3311 Repositories
Python first-year-data-analysis Libraries
An API serving data on all creatures, monsters, materials, equipment, and treasure in The Legend of Zelda: Breath of the Wild
Hyrule Compendium API An API serving data on all creatures, monsters, materials, equipment, and treasure in The Legend of Zelda: Breath of the Wild. B
 116 Dec 1, 2022
116 Dec 1, 2022
Various capabilities for static malware analysis.
Malchive The malchive serves as a compendium for a variety of capabilities mainly pertaining to malware analysis, such as scripts supporting day to da
 64 Nov 22, 2022
64 Nov 22, 2022
Soda SQL Data testing, monitoring and profiling for SQL accessible data.
Soda SQL Data testing, monitoring and profiling for SQL accessible data. What does Soda SQL do? Soda SQL allows you to Stop your pipeline when bad dat
 51 Jan 1, 2023
51 Jan 1, 2023

A framework for joint super-resolution and image synthesis, without requiring real training data
SynthSR This repository contains code to train a Convolutional Neural Network (CNN) for Super-resolution (SR), or joint SR and data synthesis. The met
 83 Jan 1, 2023
83 Jan 1, 2023
data/code repository of "C2F-FWN: Coarse-to-Fine Flow Warping Network for Spatial-Temporal Consistent Motion Transfer"
C2F-FWN data/code repository of "C2F-FWN: Coarse-to-Fine Flow Warping Network for Spatial-Temporal Consistent Motion Transfer" (https://arxiv.org/abs/
 46 Dec 14, 2022
46 Dec 14, 2022
This repository is related to an Arabic tutorial, within the tutorial we discuss the common data structure and algorithms and their worst and best case for each, then implement the code using Python.
Data Structure and Algorithms with Python This repository is related to the Arabic tutorial here, within the tutorial we discuss the common data struc
 33 Dec 2, 2022
33 Dec 2, 2022
A Pythonic client for the official https://data.gov.gr API.
pydatagovgr An unofficial Pythonic client for the official data.gov.gr API. Aims to be an easy, intuitive and out-of-the-box way to: find data publish
 40 Nov 10, 2022
40 Nov 10, 2022
PyCG: Practical Python Call Graphs
PyCG - Practical Python Call Graphs PyCG generates call graphs for Python code using static analysis. It efficiently supports Higher order functions T
 185 Dec 29, 2022
185 Dec 29, 2022
A minimalistic library designed to provide native access to YNAB data from Python
pYNAB A minimalistic library designed to provide native access to YNAB data from Python. Install The simplest way is to install the latest version fro
 92 Apr 6, 2022
92 Apr 6, 2022
Python wrapper for the Sportradar APIs ⚽️🏈
Sportradar APIs This is a Python wrapper for the sports APIs provided by Sportradar. You'll need to sign up for an API key to use the service. Sportra
 39 Jan 1, 2023
39 Jan 1, 2023
Python client for the Socrata Open Data API
sodapy sodapy is a python client for the Socrata Open Data API. Installation You can install with pip install sodapy. If you want to install from sour
 368 Dec 9, 2022
368 Dec 9, 2022
An API Client package to access the APIs for NBA.com
nba_api An API Client package to access the APIs for NBA.com Development Version: v1.1.9 nba_api is an API Client for www.nba.com. This package is mea
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
A Python API to retrieve and read MLB GameDay data
mlbgame mlbgame is a Python API to retrieve and read MLB GameDay data. mlbgame works with real time data, getting information as games are being playe
 493 Dec 13, 2022
493 Dec 13, 2022
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
 14.5k Jan 8, 2023
14.5k Jan 8, 2023
:snake: A simple library to fetch data from the iTunes Store API made for Python = 3.5
itunespy itunespy is a simple library to fetch data from the iTunes Store API made for Python 3.5 and beyond. Important: Since version 1.6 itunespy no
 56 Dec 22, 2022
56 Dec 22, 2022
Backtest 1000s of minute-by-minute trading algorithms for training AI with automated pricing data from: IEX, Tradier and FinViz. Datasets and trading performance automatically published to S3 for building AI training datasets for teaching DNNs how to trade. Runs on Kubernetes and docker-compose. 150 million trading history rows generated from +5000 algorithms. Heads up: Yahoo's Finance API was disabled on 2019-01-03 https://developer.yahoo.com/yql/
Stock Analysis Engine Build and tune investment algorithms for use with artificial intelligence (deep neural networks) with a distributed stack for ru
 828 Dec 28, 2022
828 Dec 28, 2022
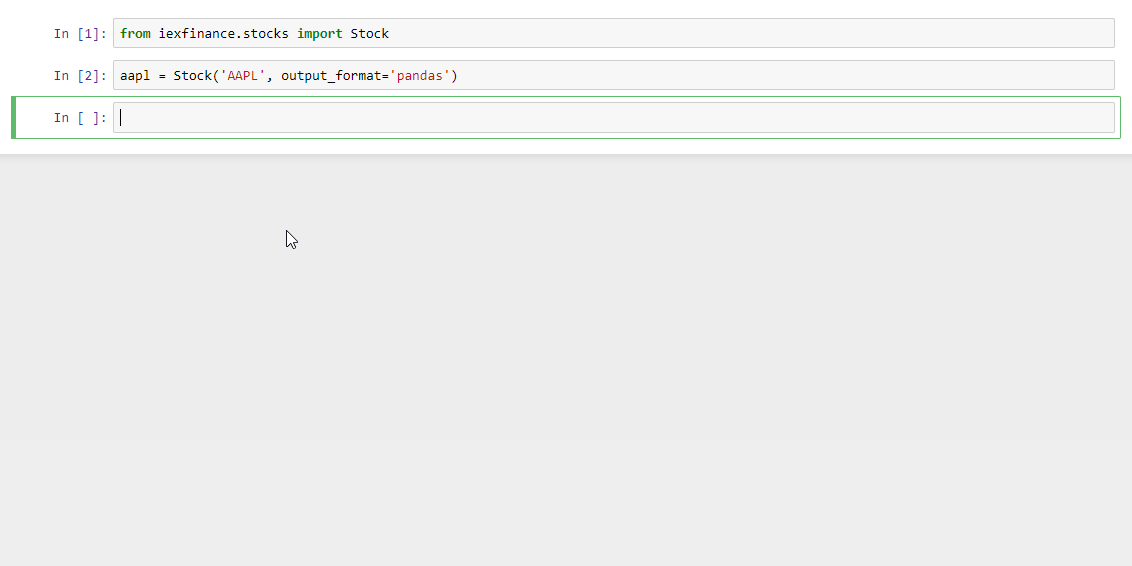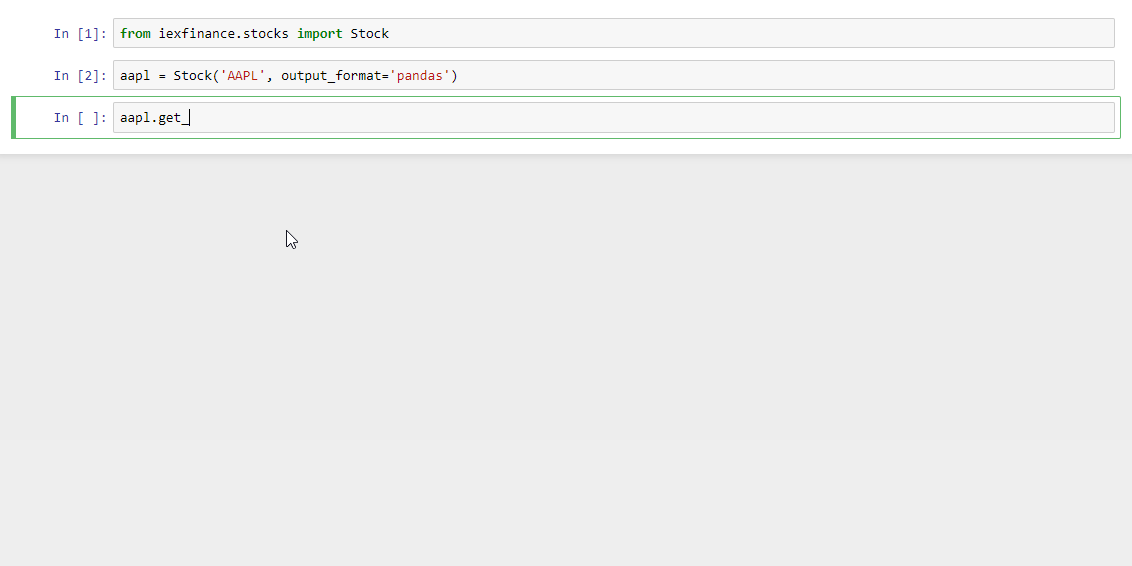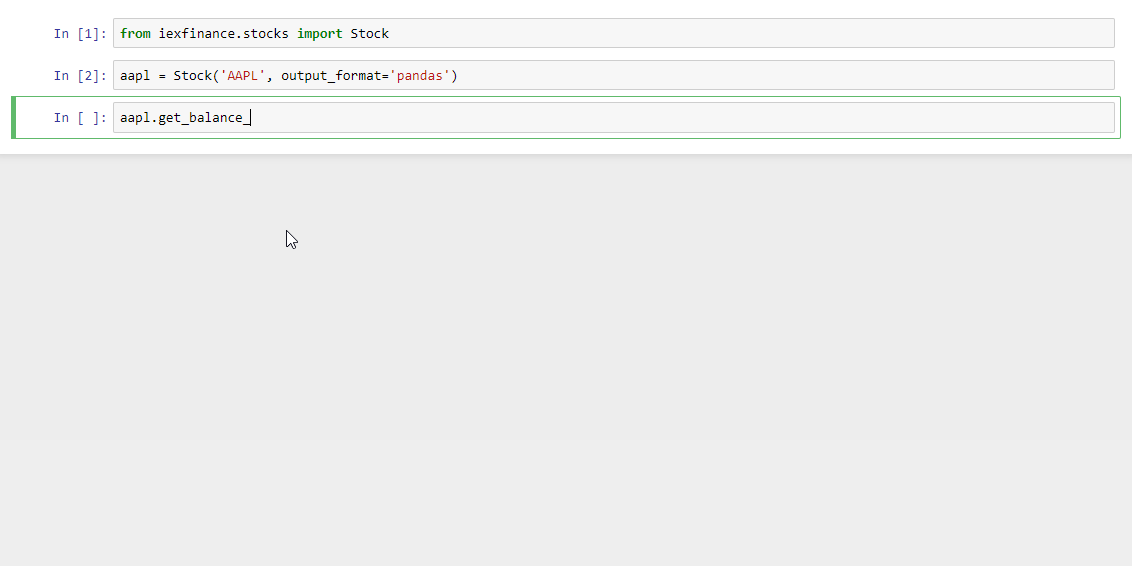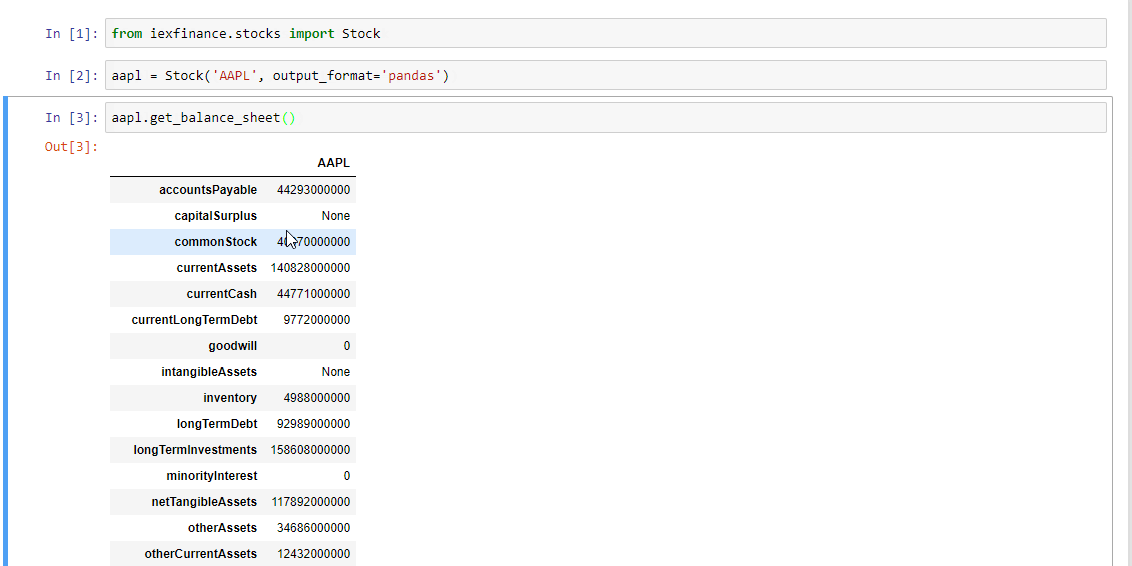
Python SDK for IEX Cloud
iexfinance Python SDK for IEX Cloud. Architecture mirrors that of the IEX Cloud API (and its documentation). An easy-to-use toolkit to obtain data for
 640 Jan 7, 2023
640 Jan 7, 2023
Mimesis is a high-performance fake data generator for Python, which provides data for a variety of purposes in a variety of languages.
Mimesis - Fake Data Generator Description Mimesis is a high-performance fake data generator for Python, which provides data for a variety of purposes
 3.8k Jan 1, 2023
3.8k Jan 1, 2023
Faker is a Python package that generates fake data for you.
Faker is a Python package that generates fake data for you. Whether you need to bootstrap your database, create good-looking XML documents, fill-in yo
 15.2k Jan 1, 2023
15.2k Jan 1, 2023
create custom test databases that are populated with fake data
About Generate fake but valid data filled databases for test purposes using most popular patterns(AFAIK). Current support is sqlite, mysql, postgresql
 2.2k Jan 6, 2023
2.2k Jan 6, 2023
Mimesis is a high-performance fake data generator for Python, which provides data for a variety of purposes in a variety of languages.
Mimesis - Fake Data Generator Description Mimesis is a high-performance fake data generator for Python, which provides data for a variety of purposes
3.8k Dec 29, 2022
Faker is a Python package that generates fake data for you.
Faker is a Python package that generates fake data for you. Whether you need to bootstrap your database, create good-looking XML documents, fill-in yo
15.2k Jan 1, 2023
create custom test databases that are populated with fake data
About Generate fake but valid data filled databases for test purposes using most popular patterns(AFAIK). Current support is sqlite, mysql, postgresql
2.2k Jan 4, 2023
Single API for reading, manipulating and writing data in csv, ods, xls, xlsx and xlsm files
pyexcel - Let you focus on data, instead of file formats Support the project If your company has embedded pyexcel and its components into a revenue ge
 1.1k Dec 29, 2022
1.1k Dec 29, 2022
Statsmodels: statistical modeling and econometrics in Python
About statsmodels statsmodels is a Python package that provides a complement to scipy for statistical computations including descriptive statistics an
 8k Dec 29, 2022
8k Dec 29, 2022
Probabilistic Programming in Python: Bayesian Modeling and Probabilistic Machine Learning with Theano
PyMC3 is a Python package for Bayesian statistical modeling and Probabilistic Machine Learning focusing on advanced Markov chain Monte Carlo (MCMC) an
 7.2k Dec 30, 2022
7.2k Dec 30, 2022

Validated, scalable, community developed variant calling, RNA-seq and small RNA analysis
Validated, scalable, community developed variant calling, RNA-seq and small RNA analysis. You write a high level configuration file specifying your in
 917 Jan 3, 2023
917 Jan 3, 2023
Rich Python data types for Redis
Created by Stephen McDonald Introduction HOT Redis is a wrapper library for the redis-py client. Rather than calling the Redis commands directly from
 281 Nov 10, 2022
281 Nov 10, 2022
Easy-to-use data handling for SQL data stores with support for implicit table creation, bulk loading, and transactions.
dataset: databases for lazy people In short, dataset makes reading and writing data in databases as simple as reading and writing JSON files. Read the
 4.2k Dec 26, 2022
4.2k Dec 26, 2022
Safely pass trusted data to untrusted environments and back.
ItsDangerous ... so better sign this Various helpers to pass data to untrusted environments and to get it back safe and sound. Data is cryptographical
 2.6k Jan 1, 2023
2.6k Jan 1, 2023
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton.
Boltons boltons should be builtins. Boltons is a set of over 230 BSD-licensed, pure-Python utilities in the same spirit as — and yet conspicuously mis
 6k Jan 6, 2023
6k Jan 6, 2023

Debugging, monitoring and visualization for Python Machine Learning and Data Science
Welcome to TensorWatch TensorWatch is a debugging and visualization tool designed for data science, deep learning and reinforcement learning from Micr
3.3k Dec 27, 2022

Analytical Web Apps for Python, R, Julia, and Jupyter. No JavaScript Required.
Dash Dash is the most downloaded, trusted Python framework for building ML & data science web apps. Built on top of Plotly.js, React and Flask, Dash t
 17.9k Dec 31, 2022
17.9k Dec 31, 2022
Multi-class confusion matrix library in Python
Table of contents Overview Installation Usage Document Try PyCM in Your Browser Issues & Bug Reports Todo Outputs Dependencies Contribution References
 1.3k Dec 31, 2022
1.3k Dec 31, 2022

:bowtie: Create a dashboard with python!
Installation | Documentation | Gitter Chat | Google Group Bowtie Introduction Bowtie is a library for writing dashboards in Python. No need to know we
 753 Dec 22, 2022
753 Dec 22, 2022

An intuitive library to add plotting functionality to scikit-learn objects.
Welcome to Scikit-plot Single line functions for detailed visualizations The quickest and easiest way to go from analysis... ...to this. Scikit-plot i
 2.3k Dec 31, 2022
2.3k Dec 31, 2022
Tools for exploratory data analysis in Python
Dora Exploratory data analysis toolkit for Python. Contents Summary Setup Usage Reading Data & Configuration Cleaning Feature Selection & Extraction V
 599 Dec 25, 2022
599 Dec 25, 2022
Apache Superset is a Data Visualization and Data Exploration Platform
Superset A modern, enterprise-ready business intelligence web application. Why Superset? | Supported Databases | Installation and Configuration | Rele
 50k Jan 6, 2023
50k Jan 6, 2023
The windML framework provides an easy-to-use access to wind data sources within the Python world, building upon numpy, scipy, sklearn, and matplotlib. Renewable Wind Energy, Forecasting, Prediction
windml Build status : The importance of wind in smart grids with a large number of renewable energy resources is increasing. With the growing infrastr
 125 Dec 24, 2022
125 Dec 24, 2022
The Python ensemble sampling toolkit for affine-invariant MCMC
emcee The Python ensemble sampling toolkit for affine-invariant MCMC emcee is a stable, well tested Python implementation of the affine-invariant ense
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
NumPy and Pandas interface to Big Data
Blaze translates a subset of modified NumPy and Pandas-like syntax to databases and other computing systems. Blaze allows Python users a familiar inte
 3.1k Jan 1, 2023
3.1k Jan 1, 2023
Fast data visualization and GUI tools for scientific / engineering applications
PyQtGraph A pure-Python graphics library for PyQt5/PyQt6/PySide2/PySide6 Copyright 2020 Luke Campagnola, University of North Carolina at Chapel Hill h
 3.1k Jan 8, 2023
3.1k Jan 8, 2023
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
 2.1k Jan 1, 2023
2.1k Jan 1, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 13.8k Jan 2, 2023
13.8k Jan 2, 2023
Yet Another Sequence Encoder - Encode sequences to vector of vector in python !
Yase Yet Another Sequence Encoder - encode sequences to vector of vectors in python ! Why Yase ? Yase enable you to encode any sequence which can be r
 12 Aug 19, 2021
12 Aug 19, 2021
💫 Industrial-strength Natural Language Processing (NLP) in Python
spaCy: Industrial-strength NLP spaCy is a library for advanced Natural Language Processing in Python and Cython. It's built on the very latest researc
 24.9k Jan 2, 2023
24.9k Jan 2, 2023
Python bindings to the dutch NLP tool Frog (pos tagger, lemmatiser, NER tagger, morphological analysis, shallow parser, dependency parser)
Frog for Python This is a Python binding to the Natural Language Processing suite Frog. Frog is intended for Dutch and performs part-of-speech tagging
 46 Dec 14, 2022
46 Dec 14, 2022
This is a Python binding to the tokenizer Ucto. Tokenisation is one of the first step in almost any Natural Language Processing task, yet it is not always as trivial a task as it appears to be. This binding makes the power of the ucto tokeniser available to Python. Ucto itself is regular-expression based, extensible, and advanced tokeniser written in C++ (http://ilk.uvt.nl/ucto).
Ucto for Python This is a Python binding to the tokeniser Ucto. Tokenisation is one of the first step in almost any Natural Language Processing task,
27 Dec 14, 2022
A Python package implementing a new model for text classification with visualization tools for Explainable AI :octocat:
A Python package implementing a new model for text classification with visualization tools for Explainable AI 🍣 Online live demos: http://tworld.io/s
 285 Jan 2, 2023
285 Jan 2, 2023
Tools, wrappers, etc... for data science with a concentration on text processing
Rosetta Tools for data science with a focus on text processing. Focuses on "medium data", i.e. data too big to fit into memory but too small to necess
 207 Nov 22, 2022
207 Nov 22, 2022

Web mining module for Python, with tools for scraping, natural language processing, machine learning, network analysis and visualization.
Pattern Pattern is a web mining module for Python. It has tools for: Data Mining: web services (Google, Twitter, Wikipedia), web crawler, HTML DOM par
 8.4k Dec 30, 2022
8.4k Dec 30, 2022

Create UIs for prototyping your machine learning model in 3 minutes
Note: We just launched Hosted, where anyone can upload their interface for permanent hosting. Check it out! Welcome to Gradio Quickly create customiza
 11.7k Jan 7, 2023
11.7k Jan 7, 2023
A unified framework for machine learning with time series
Welcome to sktime A unified framework for machine learning with time series We provide specialized time series algorithms and scikit-learn compatible
 6k Jan 8, 2023
6k Jan 8, 2023

A Peer-to-peer Platform for Secure, Privacy-preserving, Decentralized Data Science
PyGrid is a peer-to-peer network of data owners and data scientists who can collectively train AI models using PySyft. PyGrid is also the central serv
 615 Jan 3, 2023
615 Jan 3, 2023
A library for answering questions using data you cannot see
A library for computing on data you do not own and cannot see PySyft is a Python library for secure and private Deep Learning. PySyft decouples privat
8.5k Jan 2, 2023

Automates Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning :rocket:
MLJAR Automated Machine Learning Documentation: https://supervised.mljar.com/ Source Code: https://github.com/mljar/mljar-supervised Table of Contents
 2.4k Dec 31, 2022
2.4k Dec 31, 2022
A machine learning package for streaming data in Python. The other ancestor of River.
scikit-multiflow is a machine learning package for streaming data in Python. creme and scikit-multiflow are merging into a new project called River. W
 670 Dec 30, 2022
670 Dec 30, 2022
🌊 Online machine learning in Python
In a nutshell River is a Python library for online machine learning. It is the result of a merger between creme and scikit-multiflow. River's ambition
 4k Jan 2, 2023
4k Jan 2, 2023
MiraiML: asynchronous, autonomous and continuous Machine Learning in Python
MiraiML Mirai: future in japanese. MiraiML is an asynchronous engine for continuous & autonomous machine learning, built for real-time usage. Usage In
 25 Jul 27, 2022
25 Jul 27, 2022

StellarGraph - Machine Learning on Graphs
StellarGraph Machine Learning Library StellarGraph is a Python library for machine learning on graphs and networks. Table of Contents Introduction Get
 2.6k Jan 5, 2023
2.6k Jan 5, 2023
Best Practices on Recommendation Systems
Recommenders What's New (February 4, 2021) We have a new relase Recommenders 2021.2! It comes with lots of bug fixes, optimizations and 3 new algorith
14.8k Jan 3, 2023
High performance, easy-to-use, and scalable machine learning (ML) package, including linear model (LR), factorization machines (FM), and field-aware factorization machines (FFM) for Python and CLI interface.
What is xLearn? xLearn is a high performance, easy-to-use, and scalable machine learning package that contains linear model (LR), factorization machin
 3k Jan 3, 2023
3k Jan 3, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 4, 2023
6.9k Jan 4, 2023
Machine Learning From Scratch. Bare bones NumPy implementations of machine learning models and algorithms with a focus on accessibility. Aims to cover everything from linear regression to deep learning.
Machine Learning From Scratch About Python implementations of some of the fundamental Machine Learning models and algorithms from scratch. The purpose
 21.8k Jan 9, 2023
21.8k Jan 9, 2023
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate.
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate. Website • Key Features • How To Use • Docs •
 21.1k Jan 1, 2023
21.1k Jan 1, 2023

A web-based application for quick, scalable, and automated hyperparameter tuning and stacked ensembling in Python.
Xcessiv Xcessiv is a tool to help you create the biggest, craziest, and most excessive stacked ensembles you can think of. Stacked ensembles are simpl
1.3k Nov 17, 2022

Deep learning library featuring a higher-level API for TensorFlow.
TFLearn: Deep learning library featuring a higher-level API for TensorFlow. TFlearn is a modular and transparent deep learning library built on top of
 9.6k Jan 2, 2023
9.6k Jan 2, 2023
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
Master status: Development status: Package information: TPOT stands for Tree-based Pipeline Optimization Tool. Consider TPOT your Data Science Assista
 8.9k Dec 30, 2022
8.9k Dec 30, 2022
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2020 Links Doc
 4.2k Jan 2, 2023
4.2k Jan 2, 2023
Shōgun
The SHOGUN machine learning toolbox Unified and efficient Machine Learning since 1999. Latest release: Cite Shogun: Develop branch build status: Donat
 2.9k Jan 4, 2023
2.9k Jan 4, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 3, 2023
Web mining module for Python, with tools for scraping, natural language processing, machine learning, network analysis and visualization.
Pattern Pattern is a web mining module for Python. It has tools for: Data Mining: web services (Google, Twitter, Wikipedia), web crawler, HTML DOM par
8.4k Jan 3, 2023
Serverless proxy for Spark cluster
Hydrosphere Mist Hydrosphere Mist is a serverless proxy for Spark cluster. Mist provides a new functional programming framework and deployment model f
 317 Dec 1, 2022
317 Dec 1, 2022
aka "Bayesian Methods for Hackers": An introduction to Bayesian methods + probabilistic programming with a computation/understanding-first, mathematics-second point of view. All in pure Python ;)
Bayesian Methods for Hackers Using Python and PyMC The Bayesian method is the natural approach to inference, yet it is hidden from readers behind chap
 25.1k Jan 2, 2023
25.1k Jan 2, 2023
[UNMAINTAINED] Automated machine learning for analytics & production
auto_ml Automated machine learning for production and analytics Installation pip install auto_ml Getting started from auto_ml import Predictor from au
 1.6k Jan 2, 2023
1.6k Jan 2, 2023
Lightweight, Python library for fast and reproducible experimentation :microscope:
Steppy What is Steppy? Steppy is a lightweight, open-source, Python 3 library for fast and reproducible experimentation. Steppy lets data scientist fo
 134 Jul 10, 2022
134 Jul 10, 2022
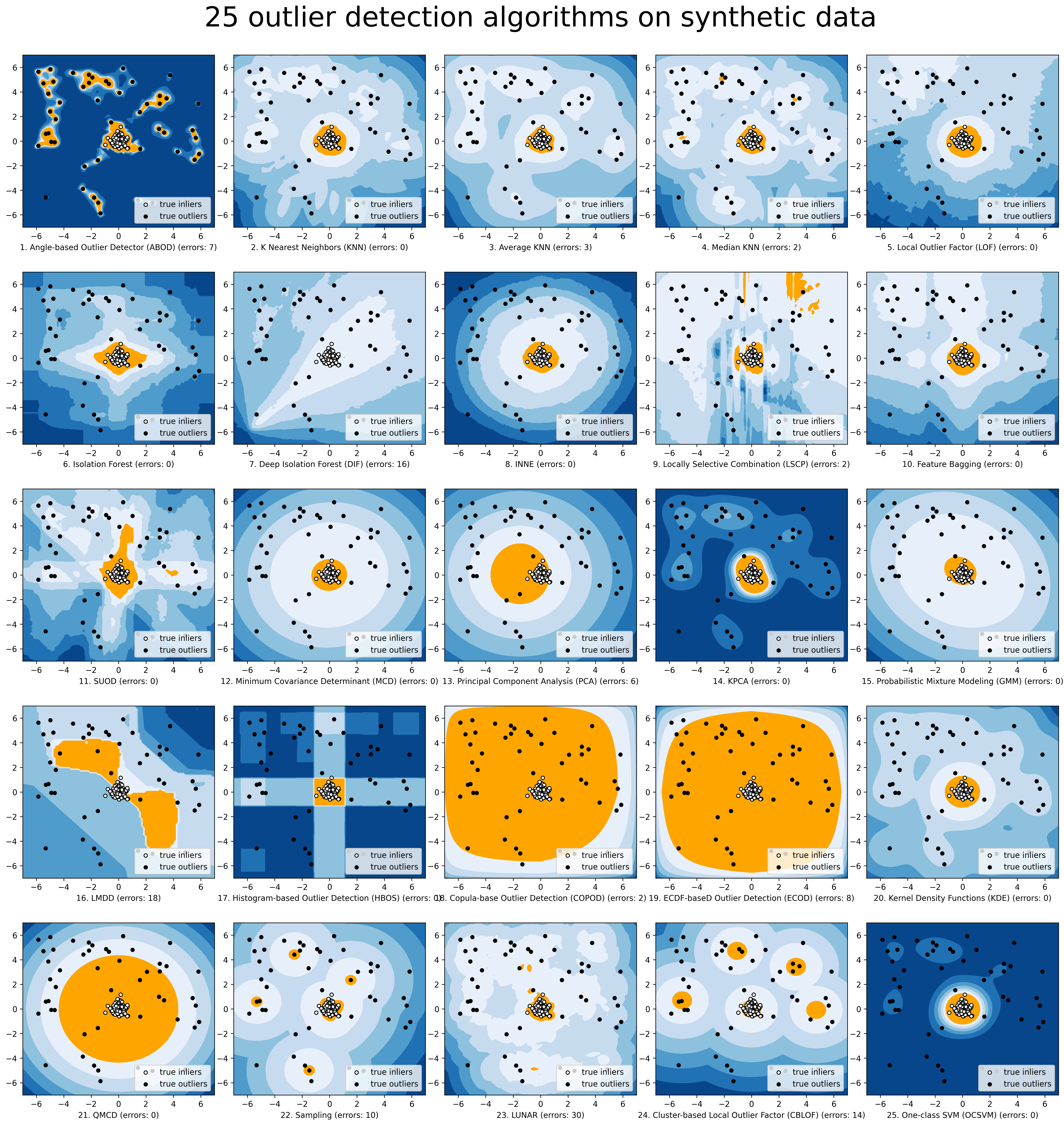
(JMLR'19) A Python Toolbox for Scalable Outlier Detection (Anomaly Detection)
Python Outlier Detection (PyOD) Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License PyOD is a comprehensive and sca
 6.6k Jan 3, 2023
6.6k Jan 3, 2023
A Temporal Extension Library for PyTorch Geometric
Documentation | External Resources | Datasets PyTorch Geometric Temporal is a temporal (dynamic) extension library for PyTorch Geometric. The library
 1.9k Jan 7, 2023
1.9k Jan 7, 2023
a delightful machine learning tool that allows you to train, test and use models without writing code
igel A delightful machine learning tool that allows you to train/fit, test and use models without writing code Note I'm also working on a GUI desktop
 3k Jan 5, 2023
3k Jan 5, 2023

A data-driven approach to quantify the value of classifiers in a machine learning ensemble.
Documentation | External Resources | Research Paper Shapley is a Python library for evaluating binary classifiers in a machine learning ensemble. The
188 Dec 29, 2022
a generic C++ library for image analysis
VIGRA Computer Vision Library Copyright 1998-2013 by Ullrich Koethe This file is part of the VIGRA computer vision library. You may use,
 378 Dec 30, 2022
378 Dec 30, 2022
H2O is an Open Source, Distributed, Fast & Scalable Machine Learning Platform: Deep Learning, Gradient Boosting (GBM) & XGBoost, Random Forest, Generalized Linear Modeling (GLM with Elastic Net), K-Means, PCA, Generalized Additive Models (GAM), RuleFit, Support Vector Machine (SVM), Stacked Ensembles, Automatic Machine Learning (AutoML), etc.
H2O H2O is an in-memory platform for distributed, scalable machine learning. H2O uses familiar interfaces like R, Python, Scala, Java, JSON and the Fl
 6.1k Jan 5, 2023
6.1k Jan 5, 2023
The easiest way to automate your data
Hello, world! 👋 We've rebuilt data engineering for the data science era. Prefect is a new workflow management system, designed for modern infrastruct
 10.9k Jan 4, 2023
10.9k Jan 4, 2023
Scapy: the Python-based interactive packet manipulation program & library. Supports Python 2 & Python 3.
Scapy Scapy is a powerful Python-based interactive packet manipulation program and library. It is able to forge or decode packets of a wide number of
 8.3k Jan 8, 2023
8.3k Jan 8, 2023
A code-completion engine for Vim
YouCompleteMe: a code-completion engine for Vim NOTE: Minimum Requirements Have Changed Our policy is to support the Vim version that's in the latest
 24.5k Dec 30, 2022
24.5k Dec 30, 2022
AkShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库
Overview AkShare requires Python(64 bit) 3.7 or greater, aims to make fetch financial data as convenient as possible. Write less, get more! Documentat
 5.8k Jan 3, 2023
5.8k Jan 3, 2023
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
Ray provides a simple, universal API for building distributed applications. Ray is packaged with the following libraries for accelerating machine lear
 23.2k Dec 30, 2022
23.2k Dec 30, 2022
Deep Learning for humans
Keras: Deep Learning for Python Under Construction In the near future, this repository will be used once again for developing the Keras codebase. For
 57k Jan 9, 2023
57k Jan 9, 2023

Sampling profiler for Python programs
py-spy: Sampling profiler for Python programs py-spy is a sampling profiler for Python programs. It lets you visualize what your Python program is spe
 9.5k Jan 8, 2023
9.5k Jan 8, 2023
Statistical data visualization using matplotlib
seaborn: statistical data visualization Seaborn is a Python visualization library based on matplotlib. It provides a high-level interface for drawing
 10.2k Dec 30, 2022
10.2k Dec 30, 2022

A grammar of graphics for Python
plotnine Latest Release License DOI Build Status Coverage Documentation plotnine is an implementation of a grammar of graphics in Python, it is based
 3.3k Jan 1, 2023
3.3k Jan 1, 2023
Interactive Data Visualization in the browser, from Python
Bokeh is an interactive visualization library for modern web browsers. It provides elegant, concise construction of versatile graphics, and affords hi
 17.1k Dec 31, 2022
17.1k Dec 31, 2022

:truck: Agile Data Preparation Workflows made easy with dask, cudf, dask_cudf and pyspark
To launch a live notebook server to test optimus using binder or Colab, click on one of the following badges: Optimus is the missing framework to prof
 1.3k Dec 30, 2022
1.3k Dec 30, 2022

Business Intelligence (BI) in Python, OLAP
Open Mining Business Intelligence (BI) Application Server written in Python Requirements Python 2.7 (Backend) Lua 5.2 or LuaJIT 5.1 (OML backend) Mong
 1.2k Dec 27, 2022
1.2k Dec 27, 2022
NumPy and Pandas interface to Big Data
Blaze translates a subset of modified NumPy and Pandas-like syntax to databases and other computing systems. Blaze allows Python users a familiar inte
3.1k Jan 5, 2023
Pandas on AWS - Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL).
AWS Data Wrangler Pandas on AWS Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretMana
 3.3k Jan 4, 2023
3.3k Jan 4, 2023

Ready-to-use OCR with 80+ supported languages and all popular writing scripts including Latin, Chinese, Arabic, Devanagari, Cyrillic and etc.
EasyOCR Ready-to-use OCR with 80+ languages supported including Chinese, Japanese, Korean and Thai. What's new 1 February 2021 - Version 1.2.3 Add set
 16.7k Jan 3, 2023
16.7k Jan 3, 2023

Typical: Fast, simple, & correct data-validation using Python 3 typing.
typical: Python's Typing Toolkit Introduction Typical is a library devoted to runtime analysis, inference, validation, and enforcement of Python types
 170 Dec 26, 2022
170 Dec 26, 2022
Data parsing and validation using Python type hints
pydantic Data validation and settings management using Python type hinting. Fast and extensible, pydantic plays nicely with your linters/IDE/brain. De
 12.1k Jan 5, 2023
12.1k Jan 5, 2023
A static analysis tool for Python
pyanalyze Pyanalyze is a tool for programmatically detecting common mistakes in Python code, such as references to undefined variables and some catego
 212 Jan 7, 2023
212 Jan 7, 2023