2224 Repositories
Python language-generation-dataset Libraries
The official code for paper "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Modeling".
R2D2 This is the official code for paper titled "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Mode
 49 Dec 17, 2022
49 Dec 17, 2022

Progressive Coordinate Transforms for Monocular 3D Object Detection
Progressive Coordinate Transforms for Monocular 3D Object Detection This repository is the official implementation of PCT. Introduction In this paper,
 58 Nov 6, 2022
58 Nov 6, 2022

A weakly-supervised scene graph generation codebase. The implementation of our CVPR2021 paper ``Linguistic Structures as Weak Supervision for Visual Scene Graph Generation''
README.md shall be finished soon. WSSGG 0 Overview 1 Installation 1.1 Faster-RCNN 1.2 Language Parser 1.3 GloVe Embeddings 2 Settings 2.1 VG-GT-Graph
 35 Nov 20, 2022
35 Nov 20, 2022

Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision. ICCV 2021.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision Download links and PyTorch implementation of "Towers of Ba
 40 Dec 14, 2022
40 Dec 14, 2022
A pytorch implementation of the CVPR2021 paper "VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild"
VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild A pytorch implementation of the CVPR2021 paper "VSPW: A Large-scale Dataset for Video
 45 Nov 29, 2022
45 Nov 29, 2022
PyTorch implementation of "Learn to Dance with AIST++: Music Conditioned 3D Dance Generation."
Learn to Dance with AIST++: Music Conditioned 3D Dance Generation. Installation pip install -r requirements.txt Prepare Dataset bash data/scripts/pre
 8 Sep 7, 2021
8 Sep 7, 2021
Vision-Language Transformer and Query Generation for Referring Segmentation (ICCV 2021)
Vision-Language Transformer and Query Generation for Referring Segmentation Please consider citing our paper in your publications if the project helps
 143 Dec 23, 2022
143 Dec 23, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023

Seeing Dynamic Scene in the Dark: High-Quality Video Dataset with Mechatronic Alignment (ICCV2021)
Seeing Dynamic Scene in the Dark: High-Quality Video Dataset with Mechatronic Alignment This is a pytorch project for the paper Seeing Dynamic Scene i
 21 Nov 28, 2022
21 Nov 28, 2022
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022
😇A pyTorch implementation of the DeepMoji model: state-of-the-art deep learning model for analyzing sentiment, emotion, sarcasm etc
------ Update September 2018 ------ It's been a year since TorchMoji and DeepMoji were released. We're trying to understand how it's being used such t
 865 Dec 24, 2022
865 Dec 24, 2022

Pytorch implementation for Semantic Segmentation/Scene Parsing on MIT ADE20K dataset
Semantic Segmentation on MIT ADE20K dataset in PyTorch This is a PyTorch implementation of semantic segmentation models on MIT ADE20K scene parsing da
 4.5k Jan 8, 2023
4.5k Jan 8, 2023
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023

HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021)
Code for HDR Video Reconstruction HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021) Guanying Chen, Cha
 64 Nov 19, 2022
64 Nov 19, 2022

This repository is to support contributions for tools for the Project CodeNet dataset hosted in DAX
The goal of Project CodeNet is to provide the AI-for-Code research community with a large scale, diverse, and high quality curated dataset to drive innovation in AI techniques.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering Papers with code | Paper Nikola Zubić Pietro Lio University
 213 Dec 27, 2022
213 Dec 27, 2022

FedScale: Benchmarking Model and System Performance of Federated Learning
FedScale: Benchmarking Model and System Performance of Federated Learning (Paper) This repository contains scripts and instructions of building FedSca
 268 Jan 1, 2023
268 Jan 1, 2023

Tracing Versus Freehand for Evaluating Computer-Generated Drawings (SIGGRAPH 2021)
Tracing Versus Freehand for Evaluating Computer-Generated Drawings (SIGGRAPH 2021) Zeyu Wang, Sherry Qiu, Nicole Feng, Holly Rushmeier, Leonard McMill
 23 Dec 9, 2022
23 Dec 9, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
 65 Sep 13, 2022
65 Sep 13, 2022
PyTorch implementation for Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuous Sign Language Recognition.
Stochastic CSLR This is the PyTorch implementation for the ECCV 2020 paper: Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuou
 28 Dec 19, 2022
28 Dec 19, 2022
Source code for "Progressive Transformers for End-to-End Sign Language Production" (ECCV 2020)
Progressive Transformers for End-to-End Sign Language Production Source code for "Progressive Transformers for End-to-End Sign Language Production" (B
 58 Dec 21, 2022
58 Dec 21, 2022
Sign Language Translation with Transformers (COLING'2020, ECCV'20 SLRTP Workshop)
transformer-slt This repository gathers data and code supporting the experiments in the paper Better Sign Language Translation with STMC-Transformer.
 107 Dec 27, 2022
107 Dec 27, 2022
Sign Language Transformers (CVPR'20)
Sign Language Transformers (CVPR'20) This repo contains the training and evaluation code for the paper Sign Language Transformers: Sign Language Trans
 164 Dec 30, 2022
164 Dec 30, 2022
Code for the paper "VisualBERT: A Simple and Performant Baseline for Vision and Language"
This repository contains code for the following two papers: VisualBERT: A Simple and Performant Baseline for Vision and Language (arxiv) with a short
 463 Dec 9, 2022
463 Dec 9, 2022
Multi Task Vision and Language
12-in-1: Multi-Task Vision and Language Representation Learning Please cite the following if you use this code. Code and pre-trained models for 12-in-
 712 Dec 19, 2022
712 Dec 19, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023

VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
VisualGPT Our Paper VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning Main Architecture of Our VisualGPT Downloa
 140 Dec 28, 2022
140 Dec 28, 2022
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Dec 29, 2022
1.3k Dec 29, 2022

The RWKV Language Model
RWKV-LM We propose the RWKV language model, with alternating time-mix and channel-mix layers: The R, K, V are generated by linear transforms of input,
 877 Jan 5, 2023
877 Jan 5, 2023
Video Visual Relation Detection (VidVRD) tracklets generation. also for ACM MM Visual Relation Understanding Grand Challenge
VidVRD-tracklets This repository contains codes for Video Visual Relation Detection (VidVRD) tracklets generation based on MEGA and deepSORT. These tr
 25 Dec 21, 2022
25 Dec 21, 2022
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
 235 Dec 22, 2022
235 Dec 22, 2022

COVID-Net Open Source Initiative
The COVID-Net models provided here are intended to be used as reference models that can be built upon and enhanced as new data becomes available
 1.1k Dec 26, 2022
1.1k Dec 26, 2022

Emotional conditioned music generation using transformer-based model.
This is the official repository of EMOPIA: A Multi-Modal Pop Piano Dataset For Emotion Recognition and Emotion-based Music Generation. The paper has b
 96 Nov 9, 2022
96 Nov 9, 2022
Code for ACL 21: Generating Query Focused Summaries from Query-Free Resources
marge This repository releases the code for Generating Query Focused Summaries from Query-Free Resources. Please cite the following paper [bib] if you
 28 Nov 10, 2022
28 Nov 10, 2022

Sum-Product Probabilistic Language
Sum-Product Probabilistic Language SPPL is a probabilistic programming language that delivers exact solutions to a broad range of probabilistic infere
 57 Nov 17, 2022
57 Nov 17, 2022

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022

Code for generating a single image pretraining dataset
Single Image Pretraining of Visual Representations As shown in the paper A critical analysis of self-supervision, or what we can learn from a single i
 12 Dec 19, 2022
12 Dec 19, 2022

Zero-Shot Text-to-Image Generation VQGAN+CLIP Dockerized
VQGAN-CLIP-Docker About Zero-Shot Text-to-Image Generation VQGAN+CLIP Dockerized This is a stripped and minimal dependency repository for running loca
 73 Sep 11, 2022
73 Sep 11, 2022
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Disfl-QA is a targeted dataset for contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages. Disfl-QA builds upon the SQuAD-v2 (Rajpurkar et al., 2018) dataset, where each question in the dev set is annotated to add a contextual disfluency using the paragraph as a source of distractors.
 52 Jun 21, 2022
52 Jun 21, 2022
This repository contains the code for using the H3DS dataset introduced in H3D-Net: Few-Shot High-Fidelity 3D Head Reconstruction
H3DS Dataset This repository contains the code for using the H3DS dataset introduced in H3D-Net: Few-Shot High-Fidelity 3D Head Reconstruction Access
 72 Dec 10, 2022
72 Dec 10, 2022
API for the GPT-J language model 🦜. Including a FastAPI backend and a streamlit frontend
gpt-j-api 🦜 An API to interact with the GPT-J language model. You can use and test the model in two different ways: Streamlit web app at http://api.v
 276 Dec 31, 2022
276 Dec 31, 2022

Pytorch implementation of CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generation"
MUST-GAN Code | paper The Pytorch implementation of our CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generat
 46 Dec 26, 2022
46 Dec 26, 2022
An implementation for `Text2Event: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction`
Text2Event An implementation for Text2Event: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction Please contact Yaojie Lu (@
 153 Jan 7, 2023
153 Jan 7, 2023

PyTorch implementation for SDEdit: Image Synthesis and Editing with Stochastic Differential Equations
SDEdit: Image Synthesis and Editing with Stochastic Differential Equations Project | Paper | Colab PyTorch implementation of SDEdit: Image Synthesis a
 536 Jan 5, 2023
536 Jan 5, 2023
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022

Benchmark for evaluating open-ended generation
OpenMEVA Contributed by Jian Guan, Zhexin Zhang. Thank Jiaxin Wen for DeBugging. OpenMEVA is a benchmark for evaluating open-ended story generation me
 25 Nov 15, 2022
25 Nov 15, 2022

Data and Code for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning"
Introduction Code and data for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning". We cons
 81 Dec 27, 2022
81 Dec 27, 2022
OpenGAN: Open-Set Recognition via Open Data Generation
OpenGAN: Open-Set Recognition via Open Data Generation ICCV 2021 (oral) Real-world machine learning systems need to analyze novel testing data that di
 90 Jan 6, 2023
90 Jan 6, 2023
Code Repo for the ACL21 paper "Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning"
Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning This is the Github repository of our paper, "Common S
 19 Nov 30, 2022
19 Nov 30, 2022
Official implementation of "StyleCariGAN: Caricature Generation via StyleGAN Feature Map Modulation" (SIGGRAPH 2021)
StyleCariGAN in PyTorch Official implementation of StyleCariGAN:Caricature Generation via StyleGAN Feature Map Modulation in PyTorch Requirements PyTo
 49 Oct 31, 2022
49 Oct 31, 2022

Code for Motion Representations for Articulated Animation paper
Motion Representations for Articulated Animation This repository contains the source code for the CVPR'2021 paper Motion Representations for Articulat
 851 Jan 9, 2023
851 Jan 9, 2023
Source code and Dataset creation for the paper "Neural Symbolic Regression That Scales"
NeuralSymbolicRegressionThatScales Pytorch implementation and pretrained models for the paper "Neural Symbolic Regression That Scales", presented at I
 35 Nov 25, 2022
35 Nov 25, 2022
Re-TACRED: Addressing Shortcomings of the TACRED Dataset
Re-TACRED Re-TACRED: Addressing Shortcomings of the TACRED Dataset
 40 Dec 10, 2022
40 Dec 10, 2022

Dataset used in "PlantDoc: A Dataset for Visual Plant Disease Detection" accepted in CODS-COMAD 2020
PlantDoc: A Dataset for Visual Plant Disease Detection This repository contains the Cropped-PlantDoc dataset used for benchmarking classification mode
 109 Dec 29, 2022
109 Dec 29, 2022
Versatile Generative Language Model
Versatile Generative Language Model This is the implementation of the paper: Exploring Versatile Generative Language Model Via Parameter-Efficient Tra
 17 Dec 2, 2022
17 Dec 2, 2022

The personal repository of the work: *DanceNet3D: Music Based Dance Generation with Parametric Motion Transformer*.
DanceNet3D The personal repository of the work: DanceNet3D: Music Based Dance Generation with Parametric Motion Transformer. Dataset and Results Pleas
 36 Dec 21, 2022
36 Dec 21, 2022
PyTorch implementation of MuseMorphose, a Transformer-based model for music style transfer.
MuseMorphose This repository contains the official implementation of the following paper: Shih-Lun Wu, Yi-Hsuan Yang MuseMorphose: Full-Song and Fine-
 142 Jan 8, 2023
142 Jan 8, 2023

Official implementation of SynthTIGER (Synthetic Text Image GEneratoR) ICDAR 2021
🐯 SynthTIGER: Synthetic Text Image GEneratoR Official implementation of SynthTIGER | Paper | Datasets Moonbin Yim1, Yoonsik Kim1, Han-cheol Cho1, Sun
 256 Jan 5, 2023
256 Jan 5, 2023

A PyTorch toolkit for 2D Human Pose Estimation.
PyTorch-Pose PyTorch-Pose is a PyTorch implementation of the general pipeline for 2D single human pose estimation. The aim is to provide the interface
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
Implementation of EMNLP 2017 Paper "Natural Language Does Not Emerge 'Naturally' in Multi-Agent Dialog" using PyTorch and ParlAI
Language Emergence in Multi Agent Dialog Code for the Paper Natural Language Does Not Emerge 'Naturally' in Multi-Agent Dialog Satwik Kottur, José M.
 105 Nov 25, 2022
105 Nov 25, 2022
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 170 Jan 4, 2023
170 Jan 4, 2023

MASS: Masked Sequence to Sequence Pre-training for Language Generation
MASS: Masked Sequence to Sequence Pre-training for Language Generation
1.1k Dec 17, 2022
Active learning for text classification in Python
Active Learning allows you to efficiently label training data in a small-data scenario.
 375 Dec 28, 2022
375 Dec 28, 2022

meProp: Sparsified Back Propagation for Accelerated Deep Learning
meProp The codes were used for the paper meProp: Sparsified Back Propagation for Accelerated Deep Learning with Reduced Overfitting (ICML 2017) [pdf]
 107 Nov 18, 2022
107 Nov 18, 2022

Train an RL agent to execute natural language instructions in a 3D Environment (PyTorch)
Gated-Attention Architectures for Task-Oriented Language Grounding This is a PyTorch implementation of the AAAI-18 paper: Gated-Attention Architecture
 234 Nov 5, 2022
234 Nov 5, 2022

🐥A PyTorch implementation of OpenAI's finetuned transformer language model with a script to import the weights pre-trained by OpenAI
PyTorch implementation of OpenAI's Finetuned Transformer Language Model This is a PyTorch implementation of the TensorFlow code provided with OpenAI's
1.4k Jan 5, 2023

NLPShala , the best IDE for all Natural language processing tasks.
The revolutionary IDE for all NLP (Natural language processing) stuffs on the internet.
 3 Aug 8, 2021
3 Aug 8, 2021
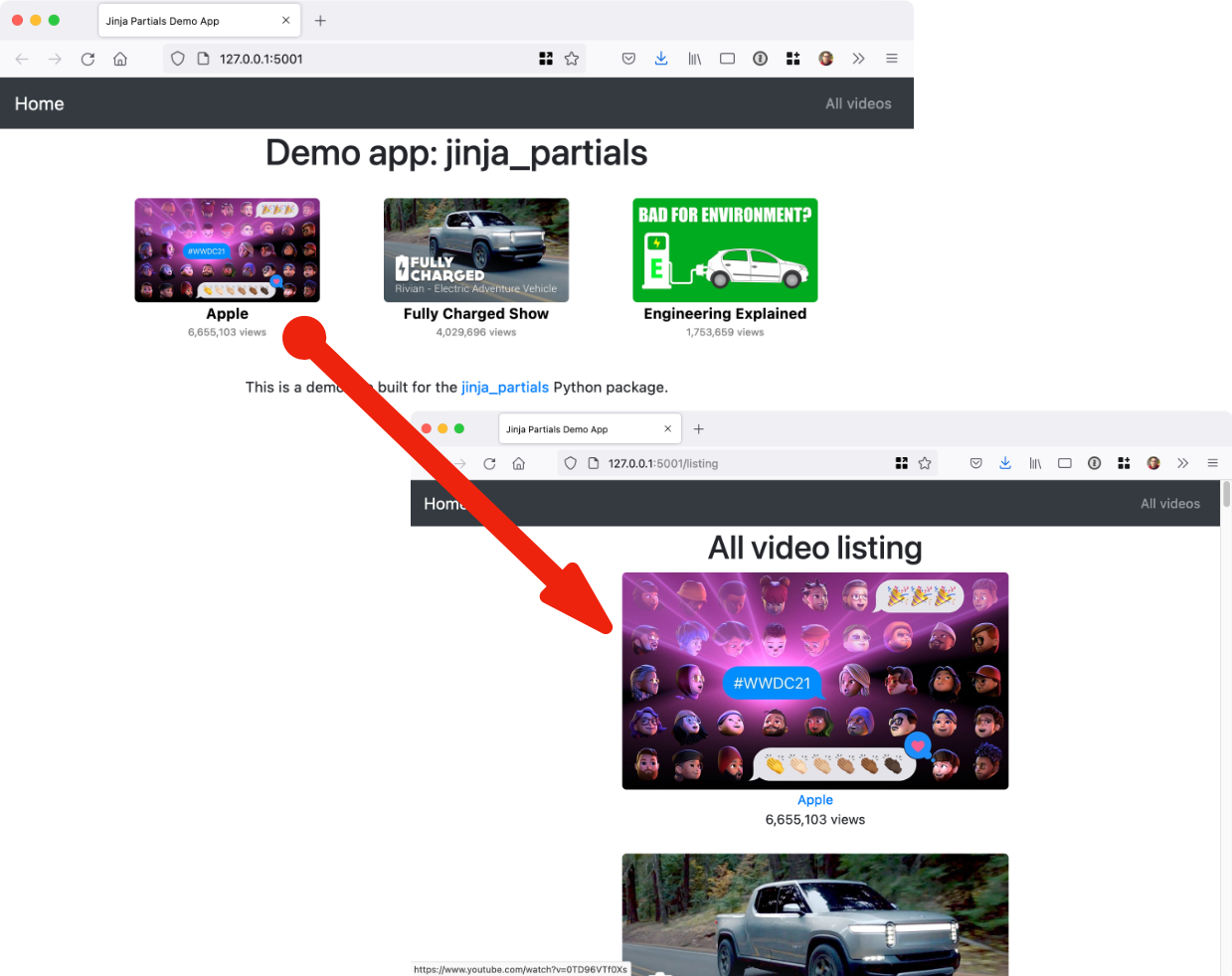
Simple reuse of partial HTML page templates in the Jinja template language for Python web frameworks.
Jinja Partials Simple reuse of partial HTML page templates in the Jinja template language for Python web frameworks. (There is also a Pyramid/Chameleo
 106 Dec 28, 2022
106 Dec 28, 2022

Synthetic LiDAR sequential point cloud dataset with point-wise annotations
SynLiDAR dataset: Learning From Synthetic LiDAR Sequential Point Cloud This is official repository of the SynLiDAR dataset. For technical details, ple
 78 Dec 27, 2022
78 Dec 27, 2022

T2F: text to face generation using Deep Learning
⭐ [NEW] ⭐ T2F - 2.0 Teaser (coming soon ...) Please note that all the faces in the above samples are generated ones. The T2F 2.0 will be using MSG-GAN
 533 Dec 22, 2022
533 Dec 22, 2022
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks (SDPoint) This repository contains the cod
 17 Jul 4, 2022
17 Jul 4, 2022
Tooling for the Common Objects In 3D dataset.
CO3D: Common Objects In 3D This repository contains a set of tools for working with the Common Objects in 3D (CO3D) dataset. Download the dataset The
724 Jan 6, 2023
GPT-Code-Clippy (GPT-CC) is an open source version of GitHub Copilot, a language model
GPT-Code-Clippy (GPT-CC) is an open source version of GitHub Copilot, a language model -- based on GPT-3, called GPT-Codex -- that is fine-tuned on publicly available code from GitHub.
 2.3k Jan 1, 2023
2.3k Jan 1, 2023

Learned Token Pruning for Transformers
LTP: Learned Token Pruning for Transformers Check our paper for more details. Installation We follow the same installation procedure as the original H
 52 Dec 29, 2022
52 Dec 29, 2022
Moment-DETR code and QVHighlights dataset
Moment-DETR QVHighlights: Detecting Moments and Highlights in Videos via Natural Language Queries Jie Lei, Tamara L. Berg, Mohit Bansal For dataset de
 133 Dec 22, 2022
133 Dec 22, 2022
Deduplicating Training Data Makes Language Models Better
Deduplicating Training Data Makes Language Models Better This repository contains code to deduplicate language model datasets as descrbed in the paper
 431 Dec 27, 2022
431 Dec 27, 2022
[ICML 2021] Towards Understanding and Mitigating Social Biases in Language Models
Towards Understanding and Mitigating Social Biases in Language Models This repo contains code and data for evaluating and mitigating bias from generat
 42 Jan 3, 2023
42 Jan 3, 2023
Reference implementation of code generation projects from Facebook AI Research. General toolkit to apply machine learning to code, from dataset creation to model training and evaluation. Comes with pretrained models.
This repository is a toolkit to do machine learning for programming languages. It implements tokenization, dataset preprocessing, model training and m
408 Jan 1, 2023
QVHighlights: Detecting Moments and Highlights in Videos via Natural Language Queries
Moment-DETR QVHighlights: Detecting Moments and Highlights in Videos via Natural Language Queries Jie Lei, Tamara L. Berg, Mohit Bansal For dataset de
133 Dec 22, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
 48 Oct 11, 2022
48 Oct 11, 2022

Rubrix is a free and open-source tool for exploring and iterating on data for artificial intelligence projects.
Open-source tool for exploring, labeling, and monitoring data for AI projects
1.5k Jan 7, 2023

A simple python tool for explore your object detection dataset
A simple tool for explore your object detection dataset. The goal of this library is to provide simple and intuitive visualizations from your dataset and automatically find the best parameters for generating a specific grid of anchors that can fit you data characteristics
 142 Dec 25, 2022
142 Dec 25, 2022

An implementation of DeepMind's Relational Recurrent Neural Networks in PyTorch.
relational-rnn-pytorch An implementation of DeepMind's Relational Recurrent Neural Networks (Santoro et al. 2018) in PyTorch. Relational Memory Core (
 241 Nov 18, 2022
241 Nov 18, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022

The Noise Contrastive Estimation for softmax output written in Pytorch
An NCE implementation in pytorch About NCE Noise Contrastive Estimation (NCE) is an approximation method that is used to work around the huge computat
 287 Nov 25, 2022
287 Nov 25, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
77.2k Jan 3, 2023
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context This repository contains the code in both PyTorch and TensorFlow for our paper
 3.3k Dec 28, 2022
3.3k Dec 28, 2022

Implementation of character based convolutional neural network
Character Based CNN This repo contains a PyTorch implementation of a character-level convolutional neural network for text classification. The model a
 248 Nov 21, 2022
248 Nov 21, 2022
PyTorch original implementation of Cross-lingual Language Model Pretraining.
XLM NEW: Added XLM-R model. PyTorch original implementation of Cross-lingual Language Model Pretraining. Includes: Monolingual language model pretrain
2.7k Dec 27, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
Pyomo is an object-oriented algebraic modeling language in Python for structured optimization problems.
Pyomo is a Python-based open-source software package that supports a diverse set of optimization capabilities for formulating and analyzing optimization models. Pyomo can be used to define symbolic problems, create concrete problem instances, and solve these instances with standard solvers.
 1.4k Dec 28, 2022
1.4k Dec 28, 2022

Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
This is the official PyTorch implementation of the ALBEF paper [Blog]. This repository supports pre-training on custom datasets, as well as finetuning on VQA, SNLI-VE, NLVR2, Image-Text Retrieval on MSCOCO and Flickr30k, and visual grounding on RefCOCO+. Pre-trained and finetuned checkpoints are released.
 805 Jan 9, 2023
805 Jan 9, 2023

RoBERTa Marathi Language model trained from scratch during huggingface 🤗 x flax community week
RoBERTa base model for Marathi Language (मराठी भाषा) Pretrained model on Marathi language using a masked language modeling (MLM) objective. RoBERTa wa
 23 Oct 19, 2022
23 Oct 19, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
 203 Dec 20, 2022
203 Dec 20, 2022

Implementation of QuickDraw - an online game developed by Google, combined with AirGesture - a simple gesture recognition application
QuickDraw - AirGesture Introduction Here is my python source code for QuickDraw - an online game developed by google, combined with AirGesture - a sim
 89 Dec 18, 2022
89 Dec 18, 2022