312 Repositories
Python embeddings-trained Libraries

DziriBERT: a Pre-trained Language Model for the Algerian Dialect
DziriBERT DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect. It handles Algerian
 117 Jan 7, 2023
117 Jan 7, 2023
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from huggingface transformers. In the future, we will also support PLMs implemented by other libraries.
 2.3k Jan 8, 2023
2.3k Jan 8, 2023

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
Pre-trained BERT Models for Ancient and Medieval Greek, and associated code for LaTeCH 2021 paper titled - "A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek"
Ancient Greek BERT The first and only available Ancient Greek sub-word BERT model! State-of-the-art post fine-tuning on Part-of-Speech Tagging and Mor
 22 Dec 8, 2022
22 Dec 8, 2022
DziriBERT: a Pre-trained Language Model for the Algerian Dialect
DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect.
117 Jan 7, 2023
![A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]](https://user-images.githubusercontent.com/33194443/104581604-2592cb00-56a2-11eb-9610-5eaa0afb6e1f.png)
A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]
PINTO_model_zoo Please read the contents of the LICENSE file located directly under each folder before using the model. My model conversion scripts ar
 2.4k Jan 5, 2023
2.4k Jan 5, 2023

Implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTorch
Neural Distance Embeddings for Biological Sequences Official implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTo
 56 Dec 23, 2022
56 Dec 23, 2022
PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization using Augmented-Self Reference and Dense Semantic Correspondence) and pre-trained model on ImageNet dataset
Reference-Based-Sketch-Image-Colorization-ImageNet This is a PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization usin
 11 Jul 28, 2022
11 Jul 28, 2022
fastgradio is a python library to quickly build and share gradio interfaces of your trained fastai models.
fastgradio is a python library to quickly build and share gradio interfaces of your trained fastai models.
 34 Jan 5, 2023
34 Jan 5, 2023

A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
 488 Nov 28, 2022
488 Nov 28, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
 586 Dec 24, 2022
586 Dec 24, 2022

PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
 1.6k Dec 25, 2022
1.6k Dec 25, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
Original implementation of the pooling method introduced in "Speaker embeddings by modeling channel-wise correlations"
Speaker-Embeddings-Correlation-Pooling This is the original implementation of the pooling method introduced in "Speaker embeddings by modeling channel
 10 Apr 30, 2022
10 Apr 30, 2022

High level network definitions with pre-trained weights in TensorFlow
TensorNets High level network definitions with pre-trained weights in TensorFlow (tested with 2.1.0 = TF = 1.4.0). Guiding principles Applicability.
 1k Dec 13, 2022
1k Dec 13, 2022
Applying "Load What You Need: Smaller Versions of Multilingual BERT" to LaBSE
smaller-LaBSE LaBSE(Language-agnostic BERT Sentence Embedding) is a very good method to get sentence embeddings across languages. But it is hard to fi
 13 Sep 2, 2022
13 Sep 2, 2022
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models
Graformer The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models Graformer (also named BridgeTransformer in t
 22 Dec 14, 2022
22 Dec 14, 2022

Embeddinghub is a database built for machine learning embeddings.
Embeddinghub is a database built for machine learning embeddings.
 1.2k Jan 1, 2023
1.2k Jan 1, 2023
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 341 Dec 29, 2022
341 Dec 29, 2022
Must-read papers on improving efficiency for pre-trained language models.
Must-read papers on improving efficiency for pre-trained language models.
 89 Jan 3, 2023
89 Jan 3, 2023
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
This repo uses a combination of logits and feature distillation method to teach the PSPNet model of ResNet18 backbone with the PSPNet model of ResNet50 backbone. All the models are trained and tested on the PASCAL-VOC2012 dataset.
PSPNet-logits and feature-distillation Introduction This repository is based on PSPNet and modified from semseg and Pixelwise_Knowledge_Distillation_P
 6 Dec 1, 2022
6 Dec 1, 2022
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

Learning Compatible Embeddings, ICCV 2021
LCE Learning Compatible Embeddings, ICCV 2021 by Qiang Meng, Chixiang Zhang, Xiaoqiang Xu and Feng Zhou Paper: Arxiv We cannot release source codes pu
 25 Dec 17, 2022
25 Dec 17, 2022
Large scale embeddings on a single machine.
Marius Marius is a system under active development for training embeddings for large-scale graphs on a single machine. Training on large scale graphs
 107 Jan 3, 2023
107 Jan 3, 2023
Official implementation for ICDAR 2021 paper "Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer"
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer Description Convert offline handwritten mathematical expressi
 87 Dec 27, 2022
87 Dec 27, 2022

Pre-Trained Image Processing Transformer (IPT)
Pre-Trained Image Processing Transformer (IPT) By Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Cha
 332 Dec 18, 2022
332 Dec 18, 2022
Versatile Generative Language Model
Versatile Generative Language Model This is the implementation of the paper: Exploring Versatile Generative Language Model Via Parameter-Efficient Tra
 17 Dec 2, 2022
17 Dec 2, 2022
PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
1.6k Dec 29, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
586 Dec 24, 2022
A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
488 Nov 28, 2022

🐥A PyTorch implementation of OpenAI's finetuned transformer language model with a script to import the weights pre-trained by OpenAI
PyTorch implementation of OpenAI's Finetuned Transformer Language Model This is a PyTorch implementation of the TensorFlow code provided with OpenAI's
 1.4k Jan 5, 2023
1.4k Jan 5, 2023
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022
Implementation of PyTorch-based multi-task pre-trained models
mtdp Library containing implementation related to the research paper "Multi-task pre-training of deep neural networks for digital pathology" (Mormont
 27 Oct 14, 2022
27 Oct 14, 2022

A PyTorch Implementation of "Watch Your Step: Learning Node Embeddings via Graph Attention" (NeurIPS 2018).
Attention Walk ⠀⠀ A PyTorch Implementation of Watch Your Step: Learning Node Embeddings via Graph Attention (NIPS 2018). Abstract Graph embedding meth
 303 Dec 9, 2022
303 Dec 9, 2022

The Hailo Model Zoo includes pre-trained models and a full building and evaluation environment
Hailo Model Zoo The Hailo Model Zoo provides pre-trained models for high-performance deep learning applications. Using the Hailo Model Zoo you can mea
 50 Dec 7, 2022
50 Dec 7, 2022

RoBERTa Marathi Language model trained from scratch during huggingface 🤗 x flax community week
RoBERTa base model for Marathi Language (मराठी भाषा) Pretrained model on Marathi language using a masked language modeling (MLM) objective. RoBERTa wa
 23 Oct 19, 2022
23 Oct 19, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
 203 Dec 20, 2022
203 Dec 20, 2022
DRIFT is a tool for Diachronic Analysis of Scientific Literature.
About DRIFT is a tool for Diachronic Analysis of Scientific Literature. The application offers user-friendly and customizable utilities for two modes:
 108 Dec 12, 2022
108 Dec 12, 2022

MicRank is a Learning to Rank neural channel selection framework where a DNN is trained to rank microphone channels.
MicRank: Learning to Rank Microphones for Distant Speech Recognition Application Scenario Many applications nowadays envision the presence of multiple
 20 Nov 10, 2022
20 Nov 10, 2022
Implementation of Rotary Embeddings, from the Roformer paper, in Pytorch
Rotary Embeddings - Pytorch A standalone library for adding rotary embeddings to transformers in Pytorch, following its success as relative positional
 110 Dec 30, 2022
110 Dec 30, 2022

Semantic Segmentation of images using PixelLib with help of Pascalvoc dataset trained with Deeplabv3+ framework.
CARscan- Approach 1 - Segmentation of images by detecting contours. It failed because in images with elements along with cars were also getting detect
 5 Jul 29, 2021
5 Jul 29, 2021
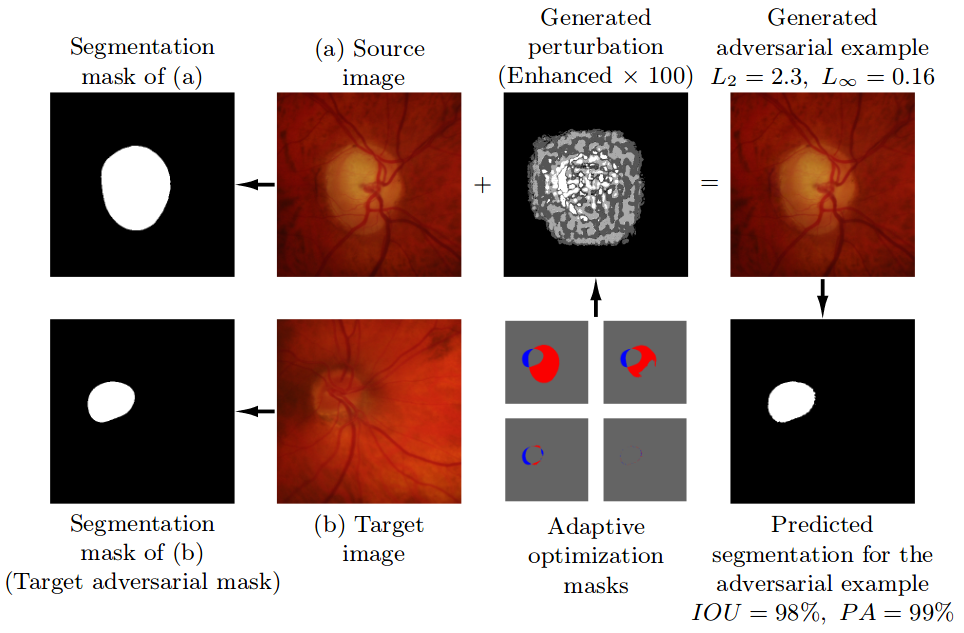
Pre-trained model, code, and materials from the paper "Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation" (MICCAI 2019).
Adaptive Segmentation Mask Attack This repository contains the implementation of the Adaptive Segmentation Mask Attack (ASMA), a targeted adversarial
 53 Jul 4, 2022
53 Jul 4, 2022
🤖 A Python library for learning and evaluating knowledge graph embeddings
PyKEEN PyKEEN (Python KnowlEdge EmbeddiNgs) is a Python package designed to train and evaluate knowledge graph embedding models (incorporating multi-m
 1.1k Jan 9, 2023
1.1k Jan 9, 2023
A simple pygame dino game which can also be trained and played by a NEAT KI
Dino Game AI Game The game itself was developed with the Pygame module pip install pygame You can also play it yourself by making the dino jump with t
 7 Dec 5, 2022
7 Dec 5, 2022
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022
Shared code for training sentence embeddings with Flax / JAX
flax-sentence-embeddings This repository will be used to share code for the Flax / JAX community event to train sentence embeddings on 1B+ training pa
 23 Dec 30, 2022
23 Dec 30, 2022

Source code for paper: Knowledge Inheritance for Pre-trained Language Models
Knowledge-Inheritance Source code paper: Knowledge Inheritance for Pre-trained Language Models (preprint). The trained model parameters (in Fairseq fo
31 Nov 19, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
 99 Dec 23, 2022
99 Dec 23, 2022
The (extremely) naive sentiment classification function based on NBSVM trained on wisesight_sentiment
thai_sentiment The naive sentiment classification function based on NBSVM trained on wisesight_sentiment วิธีติดตั้ง pip install thai_sentiment==0.1.3
 7 Dec 8, 2022
7 Dec 8, 2022

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022

UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus
UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus General info This is
 71 Oct 25, 2022
71 Oct 25, 2022

Reliable probability face embeddings
ProbFace, arxiv This is a demo code of training and testing [ProbFace] using Tensorflow. ProbFace is a reliable Probabilistic Face Embeddging (PFE) me
 34 Dec 31, 2022
34 Dec 31, 2022

We envision models that are pre-trained on a vast range of domain-relevant tasks to become key for molecule property prediction
We envision models that are pre-trained on a vast range of domain-relevant tasks to become key for molecule property prediction. This repository aims to give easy access to state-of-the-art pre-trained models.
 90 Jan 8, 2023
90 Jan 8, 2023
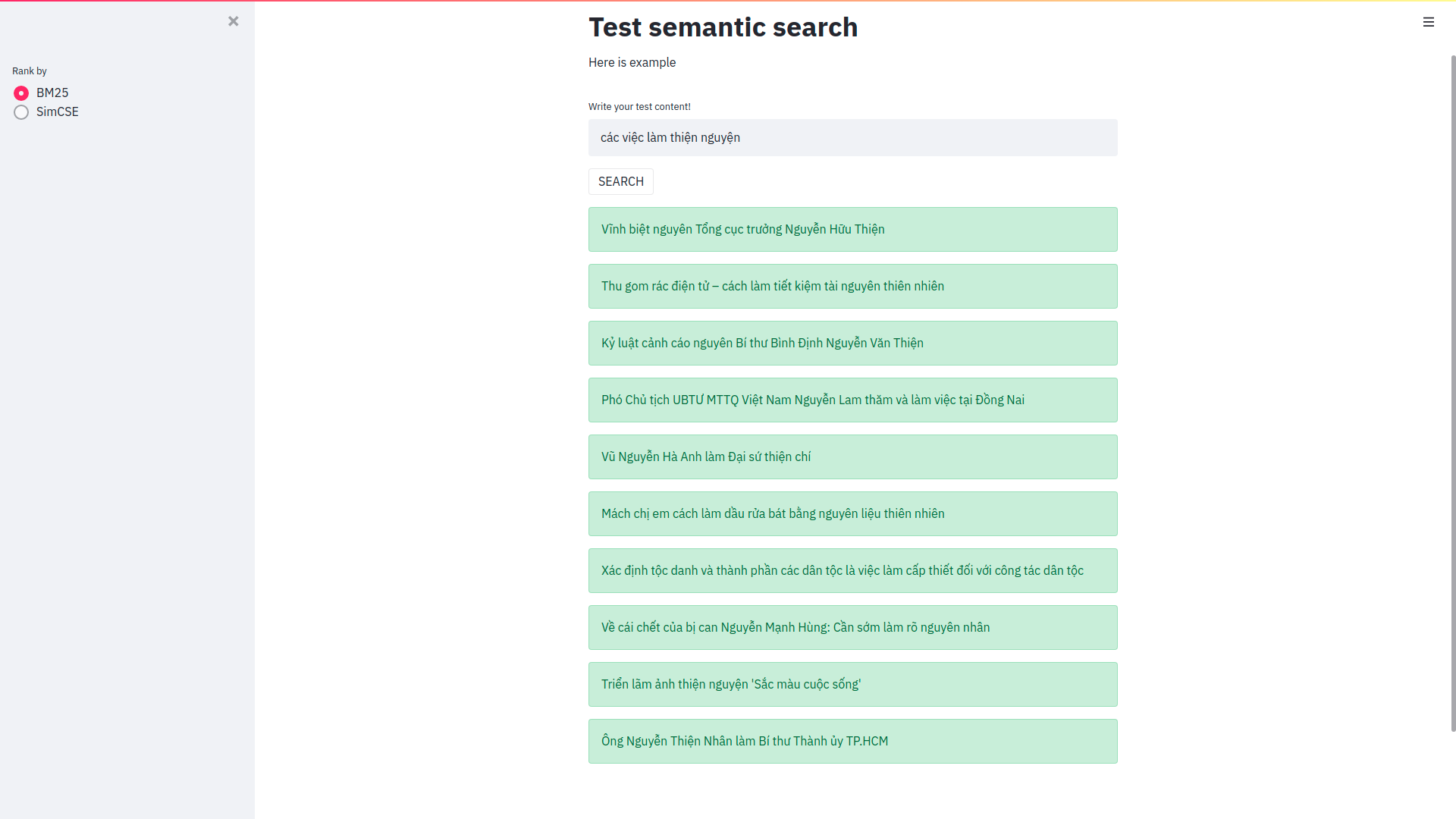
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings Trong bài viết này mình sẽ sử dụng pretrain model SimCS
 18 Nov 25, 2022
18 Nov 25, 2022
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
192 Dec 23, 2022
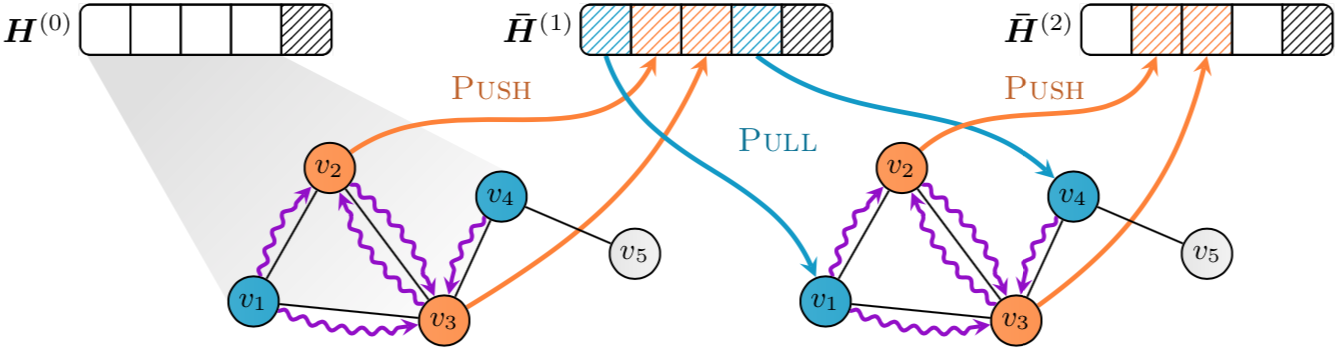
Implementation of "GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings" in PyTorch
PyGAS: Auto-Scaling GNNs in PyG PyGAS is the practical realization of our G NN A uto S cale (GAS) framework, which scales arbitrary message-passing GN
 139 Dec 25, 2022
139 Dec 25, 2022
MBTR is a python package for multivariate boosted tree regressors trained in parameter space.
MBTR is a python package for multivariate boosted tree regressors trained in parameter space.
 61 Dec 19, 2022
61 Dec 19, 2022
Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning".
ERICA Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive L
75 Nov 2, 2022
Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. This Neural Network (NN) model recognizes the text contained in the images of segmented words.
Handwritten-Text-Recognition Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. T
 27 Jan 8, 2023
27 Jan 8, 2023
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022

This repo contains the official code and pre-trained models for the Dynamic Vision Transformer (DVT).
Dynamic-Vision-Transformer (Pytorch) This repo contains the official code and pre-trained models for the Dynamic Vision Transformer (DVT). Not All Ima
 210 Dec 18, 2022
210 Dec 18, 2022
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
 224 Jan 4, 2023
224 Jan 4, 2023
Third party Pytorch implement of Image Processing Transformer (Pre-Trained Image Processing Transformer arXiv:2012.00364v2)
ImageProcessingTransformer Third party Pytorch implement of Image Processing Transformer (Pre-Trained Image Processing Transformer arXiv:2012.00364v2)
 61 Jan 1, 2023
61 Jan 1, 2023
A custom-designed Spider Robot trained to walk using Deep RL in a PyBullet Simulation
SpiderBot_DeepRL Title: Implementation of Single and Multi-Agent Deep Reinforcement Learning Algorithms for a Walking Spider Robot Authors(s): Arijit
 9 Jul 28, 2022
9 Jul 28, 2022

Ever felt tired after preprocessing the dataset, and not wanting to write any code further to train your model? Ever encountered a situation where you wanted to record the hyperparameters of the trained model and able to retrieve it afterward? Models Playground is here to help you do that. Models playground allows you to train your models right from the browser.
Models Playground 🗂️ Upload a Preprocessed Dataset 🌠 Choose whether to perform Classification or Regression 🦹 Enter the Dependent Variable ?
 19 Dec 10, 2022
19 Dec 10, 2022
Code for paper PairRE: Knowledge Graph Embeddings via Paired Relation Vectors.
PairRE Code for paper PairRE: Knowledge Graph Embeddings via Paired Relation Vectors. This implementation of PairRE for Open Graph Benchmak datasets (
 65 Dec 19, 2022
65 Dec 19, 2022
InferSent sentence embeddings
InferSent InferSent is a sentence embeddings method that provides semantic representations for English sentences. It is trained on natural language in
2.2k Dec 27, 2022

A library for Multilingual Unsupervised or Supervised word Embeddings
MUSE: Multilingual Unsupervised and Supervised Embeddings MUSE is a Python library for multilingual word embeddings, whose goal is to provide the comm
3k Jan 6, 2023

SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
 2.5k Jan 7, 2023
2.5k Jan 7, 2023
State of the art Semantic Sentence Embeddings
Contrastive Tension State of the art Semantic Sentence Embeddings Published Paper · Huggingface Models · Report Bug Overview This is the official code
 88 Dec 30, 2022
88 Dec 30, 2022
Pytorch implementation of our paper under review — Lottery Jackpots Exist in Pre-trained Models
Lottery Jackpots Exist in Pre-trained Models (Paper Link) Requirements Python = 3.7.4 Pytorch = 1.6.1 Torchvision = 0.4.1 Reproduce the Experiment
 27 Jun 28, 2022
27 Jun 28, 2022
《K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters》(2020)
K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters This repository is the implementation of the paper "K-Adapter: Infusing Knowledge
118 Dec 13, 2022
Official repository for "PAIR: Planning and Iterative Refinement in Pre-trained Transformers for Long Text Generation"
pair-emnlp2020 Official repository for the paper: Xinyu Hua and Lu Wang: PAIR: Planning and Iterative Refinement in Pre-trained Transformers for Long
 31 Oct 13, 2022
31 Oct 13, 2022
Code, Data and Demo for Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting
InversePrompting Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting Code: The code is provided in the "chinese_ip"
 101 Dec 16, 2022
101 Dec 16, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023

source code and pre-trained/fine-tuned checkpoint for NAACL 2021 paper LightningDOT
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval This repository contains source code and pre-trained/fine-tun
 65 Dec 26, 2022
65 Dec 26, 2022

Implementation of 'lightweight' GAN, proposed in ICLR 2021, in Pytorch. High resolution image generations that can be trained within a day or two
512x512 flowers after 12 hours of training, 1 gpu 256x256 flowers after 12 hours of training, 1 gpu Pizza 'Lightweight' GAN Implementation of 'lightwe
1.5k Jan 2, 2023
Library for faster pinned CPU - GPU transfer in Pytorch
SpeedTorch Faster pinned CPU tensor - GPU Pytorch variabe transfer and GPU tensor - GPU Pytorch variable transfer, in certain cases. Update 9-29-1
 657 Dec 19, 2022
657 Dec 19, 2022
Source code, datasets and trained models for the paper Learning Advanced Mathematical Computations from Examples (ICLR 2021), by François Charton, Amaury Hayat (ENPC-Rutgers) and Guillaume Lample
Maths from examples - Learning advanced mathematical computations from examples This is the source code and data sets relevant to the paper Learning a
171 Nov 23, 2022
Monocular Depth Estimation - Weighted-average prediction from multiple pre-trained depth estimation models
merged_depth runs (1) AdaBins, (2) DiverseDepth, (3) MiDaS, (4) SGDepth, and (5) Monodepth2, and calculates a weighted-average per-pixel absolute dept
 39 Nov 21, 2022
39 Nov 21, 2022
Tensorflow-based CNN+LSTM trained with CTC-loss for OCR
Overview This collection demonstrates how to construct and train a deep, bidirectional stacked LSTM using CNN features as input with CTC loss to perfo
 489 Dec 21, 2022
489 Dec 21, 2022
![[CVPR 2021] Involution: Inverting the Inherence of Convolution for Visual Recognition, a brand new neural operator](https://github.com/d-li14/involution/raw/main/fig/involution.png)
[CVPR 2021] Involution: Inverting the Inherence of Convolution for Visual Recognition, a brand new neural operator
involution Official implementation of a neural operator as described in Involution: Inverting the Inherence of Convolution for Visual Recognition (CVP
 1.3k Dec 28, 2022
1.3k Dec 28, 2022
Code associated with the "Data Augmentation using Pre-trained Transformer Models" paper
Data Augmentation using Pre-trained Transformer Models Code associated with the Data Augmentation using Pre-trained Transformer Models paper Code cont
 44 Dec 31, 2022
44 Dec 31, 2022
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. Flair is: A powerful NLP library. Flair allo
 12.3k Jan 2, 2023
12.3k Jan 2, 2023

Improving XGBoost survival analysis with embeddings and debiased estimators
xgbse: XGBoost Survival Embeddings "There are two cultures in the use of statistical modeling to reach conclusions from data
 242 Dec 30, 2022
242 Dec 30, 2022
Pre-trained NFNets with 99% of the accuracy of the official paper
NFNet Pytorch Implementation This repo contains pretrained NFNet models F0-F6 with high ImageNet accuracy from the paper High-Performance Large-Scale
 133 Dec 9, 2022
133 Dec 9, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 11.7k Feb 18, 2021
11.7k Feb 18, 2021
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
 2.1k Feb 13, 2021
2.1k Feb 13, 2021

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 1.5k Feb 17, 2021
1.5k Feb 17, 2021
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
 1.9k Feb 18, 2021
1.9k Feb 18, 2021
Sentence Embeddings with BERT & XLNet
Sentence Transformers: Multilingual Sentence Embeddings using BERT / RoBERTa / XLM-RoBERTa & Co. with PyTorch This framework provides an easy method t
 4.2k Feb 18, 2021
4.2k Feb 18, 2021
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. IMPORTANT: (30.08.2020) We moved our models
10k Feb 18, 2021

Learning RGB-D Feature Embeddings for Unseen Object Instance Segmentation
Unseen Object Clustering: Learning RGB-D Feature Embeddings for Unseen Object Instance Segmentation Introduction In this work, we propose a new method
 132 Dec 13, 2022
132 Dec 13, 2022
the code used for the preprint Embedding-based Instance Segmentation of Microscopy Images.
EmbedSeg Introduction This repository hosts the version of the code used for the preprint Embedding-based Instance Segmentation of Microscopy Images.
 88 Dec 25, 2022
88 Dec 25, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
11.7k Feb 12, 2021