1267 Repositories
Python models-converter Libraries
An executor that loads ONNX models and embeds documents using the ONNX runtime.
ONNXEncoder An executor that loads ONNX models and embeds documents using the ONNX runtime. Usage via Docker image (recommended) from jina import Flow
 2 Mar 15, 2022
2 Mar 15, 2022
Model Zoo for MindSpore
Welcome to the Model Zoo for MindSpore In order to facilitate developers to enjoy the benefits of MindSpore framework, we will continue to add typical
 226 Jan 7, 2023
226 Jan 7, 2023
American Sign Language (ASL) to Text Converter
Signterpreter American Sign Language (ASL) to Text Converter Recommendations Although there is grayscale and gaussian blur, we recommend that you use
 0 Feb 20, 2022
0 Feb 20, 2022

A few stylization coreML models that I've trained with CreateML
CoreML-StyleTransfer A few stylization coreML models that I've trained with CreateML You can open and use the .mlmodel files in the "models" folder in
 8 Aug 18, 2022
8 Aug 18, 2022

 1 Sep 7, 2021
1 Sep 7, 2021
Latte: Cross-framework Python Package for Evaluation of Latent-based Generative Models
Cross-framework Python Package for Evaluation of Latent-based Generative Models Latte Latte (for LATent Tensor Evaluation) is a cross-framework Python
 30 Sep 8, 2022
30 Sep 8, 2022

High-Resolution Image Synthesis with Latent Diffusion Models
Latent Diffusion Models arXiv | BibTeX High-Resolution Image Synthesis with Latent Diffusion Models Robin Rombach*, Andreas Blattmann*, Dominik Lorenz
 5.6k Dec 30, 2022
5.6k Dec 30, 2022
YAML-formatted plain-text file based models for Flask backed by Flask-SQLAlchemy
Flask-FileAlchemy Flask-FileAlchemy is a Flask extension that lets you use Markdown or YAML formatted plain-text files as the main data store for your
 20 Dec 14, 2022
20 Dec 14, 2022

Albert launcher extension for converting units of length, mass, speed, temperature, time, current, luminosity, printing measurements, molecular substance, and more
unit-converter-albert-ext Extension for converting units of length, mass, speed, temperature, time, current, luminosity, printing measurements, molecu
 2 Jan 13, 2022
2 Jan 13, 2022
CleverCSV is a Python package for handling messy CSV files.
CleverCSV is a Python package for handling messy CSV files. It provides a drop-in replacement for the builtin CSV module with improved dialect detection, and comes with a handy command line application for working with CSV files.
 1k Dec 19, 2022
1k Dec 19, 2022
Python SDK for building, training, and deploying ML models
Overview of Kubeflow Fairing Kubeflow Fairing is a Python package that streamlines the process of building, training, and deploying machine learning (
 325 Dec 13, 2022
325 Dec 13, 2022

This repository contains the code needed to train Mega-NeRF models and generate the sparse voxel octrees
Mega-NeRF This repository contains the code needed to train Mega-NeRF models and generate the sparse voxel octrees used by the Mega-NeRF-Dynamic viewe
 260 Dec 28, 2022
260 Dec 28, 2022

Source code of the paper "Deep Learning of Latent Variable Models for Industrial Process Monitoring".
Source code of the paper "Deep Learning of Latent Variable Models for Industrial Process Monitoring".
 7 Nov 8, 2022
7 Nov 8, 2022

This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs".
CrossSum This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summ
 29 Nov 19, 2022
29 Nov 19, 2022
Matching python environment code for Lux AI 2021 Kaggle competition, and a gym interface for RL models.
Lux AI 2021 python game engine and gym This is a replica of the Lux AI 2021 game ported directly over to python. It also sets up a classic Reinforceme
 74 Nov 3, 2022
74 Nov 3, 2022
Official codebase for running the small, filtered-data GLIDE model from GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models.
GLIDE This is the official codebase for running the small, filtered-data GLIDE model from GLIDE: Towards Photorealistic Image Generation and Editing w
 2.9k Jan 4, 2023
2.9k Jan 4, 2023

High-Resolution Image Synthesis with Latent Diffusion Models
Latent Diffusion Models Requirements A suitable conda environment named ldm can be created and activated with: conda env create -f environment.yaml co
5.6k Jan 4, 2023

Quick tutorial on orchest.io that shows how to build multiple deep learning models on your data with a single line of code using python
Deep AutoViML Pipeline for orchest.io Quickstart Build Deep Learning models with a single line of code: deep_autoviml Deep AutoViML helps you build te
 6 Oct 2, 2022
6 Oct 2, 2022
📜 GPT-2 Rhyming Limerick and Haiku models using data augmentation
Well-formed Limericks and Haikus with GPT2 📜 GPT-2 Rhyming Limerick and Haiku models using data augmentation In collaboration with Matthew Korahais &
 2 May 26, 2022
2 May 26, 2022
Resources related to our paper "CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain"
CLIN-X (CLIN-X-ES) & (CLIN-X-EN) This repository holds the companion code for the system reported in the paper: "CLIN-X: pre-trained language models a
 4 Dec 5, 2022
4 Dec 5, 2022
The source code of "Language Models are Few-shot Multilingual Learners" (MRL @ EMNLP 2021)
Language Models are Few-shot Multilingual Learners Paper This is the source code of the paper [Arxiv] [ACL Anthology]: This code has been written usin
 45 Nov 21, 2022
45 Nov 21, 2022
Header-only library for using Keras models in C++.
frugally-deep Use Keras models in C++ with ease Table of contents Introduction Usage Performance Requirements and Installation FAQ Introduction Would
 927 Jan 5, 2023
927 Jan 5, 2023

Robust fine-tuning of zero-shot models
Robust fine-tuning of zero-shot models This repository contains code for the paper Robust fine-tuning of zero-shot models by Mitchell Wortsman*, Gabri
 224 Dec 29, 2022
224 Dec 29, 2022
BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Table of contents Introduction Using BARTpho with fairseq Using BARTpho with transformers Notes BARTpho: Pre-trained Sequence-to-Sequence Models for V
 58 Dec 23, 2022
58 Dec 23, 2022

J.A.R.V.I.S is an AI virtual assistant made in python.
J.A.R.V.I.S is an AI virtual assistant made in python. Running JARVIS Without Python To run JARVIS without python: 1. Head over to our installation pa
 16 Dec 29, 2022
16 Dec 29, 2022

Benchmark for the generalization of 3D machine learning models across different remeshing/samplings of a surface.
Discretization Robust Correspondence Benchmark One challenge of machine learning on 3D surfaces is that there are many different representations/sampl
 10 Sep 30, 2022
10 Sep 30, 2022
The aim is to contain multiple models for materials discovery under a common interface
Aviary The aviary contains: - roost, - wren, cgcnn. The aim is to contain multiple models for materials discovery under a common interface Environment
 20 Jan 6, 2023
20 Jan 6, 2023

Useful PDF-related productivity tool.
Luftmensch 1.4.7 (Español) | 1.4.3 (English) Version 1.4.7 (Español) released in October 2021. Version 1.4.3 (English) released in September 2021. 🏮
 8 Dec 29, 2022
8 Dec 29, 2022
Django models and endpoints for working with large images -- tile serving
Django Large Image Models and endpoints for working with large images in Django -- specifically geared towards geospatial tile serving. DISCLAIMER: th
 42 Dec 17, 2022
42 Dec 17, 2022

Training deep models using anime, illustration images.
animeface deep models for anime images. Datasets anime-face-dataset Anime faces collected from Getchu.com. Based on Mckinsey666's dataset. 63.6K image
 61 Dec 25, 2022
61 Dec 25, 2022

A PyTorch-based model pruning toolkit for pre-trained language models
English | 中文说明 TextPruner是一个为预训练语言模型设计的模型裁剪工具包,通过轻量、快速的裁剪方法对模型进行结构化剪枝,从而实现压缩模型体积、提升模型速度。 其他相关资源: 知识蒸馏工具TextBrewer:https://github.com/airaria/TextBrewe
 231 Jan 8, 2023
231 Jan 8, 2023
A library that allows for inference on probabilistic models
Bean Machine Overview Bean Machine is a probabilistic programming language for inference over statistical models written in the Python language using
 234 Dec 29, 2022
234 Dec 29, 2022
The code written during my Bachelor Thesis "Classification of Human Whole-Body Motion using Hidden Markov Models".
This code was written during the course of my Bachelor thesis Classification of Human Whole-Body Motion using Hidden Markov Models. Some things might
 14 Dec 6, 2022
14 Dec 6, 2022
Training PyTorch models with differential privacy
Opacus is a library that enables training PyTorch models with differential privacy. It supports training with minimal code changes required on the cli
 1.3k Dec 29, 2022
1.3k Dec 29, 2022

Official code for "On the Frequency Bias of Generative Models", NeurIPS 2021
Frequency Bias of Generative Models Generator Testbed Discriminator Testbed This repository contains official code for the paper On the Frequency Bias
 35 Nov 1, 2022
35 Nov 1, 2022
Build Low Code Automated Tensorflow, What-IF explainable models in just 3 lines of code.
Build Low Code Automated Tensorflow explainable models in just 3 lines of code.
 170 Dec 26, 2022
170 Dec 26, 2022

scikit-learn models hyperparameters tuning and feature selection, using evolutionary algorithms.
Sklearn-genetic-opt scikit-learn models hyperparameters tuning and feature selection, using evolutionary algorithms. This is meant to be an alternativ
 180 Dec 20, 2022
180 Dec 20, 2022
Official code repository for "Exploring Neural Models for Query-Focused Summarization"
Query-Focused Summarization Official code repository for "Exploring Neural Models for Query-Focused Summarization" This is a work in progress. Expect
 29 Dec 18, 2022
29 Dec 18, 2022
Lex Rosetta: Transfer of Predictive Models Across Languages, Jurisdictions, and Legal Domains
Lex Rosetta: Transfer of Predictive Models Across Languages, Jurisdictions, and Legal Domains This is an accompanying repository to the ICAIL 2021 pap
 4 Dec 16, 2021
4 Dec 16, 2021
"Learning and Analyzing Generation Order for Undirected Sequence Models" in Findings of EMNLP, 2021
undirected-generation-dev This repo contains the source code of the models described in the following paper "Learning and Analyzing Generation Order f
 0 Mar 25, 2022
0 Mar 25, 2022

Ensembling Off-the-shelf Models for GAN Training
Vision-aided GAN video (3m) | website | paper Can the collective knowledge from a large bank of pretrained vision models be leveraged to improve GAN t
 345 Dec 28, 2022
345 Dec 28, 2022
Converts a base copy of Pokemon BDSP's masterdatas into a more readable and editable Pokemon Showdown Format.
Showdown-BDSP-Converter Converts a base copy of Pokemon BDSP's masterdatas into a more readable and editable Pokemon Showdown Format. Download the lat
 2 Jan 2, 2022
2 Jan 2, 2022
Code for paper Multitask-Finetuning of Zero-shot Vision-Language Models
Code for paper Multitask-Finetuning of Zero-shot Vision-Language Models
 2 Jul 15, 2022
2 Jul 15, 2022

Ensembling Off-the-shelf Models for GAN Training
Data-Efficient GANs with DiffAugment project | paper | datasets | video | slides Generated using only 100 images of Obama, grumpy cats, pandas, the Br
 1.2k Dec 26, 2022
1.2k Dec 26, 2022
Pytorch modules for paralel models with same architecture. Ideal for multi agent-based systems
WideLinears Pytorch parallel Neural Networks A package of pytorch modules for fast paralellization of separate deep neural networks. Ideal for agent-b
 1 Dec 17, 2021
1 Dec 17, 2021
Fit models to your data in Python with Sherpa.
Table of Contents Sherpa License How To Install Sherpa Using Anaconda Using pip Building from source History Release History Sherpa Sherpa is a modeli
 134 Jan 7, 2023
134 Jan 7, 2023
This repository contains the code, models and datasets discussed in our paper "Few-Shot Question Answering by Pretraining Span Selection"
Splinter This repository contains the code, models and datasets discussed in our paper "Few-Shot Question Answering by Pretraining Span Selection", to
 88 Dec 31, 2022
88 Dec 31, 2022
ByT5: Towards a token-free future with pre-trained byte-to-byte models
ByT5: Towards a token-free future with pre-trained byte-to-byte models ByT5 is a tokenizer-free extension of the mT5 model. Instead of using a subword
 409 Jan 6, 2023
409 Jan 6, 2023
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 342 Jan 5, 2023
342 Jan 5, 2023

FastFormers - highly efficient transformer models for NLU
FastFormers FastFormers provides a set of recipes and methods to achieve highly efficient inference of Transformer models for Natural Language Underst
 678 Jan 5, 2023
678 Jan 5, 2023
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022
Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models
PEGASUS library Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models, or PEGASUS, uses self-supervised
1.4k Dec 22, 2022
Fine-tuning scripts for evaluating transformer-based models on KLEJ benchmark.
The KLEJ Benchmark Baselines The KLEJ benchmark (Kompleksowa Lista Ewaluacji Językowych) is a set of nine evaluation tasks for the Polish language und
 17 Oct 18, 2022
17 Oct 18, 2022
Dense Passage Retriever - is a set of tools and models for open domain Q&A task.
Dense Passage Retrieval Dense Passage Retrieval (DPR) - is a set of tools and models for state-of-the-art open-domain Q&A research. It is based on the
1.1k Jan 7, 2023
This repository contains the code for running the character-level Sandwich Transformers from our ACL 2020 paper on Improving Transformer Models by Reordering their Sublayers.
Improving Transformer Models by Reordering their Sublayers This repository contains the code for running the character-level Sandwich Transformers fro
 53 Sep 26, 2022
53 Sep 26, 2022
Code for the paper "Language Models are Unsupervised Multitask Learners"
Status: Archive (code is provided as-is, no updates expected) gpt-2 Code and models from the paper "Language Models are Unsupervised Multitask Learner
16.1k Jan 8, 2023
Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
Tensor2Tensor Tensor2Tensor, or T2T for short, is a library of deep learning models and datasets designed to make deep learning more accessible and ac
 12.9k Jan 7, 2023
12.9k Jan 7, 2023
An implementation of model parallel GPT-2 and GPT-3-style models using the mesh-tensorflow library.
GPT Neo 🎉 1T or bust my dudes 🎉 An implementation of model & data parallel GPT3-like models using the mesh-tensorflow library. If you're just here t
 6.7k Dec 28, 2022
6.7k Dec 28, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023
Using VapourSynth with super resolution models and speeding them up with TensorRT.
VSGAN-tensorrt-docker Using image super resolution models with vapoursynth and speeding them up with TensorRT. Using NVIDIA/Torch-TensorRT combined wi
 111 Jan 5, 2023
111 Jan 5, 2023
Face and Body Tracking for VRM 3D models on the web.
Kalidoface 3D - Face and Full-Body tracking for Vtubing on the web! A sequal to Kalidoface which supports Live2D avatars, Kalidoface 3D is a web app t
 257 Jan 2, 2023
257 Jan 2, 2023
💃 VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena
💃 VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena.
 17 Nov 7, 2022
17 Nov 7, 2022
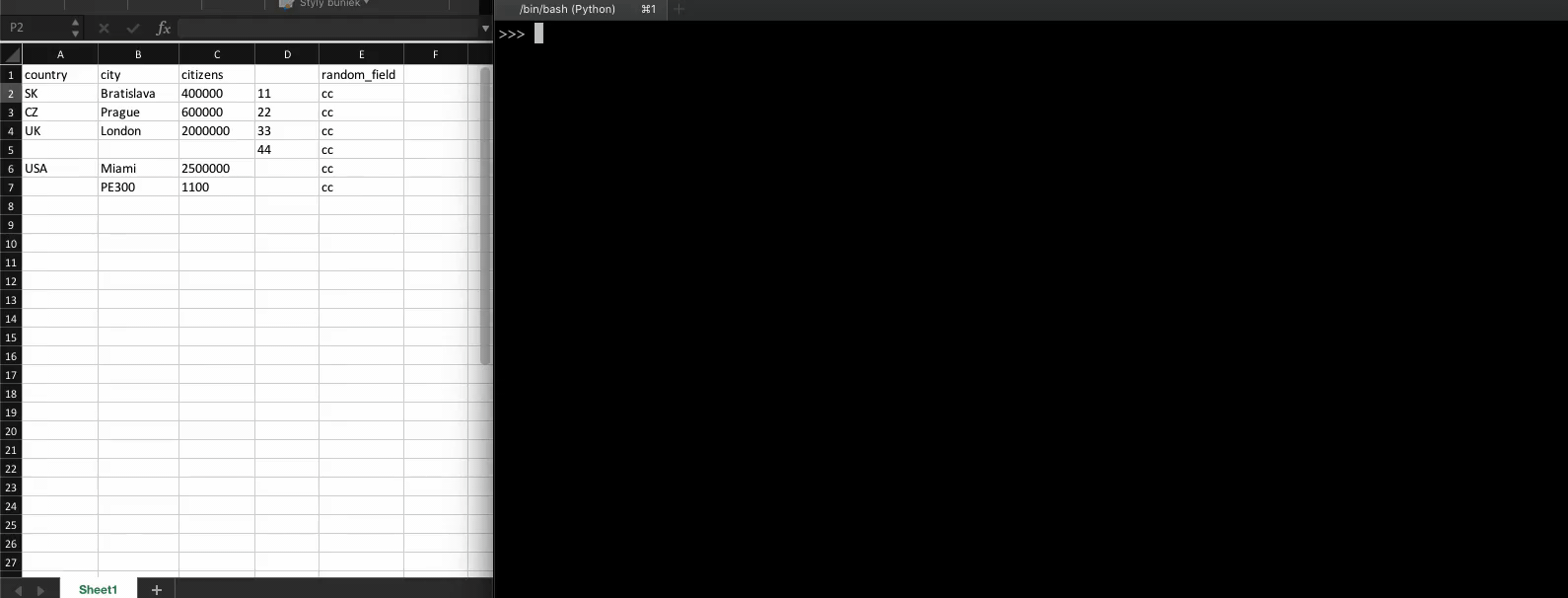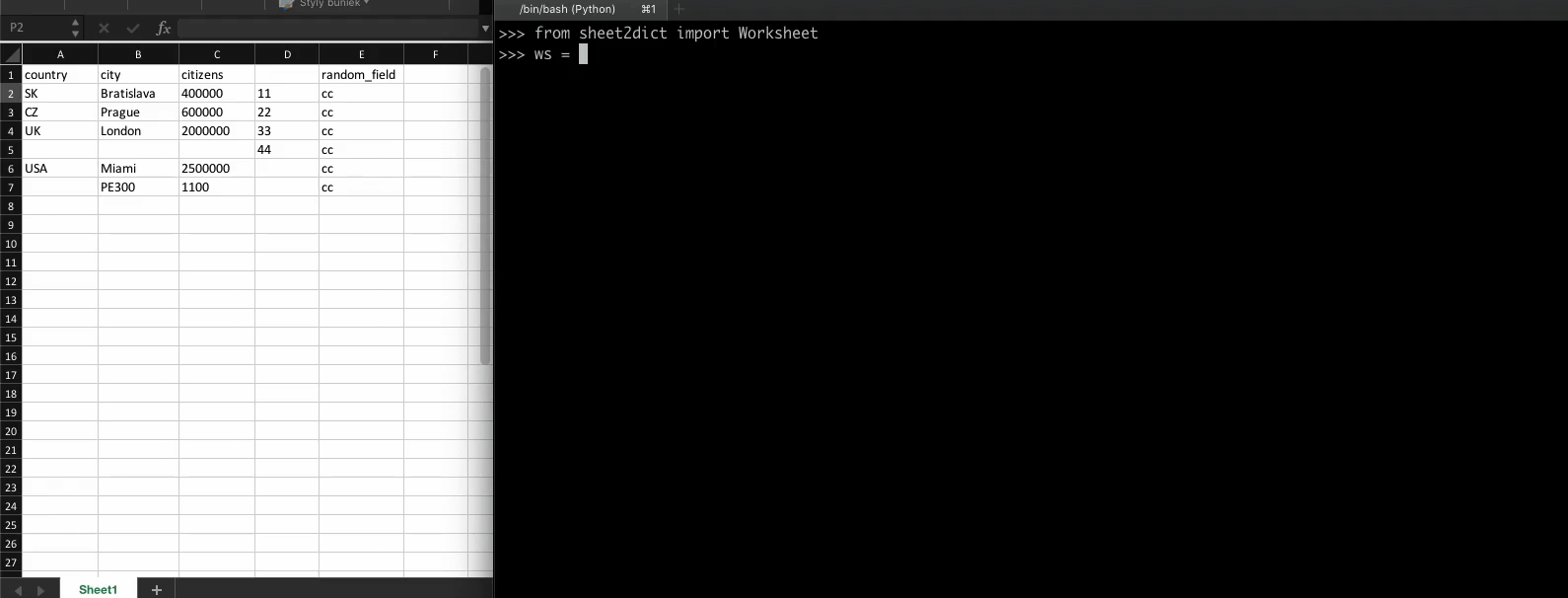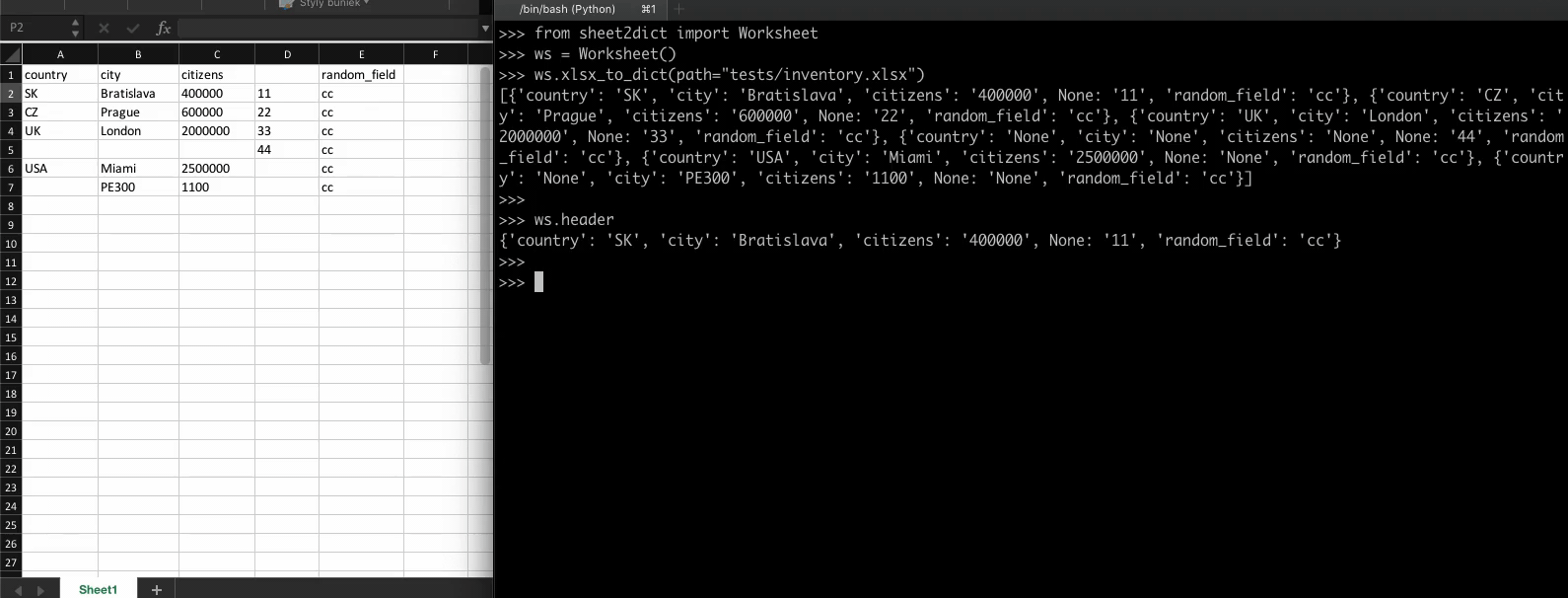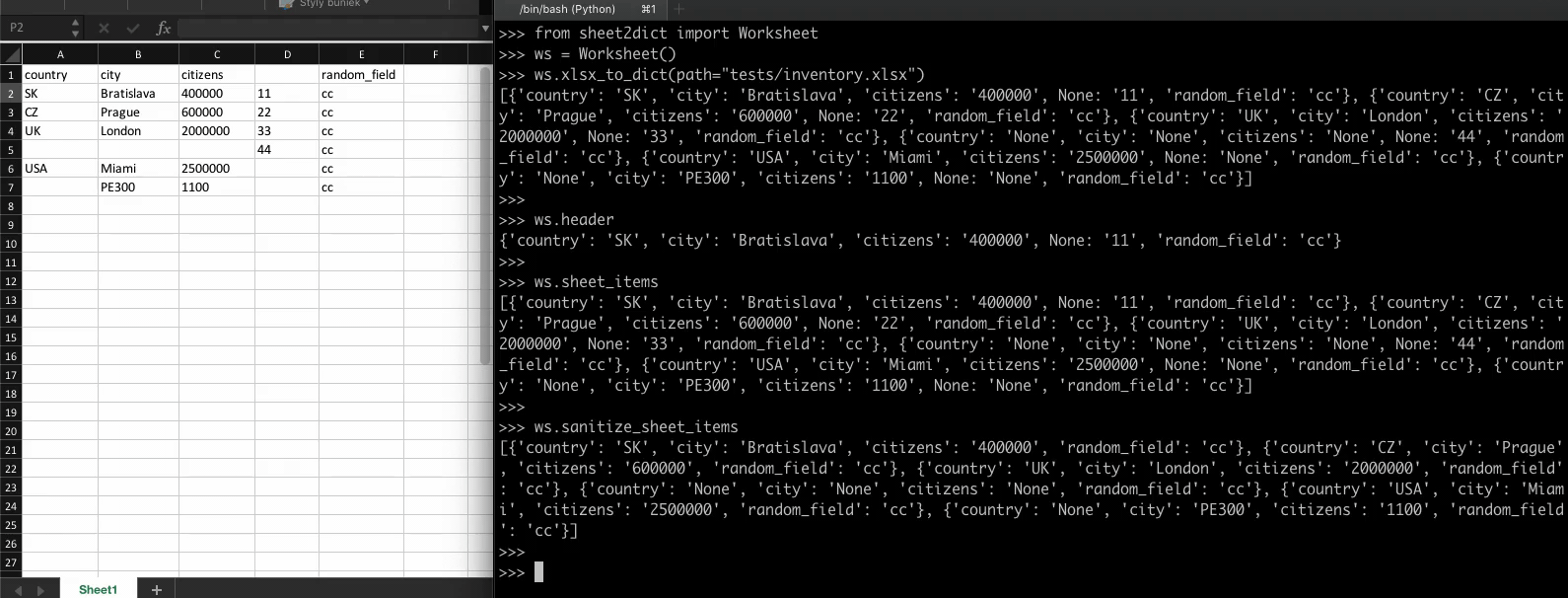
A simple XLSX/CSV reader - to dictionary converter
sheet2dict A simple XLSX/CSV reader - to dictionary converter Installing To install the package from pip, first run: python3 -m pip install --no-cache
 216 Nov 25, 2022
216 Nov 25, 2022
Whole-day timezone comparison
Timezone Converter Compare a full day of your local timezone with foreign ones $ timezone-converter tijuana --zone $ timezone-converter tijuana new_yo
 12 Nov 24, 2022
12 Nov 24, 2022
Formulae is a Python library that implements Wilkinson's formulas for mixed-effects models.
formulae formulae is a Python library that implements Wilkinson's formulas for mixed-effects models. The main difference with other implementations li
 34 Dec 21, 2022
34 Dec 21, 2022
Convert onnx models to pytorch.
onnx2torch onnx2torch is an ONNX to PyTorch converter. Our converter: Is easy to use – Convert the ONNX model with the function call convert; Is easy
 264 Dec 30, 2022
264 Dec 30, 2022

Robbing the FED: Directly Obtaining Private Data in Federated Learning with Modified Models
Robbing the FED: Directly Obtaining Private Data in Federated Learning with Modified Models This repo contains a barebones implementation for the atta
 16 Dec 4, 2022
16 Dec 4, 2022
The python SDK for Eto, the AI focused data platform for teams bringing AI models to production
Eto Labs Python SDK This is the python SDK for Eto, the AI focused data platform for teams bringing AI models to production. The python SDK makes it e
 5 Apr 21, 2022
5 Apr 21, 2022
Code for Temporally Abstract Partial Models
Code for Temporally Abstract Partial Models Accompanies the code for the experimental section of the paper: Temporally Abstract Partial Models, Khetar
 19 Jul 13, 2022
19 Jul 13, 2022
Code for WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models.
WECHSEL Code for WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models. arXiv: https://arx
 45 Dec 29, 2022
45 Dec 29, 2022

Experiments on continual learning from a stream of pretrained models.
Ex-model CL Ex-model continual learning is a setting where a stream of experts (i.e. model's parameters) is available and a CL model learns from them
 6 Dec 4, 2022
6 Dec 4, 2022
Discovering Explanatory Sentences in Legal Case Decisions Using Pre-trained Language Models.
Statutory Interpretation Data Set This repository contains the data set created for the following research papers: Savelka, Jaromir, and Kevin D. Ashl
 17 Dec 23, 2022
17 Dec 23, 2022
AdamW optimizer for bfloat16 models in pytorch.
Image source AdamW optimizer for bfloat16 models in pytorch. Bfloat16 is currently an optimal tradeoff between range and relative error for deep netwo
 8 Nov 20, 2022
8 Nov 20, 2022
Code for WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models.
WECHSEL Code for WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models. arXiv: https://arx
45 Dec 29, 2022
Simple Python Library to convert JSON to XML
json2xml Simple Python Library to convert JSON to XML
 79 Nov 11, 2022
79 Nov 11, 2022
MLReef is an open source ML-Ops platform that helps you collaborate, reproduce and share your Machine Learning work with thousands of other users.
The collaboration platform for Machine Learning MLReef is an open source ML-Ops platform that helps you collaborate, reproduce and share your Machine
 1.4k Dec 27, 2022
1.4k Dec 27, 2022
Integrate GraphQL with your Pydantic models
graphene-pydantic A Pydantic integration for Graphene. Installation pip install "graphene-pydantic" Examples Here is a simple Pydantic model: import u
 179 Jan 2, 2023
179 Jan 2, 2023
Using image super resolution models with vapoursynth and speeding them up with TensorRT
vs-RealEsrganAnime-tensorrt-docker Using image super resolution models with vapoursynth and speeding them up with TensorRT. Also a docker image since
4 Aug 23, 2022
Code for paper: "Spinning Language Models for Propaganda-As-A-Service"
Spinning Language Models for Propaganda-As-A-Service This is the source code for the Arxiv version of the paper. You can use this Google Colab to expl
 16 Jan 3, 2023
16 Jan 3, 2023
A FAIR dataset of TCV experimental results for validating edge/divertor turbulence models.
TCV-X21 validation for divertor turbulence simulations Quick links Intro Welcome to TCV-X21. We're glad you've found us! This repository is designed t
 0 Dec 18, 2021
0 Dec 18, 2021
Pydantic models for pywttr and aiopywttr.
Pydantic models for pywttr and aiopywttr.
 2 Dec 8, 2022
2 Dec 8, 2022

A minimal, standalone viewer for 3D animations stored as stop-motion sequences of individual .obj mesh files.
ObjSequenceViewer V0.5 A minimal, standalone viewer for 3D animations stored as stop-motion sequences of individual .obj mesh files. Installation: pip
 2 Aug 4, 2022
2 Aug 4, 2022
PyTorch implementation of normalizing flow models
PyTorch implementation of normalizing flow models
 242 Jan 2, 2023
242 Jan 2, 2023
Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts
t5-japanese Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts. The following is a list of models that
 1 Dec 13, 2021
1 Dec 13, 2021

PyAbsorp is a python module that has the main focus to help estimate the Sound Absorption Coefficient.
This is a package developed to be use to find the Sound Absorption Coefficient through some implemented models, like Biot-Allard, Johnson-Champoux and
 8 Oct 19, 2022
8 Oct 19, 2022
SeqAttack: a framework for adversarial attacks on token classification models
A framework for adversarial attacks against token classification models
 23 Nov 25, 2022
23 Nov 25, 2022
Users can free try their models on SIDD dataset based on this code
SIDD benchmark 1 Train python train.py If you want to train your network, just modify the yaml in the options folder. 2 Validation python validation.p
 2 May 20, 2022
2 May 20, 2022
PyTorch implementation of a collections of scalable Video Transformer Benchmarks.
PyTorch implementation of Video Transformer Benchmarks This repository is mainly built upon Pytorch and Pytorch-Lightning. We wish to maintain a colle
 156 Jan 8, 2023
156 Jan 8, 2023

easyNeuron is a simple way to create powerful machine learning models, analyze data and research cutting-edge AI.
easyNeuron is a simple way to create powerful machine learning models, analyze data and research cutting-edge AI.
 5 Jun 18, 2022
5 Jun 18, 2022
A lightweight library designed to accelerate the process of training PyTorch models by providing a minimal
A lightweight library designed to accelerate the process of training PyTorch models by providing a minimal, but extensible training loop which is flexible enough to handle the majority of use cases, and capable of utilizing different hardware options with no code changes required.
 110 Dec 23, 2022
110 Dec 23, 2022
Official code for "Maximum Likelihood Training of Score-Based Diffusion Models", NeurIPS 2021 (spotlight)
Maximum Likelihood Training of Score-Based Diffusion Models This repo contains the official implementation for the paper Maximum Likelihood Training o
 84 Dec 12, 2022
84 Dec 12, 2022

Autoregressive Models in PyTorch.
Autoregressive This repository contains all the necessary PyTorch code, tailored to my presentation, to train and generate data from WaveNet-like auto
 41 Oct 9, 2022
41 Oct 9, 2022
Models, datasets and tools for Facial keypoints detection
Template for Data Science Project This repo aims to give a robust starting point to any Data Science related project. It contains readymade tools setu
 1 Feb 11, 2022
1 Feb 11, 2022

Python bindings for MuPDF's rendering library.
PyMuPDF 1.19.3 Release date: December 15, 2021 On PyPI since August 2016: Author Jorj X. McKie, based on original code by Ruikai Liu. Introduction PyM
 0 Nov 3, 2022
0 Nov 3, 2022

Explainability of the Implications of Supervised and Unsupervised Face Image Quality Estimations Through Activation Map Variation Analyses in Face Recognition Models
Explainable_FIQA_WITH_AMVA Note This is the official repository of the paper: Explainability of the Implications of Supervised and Unsupervised Face I
 3 May 8, 2022
3 May 8, 2022

Music Source Separation; Train & Eval & Inference piplines and pretrained models we used for 2021 ISMIR MDX Challenge.
Introduction 1. Usage (For MSS) 1.1 Prepare running environment 1.2 Use pretrained model 1.3 Train new MSS models from scratch 1.3.1 How to train 1.3.
 100 Dec 25, 2022
100 Dec 25, 2022

Visual Adversarial Imitation Learning using Variational Models (VMAIL)
Visual Adversarial Imitation Learning using Variational Models (VMAIL) This is the official implementation of the NeurIPS 2021 paper. Project website
 14 Nov 18, 2022
14 Nov 18, 2022
A collection of models, views, middlewares, and forms to help secure a Django project.
Django-Security This package offers a number of models, views, middlewares and forms to facilitate security hardening of Django applications. Full doc
 258 Jan 3, 2023
258 Jan 3, 2023

RuleBERT: Teaching Soft Rules to Pre-Trained Language Models
RuleBERT: Teaching Soft Rules to Pre-Trained Language Models (Paper) (Slides) (Video) RuleBERT is a pre-trained language model that has been fine-tune
 16 Aug 24, 2022
16 Aug 24, 2022
An MLOps framework to package, deploy, monitor and manage thousands of production machine learning models
Seldon Core: Blazing Fast, Industry-Ready ML An open source platform to deploy your machine learning models on Kubernetes at massive scale. Overview S
 3.5k Jan 1, 2023
3.5k Jan 1, 2023