1649 Repositories
Python natural-language-processing Libraries

In-memory Graph Database and Knowledge Graph with Natural Language Interface, compatible with Pandas
CogniPy for Pandas - In-memory Graph Database and Knowledge Graph with Natural Language Interface Whats in the box Reasoning, exploration of RDF/OWL,
 34 Dec 13, 2022
34 Dec 13, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 9 Dec 11, 2021
9 Dec 11, 2021
In this project, we'll be creating a virtual personal assistant for ourselves using our favorite programming language
In this project, we'll be creating a virtual personal assistant for ourselves using our favorite programming language, Python. We can perform several offline as well as online operations using the bot.
 188 Jan 3, 2023
188 Jan 3, 2023

Goal: Enable awesome tooling for Bazel users of the C language family.
Hedron's Compile Commands Extractor for Bazel — User Interface What is this project trying to do for me? First, provide Bazel users cross-platform aut
 290 Dec 26, 2022
290 Dec 26, 2022
A setup script to generate ITK Python Wheels
ITK Python Package This project provides a setup.py script to build ITK Python binary packages and infrastructure to build ITK external module Python
 59 Dec 14, 2022
59 Dec 14, 2022
Code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language"
The repository provides the source code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language" submitted to HA
 3 Aug 4, 2022
3 Aug 4, 2022
Validation and inference over LinkML instance data using souffle
Translates LinkML schemas into Datalog programs and executes them using Souffle, enabling advanced validation and inference over instance data
 7 Aug 7, 2022
7 Aug 7, 2022

A concise grammar of interactive graphics, built on Vega.
Vega-Lite Vega-Lite provides a higher-level grammar for visual analysis that generates complete Vega specifications. You can find more details, docume
 4k Jan 8, 2023
4k Jan 8, 2023
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce (EMNLP Founding 2021)
Introduction K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce. Installation PyTor
 21 Nov 16, 2022
21 Nov 16, 2022

RuleBERT: Teaching Soft Rules to Pre-Trained Language Models
RuleBERT: Teaching Soft Rules to Pre-Trained Language Models (Paper) (Slides) (Video) RuleBERT is a pre-trained language model that has been fine-tune
 16 Aug 24, 2022
16 Aug 24, 2022

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
 226 Dec 7, 2022
226 Dec 7, 2022
Tools for computational pathology
A toolkit for computational pathology and machine learning. View documentation Please cite our paper Installation There are several ways to install Pa
 254 Dec 12, 2022
254 Dec 12, 2022

State-of-the-art NLP through transformer models in a modular design and consistent APIs.
Trapper (Transformers wRAPPER) Trapper is an NLP library that aims to make it easier to train transformer based models on downstream tasks. It wraps h
 42 Sep 21, 2022
42 Sep 21, 2022
This repository implements a brute-force spellchecker utilizing the Damerau-Levenshtein edit distance.
About spellchecker.py Implementing a highly-accurate, brute-force, and dynamically programmed spellchecking program that utilizes the Damerau-Levensht
 1 Dec 11, 2021
1 Dec 11, 2021
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
 922 Dec 10, 2021
922 Dec 10, 2021

CALVIN - A benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks
CALVIN CALVIN - A benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks Oier Mees, Lukas Hermann, Erick Rosete,
 107 Dec 26, 2022
107 Dec 26, 2022

Hashformers is a framework for hashtag segmentation with transformers.
Hashtag segmentation is the task of automatically inserting the missing spaces between the words in a hashtag. Hashformers applies Transformer models
 41 Nov 9, 2022
41 Nov 9, 2022
Suite of 500 procedurally-generated NLP tasks to study language model adaptability
TaskBench500 The TaskBench500 dataset and code for generating tasks. Data The TaskBench dataset is available under wget http://web.mit.edu/bzl/www/Tas
 20 May 17, 2022
20 May 17, 2022

Meandering In Networks of Entities to Reach Verisimilar Answers
MINERVA Meandering In Networks of Entities to Reach Verisimilar Answers Code and models for the paper Go for a Walk and Arrive at the Answer - Reasoni
 271 Dec 13, 2022
271 Dec 13, 2022

GLIP: Grounded Language-Image Pre-training
GLIP: Grounded Language-Image Pre-training Updates 12/06/2021: GLIP paper on arxiv https://arxiv.org/abs/2112.03857. Code and Model are under internal
 862 Jan 1, 2023
862 Jan 1, 2023

Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand
Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand Introduction We propose a generalization of leaderboards, bidimensional leader
 4 Dec 3, 2022
4 Dec 3, 2022
Suite of 500 procedurally-generated NLP tasks to study language model adaptability
TaskBench500 The TaskBench500 dataset and code for generating tasks. Data The TaskBench dataset is available under wget http://web.mit.edu/bzl/www/Tas
20 May 17, 2022
![[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining](https://github.com/microsoft/COCO-LM/raw/main/coco-lm.png)
[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
COCO-LM This repository contains the scripts for fine-tuning COCO-LM pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: COCO-LM: Correcting an
106 Dec 12, 2022
An ongoing curated list of frameworks, libraries, learning tutorials, software and resources in Python Language.
Python Development Welcome to the world of Python. An ongoing curated list of frameworks, libraries, learning tutorials, software and resources in Pyt
 2 Dec 24, 2021
2 Dec 24, 2021
A python server markup language
PSML - Python server markup language How to install: python install.py
 6 May 18, 2022
6 May 18, 2022

Free Vocabulary Trainer - not only for German, but any language
Bilderraten DOWNLOAD THE EXE FILE HERE! What can you do with it? Vocabulary Trainer for any language Use your own vocabulary list No coding required!
 4 Jan 2, 2023
4 Jan 2, 2023

Two factor authentication system using azure services and python language and its api's
FUTURE READY TALENT VIRTUAL INTERSHIP PROJECT PROJECT NAME - TWO FACTOR AUTHENTICATION SYSTEM Resources used: * Azure functions(python)
 1 Dec 10, 2021
1 Dec 10, 2021
Functions to analyze Cell-ID single-cell cytometry data using python language.
PyCellID (building...) Functions to analyze Cell-ID single-cell cytometry data using python language. Dependecies for this project. attrs(=21.1.0) fo
 0 Dec 22, 2021
0 Dec 22, 2021
The easiest tool for extracting radiomics features and training ML models on them.
Simple pipeline for experimenting with radiomics features Installation git clone https://github.com/piotrekwoznicki/ClassyRadiomics.git cd classrad pi
 17 Aug 4, 2022
17 Aug 4, 2022

A time series processing library
Timeseria Timeseria is a time series processing library which aims at making it easy to handle time series data and to build statistical and machine l
 11 Aug 8, 2022
11 Aug 8, 2022
Data pipelines for both TensorFlow and PyTorch!
rapidnlp-datasets Data pipelines for both TensorFlow and PyTorch ! If you want to load public datasets, try: tensorflow/datasets huggingface/datasets
 1 Dec 8, 2021
1 Dec 8, 2021

Tensorflow implementation of Character-Aware Neural Language Models.
Character-Aware Neural Language Models Tensorflow implementation of Character-Aware Neural Language Models. The original code of author can be found h
 751 Dec 26, 2022
751 Dec 26, 2022

Translate darknet to tensorflow. Load trained weights, retrain/fine-tune using tensorflow, export constant graph def to mobile devices
Intro Real-time object detection and classification. Paper: version 1, version 2. Read more about YOLO (in darknet) and download weight files here. In
 6.1k Dec 30, 2022
6.1k Dec 30, 2022
A python script for extracting/removing exif data from images by @AbirHasan2005
Image-Exif A Python script for extracting exif metadata from images. How to use? Using this script you can extract exif data from image and save in .c
 13 Dec 16, 2022
13 Dec 16, 2022
A design of MIDI language for music generation task, specifically for Natural Language Processing (NLP) models.
MIDI Language Introduction Reference Paper: Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions: code This
 3 May 25, 2022
3 May 25, 2022
Dragon Age: Origins toolset to extract/build .erf files, patch language-specific .dlg files, and view the contents of files in the ERF or GFF format
DAOTools This is a set of tools for Dragon Age: Origins modding. It can patch the text lines of .dlg files, extract and build an .erf file, and view t
 8 Dec 6, 2022
8 Dec 6, 2022
DG - A(n) (unusual) programming language
DG - A(n) (unusual) programming language General structure There are no infix-operators (i.e. 1 + 1) Each operator takes 2 parameters When there are m
 1 Mar 5, 2022
1 Mar 5, 2022
The Codebase for Causal Distillation for Language Models.
Causal Distillation for Language Models Zhengxuan Wu*,Atticus Geiger*, Josh Rozner, Elisa Kreiss, Hanson Lu, Thomas Icard, Christopher Potts, Noah D.
 20 Dec 31, 2022
20 Dec 31, 2022

Steerable discovery of neural audio effects
Steerable discovery of neural audio effects Christian J. Steinmetz and Joshua D. Reiss Abstract Applications of deep learning for audio effects often
 182 Dec 29, 2022
182 Dec 29, 2022
NL-Augmenter 🦎 → 🐍 A Collaborative Repository of Natural Language Transformations
NL-Augmenter 🦎 → 🐍 The NL-Augmenter is a collaborative effort intended to add transformations of datasets dealing with natural language. Transformat
 684 Jan 9, 2023
684 Jan 9, 2023
Train and use generative text models in a few lines of code.
blather Train and use generative text models in a few lines of code. To see blather in action check out the colab notebook! Installation Use the packa
 16 Nov 7, 2022
16 Nov 7, 2022

A simple tool made in Python language
Simple tool Uma simples ferramenta feita 100% em linguagem Python 💻 Requisitos: Python3 instalado em seu dispositivo Clonagem e acesso 📳 git clone h
 4 Dec 7, 2021
4 Dec 7, 2021

Object Detection with YOLOv3
Object Detection with YOLOv3 Bu projede YOLOv3-608 modeli kullanılmıştır. Requirements Python 3.8 OpenCV Numpy Documentation Yolo ile ilgili detaylı b
 0 Mar 27, 2022
0 Mar 27, 2022

ColorController is a Pythonic interface for managing colors by english-language name and various color values.
ColorController.py Table of Contents Encode color data in various formats. 1.1: Create a ColorController object using a familiar, english-language col
 2 Feb 12, 2022
2 Feb 12, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
0 Mar 20, 2022
HTSeq is a Python library to facilitate processing and analysis of data from high-throughput sequencing (HTS) experiments.
HTSeq DEVS: https://github.com/htseq/htseq DOCS: https://htseq.readthedocs.io A Python library to facilitate programmatic analysis of data from high-t
 57 Dec 20, 2022
57 Dec 20, 2022

A visual dataflow programming language for sklearn
Persimmon What is it? Persimmon is a visual dataflow language for creating sklearn pipelines. It represents functions as blocks, inputs and outputs ar
 194 Jan 4, 2023
194 Jan 4, 2023

Stenography encryption script
ImageCrypt Project description Installation Usage Project description Project AlexGyver on Python by TheK4n Design by Пашушка Byte packing in decimal
 5 Dec 14, 2022
5 Dec 14, 2022
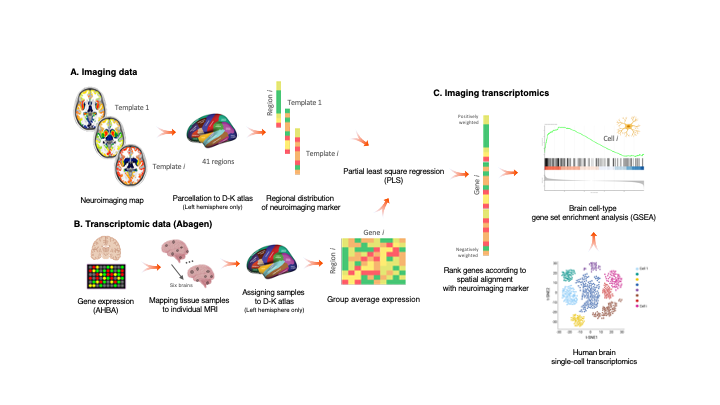
A package, and script, to perform imaging transcriptomics on a neuroimaging scan.
Imaging Transcriptomics Imaging transcriptomics is a methodology that allows to identify patterns of correlation between gene expression and some prop
 10 Dec 27, 2022
10 Dec 27, 2022

The functions we created are included in a script. The necessary parts for pre-processing were taken. Analysis complete.
Feature-Engineering The functions we created are included in a script. The necessary parts for pre-processing were taken. Analysis complete. Business
 4 Oct 17, 2021
4 Oct 17, 2021
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022

A programming language written with python
Kaoft A programming language written with python How to use A simple Hello World: c="Hello World" c Output: "Hello World" Operators: a=12
 1 Jan 24, 2022
1 Jan 24, 2022

This repository provides code for "On Interaction Between Augmentations and Corruptions in Natural Corruption Robustness".
On Interaction Between Augmentations and Corruptions in Natural Corruption Robustness This repository provides the code for the paper On Interaction B
 33 Dec 8, 2022
33 Dec 8, 2022
A project to make Amazon Echo respond to sign language using your webcam
Making Alexa respond to Sign Language using Tensorflow.js Try the live demo Read the Blog Post on Tensorflow's Blog Coming Soon Watch the video This p
 444 Jan 3, 2023
444 Jan 3, 2023
Natural Language Processing Tasks and Examples.
Natural Language Processing Tasks and Examples With the advancement of A.I. technology in recent years, natural language processing technology has bee
 53 Dec 20, 2022
53 Dec 20, 2022
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022
you can add any codes in any language by creating its respective folder (if already not available).
HACKTOBERFEST-2021-WEB-DEV Beginner-Hacktoberfest Need Your first pr for hacktoberfest 2k21 ? come on in About This is repository of Responsive Portfo
 8 Oct 17, 2022
8 Oct 17, 2022
Small C-like language compiler for the Uxn assembly language
Pyuxncle is a single-pass compiler for a small subset of C (albeit without the std library). This compiler targets Uxntal, the assembly language of the Uxn virtual computer. The output Uxntal is not meant to be human readable, only to be directly passed to uxnasm.
 13 Jun 28, 2022
13 Jun 28, 2022
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
 303 Dec 17, 2022
303 Dec 17, 2022
GPT-3: Language Models are Few-Shot Learners
GPT-3: Language Models are Few-Shot Learners arXiv link Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-trainin
 12.5k Jan 5, 2023
12.5k Jan 5, 2023

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
 463 Dec 30, 2022
463 Dec 30, 2022
MPNet: Masked and Permuted Pre-training for Language Understanding
MPNet MPNet: Masked and Permuted Pre-training for Language Understanding, by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu, is a novel pre-tr
228 Nov 21, 2022
Optimus: the first large-scale pre-trained VAE language model
Optimus: the first pre-trained Big VAE language model This repository contains source code necessary to reproduce the results presented in the EMNLP 2
 314 Dec 19, 2022
314 Dec 19, 2022
(ACL-IJCNLP 2021) Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models.
BERT Convolutions Code for the paper Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models. Contains expe
 21 Jul 18, 2022
21 Jul 18, 2022
Source code and dataset for ACL 2019 paper "ERNIE: Enhanced Language Representation with Informative Entities"
ERNIE Source code and dataset for "ERNIE: Enhanced Language Representation with Informative Entities" Reqirements: Pytorch=0.4.1 Python3 tqdm boto3 r
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph",
K-BERT Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph", which is implemented based on the UER framework. R
 834 Jan 9, 2023
834 Jan 9, 2023
LUKE -- Language Understanding with Knowledge-based Embeddings
LUKE (Language Understanding with Knowledge-based Embeddings) is a new pre-trained contextualized representation of words and entities based on transf
 587 Dec 30, 2022
587 Dec 30, 2022
Source code for TACL paper "KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation".
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation Source code for TACL 2021 paper KEPLER: A Unified Model for Kn
 138 Dec 22, 2022
138 Dec 22, 2022
Code for the ACL 2021 paper "Structural Guidance for Transformer Language Models"
Structural Guidance for Transformer Language Models This repository accompanies the paper, Structural Guidance for Transformer Language Models, publis
 10 Dec 14, 2022
10 Dec 14, 2022
Research code for the paper "How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models"
Introduction This repository contains research code for the ACL 2021 paper "How Good is Your Tokenizer? On the Monolingual Performance of Multilingual
 20 Aug 4, 2022
20 Aug 4, 2022

Code for ICLR 2020 paper "VL-BERT: Pre-training of Generic Visual-Linguistic Representations".
VL-BERT By Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. This repository is an official implementation of the paper VL-BERT:
 698 Dec 18, 2022
698 Dec 18, 2022
Vision-Language Pre-training for Image Captioning and Question Answering
VLP This repo hosts the source code for our AAAI2020 work Vision-Language Pre-training (VLP). We have released the pre-trained model on Conceptual Cap
 373 Jan 3, 2023
373 Jan 3, 2023
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
938 Dec 26, 2022

Research Code for NeurIPS 2020 Spotlight paper "Large-Scale Adversarial Training for Vision-and-Language Representation Learning": UNITER adversarial training part
VILLA: Vision-and-Language Adversarial Training This is the official repository of VILLA (NeurIPS 2020 Spotlight). This repository currently supports
 109 Dec 31, 2022
109 Dec 31, 2022

Contrastive Language-Image Pretraining
CLIP [Blog] [Paper] [Model Card] [Colab] CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pair
11.5k Jan 8, 2023

DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting Created by Yongming Rao*, Wenliang Zhao*, Guangyi Chen, Yansong Tang, Zheng Z
 322 Dec 31, 2022
322 Dec 31, 2022
Learn to code in any language. If
Learn to Code It is an intiiative undertaken by Student Ambassadors Club, Jamshoro for students who are absolute begineers in programming and want to
 15 Oct 19, 2022
15 Oct 19, 2022
The worst and slowest programming language you have ever seen
VenumLang this is a complete joke EXAMPLE: fizzbuzz in venumlang x = 0
 7 Mar 12, 2022
7 Mar 12, 2022
Makes google's political ad database actually useful
Making Google's political ad transparency library suck less This is a series of scripts that takes Google's political ad transparency data and makes t
 7 Apr 28, 2022
7 Apr 28, 2022
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting Created by Yongming Rao*, Wenliang Zhao*, Guangyi Chen, Yansong Tang, Zheng Z
321 Dec 27, 2022
Advent of Code is an Advent calendar of small programming puzzles for a variety of skill sets and skill levels that can be solved in any programming language you like.
Advent Of Code 2021 - Python English Advent of Code is an Advent calendar of small programming puzzles for a variety of skill sets and skill levels th
 2 Jan 9, 2022
2 Jan 9, 2022

Modified GPT using average pooling to reduce the softmax attention memory constraints.
NLP-GPT-Upsampling This repository contains an implementation of Open AI's GPT Model. In particular, this implementation takes inspiration from the Ny
 1 Dec 3, 2021
1 Dec 3, 2021
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
Tools for curating biomedical training data for large-scale language modeling
Tools for curating biomedical training data for large-scale language modeling
 242 Dec 25, 2022
242 Dec 25, 2022
Implementation of the paper 'Sentence Bottleneck Autoencoders from Transformer Language Models'
Introduction This repository contains the code for the paper Sentence Bottleneck Autoencoders from Transformer Language Models by Ivan Montero, Nikola
 14 Dec 28, 2022
14 Dec 28, 2022
BERTAC (BERT-style transformer-based language model with Adversarially pretrained Convolutional neural network)
BERTAC (BERT-style transformer-based language model with Adversarially pretrained Convolutional neural network) BERTAC is a framework that combines a
 6 Jan 24, 2022
6 Jan 24, 2022
Diagnostic tests for linguistic capacities in language models
LM diagnostics This repository contains the diagnostic datasets and experimental code for What BERT is not: Lessons from a new suite of psycholinguist
 61 Jan 2, 2023
61 Jan 2, 2023

Language model Prompt And Query Archive
LPAQA: Language model Prompt And Query Archive This repository contains data and code for the paper How Can We Know What Language Models Know? Install
 127 Dec 20, 2022
127 Dec 20, 2022
Code for Editing Factual Knowledge in Language Models
KnowledgeEditor Code for Editing Factual Knowledge in Language Models (https://arxiv.org/abs/2104.08164). @inproceedings{decao2021editing, title={Ed
 86 Nov 28, 2022
86 Nov 28, 2022
Code for ACL2021 long paper: Knowledgeable or Educated Guess? Revisiting Language Models as Knowledge Bases
LANKA This is the source code for paper: Knowledgeable or Educated Guess? Revisiting Language Models as Knowledge Bases (ACL 2021, long paper) Referen
 30 Oct 24, 2022
30 Oct 24, 2022
A Model for Natural Language Attack on Text Classification and Inference
TextFooler A Model for Natural Language Attack on Text Classification and Inference This is the source code for the paper: Jin, Di, et al. "Is BERT Re
 418 Dec 16, 2022
418 Dec 16, 2022

The official implementation of "BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?, ACL 2021 main conference"
BERT is to NLP what AlexNet is to CV This is the official implementation of BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Iden
 20 Nov 3, 2022
20 Nov 3, 2022
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
ALBERT ***************New March 28, 2020 *************** Add a colab tutorial to run fine-tuning for GLUE datasets. ***************New January 7, 2020
 3k Jan 1, 2023
3k Jan 1, 2023
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization (ACL 2021)
Structured Super Lottery Tickets in BERT This repo contains our codes for the paper "Super Tickets in Pre-Trained Language Models: From Model Compress
 16 Dec 11, 2022
16 Dec 11, 2022
Pretrained language model and its related optimization techniques developed by Huawei Noah's Ark Lab.
Pretrained Language Model This repository provides the latest pretrained language models and its related optimization techniques developed by Huawei N
 2.6k Jan 1, 2023
2.6k Jan 1, 2023

Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators This is our Pytorch implementation for t
 12 Jul 22, 2022
12 Jul 22, 2022
Code associated with the Don't Stop Pretraining ACL 2020 paper
dont-stop-pretraining Code associated with the Don't Stop Pretraining ACL 2020 paper Citation @inproceedings{dontstoppretraining2020, author = {Suchi
 449 Jan 4, 2023
449 Jan 4, 2023