574 Repositories
Python expressive-speech-synthesis Libraries

TSIT: A Simple and Versatile Framework for Image-to-Image Translation
TSIT: A Simple and Versatile Framework for Image-to-Image Translation This repository provides the official PyTorch implementation for the following p
 255 Nov 23, 2022
255 Nov 23, 2022

SMIS - Semantically Multi-modal Image Synthesis(CVPR 2020)
Semantically Multi-modal Image Synthesis Project page / Paper / Demo Semantically Multi-modal Image Synthesis(CVPR2020). Zhen Zhu, Zhiliang Xu, Anshen
 316 Dec 1, 2022
316 Dec 1, 2022

SEAN: Image Synthesis with Semantic Region-Adaptive Normalization (CVPR 2020, Oral)
SEAN: Image Synthesis with Semantic Region-Adaptive Normalization (CVPR 2020 Oral) Figure: Face image editing controlled via style images and segmenta
 579 Dec 30, 2022
579 Dec 30, 2022
ADGAN - The Implementation of paper Controllable Person Image Synthesis with Attribute-Decomposed GAN
ADGAN - The Implementation of paper Controllable Person Image Synthesis with Attribute-Decomposed GAN CVPR 2020 (Oral); Pose and Appearance Attributes Transfer;
 400 Dec 29, 2022
400 Dec 29, 2022

DAGAN - Dual Attention GANs for Semantic Image Synthesis
Contents Semantic Image Synthesis with DAGAN Installation Dataset Preparation Generating Images Using Pretrained Model Train and Test New Models Evalu
 104 Oct 8, 2022
104 Oct 8, 2022

CLADE - Efficient Semantic Image Synthesis via Class-Adaptive Normalization (TPAMI 2021)
Efficient Semantic Image Synthesis via Class-Adaptive Normalization (Accepted by TPAMI)
 49 Nov 17, 2022
49 Nov 17, 2022

PyTorch code for ICPR 2020 paper Future Urban Scene Generation Through Vehicle Synthesis
Future urban scene generation through vehicle synthesis This repository contains Pytorch code for the ICPR2020 paper "Future Urban Scene Generation Th
 4 Oct 11, 2021
4 Oct 11, 2021

Masked regression code - Masked Regression
Masked Regression MR - Python Implementation This repositery provides a python implementation of MR (Masked Regression). MR can efficiently synthesize
 1 Dec 23, 2021
1 Dec 23, 2021
Asr abc - Automatic speech recognition(ASR),中文语音识别
语音识别的简单示例,主要在课堂演示使用 创建python虚拟环境 在linux 和macos 上验证通过 # 如果已经有pyhon3.6 环境,跳过该步骤,使用
 8 Nov 11, 2022
8 Nov 11, 2022
DeepSpeech - Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation.
(简体中文|English) Quick Start | Documents | Models List PaddleSpeech is an open-source toolkit on PaddlePaddle platform for a variety of critical tasks i
 5.6k Jan 3, 2023
5.6k Jan 3, 2023

Amazing-Python-Scripts - 🚀 Curated collection of Amazing Python scripts from Basics to Advance with automation task scripts.
📑 Introduction A curated collection of Amazing Python scripts from Basics to Advance with automation task scripts. This is your Personal space to fin
 1.1k Dec 29, 2022
1.1k Dec 29, 2022

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

Nerf pl - NeRF (Neural Radiance Fields) and NeRF in the Wild using pytorch-lightning
nerf_pl Update: an improved NSFF implementation to handle dynamic scene is open! Update: NeRF-W (NeRF in the Wild) implementation is added to nerfw br
 1.8k Dec 30, 2022
1.8k Dec 30, 2022

VQMIVC - Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion (Interspeech
 262 Dec 31, 2022
262 Dec 31, 2022

SpecAugmentPyTorch - A Pytorch (support batch and channel) implementation of GoogleBrain's SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
SpecAugment An implementation of SpecAugment for Pytorch How to use Install pytorch, version=1.9.0 (new feature (torch.Tensor.take_along_dim) is used
 3 Oct 11, 2022
3 Oct 11, 2022

The codebase for Data-driven general-purpose voice activity detection.
Data driven GPVAD Repository for the work in TASLP 2021 Voice activity detection in the wild: A data-driven approach using teacher-student training. S
 75 Nov 27, 2022
75 Nov 27, 2022

PyTorch implementation of Neural View Synthesis and Matching for Semi-Supervised Few-Shot Learning of 3D Pose
Neural View Synthesis and Matching for Semi-Supervised Few-Shot Learning of 3D Pose Release Notes The official PyTorch implementation of Neural View S
 20 Oct 9, 2022
20 Oct 9, 2022
基于百度的语音识别,用python实现,pyaudio+pyqt
Speech-recognition 基于百度的语音识别,python3.8(conda)+pyaudio+pyqt+baidu-aip 百度有面向python
 1 Jan 3, 2022
1 Jan 3, 2022
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022
Autoregressive Predictive Coding: An unsupervised autoregressive model for speech representation learning
Autoregressive Predictive Coding This repository contains the official implementation (in PyTorch) of Autoregressive Predictive Coding (APC) proposed
 173 Dec 18, 2022
173 Dec 18, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 2, 2023
1.1k Jan 2, 2023

🚀Clone a voice in 5 seconds to generate arbitrary speech in real-time
English | 中文 Features 🌍 Chinese supported mandarin and tested with multiple datasets: aidatatang_200zh, magicdata, aishell3, data_aishell, and etc. ?
 25.6k Dec 31, 2022
25.6k Dec 31, 2022
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger In this project, our aim is to tune, compare, and contrast the perf
 0 Dec 25, 2021
0 Dec 25, 2021
The ability of computer software to identify words and phrases in spoken language and convert them to human-readable text
speech-recognition-py Speech recognition is the ability of computer software to identify words and phrases in spoken language and convert them to huma
 1 Apr 3, 2022
1 Apr 3, 2022

PyTorch implementation of the method described in the paper VoiceLoop: Voice Fitting and Synthesis via a Phonological Loop.
VoiceLoop PyTorch implementation of the method described in the paper VoiceLoop: Voice Fitting and Synthesis via a Phonological Loop. VoiceLoop is a n
 873 Dec 15, 2022
873 Dec 15, 2022

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
 76 Nov 30, 2022
76 Nov 30, 2022

Prososdy Morph: A python library for manipulating pitch and duration in an algorithmic way, for resynthesizing speech.
ProMo (Prosody Morph) Questions? Comments? Feedback? Chat with us on gitter! A library for manipulating pitch and duration in an algorithmic way, for
 71 Jan 2, 2023
71 Jan 2, 2023
Official PyTorch Implementation of paper "NeLF: Neural Light-transport Field for Single Portrait View Synthesis and Relighting", EGSR 2021.
NeLF: Neural Light-transport Field for Single Portrait View Synthesis and Relighting Official PyTorch Implementation of paper "NeLF: Neural Light-tran
 38 Dec 26, 2022
38 Dec 26, 2022
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021

ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python)
ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python) 日本語は以下に続きます (Japanese follows) English: This book is written in Japanese and primaril
 189 Dec 29, 2022
189 Dec 29, 2022
SuperCollider library for Python
SuperCollider library for Python This project is a port of core features of SuperCollider's language to Python 3. It is intended to be the same librar
 65 Dec 22, 2022
65 Dec 22, 2022

VolumeGAN - 3D-aware Image Synthesis via Learning Structural and Textural Representations
VolumeGAN - 3D-aware Image Synthesis via Learning Structural and Textural Representations 3D-aware Image Synthesis via Learning Structural and Textura
 116 Dec 26, 2022
116 Dec 26, 2022

High-Resolution Image Synthesis with Latent Diffusion Models
Latent Diffusion Models arXiv | BibTeX High-Resolution Image Synthesis with Latent Diffusion Models Robin Rombach*, Andreas Blattmann*, Dominik Lorenz
 5.6k Dec 30, 2022
5.6k Dec 30, 2022
A minimal TPU compatible Jax implementation of NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF Minimal Jax implementation of NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. Result of Tiny-NeRF RGB Depth
 11 Jul 24, 2022
11 Jul 24, 2022
Official PyTorch Implementation of paper "NeLF: Neural Light-transport Field for Single Portrait View Synthesis and Relighting", EGSR 2021.
NeLF: Neural Light-transport Field for Single Portrait View Synthesis and Relighting Official PyTorch Implementation of paper "NeLF: Neural Light-tran
38 Dec 26, 2022
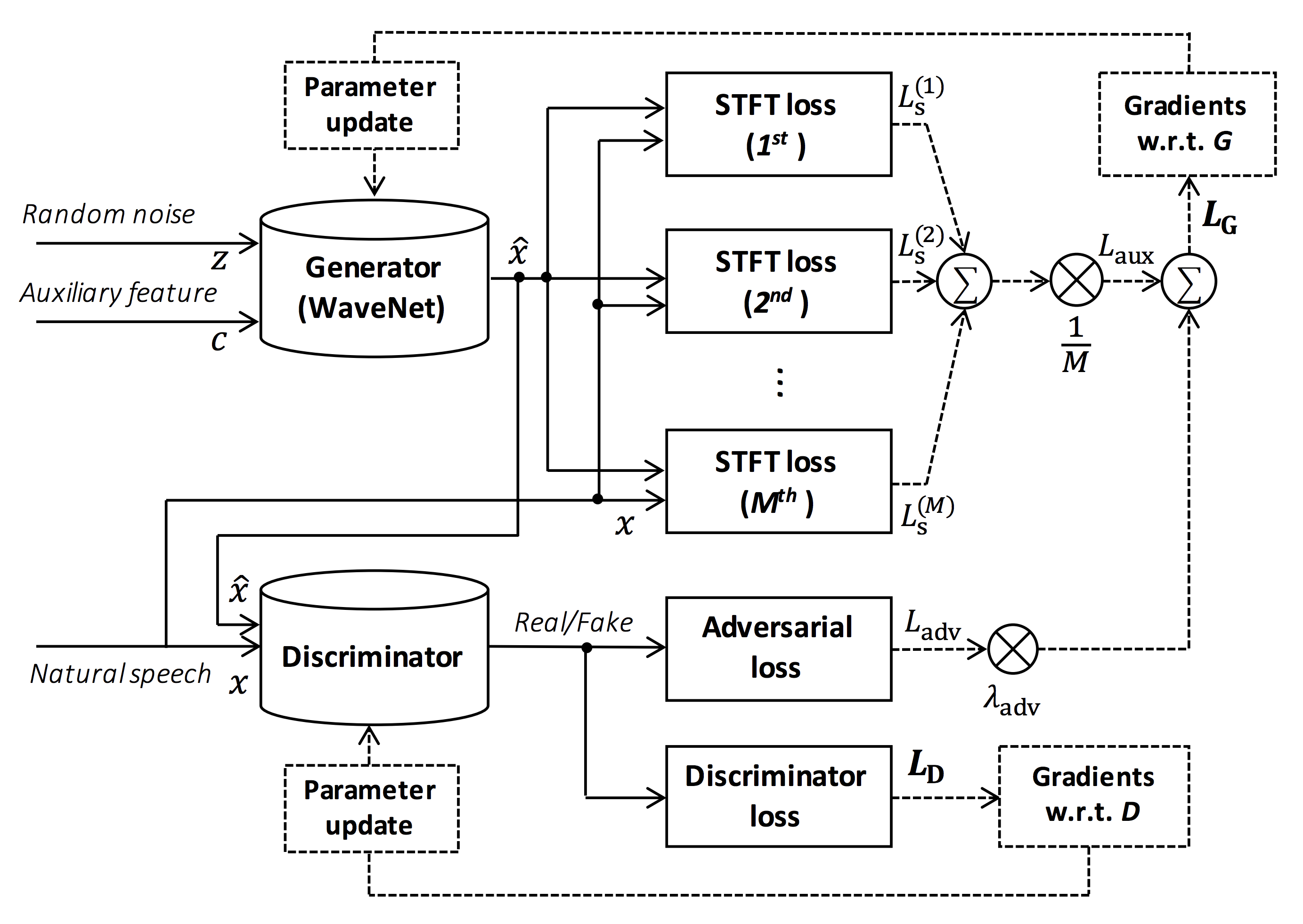
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022

Code release for the paper “Worldsheet Wrapping the World in a 3D Sheet for View Synthesis from a Single Image”, ICCV 2021.
Worldsheet: Wrapping the World in a 3D Sheet for View Synthesis from a Single Image This repository contains the code for the following paper: R. Hu,
 37 Jan 4, 2023
37 Jan 4, 2023

StyleSwin: Transformer-based GAN for High-resolution Image Generation
StyleSwin This repo is the official implementation of "StyleSwin: Transformer-based GAN for High-resolution Image Generation". By Bowen Zhang, Shuyang
 349 Dec 28, 2022
349 Dec 28, 2022

Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition"
Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition" Pre-trained Deep Convo
 5 Nov 11, 2022
5 Nov 11, 2022
Fast (simple) spectral synthesis and emission-line fitting of DESI spectra.
FastSpecFit Introduction This repository contains code and documentation to perform fast, simple spectral synthesis and emission-line fitting of DESI
 5 Aug 2, 2022
5 Aug 2, 2022

High-Resolution Image Synthesis with Latent Diffusion Models
Latent Diffusion Models Requirements A suitable conda environment named ldm can be created and activated with: conda env create -f environment.yaml co
5.6k Jan 4, 2023

This is a really simple text-to-speech app made with python and tkinter.
Tkinter Text-to-Speech App by Souvik Roy This is a really simple tkinter app which converts the text you have entered into a speech. It is created wit
 1 Dec 21, 2021
1 Dec 21, 2021
A warping based image translation model focusing on upper body synthesis.
Pose2Img Upper body image synthesis from skeleton(Keypoints). Sub module in the ICCV-2021 paper "Speech Drives Templates: Co-Speech Gesture Synthesis
 15 Nov 10, 2022
15 Nov 10, 2022
A Python module made to simplify the usage of Text To Speech and Speech Recognition.
Nav Module The solution for voice related stuff in Python Nav is a Python module which simplifies voice related stuff in Python. Just import the Modul
 1 Dec 20, 2021
1 Dec 20, 2021
Pytorch implementation of the paper Improving Text-to-Image Synthesis Using Contrastive Learning
T2I_CL This is the official Pytorch implementation of the paper Improving Text-to-Image Synthesis Using Contrastive Learning Requirements Linux Python
 42 Dec 31, 2022
42 Dec 31, 2022

DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022; Official code
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
 803 Dec 28, 2022
803 Dec 28, 2022
Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis
Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis Website | ICCV paper | arXiv | Twitter This repository contains the official i
 73 Dec 27, 2022
73 Dec 27, 2022

J.A.R.V.I.S is an AI virtual assistant made in python.
J.A.R.V.I.S is an AI virtual assistant made in python. Running JARVIS Without Python To run JARVIS without python: 1. Head over to our installation pa
 16 Dec 29, 2022
16 Dec 29, 2022
Wav2Vec for speech recognition, classification, and audio classification
Soxan در زبان پارسی به نام سخن This repository consists of models, scripts, and notebooks that help you to use all the benefits of Wav2Vec 2.0 in your
 140 Dec 15, 2022
140 Dec 15, 2022
Arabic speech recognition, classification and text-to-speech.
klaam Arabic speech recognition, classification and text-to-speech using many advanced models like wave2vec and fastspeech2. This repository allows tr
 177 Dec 27, 2022
177 Dec 27, 2022
Contains links to publicly available datasets for modeling health outcomes using speech and language.
speech-nlp-datasets Contains links to publicly available datasets for modeling various health outcomes using speech and language. Speech-based Corpora
 77 Dec 7, 2022
77 Dec 7, 2022

Create light scenes , voice control, ifttt, fuzzywuzzy speech correction and much more with Tuya light bulbs.
LightBox Features: Auto discover tuya lights Set and create moods (aka: light profiles) Change moods via IFTTT List moods via IFTTT FuzzyWuzzy, speech
 1 Dec 20, 2021
1 Dec 20, 2021
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
829 Jan 7, 2023
![[ICCV 2021] Our work presents a novel neural rendering approach that can efficiently reconstruct geometric and neural radiance fields for view synthesis.](https://github.com/apchenstu/mvsnerf/raw/main/configs/pipeline.png)
[ICCV 2021] Our work presents a novel neural rendering approach that can efficiently reconstruct geometric and neural radiance fields for view synthesis.
MVSNeRF Project page | Paper This repository contains a pytorch lightning implementation for the ICCV 2021 paper: MVSNeRF: Fast Generalizable Radiance
 529 Dec 30, 2022
529 Dec 30, 2022
Implementation of Auto-Conditioned Recurrent Networks for Extended Complex Human Motion Synthesis
acLSTM_motion This folder contains an implementation of acRNN for the CMU motion database written in Pytorch. See the following links for more backgro
 61 Sep 7, 2022
61 Sep 7, 2022
A Re-implementation of the paper "A Deep Learning Framework for Character Motion Synthesis and Editing"
What is This This is a simple re-implementation of the paper "A Deep Learning Framework for Character Motion Synthesis and Editing"(1). Only Sections
 102 Dec 14, 2022
102 Dec 14, 2022
Tensorflow Implementation of ECCV'18 paper: Multimodal Human Motion Synthesis
MT-VAE for Multimodal Human Motion Synthesis This is the code for ECCV 2018 paper MT-VAE: Learning Motion Transformations to Generate Multimodal Human
 36 Oct 2, 2022
36 Oct 2, 2022
Human motion synthesis using Unity3D
Human motion synthesis using Unity3D Prerequisite: Software: amc2bvh.exe, Unity 2017, Blender. Unity: RockVR (Video Capture), scenes, character models
 9 Jun 1, 2022
9 Jun 1, 2022
An LSTM based GAN for Human motion synthesis
GAN-motion-Prediction An LSTM based GAN for motion synthesis has a few issues reading H3.6M data from A.Jain et al , will fix soon. Prediction of the
 9 Jun 17, 2022
9 Jun 17, 2022
pyo is a Python module written in C to help digital signal processing script creation.
pyo is a Python module written in C to help digital signal processing script creation.
 1.1k Jan 1, 2023
1.1k Jan 1, 2023
Code for "Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans" CVPR 2021 best paper candidate
News 05/17/2021 To make the comparison on ZJU-MoCap easier, we save quantitative and qualitative results of other methods at here, including Neural Vo
 748 Jan 7, 2023
748 Jan 7, 2023

Tensorflow implementation of ID-Unet: Iterative Soft and Hard Deformation for View Synthesis.
ID-Unet: Iterative-view-synthesis(CVPR2021 Oral) Tensorflow implementation of ID-Unet: Iterative Soft and Hard Deformation for View Synthesis. Overvie
 17 Aug 23, 2022
17 Aug 23, 2022
Code repository for "Stable View Synthesis".
Stable View Synthesis Code repository for "Stable View Synthesis". Setup Install the following Python packages in your Python environment - numpy (1.1
 195 Dec 24, 2022
195 Dec 24, 2022
Code for paper Novel View Synthesis via Depth-guided Skip Connections
Novel View Synthesis via Depth-guided Skip Connections Code for paper Novel View Synthesis via Depth-guided Skip Connections @InProceedings{Hou_2021_W
 8 Mar 14, 2022
8 Mar 14, 2022
Code repository for "Free View Synthesis", ECCV 2020.
Free View Synthesis Code repository for "Free View Synthesis", ECCV 2020. Setup Install the following Python packages in your Python environment - num
253 Dec 7, 2022
Code for TIP 2017 paper --- Illumination Decomposition for Photograph with Multiple Light Sources.
Illumination_Decomposition Code for TIP 2017 paper --- Illumination Decomposition for Photograph with Multiple Light Sources. This code implements the
 7 Nov 15, 2020
7 Nov 15, 2020
🏃♀️ A curated list about human motion capture, analysis and synthesis.
Awesome Human Motion 🏃♀️ A curated list about human motion capture, analysis and synthesis. Contents Introduction Human Models Datasets Data Process
 274 Dec 14, 2022
274 Dec 14, 2022

PyTorch implementation of our ICCV 2019 paper: Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis
Impersonator PyTorch implementation of our ICCV 2019 paper: Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer an
 1.7k Jan 6, 2023
1.7k Jan 6, 2023

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: WavLM (arXiv): WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing UniSpeech (ICML 202
281 Dec 15, 2022
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
Malaya-Speech is a Speech-Toolkit library for bahasa Malaysia, powered by Deep Learning Tensorflow.
Malaya-Speech is a Speech-Toolkit library for bahasa Malaysia, powered by Deep Learning Tensorflow. Documentation Proper documentation is available at
 151 Jan 5, 2023
151 Jan 5, 2023
Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks
wav2vec_finetune Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks Initial test: gender recognition on this dat
 8 Aug 11, 2022
8 Aug 11, 2022
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023
Dynamic View Synthesis from Dynamic Monocular Video
Dynamic View Synthesis from Dynamic Monocular Video Project Website | Video | Paper Dynamic View Synthesis from Dynamic Monocular Video Chen Gao, Ayus
 139 Dec 28, 2022
139 Dec 28, 2022
Pytorch implementation NORESQA A Framework for Speech Quality Assessment using Non-Matching References.
NORESQA: Speech Quality Assessment using Non-Matching References This is a Pytorch implementation for using NORESQA. It contains minimal code to predi
11 Dec 14, 2021
CYGNUS, the Cynical AI, combines snarky responses with uncanny aggression.
New & (hopefully) Improved CYGNUS with several API updates, user updates, and online/offline operations added!!!
 0 Mar 28, 2022
0 Mar 28, 2022
Dynamic View Synthesis from Dynamic Monocular Video
Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer This repository contains code to compute depth from a
2.3k Jan 1, 2023

A voice assistant which can be used to interact with your computer and controls your pc operations
Introduction 👨💻 It is a voice assistant which can be used to interact with your computer and also you have been seeing it in Iron man movies, but t
 84 Dec 22, 2022
84 Dec 22, 2022

A C-like hardware description language (HDL) adding high level synthesis(HLS)-like automatic pipelining as a language construct/compiler feature.
██████╗ ██╗██████╗ ███████╗██╗ ██╗███╗ ██╗███████╗ ██████╗ ██╔══██╗██║██╔══██╗██╔════╝██║ ██║████╗ ██║██╔════╝██╔════╝ ██████╔╝██║██████╔╝█
 391 Jan 1, 2023
391 Jan 1, 2023

Generative Art Synthesizer - a python program that generates python programs that generates generative art
GAS - Generative Art Synthesizer Generative Art Synthesizer - a python program that generates python programs that generates generative art. Examples
 43 Dec 3, 2022
43 Dec 3, 2022
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022

Code for ShadeGAN (NeurIPS2021) A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis
A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis Project Page | Paper A Shading-Guided Generative Implicit Model
 71 Dec 10, 2021
71 Dec 10, 2021

The codebase for our paper "Generative Occupancy Fields for 3D Surface-Aware Image Synthesis" (NeurIPS 2021)
Generative Occupancy Fields for 3D Surface-Aware Image Synthesis (NeurIPS 2021) Project Page | Paper Xudong Xu, Xingang Pan, Dahua Lin and Bo Dai GOF
 97 Nov 10, 2022
97 Nov 10, 2022
A complete speech segmentation system using Kaldi and x-vectors for voice activity detection (VAD) and speaker diarisation.
bbc-speech-segmenter: Voice Activity Detection & Speaker Diarization A complete speech segmentation system using Kaldi and x-vectors for voice activit
 16 Oct 27, 2022
16 Oct 27, 2022
Code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language"
The repository provides the source code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language" submitted to HA
 3 Aug 4, 2022
3 Aug 4, 2022

Official implementation of "A Shared Representation for Photorealistic Driving Simulators" in PyTorch.
A Shared Representation for Photorealistic Driving Simulators The official code for the paper: "A Shared Representation for Photorealistic Driving Sim
 7 Oct 13, 2022
7 Oct 13, 2022

Official implementation of Self-supervised Image-to-text and Text-to-image Synthesis
Self-supervised Image-to-text and Text-to-image Synthesis This is the official implementation of Self-supervised Image-to-text and Text-to-image Synth
 6 Jul 31, 2022
6 Jul 31, 2022
The world's largest toxicity dataset.
The Toxicity Dataset by Surge AI Saving the internet is fun. Combing through thousands of online comments to build a toxicity dataset isn't. That's wh
 134 Dec 19, 2022
134 Dec 19, 2022
An end to end ASR Transformer model training repo
END TO END ASR TRANSFORMER 本项目基于transformer 6*encoder+6*decoder的基本结构构造的端到端的语音识别系统 Model Instructions 1.数据准备: 自行下载数据,遵循文件结构如下: ├── data │ ├── train │
 10 Jul 19, 2022
10 Jul 19, 2022
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone In our recent paper we propose the YourTTS model. YourTTS bri
 390 Dec 29, 2022
390 Dec 29, 2022

ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
ImageBART NeurIPS 2021 Patrick Esser*, Robin Rombach*, Andreas Blattmann*, Björn Ommer * equal contribution arXiv | BibTeX | Poster Requirements A sui
110 Jan 1, 2023
Generative Adversarial Text to Image Synthesis
Text To Image Synthesis This is a tensorflow implementation of synthesizing images. The images are synthesized using the GAN-CLS Algorithm from the pa
 575 Jan 8, 2023
575 Jan 8, 2023
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks - Official Project Page This repository contains the code develope
 1.7k Dec 18, 2022
1.7k Dec 18, 2022

A simple library that implements CLIP guided loss in PyTorch.
pytorch_clip_guided_loss: Pytorch implementation of the CLIP guided loss for Text-To-Image, Image-To-Image, or Image-To-Text generation. A simple libr
 74 Dec 26, 2022
74 Dec 26, 2022
This github repo is for Neurips 2021 paper, NORESQA A Framework for Speech Quality Assessment using Non-Matching References.
NORESQA: Speech Quality Assessment using Non-Matching References This is a Pytorch implementation for using NORESQA. It contains minimal code to predi
36 Dec 8, 2022
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
 76 Dec 30, 2022
76 Dec 30, 2022
Code to reproduce experiments in the paper "Task-Oriented Dialogue as Dataflow Synthesis" (TACL 2020).
Code to reproduce experiments in the paper "Task-Oriented Dialogue as Dataflow Synthesis" (TACL 2020).
274 Dec 28, 2022