2224 Repositories
Python language-generation-dataset Libraries
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Jan 5, 2023
1.3k Jan 5, 2023
A Dataset of Python Challenges for AI Research
Python Programming Puzzles (P3) This repo contains a dataset of python programming puzzles which can be used to teach and evaluate an AI's programming
 850 Dec 24, 2022
850 Dec 24, 2022

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
 140 Dec 21, 2022
140 Dec 21, 2022

Aerial Imagery dataset for fire detection: classification and segmentation (Unmanned Aerial Vehicle (UAV))
Aerial Imagery dataset for fire detection: classification and segmentation using Unmanned Aerial Vehicle (UAV) Title FLAME (Fire Luminosity Airborne-b
 79 Jan 6, 2023
79 Jan 6, 2023

CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation
CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation (CVPR 2021, oral presentation) CoCosNet v2: Full-Resolution Correspondence
308 Dec 7, 2022

COVID-19 deaths statistics around the world
COVID-19-Deaths-Dataset COVID-19 deaths statistics around the world This is a daily updated dataset of COVID-19 deaths around the world. The dataset c
 4 Jul 10, 2022
4 Jul 10, 2022
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022
Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning".
ERICA Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive L
 75 Nov 2, 2022
75 Nov 2, 2022
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 6, 2023
Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. This Neural Network (NN) model recognizes the text contained in the images of segmented words.
Handwritten-Text-Recognition Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. T
 27 Jan 8, 2023
27 Jan 8, 2023

Pytorch implementation of MaskFlownet
MaskFlownet-Pytorch Unofficial PyTorch implementation of MaskFlownet (https://github.com/microsoft/MaskFlownet). Tested with: PyTorch 1.5.0 CUDA 10.1
 84 Nov 2, 2022
84 Nov 2, 2022

PyTorch implementation of Pay Attention to MLPs
gMLP PyTorch implementation of Pay Attention to MLPs. Quickstart Clone this repository. git clone https://github.com/jaketae/g-mlp.git Navigate to th
 34 Dec 13, 2022
34 Dec 13, 2022
![[CVPR 2021] Monocular depth estimation using wavelets for efficiency](https://github.com/nianticlabs/wavelet-monodepth/raw/main/assets/combo_kitti.gif)
[CVPR 2021] Monocular depth estimation using wavelets for efficiency
Single Image Depth Prediction with Wavelet Decomposition Michaël Ramamonjisoa, Michael Firman, Jamie Watson, Vincent Lepetit and Daniyar Turmukhambeto
 205 Jan 2, 2023
205 Jan 2, 2023
![[ICML 2021, Long Talk] Delving into Deep Imbalanced Regression](https://github.com/YyzHarry/imbalanced-regression/raw/main/teaser/overview.gif)
[ICML 2021, Long Talk] Delving into Deep Imbalanced Regression
Delving into Deep Imbalanced Regression This repository contains the implementation code for paper: Delving into Deep Imbalanced Regression Yuzhe Yang
 568 Dec 30, 2022
568 Dec 30, 2022
Ecommerce product title recognition package
revizor This package solves task of splitting product title string into components, like type, brand, model and article (or SKU or product code or you
 16 Mar 3, 2022
16 Mar 3, 2022

An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C.
vizh An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C. Overview Her
 228 Dec 17, 2022
228 Dec 17, 2022
To automate the generation and validation tests of COSE/CBOR Codes and it's base45/2D Code representations
To automate the generation and validation tests of COSE/CBOR Codes and it's base45/2D Code representations, a lot of data has to be collected to ensure the variance of the tests. This respository was established to collect a lot of different test data and related test cases of different member states in a standardized manner. Each member state can generate a folder in this section.
 160 Jul 25, 2022
160 Jul 25, 2022
A simple programming language for manipulating images.
f-stop A simple programming language for manipulating images. Examples OPEN "image.png" AS image RESIZE image (300, 300) SAVE image "out.jpg" CLOSE im
 6 Oct 27, 2022
6 Oct 27, 2022
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022
sawa (ꦱꦮ) is an open source programming language, an interpreter to be precise, where you can write python code using javanese character.
ꦱꦮ sawa (ꦱꦮ) is an open source programming language, an interpreter to be precise, where you can write python code using javanese character. sawa iku
 307 Jan 7, 2023
307 Jan 7, 2023

Kestrel Threat Hunting Language
Kestrel Threat Hunting Language What is Kestrel? Why we need it? How to hunt with XDR support? What is the science behind it? You can find all the ans
 201 Dec 16, 2022
201 Dec 16, 2022

Codes for ACL-IJCNLP 2021 Paper "Zero-shot Fact Verification by Claim Generation"
Zero-shot-Fact-Verification-by-Claim-Generation This repository contains code and models for the paper: Zero-shot Fact Verification by Claim Generatio
 47 Jan 1, 2023
47 Jan 1, 2023

A framework for detecting, highlighting and correcting grammatical errors on natural language text.
Gramformer Human and machine generated text often suffer from grammatical and/or typographical errors. It can be spelling, punctuation, grammatical or
 1.3k Jan 8, 2023
1.3k Jan 8, 2023

Fine-Tune EleutherAI GPT-Neo to Generate Netflix Movie Descriptions in Only 47 Lines of Code Using Hugginface And DeepSpeed
GPT-Neo-2.7B Fine-Tuning Example Using HuggingFace & DeepSpeed Installation cd venv/bin ./pip install -r ../../requirements.txt ./pip install deepspe
 180 Jan 5, 2023
180 Jan 5, 2023
Protein Language Model
ProteinLM We pretrain protein language model based on Megatron-LM framework, and then evaluate the pretrained model results on TAPE (Tasks Assessing P
77 Dec 27, 2022

The toolkit to generate auto labeled datasets
Ozeu Ozeu is the toolkit to autolabal dataset for instance segmentation. You can generate datasets labaled with segmentation mask and bounding box fro
 28 Mar 28, 2022
28 Mar 28, 2022
PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World [ACL 2021]
piglet PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World [ACL 2021] This repo contains code and data for PIGLeT. If you like
 51 Oct 8, 2022
51 Oct 8, 2022
HatSploit native powerful payload generation and shellcode injection tool that provides support for common platforms and architectures.
HatVenom HatSploit native powerful payload generation and shellcode injection tool that provides support for common platforms and architectures. Featu
 100 Dec 23, 2022
100 Dec 23, 2022
Pynguin, The PYthoN General UnIt Test geNerator is a test-generation tool for Python
Pynguin, the PYthoN General UnIt test geNerator, is a tool that allows developers to generate unit tests automatically.
 997 Jan 6, 2023
997 Jan 6, 2023
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions (CVPR2021)
NExT-QA We reproduce some SOTA VideoQA methods to provide benchmark results for our NExT-QA dataset accepted to CVPR2021 (with 1 'Strong Accept' and 2
 50 Nov 24, 2022
50 Nov 24, 2022

Official repository for "Action-Based Conversations Dataset: A Corpus for Building More In-Depth Task-Oriented Dialogue Systems"
Action-Based Conversations Dataset (ABCD) This respository contains the code and data for ABCD (Chen et al., 2021) Introduction Whereas existing goal-
 49 Oct 9, 2022
49 Oct 9, 2022

This project provides an unsupervised framework for mining and tagging quality phrases on text corpora with pretrained language models (KDD'21).
UCPhrase: Unsupervised Context-aware Quality Phrase Tagging To appear on KDD'21...[pdf] This project provides an unsupervised framework for mining and
 146 Dec 22, 2022
146 Dec 22, 2022

(AAAI2020)Grapy-ML: Graph Pyramid Mutual Learning for Cross-dataset Human Parsing
Grapy-ML: Graph Pyramid Mutual Learning for Cross-dataset Human Parsing This repository contains pytorch source code for AAAI2020 oral paper: Grapy-ML
 54 Aug 4, 2022
54 Aug 4, 2022

BoobSnail allows generating Excel 4.0 XLM macro. Its purpose is to support the RedTeam and BlueTeam in XLM macro generation.
Follow us on Twitter! BoobSnail BoobSnail allows generating XLM (Excel 4.0) macro. Its purpose is to support the RedTeam and BlueTeam in XLM macro gen
 232 Nov 21, 2022
232 Nov 21, 2022
Rick Astley Language is a rick roll oriented, dynamic, strong, esoteric programming language.
Rick Roll Language / Rick Astley Language A rick roll oriented, dynamic, strong, esoteric programming language. Prolegomenon The reasons that I made t
 658 Jan 9, 2023
658 Jan 9, 2023
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset.
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset. Through its Python API, the pretrained model can be fine-tuned on any protein-related task in a matter of minutes. Based on our experiments with a wide range of benchmarks, ProteinBERT usually achieves state-of-the-art performance. ProteinBERT is built on TenforFlow/Keras.
 241 Jan 4, 2023
241 Jan 4, 2023

Efficient 6-DoF Grasp Generation in Cluttered Scenes
Contact-GraspNet Contact-GraspNet: Efficient 6-DoF Grasp Generation in Cluttered Scenes Martin Sundermeyer, Arsalan Mousavian, Rudolph Triebel, Dieter
 148 Dec 28, 2022
148 Dec 28, 2022

Repo for the Video Person Clustering dataset, and code for the associated paper
Video Person Clustering Repo for the Video Person Clustering dataset, and code for the associated paper. This reporsitory contains the Video Person Cl
 47 Nov 2, 2022
47 Nov 2, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 248 Dec 4, 2022
248 Dec 4, 2022
True Few-Shot Learning with Language Models
This codebase supports using language models (LMs) for true few-shot learning: learning to perform a task using a limited number of examples from a single task distribution.
 124 Jan 4, 2023
124 Jan 4, 2023
VMD Audio/Text control with natural language
This repository is a proof of principle for performing Molecular Dynamics analysis, in this case with the program VMD, via natural language commands.
 13 Jun 9, 2022
13 Jun 9, 2022
Code for the paper "Adapting Monolingual Models: Data can be Scarce when Language Similarity is High"
Wietse de Vries • Martijn Bartelds • Malvina Nissim • Martijn Wieling Adapting Monolingual Models: Data can be Scarce when Language Similarity is High
 5 Aug 2, 2021
5 Aug 2, 2021
Extract MNIST handwritten digits dataset binary file into bmp images
MNIST-dataset-extractor Extract MNIST handwritten digits dataset binary file into bmp images More info at http://yann.lecun.com/exdb/mnist/ Dependenci
 6 May 24, 2021
6 May 24, 2021
TikTok X-Gorgon & X-Khronos Generation Algorithm
TikTok X-Gorgon & X-Khronos Generation Algorithm X-Gorgon and X-Khronos headers are required to call tiktok api. I will provide you API as rental or s
 31 Dec 1, 2022
31 Dec 1, 2022

When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holdings
When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holdings This is the repository for t
 39 Jan 7, 2023
39 Jan 7, 2023
![[CVPR'21 Oral] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning](https://github.com/researchmm/soho/raw/master/resources/soho.png)
[CVPR'21 Oral] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning [CVPR'21, Oral] By Zhicheng Huang*, Zhaoyang Zeng*, Yupan H
 196 Dec 13, 2022
196 Dec 13, 2022
A GPT, made only of MLPs, in Jax
MLP GPT - Jax (wip) A GPT, made only of MLPs, in Jax. The specific MLP to be used are gMLPs with the Spatial Gating Units. Working Pytorch implementat
 53 Sep 27, 2022
53 Sep 27, 2022

A public available dataset for road boundary detection in aerial images
Topo-boundary This is the official github repo of paper Topo-boundary: A Benchmark Dataset on Topological Road-boundary Detection Using Aerial Images
 79 Jan 4, 2023
79 Jan 4, 2023

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022

This project demonstrates the use of neural networks and computer vision to create a classifier that interprets the Brazilian Sign Language.
LIBRAS-Image-Classifier This project demonstrates the use of neural networks and computer vision to create a classifier that interprets the Brazilian
 26 Oct 14, 2022
26 Oct 14, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 44 Jan 6, 2023
44 Jan 6, 2023

Official Implementation and Dataset of "PPR10K: A Large-Scale Portrait Photo Retouching Dataset with Human-Region Mask and Group-Level Consistency", CVPR 2021
Portrait Photo Retouching with PPR10K Paper | Supplementary Material PPR10K: A Large-Scale Portrait Photo Retouching Dataset with Human-Region Mask an
 184 Dec 11, 2022
184 Dec 11, 2022
Few-NERD: Not Only a Few-shot NER Dataset
Few-NERD: Not Only a Few-shot NER Dataset This is the source code of the ACL-IJCNLP 2021 paper: Few-NERD: A Few-shot Named Entity Recognition Dataset.
319 Dec 30, 2022

Text to Image Generation with Semantic-Spatial Aware GAN
text2image This repository includes the implementation for Text to Image Generation with Semantic-Spatial Aware GAN This repo is not completely. Netwo
 124 Dec 30, 2022
124 Dec 30, 2022
Code for paper "Document-Level Argument Extraction by Conditional Generation". NAACL 21'
Argument Extraction by Generation Code for paper "Document-Level Argument Extraction by Conditional Generation". NAACL 21' Dependencies pytorch=1.6 tr
 87 Dec 26, 2022
87 Dec 26, 2022
Train 🤗transformers with DeepSpeed: ZeRO-2, ZeRO-3
Fork from https://github.com/huggingface/transformers/tree/86d5fb0b360e68de46d40265e7c707fe68c8015b/examples/pytorch/language-modeling at 2021.05.17.
 12 Oct 26, 2022
12 Oct 26, 2022
Application that instantly translates sign-language to letters.
Sign Language Translator Project Description The main purpose of project is translating sign-language to letters. In accordance with this purpose we d
 3 Sep 29, 2022
3 Sep 29, 2022
Language models are open knowledge graphs ( non official implementation )
language-models-are-knowledge-graphs-pytorch Language models are open knowledge graphs ( work in progress ) A non official reimplementation of Languag
 132 Dec 18, 2022
132 Dec 18, 2022
Show Data: Show your dataset in web browser!
Show Data is to generate html tables for large scale image dataset, especially for the dataset in remote server. It provides some useful commond line tools and fully customizeble API reference to generate html table different tasks.
 83 Nov 26, 2022
83 Nov 26, 2022
Python for .NET is a package that gives Python programmers nearly seamless integration with the .NET Common Language Runtime (CLR) and provides a powerful application scripting tool for .NET developers.
pythonnet - Python.NET Python.NET is a package that gives Python programmers nearly seamless integration with the .NET Common Language Runtime (CLR) a
 3.5k Jan 6, 2023
3.5k Jan 6, 2023
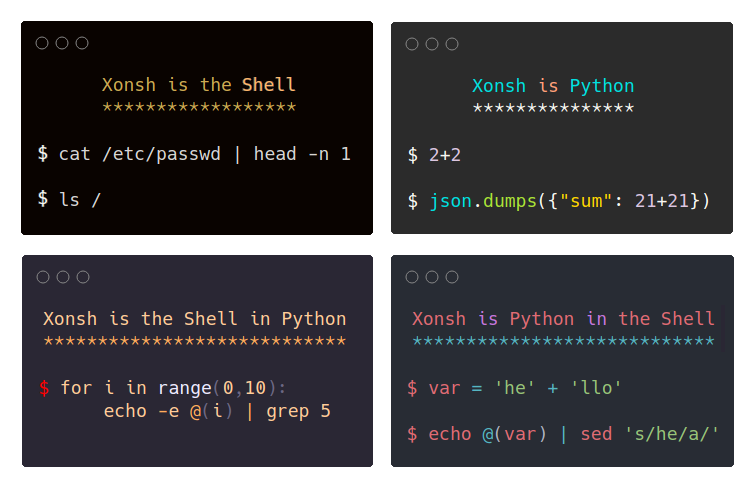
xonsh is a Python-powered, cross-platform, Unix-gazing shell language and command prompt.
xonsh xonsh is a Python-powered, cross-platform, Unix-gazing shell language and command prompt. The language is a superset of Python 3.6+ with additio
 6.7k Jan 8, 2023
6.7k Jan 8, 2023

Unofficial implementation of Google's FNet: Mixing Tokens with Fourier Transforms
FNet: Mixing Tokens with Fourier Transforms Pytorch implementation of Fnet : Mixing Tokens with Fourier Transforms. Citation: @misc{leethorp2021fnet,
 218 Jan 5, 2023
218 Jan 5, 2023
![[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.](https://github.com/cambridgeltl/sapbert/raw/main/sapbert_front_graphs_v6.png?raw=true)
[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.
SapBERT: Self-alignment pretraining for BERT This repo holds code for the SapBERT model presented in our NAACL 2021 paper: Self-Alignment Pretraining
 104 Dec 7, 2022
104 Dec 7, 2022

Ever felt tired after preprocessing the dataset, and not wanting to write any code further to train your model? Ever encountered a situation where you wanted to record the hyperparameters of the trained model and able to retrieve it afterward? Models Playground is here to help you do that. Models playground allows you to train your models right from the browser.
Models Playground 🗂️ Upload a Preprocessed Dataset 🌠 Choose whether to perform Classification or Regression 🦹 Enter the Dependent Variable ?
 19 Dec 10, 2022
19 Dec 10, 2022
A framework for cleaning Chinese dialog data
A framework for cleaning Chinese dialog data
 136 Dec 20, 2022
136 Dec 20, 2022
Multi-Track Music Generation with the Transfomer and the Johann Sebastian Bach Chorales dataset
MMM: Exploring Conditional Multi-Track Music Generation with the Transformer and the Johann Sebastian Bach Chorales Dataset. Implementation of the pap
 102 Dec 8, 2022
102 Dec 8, 2022

FactSumm: Factual Consistency Scorer for Abstractive Summarization
FactSumm: Factual Consistency Scorer for Abstractive Summarization FactSumm is a toolkit that scores Factualy Consistency for Abstract Summarization W
 83 Jan 9, 2023
83 Jan 9, 2023
An unopinionated replacement for PyTorch's Dataset and ImageFolder, that handles Tar archives
Simple Tar Dataset An unopinionated replacement for PyTorch's Dataset and ImageFolder classes, for datasets stored as uncompressed Tar archives. Just
 47 Dec 20, 2022
47 Dec 20, 2022

Code for the ICML 2021 paper: "ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision"
ViLT Code for the paper: "ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision" Install pip install -r requirements.txt pip
 922 Jan 1, 2023
922 Jan 1, 2023
Lightning fast and portable programming language!
Photon Documentation in English Lightning fast and portable programming language! What is Photon? Photon is a programming language aimed at filling th
 58 Dec 27, 2022
58 Dec 27, 2022

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022

Code for "ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on", accepted at WACV 2021 Generation of Human Behavior Workshop.
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on [ Paper ] [ Project Page ] This repository contains the code fo
 97 Dec 13, 2022
97 Dec 13, 2022
Repository for XLM-T, a framework for evaluating multilingual language models on Twitter data
This is the XLM-T repository, which includes data, code and pre-trained multilingual language models for Twitter. XLM-T - A Multilingual Language Mode
 112 Dec 27, 2022
112 Dec 27, 2022

DeepFaceEditing: Deep Face Generation and Editing with Disentangled Geometry and Appearance Control
DeepFaceEditing: Deep Face Generation and Editing with Disentangled Geometry and Appearance Control One version of our system is implemented using the
 260 Nov 28, 2022
260 Nov 28, 2022
Official implementation of ETH-XGaze dataset baseline
ETH-XGaze baseline Official implementation of ETH-XGaze dataset baseline. ETH-XGaze dataset ETH-XGaze dataset is a gaze estimation dataset consisting
 134 Jan 3, 2023
134 Jan 3, 2023
Code for the ICML 2021 paper: "ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision"
ViLT Code for the paper: "ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision" Install pip install -r requirements.txt pip
922 Jan 1, 2023

The pytorch implementation of DG-Font: Deformable Generative Networks for Unsupervised Font Generation
DG-Font: Deformable Generative Networks for Unsupervised Font Generation The source code for 'DG-Font: Deformable Generative Networks for Unsupervised
 130 Dec 5, 2022
130 Dec 5, 2022
Word2Wave: a framework for generating short audio samples from a text prompt using WaveGAN and COALA.
Word2Wave is a simple method for text-controlled GAN audio generation. You can either follow the setup instructions below and use the source code and CLI provided in this repo or you can have a play around in the Colab notebook provided. Note that, in both cases, you will need to train a WaveGAN model first
 91 Dec 23, 2022
91 Dec 23, 2022

Parrot is a paraphrase based utterance augmentation framework purpose built to accelerate training NLU models
Parrot is a paraphrase based utterance augmentation framework purpose built to accelerate training NLU models. A paraphrase framework is more than just a paraphrasing model.
681 Jan 1, 2023
Integrating the Best of TF into PyTorch, for Machine Learning, Natural Language Processing, and Text Generation. This is part of the CASL project: http://casl-project.ai/
Texar-PyTorch is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar
 726 Dec 30, 2022
726 Dec 30, 2022
Google AI 2018 BERT pytorch implementation
BERT-pytorch Pytorch implementation of Google AI's 2018 BERT, with simple annotation BERT 2018 BERT: Pre-training of Deep Bidirectional Transformers f
 5.3k Jan 7, 2023
5.3k Jan 7, 2023
A modular framework for vision & language multimodal research from Facebook AI Research (FAIR)
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains reference implementations of state-of-t
 5.1k Dec 26, 2022
5.1k Dec 26, 2022
Language-Agnostic SEntence Representations
LASER Language-Agnostic SEntence Representations LASER is a library to calculate and use multilingual sentence embeddings. NEWS 2019/11/08 CCMatrix is
3.2k Jan 4, 2023
An implementation of WaveNet with fast generation
pytorch-wavenet This is an implementation of the WaveNet architecture, as described in the original paper. Features Automatic creation of a dataset (t
 858 Dec 27, 2022
858 Dec 27, 2022

Unsupervised Language Modeling at scale for robust sentiment classification
** DEPRECATED ** This repo has been deprecated. Please visit Megatron-LM for our up to date Large-scale unsupervised pretraining and finetuning code.
 1k Nov 17, 2022
1k Nov 17, 2022

A simple command line tool for text to image generation, using OpenAI's CLIP and a BigGAN.
Ryan Murdock has done it again, combining OpenAI's CLIP and the generator from a BigGAN! This repository wraps up his work so it is easily accessible to anyone who owns a GPU.
2.3k Jan 9, 2023
A large-scale dataset of both raw MRI measurements and clinical MRI images
fastMRI is a collaborative research project from Facebook AI Research (FAIR) and NYU Langone Health to investigate the use of AI to make MRI scans faster. NYU Langone Health has released fully anonymized knee and brain MRI datasets that can be downloaded from the fastMRI dataset page. Publications associated with the fastMRI project can be found at the end of this README.
907 Jan 4, 2023

This is the dataset for testing the robustness of various VO/VIO methods
KAIST VIO dataset This is the dataset for testing the robustness of various VO/VIO methods You can download the whole dataset on KAIST VIO dataset Ind
 1 Sep 1, 2022
1 Sep 1, 2022

DeepMetaHandles: Learning Deformation Meta-Handles of 3D Meshes with Biharmonic Coordinates
DeepMetaHandles (CVPR2021 Oral) [paper] [animations] DeepMetaHandles is a shape deformation technique. It learns a set of meta-handles for each given
 73 Dec 15, 2022
73 Dec 15, 2022
A Distributional Approach To Controlled Text Generation
A Distributional Approach To Controlled Text Generation This is the repository code for the ICLR 2021 paper "A Distributional Approach to Controlled T
 102 Jan 7, 2023
102 Jan 7, 2023
Text Generation by Learning from Demonstrations
Text Generation by Learning from Demonstrations The README was last updated on March 7, 2021. The repo is based on fairseq (v0.9.?). Paper arXiv Prere
 38 Oct 21, 2022
38 Oct 21, 2022
[EMNLP 2020] Keep CALM and Explore: Language Models for Action Generation in Text-based Games
Contextual Action Language Model (CALM) and the ClubFloyd Dataset Code and data for paper Keep CALM and Explore: Language Models for Action Generation
 43 Dec 16, 2022
43 Dec 16, 2022
Codes for our paper "SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge" (EMNLP 2020)
SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge Introduction SentiLARE is a sentiment-aware pre-trained language
 74 Dec 30, 2022
74 Dec 30, 2022
Meta Language-Specific Layers in Multilingual Language Models
Meta Language-Specific Layers in Multilingual Language Models This repo contains the source codes for our paper On Negative Interference in Multilingu
 20 Feb 13, 2022
20 Feb 13, 2022
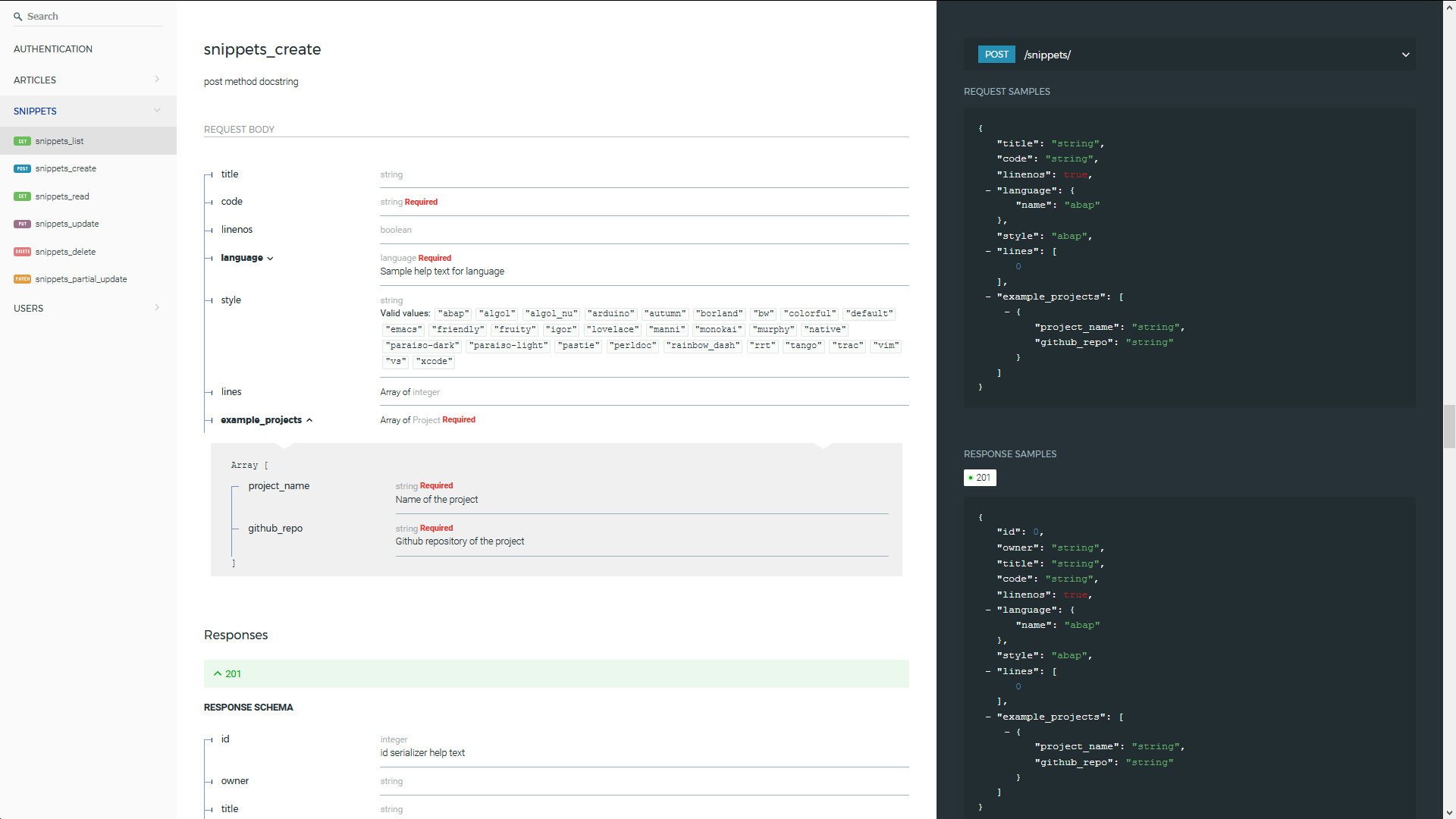
Automated generation of real Swagger/OpenAPI 2.0 schemas from Django REST Framework code.
drf-yasg - Yet another Swagger generator Generate real Swagger/OpenAPI 2.0 specifications from a Django Rest Framework API. Compatible with Django Res
 3k Jan 6, 2023
3k Jan 6, 2023

Django queries
Djaq Djaq - pronounced “Jack” - provides an instant remote API to your Django models data with a powerful query language. No server-side code beyond t
 53 Dec 12, 2022
53 Dec 12, 2022
LightSeq: A High-Performance Inference Library for Sequence Processing and Generation
LightSeq is a high performance inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT2, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, and other related tasks using these models.
 2.5k Jan 3, 2023
2.5k Jan 3, 2023
Pytorch implementation of CoCon: A Self-Supervised Approach for Controlled Text Generation
COCON_ICLR2021 This is our Pytorch implementation of COCON. CoCon: A Self-Supervised Approach for Controlled Text Generation (ICLR 2021) Alvin Chan, Y
 79 Dec 18, 2022
79 Dec 18, 2022
One Stop Anomaly Shop: Anomaly detection using two-phase approach: (a) pre-labeling using statistics, Natural Language Processing and static rules; (b) anomaly scoring using supervised and unsupervised machine learning.
One Stop Anomaly Shop (OSAS) Quick start guide Step 1: Get/build the docker image Option 1: Use precompiled image (might not reflect latest changes):
 148 Dec 26, 2022
148 Dec 26, 2022

TorchFlare is a simple, beginner-friendly, and easy-to-use PyTorch Framework train your models effortlessly.
TorchFlare TorchFlare is a simple, beginner-friendly and an easy-to-use PyTorch Framework train your models without much effort. It provides an almost
 85 Dec 26, 2022
85 Dec 26, 2022