2535 Repositories
Python data-parallelism Libraries
A logical, reasonably standardized, but flexible project structure for doing and sharing data science work.
Cookiecutter Data Science A logical, reasonably standardized, but flexible project structure for doing and sharing data science work. Project homepage
 0 Sep 5, 2021
0 Sep 5, 2021

eyes is a Public Opinion Mining System focusing on taiwanese forums such as PTT, Dcard.
eyes is a Public Opinion Mining System focusing on taiwanese forums such as PTT, Dcard. Features 🔥 Article monitor: helps you capture the trend at a
 116 Dec 29, 2022
116 Dec 29, 2022

🌌 Economics Observatory Visualisation Repository
Economics Observatory Visualisation Repository Website | Visualisations | Data | Here you will find all the data visualisations and infographics attac
 3 Dec 14, 2022
3 Dec 14, 2022

A Discord bot to easily and quickly format your JSON data
Invite PrettyJSON to your Discord server Table of contents About the project What is JSON? What is pretty printing? How to use Input options Command I
 4 Jan 24, 2022
4 Jan 24, 2022
Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training".
Mixup-Data-Dependency Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training". Running Alternating Line Exp
 0 Nov 11, 2021
0 Nov 11, 2021
The official repository for our paper "The Neural Data Router: Adaptive Control Flow in Transformers Improves Systematic Generalization".
Codebase for learning control flow in transformers The official repository for our paper "The Neural Data Router: Adaptive Control Flow in Transformer
 24 Oct 15, 2022
24 Oct 15, 2022
Tools for working with MARC data in Catalogue Bridge.
catbridge_tools Tools for working with MARC data in Catalogue Bridge. Borrows heavily from PyMarc
 1 Nov 11, 2021
1 Nov 11, 2021

collect training and calibration data for gaze tracking
Collect Training and Calibration Data for Gaze Tracking This tool allows collecting gaze data necessary for personal calibration or training of eye-tr
 5 Dec 17, 2022
5 Dec 17, 2022

Data and code for ICCV 2021 paper Distant Supervision for Scene Graph Generation.
Distant Supervision for Scene Graph Generation Data and code for ICCV 2021 paper Distant Supervision for Scene Graph Generation. Introduction The pape
 23 Dec 31, 2022
23 Dec 31, 2022

Unofficial Open Corporates CLI: OpenCorporates is a website that shares data on corporations under the copyleft Open Database License. This is an unofficial open corporates python command line tool.
Unofficial Open Corporates CLI OpenCorporates is a website that shares data on corporations under the copyleft Open Database License. This is an unoff
 30 Sep 8, 2022
30 Sep 8, 2022

Home Assistant custom integration to fetch data from Powerpal
Powerpal custom component for Home Assistant Component to integrate with powerpal. This repository and integration is not affiliated with Powerpal. Th
 32 Jan 7, 2023
32 Jan 7, 2023
Cryptocurrency Exchange Websocket Data Feed Handler
Cryptocurrency Exchange Websocket Data Feed Handler
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
Datashredder is a simple data corruption engine written in python. You can corrupt anything text, images and video.
Datashredder is a simple data corruption engine written in python. You can corrupt anything text, images and video. You can chose the cha
 2 Jul 22, 2022
2 Jul 22, 2022
An helper library to scrape data from TikTok in one line, using the Influencer Hunters APIs.
TikTok Scraper An utility library to scrape data from TikTok hassle-free Go to the website » View Demo · Report Bug · Request Feature About The Projec
 6 Jan 8, 2023
6 Jan 8, 2023
novel deep learning research works with PaddlePaddle
Research 发布基于飞桨的前沿研究工作,包括CV、NLP、KG、STDM等领域的顶会论文和比赛冠军模型。 目录 计算机视觉(Computer Vision) 自然语言处理(Natrual Language Processing) 知识图谱(Knowledge Graph) 时空数据挖掘(Spa
 1.5k Dec 29, 2022
1.5k Dec 29, 2022

Code and Data for NeurIPS2021 Paper "A Dataset for Answering Time-Sensitive Questions"
Time-Sensitive-QA The repo contains the dataset and code for NeurIPS2021 (dataset track) paper Time-Sensitive Question Answering dataset. The dataset
 35 Nov 14, 2022
35 Nov 14, 2022

Official Repository for our ICCV2021 paper: Continual Learning on Noisy Data Streams via Self-Purified Replay
Continual Learning on Noisy Data Streams via Self-Purified Replay This repository contains the official PyTorch implementation for our ICCV2021 paper.
 22 Nov 23, 2022
22 Nov 23, 2022
International Space Station data with Python research 🌎
International Space Station data with Python research 🌎 Plotting ISS trajectory, calculating the velocity over the earth and more. Plotting trajector
 41 Jun 16, 2022
41 Jun 16, 2022
Code and data for learning to search in local branching
Code and data for learning to search in local branching
 7 Dec 6, 2022
7 Dec 6, 2022
Python package for processing UC module spectral data.
UC Module Python Package How To Install clone repo. cd UC-module pip install . How to Use uc.module.UC(measurment=str, dark=str, reference=str, heade
 1 Oct 20, 2021
1 Oct 20, 2021
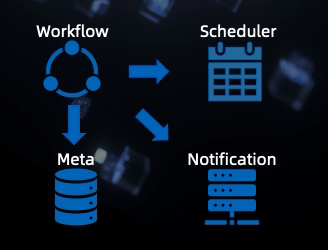
AI Flow is an open source framework that bridges big data and artificial intelligence.
Flink AI Flow Introduction Flink AI Flow is an open source framework that bridges big data and artificial intelligence. It manages the entire machine
 144 Dec 30, 2022
144 Dec 30, 2022
Script for scrape user data like "id,username,fullname,followers,tweets .. etc" by Twitter's search engine .
TwitterScraper Script for scrape user data like "id,username,fullname,followers,tweets .. etc" by Twitter's search engine . Screenshot Data Users Only
 19 Nov 17, 2022
19 Nov 17, 2022
A D3.js plugin that produces flame graphs from hierarchical data.
d3-flame-graph A D3.js plugin that produces flame graphs from hierarchical data. If you don't know what flame graphs are, check Brendan Gregg's post.
 740 Dec 29, 2022
740 Dec 29, 2022
wikirepo is a Python package that provides a framework to easily source and leverage standardized Wikidata information
Python based Wikidata framework for easy dataframe extraction wikirepo is a Python package that provides a framework to easily source and leverage sta
 35 Jan 4, 2023
35 Jan 4, 2023
Python-based Space Physics Environment Data Analysis Software
pySPEDAS pySPEDAS is an implementation of the SPEDAS framework for Python. The Space Physics Environment Data Analysis Software (SPEDAS) framework is
 98 Dec 22, 2022
98 Dec 22, 2022
Framework to collect and process weather data from wttr.in.
Weathercrawler Automatic extraction and processing framework for weather data from wttr.in Installation tested with: Python 3.7.3 Python 3.9.4 git clo
 0 Jul 26, 2021
0 Jul 26, 2021
Code and data for ACL2021 paper Cross-Lingual Abstractive Summarization with Limited Parallel Resources.
Multi-Task Framework for Cross-Lingual Abstractive Summarization (MCLAS) The code for ACL2021 paper Cross-Lingual Abstractive Summarization with Limit
 43 Nov 7, 2022
43 Nov 7, 2022
A practical and feature-rich paraphrasing framework to augment human intents in text form to build robust NLU models for conversational engines. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Parrot Parrot is a paraphrase based utterance augmentation framework purpose built to accelerate training NLU models. A paraphrase framework is more t
 690 Jan 4, 2023
690 Jan 4, 2023

MaD GUI is a basis for graphical annotation and computational analysis of time series data.
MaD GUI Machine Learning and Data Analytics Graphical User Interface MaD GUI is a basis for graphical annotation and computational analysis of time se
 10 Dec 19, 2022
10 Dec 19, 2022

Multiview 3D object detection on MultiviewC dataset through moft3d.
Multiview Orthographic Feature Transformation for 3D Object Detection Multiview 3D object detection on MultiviewC dataset through moft3d. Introduction
 20 Dec 21, 2022
20 Dec 21, 2022

Efficient matrix representations for working with tabular data
Efficient matrix representations for working with tabular data
 70 Dec 14, 2022
70 Dec 14, 2022
novel deep learning research works with PaddlePaddle
Research 发布基于飞桨的前沿研究工作,包括CV、NLP、KG、STDM等领域的顶会论文和比赛冠军模型。 目录 计算机视觉(Computer Vision) 自然语言处理(Natrual Language Processing) 知识图谱(Knowledge Graph) 时空数据挖掘(Spa
1.5k Jan 3, 2023
Code and data of the EMNLP 2021 paper "Mind the Style of Text! Adversarial and Backdoor Attacks Based on Text Style Transfer"
StyleAttack Code and data of the EMNLP 2021 paper "Mind the Style of Text! Adversarial and Backdoor Attacks Based on Text Style Transfer" Prepare Pois
19 Nov 20, 2022
Benchmark datasets, data loaders, and evaluators for graph machine learning
Overview The Open Graph Benchmark (OGB) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Datasets cover
 1.5k Jan 5, 2023
1.5k Jan 5, 2023

Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
DeCLIP Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. Our paper is available in arxiv Updates ** Ou
 470 Dec 30, 2022
470 Dec 30, 2022
DataPrep — The easiest way to prepare data in Python
DataPrep — The easiest way to prepare data in Python
 1.5k Dec 27, 2022
1.5k Dec 27, 2022
A data visualization curriculum of interactive notebooks.
A data visualization curriculum of interactive notebooks, using Vega-Lite and Altair. This repository contains a series of Python-based Jupyter notebooks.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
Python Library for Signal/Image Data Analysis with Transport Methods
PyTransKit Python Transport Based Signal Processing Toolkit Website and documentation: https://pytranskit.readthedocs.io/ Installation The library cou
 24 Dec 23, 2022
24 Dec 23, 2022
"Domain Adaptive Semantic Segmentation without Source Data" (ACM MM 2021)
LDBE Pytorch implementation for two papers (the paper will be released soon): "Domain Adaptive Semantic Segmentation without Source Data", ACM MM2021.
 16 Sep 28, 2022
16 Sep 28, 2022
A cross-lingual COVID-19 fake news dataset
CrossFake An English-Chinese COVID-19 fake&real news dataset from the ICDMW 2021 paper below: Cross-lingual COVID-19 Fake News Detection. Jiangshu Du,
 11 Dec 1, 2022
11 Dec 1, 2022

Ground truth data for the Optical Character Recognition of Historical Classical Commentaries.
OCR Ground Truth for Historical Commentaries The dataset OCR ground truth for historical commentaries (GT4HistComment) was created from the public dom
 3 Sep 8, 2022
3 Sep 8, 2022

Scrape data on SpaceX: Capsules, Rockets, Cores, Roadsters, SpaceX Info
SpaceX Sofware I developed software to scrape data on SpaceX: Capsules, Rockets, Cores, Roadsters, SpaceX Info to use the software you need Python a
 16 Aug 2, 2022
16 Aug 2, 2022
Code & Data for the Paper "Time Masking for Temporal Language Models", WSDM 2022
Time Masking for Temporal Language Models This repository provides a reference implementation of the paper: Time Masking for Temporal Language Models
 12 Jan 6, 2023
12 Jan 6, 2023
A Python package that scrapes Google News article data while remaining undetected by Google.
A Python package that scrapes Google News article data while remaining undetected by Google. Our scraper can scrape page data up until the last page and never trigger a CAPTCHA (download stats: https://pepy.tech/project/GoogleNewsScraper)
 6 Aug 10, 2022
6 Aug 10, 2022

Using Selenium with Python to Web Scrap Popular Youtube Tech Channels.
Web Scrapping Popular Youtube Tech Channels with Selenium Data Mining, Data Wrangling, and Exploratory Data Analysis About the Data Web scrapi
 0 Aug 18, 2021
0 Aug 18, 2021

👁️ Tool for Data Extraction and Web Requests.
httpmapper 👁️ Project • Technologies • Installation • How it works • License Project 🚧 For educational purposes. This is a project that I developed,
 15 Dec 5, 2021
15 Dec 5, 2021

The open-source web scrapers that feed the Los Angeles Times California coronavirus tracker.
The open-source web scrapers that feed the Los Angeles Times' California coronavirus tracker. Processed data ready for analysis is available at datade
 51 Dec 14, 2022
51 Dec 14, 2022
A tool for scraping and organizing data from NewsBank API searches
nbscraper Overview This simple tool automates the process of copying, pasting, and organizing data from NewsBank API searches. Curerntly, nbscrape onl
 0 Jun 17, 2021
0 Jun 17, 2021

A web scraping pipeline project that retrieves TV and movie data from two sources, then transforms and stores data in a MySQL database.
New to Streaming Scraper An in-progress web scraping project built with Python, R, and SQL. The scraped data are movie and TV show information. The go
 1 Mar 28, 2022
1 Mar 28, 2022
A tool to easily scrape youtube data using the Google API
YouTube data scraper To easily scrape any data from the youtube homepage, a youtube channel/user, search results, playlists, and a single video itself
 7 Dec 3, 2022
7 Dec 3, 2022

Universal Reddit Scraper - A comprehensive Reddit scraping command-line tool written in Python.
Universal Reddit Scraper - A comprehensive Reddit scraping command-line tool written in Python.
 543 Jan 3, 2023
543 Jan 3, 2023

Recommendations from Cramer: On the show Mad-Money (CNBC) Jim Cramer picks stocks which he recommends to buy. We will use this data to build a portfolio
Backtesting the "Cramer Effect" & Recommendations from Cramer Recommendations from Cramer: On the show Mad-Money (CNBC) Jim Cramer picks stocks which
 12 Aug 30, 2022
12 Aug 30, 2022
DaDRA (day-druh) is a Python library for Data-Driven Reachability Analysis.
DaDRA (day-druh) is a Python library for Data-Driven Reachability Analysis. The main goal of the package is to accelerate the process of computing estimates of forward reachable sets for nonlinear dynamical systems.
 2 Nov 8, 2021
2 Nov 8, 2021
Statistical Analysis 📈 focused on statistical analysis and exploration used on various data sets for personal and professional projects.
Statistical Analysis 📈 This repository focuses on statistical analysis and the exploration used on various data sets for personal and professional pr
 1 Sep 3, 2022
1 Sep 3, 2022
pyETT: Python library for Eleven VR Table Tennis data
pyETT: Python library for Eleven VR Table Tennis data Documentation Documentation for pyETT is located at https://pyett.readthedocs.io/. Installation
 5 Nov 19, 2022
5 Nov 19, 2022

A collection of learning outcomes data analysis using Python and SQL, from DQLab.
Data Analyst with PYTHON Data Analyst berperan dalam menghasilkan analisa data serta mempresentasikan insight untuk membantu proses pengambilan keputu
 6 Oct 11, 2022
6 Oct 11, 2022
Python Package for DataHerb: create, search, and load datasets.
The Python Package for DataHerb A DataHerb Core Service to Create and Load Datasets.
 4 Feb 11, 2022
4 Feb 11, 2022

A powerful data analysis package based on mathematical step functions. Strongly aligned with pandas.
The leading use-case for the staircase package is for the creation and analysis of step functions. Pretty exciting huh. But don't hit the close button
 48 Dec 21, 2022
48 Dec 21, 2022
HyperSpy is an open source Python library for the interactive analysis of multidimensional datasets
HyperSpy is an open source Python library for the interactive analysis of multidimensional datasets that can be described as multidimensional arrays o
 411 Dec 27, 2022
411 Dec 27, 2022
Additional tools for particle accelerator data analysis and machine information
PyLHC Tools This package is a collection of useful scripts and tools for the Optics Measurements and Corrections group (OMC) at CERN. Documentation Au
 3 Apr 13, 2022
3 Apr 13, 2022
GWpy is a collaboration-driven Python package providing tools for studying data from ground-based gravitational-wave detectors
GWpy is a collaboration-driven Python package providing tools for studying data from ground-based gravitational-wave detectors. GWpy provides a user-f
 342 Jan 7, 2023
342 Jan 7, 2023
Open Data Cube analyses continental scale Earth Observation data through time
Open Data Cube Core Overview The Open Data Cube Core provides an integrated gridded data analysis environment for decades of analysis ready earth obse
 410 Dec 13, 2022
410 Dec 13, 2022
Toolchest provides APIs for scientific and bioinformatic data analysis.
Toolchest Python Client Toolchest provides APIs for scientific and bioinformatic data analysis. It allows you to abstract away the costliness of runni
 11 Jun 30, 2022
11 Jun 30, 2022

A data analysis using python and pandas to showcase trends in school performance.
A data analysis using python and pandas to showcase trends in school performance. A data analysis to showcase trends in school performance using Panda
 0 Sep 7, 2021
0 Sep 7, 2021

An end-to-end regression problem of predicting the price of properties in Bangalore.
Bangalore-House-Price-Prediction An end-to-end regression problem of predicting the price of properties in Bangalore. Deployed in Heroku using Flask.
 1 Nov 25, 2022
1 Nov 25, 2022

Repositori untuk menyimpan material Long Course STMKGxHMGI tentang Geophysical Python for Seismic Data Analysis
Long Course "Geophysical Python for Seismic Data Analysis" Instruktur: Dr.rer.nat. Wiwit Suryanto, M.Si Dipersiapkan oleh: Anang Sahroni Waktu: Sesi 1
 0 Dec 4, 2021
0 Dec 4, 2021
The OHSDI OMOP Common Data Model allows for the systematic analysis of healthcare observational databases.
The OHSDI OMOP Common Data Model allows for the systematic analysis of healthcare observational databases.
 14 Jan 2, 2023
14 Jan 2, 2023
Universal data analysis tools for atmospheric sciences
U_analysis Universal data analysis tools for atmospheric sciences Script written in python 3. This file defines multiple functions that can be used fo
 1 Oct 10, 2021
1 Oct 10, 2021
Django3 web app that renders OpenWeather API data ☁️☁️
nz-weather For a live build, visit - https://brandonru.pythonanywhere.com/ NZ Openweather API data rendered using Django3 and requests ☀️ Local Run In
 1 Oct 17, 2021
1 Oct 17, 2021

Trained on Simulated Data, Tested in the Real World
Trained on Simulated Data, Tested in the Real World
 43 Nov 18, 2022
43 Nov 18, 2022
Helper tools to construct probability distributions built from expert elicited data for use in monte carlo simulations.
Elicited Helper tools to construct probability distributions built from expert elicited data for use in monte carlo simulations. Credit to Brett Hoove
 3 Nov 4, 2022
3 Nov 4, 2022

A synthetic texture-invariant dataset for object detection of UAVs
A synthetic dataset for object detection of UAVs This repository contains a synthetic datasets accompanying the paper Sim2Air - Synthetic aerial datas
 10 Aug 13, 2022
10 Aug 13, 2022

Learning from Synthetic Data with Fine-grained Attributes for Person Re-Identification
Less is More: Learning from Synthetic Data with Fine-grained Attributes for Person Re-Identification Suncheng Xiang Shanghai Jiao Tong University Over
 68 Dec 13, 2022
68 Dec 13, 2022
Perform Linear Classification with Multi-way Data
MultiwayClassification This is an R package to perform linear classification for data with multi-way structure. The distance-weighted discrimination (
 2 Dec 15, 2020
2 Dec 15, 2020

TCube generates rich and fluent narratives that describes the characteristics, trends, and anomalies of any time-series data (domain-agnostic) using the transfer learning capabilities of PLMs.
TCube: Domain-Agnostic Neural Time series Narration This repository contains the code for the paper: "TCube: Domain-Agnostic Neural Time series Narrat
 7 Oct 31, 2021
7 Oct 31, 2021
This repository is for EMNLP 2021 paper: It is Not as Good as You Think! Evaluating Simultaneous Machine Translation on Interpretation Data
InterpretationData This repository is for our EMNLP 2021 paper: It is Not as Good as You Think! Evaluating Simultaneous Machine Translation on Interpr
 4 Apr 21, 2022
4 Apr 21, 2022
This repository contains all data used for writing a research paper Multiple Object Trackers in OpenCV: A Benchmark, presented in ISIE 2021 conference in Kyoto, Japan.
OpenCV-Multiple-Object-Tracking Python is version 3.6.7 to install opencv: pip uninstall opecv-python pip uninstall opencv-contrib-python pip install
 6 Dec 19, 2021
6 Dec 19, 2021

Biomarker identification for COVID-19 Severity in BALF cells Single-cell RNA-seq data
scBALF Covid-19 dataset Analysis Here is the Github page that has the codes for the bioinformatics pipeline described in the paper COVID-Datathon: Bio
 2 May 21, 2022
2 May 21, 2022
Code repository for the paper "Doubly-Trained Adversarial Data Augmentation for Neural Machine Translation" with instructions to reproduce the results.
Doubly Trained Neural Machine Translation System for Adversarial Attack and Data Augmentation Languages Experimented: Data Overview: Source Target Tra
 1 Aug 18, 2022
1 Aug 18, 2022
Nonnegative spatial factorization for multivariate count data
Nonnegative spatial factorization for multivariate count data This repository contains supporting code to facilitate reproducible analysis. For detail
 24 Dec 19, 2022
24 Dec 19, 2022

Download India Stocks Historical Data
Kite Helper - Download Stock Market Data 🌎 Website Simple Application to Download any stock market data in .csv format using Kite 🏃♂️ Running Serve
 12 Dec 6, 2022
12 Dec 6, 2022
Stitch together Nanopore tiled amplicon data without polishing a reference
Stitch together Nanopore tiled amplicon data using a reference guided approach Tiled amplicon data, like those produced from primers designed with pri
 14 Aug 30, 2022
14 Aug 30, 2022
A bot to display per user data from the Twitch Leak
twitch-leak-bot-discord A bot to display per user data from the Twitch Leak by username Where's the data? I can't and don't want to supply the .csv's
 0 Nov 8, 2022
0 Nov 8, 2022
Tooling for converting STAC metadata to ODC data model
Tooling for converting STAC metadata to ODC data model.
65 Dec 20, 2022
Helpers to extend Django Admin with data from external service with minimal hacks
django-admin-data-from-external-service Helpers to extend Django Admin with data from external service with minimal hacks Live demo with sources on He
 7 Apr 27, 2022
7 Apr 27, 2022

A lightweight, hub-and-spoke dashboard for multi-account Data Science projects
A lightweight, hub-and-spoke dashboard for cross-account Data Science Projects Introduction Modern Data Science environments often involve many indepe
 3 Oct 30, 2021
3 Oct 30, 2021
This repository will be a draft of a package about the latest total marine fish production in Indonesia. Data will be collected from PIPP (Pusat Informasi Pelabuhan Perikanan).
indomarinefish This package will give us information about the latest total marine fish production in Indonesia. The Name of the fish is written in In
 1 Oct 13, 2021
1 Oct 13, 2021

Mix3D: Out-of-Context Data Augmentation for 3D Scenes (3DV 2021)
Mix3D: Out-of-Context Data Augmentation for 3D Scenes (3DV 2021) Alexey Nekrasov*, Jonas Schult*, Or Litany, Bastian Leibe, Francis Engelmann Mix3D is
 189 Dec 26, 2022
189 Dec 26, 2022
A Python script to update Spotify Playlist data every 5 minutes.
Spotify Playlist Updater A Python script to update Spotify Playlist data every 5 minutes. Description An automatic playlist updater using Spotify API
 6 Nov 24, 2022
6 Nov 24, 2022

The official implementation of the paper, "SubTab: Subsetting Features of Tabular Data for Self-Supervised Representation Learning"
SubTab: Author: Talip Ucar ([email protected]) The official implementation of the paper, SubTab: Subsetting Features of Tabular Data for Self-Supervis
 98 Dec 29, 2022
98 Dec 29, 2022
An utility library to scrape data from TikTok, Instagram, Twitch, Youtube, Twitter or Reddit in one line!
Social Media Scraper An utility library to scrape data from TikTok, Instagram, Twitch, Youtube, Twitter or Reddit in one line! Go to the website » Vie
2 Aug 3, 2022
FAST-RIR: FAST NEURAL DIFFUSE ROOM IMPULSE RESPONSE GENERATOR
This is the official implementation of our neural-network-based fast diffuse room impulse response generator (FAST-RIR) for generating room impulse responses (RIRs) for a given acoustic environment.
 89 Dec 22, 2022
89 Dec 22, 2022
Data Augmentation with Variational Autoencoders
Documentation Pyraug This library provides a way to perform Data Augmentation using Variational Autoencoders in a reliable way even in challenging con
 112 Nov 30, 2022
112 Nov 30, 2022
A framework for building (and incrementally growing) graph-based data structures used in hierarchical or DAG-structured clustering and nearest neighbor search
A framework for building (and incrementally growing) graph-based data structures used in hierarchical or DAG-structured clustering and nearest neighbor search
 31 Nov 3, 2022
31 Nov 3, 2022

A project based example of Data pipelines, ML workflow management, API endpoints and Monitoring.
MLOps template with examples for Data pipelines, ML workflow management, API development and Monitoring.
 33 Dec 3, 2022
33 Dec 3, 2022
A simple command for converting and processing data from your clipboard.
A generic text conversion/processing tool
 29 Jan 17, 2022
29 Jan 17, 2022
Script that organizes the Google Takeout archive into one big chronological folder
Script that organizes the Google Takeout archive into one big chronological folder
 1.6k Jan 9, 2023
1.6k Jan 9, 2023

This app will let you continuously scrape certain parts of LeasePlan and extract data of cars becoming available for lease.
LeasePlan - Scraper This app will let you continuously scrape certain parts of LeasePlan and extract data of cars becoming available for lease. It has
 4 Nov 18, 2022
4 Nov 18, 2022
PyTorch implementation of DUL (Data Uncertainty Learning in Face Recognition, CVPR2020)
PyTorch implementation of DUL (Data Uncertainty Learning in Face Recognition, CVPR2020)
 20 Nov 15, 2022
20 Nov 15, 2022
Projects that implement various aspects of Data Engineering.
DATAWAREHOUSE ON AWS The purpose of this project is to build a datawarehouse to accomodate data of active user activity for music streaming applicatio
 2 Oct 14, 2021
2 Oct 14, 2021