206 Repositories
Python vectors-trained Libraries

Code and pre-trained models for MultiMAE: Multi-modal Multi-task Masked Autoencoders
MultiMAE: Multi-modal Multi-task Masked Autoencoders Roman Bachmann*, David Mizrahi*, Andrei Atanov, Amir Zamir Website | arXiv | BibTeX Official PyTo
 385 Jan 6, 2023
385 Jan 6, 2023
Unified API to facilitate usage of pre-trained "perceptor" models, a la CLIP
mmc installation git clone https://github.com/dmarx/Multi-Modal-Comparators cd 'Multi-Modal-Comparators' pip install poetry poetry build pip install d
 37 Nov 25, 2022
37 Nov 25, 2022

Process text, including tokenizing and representing sentences as vectors and Applying some concepts like RNN, LSTM and GRU to create a classifier can detect the language in which a sentence is written from among 17 languages.
Language Identifier What is this ? The goal of this project is to create a model that is able to predict a given sentence language through text proces
 9 Dec 15, 2022
9 Dec 15, 2022

Guide to using pre-trained large language models of source code
Large Models of Source Code I occasionally train and publicly release large neural language models on programs, including PolyCoder. Here, I describe
 947 Dec 28, 2022
947 Dec 28, 2022

In this tutorial, you will perform inference across 10 well-known pre-trained object detectors and fine-tune on a custom dataset. Design and train your own object detector.
Object Detection Object detection is a computer vision task for locating instances of predefined objects in images or videos. In this tutorial, you wi
 62 Dec 25, 2022
62 Dec 25, 2022

Code for CVPR'2022 paper ✨ "Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model"
PPE ✨ Repository for our CVPR'2022 paper: Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-
 34 Nov 28, 2022
34 Nov 28, 2022

SIGIR'22 paper: Axiomatically Regularized Pre-training for Ad hoc Search
Introduction This codebase contains source-code of the Python-based implementation (ARES) of our SIGIR 2022 paper. Chen, Jia, et al. "Axiomatically Re
 17 Nov 9, 2022
17 Nov 9, 2022
A multi-voice TTS system trained with an emphasis on quality
TorToiSe Tortoise is a text-to-speech program built with the following priorities: Strong multi-voice capabilities. Highly realistic prosody and inton
 2.1k Jan 1, 2023
2.1k Jan 1, 2023
PyTorch Implementation of "Bridging Pre-trained Language Models and Hand-crafted Features for Unsupervised POS Tagging" (Findings of ACL 2022)
Feature_CRF_AE Feature_CRF_AE provides a implementation of Bridging Pre-trained Language Models and Hand-crafted Features for Unsupervised POS Tagging
 6 Apr 29, 2022
6 Apr 29, 2022
Instant-nerf-pytorch - NeRF trained SUPER FAST in pytorch
instant-nerf-pytorch This is WORK IN PROGRESS, please feel free to contribute vi
 94 Nov 22, 2022
94 Nov 22, 2022

SUPERVISED-CONTRASTIVE-LEARNING-FOR-PRE-TRAINED-LANGUAGE-MODEL-FINE-TUNING - The Facebook paper about fine tuning RoBERTa with contrastive loss
"# SUPERVISED-CONTRASTIVE-LEARNING-FOR-PRE-TRAINED-LANGUAGE-MODEL-FINE-TUNING" i
 28 Dec 12, 2022
28 Dec 12, 2022
ATAC: Adversarially Trained Actor Critic
ATAC: Adversarially Trained Actor Critic Adversarially Trained Actor Critic for Offline Reinforcement Learning by Ching-An Cheng*, Tengyang Xie*, Nan
 41 Dec 8, 2022
41 Dec 8, 2022
KoRean based ELECTRA pre-trained models (KR-ELECTRA) for Tensorflow and PyTorch
KoRean based ELECTRA (KR-ELECTRA) This is a release of a Korean-specific ELECTRA model with comparable or better performances developed by the Computa
 12 Jun 3, 2022
12 Jun 3, 2022
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
BROS (BERT Relying On Spatiality) is a pre-trained language model focusing on text and layout for better key information extraction from documents. Given the OCR results of the document image, which are text and bounding box pairs, it can perform various key information extraction tasks, such as extracting an ordered item list from receipts
 94 Dec 30, 2022
94 Dec 30, 2022

A custom DeepStack model that has been trained detecting ONLY the USPS logo
This repository provides a custom DeepStack model that has been trained detecting ONLY the USPS logo. This was created after I discovered that the Deepstack OpenLogo custom model I was using did not contain USPS.
 9 Dec 27, 2022
9 Dec 27, 2022
Explore extreme compression for pre-trained language models
Code for paper "Exploring extreme parameter compression for pre-trained language models ICLR2022"
 16 Nov 14, 2022
16 Nov 14, 2022
/samples.jpg)
A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution.
Awesome Pretrained StyleGAN2 A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution. Note the readme is a
 1.1k Dec 24, 2022
1.1k Dec 24, 2022
Human segmentation models, training/inference code, and trained weights, implemented in PyTorch
Human-Segmentation-PyTorch Human segmentation models, training/inference code, and trained weights, implemented in PyTorch. Supported networks UNet: b
 474 Dec 19, 2022
474 Dec 19, 2022

RuCLIP tiny (Russian Contrastive Language–Image Pretraining) is a neural network trained to work with different pairs (images, texts).
RuCLIPtiny Zero-shot image classification model for Russian language RuCLIP tiny (Russian Contrastive Language–Image Pretraining) is a neural network
 26 Sep 20, 2022
26 Sep 20, 2022
Implementation of the SUMO (Slim U-Net trained on MODA) model
SUMO - Slim U-Net trained on MODA Implementation of the SUMO (Slim U-Net trained on MODA) model as described in: TODO: add reference to paper once ava
 6 Nov 19, 2022
6 Nov 19, 2022
nlabel is a library for generating, storing and retrieving tagging information and embedding vectors from various nlp libraries through a unified interface.
nlabel is a library for generating, storing and retrieving tagging information and embedding vectors from various nlp libraries through a unified interface.
 2 Jun 10, 2022
2 Jun 10, 2022
Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners
DART Implementation for ICLR2022 paper Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners. Environment python@3.6 Use pi
 83 Dec 27, 2022
83 Dec 27, 2022
Annotate datasets with a semi-trained or fully trained YOLOv5 model
YOLOv5 Auto Annotator Annotate datasets with a semi-trained or fully trained YOLOv5 model Prerequisites Ubuntu =20.04 Python =3.7 System dependencie
 3 May 14, 2022
3 May 14, 2022

An Empirical Investigation of Model-to-Model Distribution Shifts in Trained Convolutional Filters
CNN-Filter-DB An Empirical Investigation of Model-to-Model Distribution Shifts in Trained Convolutional Filters Paul Gavrikov, Janis Keuper Paper: htt
 18 Dec 30, 2022
18 Dec 30, 2022

Official code of Team Yao at Multi-Modal-Fact-Verification-2022
Official code of Team Yao at Multi-Modal-Fact-Verification-2022 A Multi-Modal Fact Verification dataset released as part of the De-Factify workshop in
 11 Nov 15, 2022
11 Nov 15, 2022

PyTorch implementation of our paper How robust are discriminatively trained zero-shot learning models?
How robust are discriminatively trained zero-shot learning models? This repository contains the PyTorch implementation of our paper How robust are dis
 5 Feb 4, 2022
5 Feb 4, 2022
Detic ros - A simple ROS wrapper for Detic instance segmentation using pre-trained dataset
Detic ros - A simple ROS wrapper for Detic instance segmentation using pre-trained dataset
 12 Nov 19, 2022
12 Nov 19, 2022
This repository contains pre-trained models and some evaluation code for our paper Towards Unsupervised Dense Information Retrieval with Contrastive Learning
Contriever: Towards Unsupervised Dense Information Retrieval with Contrastive Learning This repository contains pre-trained models and some evaluation
 207 Jan 8, 2023
207 Jan 8, 2023
RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2
RoNER RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2. It is meant to be an easy to use, hi
 9 Nov 7, 2022
9 Nov 7, 2022

CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs
CLIP [Blog] [Paper] [Model Card] [Colab] CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pair
 6k Jan 25, 2022
6k Jan 25, 2022
STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs
STonKGs STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs. This multimodal Transformer combin
 27 Aug 11, 2022
27 Aug 11, 2022
Pre-trained models for a Cascaded-FCN in caffe and tensorflow that segments
Cascaded-FCN This repository contains the pre-trained models for a Cascaded-FCN in caffe and tensorflow that segments the liver and its lesions out of
 300 Nov 22, 2022
300 Nov 22, 2022
This repository contains code, network definitions and pre-trained models for working on remote sensing images using deep learning
Deep learning for Earth Observation This repository contains code, network definitions and pre-trained models for working on remote sensing images usi
 447 Jan 5, 2023
447 Jan 5, 2023
TLXZoo - Pre-trained models based on TensorLayerX
Pre-trained models based on TensorLayerX. TensorLayerX is a multi-backend AI fra
 13 Dec 7, 2022
13 Dec 7, 2022

MADT: Offline Pre-trained Multi-Agent Decision Transformer
MADT: Offline Pre-trained Multi-Agent Decision Transformer A link to our paper can be found on Arxiv. Overview Official codebase for Offline Pre-train
 51 Dec 21, 2022
51 Dec 21, 2022
TweebankNLP - Pre-trained Tweet NLP Pipeline (NER, tokenization, lemmatization, POS tagging, dependency parsing) + Models + Tweebank-NER
TweebankNLP This repo contains the new Tweebank-NER dataset and Twitter-Stanza p
 84 Dec 20, 2022
84 Dec 20, 2022
The trained model and denoising example for paper : Cardiopulmonary Auscultation Enhancement with a Two-Stage Noise Cancellation Approach
The trained model and denoising example for paper : Cardiopulmonary Auscultation Enhancement with a Two-Stage Noise Cancellation Approach
 1 Jan 18, 2022
1 Jan 18, 2022
Custom IMDB Dataset is extracted between 2020-2021 and custom distilBERT model is trained for movie success probability prediction
IMDB Success Predictor Project involves Web Scraping custom IMDB data between 2020 and 2021 of 10000 movies and shows sorted by number of votes ,fine
 1 Jan 18, 2022
1 Jan 18, 2022

Predicting 10 different clothing types using Xception pre-trained model.
Predicting-Clothing-Types Predicting 10 different clothing types using Xception pre-trained model from Keras library. It is reimplemented version from
 3 Dec 29, 2021
3 Dec 29, 2021
Visual dialog agents with pre-trained vision-and-language encoders.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation Or READ-UP: Referring Expression Agent Dialog with Unified Pretr
 7 Oct 8, 2022
7 Oct 8, 2022
Pytorch implementation of MLP-Mixer with loading pre-trained models.
MLP-Mixer-Pytorch PyTorch implementation of MLP-Mixer: An all-MLP Architecture for Vision with the function of loading official ImageNet pre-trained p
 2 Sep 29, 2022
2 Sep 29, 2022

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
A Comprehensive Empirical Study of Vision-Language Pre-trained Model for Supervised Cross-Modal Retrieval
CLIP4CMR A Comprehensive Empirical Study of Vision-Language Pre-trained Model for Supervised Cross-Modal Retrieval The original data and pre-calculate
 9 Jan 12, 2022
9 Jan 12, 2022
A Comprehensive Empirical Study of Vision-Language Pre-trained Model for Supervised Cross-Modal Retrieval
CLIP4CMR A Comprehensive Empirical Study of Vision-Language Pre-trained Model for Supervised Cross-Modal Retrieval The original data and pre-calculate
24 Dec 26, 2022

Translate darknet to tensorflow. Load trained weights, retrain/fine-tune using tensorflow, export constant graph def to mobile devices
Intro Real-time object detection and classification. Paper: version 1, version 2. Read more about YOLO (in darknet) and download weight files here. In
 6.1k Jan 4, 2023
6.1k Jan 4, 2023
Official Implementation of "DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization."
DialogLM Code for AAAI 2022 paper: DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization. Pre-trained Models We release two ve
92 Dec 19, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022

Cherche (search in French) allows you to create a neural search pipeline using retrievers and pre-trained language models as rankers.
Cherche (search in French) allows you to create a neural search pipeline using retrievers and pre-trained language models as rankers. Cherche is meant to be used with small to medium sized corpora. Cherche's main strength is its ability to build diverse and end-to-end pipelines.
 224 Nov 29, 2022
224 Nov 29, 2022

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022

Code, pre-trained models and saliency results for the paper "Boosting RGB-D Saliency Detection by Leveraging Unlabeled RGB Images".
Boosting RGB-D Saliency Detection by Leveraging Unlabeled RGB This repository is the official implementation of the paper. Our results comming soon in
 8 May 22, 2022
8 May 22, 2022

SAVI2I: Continuous and Diverse Image-to-Image Translation via Signed Attribute Vectors
SAVI2I: Continuous and Diverse Image-to-Image Translation via Signed Attribute Vectors [Paper] [Project Website] Pytorch implementation for SAVI2I. We
 44 Dec 30, 2022
44 Dec 30, 2022

UI2I via StyleGAN2 - Unsupervised image-to-image translation method via pre-trained StyleGAN2 network
We proposed an unsupervised image-to-image translation method via pre-trained StyleGAN2 network. paper: Unsupervised Image-to-Image Translation via Pr
 208 Dec 30, 2022
208 Dec 30, 2022
DGN pymarl - Implementation of DGN on Pymarl, which could be trained by VDN or QMIX
This is the implementation of DGN on Pymarl, which could be trained by VDN or QM
 4 Nov 23, 2022
4 Nov 23, 2022
Got-book-6 - LSTM trained on the first five ASOIAF/GOT books
GOT Book 6 Generator Are you tired of waiting for the next GOT book to come out? I know that I am, which is why I decided to train a RNN on the first
 974 Oct 27, 2022
974 Oct 27, 2022

KoBERT - Korean BERT pre-trained cased (KoBERT)
KoBERT KoBERT Korean BERT pre-trained cased (KoBERT) Why'?' Training Environment Requirements How to install How to use Using with PyTorch Using with
 1k Jan 2, 2023
1k Jan 2, 2023

Price-Prediction-For-a-Dream-Home - A machine learning based linear regression trained model for house price prediction.
Price-Prediction-For-a-Dream-Home ROADMAP TO THIS LINEAR REGRESSION BASED HOUSE PRICE PREDICTION PREDICTION MODEL Import all the dependencies of the p
 1 Dec 29, 2021
1 Dec 29, 2021

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022

Neural network chess engine trained on Gary Kasparov's games.
Neural Chess It's not the best chess engine, but it is a chess engine. Proof of concept neural network chess engine (feed-forward multi-layer perceptr
 3 Jun 22, 2022
3 Jun 22, 2022

A few stylization coreML models that I've trained with CreateML
CoreML-StyleTransfer A few stylization coreML models that I've trained with CreateML You can open and use the .mlmodel files in the "models" folder in
 8 Aug 18, 2022
8 Aug 18, 2022

Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition"
Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition" Pre-trained Deep Convo
 5 Nov 11, 2022
5 Nov 11, 2022
Resources related to our paper "CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain"
CLIN-X (CLIN-X-ES) & (CLIN-X-EN) This repository holds the companion code for the system reported in the paper: "CLIN-X: pre-trained language models a
 4 Dec 5, 2022
4 Dec 5, 2022

LSTM model trained on a small dataset of 3000 names written in PyTorch
LSTM model trained on a small dataset of 3000 names. Model generates names from model by selecting one out of top 3 letters suggested by model at a time until an EOS (End Of Sentence) character is not encountered.
 1 Dec 20, 2021
1 Dec 20, 2021
BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Table of contents Introduction Using BARTpho with fairseq Using BARTpho with transformers Notes BARTpho: Pre-trained Sequence-to-Sequence Models for V
 58 Dec 23, 2022
58 Dec 23, 2022

A PyTorch-based model pruning toolkit for pre-trained language models
English | 中文说明 TextPruner是一个为预训练语言模型设计的模型裁剪工具包,通过轻量、快速的裁剪方法对模型进行结构化剪枝,从而实现压缩模型体积、提升模型速度。 其他相关资源: 知识蒸馏工具TextBrewer:https://github.com/airaria/TextBrewe
 231 Jan 8, 2023
231 Jan 8, 2023

Industrial Image Anomaly Localization Based on Gaussian Clustering of Pre-trained Feature
Industrial Image Anomaly Localization Based on Gaussian Clustering of Pre-trained Feature Q. Wan, L. Gao, X. Li and L. Wen, "Industrial Image Anomaly
 6 Dec 25, 2022
6 Dec 25, 2022
Rotary Transformer is an MLM pre-trained language model with rotary position embedding (RoPE)
[中文|English] Rotary Transformer Rotary Transformer is an MLM pre-trained language model with rotary position embedding (RoPE). The RoPE is a relative
 211 Dec 8, 2021
211 Dec 8, 2021
ByT5: Towards a token-free future with pre-trained byte-to-byte models
ByT5: Towards a token-free future with pre-trained byte-to-byte models ByT5 is a tokenizer-free extension of the mT5 model. Instead of using a subword
 409 Jan 6, 2023
409 Jan 6, 2023

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 342 Jan 5, 2023
342 Jan 5, 2023
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
7.8k Jan 9, 2023
CodeBERT: A Pre-Trained Model for Programming and Natural Languages.
CodeBERT This repo provides the code for reproducing the experiments in CodeBERT: A Pre-Trained Model for Programming and Natural Languages. CodeBERT
1k Jan 3, 2023

A 1.3B text-to-image generation model trained on 14 million image-text pairs
minDALL-E on Conceptual Captions minDALL-E, named after minGPT, is a 1.3B text-to-image generation model trained on 14 million image-text pairs for no
 604 Dec 14, 2022
604 Dec 14, 2022
Discovering Explanatory Sentences in Legal Case Decisions Using Pre-trained Language Models.
Statutory Interpretation Data Set This repository contains the data set created for the following research papers: Savelka, Jaromir, and Kevin D. Ashl
 17 Dec 23, 2022
17 Dec 23, 2022
Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts
t5-japanese Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts. The following is a list of models that
 1 Dec 13, 2021
1 Dec 13, 2021
A python code to convert Keras pre-trained weights to Pytorch version
Weights_Keras_2_Pytorch 最近想在Pytorch项目里使用一下谷歌的NIMA,但是发现没有预训练好的pytorch权重,于是整理了一下将Keras预训练权重转为Pytorch的代码,目前是支持Keras的Conv2D, Dense, DepthwiseConv2D, Batch
 2 Dec 16, 2021
2 Dec 16, 2021
A complete speech segmentation system using Kaldi and x-vectors for voice activity detection (VAD) and speaker diarisation.
bbc-speech-segmenter: Voice Activity Detection & Speaker Diarization A complete speech segmentation system using Kaldi and x-vectors for voice activit
 16 Oct 27, 2022
16 Oct 27, 2022
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce (EMNLP Founding 2021)
Introduction K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce. Installation PyTor
 21 Nov 16, 2022
21 Nov 16, 2022

RuleBERT: Teaching Soft Rules to Pre-Trained Language Models
RuleBERT: Teaching Soft Rules to Pre-Trained Language Models (Paper) (Slides) (Video) RuleBERT is a pre-trained language model that has been fine-tune
 16 Aug 24, 2022
16 Aug 24, 2022
Translate darknet to tensorflow. Load trained weights, retrain/fine-tune using tensorflow, export constant graph def to mobile devices
Intro Real-time object detection and classification. Paper: version 1, version 2. Read more about YOLO (in darknet) and download weight files here. In
6.1k Dec 30, 2022
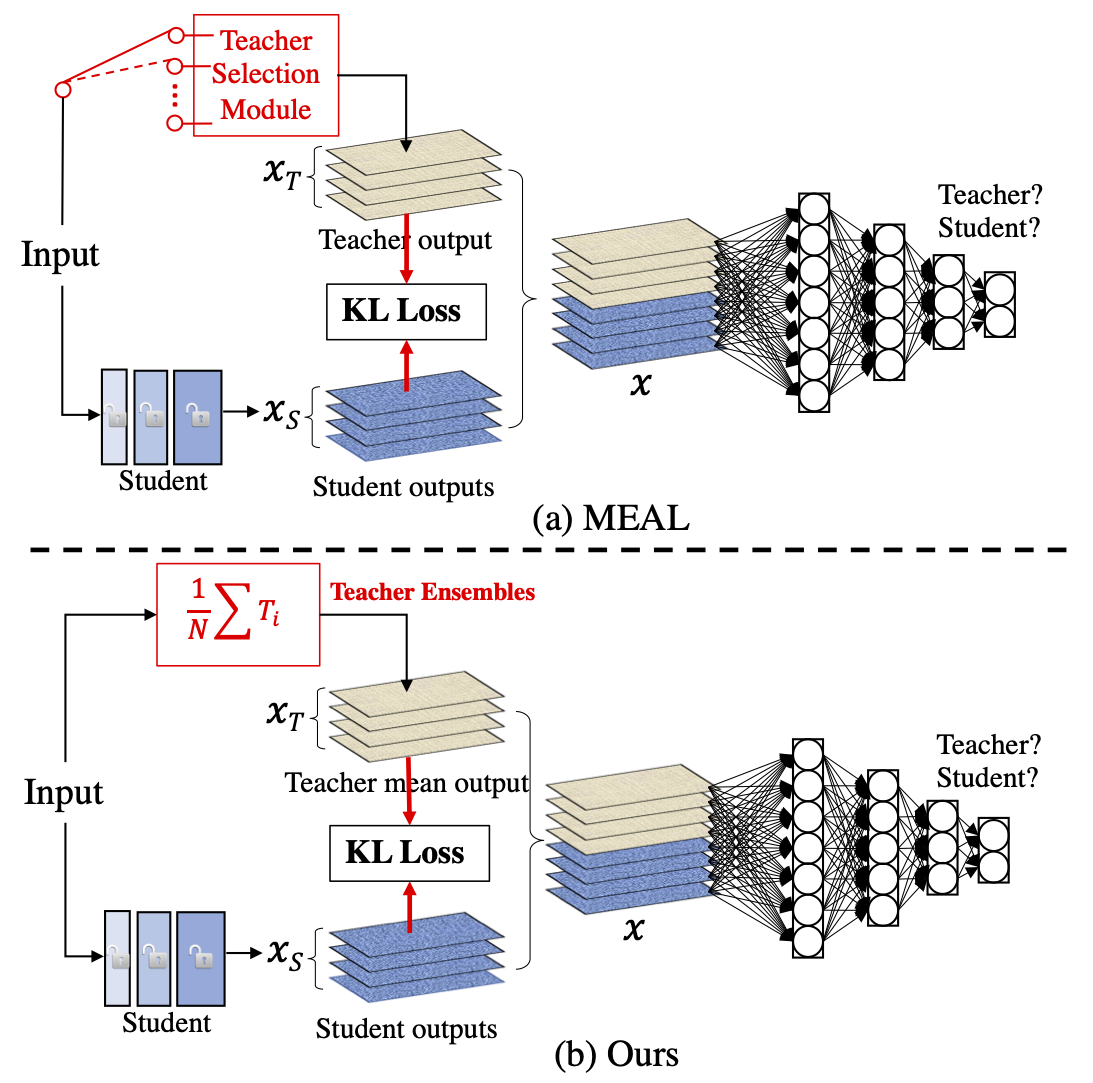
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022

Official Pytorch implementation for 2021 ICCV paper "Learning Motion Priors for 4D Human Body Capture in 3D Scenes" and trained models / data
Learning Motion Priors for 4D Human Body Capture in 3D Scenes (LEMO) Official Pytorch implementation for 2021 ICCV (oral) paper "Learning Motion Prior
 165 Dec 19, 2022
165 Dec 19, 2022
100+ Chinese Word Vectors 上百种预训练中文词向量
Chinese Word Vectors 中文词向量 中文 This project provides 100+ Chinese Word Vectors (embeddings) trained with different representations (dense and sparse),
 10.4k Jan 9, 2023
10.4k Jan 9, 2023
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
 463 Dec 30, 2022
463 Dec 30, 2022
Optimus: the first large-scale pre-trained VAE language model
Optimus: the first pre-trained Big VAE language model This repository contains source code necessary to reproduce the results presented in the EMNLP 2
 314 Dec 19, 2022
314 Dec 19, 2022
(ACL-IJCNLP 2021) Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models.
BERT Convolutions Code for the paper Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models. Contains expe
 21 Jul 18, 2022
21 Jul 18, 2022
Source code for TACL paper "KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation".
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation Source code for TACL 2021 paper KEPLER: A Unified Model for Kn
 138 Dec 22, 2022
138 Dec 22, 2022
Code and pre-trained models for "ReasonBert: Pre-trained to Reason with Distant Supervision", EMNLP'2021
ReasonBERT Code and pre-trained models for ReasonBert: Pre-trained to Reason with Distant Supervision, EMNLP'2021 Pretrained Models The pretrained mod
 29 Dec 19, 2022
29 Dec 19, 2022

Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks. [NeurIPS
 122 Dec 14, 2022
122 Dec 14, 2022

The official implementation of "BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?, ACL 2021 main conference"
BERT is to NLP what AlexNet is to CV This is the official implementation of BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Iden
 20 Nov 3, 2022
20 Nov 3, 2022
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization (ACL 2021)
Structured Super Lottery Tickets in BERT This repo contains our codes for the paper "Super Tickets in Pre-Trained Language Models: From Model Compress
 16 Dec 11, 2022
16 Dec 11, 2022

Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators This is our Pytorch implementation for t
 12 Jul 22, 2022
12 Jul 22, 2022

Source code for the ACL-IJCNLP 2021 paper entitled "T-DNA: Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adaptation" by Shizhe Diao et al.
T-DNA Source code for the ACL-IJCNLP 2021 paper entitled Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adapta
 17 Dec 22, 2022
17 Dec 22, 2022
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
124 Jan 2, 2023

Search with BERT vectors in Solr and Elasticsearch
Search with BERT vectors in Solr and Elasticsearch
 123 Dec 29, 2022
123 Dec 29, 2022
Pre-trained Deep Learning models and demos (high quality and extremely fast)
OpenVINO™ Toolkit - Open Model Zoo repository This repository includes optimized deep learning models and a set of demos to expedite development of hi
 3.4k Dec 31, 2022
3.4k Dec 31, 2022
KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
KoGPT KoGPT (Korean Generative Pre-trained Transformer) https://github.com/kakaobrain/kogpt https://huggingface.co/kakaobrain/kogpt Model Descriptions
799 Dec 28, 2022
VGGVox models for Speaker Identification and Verification trained on the VoxCeleb (1 & 2) datasets
VGGVox models for speaker identification and verification This directory contains code to import and evaluate the speaker identification and verificat
 338 Dec 27, 2022
338 Dec 27, 2022
A fast, efficient universal vector embedding utility package.
Magnitude: a fast, simple vector embedding utility library A feature-packed Python package and vector storage file format for utilizing vector embeddi
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
A library for efficient similarity search and clustering of dense vectors.
Faiss Faiss is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any
18.8k Jan 8, 2023