312 Repositories
Python embeddings-trained Libraries
Discovering Explanatory Sentences in Legal Case Decisions Using Pre-trained Language Models.
Statutory Interpretation Data Set This repository contains the data set created for the following research papers: Savelka, Jaromir, and Kevin D. Ashl
 17 Dec 23, 2022
17 Dec 23, 2022

A high-performance distributed deep learning system targeting large-scale and automated distributed training.
HETU Documentation | Examples Hetu is a high-performance distributed deep learning system targeting trillions of parameters DL model training, develop
 150 Dec 21, 2022
150 Dec 21, 2022
Code for WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models.
WECHSEL Code for WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models. arXiv: https://arx
 45 Dec 29, 2022
45 Dec 29, 2022
Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts
t5-japanese Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts. The following is a list of models that
 1 Dec 13, 2021
1 Dec 13, 2021
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022
A python code to convert Keras pre-trained weights to Pytorch version
Weights_Keras_2_Pytorch 最近想在Pytorch项目里使用一下谷歌的NIMA,但是发现没有预训练好的pytorch权重,于是整理了一下将Keras预训练权重转为Pytorch的代码,目前是支持Keras的Conv2D, Dense, DepthwiseConv2D, Batch
 2 Dec 16, 2021
2 Dec 16, 2021
Scripts and outputs related to the paper Prediction of Adverse Biological Effects of Chemicals Using Knowledge Graph Embeddings.
Knowledge Graph Embeddings and Chemical Effect Prediction, 2020. Scripts and outputs related to the paper Prediction of Adverse Biological Effects of
 1 Nov 1, 2021
1 Nov 1, 2021

VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
VarCLR: Variable Representation Pre-training via Contrastive Learning New: Paper accepted by ICSE 2022. Preprint at arXiv! This repository contain
 14 Dec 10, 2021
14 Dec 10, 2021
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce (EMNLP Founding 2021)
Introduction K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce. Installation PyTor
 21 Nov 16, 2022
21 Nov 16, 2022

RuleBERT: Teaching Soft Rules to Pre-Trained Language Models
RuleBERT: Teaching Soft Rules to Pre-Trained Language Models (Paper) (Slides) (Video) RuleBERT is a pre-trained language model that has been fine-tune
 16 Aug 24, 2022
16 Aug 24, 2022

ViSER: Video-Specific Surface Embeddings for Articulated 3D Shape Reconstruction
ViSER: Video-Specific Surface Embeddings for Articulated 3D Shape Reconstruction. NeurIPS 2021.
 59 Nov 25, 2022
59 Nov 25, 2022

Translate darknet to tensorflow. Load trained weights, retrain/fine-tune using tensorflow, export constant graph def to mobile devices
Intro Real-time object detection and classification. Paper: version 1, version 2. Read more about YOLO (in darknet) and download weight files here. In
 6.1k Dec 30, 2022
6.1k Dec 30, 2022
VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
VarCLR: Variable Representation Pre-training via Contrastive Learning New: Paper accepted by ICSE 2022. Preprint at arXiv! This repository contain
32 Oct 24, 2022
BERTMap: A BERT-Based Ontology Alignment System
BERTMap: A BERT-based Ontology Alignment System Important Notices The relevant paper was accepted in AAAI-2022. Arxiv version is available at: https:/
 36 Dec 24, 2022
36 Dec 24, 2022
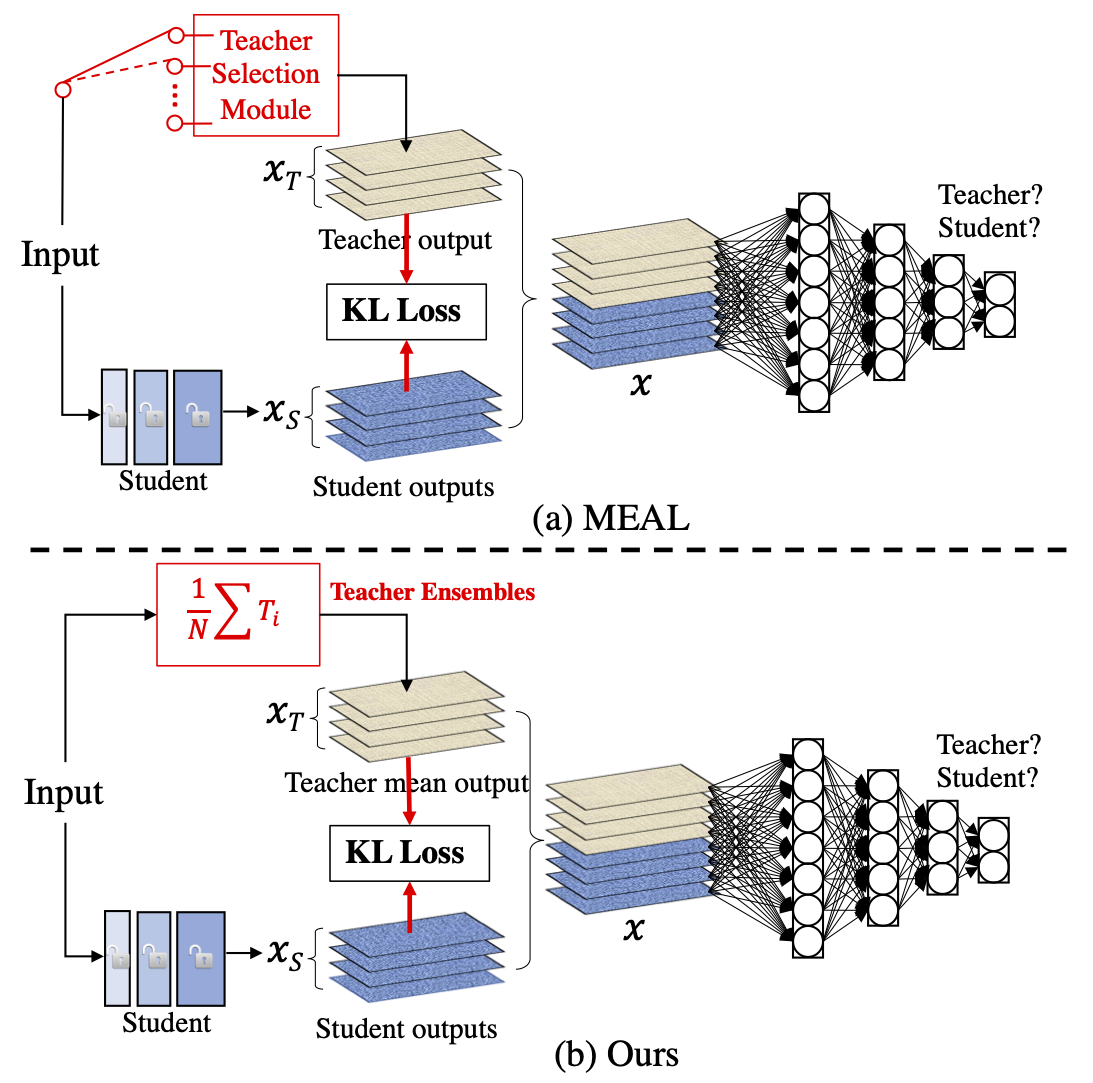
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022

Official Pytorch implementation for 2021 ICCV paper "Learning Motion Priors for 4D Human Body Capture in 3D Scenes" and trained models / data
Learning Motion Priors for 4D Human Body Capture in 3D Scenes (LEMO) Official Pytorch implementation for 2021 ICCV (oral) paper "Learning Motion Prior
 165 Dec 19, 2022
165 Dec 19, 2022
100+ Chinese Word Vectors 上百种预训练中文词向量
Chinese Word Vectors 中文词向量 中文 This project provides 100+ Chinese Word Vectors (embeddings) trained with different representations (dense and sparse),
 10.4k Jan 9, 2023
10.4k Jan 9, 2023
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
 463 Dec 30, 2022
463 Dec 30, 2022
Optimus: the first large-scale pre-trained VAE language model
Optimus: the first pre-trained Big VAE language model This repository contains source code necessary to reproduce the results presented in the EMNLP 2
 314 Dec 19, 2022
314 Dec 19, 2022
(ACL-IJCNLP 2021) Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models.
BERT Convolutions Code for the paper Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models. Contains expe
 21 Jul 18, 2022
21 Jul 18, 2022
LUKE -- Language Understanding with Knowledge-based Embeddings
LUKE (Language Understanding with Knowledge-based Embeddings) is a new pre-trained contextualized representation of words and entities based on transf
 587 Dec 30, 2022
587 Dec 30, 2022
Source code for TACL paper "KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation".
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation Source code for TACL 2021 paper KEPLER: A Unified Model for Kn
 138 Dec 22, 2022
138 Dec 22, 2022
Phrase-BERT: Improved Phrase Embeddings from BERT with an Application to Corpus Exploration
Phrase-BERT: Improved Phrase Embeddings from BERT with an Application to Corpus Exploration This is the official repository for the EMNLP 2021 long pa
 70 Dec 11, 2022
70 Dec 11, 2022
Code and pre-trained models for "ReasonBert: Pre-trained to Reason with Distant Supervision", EMNLP'2021
ReasonBERT Code and pre-trained models for ReasonBert: Pre-trained to Reason with Distant Supervision, EMNLP'2021 Pretrained Models The pretrained mod
 29 Dec 19, 2022
29 Dec 19, 2022

Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks. [NeurIPS
 122 Dec 14, 2022
122 Dec 14, 2022

The official implementation of "BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?, ACL 2021 main conference"
BERT is to NLP what AlexNet is to CV This is the official implementation of BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Iden
 20 Nov 3, 2022
20 Nov 3, 2022
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization (ACL 2021)
Structured Super Lottery Tickets in BERT This repo contains our codes for the paper "Super Tickets in Pre-Trained Language Models: From Model Compress
 16 Dec 11, 2022
16 Dec 11, 2022

Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators This is our Pytorch implementation for t
 12 Jul 22, 2022
12 Jul 22, 2022

Source code for the ACL-IJCNLP 2021 paper entitled "T-DNA: Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adaptation" by Shizhe Diao et al.
T-DNA Source code for the ACL-IJCNLP 2021 paper entitled Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adapta
 17 Dec 22, 2022
17 Dec 22, 2022
Official Implementation of "Learning Disentangled Behavior Embeddings"
DBE: Disentangled-Behavior-Embedding Official implementation of Learning Disentangled Behavior Embeddings (NeurIPS 2021). Environment requirement The
 12 Sep 28, 2022
12 Sep 28, 2022
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
124 Jan 2, 2023
OpenL3: Open-source deep audio and image embeddings
OpenL3 OpenL3 is an open-source Python library for computing deep audio and image embeddings. Please refer to the documentation for detailed instructi
 326 Jan 2, 2023
326 Jan 2, 2023
Pre-trained Deep Learning models and demos (high quality and extremely fast)
OpenVINO™ Toolkit - Open Model Zoo repository This repository includes optimized deep learning models and a set of demos to expedite development of hi
 3.4k Dec 31, 2022
3.4k Dec 31, 2022
KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
KoGPT KoGPT (Korean Generative Pre-trained Transformer) https://github.com/kakaobrain/kogpt https://huggingface.co/kakaobrain/kogpt Model Descriptions
 799 Dec 28, 2022
799 Dec 28, 2022
Generate text captions for images from their CLIP embeddings. Includes PyTorch model code and example training script.
clip-text-decoder Generate text captions for images from their CLIP embeddings. Includes PyTorch model code and example training script. Example Predi
 36 Dec 21, 2022
36 Dec 21, 2022
Resources related to EMNLP 2021 paper "FAME: Feature-Based Adversarial Meta-Embeddings for Robust Input Representations"
FAME: Feature-based Adversarial Meta-Embeddings This is the companion code for the experiments reported in the paper "FAME: Feature-Based Adversarial
 11 Nov 27, 2022
11 Nov 27, 2022
VGGVox models for Speaker Identification and Verification trained on the VoxCeleb (1 & 2) datasets
VGGVox models for speaker identification and verification This directory contains code to import and evaluate the speaker identification and verificat
 338 Dec 27, 2022
338 Dec 27, 2022
Switch spaces for knowledge graph embeddings
SwisE Switch spaces for knowledge graph embeddings. Requirements: python3 pytorch numpy tqdm Reproduce the results To reproduce the reported results,
 4 Dec 1, 2021
4 Dec 1, 2021
Exploring dimension-reduced embeddings
sleepwalk Exploring dimension-reduced embeddings This is the code repository. See here for the Sleepwalk web page. License and disclaimer This program
 91 Nov 29, 2022
91 Nov 29, 2022
A fast, efficient universal vector embedding utility package.
Magnitude: a fast, simple vector embedding utility library A feature-packed Python package and vector storage file format for utilizing vector embeddi
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Repo for the paper "DiLBERT: Cheap Embeddings for Disease Related Medical NLP"
DiLBERT Repo for the paper "DiLBERT: Cheap Embeddings for Disease Related Medical NLP" Pretrained Model The pretrained model presented in the paper is
 2 Dec 15, 2022
2 Dec 15, 2022
TensorFlow code and pre-trained models for BERT
BERT ***** New March 11th, 2020: Smaller BERT Models ***** This is a release of 24 smaller BERT models (English only, uncased, trained with WordPiece
 32.9k Jan 8, 2023
32.9k Jan 8, 2023
Code for the paper "A Simple but Tough-to-Beat Baseline for Sentence Embeddings".
Code for the paper "A Simple but Tough-to-Beat Baseline for Sentence Embeddings".
 1.1k Dec 27, 2022
1.1k Dec 27, 2022
A pre-trained language model for social media text in Spanish
RoBERTuito A pre-trained language model for social media text in Spanish READ THE FULL PAPER Github Repository RoBERTuito is a pre-trained language mo
 25 Dec 29, 2022
25 Dec 29, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 A repository part of the MarIA project. Corpora 📃 Corpora Number of documents Number of tokens Size (GB) BNE 201,080,084
 203 Dec 20, 2022
203 Dec 20, 2022

This is the code used in the paper "Entity Embeddings of Categorical Variables".
This is the code used in the paper "Entity Embeddings of Categorical Variables". If you want to get the original version of the code used for the Kagg
 845 Nov 29, 2022
845 Nov 29, 2022
Hummingbird compiles trained ML models into tensor computation for faster inference.
Hummingbird Introduction Hummingbird is a library for compiling trained traditional ML models into tensor computations. Hummingbird allows users to se
 3.1k Dec 30, 2022
3.1k Dec 30, 2022
Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings
Text2Music Emotion Embedding Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings Reference Emotion Embedding Spaces for Matching
 50 Dec 5, 2022
50 Dec 5, 2022
Source code for our EMNLP'21 paper 《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》
Child-Tuning Source code for EMNLP 2021 Long paper: Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning. 1. Environ
 46 Dec 12, 2022
46 Dec 12, 2022
Transpile trained scikit-learn estimators to C, Java, JavaScript and others.
sklearn-porter Transpile trained scikit-learn estimators to C, Java, JavaScript and others. It's recommended for limited embedded systems and critical
 1.2k Jan 5, 2023
1.2k Jan 5, 2023
TensorFlow implementation of ENet, trained on the Cityscapes dataset.
segmentation TensorFlow implementation of ENet (https://arxiv.org/pdf/1606.02147.pdf) based on the official Torch implementation (https://github.com/e
 248 Dec 16, 2022
248 Dec 16, 2022
Segmentation models with pretrained backbones. Keras and TensorFlow Keras.
Python library with Neural Networks for Image Segmentation based on Keras and TensorFlow. The main features of this library are: High level API (just
 4.2k Jan 9, 2023
4.2k Jan 9, 2023
UNet model with VGG11 encoder pre-trained on Kaggle Carvana dataset
TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation By Vladimir Iglovikov and Alexey Shvets Introduction TernausNet is
 1k Dec 28, 2022
1k Dec 28, 2022
PyQT5 app that colorize black & white pictures using CNN(use pre-trained model which was made with OpenCV)
About PyQT5 app that colorize black & white pictures using CNN(use pre-trained model which was made with OpenCV) Colorizor Приложение для проекта Yand
 1 Apr 4, 2022
1 Apr 4, 2022
KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
KoGPT KoGPT (Korean Generative Pre-trained Transformer) https://github.com/kakaobrain/kogpt https://huggingface.co/kakaobrain/kogpt Model Descriptions
797 Dec 26, 2022

Code repository for EMNLP 2021 paper 'Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods'
Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods This is the code repository to accompany the EMNLP 2021 paper on ad
 7 Sep 25, 2022
7 Sep 25, 2022
In this Repo a simple Sklearn Model will be trained and pushed to MLFlow
SKlearn_to_MLFLow In this Repo a simple Sklearn Model will be trained and pushed to MLFlow Install This Repo is based on poetry python3 -m venv .venv
 1 Dec 13, 2021
1 Dec 13, 2021
PyTorch implementation of Spiking Neural Networks trained on surrogate gradient & BPTT using snntorch.
snn-localization repo PyTorch implementation of Spiking Neural Networks trained on surrogate gradient & BPTT using snntorch. Install Dependencies Orig
 1 Jan 6, 2022
1 Jan 6, 2022
Chinese Pre-Trained Language Models (CPM-LM) Version-I
CPM-Generate 为了促进中文自然语言处理研究的发展,本项目提供了 CPM-LM (2.6B) 模型的文本生成代码,可用于文本生成的本地测试,并以此为基础进一步研究零次学习/少次学习等场景。[项目首页] [模型下载] [技术报告] 若您想使用CPM-1进行推理,我们建议使用高效推理工具BMI
 1.4k Jan 3, 2023
1.4k Jan 3, 2023
🌸 fastText + Bloom embeddings for compact, full-coverage vectors with spaCy
floret: fastText + Bloom embeddings for compact, full-coverage vectors with spaCy floret is an extended version of fastText that can produce word repr
 222 Dec 16, 2022
222 Dec 16, 2022
A method to perform unsupervised cross-region adaptation of crop classifiers trained with satellite image time series.
TimeMatch Official source code of TimeMatch: Unsupervised Cross-region Adaptation by Temporal Shift Estimation by Joachim Nyborg, Charlotte Pelletier,
 17 Nov 1, 2022
17 Nov 1, 2022
An Open-Source Toolkit for Prompt-Learning.
An Open-Source Framework for Prompt-learning. Overview • Installation • How To Use • Docs • Paper • Citation • What's New? Nov 2021: Now we have relea
 2.3k Jan 7, 2023
2.3k Jan 7, 2023
DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models
DSEE Codes for [Preprint] DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models Xuxi Chen, Tianlong Chen, Yu Cheng, Weizhu Ch
4 Dec 27, 2021
gtfs2vec - Learning GTFS Embeddings for comparing PublicTransport Offer in Microregions
gtfs2vec This is a companion repository for a gtfs2vec - Learning GTFS Embeddings for comparing PublicTransport Offer in Microregions publication. Vis
 5 Oct 10, 2022
5 Oct 10, 2022
PyTorch implementation of a Real-ESRGAN model trained on custom dataset
Real-ESRGAN PyTorch implementation of a Real-ESRGAN model trained on custom dataset. This model shows better results on faces compared to the original
 160 Jan 4, 2023
160 Jan 4, 2023
The code of paper ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs. Zhanqiu Zhang, Jie Wang, Jiajun Chen, Shuiwang Ji, Feng Wu. NeurIPS 2021.
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs This is the code of paper ConE: Cone Embeddings for Multi-Hop Reasoning over Knowl
 3 Oct 28, 2021
3 Oct 28, 2021
Face recognition with trained classifiers for detecting objects using OpenCV
Face_Detector Face recognition with trained classifiers for detecting objects using OpenCV Libraries required to be installed using pip Command: cv2 n
 0 Oct 31, 2021
0 Oct 31, 2021
a reccurrent neural netowrk that when trained on a peice of text and fed a starting prompt will write its on 250 character text using LSTM layers
RNN-Playwrite a reccurrent neural netowrk that when trained on a peice of text and fed a starting prompt will write its on 250 character text using LS
 1 Oct 29, 2021
1 Oct 29, 2021
With this package, you can generate mixed-integer linear programming (MIP) models of trained artificial neural networks (ANNs) using the rectified linear unit (ReLU) activation function
With this package, you can generate mixed-integer linear programming (MIP) models of trained artificial neural networks (ANNs) using the rectified linear unit (ReLU) activation function. At the moment, only TensorFlow sequential models are supported. Interfaces to either the Pyomo or Gurobi modeling environments are offered.
 40 Dec 27, 2022
40 Dec 27, 2022
A PyTorch implementation of unsupervised SimCSE
A PyTorch implementation of unsupervised SimCSE
 99 Dec 23, 2022
99 Dec 23, 2022
A pre-trained model with multi-exit transformer architecture.
ElasticBERT This repository contains finetuning code and checkpoints for ElasticBERT. Towards Efficient NLP: A Standard Evaluation and A Strong Baseli
 48 Dec 14, 2022
48 Dec 14, 2022
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs This is the code of paper ConE: Cone Embeddings for Multi-Hop Reasoning over Knowl
33 Dec 7, 2022
Towhee is a flexible machine learning framework currently focused on computing deep learning embeddings over unstructured data.
Towhee is a flexible machine learning framework currently focused on computing deep learning embeddings over unstructured data.
 1.7k Jan 8, 2023
1.7k Jan 8, 2023
ElasticBERT: A pre-trained model with multi-exit transformer architecture.
This repository contains finetuning code and checkpoints for ElasticBERT. Towards Efficient NLP: A Standard Evaluation and A Strong Baseli
48 Dec 14, 2022
Language Models for the legal domain in Spanish done @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish legal domain Language Model ⚖️ This repository contains the page for two main resources for the Spanish legal domain: A RoBERTa model: https:/
12 Nov 14, 2022

Convolutional neural network web app trained to track our infant’s sleep schedule using our Google Nest camera.
Machine Learning Sleep Schedule Tracker What is it? Convolutional neural network web app trained to track our infant’s sleep schedule using our Google
 7 Jul 15, 2022
7 Jul 15, 2022

PyTorch implementation of Octave Convolution with pre-trained Oct-ResNet and Oct-MobileNet models
octconv.pytorch PyTorch implementation of Octave Convolution in Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octa
 273 Dec 18, 2022
273 Dec 18, 2022
Official code for the paper Inverse Problems Leveraging Pre-trained Contrastive Representations.
The official code for the paper "Inverse Problems Leveraging Pre-trained Contrastive Representations" (to appear in NeurIPS 2021).
 16 Oct 24, 2021
16 Oct 24, 2021
Bootstrapped Unsupervised Sentence Representation Learning (ACL 2021)
Install first pip3 install -e . Training python3 training/unsupervised_tuning.py python3 training/supervised_tuning.py python3 training/multilingual_
 26 Jul 22, 2022
26 Jul 22, 2022

Code for reproducing our paper: LMSOC: An Approach for Socially Sensitive Pretraining
LMSOC: An Approach for Socially Sensitive Pretraining Code for reproducing the paper LMSOC: An Approach for Socially Sensitive Pretraining to appear a
 11 Dec 20, 2022
11 Dec 20, 2022

This repository contains all source code, pre-trained models related to the paper "An Empirical Study on GANs with Margin Cosine Loss and Relativistic Discriminator"
An Empirical Study on GANs with Margin Cosine Loss and Relativistic Discriminator This is a Pytorch implementation for the paper "An Empirical Study o
 3 Nov 15, 2021
3 Nov 15, 2021
A Word Level Transformer layer based on PyTorch and 🤗 Transformers.
Transformer Embedder A Word Level Transformer layer based on PyTorch and 🤗 Transformers. How to use Install the library from PyPI: pip install transf
 27 Nov 20, 2022
27 Nov 20, 2022

Implementation of CVAE. Trained CVAE on faces from UTKFace Dataset to produce synthetic faces with a given degree of happiness/smileyness.
Conditional Smiles! (SmileCVAE) About Implementation of AE, VAE and CVAE. Trained CVAE on faces from UTKFace Dataset. Using an encoding of the Smile-s
 3 Jan 9, 2022
3 Jan 9, 2022
Implementation of Natural Language Code Search in the project CodeBERT: A Pre-Trained Model for Programming and Natural Languages.
CodeBERT-Implementation In this repo we have replicated the paper CodeBERT: A Pre-Trained Model for Programming and Natural Languages. We are interest
 4 Jul 1, 2022
4 Jul 1, 2022

Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
 794 Dec 31, 2022
794 Dec 31, 2022
Vector AI — A platform for building vector based applications. Encode, query and analyse data using vectors.
Vector AI is a framework designed to make the process of building production grade vector based applications as quickly and easily as possible. Create
 267 Dec 23, 2022
267 Dec 23, 2022

EMNLP'2021: SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
 2.5k Dec 29, 2022
2.5k Dec 29, 2022

An NLP library with Awesome pre-trained Transformer models and easy-to-use interface, supporting wide-range of NLP tasks from research to industrial applications.
简体中文 | English News [2021-10-12] PaddleNLP 2.1版本已发布!新增开箱即用的NLP任务能力、Prompt Tuning应用示例与生成任务的高性能推理! 🎉 更多详细升级信息请查看Release Note。 [2021-08-22]《千言:面向事实一致性的生
 6.9k Jan 1, 2023
6.9k Jan 1, 2023
Code for ICML2019 Paper "Compositional Invariance Constraints for Graph Embeddings"
Dependencies NOTE: This code has been updated, if you were using this repo earlier and experienced issues that was due to an outaded codebase. Please
 43 Nov 25, 2022
43 Nov 25, 2022
SciBERT is a BERT model trained on scientific text.
SciBERT is a BERT model trained on scientific text.
 1.2k Dec 24, 2022
1.2k Dec 24, 2022

Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer
MT5_paddle Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer English | 简体中文 mT5: A Massively
 2 Oct 17, 2021
2 Oct 17, 2021
Using contrastive learning and OpenAI's CLIP to find good embeddings for images with lossy transformations
Creating Robust Representations from Pre-Trained Image Encoders using Contrastive Learning Sriram Ravula, Georgios Smyrnis This is the code for our pr
26 Dec 10, 2022

Trained on Simulated Data, Tested in the Real World
Trained on Simulated Data, Tested in the Real World
 43 Nov 18, 2022
43 Nov 18, 2022
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022
A cross-document event and entity coreference resolution system, trained and evaluated on the ECB+ corpus.
A Comprehensive Comparison of Word Embeddings in Event & Entity Coreference Resolution. Introduction This repo contains experimental code derived from
 2 May 9, 2022
2 May 9, 2022
Code repository for the paper "Doubly-Trained Adversarial Data Augmentation for Neural Machine Translation" with instructions to reproduce the results.
Doubly Trained Neural Machine Translation System for Adversarial Attack and Data Augmentation Languages Experimented: Data Overview: Source Target Tra
 1 Aug 18, 2022
1 Aug 18, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023