415 Repositories
Python motion-synthesis Libraries

Deep Unsupervised 3D SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment.
(ACMMM 2021 Oral) SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment This repository shows two tasks: Face landmark detection and Fac
 51 Dec 13, 2022
51 Dec 13, 2022

ManipNet: Neural Manipulation Synthesis with a Hand-Object Spatial Representation - SIGGRAPH 2021
ManipNet: Neural Manipulation Synthesis with a Hand-Object Spatial Representation - SIGGRAPH 2021 Dataset Code Demos Authors: He Zhang, Yuting Ye, Tak
 194 Dec 6, 2022
194 Dec 6, 2022
![[ICCV'21] Official implementation for the paper Social NCE: Contrastive Learning of Socially-aware Motion Representations](https://github.com/vita-epfl/social-nce-crowdnav/raw/main/docs/illustration.png)
[ICCV'21] Official implementation for the paper Social NCE: Contrastive Learning of Socially-aware Motion Representations
CrowdNav with Social-NCE This is an official implementation for the paper Social NCE: Contrastive Learning of Socially-aware Motion Representations by
 125 Dec 23, 2022
125 Dec 23, 2022
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion Yinghao Aaron Li, Ali Zare, Nima Mesgarani We pres
 282 Jan 1, 2023
282 Jan 1, 2023
Implementation supporting the ICCV 2017 paper "GANs for Biological Image Synthesis"
GANs for Biological Image Synthesis This codes implements the ICCV-2017 paper "GANs for Biological Image Synthesis". The paper and its supplementary m
 95 Nov 25, 2022
95 Nov 25, 2022

A PyTorch implementation of the paper "Semantic Image Synthesis via Adversarial Learning" in ICCV 2017
Semantic Image Synthesis via Adversarial Learning This is a PyTorch implementation of the paper Semantic Image Synthesis via Adversarial Learning. Req
 146 Nov 25, 2022
146 Nov 25, 2022
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
 279 Dec 9, 2022
279 Dec 9, 2022

Generate vibrant and detailed images using only text.
CLIP Guided Diffusion From RiversHaveWings. Generate vibrant and detailed images using only text. See captions and more generations in the Gallery See
 401 Dec 28, 2022
401 Dec 28, 2022
Deep Unsupervised 3D SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment.
(ACMMM 2021 Oral) SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment This repository shows two tasks: Face landmark detection and Fac
51 Dec 13, 2022
This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab.
Speech-Backbones This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab. Grad-TTS Official implementation of the Grad-
 295 Jan 7, 2023
295 Jan 7, 2023
A curated list of resources for Image and Video Deblurring
A curated list of resources for Image and Video Deblurring
 1.7k Jan 1, 2023
1.7k Jan 1, 2023

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023

Pytorch implementation for reproducing StackGAN_v2 results in the paper StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks
StackGAN-v2 StackGAN-v1: Tensorflow implementation StackGAN-v1: Pytorch implementation Inception score evaluation Pytorch implementation for reproduci
 809 Dec 16, 2022
809 Dec 16, 2022

The pytorch implementation of the paper "text-guided neural image inpainting" at MM'2020
TDANet: Text-Guided Neural Image Inpainting, MM'2020 (Oral) MM | ArXiv This repository implements the paper "Text-Guided Neural Image Inpainting" by L
 75 Dec 22, 2022
75 Dec 22, 2022

Disentangled Lifespan Face Synthesis
Disentangled Lifespan Face Synthesis Project Page | Paper Demo on Colab Preparation Please follow this github to prepare the environments and dataset.
 50 Sep 20, 2022
50 Sep 20, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
 47 Dec 18, 2022
47 Dec 18, 2022
StarGAN-ZSVC: Unofficial PyTorch Implementation
This repository is an unofficial PyTorch implementation of StarGAN-ZSVC by Matthew Baas and Herman Kamper. This repository provides both model architectures and the code to inference or train them.
 11 Aug 28, 2022
11 Aug 28, 2022
QSynthesis is a Python3 API to perform I/O based program synthesis of bitvector expressions.
QSynthesis is a Python3 API to perform I/O based program synthesis of bitvector expressions. It aims at facilitating code deobfuscation. The algorithm is greybox approach combining both a blackbox I/O based synthesis and a whitebox AST search to synthesize sub-expressions
 103 Dec 30, 2022
103 Dec 30, 2022

Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis Implementation
Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis Implementation This project attempted to implement the paper Putting NeRF on a
 254 Dec 27, 2022
254 Dec 27, 2022

PyTorch implementation for SDEdit: Image Synthesis and Editing with Stochastic Differential Equations
SDEdit: Image Synthesis and Editing with Stochastic Differential Equations Project | Paper | Colab PyTorch implementation of SDEdit: Image Synthesis a
 536 Jan 5, 2023
536 Jan 5, 2023
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022

Code for Motion Representations for Articulated Animation paper
Motion Representations for Articulated Animation This repository contains the source code for the CVPR'2021 paper Motion Representations for Articulat
 851 Jan 9, 2023
851 Jan 9, 2023

The personal repository of the work: *DanceNet3D: Music Based Dance Generation with Parametric Motion Transformer*.
DanceNet3D The personal repository of the work: DanceNet3D: Music Based Dance Generation with Parametric Motion Transformer. Dataset and Results Pleas
 36 Dec 21, 2022
36 Dec 21, 2022
Learnable Motion Coherence for Correspondence Pruning
Learnable Motion Coherence for Correspondence Pruning Yuan Liu, Lingjie Liu, Cheng Lin, Zhen Dong, Wenping Wang Project Page Any questions or discussi
 41 Nov 30, 2022
41 Nov 30, 2022

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 170 Jan 4, 2023
170 Jan 4, 2023

Photographic Image Synthesis with Cascaded Refinement Networks - Pytorch Implementation
Photographic Image Synthesis with Cascaded Refinement Networks-Pytorch (https://arxiv.org/abs/1707.09405) This is a Pytorch implementation of cascaded
 63 Mar 27, 2022
63 Mar 27, 2022

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
1.8k Dec 30, 2022

Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
 193 Dec 30, 2022
193 Dec 30, 2022
Deep Two-View Structure-from-Motion Revisited
Deep Two-View Structure-from-Motion Revisited This repository provides the code for our CVPR 2021 paper Deep Two-View Structure-from-Motion Revisited.
 145 Jan 6, 2023
145 Jan 6, 2023

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022
A Flow-based Generative Network for Speech Synthesis
WaveGlow: a Flow-based Generative Network for Speech Synthesis Ryan Prenger, Rafael Valle, and Bryan Catanzaro In our recent paper, we propose WaveGlo
 2k Dec 26, 2022
2k Dec 26, 2022
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
 204 Jul 14, 2022
204 Jul 14, 2022
Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
193 Dec 30, 2022
PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022
efficient neural audio synthesis in the waveform domain
neural waveshaping synthesis real-time neural audio synthesis in the waveform domain paper • website • colab • audio by Ben Hayes, Charalampos Saitis,
 169 Dec 23, 2022
169 Dec 23, 2022

Unofficial Pytorch Implementation of WaveGrad2
WaveGrad 2 — Unofficial PyTorch Implementation WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis Unofficial PyTorch+Lightning Implementati
104 Nov 29, 2022

Motion Planner Augmented Reinforcement Learning for Robot Manipulation in Obstructed Environments (CoRL 2020)
Motion Planner Augmented Reinforcement Learning for Robot Manipulation in Obstructed Environments [Project website] [Paper] This project is a PyTorch
 49 Nov 28, 2022
49 Nov 28, 2022

iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis
iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis Andreas Bl
 36 Dec 25, 2022
36 Dec 25, 2022
Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
MLP Singer Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis. Audio samples are available on our demo page.
 103 Dec 23, 2022
103 Dec 23, 2022

Official implementation of FCL-taco2: Fast, Controllable and Lightweight version of Tacotron2 @ ICASSP 2021
FCL-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech synthesis (ICASSP 2021) Paper | Demo Block diagram of FCL-taco2, where the decode
 39 Sep 28, 2022
39 Sep 28, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
 93 Dec 17, 2022
93 Dec 17, 2022

PyTorch Implementation of NCSOFT's FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
FastPitchFormant - PyTorch Implementation PyTorch Implementation of FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis. Qu
63 Jan 2, 2023

Implementation of "JOKR: Joint Keypoint Representation for Unsupervised Cross-Domain Motion Retargeting"
JOKR: Joint Keypoint Representation for Unsupervised Cross-Domain Motion Retargeting Pytorch implementation for the paper "JOKR: Joint Keypoint Repres
 45 Dec 25, 2022
45 Dec 25, 2022
This is a template for the Non-autoregressive Deep Learning-Based TTS model (in PyTorch).
Non-autoregressive Deep Learning-Based TTS Template This is a template for the Non-autoregressive TTS model. It contains Data Preprocessing Pipeline D
13 Dec 5, 2022
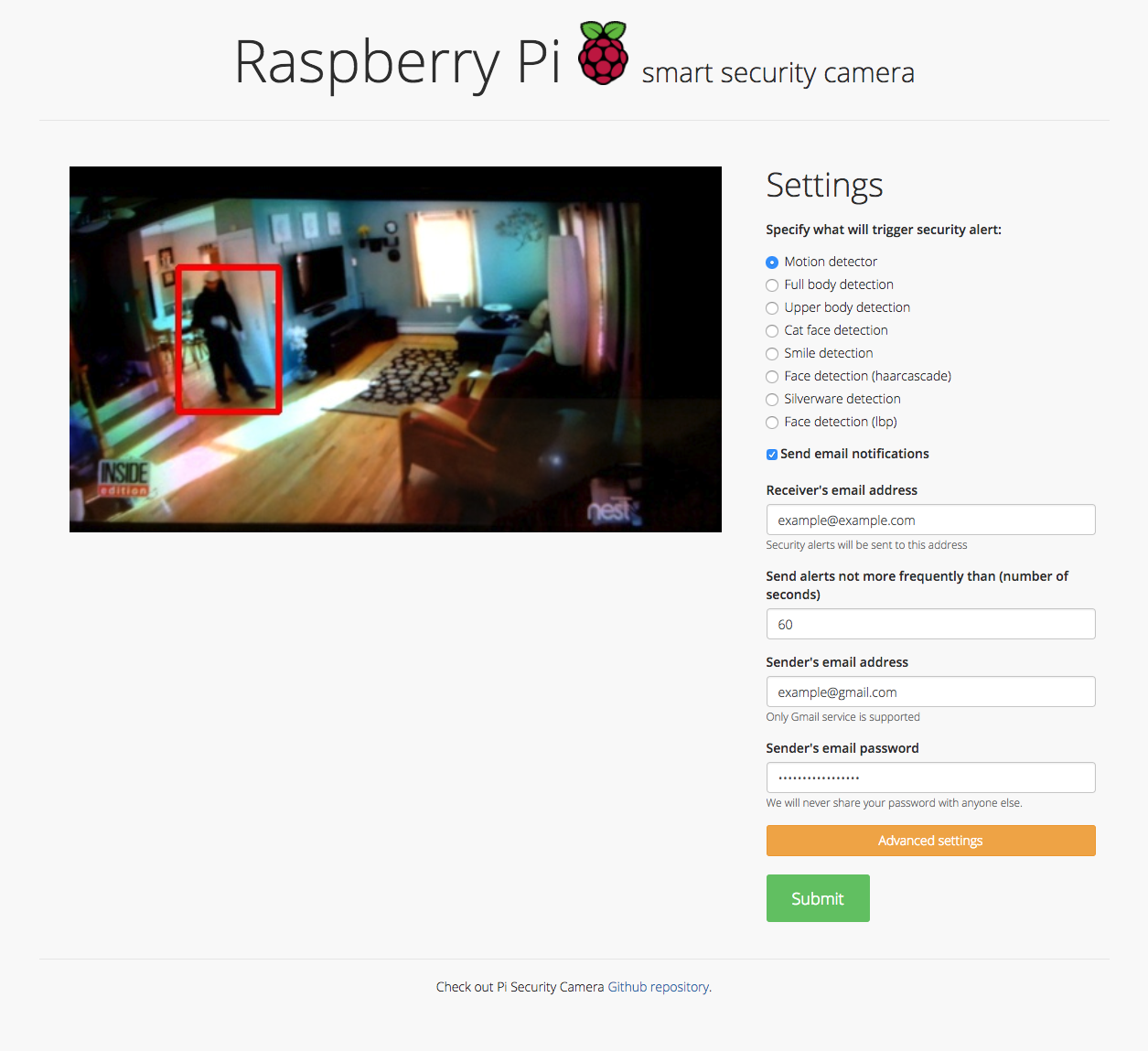
Motion detector, Full body detection, Upper body detection, Cat face detection, Smile detection, Face detection (haar cascade), Silverware detection, Face detection (lbp), and Sending email notifications
Security camera running OpenCV for object and motion detection. The camera will send email with image of any objects it detects. It also runs a server that provides web interface with live stream video.
 10 Jun 30, 2021
10 Jun 30, 2021

This repository contains a PyTorch implementation of "AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis".
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis | Project Page | Paper | PyTorch implementation for the paper "AD-NeRF: Audio
 551 Dec 29, 2022
551 Dec 29, 2022
This repository contains the code for the paper "Hierarchical Motion Understanding via Motion Programs"
Hierarchical Motion Understanding via Motion Programs (CVPR 2021) This repository contains the official implementation of: Hierarchical Motion Underst
 40 Dec 5, 2022
40 Dec 5, 2022
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
 38.5k Jan 3, 2023
38.5k Jan 3, 2023

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
59 Dec 6, 2022

Pytorch implementation of few-shot semantic image synthesis
Few-shot Semantic Image Synthesis Using StyleGAN Prior Our method can synthesize photorealistic images from dense or sparse semantic annotations using
 40 Sep 26, 2022
40 Sep 26, 2022

Code for "CloudAAE: Learning 6D Object Pose Regression with On-line Data Synthesis on Point Clouds" @ICRA2021
CloudAAE This is an tensorflow implementation of "CloudAAE: Learning 6D Object Pose Regression with On-line Data Synthesis on Point Clouds" Files log:
 35 Nov 14, 2022
35 Nov 14, 2022
π-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
π-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis Project Page | Paper | Data Eric Ryan Chan*, Marco Monteiro*, Pe
 375 Dec 31, 2022
375 Dec 31, 2022

Implementation of Diverse Semantic Image Synthesis via Probability Distribution Modeling
Diverse Semantic Image Synthesis via Probability Distribution Modeling (CVPR 2021) Paper Zhentao Tan, Menglei Chai, Dongdong Chen, Jing Liao, Qi Chu,
 45 Nov 17, 2022
45 Nov 17, 2022

Stereo Radiance Fields (SRF): Learning View Synthesis for Sparse Views of Novel Scenes
Stereo Radiance Fields (SRF): Learning View Synthesis for Sparse Views of Novel Scenes
 111 Dec 29, 2022
111 Dec 29, 2022

Waymo motion prediction challenge 2021: 3rd place solution
Waymo motion prediction challenge 2021: 3rd place solution 📜 Technical report 🗨️ Presentation 🎉 Announcement 🛆Motion Prediction Channel Website 🛆
 158 Jan 8, 2023
158 Jan 8, 2023
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. Training python train.py --c
55 Dec 26, 2022

Official PyTorch implementation of "Proxy Synthesis: Learning with Synthetic Classes for Deep Metric Learning" (AAAI 2021)
Proxy Synthesis: Learning with Synthetic Classes for Deep Metric Learning Official PyTorch implementation of "Proxy Synthesis: Learning with Synthetic
 30 Dec 6, 2022
30 Dec 6, 2022
Port Hitsuboku Kumi Chinese CVVC voicebank to deepvocal. / 筆墨クミDeepvocal中文音源
Hitsuboku Kumi (筆墨クミ) is a UTAU virtual singer developed by Cubialpha. This project ports Hitsuboku Kumi Chinese CVVC voicebank to deepvocal. This is the first open-source deepvocal voicebank on Github.
 8 Apr 26, 2022
8 Apr 26, 2022

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
140 Dec 21, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
31 Dec 8, 2022

CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation
CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation (CVPR 2021, oral presentation) CoCosNet v2: Full-Resolution Correspondence
 308 Dec 7, 2022
308 Dec 7, 2022

Intruder detection systems are common place now, and readily available in industry, but how do they work? They must detect people and large animals, but not generate false alarms in the presence of small animals, changes in lighting, environmental motion such as trees, or melting snow. To work correctly, the system must learn the background, in order to differentiate foreground objects.
Intruder-Detection Intruder detection systems are common place now, and readily available in industry, but how do they work? They must detect people a
 4 Jul 18, 2021
4 Jul 18, 2021
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 6, 2023

Neural Factorization of Shape and Reflectance Under An Unknown Illumination
NeRFactor [Paper] [Video] [Project] This is the authors' code release for: NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown I
 283 Jan 4, 2023
283 Jan 4, 2023

Detection of drones using their thermal signatures from thermal camera through YOLO-V3 based CNN with modifications to encapsulate drone motion
Drone Detection using Thermal Signature This repository highlights the work for night-time drone detection using a using an Optris PI Lightweight ther
 6 Dec 31, 2022
6 Dec 31, 2022

Pytorch Implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension)
DiffSinger - PyTorch Implementation PyTorch implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension). Status
152 Jan 2, 2023

Official implementation of the network presented in the paper "M4Depth: A motion-based approach for monocular depth estimation on video sequences"
M4Depth This is the reference TensorFlow implementation for training and testing depth estimation models using the method described in M4Depth: A moti
 76 Jan 3, 2023
76 Jan 3, 2023
[WACV 2020] Reducing Footskate in Human Motion Reconstruction with Ground Contact Constraints
Reducing Footskate in Human Motion Reconstruction with Ground Contact Constraints Official implementation for Reducing Footskate in Human Motion Recon
 38 Nov 1, 2022
38 Nov 1, 2022

PyTorch implementation DRO: Deep Recurrent Optimizer for Structure-from-Motion
DRO: Deep Recurrent Optimizer for Structure-from-Motion This is the official PyTorch implementation code for DRO-sfm. For technical details, please re
 56 Dec 12, 2022
56 Dec 12, 2022

ERISHA is a mulitilingual multispeaker expressive speech synthesis framework. It can transfer the expressivity to the speaker's voice for which no expressive speech corpus is available.
ERISHA: Multilingual Multispeaker Expressive Text-to-Speech Library ERISHA is a multilingual multispeaker expressive speech synthesis framework. It ca
 43 Nov 27, 2022
43 Nov 27, 2022

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
170 Dec 27, 2022
Implementation of Stochastic Image-to-Video Synthesis using cINNs.
Stochastic Image-to-Video Synthesis using cINNs Official PyTorch implementation of Stochastic Image-to-Video Synthesis using cINNs accepted to CVPR202
135 Dec 28, 2022
This is the codebase for Diffusion Models Beat GANS on Image Synthesis.
This is the codebase for Diffusion Models Beat GANS on Image Synthesis.
 3k Dec 26, 2022
3k Dec 26, 2022
NeRF Meta-Learning with PyTorch
NeRF Meta Learning With PyTorch nerf-meta is a PyTorch re-implementation of NeRF experiments from the paper "Learned Initializations for Optimizing Co
 78 Dec 18, 2022
78 Dec 18, 2022

Zero-shot Synthesis with Group-Supervised Learning (ICLR 2021 paper)
GSL - Zero-shot Synthesis with Group-Supervised Learning Figure: Zero-shot synthesis performance of our method with different dataset (iLab-20M, RaFD,
 62 Dec 21, 2022
62 Dec 21, 2022

An implementation of "Optimal Textures: Fast and Robust Texture Synthesis and Style Transfer through Optimal Transport"
Optex An implementation of Optimal Textures: Fast and Robust Texture Synthesis and Style Transfer through Optimal Transport for TU Delft CS4240. You c
 33 Jan 5, 2023
33 Jan 5, 2023
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.0.1 1.1.0 1.2.0 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 ubuntu18/python3.8/pip ubuntu18
 5.9k Jan 3, 2023
5.9k Jan 3, 2023

Unofficial & improved implementation of NeRF--: Neural Radiance Fields Without Known Camera Parameters
[Unofficial code-base] NeRF--: Neural Radiance Fields Without Known Camera Parameters [ Project | Paper | Official code base ] ⬅️ Thanks the original
 239 Dec 22, 2022
239 Dec 22, 2022

Geometry-Free View Synthesis: Transformers and no 3D Priors
Geometry-Free View Synthesis: Transformers and no 3D Priors Geometry-Free View Synthesis: Transformers and no 3D Priors Robin Rombach*, Patrick Esser*
293 Dec 22, 2022

Invert and perturb GAN images for test-time ensembling
GAN Ensembling Project Page | Paper | Bibtex Ensembling with Deep Generative Views. Lucy Chai, Jun-Yan Zhu, Eli Shechtman, Phillip Isola, Richard Zhan
 93 Dec 8, 2022
93 Dec 8, 2022

Official Pytorch implementation of "Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video", CVPR 2021
TCMR: Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video Qualtitative result Paper teaser video Introduction This r
 215 Jan 6, 2023
215 Jan 6, 2023
Synthesizing Long-Term 3D Human Motion and Interaction in 3D in CVPR2021
Long-term-Motion-in-3D-Scenes This is an implementation of the CVPR'21 paper "Synthesizing Long-Term 3D Human Motion and Interaction in 3D". Please ch
 76 Dec 13, 2022
76 Dec 13, 2022
Binaural Speech Synthesis
Binaural Speech Synthesis This repository contains code to train a mono-to-binaural neural sound renderer. If you use this code or the provided datase
 135 Dec 18, 2022
135 Dec 18, 2022
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction.
TalkNet 2 [WIP] TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Predictio
69 Dec 17, 2022
(Arxiv 2021) NeRF--: Neural Radiance Fields Without Known Camera Parameters
NeRF--: Neural Radiance Fields Without Known Camera Parameters Project Page | Arxiv | Colab Notebook | Data Zirui Wang¹, Shangzhe Wu², Weidi Xie², Min
 411 Dec 26, 2022
411 Dec 26, 2022

MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images
Main repo for ECCV 2020 paper MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images. visual.cs.brown.edu/matryodshka
 75 Dec 13, 2022
75 Dec 13, 2022
Learning to Estimate Hidden Motions with Global Motion Aggregation
Learning to Estimate Hidden Motions with Global Motion Aggregation (GMA) This repository contains the source code for our paper: Learning to Estimate
 221 Dec 18, 2022
221 Dec 18, 2022
《Image2Reverb: Cross-Modal Reverb Impulse Response Synthesis》(2021)
Image2Reverb Image2Reverb is an end-to-end neural network that generates plausible audio impulse responses from single images of acoustic environments
 48 Nov 27, 2022
48 Nov 27, 2022
![[arXiv] What-If Motion Prediction for Autonomous Driving ❓🚗💨](https://github.com/wqi/WIMP/raw/master/docs/img/demo.gif)
[arXiv] What-If Motion Prediction for Autonomous Driving ❓🚗💨
WIMP - What If Motion Predictor Reference PyTorch Implementation for What If Motion Prediction [PDF] [Dynamic Visualizations] Setup Requirements The W
 96 Dec 29, 2022
96 Dec 29, 2022
dataset for ECCV 2020 "Motion Capture from Internet Videos"
Motion Capture from Internet Videos Motion Capture from Internet Videos Junting Dong*, Qing Shuai*, Yuanqing Zhang, Xian Liu, Xiaowei Zhou, Hujun Bao
 98 Dec 7, 2022
98 Dec 7, 2022
Code release for NeX: Real-time View Synthesis with Neural Basis Expansion
NeX: Real-time View Synthesis with Neural Basis Expansion Project Page | Video | Paper | COLAB | Shiny Dataset We present NeX, a new approach to novel
 536 Dec 20, 2022
536 Dec 20, 2022
Code release for NeX: Real-time View Synthesis with Neural Basis Expansion
NeX: Real-time View Synthesis with Neural Basis Expansion Project Page | Video | Paper | COLAB | Shiny Dataset We present NeX, a new approach to novel
537 Jan 5, 2023

When Age-Invariant Face Recognition Meets Face Age Synthesis: A Multi-Task Learning Framework (CVPR 2021 oral)
MTLFace This repository contains the PyTorch implementation and the dataset of the paper: When Age-Invariant Face Recognition Meets Face Age Synthesis
 120 Jan 5, 2023
120 Jan 5, 2023

Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
English | 简体中文 Introduction PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools that help users train better models and a
 27.5k Jan 8, 2023
27.5k Jan 8, 2023
TensorFlowTTS: Real-Time State-of-the-art Speech Synthesis for Tensorflow 2 (supported including English, Korean, Chinese, German and Easy to adapt for other languages)
🤪 TensorFlowTTS provides real-time state-of-the-art speech synthesis architectures such as Tacotron-2, Melgan, Multiband-Melgan, FastSpeech, FastSpeech2 based-on TensorFlow 2. With Tensorflow 2, we can speed-up training/inference progress, optimizer further by using fake-quantize aware and pruning, make TTS models can be run faster than real-time and be able to deploy on mobile devices or embedded systems.
 3k Jan 4, 2023
3k Jan 4, 2023
Character Controllers using Motion VAEs
Character Controllers using Motion VAEs This repo is the codebase for the SIGGRAPH 2020 paper with the title above. Please find the paper and demo at
 165 Jan 3, 2023
165 Jan 3, 2023

DeFMO: Deblurring and Shape Recovery of Fast Moving Objects (CVPR 2021)
Evaluation, Training, Demo, and Inference of DeFMO DeFMO: Deblurring and Shape Recovery of Fast Moving Objects (CVPR 2021) Denys Rozumnyi, Martin R. O
 139 Dec 26, 2022
139 Dec 26, 2022
![[CVPR 2021] Anycost GANs for Interactive Image Synthesis and Editing](https://github.com/mit-han-lab/anycost-gan/raw/master/assets/figures/demo.gif)
[CVPR 2021] Anycost GANs for Interactive Image Synthesis and Editing
Anycost GAN video | paper | website Anycost GANs for Interactive Image Synthesis and Editing Ji Lin, Richard Zhang, Frieder Ganz, Song Han, Jun-Yan Zh
 726 Dec 28, 2022
726 Dec 28, 2022

Object Depth via Motion and Detection Dataset
ODMD Dataset ODMD is the first dataset for learning Object Depth via Motion and Detection. ODMD training data are configurable and extensible, with ea
 172 Dec 21, 2022
172 Dec 21, 2022
Marsyas - Music Analysis, Retrieval and Synthesis for Audio Signals
Welcome to MARSYAS. MARSYAS is a software framework for rapid prototyping of audio applications, with flexibility and extensibility as primary concer
 364 Oct 31, 2022
364 Oct 31, 2022