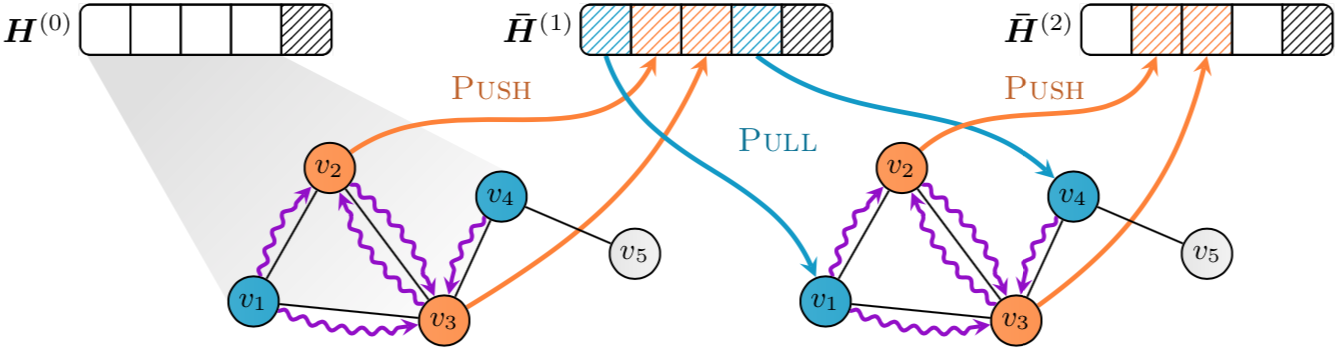
Implementation of "GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings" in PyTorch
PyGAS: Auto-Scaling GNNs in PyG PyGAS is the practical realization of our G NN A uto S cale (GAS) framework, which scales arbitrary message-passing GN
 139 Dec 25, 2022
139 Dec 25, 2022

The official implementation of You Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient.
You Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient (paper) @misc{zhang2021compress,
 46 Dec 7, 2022
46 Dec 7, 2022

Source code for NAACL 2021 paper "TR-BERT: Dynamic Token Reduction for Accelerating BERT Inference"
TR-BERT Source code and dataset for "TR-BERT: Dynamic Token Reduction for Accelerating BERT Inference". The code is based on huggaface's transformers.
 37 Oct 30, 2022
37 Oct 30, 2022
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022