178 Repositories
Python bootstrapping-statistics Libraries

Forecasting for knowable future events using Bayesian informative priors (forecasting with judgmental-adjustment).
What is judgyprophet? judgyprophet is a Bayesian forecasting algorithm based on Prophet, that enables forecasting while using information known by the
 56 Oct 26, 2022
56 Oct 26, 2022

Lightning ⚡️ fast forecasting with statistical and econometric models.
Nixtla Statistical ⚡️ Forecast Lightning fast forecasting with statistical and econometric models StatsForecast offers a collection of widely used uni
 2.1k Dec 29, 2022
2.1k Dec 29, 2022

This repository contains the best Data Science free hand-picked resources to equip you with all the industry-driven skills and interview preparation kit.
Best Data Science Resources Hey, Data Enthusiasts out there! Finally, after lots of requests from the community I finally came up with the best free D
 415 Dec 31, 2022
415 Dec 31, 2022
This repository contains implementations of all Machine Learning Algorithms from scratch in Python. Mathematics required for ML and many projects have also been included.
👏 Pre- requisites to Machine Learning
 147 Jan 7, 2023
147 Jan 7, 2023

Bootstrapping your personal Web3 info hub from more than 500 RSS Feeds.
RSS Aggregator for Web3 (or 🥩 RAW for short) Bootstrapping your personal Web3 info hub from more than 500 RSS Feeds. What is RSS or Reader Services?
 1.8k Dec 29, 2022
1.8k Dec 29, 2022
A program that uses real statistics to choose the best times to bet on BloxFlip's crash gamemode
Bloxflip Smart Bet A program that uses real statistics to choose the best times to bet on BloxFlip's crash gamemode. https://bloxflip.com/crash. THIS
 43 Jan 5, 2023
43 Jan 5, 2023
STATS305C: Applied Statistics III (Spring, 2022)
STATS305C: Applied Statistics III Instructor: Scott Linderman TA: Matt MacKay, James Yang Term: Spring 2022 Stanford University Course Description: Pr
 14 Aug 11, 2022
14 Aug 11, 2022
Statistics and Mathematics for Machine Learning, Deep Learning , Deep NLP
Stat4ML Statistics and Mathematics for Machine Learning, Deep Learning , Deep NLP This is the first course from our trio courses: Statistics Foundatio
 83 Dec 29, 2022
83 Dec 29, 2022
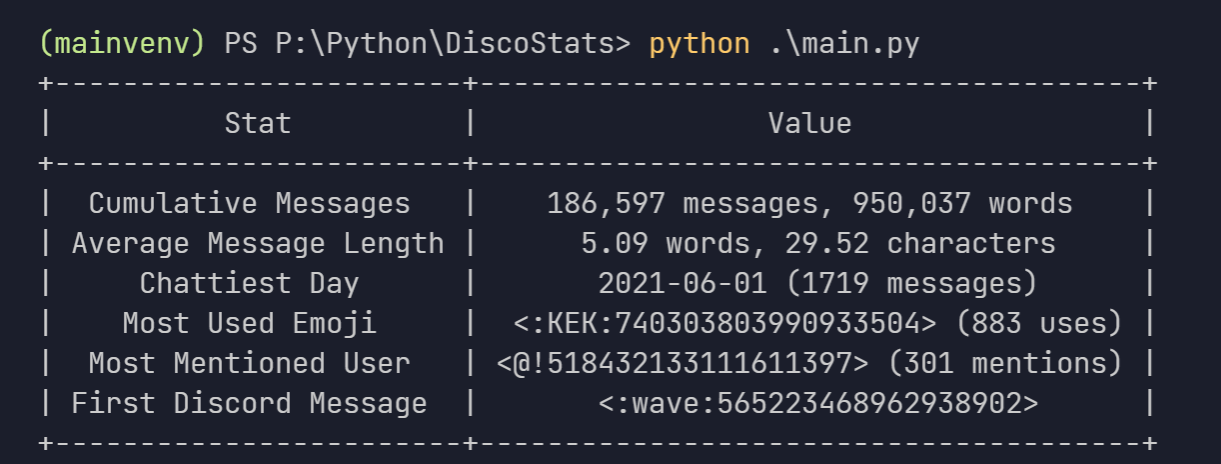
view cool stats related to your discord account.
DiscoStats cool statistics generated using your discord data. How? DiscoStats is not a service that breaks the Discord Terms of Service or Community G
 5 Jun 2, 2022
5 Jun 2, 2022

Athena is the only tool that you will ever need to optimize your portfolio.
Athena Portfolio optimization is the process of selecting the best portfolio (asset distribution), out of the set of all portfolios being considered,
 1 Mar 25, 2022
1 Mar 25, 2022
Live Corona statistics and information site with flask.
Flask Live Corona Info Live Corona statistics and information site with flask. Tools Flask Scrapy Matplotlib How to Run Project Download Codes git clo
 5 Jul 15, 2022
5 Jul 15, 2022
Everything you need to know about NumPy( Creating Arrays, Indexing, Math,Statistics,Reshaping).
Everything you need to know about NumPy( Creating Arrays, Indexing, Math,Statistics,Reshaping).
 1 Feb 14, 2022
1 Feb 14, 2022

A research of IT labor market based especially on hh.ru. Salaries, rate of technologies and etc.
hh_ru_research Проект реализован в учебных целях анализа рынка труда, в особенности по hh.ru Input data В качестве входных данных используются сериали
 3 Sep 7, 2022
3 Sep 7, 2022
Python package for concise, transparent, and accurate predictive modeling
Python package for concise, transparent, and accurate predictive modeling. All sklearn-compatible and easy to use. 📚 docs • 📖 demo notebooks Modern
 983 Jan 1, 2023
983 Jan 1, 2023

Pihole-eink-display - A simple Python script to display PiHole statistics on an eInk Display
Pihole-eink-display - A simple Python script to display PiHole statistics on an eInk Display
 64 Oct 11, 2022
64 Oct 11, 2022
Tarstats - A simple Python commandline application that collects statistics about tarfiles
A simple Python commandline application that collects statistics about tarfiles.
 13 Feb 20, 2022
13 Feb 20, 2022
Projeto de análise de dados com SQL
Project-Analizyng-International-Debt-Statistics- Projeto de análise de dados com SQL - Plataforma Data Camp Descrição do Projeto : Não é que nós human
 1 Feb 1, 2022
1 Feb 1, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
Driver Analysis with Factors and Forests: An Automated Data Science Tool using Python
Driver Analysis with Factors and Forests: An Automated Data Science Tool using Python 📊
 2 May 26, 2022
2 May 26, 2022
The open-source and free to use Python package miseval was developed to establish a standardized medical image segmentation evaluation procedure
miseval: a metric library for Medical Image Segmentation EVALuation The open-source and free to use Python package miseval was developed to establish
 59 Dec 10, 2022
59 Dec 10, 2022
Python based project to pull useful account statistics from the Algorand block chain.
PlanetWatchStats Python based project to pull useful account statistics from the Algorand block chain. Setup pip install -r requirements.txt Run pytho
 1 Jan 27, 2022
1 Jan 27, 2022

FairLens is an open source Python library for automatically discovering bias and measuring fairness in data
FairLens FairLens is an open source Python library for automatically discovering bias and measuring fairness in data. The package can be used to quick
 69 Dec 15, 2022
69 Dec 15, 2022
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences. Copula and functional Principle Component Analysis (fPCA) are statistical models that allow these properties to be simulated (Joe 2014). As such, copula generated data have shown potential to improve the generalization of machine learning (ML) emulators (Meyer et al. 2021) or anonymize real-data datasets (Patki et al. 2016).
 32 Dec 20, 2022
32 Dec 20, 2022

ParaMonte is a serial/parallel library of Monte Carlo routines for sampling mathematical objective functions of arbitrary-dimensions
ParaMonte is a serial/parallel library of Monte Carlo routines for sampling mathematical objective functions of arbitrary-dimensions, in particular, the posterior distributions of Bayesian models in data science, Machine Learning, and scientific inference, with the design goal of unifying the automation (of Monte Carlo simulations), user-friendliness (of the library), accessibility (from multiple programming environments), high-performance (at runtime), and scalability (across many parallel processors).
 182 Dec 31, 2022
182 Dec 31, 2022
Jupyter notebooks for the book "The Elements of Statistical Learning".
This repository contains Jupyter notebooks implementing the algorithms found in the book and summary of the textbook.
 369 Dec 30, 2022
369 Dec 30, 2022
Bayesian A/B testing
bayesian_testing is a small package for a quick evaluation of A/B (or A/B/C/...) tests using Bayesian approach.
 35 Dec 15, 2022
35 Dec 15, 2022

Astrostatistics class for the MSc degree in Astrophysics at the University of Milan-Bicocca (Italy)
Astrostatistics Davide Gerosa - [email protected] University of Milano-Bicocca, 2022. Schedule Introduction Probability and Statistics I Probabi
 25 Jan 2, 2023
25 Jan 2, 2023
Generate daily updated visualizations of user and repository statistics from the GitHub API using GitHub Actions
Generate daily updated visualizations of user and repository statistics from the GitHub API using GitHub Actions for any combination of private and public repositories - dark mode supported
 15 Dec 31, 2022
15 Dec 31, 2022
Generate SVG (dark/light) images visualizing (private/public) GitHub repo statistics for profile/website.
Generate daily updated visualizations of GitHub user and repository statistics from the GitHub API using GitHub Actions for any combination of private and public repositories, whether owned or contributed to - no server required.
2 Dec 16, 2022

A python tutorial on bayesian modeling techniques (PyMC3)
Bayesian Modelling in Python Welcome to "Bayesian Modelling in Python" - a tutorial for those interested in learning how to apply bayesian modelling t
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
Python Machine Learning Jupyter Notebooks (ML website)
Python Machine Learning Jupyter Notebooks (ML website) Dr. Tirthajyoti Sarkar, Fremont, California (Please feel free to connect on LinkedIn here) Also
 2.6k Jan 3, 2023
2.6k Jan 3, 2023

Specification language for generating Generalized Linear Models (with or without mixed effects) from conceptual models
tisane Tisane: Authoring Statistical Models via Formal Reasoning from Conceptual and Data Relationships TL;DR: Analysts can use Tisane to author gener
 11 Nov 15, 2022
11 Nov 15, 2022
FEMDA: Robust classification with Flexible Discriminant Analysis in heterogeneous data
FEMDA: Robust classification with Flexible Discriminant Analysis in heterogeneous data. Flexible EM-Inspired Discriminant Analysis is a robust supervised classification algorithm that performs well in noisy and contaminated datasets.
 0 Sep 6, 2022
0 Sep 6, 2022
Survival analysis in Python
What is survival analysis and why should I learn it? Survival analysis was originally developed and applied heavily by the actuarial and medical commu
 2k Jan 8, 2023
2k Jan 8, 2023
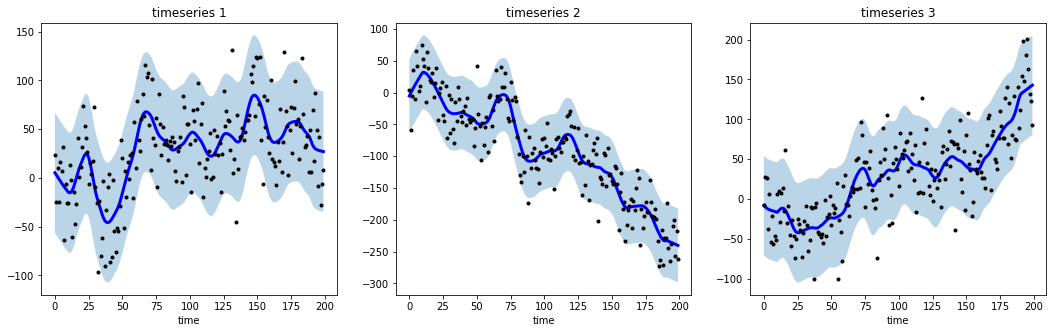
A python library for time-series smoothing and outlier detection in a vectorized way.
tsmoothie A python library for time-series smoothing and outlier detection in a vectorized way. Overview tsmoothie computes, in a fast and efficient w
 517 Dec 28, 2022
517 Dec 28, 2022
examify-io is an online examination system that offers automatic grading , exam statistics , proctoring and programming tests , multiple user roles
examify-io is an online examination system that offers automatic grading , exam statistics , proctoring and programming tests , multiple user roles ( Examiner , Supervisor , Student )
 4 Oct 28, 2021
4 Oct 28, 2021
Ipython notebook presentations for getting starting with basic programming, statistics and machine learning techniques
Data Science 45-min Intros Every week*, our data science team @Gnip (aka @TwitterBoulder) gets together for about 50 minutes to learn something. While
 1.6k Dec 31, 2022
1.6k Dec 31, 2022

A Collection of Cheatsheets, Books, Questions, and Portfolio For DS/ML Interview Prep
Here are the sections: Data Science Cheatsheets Data Science EBooks Data Science Question Bank Data Science Case Studies Data Science Portfolio Data J
 2.5k Jan 2, 2023
2.5k Jan 2, 2023

Introduction to Statistics and Basics of Mathematics for Data Science - The Hacker's Way
HackerMath for Machine Learning “Study hard what interests you the most in the most undisciplined, irreverent and original manner possible.” ― Richard
 1.4k Dec 22, 2022
1.4k Dec 22, 2022
MNE: Magnetoencephalography (MEG) and Electroencephalography (EEG) in Python
MNE-Python MNE-Python software is an open-source Python package for exploring, visualizing, and analyzing human neurophysiological data such as MEG, E
 2.1k Dec 28, 2022
2.1k Dec 28, 2022
Text and code for the forthcoming second edition of Think Bayes, by Allen Downey.
Think Bayes 2 by Allen B. Downey The HTML version of this book is here. Think Bayes is an introduction to Bayesian statistics using computational meth
 1.5k Jan 8, 2023
1.5k Jan 8, 2023

Iris prediction model is used to classify iris species created julia's DecisionTree, DataFrames, JLD2, PlotlyJS and Statistics packages.
Iris Species Predictor Iris prediction is used to classify iris species using their sepal length, sepal width, petal length and petal width created us
 2 Jan 6, 2022
2 Jan 6, 2022
Ferramenta de monitoramento do risco de colapso no sistema de saúde em municípios brasileiros com a Covid-19.
FarolCovid 🚦 Ferramenta de monitoramento do risco de colapso no sistema de saúde em municípios brasileiros com a Covid-19. Monitoring tool & simulati
 49 Jul 10, 2022
49 Jul 10, 2022
Python’s bokeh, holoviews, matplotlib, plotly, seaborn package-based visualizations about COVID statistics eventually hosted as a web app on Heroku
COVID-Watch-NYC-Python-Visualization-App Python’s bokeh, holoviews, matplotlib, plotly, seaborn package-based visualizations about COVID statistics ev
 1 Jan 4, 2022
1 Jan 4, 2022
Ssma is a tool that helps you collect your badges in a satr platform
satr-statistics-maker ssma is a tool that helps you collect your badges in a satr platform 🎖️ Requirements python = 3.7 Installation first clone the
 3 Jan 4, 2022
3 Jan 4, 2022

Practical-statistics-for-data-scientists - Code repository for O'Reilly book
Code repository Practical Statistics for Data Scientists: 50+ Essential Concepts Using R and Python by Peter Bruce, Andrew Bruce, and Peter Gedeck Pub
 1.7k Jan 4, 2023
1.7k Jan 4, 2023
Tautulli - A Python based monitoring and tracking tool for Plex Media Server.
Tautulli A python based web application for monitoring, analytics and notifications for Plex Media Server. This project is based on code from Headphon
 4.7k Jan 7, 2023
4.7k Jan 7, 2023
Prml - Repository of notes, code and notebooks in Python for the book Pattern Recognition and Machine Learning by Christopher Bishop
Pattern Recognition and Machine Learning (PRML) This project contains Jupyter notebooks of many the algorithms presented in Christopher Bishop's Patte
 1k Jan 7, 2023
1k Jan 7, 2023
Spin-off Notice: the modules and functions used by our research notebooks have been refactored into another repository
Fecon235 - Notebooks for financial economics. Keywords: Jupyter notebook pandas Federal Reserve FRED Ferbus GDP CPI PCE inflation unemployment wage income debt Case-Shiller housing asset portfolio equities SPX bonds TIPS rates currency FX euro EUR USD JPY yen XAU gold Brent WTI oil Holt-Winters time-series forecasting statistics econometrics
 825 Dec 27, 2022
825 Dec 27, 2022
Statistical-Rethinking-with-Python-and-PyMC3 - Python/PyMC3 port of the examples in " Statistical Rethinking A Bayesian Course with Examples in R and Stan" by Richard McElreath
Statistical Rethinking with Python and PyMC3 This repository has been deprecated in favour of this one, please check that repository for updates, for
 786 Dec 29, 2022
786 Dec 29, 2022

50-days-of-Statistics-for-Data-Science - This repository consist of a 50-day program
50-days-of-Statistics-for-Data-Science - This repository consist of a 50-day program. All the statistics required for the complete understanding of data science will be uploaded in this repository.
 22 Dec 9, 2022
22 Dec 9, 2022
Generate visualizations of GitHub user and repository statistics using GitHubActions
GitHub Stats Visualization Generate visualizations of GitHub user and repository
 3 Dec 15, 2022
3 Dec 15, 2022
Generate visualizations of GitHub user and repository statistics using GitHub Actions.
GitHub Stats Visualization Generate visualizations of GitHub user and repository statistics using GitHub Actions. This project is currently a work-in-
 1 Jan 11, 2022
1 Jan 11, 2022
Statistics Calculator module for all types of Stats calculations.
Statistics-Calculator This Calculator user the formulas and methods to find the statistical values listed. Statistics Calculator module for all types
 2 May 29, 2022
2 May 29, 2022
whylogs: A Data and Machine Learning Logging Standard
whylogs: A Data and Machine Learning Logging Standard whylogs is an open source standard for data and ML logging whylogs logging agent is the easiest
 2k Jan 6, 2023
2k Jan 6, 2023
Osu statistics right on your desktop, made with pyqt
Osu!Stat Osu statistics right on your desktop, made with Qt5 Credits Would like to thank these creators for their projects and contributions. ppy, osu
 21 Jul 13, 2022
21 Jul 13, 2022
Monitor the stability of a pandas or spark dataframe ⚙︎
Population Shift Monitoring popmon is a package that allows one to check the stability of a dataset. popmon works with both pandas and spark datasets.
 403 Dec 7, 2022
403 Dec 7, 2022

"zpool iostats" for humans; find the slow parts of your ZFS pool
Getting the gist of zfs statistics vpool-demo.mp4 The ZFS command "zpool iostat" provides a histogram listing of how often it takes to do things in pa
 57 Oct 24, 2022
57 Oct 24, 2022
Library for Memory Trace Statistics in Python
Memory Search Library for Memory Trace Statistics in Python The library uses tracemalloc as a core module, which is why it is only available for Pytho
 1 Dec 20, 2021
1 Dec 20, 2021

Automatic labeling, conversion of different data set formats, sample size statistics, model cascade
Simple Gadget Collection for Object Detection Tasks Automatic image annotation Conversion between different annotation formats Obtain statistical info
 4 Aug 24, 2022
4 Aug 24, 2022
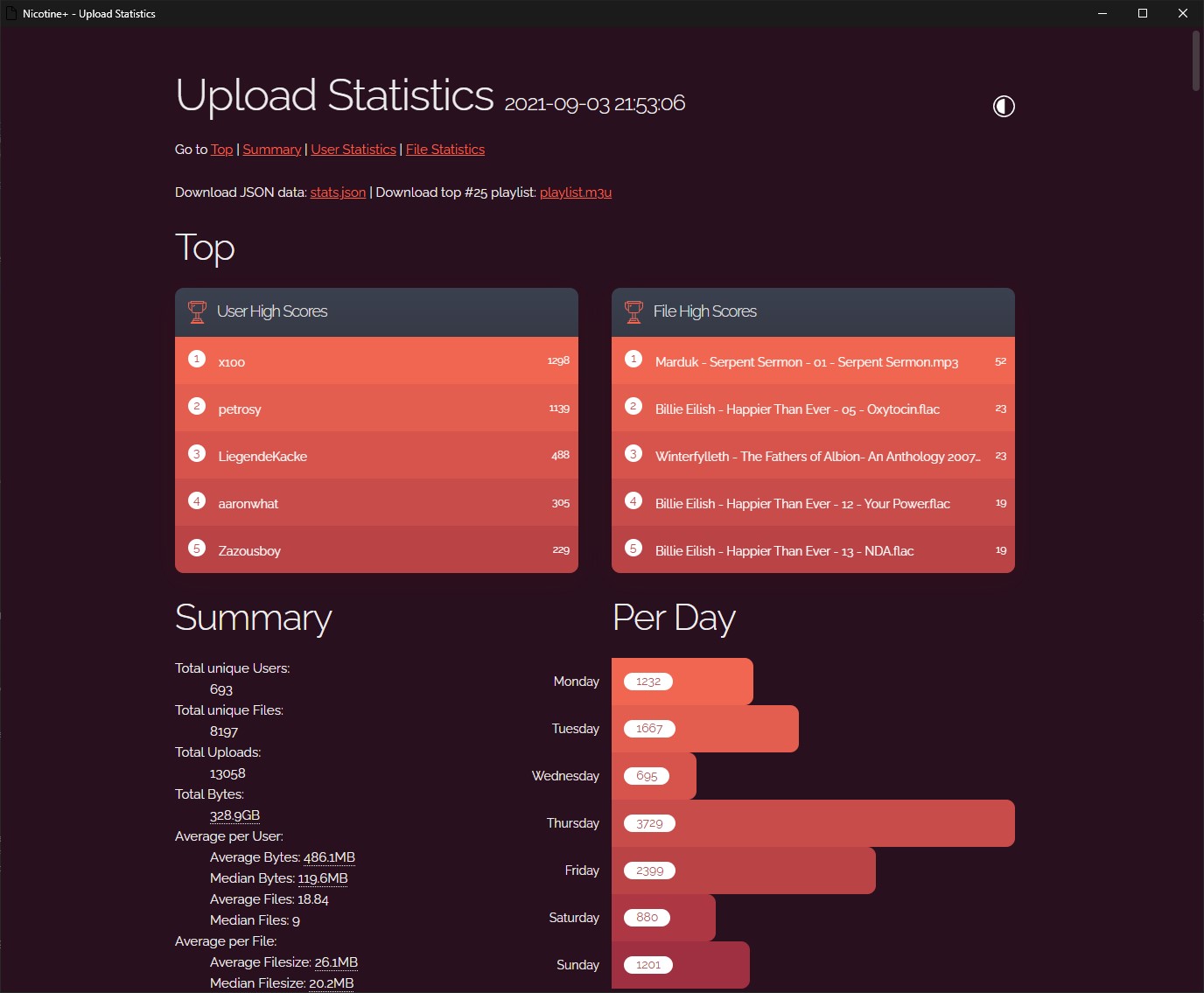
More detailed upload statistics for Nicotine+
More Upload Statistics A small plugin for Nicotine+ 3.1+ to create more detailed upload statistics. ⚠ No data previous to enabling this plugin will be
 1 Dec 17, 2021
1 Dec 17, 2021
The official repository for ROOT: analyzing, storing and visualizing big data, scientifically
About The ROOT system provides a set of OO frameworks with all the functionality needed to handle and analyze large amounts of data in a very efficien
 2k Dec 29, 2022
2k Dec 29, 2022
Fit models to your data in Python with Sherpa.
Table of Contents Sherpa License How To Install Sherpa Using Anaconda Using pip Building from source History Release History Sherpa Sherpa is a modeli
 134 Jan 7, 2023
134 Jan 7, 2023
Telegram Group Chat Statistics With Python
Telegram Group Chat Statistics How to Run First add PYTHONPATH in repository root directory enviroment variable by running: export PYTHONPATH=${PWD}
 3 Apr 18, 2022
3 Apr 18, 2022

Baseball Discord bot that can post up-to-date scores, lineups, and home runs.
Sunny Day Discord Bot Baseball Discord bot that can post up-to-date scores, lineups, and home runs. Uses webscraping techniques to scrape baseball dat
 1 Jun 20, 2022
1 Jun 20, 2022

Revisiting Global Statistics Aggregation for Improving Image Restoration
Revisiting Global Statistics Aggregation for Improving Image Restoration Xiaojie Chu, Liangyu Chen, Chengpeng Chen, Xin Lu Paper: https://arxiv.org/pd
 128 Dec 24, 2022
128 Dec 24, 2022
Sample python script for monitoring Rocketchat database and get statistics of users.
rocketchat-DB-monitoring Sample python script for monitoring Rocketchat database and get statistics of users. 1. Update python: yum check-update && yu
 1 Apr 12, 2022
1 Apr 12, 2022
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
 25 Dec 28, 2022
25 Dec 28, 2022

This project is created to visualize the system statistics such as memory usage, CPU usage, memory accessible by process and much more using Kibana Dashboard with Elasticsearch.
System Stats Visualizer This project is created to visualize the system statistics such as memory usage, CPU usage, memory accessible by process and m
 5 Feb 6, 2022
5 Feb 6, 2022

Simple API for UCI Machine Learning Dataset Repository (search, download, analyze)
A simple API for working with University of California, Irvine (UCI) Machine Learning (ML) repository Table of Contents Introduction About Page of the
223 Dec 5, 2022
The codes reproduce the figures and statistics in the paper, "Controlling for multiple covariates," by Mark Tygert.
The accompanying codes reproduce all figures and statistics presented in "Controlling for multiple covariates" by Mark Tygert. This repository also pr
 1 Dec 2, 2021
1 Dec 2, 2021

It's an .exe file that can notify your chia profit and warning message every time automatically.
chia-Notify-with-Line 警示程式 It's an .exe file that can notify your chia profit and warning message every time automatically. 這是我自行設計的小程式,有轉成.exe檔了,可以在沒
 1 Oct 28, 2021
1 Oct 28, 2021
Generate visualizations of GitHub user and repository statistics using GitHub Actions.
GitHub Stats Visualization Generate visualizations of GitHub user and repository statistics using GitHub Actions. This project is currently a work-in-
 3 Dec 14, 2022
3 Dec 14, 2022
eBay's TSV Utilities: Command line tools for large, tabular data files. Filtering, statistics, sampling, joins and more.
Command line utilities for tabular data files This is a set of command line utilities for manipulating large tabular data files. Files of numeric and
 1.4k Jan 9, 2023
1.4k Jan 9, 2023
stability-selection - A scikit-learn compatible implementation of stability selection
stability-selection - A scikit-learn compatible implementation of stability selection stability-selection is a Python implementation of the stability
 185 Dec 3, 2022
185 Dec 3, 2022
Find usage statistics (imports, function calls, attribute access) for Python code-bases
Python Library stats This is a small library that allows you to query some useful statistics for Python code-bases. We currently report library import
 13 May 2, 2022
13 May 2, 2022
Export Statistics for a Telegram Group Chat
Telegram Statistics Export Statistics for a Telegram Group Chat How to Run First, in main repo directory, run the following code to add src to your PY
 22 Dec 5, 2022
22 Dec 5, 2022
A pairs trade is a market neutral trading strategy enabling traders to profit from virtually any market conditions.
A pairs trade is a market neutral trading strategy enabling traders to profit from virtually any market conditions. This strategy is categorized as a statistical arbitrage and convergence trading strategy.
 13 Nov 27, 2022
13 Nov 27, 2022

Python module for performing linear regression for data with measurement errors and intrinsic scatter
Linear regression for data with measurement errors and intrinsic scatter (BCES) Python module for performing robust linear regression on (X,Y) data po
 56 Sep 27, 2022
56 Sep 27, 2022

Render tokei's output to interactive sunburst chart.
Render tokei's output to interactive sunburst chart.
 134 Dec 15, 2022
134 Dec 15, 2022

GWAS summary statistics files QC tool
SSrehab dependencies: python 3.8+ a GNU/Linux with bash v4 or 5. python packages in requirements.txt bcftools (only for prepare_dbSNPs) gz-sort (only
 21 Nov 2, 2022
21 Nov 2, 2022
Distance correlation and related E-statistics in Python
dcor dcor: distance correlation and related E-statistics in Python. E-statistics are functions of distances between statistical observations in metric
 108 Dec 27, 2022
108 Dec 27, 2022
Computations and statistics on manifolds with geometric structures.
Geomstats Code Continuous Integration Code coverage (numpy) Code coverage (autograd, tensorflow, pytorch) Documentation Community NEWS: Geomstats is r
 875 Dec 31, 2022
875 Dec 31, 2022
Kats, a kit to analyze time series data, a lightweight, easy-to-use, generalizable, and extendable framework to perform time series analysis, from understanding the key statistics and characteristics, detecting change points and anomalies, to forecasting future trends.
Description Kats is a toolkit to analyze time series data, a lightweight, easy-to-use, and generalizable framework to perform time series analysis. Ti
4.1k Jan 9, 2023

Statistical and Algorithmic Investing Strategies for Everyone
Eiten - Algorithmic Investing Strategies for Everyone Eiten is an open source toolkit by Tradytics that implements various statistical and algorithmic
 2.5k Jan 2, 2023
2.5k Jan 2, 2023
🌊 River is a Python library for online machine learning.
River is a Python library for online machine learning. It is the result of a merger between creme and scikit-multiflow. River's ambition is to be the go-to library for doing machine learning on streaming data.
 4k Jan 3, 2023
4k Jan 3, 2023
A collection of video resources for machine learning
Machine Learning Videos This is a collection of recorded talks at machine learning conferences, workshops, seminars, summer schools, and miscellaneous
 1.5k Dec 29, 2022
1.5k Dec 29, 2022
A paper using optimal transport to solve the graph matching problem.
GOAT A paper using optimal transport to solve the graph matching problem. https://arxiv.org/abs/2111.05366 Repo structure .github: Files specifying ho
 8 Jan 4, 2023
8 Jan 4, 2023
Important dataframe statistics with a single command
quick_eda Receiving dataframe statistics with one command Project description A python package for Data Scientists, Students, ML Engineers and anyone
 2 Dec 19, 2021
2 Dec 19, 2021
PyScaffold is a project generator for bootstrapping high quality Python packages
PyScaffold is a project generator for bootstrapping high quality Python packages, ready to be shared on PyPI and installable via pip. It is easy to use and encourages the adoption of the best tools and practices of the Python ecosystem, helping you and your team to stay sane, happy and productive. The best part? It is stable and has been used by thousands of developers for over half a decade!
 1.7k Jan 3, 2023
1.7k Jan 3, 2023
Code for "Long Range Probabilistic Forecasting in Time-Series using High Order Statistics"
Long Range Probabilistic Forecasting in Time-Series using High Order Statistics This is the code produced as part of the paper Long Range Probabilisti
 16 Dec 6, 2022
16 Dec 6, 2022
ecoglib: visualization and statistics for high density microecog signals
ecoglib: visualization and statistics for high density microecog signals This library contains high-level analysis tools for "topos" and "chronos" asp
 1 Nov 17, 2021
1 Nov 17, 2021

Data science, Data manipulation and Machine learning package.
duality Data science, Data manipulation and Machine learning package. Use permitted according to the terms of use and conditions set by the attached l
 3 Oct 19, 2022
3 Oct 19, 2022
A python package which can be pip installed to perform statistics and visualize binomial and gaussian distributions of the dataset
GBiStat package A python package to assist programmers with data analysis. This package could be used to plot : Binomial Distribution of the dataset p
 4 Oct 17, 2022
4 Oct 17, 2022
Working Time Statistics of working hours and working conditions by industry and company
Working Time Statistics of working hours and working conditions by industry and company
 88 Nov 4, 2022
88 Nov 4, 2022
A bot to get Statistics like the Playercount from your Minecraft-Server on your Discord-Server
Hey Thanks for reading me. Warning: My English is not the best I have programmed this bot to show me statistics about the player numbers and ping of m
 12 Sep 24, 2022
12 Sep 24, 2022

Command-line interface to PyPI Stats API to get download stats for Python packages
pypistats Python 3.6+ interface to PyPI Stats API to get aggregate download statistics on Python packages on the Python Package Index without having t
 140 Jan 3, 2023
140 Jan 3, 2023

pypinfo is a simple CLI to access PyPI download statistics via Google's BigQuery.
pypinfo: View PyPI download statistics with ease. pypinfo is a simple CLI to access PyPI download statistics via Google's BigQuery. Installation pypin
 351 Dec 26, 2022
351 Dec 26, 2022
Can a machine learning project be implemented to estimate the salaries of baseball players whose salary information and career statistics for 1986 are shared?
END TO END MACHINE LEARNING PROJECT ON HITTERS DATASET Can a machine learning project be implemented to estimate the salaries of baseball players whos
 7 Dec 18, 2021
7 Dec 18, 2021
K-means clustering is a method used for clustering analysis, especially in data mining and statistics.
K Means Algorithm What is K Means This algorithm is an iterative algorithm that partitions the dataset according to their features into K number of pr
 1 Nov 1, 2021
1 Nov 1, 2021