640 Repositories
Python dynamic-attention Libraries

LightNet++: Boosted Light-weighted Networks for Real-time Semantic Segmentation
LightNet++ !!!New Repo.!!! ⇒ EfficientNet.PyTorch: Concise, Modular, Human-friendly PyTorch implementation of EfficientNet with Pre-trained Weights !!
 237 Jan 5, 2023
237 Jan 5, 2023
The official implementation of ELSA: Enhanced Local Self-Attention for Vision Transformer
ELSA: Enhanced Local Self-Attention for Vision Transformer By Jingkai Zhou, Pich
 87 Dec 19, 2022
87 Dec 19, 2022

Repository of Vision Transformer with Deformable Attention
Vision Transformer with Deformable Attention This repository contains the code for the paper Vision Transformer with Deformable Attention [arXiv]. Int
 410 Jan 3, 2023
410 Jan 3, 2023
This repository provides the official implementation of 'Learning to ignore: rethinking attention in CNNs' accepted in BMVC 2021.
inverse_attention This repository provides the official implementation of 'Learning to ignore: rethinking attention in CNNs' accepted in BMVC 2021. Le
 5 Jul 8, 2022
5 Jul 8, 2022
Unofficial PyTorch reimplementation of the paper Swin Transformer V2: Scaling Up Capacity and Resolution
PyTorch reimplementation of the paper Swin Transformer V2: Scaling Up Capacity and Resolution [arXiv 2021].
 122 Dec 12, 2022
122 Dec 12, 2022
The official TensorFlow implementation of the paper Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition
Action Transformer A Self-Attention Model for Short-Time Human Action Recognition This repository contains the official TensorFlow implementation of t
 20 Jan 3, 2023
20 Jan 3, 2023
Alignment Attention Fusion framework for Few-Shot Object Detection
AAF framework Framework generalities This repository contains the code of the AAF framework proposed in this paper. The main idea behind this work is
 20 Dec 16, 2022
20 Dec 16, 2022
R-package accompanying the paper "Dynamic Factor Model for Functional Time Series: Identification, Estimation, and Prediction"
dffm The goal of dffm is to provide functionality to apply the methods developed in the paper “Dynamic Factor Model for Functional Time Series: Identi
 3 Dec 9, 2022
3 Dec 9, 2022

Implementation of a Transformer using ReLA (Rectified Linear Attention)
ReLA (Rectified Linear Attention) Transformer Implementation of a Transformer using ReLA (Rectified Linear Attention). It will also contain an attempt
 49 Oct 14, 2022
49 Oct 14, 2022

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022
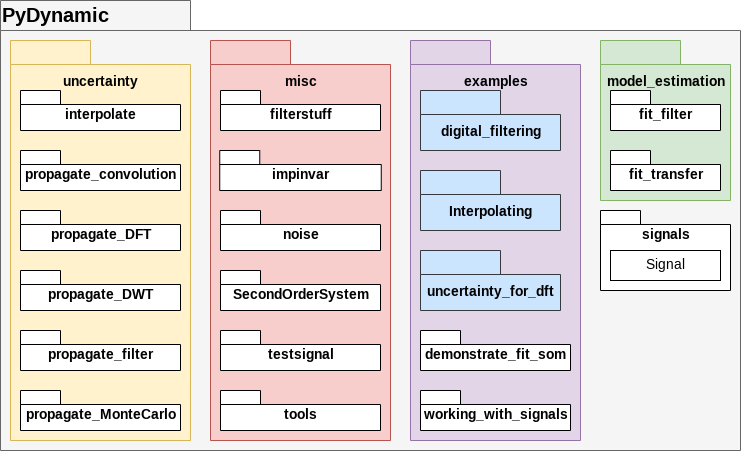
Python library for the analysis of dynamic measurements
Python library for the analysis of dynamic measurements The goal of this library is to provide a starting point for users in metrology and related are
 18 Dec 21, 2022
18 Dec 21, 2022

MVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions
MVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions Project Page | Paper If you find our work useful for your research, please con
 96 Jan 4, 2023
96 Jan 4, 2023

Official PyTorch implementation of "The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation" (ICCV 21).
CenterGroup This the official implementation of our ICCV 2021 paper The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person P
 43 Dec 25, 2022
43 Dec 25, 2022

Code for "Multi-Time Attention Networks for Irregularly Sampled Time Series", ICLR 2021.
Multi-Time Attention Networks (mTANs) This repository contains the PyTorch implementation for the paper Multi-Time Attention Networks for Irregularly
 68 Dec 17, 2022
68 Dec 17, 2022

This is a super simple visualization toolbox (script) for transformer attention visualization ✌
Trans_attention_vis This is a super simple visualization toolbox (script) for transformer attention visualization ✌ 1. How to prepare your attention m
 3 Jul 9, 2022
3 Jul 9, 2022
RaftMLP: How Much Can Be Done Without Attention and with Less Spatial Locality?
RaftMLP RaftMLP: How Much Can Be Done Without Attention and with Less Spatial Locality? By Yuki Tatsunami and Masato Taki (Rikkyo University) [arxiv]
 20 Aug 31, 2022
20 Aug 31, 2022
Python port of R's Comprehensive Dynamic Time Warp algorithm package
Welcome to the dtw-python package Comprehensive implementation of Dynamic Time Warping algorithms. DTW is a family of algorithms which compute the loc
 154 Dec 26, 2022
154 Dec 26, 2022
Quantify the difference between two arbitrary curves in space
similaritymeasures Quantify the difference between two arbitrary curves Curves in this case are: discretized by inidviudal data points ordered from a
 175 Jan 8, 2023
175 Jan 8, 2023
Python package for dynamic system estimation of time series
PyDSE Toolset for Dynamic System Estimation for time series inspired by DSE. It is in a beta state and only includes ARMA models right now. Documentat
 40 Oct 7, 2022
40 Oct 7, 2022

In this project we use both Resnet and Self-attention layer for cat, dog and flower classification.
cdf_att_classification classes = {0: 'cat', 1: 'dog', 2: 'flower'} In this project we use both Resnet and Self-attention layer for cdf-Classification.
 3 Nov 23, 2022
3 Nov 23, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

GAT - Graph Attention Network (PyTorch) 💻 + graphs + 📣 = ❤️
GAT - Graph Attention Network (PyTorch) 💻 + graphs + 📣 = ❤️ This repo contains a PyTorch implementation of the original GAT paper ( 🔗 Veličković et
 1.9k Jan 9, 2023
1.9k Jan 9, 2023
Fast convergence of detr with spatially modulated co-attention
Fast convergence of detr with spatially modulated co-attention Usage There are no extra compiled components in SMCA DETR and package dependencies are
 135 Dec 7, 2022
135 Dec 7, 2022

SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition
SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition PDF Abstract Explainable artificial intelligence has been gaining attention
 87 Dec 26, 2022
87 Dec 26, 2022
A new codebase for Group Activity Recognition. It contains codes for ICCV 2021 paper: Spatio-Temporal Dynamic Inference Network for Group Activity Recognition and some other methods.
Spatio-Temporal Dynamic Inference Network for Group Activity Recognition The source codes for ICCV2021 Paper: Spatio-Temporal Dynamic Inference Networ
 40 Dec 12, 2022
40 Dec 12, 2022
Custom studies about block sparse attention.
Block Sparse Attention 研究总结 本人近半年来对Block Sparse Attention(块稀疏注意力)的研究总结(持续更新中)。按时间顺序,主要分为如下三部分: PyTorch 自定义 CUDA 算子——以矩阵乘法为例 基于 Triton 的 Block Sparse A
 2 Jan 9, 2022
2 Jan 9, 2022

Attention-based Transformation from Latent Features to Point Clouds (AAAI 2022)
Attention-based Transformation from Latent Features to Point Clouds This repository contains a PyTorch implementation of the paper: Attention-based Tr
 12 Nov 11, 2022
12 Nov 11, 2022

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 9, 2023
1.3k Jan 9, 2023
An analysis tool for Python that blurs the line between testing and type systems.
CrossHair An analysis tool for Python that blurs the line between testing and type systems. THE LATEST NEWS: Check out the new crosshair cover command
 836 Jan 8, 2023
836 Jan 8, 2023

This MVP data web app uses the Streamlit framework and Facebook's Prophet forecasting package to generate a dynamic forecast from your own data.
📈 Automated Time Series Forecasting Background: This MVP data web app uses the Streamlit framework and Facebook's Prophet forecasting package to gene
 42 Jan 4, 2023
42 Jan 4, 2023
torchsummaryDynamic: support real FLOPs calculation of dynamic network or user-custom PyTorch ops
torchsummaryDynamic Improved tool of torchsummaryX. torchsummaryDynamic support real FLOPs calculation of dynamic network or user-custom PyTorch ops.
 1 Jan 7, 2022
1 Jan 7, 2022
DeepSpamReview: Detection of Fake Reviews on Online Review Platforms using Deep Learning Architectures. Summer Internship project at CoreView Systems.
Detection of Fake Reviews on Online Review Platforms using Deep Learning Architectures Dataset: https://s3.amazonaws.com/fast-ai-nlp/yelp_review_polar
 37 Dec 17, 2022
37 Dec 17, 2022
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss This repository implements the SAFL in pytorch. Installation conda env create -f environm
 6 Aug 24, 2022
6 Aug 24, 2022

DAGAN - Dual Attention GANs for Semantic Image Synthesis
Contents Semantic Image Synthesis with DAGAN Installation Dataset Preparation Generating Images Using Pretrained Model Train and Test New Models Evalu
 104 Oct 8, 2022
104 Oct 8, 2022

AttentionGAN for Unpaired Image-to-Image Translation & Multi-Domain Image-to-Image Translation
AttentionGAN-v2 for Unpaired Image-to-Image Translation AttentionGAN-v2 Framework The proposed generator learns both foreground and background attenti
530 Dec 27, 2022

A unified framework to jointly model images, text, and human attention traces.
connect-caption-and-trace This repository contains the reference code for our paper Connecting What to Say With Where to Look by Modeling Human Attent
 73 Oct 24, 2022
73 Oct 24, 2022
![Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]](https://github.com/JDAI-CV/image-captioning/raw/master/images/framework.jpg)
Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]
Introduction This repository is for X-Linear Attention Networks for Image Captioning (CVPR 2020). The original paper can be found here. Please cite wi
 240 Dec 17, 2022
240 Dec 17, 2022
Code for paper Adaptively Aligned Image Captioning via Adaptive Attention Time
Adaptively Aligned Image Captioning via Adaptive Attention Time This repository includes the implementation for Adaptively Aligned Image Captioning vi
 45 Aug 27, 2022
45 Aug 27, 2022

Tensorflow implementation of soft-attention mechanism for video caption generation.
SA-tensorflow Tensorflow implementation of soft-attention mechanism for video caption generation. An example of soft-attention mechanism. The attentio
 153 Nov 14, 2022
153 Nov 14, 2022

Show-attend-and-tell - TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
 902 Nov 29, 2022
902 Nov 29, 2022

Image captioning - Tensorflow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Introduction This neural system for image captioning is roughly based on the paper "Show, Attend and Tell: Neural Image Caption Generation with Visual
 749 Dec 28, 2022
749 Dec 28, 2022
![[3DV 2021] Channel-Wise Attention-Based Network for Self-Supervised Monocular Depth Estimation](https://github.com/kamiLight/CADepth-master/raw/main/images/Quantitative_result.png)
[3DV 2021] Channel-Wise Attention-Based Network for Self-Supervised Monocular Depth Estimation
Channel-Wise Attention-Based Network for Self-Supervised Monocular Depth Estimation This is the official implementation for the method described in Ch
 27 Dec 30, 2022
27 Dec 30, 2022
AlexaUsingPython - Alexa will pay attention to your order, as: Hello Alexa, play music, Hello Alexa
AlexaUsingPython - Alexa will pay attention to your order, as: Hello Alexa, play music, Hello Alexa, what's the time? Alexa will pay attention to your order, get it, and afterward do some activity as indicated by your order.
 10 Aug 18, 2022
10 Aug 18, 2022

Tensorflow-seq2seq-tutorials - Dynamic seq2seq in TensorFlow, step by step
seq2seq with TensorFlow Collection of unfinished tutorials. May be good for educational purposes. 1 - simple sequence-to-sequence model with dynamic u
 1k Dec 17, 2022
1k Dec 17, 2022

Awesome Graph Classification - A collection of important graph embedding, classification and representation learning papers with implementations.
A collection of graph classification methods, covering embedding, deep learning, graph kernel and factorization papers
 4.5k Jan 1, 2023
4.5k Jan 1, 2023

A Tensorflow implementation of CapsNet based on Geoffrey Hinton's paper Dynamic Routing Between Capsules
CapsNet-Tensorflow A Tensorflow implementation of CapsNet based on Geoffrey Hinton's paper Dynamic Routing Between Capsules Notes: The current version
 3.8k Dec 29, 2022
3.8k Dec 29, 2022

Transformer - A TensorFlow Implementation of the Transformer: Attention Is All You Need
[UPDATED] A TensorFlow Implementation of Attention Is All You Need When I opened this repository in 2017, there was no official code yet. I tried to i
 3.8k Dec 26, 2022
3.8k Dec 26, 2022

PathPlanning - Common used path planning algorithms with animations.
Overview This repository implements some common path planning algorithms used in robotics, including Search-based algorithms and Sampling-based algori
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
Offical implementation of Shunted Self-Attention via Multi-Scale Token Aggregation
Shunted Transformer This is the offical implementation of Shunted Self-Attention via Multi-Scale Token Aggregation by Sucheng Ren, Daquan Zhou, Shengf
 156 Dec 27, 2022
156 Dec 27, 2022

Learning Dynamic Network Using a Reuse Gate Function in Semi-supervised Video Object Segmentation.
Training Script for Reuse-VOS This code implementation of CVPR 2021 paper : Learning Dynamic Network Using a Reuse Gate Function in Semi-supervised Vi
 22 Jan 1, 2023
22 Jan 1, 2023
Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation, CVPR 2020 (Oral)
SEAM The implementation of Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentaion. You can also download the repos
 459 Dec 26, 2022
459 Dec 26, 2022
A PyTorch implementation of "SelfGNN: Self-supervised Graph Neural Networks without explicit negative sampling"
SelfGNN A PyTorch implementation of "SelfGNN: Self-supervised Graph Neural Networks without explicit negative sampling" paper, which will appear in Th
 24 Jun 21, 2022
24 Jun 21, 2022
Pretraining on Dynamic Graph Neural Networks
Pretraining on Dynamic Graph Neural Networks Our article is PT-DGNN and the code is modified based on GPT-GNN Requirements python 3.6 Ubuntu 18.04.5 L
 7 Dec 17, 2022
7 Dec 17, 2022
General neural ODE and DAE modules for power system dynamic modeling.
Py_PSNODE General neural ODE and DAE modules for power system dynamic modeling. The PyTorch-based ODE solver is developed based on torchdiffeq. Sample
 14 Dec 31, 2022
14 Dec 31, 2022

Source code of the "Graph-Bert: Only Attention is Needed for Learning Graph Representations" paper
Graph-Bert Source code of "Graph-Bert: Only Attention is Needed for Learning Graph Representations". Please check the script.py as the entry point. We
 14 Mar 25, 2022
14 Mar 25, 2022

AdaFocus V2: End-to-End Training of Spatial Dynamic Networks for Video Recognition
AdaFocusV2 This repo contains the official code and pre-trained models for AdaFo
79 Dec 26, 2022

TensorFlow implementation of "Attention is all you need (Transformer)"
[TensorFlow 2] Attention is all you need (Transformer) TensorFlow implementation of "Attention is all you need (Transformer)" Dataset The MNIST datase
 4 Jan 5, 2022
4 Jan 5, 2022
The code for SAG-DTA: Prediction of Drug–Target Affinity Using Self-Attention Graph Network.
SAG-DTA The code is the implementation for the paper 'SAG-DTA: Prediction of Drug–Target Affinity Using Self-Attention Graph Network'. Requirements py
 7 Aug 2, 2022
7 Aug 2, 2022

XViT - Space-time Mixing Attention for Video Transformer
XViT - Space-time Mixing Attention for Video Transformer This is the official implementation of the XViT paper: @inproceedings{bulat2021space, title
 33 Dec 23, 2022
33 Dec 23, 2022

Attention for PyTorch with Linear Memory Footprint
Attention for PyTorch with Linear Memory Footprint Unofficially implements https://arxiv.org/abs/2112.05682 to get Linear Memory Cost on Attention (+
 11 Jan 9, 2022
11 Jan 9, 2022
PyTorch implementation of Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.
ALiBi PyTorch implementation of Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. Quickstart Clone this reposit
 4 Jul 27, 2022
4 Jul 27, 2022

Learning hierarchical attention for weakly-supervised chest X-ray abnormality localization and diagnosis
Hierarchical Attention Mining (HAM) for weakly-supervised abnormality localization This is the official PyTorch implementation for the HAM method. Pap
 22 Jan 2, 2023
22 Jan 2, 2023
Multi-Probe Attention for Semantic Indexing
Multi-Probe Attention for Semantic Indexing About This project is developed for the topic of COVID-19 semantic indexing. Directories & files A. The di
 1 Dec 18, 2022
1 Dec 18, 2022
A human-readable PyTorch implementation of "Self-attention Does Not Need O(n^2) Memory"
memory_efficient_attention.pytorch A human-readable PyTorch implementation of "Self-attention Does Not Need O(n^2) Memory" (Rabe&Staats'21). def effic
 7 Dec 26, 2022
7 Dec 26, 2022
Weak-supervised Visual Geo-localization via Attention-based Knowledge Distillation
Weak-supervised Visual Geo-localization via Attention-based Knowledge Distillation Introduction WAKD is a PyTorch implementation for our ICPR-2022 pap
 2 Oct 20, 2022
2 Oct 20, 2022
Flexible constructor to create dynamic list of heterogeneous properties for some kind of entity
Flexible constructor to create dynamic list of heterogeneous properties for some kind of entity. This set of helpers useful to create properties like contacts or attributes for describe car/computer/etc.
 24 Jul 21, 2022
24 Jul 21, 2022

ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python)
ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python) 日本語は以下に続きます (Japanese follows) English: This book is written in Japanese and primaril
 189 Dec 29, 2022
189 Dec 29, 2022
Source code of D-HAN: Dynamic News Recommendation with Hierarchical Attention Network
D-HAN The source code of D-HAN This is the source code of D-HAN: Dynamic News Recommendation with Hierarchical Attention Network. However, only the co
 30 Sep 22, 2022
30 Sep 22, 2022
NumPy aware dynamic Python compiler using LLVM
Numba A Just-In-Time Compiler for Numerical Functions in Python Numba is an open source, NumPy-aware optimizing compiler for Python sponsored by Anaco
 8.2k Jan 7, 2023
8.2k Jan 7, 2023

Implementation of our paper "DMT: Dynamic Mutual Training for Semi-Supervised Learning"
DMT: Dynamic Mutual Training for Semi-Supervised Learning This repository contains the code for our paper DMT: Dynamic Mutual Training for Semi-Superv
 120 Dec 30, 2022
120 Dec 30, 2022
simple demo codes for Learning to Teach with Dynamic Loss Functions
Learning to Teach with Dynamic Loss Functions This repo contains the simple demo for the NeurIPS-18 paper: Learning to Teach with Dynamic Loss Functio
 15 Dec 30, 2021
15 Dec 30, 2021
Dynamic Twitter banner, to show off your spotify status. Banner updated every 5 minutes.
Spotify Twitter Banner Dynamic Twitter banner, to show off your spotify status. Banner updated every 5 minutes. Installation and Usage Install the dep
 23 Jan 5, 2023
23 Jan 5, 2023

Codes for “A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection”
DSAMNet The pytorch implementation for "A Deeply-supervised Attention Metric-based Network and an Open Aerial Image Dataset for Remote Sensing Change
 41 Dec 14, 2022
41 Dec 14, 2022

CoANet: Connectivity Attention Network for Road Extraction From Satellite Imagery
CoANet: Connectivity Attention Network for Road Extraction From Satellite Imagery This paper (CoANet) has been published in IEEE TIP 2021. This code i
 53 Dec 3, 2022
53 Dec 3, 2022

Official Pytorch implementation of the paper: "Locally Shifted Attention With Early Global Integration"
Locally-Shifted-Attention-With-Early-Global-Integration Pretrained models You can download all the models from here. Training Imagenet python -m torch
 14 Apr 15, 2022
14 Apr 15, 2022

A-ESRGAN aims to provide better super-resolution images by using multi-scale attention U-net discriminators.
A-ESRGAN: Training Real-World Blind Super-Resolution with Attention-based U-net Discriminators The authors are hidden for the purpose of double blind
 77 Dec 16, 2022
77 Dec 16, 2022
A dynamic multi-STL, multi-process OpenSCAD build system with autoplating support
scad-build This is a multi-STL OpenSCAD build system based around GNU make. It supports dynamic build targets, intelligent previews with user-defined
 1 Dec 21, 2021
1 Dec 21, 2021

Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition"
Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition" Pre-trained Deep Convo
 5 Nov 11, 2022
5 Nov 11, 2022
RapiDAST provides a framework for continuous, proactive and fully automated dynamic scanning against web apps/API.
RapiDAST RapiDAST provides a framework for continuous, proactive and fully automated dynamic scanning against web apps/API. Its core engine is OWASP Z
 17 Nov 11, 2022
17 Nov 11, 2022
A great python/java dynamic DNS service for NameSilo, with log, email reminder...
English NameSilo DDNS is a DDNS service for NameSilo domain names for home broadband , it can automatically detect IP changes in home broadband
 77 Dec 28, 2022
77 Dec 28, 2022
TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
902 Nov 29, 2022
![[CVPR 2019 Oral] Multi-Channel Attention Selection GAN with Cascaded Semantic Guidance for Cross-View Image Translation](https://github.com/Ha0Tang/SelectionGAN/raw/master/imgs/motivation.jpg)
[CVPR 2019 Oral] Multi-Channel Attention Selection GAN with Cascaded Semantic Guidance for Cross-View Image Translation
SelectionGAN for Guided Image-to-Image Translation CVPR Paper | Extended Paper | Guided-I2I-Translation-Papers Citation If you use this code for your
424 Dec 2, 2022
Memory Efficient Attention (O(sqrt(n)) for Jax and PyTorch
Memory Efficient Attention This is unofficial implementation of Self-attention Does Not Need O(n^2) Memory for Jax and PyTorch. Implementation is almo
 126 Dec 27, 2022
126 Dec 27, 2022
Code for "Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans" CVPR 2021 best paper candidate
News 05/17/2021 To make the comparison on ZJU-MoCap easier, we save quantitative and qualitative results of other methods at here, including Neural Vo
 748 Jan 7, 2023
748 Jan 7, 2023

Hierarchical Cross-modal Talking Face Generation with Dynamic Pixel-wise Loss (ATVGnet)
Hierarchical Cross-modal Talking Face Generation with Dynamic Pixel-wise Loss (ATVGnet) By Lele Chen , Ross K Maddox, Zhiyao Duan, Chenliang Xu. Unive
 218 Dec 27, 2022
218 Dec 27, 2022

Code for the paper Progressive Pose Attention for Person Image Generation in CVPR19 (Oral).
Pose-Transfer Code for the paper Progressive Pose Attention for Person Image Generation in CVPR19(Oral). The paper is available here. Video generation
 679 Jan 4, 2023
679 Jan 4, 2023
Resolve form field arguments dynamically when a form is instantiated
django-forms-dynamic Resolve form field arguments dynamically when a form is instantiated, not when it's declared. Tested against Django 2.2, 3.2 and
 108 Jan 3, 2023
108 Jan 3, 2023

The official implementation of the Hybrid Self-Attention NEAT algorithm
PUREPLES - Pure Python Library for ES-HyperNEAT About This is a library of evolutionary algorithms with a focus on neuroevolution, implemented in pure
 91 Dec 12, 2022
91 Dec 12, 2022
GANformer: Generative Adversarial Transformers
GANformer: Generative Adversarial Transformers Drew A. Hudson* & C. Lawrence Zitnick Update: We released the new GANformer2 paper! *I wish to thank Ch
 1k Dec 16, 2021
1k Dec 16, 2021
Edge-Augmented Graph Transformer
Edge-augmented Graph Transformer Introduction This is the official implementation of the Edge-augmented Graph Transformer (EGT) as described in https:
 21 Dec 14, 2022
21 Dec 14, 2022

Nystromformer: A Nystrom-based Algorithm for Approximating Self-Attention
Nystromformer: A Nystrom-based Algorithm for Approximating Self-Attention April 6, 2021 We extended segment-means to compute landmarks without requiri
 322 Jan 1, 2023
322 Jan 1, 2023

Sinkhorn Transformer - Practical implementation of Sparse Sinkhorn Attention
Sinkhorn Transformer This is a reproduction of the work outlined in Sparse Sinkhorn Attention, with additional enhancements. It includes a parameteriz
217 Nov 25, 2022
ConvBERT: Improving BERT with Span-based Dynamic Convolution
ConvBERT Introduction In this repo, we introduce a new architecture ConvBERT for pre-training based language model. The code is tested on a V100 GPU.
 237 Dec 10, 2022
237 Dec 10, 2022

An implementation of the Pay Attention when Required transformer
Pay Attention when Required (PAR) Transformer-XL An implementation of the Pay Attention when Required transformer from the paper: https://arxiv.org/pd
 7 Aug 11, 2022
7 Aug 11, 2022
DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
DeeBERT This is the code base for the paper DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference. Code in this repository is also available
 132 Nov 14, 2022
132 Nov 14, 2022

Fully featured implementation of Routing Transformer
Routing Transformer A fully featured implementation of Routing Transformer. The paper proposes using k-means to route similar queries / keys into the
246 Jan 2, 2023

Reproducing the Linear Multihead Attention introduced in Linformer paper (Linformer: Self-Attention with Linear Complexity)
Linear Multihead Attention (Linformer) PyTorch Implementation of reproducing the Linear Multihead Attention introduced in Linformer paper (Linformer:
 58 Dec 23, 2022
58 Dec 23, 2022
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
DeBERTa: Decoding-enhanced BERT with Disentangled Attention This repository is the official implementation of DeBERTa: Decoding-enhanced BERT with Dis
 1.2k Jan 3, 2023
1.2k Jan 3, 2023
Examples of using sparse attention, as in "Generating Long Sequences with Sparse Transformers"
Status: Archive (code is provided as-is, no updates expected) Update August 2020: For an example repository that achieves state-of-the-art modeling pe
 1.3k Dec 28, 2022
1.3k Dec 28, 2022
PyContinual (An Easy and Extendible Framework for Continual Learning)
PyContinual (An Easy and Extendible Framework for Continual Learning) Easy to Use You can sumply change the baseline, backbone and task, and then read
 176 Jan 5, 2023
176 Jan 5, 2023