1603 Repositories
Python nlp-language-identification Libraries
Deep learning for NLP crash course at ABBYY.
Deep NLP Course at ABBYY Deep learning for NLP crash course at ABBYY. Suggested textbook: Neural Network Methods in Natural Language Processing by Yoa
 597 Dec 18, 2022
597 Dec 18, 2022
nlp-tutorial is a tutorial for who is studying NLP(Natural Language Processing) using Pytorch
nlp-tutorial is a tutorial for who is studying NLP(Natural Language Processing) using Pytorch. Most of the models in NLP were implemented with less than 100 lines of code.(except comments or blank lines)
 11.9k Jan 8, 2023
11.9k Jan 8, 2023
Transpiler for Excel formula like language to Python. Support script and module mode
Transpiler for Excel formula like language to Python. Support script and module mode (formulas are functions).
 1 Dec 7, 2021
1 Dec 7, 2021

Biterm Topic Model (BTM): modeling topics in short texts
Biterm Topic Model Bitermplus implements Biterm topic model for short texts introduced by Xiaohui Yan, Jiafeng Guo, Yanyan Lan, and Xueqi Cheng. Actua
 49 Dec 30, 2022
49 Dec 30, 2022

Binary LSTM model for text classification
Text Classification The purpose of this repository is to create a neural network model of NLP with deep learning for binary classification of texts re
 1 Mar 11, 2022
1 Mar 11, 2022
AI-powered literature discovery and review engine for medical/scientific papers
AI-powered literature discovery and review engine for medical/scientific papers paperai is an AI-powered literature discovery and review engine for me
 819 Dec 30, 2022
819 Dec 30, 2022
A simple pygame implementation of the LOGO programming language.
LOGO-py A simple pygame implementation of the LOGO programming language. Latest Version Notes Fixed a bug where penup/pendown would not work properly.
 1 Dec 5, 2021
1 Dec 5, 2021
topic modeling on unstructured data in Space news articles retrieved from the Guardian (UK) newspaper using API
NLP Space News Topic Modeling Photos by nasa.gov (1, 2, 3, 4, 5) and extremetech.com Table of Contents Project Idea Data acquisition Primary data sour
 1 Jan 3, 2022
1 Jan 3, 2022
Automated Machine Learning Pipeline for tabular data. Designed for predictive maintenance applications, failure identification, failure prediction, condition monitoring, etc.
Automated Machine Learning Pipeline for tabular data. Designed for predictive maintenance applications, failure identification, failure prediction, condition monitoring, etc.
 10 May 15, 2022
10 May 15, 2022

This project uses unsupervised machine learning to identify correlations between daily inoculation rates in the USA and twitter sentiment in regards to COVID-19.
Twitter COVID-19 Sentiment Analysis Members: Christopher Bach | Khalid Hamid Fallous | Jay Hirpara | Jing Tang | Graham Thomas | David Wetherhold Pro
 4 Oct 15, 2022
4 Oct 15, 2022
Taichi is a parallel programming language for high-performance numerical computations.
Taichi is a parallel programming language for high-performance numerical computations.
 22k Jan 4, 2023
22k Jan 4, 2023

Conversational text Analysis using various NLP techniques
Conversational text Analysis using various NLP techniques
 159 Jan 6, 2023
159 Jan 6, 2023
Politecnico of Turin Thesis: "Implementation and Evaluation of an Educational Chatbot based on NLP Techniques"
THESIS_CAIRONE_FIORENTINO Politecnico of Turin Thesis: "Implementation and Evaluation of an Educational Chatbot based on NLP Techniques" GENERATE TOKE
 1 Dec 10, 2021
1 Dec 10, 2021
The implementation of DeBERTa
DeBERTa: Decoding-enhanced BERT with Disentangled Attention This repository is the official implementation of DeBERTa: Decoding-enhanced BERT with Dis
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
A pre-trained language model for social media text in Spanish
RoBERTuito A pre-trained language model for social media text in Spanish READ THE FULL PAPER Github Repository RoBERTuito is a pre-trained language mo
 25 Dec 29, 2022
25 Dec 29, 2022
A number of methods in order to perform Natural Language Processing on live data derived from Twitter
A number of methods in order to perform Natural Language Processing on live data derived from Twitter
 1 Nov 24, 2021
1 Nov 24, 2021
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
 1.4k Jan 4, 2023
1.4k Jan 4, 2023
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 A repository part of the MarIA project. Corpora 📃 Corpora Number of documents Number of tokens Size (GB) BNE 201,080,084
 203 Dec 20, 2022
203 Dec 20, 2022
Maha is a text processing library specially developed to deal with Arabic text.
An Arabic text processing library intended for use in NLP applications Maha is a text processing library specially developed to deal with Arabic text.
 184 Nov 27, 2022
184 Nov 27, 2022
Code for text augmentation method leveraging large-scale language models
HyperMix Code for our paper GPT3Mix and conducting classification experiments using GPT-3 prompt-based data augmentation. Getting Started Installing P
 47 Dec 20, 2022
47 Dec 20, 2022
Eros is an expiremental programming language built using simple Python code.
Eros is an expiremental programming language built using simple Python code. Featuring an easy syntax and unique features like type slicing, the language remains an expirement that grows in down time.
 2 Nov 21, 2021
2 Nov 21, 2021
Code for training and evaluation of the model from "Language Generation with Recurrent Generative Adversarial Networks without Pre-training"
Language Generation with Recurrent Generative Adversarial Networks without Pre-training Code for training and evaluation of the model from "Language G
 253 Sep 14, 2022
253 Sep 14, 2022
Exemplary lightweight and ready-to-deploy machine learning project
Exemplary lightweight and ready-to-deploy machine learning project
 6 Dec 20, 2022
6 Dec 20, 2022
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding This repo contains the data and source code for baseline models in the NeurIPS 2
10 Nov 17, 2021
An experimental Python-to-C transpiler and domain specific language for embedded high-performance computing
An experimental Python-to-C transpiler and domain specific language for embedded high-performance computing
 562 Dec 28, 2022
562 Dec 28, 2022

🛠️ Tools for Transformers compression using Lightning ⚡
Bert-squeeze is a repository aiming to provide code to reduce the size of Transformer-based models or decrease their latency at inference time.
 66 Dec 11, 2022
66 Dec 11, 2022

 1.2k Dec 26, 2022
1.2k Dec 26, 2022
Python library for Serbian Natural language processing (NLP)
SrbAI - Python biblioteka za procesiranje srpskog jezika SrbAI je projekat prikupljanja algoritama i modela za procesiranje srpskog jezika u jedinstve
 3 Nov 22, 2022
3 Nov 22, 2022

PESTO: Switching Point based Dynamic and Relative Positional Encoding for Code-Mixed Languages
PESTO: Switching Point based Dynamic and Relative Positional Encoding for Code-Mixed Languages Abstract NLP applications for code-mixed (CM) or mix-li
 1 Nov 12, 2021
1 Nov 12, 2021
Extracting and filtering paraphrases by bridging natural language inference and paraphrasing
nli2paraphrases Source code repository accompanying the preprint Extracting and filtering paraphrases by bridging natural language inference and parap
 1 Mar 9, 2022
1 Mar 9, 2022

Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition | paper | dataset | pretrained detection model | Authors: Yi-Chang Che
 1 Aug 23, 2022
1 Aug 23, 2022
Improving the robustness and performance of biomedical NLP models through adversarial training
RobustBioNLP Improving the robustness and performance of biomedical NLP models through adversarial training In this repository you can find suppliment
 3 Sep 20, 2022
3 Sep 20, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE: A Benchmark Suite for Data-centric NLP You can get the english version of README. 以数据为中心的AI测评(DataCLUE) 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE
 135 Dec 22, 2022
135 Dec 22, 2022
Extracting knowledge graphs from language models as a diagnostic benchmark of model performance.
Interpreting Language Models Through Knowledge Graph Extraction Idea: How do we interpret what a language model learns at various stages of training?
 9 Oct 25, 2022
9 Oct 25, 2022
Source code for our EMNLP'21 paper 《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》
Child-Tuning Source code for EMNLP 2021 Long paper: Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning. 1. Environ
 46 Dec 12, 2022
46 Dec 12, 2022

TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning
TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning Authors: Yixuan Su, Fangyu Liu, Zaiqiao Meng, Lei Shu, Ehsan Shareghi, and Nig
 21 Nov 17, 2021
21 Nov 17, 2021
AfriBERTa: Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages
AfriBERTa: Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages This repository contains the code for the pa
 40 Nov 24, 2022
40 Nov 24, 2022
Voice helper on russian
Voice helper on russian
 1 Jun 30, 2022
1 Jun 30, 2022
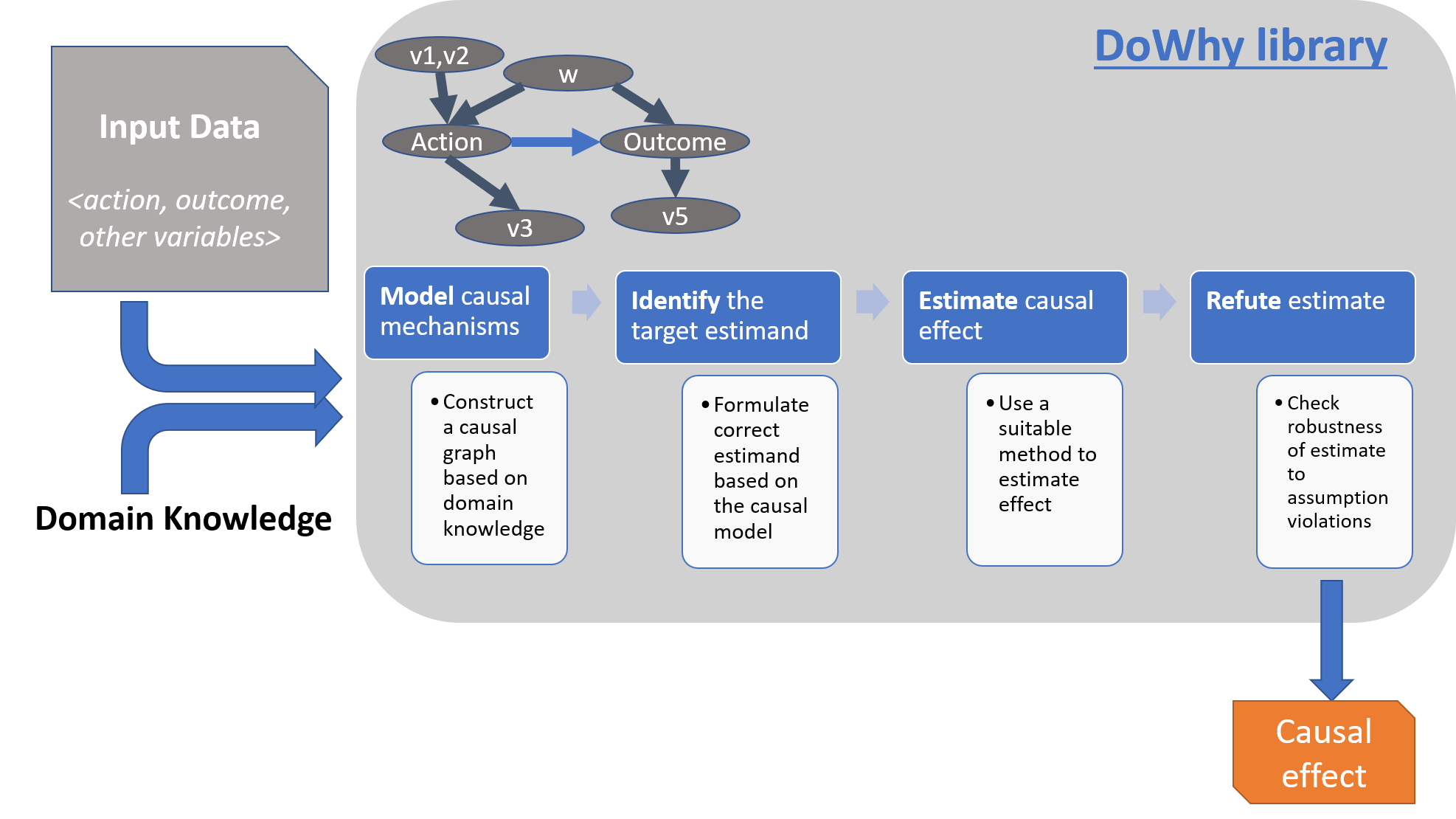
DoWhy is a Python library for causal inference that supports explicit modeling and testing of causal assumptions. DoWhy is based on a unified language for causal inference, combining causal graphical models and potential outcomes frameworks.
DoWhy | An end-to-end library for causal inference Amit Sharma, Emre Kiciman Introducing DoWhy and the 4 steps of causal inference | Microsoft Researc
5.6k Jan 7, 2023
moDel Agnostic Language for Exploration and eXplanation
moDel Agnostic Language for Exploration and eXplanation Overview Unverified black box model is the path to the failure. Opaqueness leads to distrust.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
CVXPY is a Python-embedded modeling language for convex optimization problems.
CVXPY The CVXPY documentation is at cvxpy.org. We are building a CVXPY community on Discord. Join the conversation! For issues and long-form discussio
 4.3k Jan 8, 2023
4.3k Jan 8, 2023
🚪✊Knock Knock: Get notified when your training ends with only two additional lines of code
Knock Knock A small library to get a notification when your training is complete or when it crashes during the process with two additional lines of co
 2.5k Jan 7, 2023
2.5k Jan 7, 2023
Python package for Turkish Language.
PyTurkce Python package for Turkish Language. Documentation: https://pyturkce.readthedocs.io. Installation pip install pyturkce Usage from pyturkce im
 14 Oct 9, 2022
14 Oct 9, 2022
A combination of autoregressors and autoencoders using XLNet for sentiment analysis
A combination of autoregressors and autoencoders using XLNet for sentiment analysis Abstract In this paper sentiment analysis has been performed in or
 2 Nov 20, 2021
2 Nov 20, 2021
Nateve compiler developed with python.
Adam Adam is a Nateve Programming Language compiler developed using Python. Nateve Nateve is a new general domain programming language open source ins
 7 Jan 15, 2022
7 Jan 15, 2022
🕟 Date and time processing language
Date Time Expression dte is a WIP date-time processing language with focus on broad interpretation. If you don't think it's intuitive, it's most likel
 303 Dec 19, 2022
303 Dec 19, 2022

History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
 46 Nov 23, 2022
46 Nov 23, 2022
KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
KoGPT KoGPT (Korean Generative Pre-trained Transformer) https://github.com/kakaobrain/kogpt https://huggingface.co/kakaobrain/kogpt Model Descriptions
 797 Dec 26, 2022
797 Dec 26, 2022
Blazing fast language detection using fastText model
Luga A blazing fast language detection using fastText's language models Luga is a Swahili word for language. fastText provides a blazing fast language
 18 Dec 20, 2022
18 Dec 20, 2022
Journey is a NLP-Powered Developer assistant
Journey Journey is a NLP-Powered Developer assistant Using on the powerful Natural Language Processing library Mindmeld, this projects aims to assist
 21 Dec 11, 2022
21 Dec 11, 2022

Exploiting Robust Unsupervised Video Person Re-identification
Exploiting Robust Unsupervised Video Person Re-identification Implementation of the proposed uPMnet. For the preprint, please refer to [Arxiv]. Gettin
 1 Apr 9, 2022
1 Apr 9, 2022
A Python script to convert your favorite TV series into an Anki deck.
Ankiniser A Python3.8 script to convert your favorite TV series into an Anki deck. How to install? Download the script with git or download it manualy
 37 Nov 3, 2022
37 Nov 3, 2022

ML for NLP and Computer Vision.
Sparrow is our open-source ML product. It runs on Skipper MLOps infrastructure.
 2 Nov 28, 2021
2 Nov 28, 2021
Simple python tool for the purpose of swapping latinic letters with cirilic ones and vice versa in txt, docx and pdf files in Serbian language
Alpha Swap English This is a simple python tool for the purpose of swapping latinic letters with cirylic ones and vice versa, in txt, docx and pdf fil
 3 May 31, 2022
3 May 31, 2022
Vehicle direction identification consists of three module detection , tracking and direction recognization.
Vehicle-direction-identification Vehicle direction identification consists of three module detection , tracking and direction recognization. Algorithm
 5 Nov 15, 2022
5 Nov 15, 2022
History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
46 Nov 23, 2022
We have built a Voice based Personal Assistant for people to access files hands free in their device using natural language processing.
Voice Based Personal Assistant We have built a Voice based Personal Assistant for people to access files hands free in their device using natural lang
 2 Nov 13, 2021
2 Nov 13, 2021
Partially offline multi-language translator built upon Huggingface transformers.
Translate Command-line interface to translation pipelines, powered by Huggingface transformers. This tool can download translation models, and then us
 8 Oct 25, 2022
8 Oct 25, 2022
ChirpText is a collection of text processing tools for Python 3.
ChirpText is a collection of text processing tools for Python 3. It is not meant to be a powerful tank like the popular NTLK but a small package which
 5 Nov 30, 2022
5 Nov 30, 2022
CiteURL is an extensible tool that parses legal citations and makes links to websites where you can read the cited language for free.
CiteURL is an extensible tool that parses legal citations and makes links to websites where you can read the cited language for free. It can be used t
 15 Dec 27, 2022
15 Dec 27, 2022
PyKaldi is a Python scripting layer for the Kaldi speech recognition toolkit.
PyKaldi is a Python scripting layer for the Kaldi speech recognition toolkit. It provides easy-to-use, low-overhead, first-class Python wrappers for t
 922 Dec 31, 2022
922 Dec 31, 2022
JSON and CSV data for Swahili dictionary with over 16600+ words
kamusi JSON and CSV data for swahili dictionary with over 16600+ words. This repo consists of data from swahili dictionary with about 16683 words toge
 8 Jan 13, 2022
8 Jan 13, 2022
Ducky Script is the payload language of Hak5 gear.
Ducky Script is the payload language of Hak5 gear. Since its introduction with the USB Rubber Ducky in 2010, Ducky Script has grown in capability while maintaining simplicity. Aided by Bash for logic and conditional operations, Ducky Script provides multi-vector functions for all Hak5 payload platforms.
 6 Oct 7, 2022
6 Oct 7, 2022
Implementation of the bachelor's thesis "Real-time stock predictions with deep learning and news scraping".
Real-time stock predictions with deep learning and news scraping This repository contains a partial implementation of my bachelor's thesis "Real-time
 0 Feb 9, 2022
0 Feb 9, 2022
Yodatranslator is a simple translator English to Yoda-language
yodatranslator Overview yodatranslator is a simple translator English to Yoda-language. Project is created for educational purposes. It is intended to
 1 Nov 11, 2021
1 Nov 11, 2021
Code & Experiments for "LILA: Language-Informed Latent Actions" to be presented at the Conference on Robot Learning (CoRL) 2021.
LILA LILA: Language-Informed Latent Actions Code and Experiments for Language-Informed Latent Actions (LILA), for using natural language to guide assi
 11 Nov 25, 2022
11 Nov 25, 2022

Official Code Release for "TIP-Adapter: Training-free clIP-Adapter for Better Vision-Language Modeling"
Official Code Release for "TIP-Adapter: Training-free clIP-Adapter for Better Vision-Language Modeling" Pipeline of Tip-Adapter Tip-Adapter can provid
 187 Dec 28, 2022
187 Dec 28, 2022

The repository for our EMNLP 2021 paper "Finnish Dialect Identification: The Effect of Audio and Text"
Finnish Dialect Identification The repository for our EMNLP 2021 paper "Finnish Dialect Identification: The Effect of Audio and Text". We present a te
 2 Dec 25, 2021
2 Dec 25, 2021

NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework
NLP From Scratch Without Large-Scale Pretraining This repository contains the code, pre-trained model checkpoints and curated datasets for our paper:
 224 Dec 8, 2022
224 Dec 8, 2022

An open-source online reverse dictionary.
An open-source online reverse dictionary.
 6.3k Jan 9, 2023
6.3k Jan 9, 2023
Plock : A stack based programming language
Plock : A stack based programming language
 1 Oct 25, 2021
1 Oct 25, 2021
TaCL: Improve BERT Pre-training with Token-aware Contrastive Learning
TaCL: Improve BERT Pre-training with Token-aware Contrastive Learning
26 Oct 17, 2022
Wikipedia Extractive Text Summarizer + Keywords Identification (entropy-based)
Wikipedia Extractive Text Summarizer + Keywords Identification (entropy-based)Wikipedia Extractive Text Summarizer + Keywords Identification (entropy-based)
 1 Nov 8, 2021
1 Nov 8, 2021
Ralebel is an interpreted, Haitian Creole programming language that aims to help Haitians by starting with the fundamental algorithm
Ralebel is an interpreted, Haitian Creole programming language that aims to help Haitians by starting with the fundamental algorithm
 5 Dec 1, 2022
5 Dec 1, 2022
This repository details the steps in creating a Part of Speech tagger using Trigram Hidden Markov Models and the Viterbi Algorithm without using external libraries.
POS-Tagger This repository details the creation of a Part-of-Speech tagger using Trigram Hidden Markov Models to predict word tags in a word sequence.
 1 Dec 9, 2021
1 Dec 9, 2021

Obsei is a low code AI powered automation tool.
Obsei is a low code AI powered automation tool. It can be used in various business flows like social listening, AI based alerting, brand image analysis, comparative study and more .
 782 Dec 31, 2022
782 Dec 31, 2022
Pythonic Smart Contract Language for the EVM
Getting Started See Installing Vyper to install vyper. See Tools and Resources for an additional list of framework and tools with vyper support. See D
 4.4k Dec 30, 2022
4.4k Dec 30, 2022
🦅 Pretrained BigBird Model for Korean (up to 4096 tokens)
Pretrained BigBird Model for Korean What is BigBird • How to Use • Pretraining • Evaluation Result • Docs • Citation 한국어 | English What is BigBird? Bi
 183 Dec 14, 2022
183 Dec 14, 2022
[ICCV 2021 Oral] Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Just Ask: Learning to Answer Questions from Millions of Narrated Videos Webpage • Demo • Paper This repository provides the code for our paper, includ
 87 Jan 5, 2023
87 Jan 5, 2023
This repo holds codes of the ICCV21 paper: Visual Alignment Constraint for Continuous Sign Language Recognition.
VAC_CSLR This repo holds codes of the paper: Visual Alignment Constraint for Continuous Sign Language Recognition.(ICCV 2021) [paper] Prerequisites Th
 64 Dec 19, 2022
64 Dec 19, 2022
VLGrammar: Grounded Grammar Induction of Vision and Language
VLGrammar: Grounded Grammar Induction of Vision and Language
 27 Dec 23, 2022
27 Dec 23, 2022
A simple language translator with python and google translate api
Language translator with python A simple language translator with python and google translate api Install pip and python 3.9. All the required depende
 0 Nov 11, 2021
0 Nov 11, 2021
The official github repository for Towards Continual Knowledge Learning of Language Models
Towards Continual Knowledge Learning of Language Models This is the official github repository for Towards Continual Knowledge Learning of Language Mo
 65 Jan 7, 2023
65 Jan 7, 2023
An open-source NLP library: fast text cleaning and preprocessing.
An open-source NLP library: fast text cleaning and preprocessing
 21 Mar 18, 2022
21 Mar 18, 2022

Chinese Advertisement Board Identification(Pytorch)
Chinese-Advertisement-Board-Identification. We use YoloV5 to extract the ROI of the location of the chinese word. Next, we sort the bounding box and recognize every chinese words which we extracted. The methods which we use are Yolov5, ArgMargin and Focal loss.
 12 Jul 21, 2022
12 Jul 21, 2022
A trashy useless Latin programming language written in python.
Codigum! The first programming langage in latin! (please keep your eyes closed when if you read the source code) It is pretty useless though. Document
 2 Oct 25, 2021
2 Oct 25, 2021
Code to reproduce the results of the paper 'Towards Realistic Few-Shot Relation Extraction' (EMNLP 2021)
Realistic Few-Shot Relation Extraction This repository contains code to reproduce the results in the paper "Towards Realistic Few-Shot Relation Extrac
 8 Nov 9, 2022
8 Nov 9, 2022
Sodium is a general purpose programming language which is instruction-oriented
Sodium is a general purpose programming language which is instruction-oriented (a new programming concept that we are developing and devising)
 22 Jan 11, 2022
22 Jan 11, 2022
A programming language with logic of Python, and syntax of all languages.
Pytov The idea was to take all well known syntaxes, and combine them into one programming language with many posabilities. Installation Install using
 14 Dec 7, 2022
14 Dec 7, 2022
Open-source linguistic ethnography tool for framing public opinion in mediatized groups.
Open-source linguistic ethnography tool for framing public opinion in mediatized groups. Table of Contents Installing Quickstart Links Installing Pyth
 7 Jun 2, 2022
7 Jun 2, 2022
Simple NLP based project without any use of AI
Simple NLP based project without any use of AI
 1 Apr 26, 2022
1 Apr 26, 2022
Ukrainian TTS (text-to-speech) using Coqui TTS
title emoji colorFrom colorTo sdk app_file pinned Ukrainian TTS 🐸 green green gradio app.py false Ukrainian TTS 📢 🤖 Ukrainian TTS (text-to-speech)
 85 Dec 26, 2022
85 Dec 26, 2022
Chinese Pre-Trained Language Models (CPM-LM) Version-I
CPM-Generate 为了促进中文自然语言处理研究的发展,本项目提供了 CPM-LM (2.6B) 模型的文本生成代码,可用于文本生成的本地测试,并以此为基础进一步研究零次学习/少次学习等场景。[项目首页] [模型下载] [技术报告] 若您想使用CPM-1进行推理,我们建议使用高效推理工具BMI
 1.4k Jan 3, 2023
1.4k Jan 3, 2023
A faster and highly-compatible implementation of the Python programming language.
Pyston Pyston is a fork of CPython 3.8.8 with additional optimizations for performance. It is targeted at large real-world applications such as web se
 2.3k Jan 9, 2023
2.3k Jan 9, 2023
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding This repo contains the data and source code for baseline models in the NeurIPS 2
29 Dec 29, 2022

OCR Post Correction for Endangered Language Texts
📌 Coming soon: an update to the software including features from our paper on semi-supervised OCR post-correction, to be published in the Transaction
 96 Dec 31, 2022
96 Dec 31, 2022
NLP codes implemented with Pytorch (w/o library such as huggingface)
NLP_scratch NLP codes implemented with Pytorch (w/o library such as huggingface) scripts ├── models: Neural Network models ├── data: codes for dataloa
 3 Dec 28, 2021
3 Dec 28, 2021

A ray tracing render implemented using Taichi language.
A ray tracing render implemented using Taichi language.
 45 Oct 23, 2022
45 Oct 23, 2022
Q-Tracker is originally a High School Project created by Admins of Cirus Lab.
Q-Tracker is originally a High School Project created by Admins of Cirus Lab. It's completly coded in python along with mysql.(Tkinter For GUI)
 2 Nov 14, 2022
2 Nov 14, 2022

Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
 176 Nov 28, 2022
176 Nov 28, 2022