2128 Repositories
Python language-models Libraries

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
The source codes for ACL 2021 paper 'BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data'
BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data This repository provides the implementation details for
 124 Dec 27, 2022
124 Dec 27, 2022
PyTorch impelementations of BERT-based Spelling Error Correction Models
PyTorch impelementations of BERT-based Spelling Error Correction Models
 59 Jun 29, 2021
59 Jun 29, 2021
PyTorch impelementations of BERT-based Spelling Error Correction Models.
PyTorch impelementations of BERT-based Spelling Error Correction Models. 基于BERT的文本纠错模型,使用PyTorch实现。
209 Dec 30, 2022
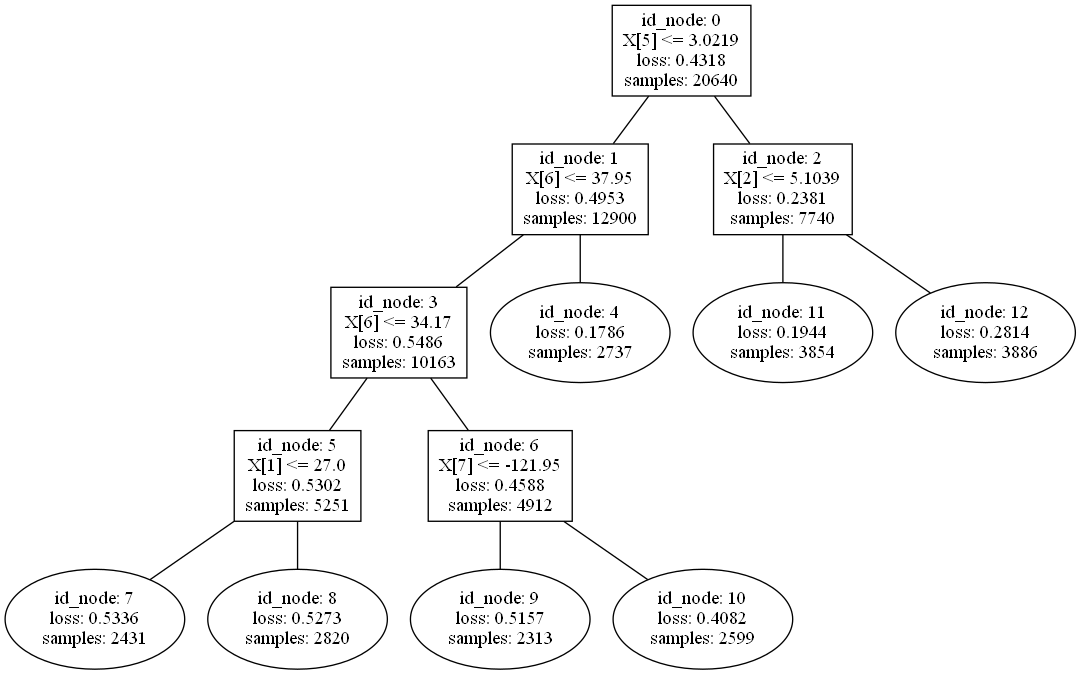
A python library to build Model Trees with Linear Models at the leaves.
A python library to build Model Trees with Linear Models at the leaves.
 212 Dec 30, 2022
212 Dec 30, 2022
Deep Learning Models for Causal Inference
Extensive tutorials for learning how to build deep learning models for causal inference using selection on observables in Tensorflow 2.
 151 Dec 31, 2022
151 Dec 31, 2022
ToR[e]cSys is a PyTorch Framework to implement recommendation system algorithms
ToR[e]cSys is a PyTorch Framework to implement recommendation system algorithms, including but not limited to click-through-rate (CTR) prediction, learning-to-ranking (LTR), and Matrix/Tensor Embedding. The project objective is to develop a ecosystem to experiment, share, reproduce, and deploy in real world in a smooth and easy way (Hope it can be done).
 90 Oct 8, 2022
90 Oct 8, 2022

Find a Doc is a free online resource aimed at helping connect the foreign community in Japan with health services in their native language.
Find a Doc - Localization Find a Doc is a free online resource aimed at helping connect the foreign community in Japan with health services in their n
 18 Dec 19, 2022
18 Dec 19, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
 189 Jan 2, 2023
189 Jan 2, 2023

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022

30 Days Of Machine Learning Using Pytorch
Objective of the repository is to learn and build machine learning models using Pytorch. 30DaysofML Using Pytorch
 119 Nov 24, 2022
119 Nov 24, 2022
Pretrained SOTA Deep Learning models, callbacks and more for research and production with PyTorch Lightning and PyTorch
Pretrained SOTA Deep Learning models, callbacks and more for research and production with PyTorch Lightning and PyTorch
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

Framework that uses artificial intelligence applied to mathematical models to make predictions
LiconIA Framework that uses artificial intelligence applied to mathematical models to make predictions Interface Overview Table of contents [TOC] 1 Ar
 4 Jun 20, 2021
4 Jun 20, 2021

BRepNet: A topological message passing system for solid models
BRepNet: A topological message passing system for solid models This repository contains the an implementation of BRepNet: A topological message passin
 42 Dec 30, 2022
42 Dec 30, 2022
This is the repo for our work "Towards Persona-Based Empathetic Conversational Models" (EMNLP 2020)
Towards Persona-Based Empathetic Conversational Models (PEC) This is the repo for our work "Towards Persona-Based Empathetic Conversational Models" (E
 35 Nov 17, 2022
35 Nov 17, 2022
Code to train models from "Paraphrastic Representations at Scale".
Paraphrastic Representations at Scale Code to train models from "Paraphrastic Representations at Scale". The code is written in Python 3.7 and require
 71 Dec 19, 2022
71 Dec 19, 2022
CausaLM: Causal Model Explanation Through Counterfactual Language Models
CausaLM: Causal Model Explanation Through Counterfactual Language Models Authors: Amir Feder, Nadav Oved, Uri Shalit, Roi Reichart Abstract: Understan
 39 Jul 10, 2022
39 Jul 10, 2022
CVPR 2021 Official Pytorch Code for UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training
UC2 UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training Mingyang Zhou, Luowei Zhou, Shuohang Wang, Yu Cheng, Linjie Li, Zhou Yu,
 28 Dec 30, 2022
28 Dec 30, 2022

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022

Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models
Patch-Rotation(PatchRot) Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models Submitted to Neurips2021 To
 4 Jul 12, 2021
4 Jul 12, 2021
Machine Learning Model to predict the payment date of an invoice when it gets created in the system.
Payment-Date-Prediction Machine Learning Model to predict the payment date of an invoice when it gets created in the system.
 15 Sep 9, 2022
15 Sep 9, 2022
darts is a Python library for easy manipulation and forecasting of time series.
A python library for easy manipulation and forecasting of time series.
 5.2k Jan 1, 2023
5.2k Jan 1, 2023
Deep Learning for Natural Language Processing - Lectures 2021
This repository contains slides for the course "20-00-0947: Deep Learning for Natural Language Processing" (Technical University of Darmstadt, Summer term 2021).
 0 Feb 21, 2022
0 Feb 21, 2022

A collection of Classical Chinese natural language processing models, including Classical Chinese related models and resources on the Internet.
GuwenModels: 古文自然语言处理模型合集, 收录互联网上的古文相关模型及资源. A collection of Classical Chinese natural language processing models, including Classical Chinese related models and resources on the Internet.
 66 Dec 26, 2022
66 Dec 26, 2022
51AC8 is a stack based golfing / esolang that I am trying to make.
51AC8 is a stack based golfing / esolang that I am trying to make.
 7 May 22, 2022
7 May 22, 2022

Unofficial PyTorch implementation of Neural Additive Models (NAM) by Agarwal, et al.
nam-pytorch Unofficial PyTorch implementation of Neural Additive Models (NAM) by Agarwal, et al. [abs, pdf] Installation You can access nam-pytorch vi
 11 Mar 14, 2022
11 Mar 14, 2022

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022

Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition The official code of ABINet (CVPR 2021, Oral).
 334 Dec 31, 2022
334 Dec 31, 2022

UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus
UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus General info This is
 71 Oct 25, 2022
71 Oct 25, 2022
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022
Using pretrained language models for biomedical knowledge graph completion.
LMs for biomedical KG completion This repository contains code to run the experiments described in: Scientific Language Models for Biomedical Knowledg
 41 Nov 30, 2022
41 Nov 30, 2022

PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer
Official code Cross-Covariance Image Transformer (XCiT)
 605 Jan 2, 2023
605 Jan 2, 2023

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022

We envision models that are pre-trained on a vast range of domain-relevant tasks to become key for molecule property prediction
We envision models that are pre-trained on a vast range of domain-relevant tasks to become key for molecule property prediction. This repository aims to give easy access to state-of-the-art pre-trained models.
 90 Jan 8, 2023
90 Jan 8, 2023

This repository contains all the source code that is needed for the project : An Efficient Pipeline For Bloom’s Taxonomy Using Natural Language Processing and Deep Learning
Pipeline For NLP with Bloom's Taxonomy Using Improved Question Classification and Question Generation using Deep Learning This repository contains all
 9 Jul 17, 2021
9 Jul 17, 2021
PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer
Cross-Covariance Image Transformer (XCiT) PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer L
605 Jan 2, 2023

Official Pytorch implementation of paper "Reverse Engineering of Generative Models: Inferring Model Hyperparameters from Generated Images"
Reverse_Engineering_GMs Official Pytorch implementation of paper "Reverse Engineering of Generative Models: Inferring Model Hyperparameters from Gener
 100 Dec 18, 2022
100 Dec 18, 2022
NL-Augmenter 🦎 → 🐍 A Collaborative Repository of Natural Language Transformations
NL-Augmenter 🦎 → 🐍 The NL-Augmenter is a collaborative effort intended to add transformations of datasets dealing with natural language. Transformat
 684 Jan 9, 2023
684 Jan 9, 2023

Code for "LoRA: Low-Rank Adaptation of Large Language Models"
LoRA: Low-Rank Adaptation of Large Language Models This repo contains the implementation of LoRA in GPT-2 and steps to replicate the results in our re
 394 Jan 8, 2023
394 Jan 8, 2023
A Regex based linter tool that works for any language and works exclusively with custom linting rules.
renag Documentation Available Here Short for Regex (re) Nag (like "one who complains"). Now also PEGs (Parsing Expression Grammars) compatible with py
 12 Oct 20, 2022
12 Oct 20, 2022

Official PyTorch implementation and pretrained models of the paper Self-Supervised Classification Network
Self-Classifier: Self-Supervised Classification Network Official PyTorch implementation and pretrained models of the paper Self-Supervised Classificat
 24 Dec 21, 2022
24 Dec 21, 2022

A task-agnostic vision-language architecture as a step towards General Purpose Vision
Towards General Purpose Vision Systems By Tanmay Gupta, Amita Kamath, Aniruddha Kembhavi, and Derek Hoiem Overview Welcome to the official code base f
 79 Dec 23, 2022
79 Dec 23, 2022
The official implementation for ACL 2021 "Challenges in Information Seeking QA: Unanswerable Questions and Paragraph Retrieval".
Code for "Challenges in Information Seeking QA: Unanswerable Questions and Paragraph Retrieval" (ACL 2021, Long) This is the repository for baseline m
 25 Oct 30, 2022
25 Oct 30, 2022
✨ Udemy Coupon Finder For Discord. Supports Turkish & English Language.
Udemy Course Finder Bot | Udemy Kupon Bulucu Botu This bot finds new udemy coupons and sends to the channel. Before Setup You must have python = 3.6
 4 May 4, 2022
4 May 4, 2022

This project is based on RIFE and aims to make RIFE more practical for users by adding various features and design new models
This project is based on RIFE and aims to make RIFE more practical for users by adding various features and design new models. Because improving the PSNR index is not compatible with subjective effects, we hope this part of work and our academic research are independent of each other.
 190 Jan 8, 2023
190 Jan 8, 2023
2021海华AI挑战赛·中文阅读理解·技术组·第三名
文字是人类用以记录和表达的最基本工具,也是信息传播的重要媒介。透过文字与符号,我们可以追寻人类文明的起源,可以传播知识与经验,读懂文字是认识与了解的第一步。对于人工智能而言,它的核心问题之一就是认知,而认知的核心则是语义理解。
 21 Dec 26, 2022
21 Dec 26, 2022
Code for our paper "Transfer Learning for Sequence Generation: from Single-source to Multi-source" in ACL 2021.
TRICE: a task-agnostic transferring framework for multi-source sequence generation This is the source code of our work Transfer Learning for Sequence
 9 Jun 27, 2022
9 Jun 27, 2022

The codes and models in 'Gaze Estimation using Transformer'.
GazeTR We provide the code of GazeTR-Hybrid in "Gaze Estimation using Transformer". We recommend you to use data processing codes provided in GazeHub.
 65 Dec 27, 2022
65 Dec 27, 2022

A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/casual, active/passive, and many more. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Styleformer A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/cas
 431 Dec 19, 2022
431 Dec 19, 2022
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
192 Dec 23, 2022
Repository for publicly available deep learning models developed in Rosetta community
trRosetta2 This package contains deep learning models and related scripts used by Baker group in CASP14. Installation Linux/Mac clone the package git
 81 Dec 29, 2022
81 Dec 29, 2022
A Python package for the mathematical modeling of infectious diseases via compartmental models
A Python package for the mathematical modeling of infectious diseases via compartmental models. Originally designed for epidemiologists, epispot can be adapted for almost any type of modeling scenario.
 12 Dec 28, 2022
12 Dec 28, 2022
![[CVPR 2021] Teachers Do More Than Teach: Compressing Image-to-Image Models (CAT)](https://github.com/snap-research/CAT/raw/main/images/comparison.png)
[CVPR 2021] Teachers Do More Than Teach: Compressing Image-to-Image Models (CAT)
CAT arXiv Pytorch implementation of our method for compressing image-to-image models. Teachers Do More Than Teach: Compressing Image-to-Image Models Q
 160 Dec 9, 2022
160 Dec 9, 2022
MERLOT: Multimodal Neural Script Knowledge Models
merlot MERLOT: Multimodal Neural Script Knowledge Models MERLOT is a model for learning what we are calling "neural script knowledge" -- representatio
 190 Dec 22, 2022
190 Dec 22, 2022

Code implementation of "Sparsity Probe: Analysis tool for Deep Learning Models"
Sparsity Probe: Analysis tool for Deep Learning Models This repository is a limited implementation of Sparsity Probe: Analysis tool for Deep Learning
 3 Jun 9, 2021
3 Jun 9, 2021
Official PyTorch implementation for FastDPM, a fast sampling algorithm for diffusion probabilistic models
Official PyTorch implementation for "On Fast Sampling of Diffusion Probabilistic Models". FastDPM generation on CIFAR-10, CelebA, and LSUN datasets. S
 68 Dec 26, 2022
68 Dec 26, 2022
Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning".
ERICA Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive L
 75 Nov 2, 2022
75 Nov 2, 2022
Python API for working with RESQML models
resqpy: Python API for working with RESQML models Introduction resqpy is a pure python package which provides a programming interface (API) for readin
 44 Dec 14, 2022
44 Dec 14, 2022
A framework for analyzing computer vision models with simulated data
3DB: A framework for analyzing computer vision models with simulated data Paper Quickstart guide Blog post Installation Follow instructions on: https:
 112 Jan 1, 2023
112 Jan 1, 2023
This code reproduces the results of the paper, "Measuring Data Leakage in Machine-Learning Models with Fisher Information"
Fisher Information Loss This repository contains code that can be used to reproduce the experimental results presented in the paper: Awni Hannun, Chua
43 Dec 30, 2022

PyTorch implementation of Pay Attention to MLPs
gMLP PyTorch implementation of Pay Attention to MLPs. Quickstart Clone this repository. git clone https://github.com/jaketae/g-mlp.git Navigate to th
 34 Dec 13, 2022
34 Dec 13, 2022
Adversarial Attacks on Probabilistic Autoregressive Forecasting Models.
Attack-Probabilistic-Models This is the source code for Adversarial Attacks on Probabilistic Autoregressive Forecasting Models. This repository contai
 25 Sep 14, 2022
25 Sep 14, 2022
![[ICML 2021, Long Talk] Delving into Deep Imbalanced Regression](https://github.com/YyzHarry/imbalanced-regression/raw/main/teaser/overview.gif)
[ICML 2021, Long Talk] Delving into Deep Imbalanced Regression
Delving into Deep Imbalanced Regression This repository contains the implementation code for paper: Delving into Deep Imbalanced Regression Yuzhe Yang
 568 Dec 30, 2022
568 Dec 30, 2022
![[CVPR 2021]](https://github.com/VITA-Group/CV_LTH_Pre-training/raw/main/Figs/Teaser.png)
[CVPR 2021] "The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models" Tianlong Chen, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Michael Carbin, Zhangyang Wang
The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models Codes for this paper The Lottery Tickets Hypo
 59 Dec 28, 2022
59 Dec 28, 2022
Ecommerce product title recognition package
revizor This package solves task of splitting product title string into components, like type, brand, model and article (or SKU or product code or you
 16 Mar 3, 2022
16 Mar 3, 2022

An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C.
vizh An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C. Overview Her
 228 Dec 17, 2022
228 Dec 17, 2022
A simple programming language for manipulating images.
f-stop A simple programming language for manipulating images. Examples OPEN "image.png" AS image RESIZE image (300, 300) SAVE image "out.jpg" CLOSE im
 6 Oct 27, 2022
6 Oct 27, 2022

The official codes of "Semi-supervised Models are Strong Unsupervised Domain Adaptation Learners".
SSL models are Strong UDA learners Introduction This is the official code of paper "Semi-supervised Models are Strong Unsupervised Domain Adaptation L
 26 Dec 26, 2022
26 Dec 26, 2022
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022
FEDn is an open-source, modular and ML-framework agnostic framework for Federated Machine Learning
FEDn is an open-source, modular and ML-framework agnostic framework for Federated Machine Learning (FedML) developed and maintained by Scaleout Systems. FEDn enables highly scalable cross-silo and cross-device use-cases over FEDn networks.
 75 Nov 9, 2022
75 Nov 9, 2022
sawa (ꦱꦮ) is an open source programming language, an interpreter to be precise, where you can write python code using javanese character.
ꦱꦮ sawa (ꦱꦮ) is an open source programming language, an interpreter to be precise, where you can write python code using javanese character. sawa iku
 307 Jan 7, 2023
307 Jan 7, 2023

Pytorch Implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension)
DiffSinger - PyTorch Implementation PyTorch implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension). Status
 152 Jan 2, 2023
152 Jan 2, 2023

Kestrel Threat Hunting Language
Kestrel Threat Hunting Language What is Kestrel? Why we need it? How to hunt with XDR support? What is the science behind it? You can find all the ans
 201 Dec 16, 2022
201 Dec 16, 2022

Pytorch implementation of Generative Models as Distributions of Functions 🌿
Generative Models as Distributions of Functions This repo contains code to reproduce all experiments in Generative Models as Distributions of Function
 117 Dec 29, 2022
117 Dec 29, 2022
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging This repository contains an implementation
 1.1k Jan 2, 2023
1.1k Jan 2, 2023

Inferoxy is a service for quick deploying and using dockerized Computer Vision models.
Inferoxy is a service for quick deploying and using dockerized Computer Vision models. It's a core of EORA's Computer Vision platform Vision Hub that runs on top of AWS EKS.
 94 Oct 10, 2022
94 Oct 10, 2022

A framework for detecting, highlighting and correcting grammatical errors on natural language text.
Gramformer Human and machine generated text often suffer from grammatical and/or typographical errors. It can be spelling, punctuation, grammatical or
1.3k Jan 8, 2023
Protein Language Model
ProteinLM We pretrain protein language model based on Megatron-LM framework, and then evaluate the pretrained model results on TAPE (Tasks Assessing P
 77 Dec 27, 2022
77 Dec 27, 2022
PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World [ACL 2021]
piglet PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World [ACL 2021] This repo contains code and data for PIGLeT. If you like
51 Oct 8, 2022

simpleT5 is built on top of PyTorch-lightning⚡️ and Transformers🤗 that lets you quickly train your T5 models.
Quickly train T5 models in just 3 lines of code + ONNX support simpleT5 is built on top of PyTorch-lightning ⚡️ and Transformers 🤗 that lets you quic
 220 Dec 30, 2022
220 Dec 30, 2022
tf2onnx - Convert TensorFlow, Keras and Tflite models to ONNX.
tf2onnx converts TensorFlow (tf-1.x or tf-2.x), tf.keras and tflite models to ONNX via command line or python api.
 1.8k Jan 8, 2023
1.8k Jan 8, 2023

This repo contains the official code and pre-trained models for the Dynamic Vision Transformer (DVT).
Dynamic-Vision-Transformer (Pytorch) This repo contains the official code and pre-trained models for the Dynamic Vision Transformer (DVT). Not All Ima
 210 Dec 18, 2022
210 Dec 18, 2022
Repository for the "Gotta Go Fast When Generating Data with Score-Based Models" paper
Gotta Go Fast When Generating Data with Score-Based Models This repo contains the official implementation for the paper Gotta Go Fast When Generating
 89 Nov 9, 2022
89 Nov 9, 2022
SparseML is a libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models
SparseML is a toolkit that includes APIs, CLIs, scripts and libraries that apply state-of-the-art sparsification algorithms such as pruning and quantization to any neural network. General, recipe-driven approaches built around these algorithms enable the simplification of creating faster and smaller models for the ML performance community at large.
 1.5k Dec 30, 2022
1.5k Dec 30, 2022
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions (CVPR2021)
NExT-QA We reproduce some SOTA VideoQA methods to provide benchmark results for our NExT-QA dataset accepted to CVPR2021 (with 1 'Strong Accept' and 2
 50 Nov 24, 2022
50 Nov 24, 2022

Anonymize BLM Protest Images
Anonymize BLM Protest Images This repository automates @BLMPrivacyBot, a Twitter bot that shows the anonymized images to help keep protesters safe. Us
 40 Oct 13, 2022
40 Oct 13, 2022

This project provides an unsupervised framework for mining and tagging quality phrases on text corpora with pretrained language models (KDD'21).
UCPhrase: Unsupervised Context-aware Quality Phrase Tagging To appear on KDD'21...[pdf] This project provides an unsupervised framework for mining and
 146 Dec 22, 2022
146 Dec 22, 2022
Rick Astley Language is a rick roll oriented, dynamic, strong, esoteric programming language.
Rick Roll Language / Rick Astley Language A rick roll oriented, dynamic, strong, esoteric programming language. Prolegomenon The reasons that I made t
 658 Jan 9, 2023
658 Jan 9, 2023
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset.
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset. Through its Python API, the pretrained model can be fine-tuned on any protein-related task in a matter of minutes. Based on our experiments with a wide range of benchmarks, ProteinBERT usually achieves state-of-the-art performance. ProteinBERT is built on TenforFlow/Keras.
 241 Jan 4, 2023
241 Jan 4, 2023
This repository contains the implementations related to the experiments of a set of publicly available datasets that are used in the time series forecasting research space.
TSForecasting This repository contains the implementations related to the experiments of a set of publicly available datasets that are used in the tim
 80 Dec 30, 2022
80 Dec 30, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 248 Dec 4, 2022
248 Dec 4, 2022
TensorFlow Decision Forests (TF-DF) is a collection of state-of-the-art algorithms for the training, serving and interpretation of Decision Forest models.
TensorFlow Decision Forests (TF-DF) is a collection of state-of-the-art algorithms for the training, serving and interpretation of Decision Forest models. The library is a collection of Keras models and supports classification, regression and ranking. TF-DF is a TensorFlow wrapper around the Yggdrasil Decision Forests C++ libraries. Models trained with TF-DF are compatible with Yggdrasil Decision Forests' models, and vice versa.
 538 Jan 1, 2023
538 Jan 1, 2023
True Few-Shot Learning with Language Models
This codebase supports using language models (LMs) for true few-shot learning: learning to perform a task using a limited number of examples from a single task distribution.
 124 Jan 4, 2023
124 Jan 4, 2023
VMD Audio/Text control with natural language
This repository is a proof of principle for performing Molecular Dynamics analysis, in this case with the program VMD, via natural language commands.
 13 Jun 9, 2022
13 Jun 9, 2022
Code for the paper "Adapting Monolingual Models: Data can be Scarce when Language Similarity is High"
Wietse de Vries • Martijn Bartelds • Malvina Nissim • Martijn Wieling Adapting Monolingual Models: Data can be Scarce when Language Similarity is High
 5 Aug 2, 2021
5 Aug 2, 2021
![[CVPR'21 Oral] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning](https://github.com/researchmm/soho/raw/master/resources/soho.png)
[CVPR'21 Oral] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning [CVPR'21, Oral] By Zhicheng Huang*, Zhaoyang Zeng*, Yupan H
 196 Dec 13, 2022
196 Dec 13, 2022
A GPT, made only of MLPs, in Jax
MLP GPT - Jax (wip) A GPT, made only of MLPs, in Jax. The specific MLP to be used are gMLPs with the Spatial Gating Units. Working Pytorch implementat
 53 Sep 27, 2022
53 Sep 27, 2022
An evaluation toolkit for voice conversion models.
Voice-conversion-evaluation An evaluation toolkit for voice conversion models. Sample test pair Generate the metadata for evaluating models. The direc
 30 Aug 29, 2022
30 Aug 29, 2022