2613 Repositories
Python nse-stock-data Libraries
Senator Stock Trading Tester
Senator Stock Trading Tester Program to compare stock performance of Senator's transactions vs when the sale is disclosed. Using to find if tracking S
 1 Dec 7, 2021
1 Dec 7, 2021
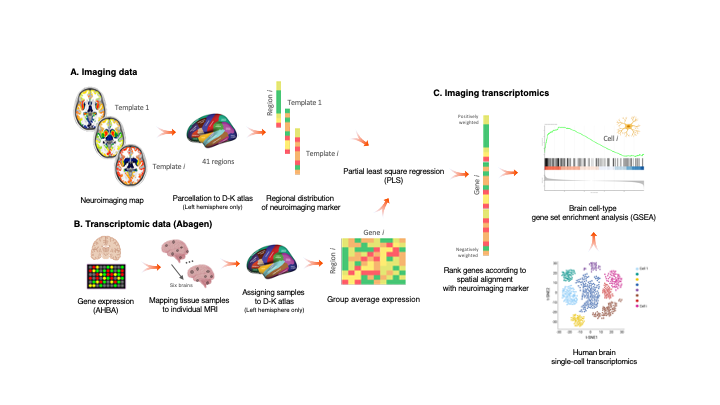
A package, and script, to perform imaging transcriptomics on a neuroimaging scan.
Imaging Transcriptomics Imaging transcriptomics is a methodology that allows to identify patterns of correlation between gene expression and some prop
 10 Dec 27, 2022
10 Dec 27, 2022
Script to generate a massive volume of data in sql, csv, json or xml format
DataGenerator Made with Python Open for pull requests 1. Dependencies To install required dependencies run pip install -r requirements.txt 2. Executi
 3 Sep 20, 2022
3 Sep 20, 2022

Technical Analysis Indicators - Pandas TA is an easy to use Python 3 Pandas Extension with 130+ Indicators
Pandas TA - A Technical Analysis Library in Python 3 Pandas Technical Analysis (Pandas TA) is an easy to use library that leverages the Pandas package
 3.2k Jan 9, 2023
3.2k Jan 9, 2023
This is collection of Managementsystem programs: Hospital Management, Student Managemen, etc
Contribute in this repository and help other students with their assignment by adding python scripts for various management system programs.
 3 Mar 20, 2022
3 Mar 20, 2022

Official Pytorch implementation for 2021 ICCV paper "Learning Motion Priors for 4D Human Body Capture in 3D Scenes" and trained models / data
Learning Motion Priors for 4D Human Body Capture in 3D Scenes (LEMO) Official Pytorch implementation for 2021 ICCV (oral) paper "Learning Motion Prior
 165 Dec 19, 2022
165 Dec 19, 2022
This directory gathers the tools developed by the Data Sourcing Working Group
BigScience Data Sourcing Code This directory gathers the tools developed by the Data Sourcing Working Group First Sourcing Sprint: October 2021 The co
 27 Nov 4, 2022
27 Nov 4, 2022
An audnexus client, providing rich author and audiobook data to Plex via it's legacy plugin agent system.
Audnexus.bundle An audnex.us client, providing rich author and audiobook data to Plex via it's legacy plugin agent system. 📝 Table of Contents About
 248 Jan 2, 2023
248 Jan 2, 2023
An assignment from my grad-level data mining course demonstrating some experience with NLP/neural networks/Pytorch
NLP-Pytorch-Assignment An assignment from my grad-level data mining course (before I started personal projects) demonstrating some experience with NLP
 0 Feb 6, 2022
0 Feb 6, 2022
Demonstrate a Dataflow pipeline that saves data from an API into BigQuery table
Overview dataflow-mvp provides a basic example pipeline that pulls data from an API and writes it to a BigQuery table using GCP's Dataflow (i.e., Apac
 1 Dec 3, 2021
1 Dec 3, 2021
A Python library for loading data from a SpaceX Starlink satellite.
Starlink Python A Python library for loading data from a SpaceX Starlink satellite. The goal is to be a simple interface for Starlink. It builds upon
 2 Jan 16, 2022
2 Jan 16, 2022
Visualize large time-series data in plotly
plotly_resampler enables visualizing large sequential data by adding resampling functionality to Plotly figures. In this Plotly-Resampler demo over 11
 604 Dec 28, 2022
604 Dec 28, 2022
Rainbow DQN implementation accompanying the paper "Fast and Data-Efficient Training of Rainbow" which reaches 205.7 median HNS after 10M frames. 🌈
Rainbow 🌈 An implementation of Rainbow DQN which reaches a median HNS of 205.7 after only 10M frames (the original Rainbow from Hessel et al. 2017 re
 15 Dec 3, 2021
15 Dec 3, 2021
Randomisation-based inference in Python based on data resampling and permutation.
Randomisation-based inference in Python based on data resampling and permutation.
 67 Dec 27, 2022
67 Dec 27, 2022
Python code for working with NFL play by play data.
nfl_data_py nfl_data_py is a Python library for interacting with NFL data sourced from nflfastR, nfldata, dynastyprocess, and Draft Scout. Includes im
 82 Jan 5, 2023
82 Jan 5, 2023
voice assistant made with python that search for covid19 data(like total cases, deaths and etc) in a specific country
covid19-voice-assistant voice assistant made with python that search for covid19 data(like total cases, deaths and etc) in a specific country installi
 2 Dec 5, 2021
2 Dec 5, 2021
Cryptick is a stock ticker for cryptocurrency tokens, and a physical NFT.
Cryptick is a stock ticker for cryptocurrency tokens, and a physical NFT. This repository includes tools and documentation for the Cryptick device.
 1 Dec 31, 2021
1 Dec 31, 2021

Simple API for UCI Machine Learning Dataset Repository (search, download, analyze)
A simple API for working with University of California, Irvine (UCI) Machine Learning (ML) repository Table of Contents Introduction About Page of the
 223 Dec 5, 2022
223 Dec 5, 2022
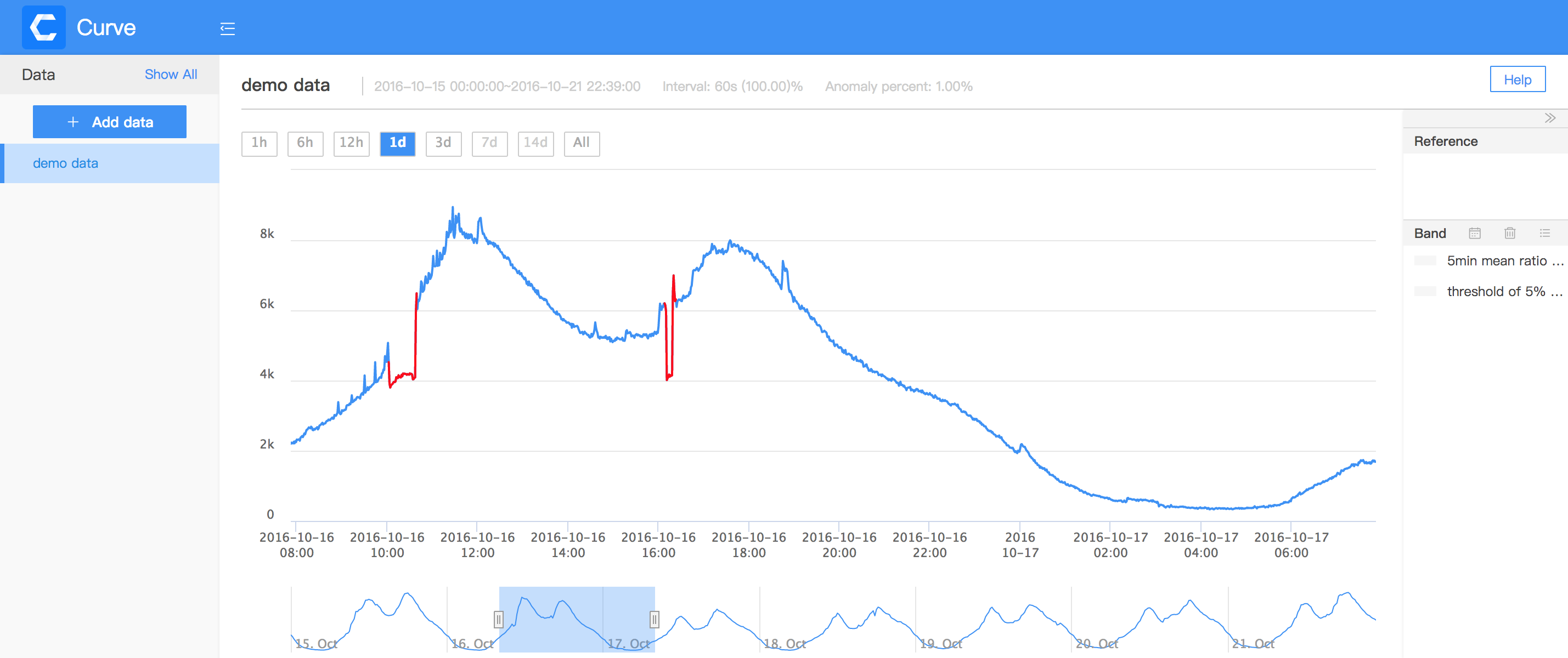
An Integrated Experimental Platform for time series data anomaly detection.
Curve Sorry to tell contributors and users. We decided to archive the project temporarily due to the employee work plan of collaborators. There are no
 486 Dec 21, 2022
486 Dec 21, 2022
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022
Python script to tabulate data formats like json, csv, html, etc
pyT PyT is a a command line tool and as well a library for visualising various data formats like: JSON HTML Table CSV XML, etc. Features Print table o
 1 Dec 30, 2021
1 Dec 30, 2021

MS in Data Science capstone project. Studying attacks on autonomous vehicles.
Surveying Attack Models for CAVs Guide to Installing CARLA and Collecting Data Our project focuses on surveying attack models for Connveced Autonomous
 1 Dec 9, 2021
1 Dec 9, 2021
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022
GDSC UIET KUK 📍 , welcomes you all to this amazing event where you will be introduced to the world of coding 💻 .
GDSC UIET KUK 📍 , welcomes you all to this amazing event where you will be introduced to the world of coding 💻 .
 9 Mar 24, 2022
9 Mar 24, 2022

SentAugment is a data augmentation technique for semi-supervised learning in NLP.
SentAugment SentAugment is a data augmentation technique for semi-supervised learning in NLP. It uses state-of-the-art sentence embeddings to structur
 363 Dec 30, 2022
363 Dec 30, 2022
Creating predictive checklists from data using integer programming.
Learning Optimal Predictive Checklists A Python package to learn simple predictive checklists from data subject to customizable constraints. For more
 5 Apr 19, 2022
5 Apr 19, 2022
![Code and Data for the paper: Molecular Contrastive Learning with Chemical Element Knowledge Graph [AAAI 2022]](https://github.com/Fangyin1994/KCL/raw/main/fig/overview.png)
Code and Data for the paper: Molecular Contrastive Learning with Chemical Element Knowledge Graph [AAAI 2022]
Knowledge-enhanced Contrastive Learning (KCL) Molecular Contrastive Learning with Chemical Element Knowledge Graph [ AAAI 2022 ]. We construct a Chemi
 58 Dec 26, 2022
58 Dec 26, 2022
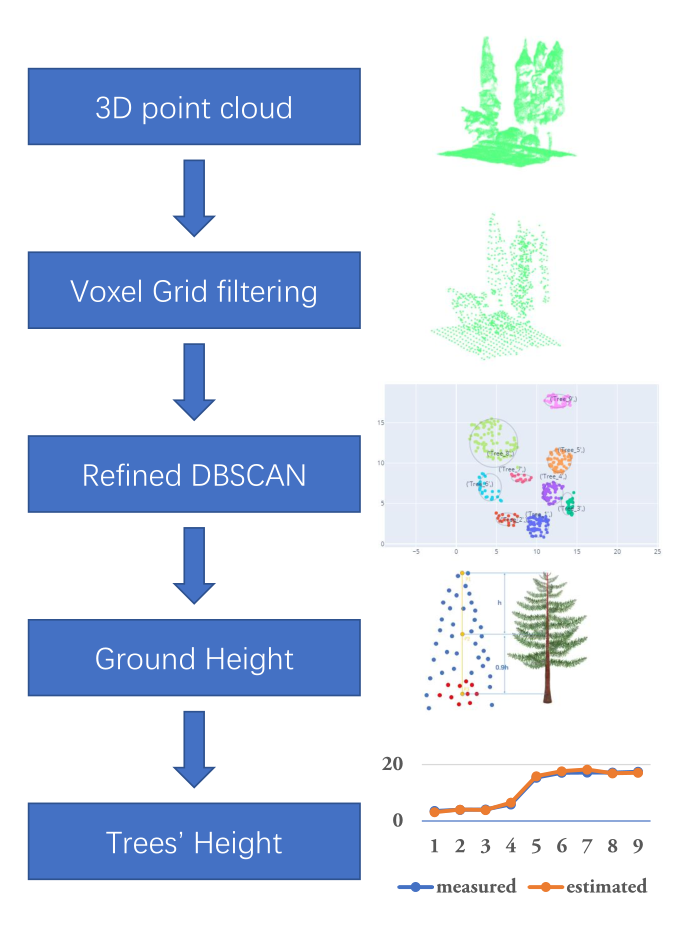
A simple algorithm for extracting tree height in sparse scene from point cloud data.
TREE HEIGHT EXTRACTION IN SPARSE SCENES BASED ON UAV REMOTE SENSING This is the offical python implementation of the paper "Tree Height Extraction in
 6 Oct 28, 2022
6 Oct 28, 2022

My notes on Data structure and Algos in golang implementation and python
My notes on DS and Algo Table of Contents Arrays LinkedList Trees Types of trees: Tree/Graph Traversal Algorithms Heap Priorty Queue Trie Graphs Graph
 0 Feb 13, 2022
0 Feb 13, 2022
Minimal pure Python library for working with little-endian list representation of bit strings.
bitlist Minimal Python library for working with bit vectors natively. Purpose This library allows programmers to work with a native representation of
 0 Jul 25, 2022
0 Jul 25, 2022

Google, Facebook, Amazon, Microsoft, Netflix tech interview questions
Algorithm and Data Structures Interview Questions HackerRank | Practice, Tutorials & Interview Preparation Solutions This repository consists of solut
 8 Oct 4, 2022
8 Oct 4, 2022
Learn to code in any language. If
Learn to Code It is an intiiative undertaken by Student Ambassadors Club, Jamshoro for students who are absolute begineers in programming and want to
 15 Oct 19, 2022
15 Oct 19, 2022
Multiple Imputation with Random Forests in Python
miceforest: Fast, Memory Efficient Imputation with lightgbm Fast, memory efficient Multiple Imputation by Chained Equations (MICE) with lightgbm. The
 202 Dec 31, 2022
202 Dec 31, 2022
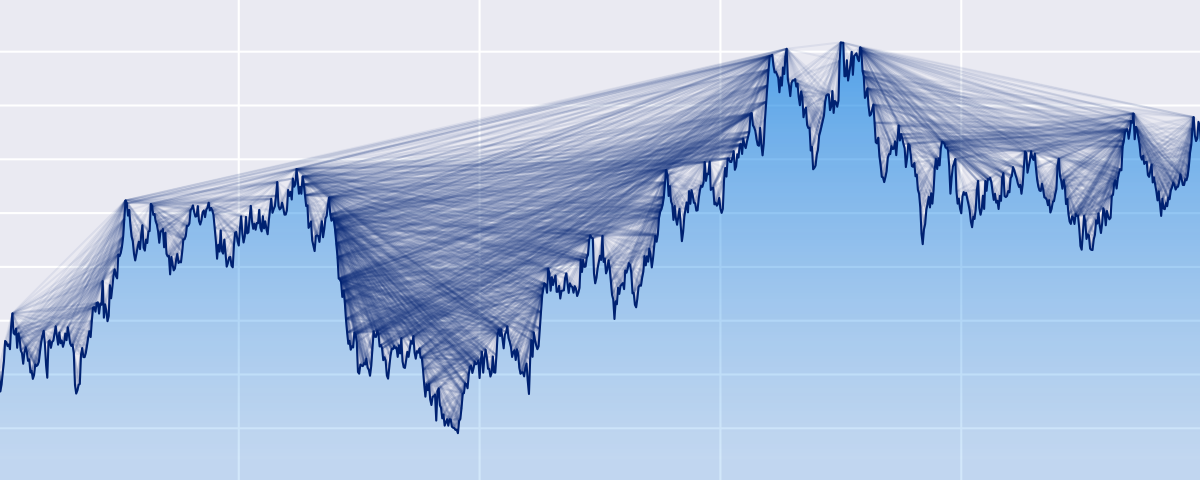
Python ts2vg package provides high-performance algorithm implementations to build visibility graphs from time series data.
ts2vg: Time series to visibility graphs The Python ts2vg package provides high-performance algorithm implementations to build visibility graphs from t
 26 Dec 17, 2022
26 Dec 17, 2022

Very useful and necessary functions that simplify working with data
Additional-function-for-pandas Very useful and necessary functions that simplify working with data random_fill_nan(module_name, nan) - Replaces all sp
 2 Dec 2, 2021
2 Dec 2, 2021
A simple python stock Predictor
Python Stock Predictor A simple python stock Predictor Demo Run Locally Clone the project git clone https://github.com/yashraj-n/stock-price-predict
 5 Nov 29, 2021
5 Nov 29, 2021
A tool to nowcast quarterly data with monthly indicators: US consumption example
MIDAS_Nowcaster A tool to nowcast quarterly data with monthly indicators: US consumption example Pulls data directly from FRED from a list of codes -
 3 Oct 6, 2022
3 Oct 6, 2022
Data Exfiltration without ever making a connection. Using TCP header space.
TCPwned PoC toy code to exfiltrate data without ever making a TCP connection. This will never show up in firewall logs, much less, actually be monitor
 2 Nov 21, 2022
2 Nov 21, 2022
Upgini : data search library for your machine learning pipelines
Automated data search library for your machine learning pipelines → find & deliver relevant external data & features to boost ML accuracy :chart_with_upwards_trend:
 175 Jan 8, 2023
175 Jan 8, 2023
A light weight data augmentation tool for training CNNs and Viola Jones detectors
hey-daug A light weight data augmentation tool for training CNNs and Viola Jones detectors (Haar Cascades). This tool inflates your data by up to six
 2 Nov 23, 2019
2 Nov 23, 2019
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
Tools for curating biomedical training data for large-scale language modeling
Tools for curating biomedical training data for large-scale language modeling
242 Dec 25, 2022
The repository for the paper "When Do You Need Billions of Words of Pretraining Data?"
pretraining-learning-curves This is the repository for the paper When Do You Need Billions of Words of Pretraining Data? Edge Probing We use jiant1 fo
 19 Nov 25, 2022
19 Nov 25, 2022
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed+Megatron trained the world's most powerful language model: MT-530B DeepSpeed is hiring, come join us! DeepSpeed is a deep learning optimizat
 8.4k Dec 28, 2022
8.4k Dec 28, 2022
Information Gain Filtration (IGF) is a method for filtering domain-specific data during language model finetuning. IGF shows significant improvements over baseline fine-tuning without data filtration.
Information Gain Filtration Information Gain Filtration (IGF) is a method for filtering domain-specific data during language model finetuning. IGF sho
 4 Jul 28, 2022
4 Jul 28, 2022
The code is the training example of AAAI2022 Security AI Challenger Program Phase 8: Data Centric Robot Learning on ML models.
Example code of [Tianchi AAAI2022 Security AI Challenger Program Phase 8]
 22 Oct 14, 2022
22 Oct 14, 2022

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
Data preprocessing rosetta parser for python
datapreprocessing_rosetta_parser I've never done any NLP or text data processing before, so I wanted to use this hackathon as a learning opportunity,
 2 Nov 28, 2021
2 Nov 28, 2021
Async boto3 with Autogenerated Data Classes
awspydk Async boto3 with Autogenerated JIT Data Classes Motivation This library is forked from an internal project that works with a lot of backend AW
 1 Dec 5, 2021
1 Dec 5, 2021
A command line tool that creates a super timeline from SentinelOne's Deep Visibility data
S1SuperTimeline A command line tool that creates a super timeline from SentinelOne's Deep Visibility data What does it do? The script accepts a S1QL q
 2 Feb 8, 2022
2 Feb 8, 2022
Visualize your pandas data with one-line code
PandasEcharts 简介 基于pandas和pyecharts的可视化工具 安装 pip 安装 $ pip install pandasecharts 源码安装 $ git clone https://github.com/gamersover/pandasecharts $ cd pand
 2 Apr 13, 2022
2 Apr 13, 2022

A Pythonic framework for threat modeling
pytm: A Pythonic framework for threat modeling Introduction Traditional threat modeling too often comes late to the party, or sometimes not at all. In
 644 Dec 20, 2022
644 Dec 20, 2022

ClearML - Auto-Magical Suite of tools to streamline your ML workflow. Experiment Manager, MLOps and Data-Management
ClearML - Auto-Magical Suite of tools to streamline your ML workflow Experiment Manager, MLOps and Data-Management ClearML Formerly known as Allegro T
 3.9k Jan 1, 2023
3.9k Jan 1, 2023
Official Repository for "Robust On-Policy Data Collection for Data Efficient Policy Evaluation" (NeurIPS 2021 Workshop on OfflineRL).
Robust On-Policy Data Collection for Data-Efficient Policy Evaluation Source code of Robust On-Policy Data Collection for Data-Efficient Policy Evalua
 2 Oct 9, 2022
2 Oct 9, 2022
Self-Supervised Image Denoising via Iterative Data Refinement
Self-Supervised Image Denoising via Iterative Data Refinement Yi Zhang1, Dasong Li1, Ka Lung Law2, Xiaogang Wang1, Hongwei Qin2, Hongsheng Li1 1CUHK-S
 72 Jan 1, 2023
72 Jan 1, 2023
Data Consistency for Magnetic Resonance Imaging
Data Consistency for Magnetic Resonance Imaging Data Consistency (DC) is crucial for generalization in multi-modal MRI data and robustness in detectin
 19 Dec 12, 2022
19 Dec 12, 2022

Automatic Data-Regularized Actor-Critic (Auto-DrAC)
Auto-DrAC: Automatic Data-Regularized Actor-Critic This is a PyTorch implementation of the methods proposed in Automatic Data Augmentation for General
 89 Dec 13, 2022
89 Dec 13, 2022
This repository is for the preprint "A generative nonparametric Bayesian model for whole genomes"
BEAR Overview This repository contains code associated with the preprint A generative nonparametric Bayesian model for whole genomes (2021), which pro
 10 Sep 18, 2022
10 Sep 18, 2022

Removing Inter-Experimental Variability from Functional Data in Systems Neuroscience
Removing Inter-Experimental Variability from Functional Data in Systems Neuroscience This repository is the official implementation of [https://www.bi
 6 Oct 9, 2022
6 Oct 9, 2022
Auditing Black-Box Prediction Models for Data Minimization Compliance
Data-Minimization-Auditor An auditing tool for model-instability based data minimization that is introduced in "Auditing Black-Box Prediction Models f
 2 Mar 24, 2022
2 Mar 24, 2022
[NeurIPS 2021] "G-PATE: Scalable Differentially Private Data Generator via Private Aggregation of Teacher Discriminators"
G-PATE This is the official code base for our NeurIPS 2021 paper: "G-PATE: Scalable Differentially Private Data Generator via Private Aggregation of T
 14 Oct 12, 2022
14 Oct 12, 2022
TAUFE: Task-Agnostic Undesirable Feature DeactivationUsing Out-of-Distribution Data
A deep neural network (DNN) has achieved great success in many machine learning tasks by virtue of its high expressive power. However, its prediction can be easily biased to undesirable features, which are not essential for solving the target task and are even imperceptible to a human, thereby resulting in poor generalization
 8 Dec 7, 2022
8 Dec 7, 2022
Equivariant layers for RC-complement symmetry in DNA sequence data
Equi-RC Equivariant layers for RC-complement symmetry in DNA sequence data This is a repository that implements the layers as described in "Reverse-Co
 7 May 19, 2022
7 May 19, 2022
Hide sensitive information in images
Data-Preserved Script allowing to blur the most sensitive information on images. Prerequisites Before you begin, ensure you have met the following req
 2 Dec 1, 2021
2 Dec 1, 2021

Official PyTorch implementation of Data-free Knowledge Distillation for Object Detection, WACV 2021.
Introduction This repository is the official PyTorch implementation of Data-free Knowledge Distillation for Object Detection, WACV 2021. Data-free Kno
 50 Jan 5, 2023
50 Jan 5, 2023

Algorithm for Cutting Stock Problem using Google OR-Tools. Link to the tool:
Cutting Stock Problem Cutting Stock Problem (CSP) deals with planning the cutting of items (rods / sheets) from given stock items (which are usually o
 87 Dec 31, 2022
87 Dec 31, 2022
Sign data using symmetric-key algorithm encryption.
Sign data using symmetric-key algorithm encryption. Validate signed data and identify possible validation errors. Uses sha-(1, 224, 256, 385 and 512)/hmac for signature encryption. Custom hash algorithms are allowed. Useful shortcut functions for signing (and validating) dictionaries and URLs.
 39 Jun 10, 2022
39 Jun 10, 2022
A Python 3 library making time series data mining tasks, utilizing matrix profile algorithms
MatrixProfile MatrixProfile is a Python 3 library, brought to you by the Matrix Profile Foundation, for mining time series data. The Matrix Profile is
 302 Dec 29, 2022
302 Dec 29, 2022
Primitives for machine learning and data science.
An Open Source Project from the Data to AI Lab, at MIT MLPrimitives Pipelines and primitives for machine learning and data science. Documentation: htt
 65 Dec 29, 2022
65 Dec 29, 2022
IBD Style Relative Strength Percentile Ranking of Stocks (i.e. 0-100 Score).
relative-strength IBD Style Relative Strength Percentile Ranking of Stocks (i.e. 0-100 Score). I also made a TradingView indicator, but it cannot give
 57 Jan 6, 2023
57 Jan 6, 2023
An helper library to scrape data from Instagram effortlessly, using the Influencer Hunters APIs.
Instagram Scraper An utility library to scrape data from Instagram hassle-free Go to the website » View Demo · Report Bug · Request Feature About The
 2 Jul 6, 2022
2 Jul 6, 2022
tradingview socket api for fetching real time prices.
tradingView-API tradingview socket api for fetching real time prices. How to run git clone https://github.com/mohamadkhalaj/tradingView-API.git cd tra
 35 Dec 31, 2022
35 Dec 31, 2022
This repository is used to provide data to zzhack,
This repository is used to provide data to zzhack, but you don't have to care about anything, just write your thinking down, and you can see your thinking is rendered in zzhack perfectly
 5 Apr 29, 2022
5 Apr 29, 2022
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository provides the official PyTorch implementation
 155 Nov 30, 2021
155 Nov 30, 2021
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
 1 Nov 30, 2021
1 Nov 30, 2021
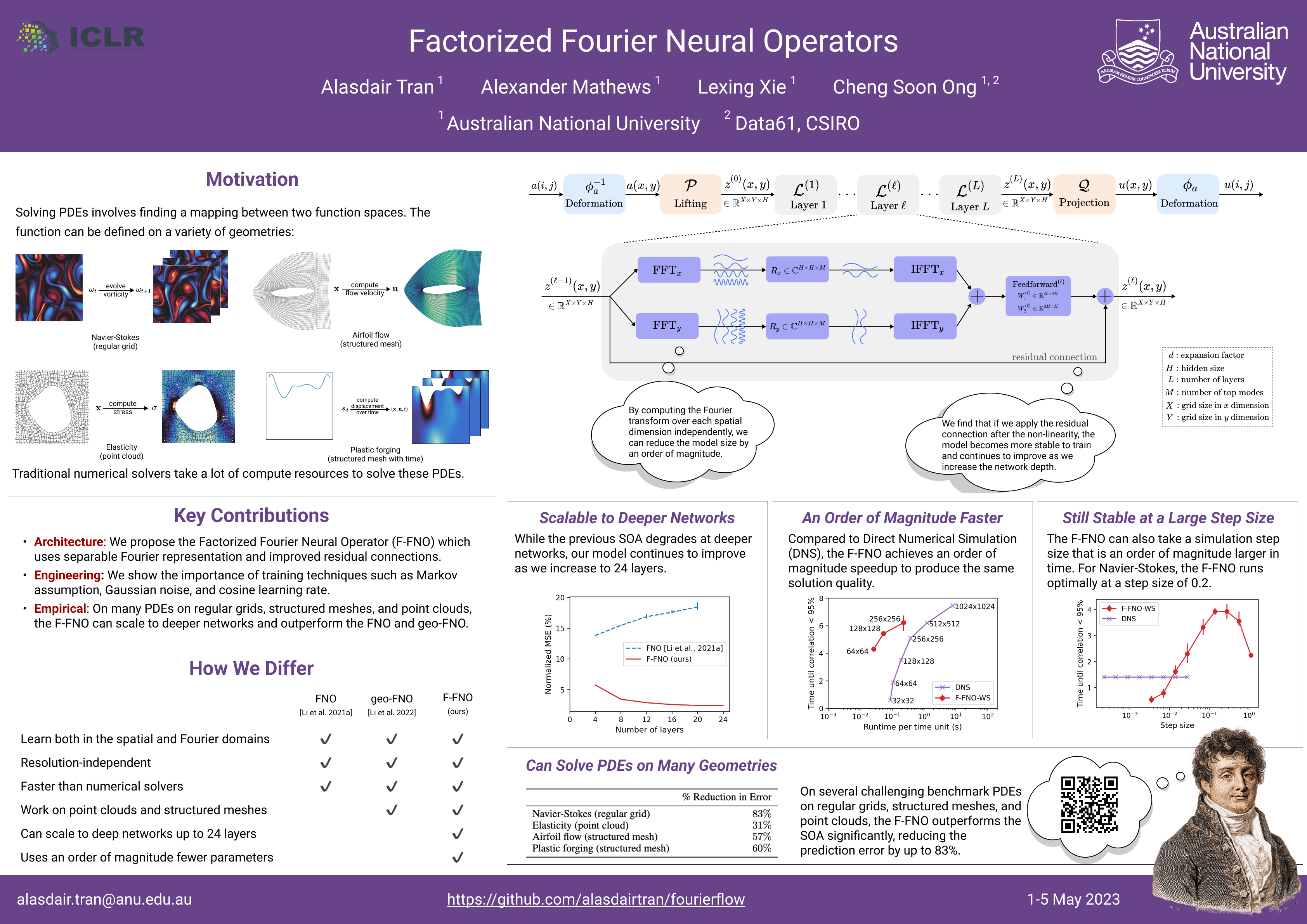
Experiments with Fourier layers on simulation data.
Factorized Fourier Neural Operators This repository contains the code to reproduce the results in our NeurIPS 2021 ML4PS workshop paper, Factorized Fo
 57 Dec 25, 2022
57 Dec 25, 2022
The first GANs-based omics-to-omics translation framework
OmiTrans Please also have a look at our multi-omics multi-task DL freamwork 👀 : OmiEmbed The FIRST GANs-based omics-to-omics translation framework Xi
 1 Nov 30, 2021
1 Nov 30, 2021
Auxiliary data to the CHIIR paper Searching to Learn with Instructional Scaffolding
Searching to Learn with Instructional Scaffolding This is the data and analysis code for the paper "Searching to Learn with Instructional Scaffolding"
 2 Mar 2, 2022
2 Mar 2, 2022
Source Code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Description The source code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chin
 3 Jun 28, 2022
3 Jun 28, 2022

A program that analyzes data from inertia measurement units installed in aircraft and generates g-exceedance curves.
A program that analyzes data from inertia measurement units installed in aircraft and generates g-exceedance curves.
 1 Dec 2, 2021
1 Dec 2, 2021
Data wrangling & common calculations for results from qMem measurement software
qMem Datawrangler This script processes output of qMem measurement software into an Origin ® compatible *.csv files and matplotlib graphs to quickly v
 1 Nov 30, 2021
1 Nov 30, 2021
Django based webapp pulling in crypto news and price data via api
Deploy Django in Production FTA project implementing containerization of Django Web Framework into Docker to be placed into Azure Container Services a
 0 Sep 21, 2022
0 Sep 21, 2022

Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Vedaldi, Andrew Zisserman, CVPR 2016.
SynthText Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Ved
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

🛰️ Scripts démontrant l'utilisation de l'imagerie RADARSAT-1 à partir d'un seau AWS | 🛰️ Scripts demonstrating the use of RADARSAT-1 imagery from an AWS bucket
🛰️ Scripts démontrant l'utilisation de l'imagerie RADARSAT-1 à partir d'un seau AWS | 🛰️ Scripts demonstrating the use of RADARSAT-1 imagery from an AWS bucket
 4 May 18, 2022
4 May 18, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

This is a python script to grab data from Zyxel NSA310 NAS and display in Home Asisstant as sensors.
Home-Assistant Python Scripts Python Scripts for Home-Assistant (http://www.home-assistant.io) Zyxel-NSA310-Home-Assistant Monitoring This is a python
 6 Oct 31, 2022
6 Oct 31, 2022

A real world application of a Recurrent Neural Network on a binary classification of time series data
What is this This is a real world application of a Recurrent Neural Network on a binary classification of time series data. This project includes data
 2 Jan 30, 2022
2 Jan 30, 2022

APIlocal_dbAWS_RDS - Disclaimer! All data used is for educational purposes only.
APIlocal_dbAWS_RDS Disclaimer! All data used is for educational purposes only. ETL pipeline diagram. Aim of project By creating a fully working pipe
 0 Apr 25, 2022
0 Apr 25, 2022
Flexible time series feature extraction & processing
tsflex is a toolkit for flexible time series processing & feature extraction, that is efficient and makes few assumptions about sequence data. Useful
206 Dec 28, 2022

DuBE: Duple-balanced Ensemble Learning from Skewed Data
DuBE: Duple-balanced Ensemble Learning from Skewed Data "Towards Inter-class and Intra-class Imbalance in Class-imbalanced Learning" (IEEE ICDE 2022 S
 6 Nov 12, 2022
6 Nov 12, 2022

Fast mesh denoising with data driven normal filtering using deep variational autoencoders
Fast mesh denoising with data driven normal filtering using deep variational autoencoders This is an implementation for the paper entitled "Fast mesh
 9 Dec 2, 2022
9 Dec 2, 2022

IMBENS: class-imbalanced ensemble learning in Python.
IMBENS: class-imbalanced ensemble learning in Python. Links: [Documentation] [Gallery] [PyPI] [Changelog] [Source] [Download] [知乎/Zhihu] [中文README] [a
 176 Jan 4, 2023
176 Jan 4, 2023
Research code for the paper "Variational Gibbs inference for statistical estimation from incomplete data".
Variational Gibbs inference (VGI) This repository contains the research code for Simkus, V., Rhodes, B., Gutmann, M. U., 2021. Variational Gibbs infer
 1 Apr 8, 2022
1 Apr 8, 2022

Deep Learning Emotion decoding using EEG data from Autism individuals
Deep Learning Emotion decoding using EEG data from Autism individuals This repository includes the python and matlab codes using for processing EEG 2D
 12 Dec 8, 2022
12 Dec 8, 2022

This repository contains all code and data for the Inside Out Visual Place Recognition task
Inside Out Visual Place Recognition This repository contains code and instructions to reproduce the results for the Inside Out Visual Place Recognitio
 15 May 21, 2022
15 May 21, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
Tool for running a high throughput data ingestion/transformation workload with MongoDB
Mongo Mangler The mongo-mangler tool is a lightweight Python utility, which you can run from a low-powered machine to execute a high throughput data i
 9 Jan 2, 2023
9 Jan 2, 2023
Gathering data of likes on Tinder within the past 7 days
tinder_likes_data Gathering data of Likes Sent on Tinder within the past 7 days. Versions November 25th, 2021 - Functionality to get the name and age
 12 Jan 5, 2023
12 Jan 5, 2023
Empresas do Brasil (CNPJs)
Biblioteca em Python que coleta informações cadastrais de empresas do Brasil (CNPJ) obtidas de fontes oficiais (Receita Federal) e exporta para um formato legível por humanos (CSV ou JSON).
 8 Aug 17, 2022
8 Aug 17, 2022