209 Repositories
Python calculate-statistics Libraries
Distance correlation and related E-statistics in Python
dcor dcor: distance correlation and related E-statistics in Python. E-statistics are functions of distances between statistical observations in metric
 108 Dec 27, 2022
108 Dec 27, 2022
Computations and statistics on manifolds with geometric structures.
Geomstats Code Continuous Integration Code coverage (numpy) Code coverage (autograd, tensorflow, pytorch) Documentation Community NEWS: Geomstats is r
 875 Dec 31, 2022
875 Dec 31, 2022
Kats, a kit to analyze time series data, a lightweight, easy-to-use, generalizable, and extendable framework to perform time series analysis, from understanding the key statistics and characteristics, detecting change points and anomalies, to forecasting future trends.
Description Kats is a toolkit to analyze time series data, a lightweight, easy-to-use, and generalizable framework to perform time series analysis. Ti
 4.1k Jan 9, 2023
4.1k Jan 9, 2023

Statistical and Algorithmic Investing Strategies for Everyone
Eiten - Algorithmic Investing Strategies for Everyone Eiten is an open source toolkit by Tradytics that implements various statistical and algorithmic
 2.5k Jan 2, 2023
2.5k Jan 2, 2023
🌊 River is a Python library for online machine learning.
River is a Python library for online machine learning. It is the result of a merger between creme and scikit-multiflow. River's ambition is to be the go-to library for doing machine learning on streaming data.
 4k Jan 3, 2023
4k Jan 3, 2023
A collection of video resources for machine learning
Machine Learning Videos This is a collection of recorded talks at machine learning conferences, workshops, seminars, summer schools, and miscellaneous
 1.5k Dec 29, 2022
1.5k Dec 29, 2022
A paper using optimal transport to solve the graph matching problem.
GOAT A paper using optimal transport to solve the graph matching problem. https://arxiv.org/abs/2111.05366 Repo structure .github: Files specifying ho
 8 Jan 4, 2023
8 Jan 4, 2023
Important dataframe statistics with a single command
quick_eda Receiving dataframe statistics with one command Project description A python package for Data Scientists, Students, ML Engineers and anyone
 2 Dec 19, 2021
2 Dec 19, 2021
Code for "Long Range Probabilistic Forecasting in Time-Series using High Order Statistics"
Long Range Probabilistic Forecasting in Time-Series using High Order Statistics This is the code produced as part of the paper Long Range Probabilisti
 16 Dec 6, 2022
16 Dec 6, 2022
ecoglib: visualization and statistics for high density microecog signals
ecoglib: visualization and statistics for high density microecog signals This library contains high-level analysis tools for "topos" and "chronos" asp
 1 Nov 17, 2021
1 Nov 17, 2021

Small project to recursively calculate and plot each successive order of the Hilbert Curve
hilbert-curve Small project to recursively calculate and plot each successive order of the Hilbert Curve. After watching 3Blue1Brown's video on Hilber
 2 Nov 15, 2021
2 Nov 15, 2021
This is a tool to calculate a resulting color of the alpha blending process.
blec: alpha blending calculator This is a tool to calculate a resulting color of the alpha blending process. A gamma correction is enabled and the def
 12 Sep 7, 2022
12 Sep 7, 2022

Data science, Data manipulation and Machine learning package.
duality Data science, Data manipulation and Machine learning package. Use permitted according to the terms of use and conditions set by the attached l
 3 Oct 19, 2022
3 Oct 19, 2022

Flames Calculater App used to calculate flames status between two names created using python's Flask web framework.
Flames Finder Web App Flames Calculater App used to calculate flames status between two names created using python's Flask web framework. First, App g
 4 Jan 2, 2022
4 Jan 2, 2022
A python package which can be pip installed to perform statistics and visualize binomial and gaussian distributions of the dataset
GBiStat package A python package to assist programmers with data analysis. This package could be used to plot : Binomial Distribution of the dataset p
 4 Oct 17, 2022
4 Oct 17, 2022
Working Time Statistics of working hours and working conditions by industry and company
Working Time Statistics of working hours and working conditions by industry and company
 88 Nov 4, 2022
88 Nov 4, 2022
A bot to get Statistics like the Playercount from your Minecraft-Server on your Discord-Server
Hey Thanks for reading me. Warning: My English is not the best I have programmed this bot to show me statistics about the player numbers and ping of m
 12 Sep 24, 2022
12 Sep 24, 2022

Command-line interface to PyPI Stats API to get download stats for Python packages
pypistats Python 3.6+ interface to PyPI Stats API to get aggregate download statistics on Python packages on the Python Package Index without having t
 140 Jan 3, 2023
140 Jan 3, 2023

pypinfo is a simple CLI to access PyPI download statistics via Google's BigQuery.
pypinfo: View PyPI download statistics with ease. pypinfo is a simple CLI to access PyPI download statistics via Google's BigQuery. Installation pypin
 351 Dec 26, 2022
351 Dec 26, 2022
Can a machine learning project be implemented to estimate the salaries of baseball players whose salary information and career statistics for 1986 are shared?
END TO END MACHINE LEARNING PROJECT ON HITTERS DATASET Can a machine learning project be implemented to estimate the salaries of baseball players whos
 7 Dec 18, 2021
7 Dec 18, 2021
K-means clustering is a method used for clustering analysis, especially in data mining and statistics.
K Means Algorithm What is K Means This algorithm is an iterative algorithm that partitions the dataset according to their features into K number of pr
 1 Nov 1, 2021
1 Nov 1, 2021
This is a python package that turns any images into MIDI files that views the same as them
image_to_midi This is a python package that turns any images into MIDI files that views the same as them. This package firstly convert the image to AS
 4 Mar 10, 2022
4 Mar 10, 2022

Created as part of CS50 AI's coursework. This AI makes use of knowledge entailment to calculate the best probabilities to win Minesweeper.
Minesweeper-AI Created as part of CS50 AI's coursework. This AI makes use of knowledge entailment to calculate the best probabilities to win Minesweep
 0 Jul 20, 2022
0 Jul 20, 2022
Adaptive, interpretable wavelets across domains (NeurIPS 2021)
Adaptive wavelets Wavelets which adapt given data (and optionally a pre-trained model). This yields models which are faster, more compressible, and mo
 50 Dec 16, 2022
50 Dec 16, 2022
BasstatPL is a package for performing different tabulations and calculations for descriptive statistics.
BasstatPL is a package for performing different tabulations and calculations for descriptive statistics. It provides: Frequency table constr
 1 Oct 31, 2021
1 Oct 31, 2021

topalias - Linux alias generator from bash/zsh command history with statistics, written on Python.
topalias topalias - Linux alias generator from bash/zsh command history with statistics, written on Python. Features Generate short alias for popular
 38 May 26, 2022
38 May 26, 2022
PyImpetus is a Markov Blanket based feature subset selection algorithm that considers features both separately and together as a group in order to provide not just the best set of features but also the best combination of features
PyImpetus PyImpetus is a Markov Blanket based feature selection algorithm that selects a subset of features by considering their performance both indi
 103 Dec 14, 2022
103 Dec 14, 2022
Focal Statistics
Focal-Statistics The Focal statistics tool in many GIS applications like ArcGIS, QGIS and GRASS GIS is a standard method to gain a local overview of r
 1 Oct 21, 2021
1 Oct 21, 2021
Small Python script to parse endlessh's output and print some neat statistics
endlessh_parser endlessh_parser is a small Python script that parses endlessh's output and prints some neat statistics about it Usage Install all the
 1 Oct 18, 2021
1 Oct 18, 2021
High-quality implementations of standard and SOTA methods on a variety of tasks.
Uncertainty Baselines The goal of Uncertainty Baselines is to provide a template for researchers to build on. The baselines can be a starting point fo
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
StudyLion is a Discord bot that tracks members' study and work time while offering members to view their statistics and use productivity tools such as: To-do lists, Pomodoro timers, reminders, and much more.
StudyLion - Discord Productivity Bot StudyLion is a Discord bot that tracks members' study and work time while offering members the ability to view th
 45 Dec 26, 2022
45 Dec 26, 2022
Tindicators is a Python library to calculate the values of various technical indicators
Tindicators is a Python library to calculate the values of various technical indicators
 3 Mar 3, 2022
3 Mar 3, 2022
A repository for collating all the resources such as articles, blogs, papers, and books related to Bayesian Statistics.
A repository for collating all the resources such as articles, blogs, papers, and books related to Bayesian Statistics.
 80 Dec 12, 2022
80 Dec 12, 2022
wikirepo is a Python package that provides a framework to easily source and leverage standardized Wikidata information
Python based Wikidata framework for easy dataframe extraction wikirepo is a Python package that provides a framework to easily source and leverage sta
 35 Jan 4, 2023
35 Jan 4, 2023

Better GitHub statistics images for your profile, with stats from private and public repos
Better GitHub statistics images for your profile, with stats from private and public repos
 2k Dec 30, 2022
2k Dec 30, 2022
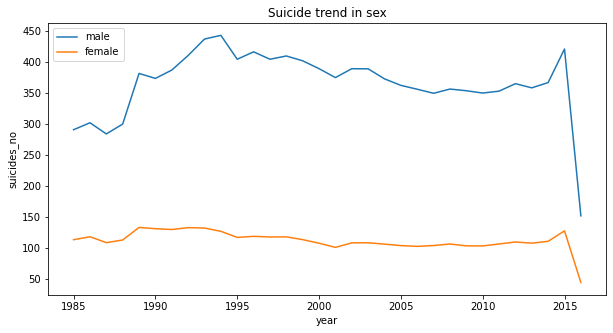
Statistical Analysis 📈 focused on statistical analysis and exploration used on various data sets for personal and professional projects.
Statistical Analysis 📈 This repository focuses on statistical analysis and the exploration used on various data sets for personal and professional pr
 1 Sep 3, 2022
1 Sep 3, 2022

A data analysis using python and pandas to showcase trends in school performance.
A data analysis using python and pandas to showcase trends in school performance. A data analysis to showcase trends in school performance using Panda
 0 Sep 7, 2021
0 Sep 7, 2021
Module to use some statistics from Spotify API
statify Module to use some statistics from Spotify API To use it you have to import the functions into your own project. You have also to authenticate
 2 Jun 2, 2022
2 Jun 2, 2022

A tool to allow New World players to calculate the best place to put their Attribute Points for their build and level
New World Damage Simulator A tool designed to take a characters base stats including armor and weapons, level, and base damage of their items (slash d
 31 Nov 1, 2022
31 Nov 1, 2022
Graphsignal is a machine learning model monitoring platform.
Graphsignal is a machine learning model monitoring platform. It helps ML engineers, MLOps teams and data scientists to quickly address issues with data and models as well as proactively analyze model performance and availability.
 143 Dec 5, 2022
143 Dec 5, 2022
Fuzzy string matching like a boss. It uses Levenshtein Distance to calculate the differences between sequences in a simple-to-use package.
Fuzzy string matching like a boss. It uses Levenshtein Distance to calculate the differences between sequences in a simple-to-use package.
 1.2k Jan 1, 2023
1.2k Jan 1, 2023

distfit - Probability density fitting
Python package for probability density function fitting of univariate distributions of non-censored data
 187 Dec 30, 2022
187 Dec 30, 2022

Using / reproducing ACD from the paper "Hierarchical interpretations for neural network predictions" 🧠 (ICLR 2019)
Hierarchical neural-net interpretations (ACD) 🧠 Produces hierarchical interpretations for a single prediction made by a pytorch neural network. Offic
 111 Jan 3, 2023
111 Jan 3, 2023
A discord bot for tracking Iranian Minecraft servers and showing the statistics of them
A discord bot for tracking Iranian Minecraft servers and showing the statistics of them
 20 Dec 30, 2022
20 Dec 30, 2022
Functional Data Analysis, or FDA, is the field of Statistics that analyses data that depend on a continuous parameter.
Functional Data Analysis Python package
 184 Dec 27, 2022
184 Dec 27, 2022
scrilla: A Financial Optimization Application
A python application that wraps around AlphaVantage, Quandl and IEX APIs, calculates financial statistics and optimizes portfolio allocations.
 6 Dec 17, 2022
6 Dec 17, 2022

skimpy is a light weight tool that provides summary statistics about variables in data frames within the console.
skimpy Welcome Welcome to skimpy! skimpy is a light weight tool that provides summary statistics about variables in data frames within the console. Th
 267 Dec 29, 2022
267 Dec 29, 2022
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022

track your GitHub statistics
GitHub-Stalker track your github statistics 👀 features find new followers or unfollowers find who got a star on your project or remove stars find who
 34 Nov 18, 2022
34 Nov 18, 2022

Monitor and log Network and Disks statistics in MegaBytes per second.
iometrics Monitor and log Network and Disks statistics in MegaBytes per second. Install pip install iometrics Usage Pytorch-lightning integration from
 17 May 3, 2022
17 May 3, 2022
peace-performance (Rust) binding for python. To calculate star ratings and performance points for all osu! gamemodes
peace-performance-python Fast, To calculate star ratings and performance points for all osu! gamemodes peace-performance (Rust) binding for python bas
 9 Sep 19, 2022
9 Sep 19, 2022

Pytorch implementation of CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generation"
MUST-GAN Code | paper The Pytorch implementation of our CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generat
 46 Dec 26, 2022
46 Dec 26, 2022
A simple, transparent, open-source key logger, written in Python, for tracking your own key-usage statistics.
A simple, transparent, open-source key logger, written in Python, for tracking your own key-usage statistics, originally intended for keyboard layout optimization.
 56 Jan 3, 2023
56 Jan 3, 2023
Custom component to calculate estimated power consumption of lights and other appliances
Custom component to calculate estimated power consumption of lights and other appliances. Provides easy configuration to get virtual power consumption sensors in Home Assistant for all your devices which don't have a build in power meter.
 552 Dec 28, 2022
552 Dec 28, 2022
A corona statistics and information telegram bot.
A corona statistics and information telegram bot.
 15 Oct 21, 2022
15 Oct 21, 2022
MDAnalysis tool to calculate membrane curvature.
The MDAkit for membrane curvature analysis is part of the Google Summer of Code program and it is linked to a Code of Conduct.
 19 Oct 20, 2022
19 Oct 20, 2022

COVID-19 deaths statistics around the world
COVID-19-Deaths-Dataset COVID-19 deaths statistics around the world This is a daily updated dataset of COVID-19 deaths around the world. The dataset c
 4 Jul 10, 2022
4 Jul 10, 2022

Statistics and Visualization of acceptance rate, main keyword of CVPR 2021 accepted papers for the main Computer Vision conference (CVPR)
Statistics and Visualization of acceptance rate, main keyword of CVPR 2021 accepted papers for the main Computer Vision conference (CVPR)
 78 Aug 23, 2022
78 Aug 23, 2022

This little tool is to calculate a MurmurHash value of a favicon to hunt phishing websites on the Shodan platform.
MurMurHash This little tool is to calculate a MurmurHash value of a favicon to hunt phishing websites on the Shodan platform. What is MurMurHash? Murm
 87 Dec 31, 2022
87 Dec 31, 2022

Graphsignal Logger
Graphsignal Logger Overview Graphsignal is an observability platform for monitoring and troubleshooting production machine learning applications. It h
143 Dec 5, 2022

Prometheus exporter for several chia node statistics
prometheus-chia-exporter Prometheus exporter for several chia node statistics It's assumed that the full node, the harvester and the wallet run on the
 30 Sep 19, 2022
30 Sep 19, 2022
Statsmodels: statistical modeling and econometrics in Python
About statsmodels statsmodels is a Python package that provides a complement to scipy for statistical computations including descriptive statistics an
 8.1k Dec 30, 2022
8.1k Dec 30, 2022
Domain Generalization with MixStyle, ICLR'21.
MixStyle This repo contains the code of our ICLR'21 paper, "Domain Generalization with MixStyle". The OpenReview link is https://openreview.net/forum?
 208 Dec 28, 2022
208 Dec 28, 2022
One Stop Anomaly Shop: Anomaly detection using two-phase approach: (a) pre-labeling using statistics, Natural Language Processing and static rules; (b) anomaly scoring using supervised and unsupervised machine learning.
One Stop Anomaly Shop (OSAS) Quick start guide Step 1: Get/build the docker image Option 1: Use precompiled image (might not reflect latest changes):
 148 Dec 26, 2022
148 Dec 26, 2022
A complete guide to start and improve in machine learning (ML)
A complete guide to start and improve in machine learning (ML), artificial intelligence (AI) in 2021 without ANY background in the field and stay up-to-date with the latest news and state-of-the-art techniques!
 3.3k Jan 4, 2023
3.3k Jan 4, 2023
Calculate the area inside of any GeoJSON geometry. This is a port of Mapbox's geojson-area for Python
geojson-area Calculate the area inside of any GeoJSON geometry. This is a port of Mapbox's geojson-area for Python. Installation $ pip install area U
 87 Dec 14, 2022
87 Dec 14, 2022

Summary statistics of geospatial raster datasets based on vector geometries.
rasterstats rasterstats is a Python module for summarizing geospatial raster datasets based on vector geometries. It includes functions for zonal stat
 437 Dec 23, 2022
437 Dec 23, 2022
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton.
Boltons boltons should be builtins. Boltons is a set of over 230 BSD-licensed, pure-Python utilities in the same spirit as — and yet conspicuously mis
 6k Jan 4, 2023
6k Jan 4, 2023
Statistical package in Python based on Pandas
Pingouin is an open-source statistical package written in Python 3 and based mostly on Pandas and NumPy. Some of its main features are listed below. F
 1.2k Dec 31, 2022
1.2k Dec 31, 2022
A probabilistic programming language in TensorFlow. Deep generative models, variational inference.
Edward is a Python library for probabilistic modeling, inference, and criticism. It is a testbed for fast experimentation and research with probabilis
 4.7k Jan 9, 2023
4.7k Jan 9, 2023
Python Library for learning (Structure and Parameter) and inference (Statistical and Causal) in Bayesian Networks.
pgmpy pgmpy is a python library for working with Probabilistic Graphical Models. Documentation and list of algorithms supported is at our official sit
 2.2k Dec 25, 2022
2.2k Dec 25, 2022
Gaussian processes in TensorFlow
Website | Documentation (release) | Documentation (develop) | Glossary Table of Contents What does GPflow do? Installation Getting Started with GPflow
 1.7k Jan 6, 2023
1.7k Jan 6, 2023
Probabilistic reasoning and statistical analysis in TensorFlow
TensorFlow Probability TensorFlow Probability is a library for probabilistic reasoning and statistical analysis in TensorFlow. As part of the TensorFl
 3.8k Jan 5, 2023
3.8k Jan 5, 2023
A Python Package to Tackle the Curse of Imbalanced Datasets in Machine Learning
imbalanced-learn imbalanced-learn is a python package offering a number of re-sampling techniques commonly used in datasets showing strong between-cla
 6.2k Jan 1, 2023
6.2k Jan 1, 2023

A python library for Bayesian time series modeling
PyDLM Welcome to pydlm, a flexible time series modeling library for python. This library is based on the Bayesian dynamic linear model (Harrison and W
 438 Dec 17, 2022
438 Dec 17, 2022
Supply a wrapper ``StockDataFrame`` based on the ``pandas.DataFrame`` with inline stock statistics/indicators support.
Stock Statistics/Indicators Calculation Helper VERSION: 0.3.2 Introduction Supply a wrapper StockDataFrame based on the pandas.DataFrame with inline s
 1.1k Dec 28, 2022
1.1k Dec 28, 2022

Implementation of Kalman Filter in Python
Kalman Filter in Python This is a basic example of how Kalman filter works in Python. I do plan on refactoring and expanding this repo in the future.
 35 Sep 11, 2022
35 Sep 11, 2022
Multiple Pairwise Comparisons (Post Hoc) Tests in Python
scikit-posthocs is a Python package that provides post hoc tests for pairwise multiple comparisons that are usually performed in statistical data anal
 264 Dec 30, 2022
264 Dec 30, 2022
Pandas-based utility to calculate weighted means, medians, distributions, standard deviations, and more.
weightedcalcs weightedcalcs is a pandas-based Python library for calculating weighted means, medians, standard deviations, and more. Features Plays we
 98 Dec 31, 2022
98 Dec 31, 2022
Supply a wrapper ``StockDataFrame`` based on the ``pandas.DataFrame`` with inline stock statistics/indicators support.
Stock Statistics/Indicators Calculation Helper VERSION: 0.3.2 Introduction Supply a wrapper StockDataFrame based on the pandas.DataFrame with inline s
1.1k Dec 28, 2022
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
 10k Jan 1, 2023
10k Jan 1, 2023
Probabilistic Programming and Statistical Inference in PyTorch
PtStat Probabilistic Programming and Statistical Inference in PyTorch. Introduction This project is being developed during my time at Cogent Labs. The
 109 Nov 26, 2022
109 Nov 26, 2022
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
10k Jan 1, 2023
A Python Package to Tackle the Curse of Imbalanced Datasets in Machine Learning
imbalanced-learn imbalanced-learn is a python package offering a number of re-sampling techniques commonly used in datasets showing strong between-cla
6.2k Jan 1, 2023
Open source time series library for Python
PyFlux PyFlux is an open source time series library for Python. The library has a good array of modern time series models, as well as a flexible array
 2k Jan 2, 2023
2k Jan 2, 2023
Module for statistical learning, with a particular emphasis on time-dependent modelling
Operating system Build Status Linux/Mac Windows tick tick is a Python 3 module for statistical learning, with a particular emphasis on time-dependent
 410 Dec 14, 2022
410 Dec 14, 2022
50% faster, 50% less RAM Machine Learning. Numba rewritten Sklearn. SVD, NNMF, PCA, LinearReg, RidgeReg, Randomized, Truncated SVD/PCA, CSR Matrices all 50+% faster
[Due to the time taken @ uni, work + hell breaking loose in my life, since things have calmed down a bit, will continue commiting!!!] [By the way, I'm
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
High performance, easy-to-use, and scalable machine learning (ML) package, including linear model (LR), factorization machines (FM), and field-aware factorization machines (FFM) for Python and CLI interface.
What is xLearn? xLearn is a high performance, easy-to-use, and scalable machine learning package that contains linear model (LR), factorization machin
 3k Jan 8, 2023
3k Jan 8, 2023
Calculate the efficient frontier
关于 代码主要参考Fábio Neves的文章,你可以在他的文章中找到一些细节性的解释
 104 Nov 11, 2022
104 Nov 11, 2022
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton.
Boltons boltons should be builtins. Boltons is a set of over 230 BSD-licensed, pure-Python utilities in the same spirit as — and yet conspicuously mis
5.4k Feb 20, 2021
Calculate your taxes from cryptocurrency gains
CoinTaxman helps you to bring your income from crypto trading, lending, ... into your tax declaration.
 118 Dec 26, 2022
118 Dec 26, 2022
Visualize and compare datasets, target values and associations, with one line of code.
In-depth EDA (target analysis, comparison, feature analysis, correlation) in two lines of code! Sweetviz is an open-source Python library that generat
 1.2k Feb 18, 2021
1.2k Feb 18, 2021
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
6.8k Feb 18, 2021
Visualize and compare datasets, target values and associations, with one line of code.
In-depth EDA (target analysis, comparison, feature analysis, correlation) in two lines of code! Sweetviz is an open-source Python library that generat
2.3k Jan 5, 2023
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
10k Jan 1, 2023
High performance, easy-to-use, and scalable machine learning (ML) package, including linear model (LR), factorization machines (FM), and field-aware factorization machines (FFM) for Python and CLI interface.
What is xLearn? xLearn is a high performance, easy-to-use, and scalable machine learning package that contains linear model (LR), factorization machin
2.8k Feb 12, 2021
Statsmodels: statistical modeling and econometrics in Python
About statsmodels statsmodels is a Python package that provides a complement to scipy for statistical computations including descriptive statistics an
8.1k Jan 2, 2023
scikit-learn: machine learning in Python
scikit-learn is a Python module for machine learning built on top of SciPy and is distributed under the 3-Clause BSD license. The project was started
 52.5k Jan 8, 2023
52.5k Jan 8, 2023

curl statistics made simple
httpstat httpstat visualizes curl(1) statistics in a way of beauty and clarity. It is a single file 🌟 Python script that has no dependency 👏 and is
 5.3k Jan 4, 2023
5.3k Jan 4, 2023

This program goes thru reddit, finds the most mentioned tickers and uses Vader SentimentIntensityAnalyzer to calculate the ticker compound value.
This program goes thru reddit, finds the most mentioned tickers and uses Vader SentimentIntensityAnalyzer to calculate the ticker compound value.
 195 Dec 13, 2022
195 Dec 13, 2022