154 Repositories
Python cuda-kernel Libraries

Demonstrates how to divide a DL model into multiple IR model files (division) and introduce a simplest way to implement a custom layer works with OpenVINO IR models.
Demonstration of OpenVINO techniques - Model-division and a simplest-way to support custom layers Description: Model Optimizer in Intel(r) OpenVINO(tm
 12 Nov 9, 2022
12 Nov 9, 2022

Official PyTorch code for Mutual Affine Network for Spatially Variant Kernel Estimation in Blind Image Super-Resolution (MANet, ICCV2021)
Mutual Affine Network for Spatially Variant Kernel Estimation in Blind Image Super-Resolution (MANet, ICCV2021) This repository is the official PyTorc
 139 Dec 29, 2022
139 Dec 29, 2022
Implementations of polygamma, lgamma, and beta functions for PyTorch
lgamma Implementations of polygamma, lgamma, and beta functions for PyTorch. It's very hacky, but that's usually ok for research use. To build, run: .
 24 Nov 9, 2021
24 Nov 9, 2021
A curated list of resources for Image and Video Deblurring
A curated list of resources for Image and Video Deblurring
 1.7k Jan 1, 2023
1.7k Jan 1, 2023
CUDA Python Low-level Bindings
CUDA Python Low-level Bindings
 529 Jan 3, 2023
529 Jan 3, 2023
tinykernel - A minimal Python kernel so you can run Python in your Python
tinykernel - A minimal Python kernel so you can run Python in your Python
 37 Dec 2, 2022
37 Dec 2, 2022
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023

Exploring Image Deblurring via Blur Kernel Space (CVPR'21)
Exploring Image Deblurring via Encoded Blur Kernel Space About the project We introduce a method to encode the blur operators of an arbitrary dataset
 118 Dec 19, 2022
118 Dec 19, 2022
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
 14 Dec 17, 2022
14 Dec 17, 2022

Official code for UnICORNN (ICML 2021)
UnICORNN (Undamped Independent Controlled Oscillatory RNN) [ICML 2021] This repository contains the implementation to reproduce the numerical experime
 21 Dec 22, 2022
21 Dec 22, 2022
Kaldi-compatible feature extraction with PyTorch, supporting CUDA, batch processing, chunk processing, and autograd
Kaldi-compatible feature extraction with PyTorch, supporting CUDA, batch processing, chunk processing, and autograd
 119 Jan 3, 2023
119 Jan 3, 2023
Convert Python 3 code to CUDA code.
Py2CUDA Convert python code to CUDA. Usage To convert a python file say named py_file.py to CUDA, run python generate_cuda.py --file py_file.py --arch
 3 Jul 14, 2021
3 Jul 14, 2021

A community run, 5-day PyTorch Deep Learning Bootcamp
Deep Learning Winter School, November 2107. Tel Aviv Deep Learning Bootcamp : http://deep-ml.com. About Tel-Aviv Deep Learning Bootcamp is an intensiv
 1.3k Sep 4, 2021
1.3k Sep 4, 2021

PyTorch - Python + Nim
Master Release Pytorch - Py + Nim A Nim frontend for pytorch, aiming to be mostly auto-generated and internally using ATen. Because Nim compiles to C+
 425 Dec 22, 2022
425 Dec 22, 2022
Example repository for custom C++/CUDA operators for TorchScript
Custom TorchScript Operators Example This repository contains examples for writing, compiling and using custom TorchScript operators. See here for the
 106 Dec 14, 2022
106 Dec 14, 2022
DI-HPC is an acceleration operator component for general algorithm modules in reinforcement learning algorithms
DI-HPC: Decision Intelligence - High Performance Computation DI-HPC is an acceleration operator component for general algorithm modules in reinforceme
 185 Dec 29, 2022
185 Dec 29, 2022
QPT-Quick packaging tool 前项式Python环境快捷封装工具
QPT - Quick packaging tool 快捷封装工具 GitHub主页 | Gitee主页 QPT是一款可以“模拟”开发环境的多功能封装工具,一行命令即可将普通的Python脚本打包成EXE可执行程序,与此同时还可轻松引入CUDA等深度学习加速库, 尽可能在用户使用时复现您的开发环境。
 545 Dec 28, 2022
545 Dec 28, 2022

PyTorch implementation of Soft-DTW: a Differentiable Loss Function for Time-Series in CUDA
Soft DTW Loss Function for PyTorch in CUDA This is a Pytorch Implementation of Soft-DTW: a Differentiable Loss Function for Time-Series which is batch
 76 Dec 20, 2022
76 Dec 20, 2022

Official PyTorch code for CVPR 2020 paper "Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision"
Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision https://arxiv.org/abs/2003.00393 Abstract Active learning (AL) aims to min
 29 Nov 21, 2022
29 Nov 21, 2022
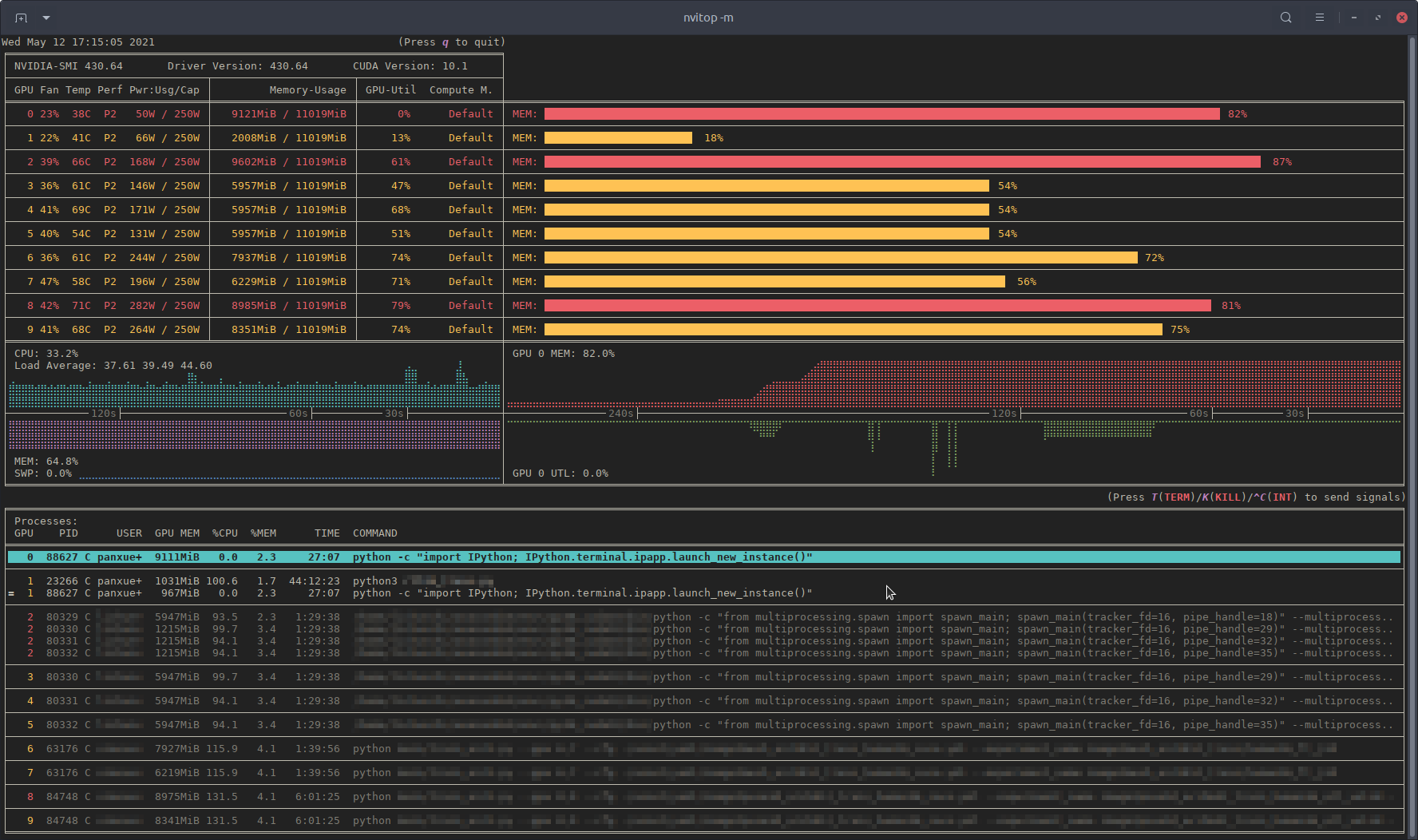
nvitop, an interactive NVIDIA-GPU process viewer, the one-stop solution for GPU process management
An interactive NVIDIA-GPU process viewer, the one-stop solution for GPU process management.
 1.3k Jan 2, 2023
1.3k Jan 2, 2023
This Repo is the official CUDA implementation of ICCV 2019 Oral paper for CARAFE: Content-Aware ReAssembly of FEatures
Introduction This Repo is the official CUDA implementation of ICCV 2019 Oral paper for CARAFE: Content-Aware ReAssembly of FEatures. @inproceedings{Wa
 42 Jan 7, 2023
42 Jan 7, 2023

Fast, differentiable sorting and ranking in PyTorch
Torchsort Fast, differentiable sorting and ranking in PyTorch. Pure PyTorch implementation of Fast Differentiable Sorting and Ranking (Blondel et al.)
 655 Jan 4, 2023
655 Jan 4, 2023
LightSeq: A High-Performance Inference Library for Sequence Processing and Generation
LightSeq is a high performance inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT2, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, and other related tasks using these models.
2.5k Jan 3, 2023

3D ResNet Video Classification accelerated by TensorRT
Activity Recognition TensorRT Perform video classification using 3D ResNets trained on Kinetics-400 dataset and accelerated with TensorRT P.S Click on
 39 Nov 21, 2022
39 Nov 21, 2022
monolish: MONOlithic Liner equation Solvers for Highly-parallel architecture
monolish is a linear equation solver library that monolithically fuses variable data type, matrix structures, matrix data format, vendor specific data transfer APIs, and vendor specific numerical algebra libraries.
 179 Dec 21, 2022
179 Dec 21, 2022

An open-source library of algorithms to analyse time series in GPU and CPU.
An open-source library of algorithms to analyse time series in GPU and CPU.
 216 Dec 30, 2022
216 Dec 30, 2022

(CVPR 2021) PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds
PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds by Mutian Xu*, Runyu Ding*, Hengshuang Zhao, and Xiaojuan Qi. Int
 228 Dec 25, 2022
228 Dec 25, 2022
Picasso: A CUDA-based Library for Deep Learning over 3D Meshes
The Picasso Library is intended for complex real-world applications with large-scale surfaces, while it also performs impressively on the small-scale applications over synthetic shape manifolds. We have upgraded the point cloud modules of SPH3D-GCN from homogeneous to heterogeneous representations, and included the upgraded modules into this latest work as well. We are happy to announce that the work is accepted to IEEE CVPR2021.
 97 Dec 1, 2022
97 Dec 1, 2022
Several simple examples for popular neural network toolkits calling custom CUDA operators.
Neural Network CUDA Example Several simple examples for neural network toolkits (PyTorch, TensorFlow, etc.) calling custom CUDA operators. We provide
 798 Jan 1, 2023
798 Jan 1, 2023
Library for faster pinned CPU - GPU transfer in Pytorch
SpeedTorch Faster pinned CPU tensor - GPU Pytorch variabe transfer and GPU tensor - GPU Pytorch variable transfer, in certain cases. Update 9-29-1
 657 Dec 19, 2022
657 Dec 19, 2022
cuML - RAPIDS Machine Learning Library
cuML - GPU Machine Learning Algorithms cuML is a suite of libraries that implement machine learning algorithms and mathematical primitives functions t
 3.1k Jan 4, 2023
3.1k Jan 4, 2023
cuDF - GPU DataFrame Library
cuDF - GPU DataFrames NOTE: For the latest stable README.md ensure you are on the main branch. Resources cuDF Reference Documentation: Python API refe
5.2k Jan 8, 2023
Python interface to GPU-powered libraries
Package Description scikit-cuda provides Python interfaces to many of the functions in the CUDA device/runtime, CUBLAS, CUFFT, and CUSOLVER libraries
 924 Dec 26, 2022
924 Dec 26, 2022
ArrayFire: a general purpose GPU library.
ArrayFire is a general-purpose library that simplifies the process of developing software that targets parallel and massively-parallel architectures i
 4k Dec 29, 2022
4k Dec 29, 2022
CUDA integration for Python, plus shiny features
PyCUDA lets you access Nvidia's CUDA parallel computation API from Python. Several wrappers of the CUDA API already exist-so what's so special about P
 1.4k Jan 2, 2023
1.4k Jan 2, 2023
A NumPy-compatible array library accelerated by CUDA
CuPy : A NumPy-compatible array library accelerated by CUDA Website | Docs | Install Guide | Tutorial | Examples | API Reference | Forum CuPy is an im
 6.6k Jan 5, 2023
6.6k Jan 5, 2023
Code for Mesh Convolution Using a Learned Kernel Basis
Mesh Convolution This repository contains the implementation (in PyTorch) of the paper FULLY CONVOLUTIONAL MESH AUTOENCODER USING EFFICIENT SPATIALLY
 35 Jan 3, 2023
35 Jan 3, 2023
kaldi-asr/kaldi is the official location of the Kaldi project.
Kaldi Speech Recognition Toolkit To build the toolkit: see ./INSTALL. These instructions are valid for UNIX systems including various flavors of Linux
 12.3k Jan 5, 2023
12.3k Jan 5, 2023
cuDF - GPU DataFrame Library
cuDF - GPU DataFrames NOTE: For the latest stable README.md ensure you are on the main branch. Built based on the Apache Arrow columnar memory format,
5.2k Dec 31, 2022
ThunderGBM: Fast GBDTs and Random Forests on GPUs
Documentations | Installation | Parameters | Python (scikit-learn) interface What's new? ThunderGBM won 2019 Best Paper Award from IEEE Transactions o
 648 Dec 16, 2022
648 Dec 16, 2022
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
ThunderSVM: A Fast SVM Library on GPUs and CPUs
What's new We have recently released ThunderGBM, a fast GBDT and Random Forest library on GPUs. add scikit-learn interface, see here Overview The miss
1.4k Dec 22, 2022
cuML - RAPIDS Machine Learning Library
cuML - GPU Machine Learning Algorithms cuML is a suite of libraries that implement machine learning algorithms and mathematical primitives functions t
3.1k Dec 28, 2022
Extending JAX with custom C++ and CUDA code
Extending JAX with custom C++ and CUDA code This repository is meant as a tutorial demonstrating the infrastructure required to provide custom ops in
 237 Dec 23, 2022
237 Dec 23, 2022
MINIROCKET: A Very Fast (Almost) Deterministic Transform for Time Series Classification
MINIROCKET: A Very Fast (Almost) Deterministic Transform for Time Series Classification
 187 Dec 26, 2022
187 Dec 26, 2022
ThunderGBM: Fast GBDTs and Random Forests on GPUs
Documentations | Installation | Parameters | Python (scikit-learn) interface What's new? ThunderGBM won 2019 Best Paper Award from IEEE Transactions o
647 Jan 4, 2023
ThunderSVM: A Fast SVM Library on GPUs and CPUs
What's new We have recently released ThunderGBM, a fast GBDT and Random Forest library on GPUs. add scikit-learn interface, see here Overview The miss
1.4k Dec 22, 2022
Fast and Easy Infinite Neural Networks in Python
Neural Tangents ICLR 2020 Video | Paper | Quickstart | Install guide | Reference docs | Release notes Overview Neural Tangents is a high-level neural
 1.9k Jan 9, 2023
1.9k Jan 9, 2023

A flexible framework of neural networks for deep learning
Chainer: A deep learning framework Website | Docs | Install Guide | Tutorials (ja) | Examples (Official, External) | Concepts | ChainerX Forum (en, ja
 5.5k Feb 12, 2021
5.5k Feb 12, 2021
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
5.7k Feb 12, 2021
A Python interface module to the SAS System. It works with Linux, Windows, and mainframe SAS. It supports the sas_kernel project (a Jupyter Notebook kernel for SAS) or can be used on its own.
A Python interface to MVA SAS Overview This module creates a bridge between Python and SAS 9.4. This module enables a Python developer, familiar with
 319 Dec 19, 2022
319 Dec 19, 2022
Python bindings for ArrayFire: A general purpose GPU library.
ArrayFire Python Bindings ArrayFire is a high performance library for parallel computing with an easy-to-use API. It enables users to write scientific
402 Dec 20, 2022
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
6.9k Jan 4, 2023
A flexible framework of neural networks for deep learning
Chainer: A deep learning framework Website | Docs | Install Guide | Tutorials (ja) | Examples (Official, External) | Concepts | ChainerX Forum (en, ja
5.8k Jan 6, 2023