789 Repositories
Python pseudo-visual-speech-denoising Libraries

A real-time speech emotion recognition application using Scikit-learn and gradio
Speech-Emotion-Recognition-App A real-time speech emotion recognition application using Scikit-learn and gradio. Requirements librosa==0.6.3 numpy sou
 6 Oct 4, 2022
6 Oct 4, 2022
A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk.
Simple-Vosk A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk. Check out the official Vosk G
 2 Jun 19, 2022
2 Jun 19, 2022
🚀 PyTorch Implementation of "Progressive Distillation for Fast Sampling of Diffusion Models(v-diffusion)"
PyTorch Implementation of "Progressive Distillation for Fast Sampling of Diffusion Models(v-diffusion)" Unofficial PyTorch Implementation of Progressi
 58 Dec 19, 2022
58 Dec 19, 2022
Let's make a lot of random function from Scracth...
Pseudo-Random On a whim I asked myself the question about how randomness is integrated into an algorithm? So I started the adventure by trying to code
 2 Jan 19, 2022
2 Jan 19, 2022

TCNN Temporal convolutional neural network for real-time speech enhancement in the time domain
TCNN Pandey A, Wang D L. TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain[C]//ICASSP 2019-2019 IEEE Int
 16 Dec 30, 2022
16 Dec 30, 2022
The trained model and denoising example for paper : Cardiopulmonary Auscultation Enhancement with a Two-Stage Noise Cancellation Approach
The trained model and denoising example for paper : Cardiopulmonary Auscultation Enhancement with a Two-Stage Noise Cancellation Approach
 1 Jan 18, 2022
1 Jan 18, 2022

Visual Python and C++ nanosecond profiler, logger, tests enabler
Look into Palanteer and get an omniscient view of your program Palanteer is a set of lean and efficient tools to improve the quality of software, for
 1.9k Dec 26, 2022
1.9k Dec 26, 2022
Flow-based visual scripting for Python
A simple visual node editor for Python Ryven combines flow-based visual scripting with Python. It gives you absolute freedom for your nodes and a simp
 3.1k Jan 6, 2023
3.1k Jan 6, 2023
PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluation of Visual Stories via Semantic Consistency"
Improving Generation and Evaluation of Visual Stories via Semantic Consistency PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluat
 28 Dec 8, 2022
28 Dec 8, 2022
Visual dialog agents with pre-trained vision-and-language encoders.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation Or READ-UP: Referring Expression Agent Dialog with Unified Pretr
 7 Oct 8, 2022
7 Oct 8, 2022

Implementations for the ICLR-2021 paper: SEED: Self-supervised Distillation For Visual Representation.
Implementations for the ICLR-2021 paper: SEED: Self-supervised Distillation For Visual Representation.
 27 Oct 23, 2022
27 Oct 23, 2022

PyFlow is a general purpose visual scripting framework for python
PyFlow is a general purpose visual scripting framework for python. State Base structure of program implemented, such things as packages disco
 1.8k Jan 7, 2023
1.8k Jan 7, 2023
Reproducing-BowNet: Learning Representations by Predicting Bags of Visual Words
Reproducing-BowNet Our reproducibility effort based on the 2020 ML Reproducibility Challenge. We are reproducing the results of this CVPR 2020 paper:
 6 Mar 16, 2022
6 Mar 16, 2022
Denoising images with Fourier Ring Correlation loss
Denoising images with Fourier Ring Correlation loss The python code accompanies the working manuscript Image quality measurements and denoising using
 2 Mar 12, 2022
2 Mar 12, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
 26 Jan 16, 2022
26 Jan 16, 2022
Source codes for Improved Few-Shot Visual Classification (CVPR 2020), Enhancing Few-Shot Image Classification with Unlabelled Examples
Source codes for Improved Few-Shot Visual Classification (CVPR 2020), Enhancing Few-Shot Image Classification with Unlabelled Examples (WACV 2022) and Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning (TPAMI 2022 - in submission)
 42 Dec 6, 2022
42 Dec 6, 2022
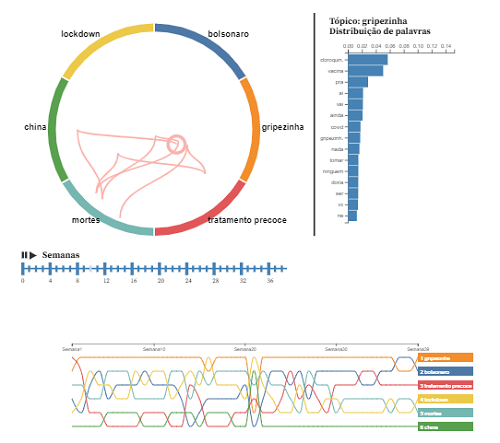
Project for the discipline of Visual Data Analysis at EMAp FGV.
Analysis of the dissemination of fake news about COVID-19 on Twitter This project was the final work for the discipline of Visual Data Analysis of the
 2 Jan 17, 2022
2 Jan 17, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
118 Jan 6, 2023
VL-LTR: Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition
VL-LTR: Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition Usage First, install PyTorch 1.7.1+, torchvision 0.8.2
 40 Dec 12, 2022
40 Dec 12, 2022

I-Spy is a discord and twitter bot 🤖 that keeps a check on usage foul language, hate-speech and NSFW contents
I-Spy is a discord and twitter bot 🤖 that keeps a check on usage foul language, hate-speech and NSFW contents. It is the one stop solution to monitor your discord servers and twitter handles against community demons by offering content moderation.
 5 Nov 16, 2022
5 Nov 16, 2022

PyTorch implementation of Lip to Speech Synthesis with Visual Context Attentional GAN (NeurIPS2021)
Lip to Speech Synthesis with Visual Context Attentional GAN This repository contains the PyTorch implementation of the following paper: Lip to Speech
 6 Nov 2, 2022
6 Nov 2, 2022
RARA: Zero-shot Sim2Real Visual Navigation with Following Foreground Cues
RARA: Zero-shot Sim2Real Visual Navigation with Following Foreground Cues FGBG (foreground-background) pytorch package for defining and training model
 1 Jun 2, 2022
1 Jun 2, 2022

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022

Fancy console logger and wise assistant within your python projects
Fancy console logger and wise assistant within your python projects. Made to save tons of hours for common routines.
 5 Apr 1, 2022
5 Apr 1, 2022

A High-Quality Real Time Upscaler for Anime Video
Anime4K Anime4K is a set of open-source, high-quality real-time anime upscaling/denoising algorithms that can be implemented in any programming langua
 15.7k Jan 6, 2023
15.7k Jan 6, 2023
Housing Price Prediction Using Machine Learning.
HOUSING PRICE PREDICTION USING MACHINE LEARNING DESCRIPTION Housing Price Prediction Using Machine Learning is to predict the data of housings. Here I
 1 Aug 3, 2022
1 Aug 3, 2022
Which Apple Keeps Which Doctor Away? Colorful Word Representations with Visual Oracles
Which Apple Keeps Which Doctor Away? Colorful Word Representations with Visual Oracles (TASLP 2022)
 3 Apr 14, 2022
3 Apr 14, 2022

PyTorch implementaton of our CVPR 2021 paper "Bridging the Visual Gap: Wide-Range Image Blending"
Bridging the Visual Gap: Wide-Range Image Blending PyTorch implementaton of our CVPR 2021 paper "Bridging the Visual Gap: Wide-Range Image Blending".
 69 Dec 20, 2022
69 Dec 20, 2022
Implementation of paper "DCS-Net: Deep Complex Subtractive Neural Network for Monaural Speech Enhancement"
DCS-Net This is the implementation of "DCS-Net: Deep Complex Subtractive Neural Network for Monaural Speech Enhancement" Steps to run the model Edit V
 10 Apr 4, 2022
10 Apr 4, 2022
End-to-end speech secognition toolkit
End-to-end speech secognition toolkit This is an E2E ASR toolkit modified from Espnet1 (version 0.9.9). This is the official implementation of paper:
 147 Dec 28, 2022
147 Dec 28, 2022

A Physics-based Noise Formation Model for Extreme Low-light Raw Denoising (CVPR 2020 Oral & TPAMI 2021)
ELD The implementation of CVPR 2020 (Oral) paper "A Physics-based Noise Formation Model for Extreme Low-light Raw Denoising" and its journal (TPAMI) v
 359 Jan 1, 2023
359 Jan 1, 2023

Speech Recognition Database Management with python
Speech Recognition Database Management The main aim of this project is to recogn
 2 Feb 2, 2022
2 Feb 2, 2022

Speech to text streamlit app
Speech to text Streamlit-app! 👄 This speech to text recognition is powered by t
 9 Jan 1, 2023
9 Jan 1, 2023
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi.
Spchcat Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that read
 279 Jan 3, 2023
279 Jan 3, 2023

A self-supervised learning framework for audio-visual speech
AV-HuBERT (Audio-Visual Hidden Unit BERT) Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction Robust Self-Supervised A
 431 Jan 7, 2023
431 Jan 7, 2023

The official code for the ICCV-2021 paper "Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates".
SpeechDrivesTemplates The official repo for the ICCV-2021 paper "Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates". [arxiv
 53 Dec 23, 2022
53 Dec 23, 2022

We propose the adversarial blur attack (ABA) against visual object tracking.
ABA We propose the adversarial blur attack (ABA) against visual object tracking. The ICCV link: https://arxiv.org/abs/2107.12085 and, https://openacce
 13 Dec 1, 2022
13 Dec 1, 2022

Train Scene Graph Generation for Visual Genome and GQA in PyTorch = 1.2 with improved zero and few-shot generalization.
Scene Graph Generation Object Detections Ground truth Scene Graph Generated Scene Graph In this visualization, woman sitting on rock is a zero-shot tr
 93 Dec 28, 2022
93 Dec 28, 2022
Code and Experiments for ACL-IJCNLP 2021 Paper Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering.
Code and Experiments for ACL-IJCNLP 2021 Paper Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering.
 50 Nov 16, 2022
50 Nov 16, 2022

Graphical Password Authentication System.
Graphical Password Authentication System. This is used to increase the protection/security of a website. Our system is divided into further 4 layers of protection. Each layer is totally different and diverse than the others. This not only increases protection, but also makes sure that no non-human can log in to your account using different activities such as Brute Force Algorithm and so on.
 12 Dec 16, 2022
12 Dec 16, 2022
ConferencingSpeech2022; Non-intrusive Objective Speech Quality Assessment (NISQA) Challenge
ConferencingSpeech 2022 challenge This repository contains the datasets list and scripts required for the ConferencingSpeech 2022 challenge. For more
 21 Dec 2, 2022
21 Dec 2, 2022

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 9, 2023
1.3k Jan 9, 2023

Automagically synchronize subtitles with video.
FFsubsync Language-agnostic automatic synchronization of subtitles with video, so that subtitles are aligned to the correct starting point within the
 5.7k Jan 6, 2023
5.7k Jan 6, 2023

Go from graph data to a secure and interactive visual graph app in 15 minutes. Batteries-included self-hosting of graph data apps with Streamlit, Graphistry, RAPIDS, and more!
✔️ Linux ✔️ OS X ❌ Windows (#39) Welcome to graph-app-kit Turn your graph data into a secure and interactive visual graph app in 15 minutes! Why This
 107 Jan 2, 2023
107 Jan 2, 2023

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022

(EI 2022) Controllable Confidence-Based Image Denoising
Image Denoising with Control over Deep Network Hallucination Paper and arXiv preprint -- Our frequency-domain insights derive from SFM and the concept
 5 Dec 18, 2022
5 Dec 18, 2022

Referring Video Object Segmentation
Awesome-Referring-Video-Object-Segmentation Welcome to starts ⭐ & comments 💹 & sharing 😀 !! - 2021.12.12: Recent papers (from 2021) - welcome to ad
 57 Dec 11, 2022
57 Dec 11, 2022

A simple Tensorflow based library for deep and/or denoising AutoEncoder.
libsdae - deep-Autoencoder & denoising autoencoder A simple Tensorflow based library for Deep autoencoder and denoising AE. Library follows sklearn st
 147 Nov 18, 2022
147 Nov 18, 2022
PyTorch code for: Learning to Generate Grounded Visual Captions without Localization Supervision
Learning to Generate Grounded Visual Captions without Localization Supervision This is the PyTorch implementation of our paper: Learning to Generate G
 41 Nov 17, 2022
41 Nov 17, 2022

Meshed-Memory Transformer for Image Captioning. CVPR 2020
M²: Meshed-Memory Transformer This repository contains the reference code for the paper Meshed-Memory Transformer for Image Captioning (CVPR 2020). Pl
 422 Dec 28, 2022
422 Dec 28, 2022
This repository focus on Image Captioning & Video Captioning & Seq-to-Seq Learning & NLP
Awesome-Visual-Captioning Table of Contents ACL-2021 CVPR-2021 AAAI-2021 ACMMM-2020 NeurIPS-2020 ECCV-2020 CVPR-2020 ACL-2020 AAAI-2020 ACL-2019 NeurI
 362 Jan 3, 2023
362 Jan 3, 2023
Asr abc - Automatic speech recognition(ASR),中文语音识别
语音识别的简单示例,主要在课堂演示使用 创建python虚拟环境 在linux 和macos 上验证通过 # 如果已经有pyhon3.6 环境,跳过该步骤,使用
 8 Nov 11, 2022
8 Nov 11, 2022

Pytorch-diffusion - A basic PyTorch implementation of 'Denoising Diffusion Probabilistic Models'
PyTorch implementation of 'Denoising Diffusion Probabilistic Models' This reposi
 76 Jan 7, 2023
76 Jan 7, 2023

Image captioning - Tensorflow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Introduction This neural system for image captioning is roughly based on the paper "Show, Attend and Tell: Neural Image Caption Generation with Visual
 749 Dec 28, 2022
749 Dec 28, 2022
DeepSpeech - Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation.
(简体中文|English) Quick Start | Documents | Models List PaddleSpeech is an open-source toolkit on PaddlePaddle platform for a variety of critical tasks i
 5.6k Jan 3, 2023
5.6k Jan 3, 2023
NFT-Price-Prediction-CNN - Using visual feature extraction, prices of NFTs are predicted via CNN (Alexnet and Resnet) architectures.
NFT-Price-Prediction-CNN - Using visual feature extraction, prices of NFTs are predicted via CNN (Alexnet and Resnet) architectures.
 5 Nov 3, 2022
5 Nov 3, 2022
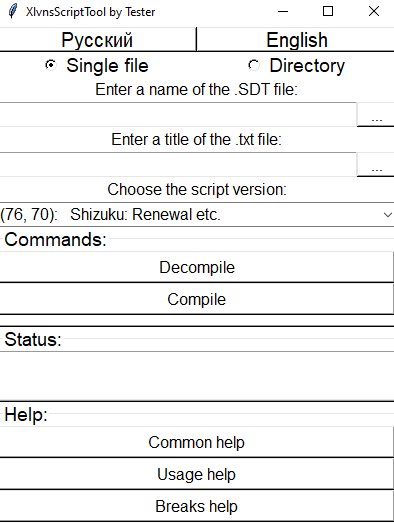
XlvnsScriptTool - Tool for decompilation and compilation of scripts .SDT from the visual novel's engine xlvns
XlvnsScriptTool English Dual languaged (rus+eng) tool for decompiling and compiling (actually, this tool is more than just (dis)assenbler, but less th
 3 Sep 15, 2022
3 Sep 15, 2022

Amazing-Python-Scripts - 🚀 Curated collection of Amazing Python scripts from Basics to Advance with automation task scripts.
📑 Introduction A curated collection of Amazing Python scripts from Basics to Advance with automation task scripts. This is your Personal space to fin
 1.1k Dec 29, 2022
1.1k Dec 29, 2022

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

Pseudo lidar - (CVPR 2019) Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving This paper has been accpeted by Conference o
 881 Dec 27, 2022
881 Dec 27, 2022

SPT_LSA_ViT - Implementation for Visual Transformer for Small-size Datasets
Vision Transformer for Small-Size Datasets Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song | Paper Inha University Abstract Recently, the Vision
 87 Jan 1, 2023
87 Jan 1, 2023

Pseudo-rng-app - whos needs science to make a random number when you have pseudoscience?
Pseudo-random numbers with pseudoscience rng is so complicated! Why cant we have a horoscopic, vibe-y way of calculating a random number? Why cant rng
 1 Dec 27, 2021
1 Dec 27, 2021

VQMIVC - Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion (Interspeech
 262 Dec 31, 2022
262 Dec 31, 2022

SpecAugmentPyTorch - A Pytorch (support batch and channel) implementation of GoogleBrain's SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
SpecAugment An implementation of SpecAugment for Pytorch How to use Install pytorch, version=1.9.0 (new feature (torch.Tensor.take_along_dim) is used
 3 Oct 11, 2022
3 Oct 11, 2022
Minimal diffusion models - Minimal code and simple experiments to play with Denoising Diffusion Probabilistic Models (DDPMs)
Minimal code and simple experiments to play with Denoising Diffusion Probabilist
 16 Oct 6, 2022
16 Oct 6, 2022

The codebase for Data-driven general-purpose voice activity detection.
Data driven GPVAD Repository for the work in TASLP 2021 Voice activity detection in the wild: A data-driven approach using teacher-student training. S
 75 Nov 27, 2022
75 Nov 27, 2022

Scaling and Benchmarking Self-Supervised Visual Representation Learning
FAIR Self-Supervision Benchmark is deprecated. Please see VISSL, a ground-up rewrite of benchmark in PyTorch. FAIR Self-Supervision Benchmark This cod
584 Dec 31, 2022
基于百度的语音识别,用python实现,pyaudio+pyqt
Speech-recognition 基于百度的语音识别,python3.8(conda)+pyaudio+pyqt+baidu-aip 百度有面向python
 1 Jan 3, 2022
1 Jan 3, 2022

Official implementation of CATs: Cost Aggregation Transformers for Visual Correspondence NeurIPS'21
CATs: Cost Aggregation Transformers for Visual Correspondence NeurIPS'21 For more information, check out the paper on [arXiv]. Training with different
 120 Jan 4, 2023
120 Jan 4, 2023
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022
🔀 Visual Room Rearrangement
AI2-THOR Rearrangement Challenge Welcome to the 2021 AI2-THOR Rearrangement Challenge hosted at the CVPR'21 Embodied-AI Workshop. The goal of this cha
 55 Dec 22, 2022
55 Dec 22, 2022

For storing the complete exploration of Visual Question Answering for our B.Tech Project
Multi-Image vqa @authors: Akhilesh, Janhavi, Harsh Paper summary, Ideas tried and their corresponding results: on wiki Other discussions: on discussio
 3 Jun 16, 2022
3 Jun 16, 2022
Autoregressive Predictive Coding: An unsupervised autoregressive model for speech representation learning
Autoregressive Predictive Coding This repository contains the official implementation (in PyTorch) of Autoregressive Predictive Coding (APC) proposed
 173 Dec 18, 2022
173 Dec 18, 2022

Code to generate datasets used in "How Useful is Self-Supervised Pretraining for Visual Tasks?"
Synthetic dataset rendering Framework for producing the synthetic datasets used in: How Useful is Self-Supervised Pretraining for Visual Tasks? Alejan
 21 Apr 29, 2022
21 Apr 29, 2022

PyTorch implementation of MoCo: Momentum Contrast for Unsupervised Visual Representation Learning
MoCo: Momentum Contrast for Unsupervised Visual Representation Learning This is a PyTorch implementation of the MoCo paper: @Article{he2019moco, aut
3.7k Jan 2, 2023
![[arXiv 2020] Video Representation Learning with Visual Tempo Consistency](https://github.com/decisionforce/VTHCL/raw/master/docs/figures/pipeline.png)
[arXiv 2020] Video Representation Learning with Visual Tempo Consistency
Video Representation Learning with Visual Tempo Consistency [Paper] [Project Page] News Full codebae is coming soon Pretained Models For now, we provi
 24 Nov 23, 2022
24 Nov 23, 2022

An unsupervised learning framework for depth and ego-motion estimation from monocular videos
SfMLearner This codebase implements the system described in the paper: Unsupervised Learning of Depth and Ego-Motion from Video Tinghui Zhou, Matthew
 1.8k Dec 30, 2022
1.8k Dec 30, 2022

Code for the paper: Audio-Visual Scene Analysis with Self-Supervised Multisensory Features
[Paper] [Project page] This repository contains code for the paper: Andrew Owens, Alexei A. Efros. Audio-Visual Scene Analysis with Self-Supervised Mu
 202 Dec 13, 2022
202 Dec 13, 2022
Percy visual testing for Python Selenium
percy-selenium-python Percy visual testing for Python Selenium. Installation npm install @percy/cli: $ npm install --save-dev @percy/cli pip install P
 9 Mar 24, 2022
9 Mar 24, 2022

A small script written in Python3 that generates a visual representation of the Mandelbrot set.
Mandelbrot Set Generator A small script written in Python3 that generates a visual representation of the Mandelbrot set. Abstract The colors in the ou
 1 Dec 28, 2021
1 Dec 28, 2021

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 2, 2023
1.1k Jan 2, 2023

🚀Clone a voice in 5 seconds to generate arbitrary speech in real-time
English | 中文 Features 🌍 Chinese supported mandarin and tested with multiple datasets: aidatatang_200zh, magicdata, aishell3, data_aishell, and etc. ?
 25.6k Dec 31, 2022
25.6k Dec 31, 2022

TE-dependent analysis (tedana) is a Python library for denoising multi-echo functional magnetic resonance imaging (fMRI) data
tedana: TE Dependent ANAlysis TE-dependent analysis (tedana) is a Python library for denoising multi-echo functional magnetic resonance imaging (fMRI)
 136 Dec 22, 2022
136 Dec 22, 2022
![[ACMMM 2021, Oral] Code release for](https://github.com/yikaiw/EIP/raw/main/assets/intro.png)
[ACMMM 2021, Oral] Code release for "Elastic Tactile Simulation Towards Tactile-Visual Perception"
EIP: Elastic Interaction of Particles Code release for "Elastic Tactile Simulation Towards Tactile-Visual Perception", in ACMMM (Oral) 2021. By Yikai
 37 Dec 20, 2022
37 Dec 20, 2022

CVPR2021 Workshop - HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization.
HDRUNet [Paper Link] HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization By Xiangyu Chen, Yihao Liu, Zhengwen Zhang, Yu Qiao an
 105 Dec 20, 2022
105 Dec 20, 2022

Visual odometry package based on hardware-accelerated NVIDIA Elbrus library with world class quality and performance.
Isaac ROS Visual Odometry This repository provides a ROS2 package that estimates stereo visual inertial odometry using the Isaac Elbrus GPU-accelerate
 343 Jan 3, 2023
343 Jan 3, 2023
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger In this project, our aim is to tune, compare, and contrast the perf
 0 Dec 25, 2021
0 Dec 25, 2021
The ability of computer software to identify words and phrases in spoken language and convert them to human-readable text
speech-recognition-py Speech recognition is the ability of computer software to identify words and phrases in spoken language and convert them to huma
 1 Apr 3, 2022
1 Apr 3, 2022
Python package for analyzing behavioral data for Brain Observatory: Visual Behavior
Allen Institute Visual Behavior Analysis package This repository contains code for analyzing behavioral data from the Allen Brain Observatory: Visual
 16 Nov 4, 2022
16 Nov 4, 2022

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
 76 Nov 30, 2022
76 Nov 30, 2022

Prososdy Morph: A python library for manipulating pitch and duration in an algorithmic way, for resynthesizing speech.
ProMo (Prosody Morph) Questions? Comments? Feedback? Chat with us on gitter! A library for manipulating pitch and duration in an algorithmic way, for
 71 Jan 2, 2023
71 Jan 2, 2023
Weak-supervised Visual Geo-localization via Attention-based Knowledge Distillation
Weak-supervised Visual Geo-localization via Attention-based Knowledge Distillation Introduction WAKD is a PyTorch implementation for our ICPR-2022 pap
 2 Oct 20, 2022
2 Oct 20, 2022
Cilantropy: a Python Package Manager interface created to provide an "easy-to-use" visual and also a command-line interface for Pythonistas.
Cilantropy Cilantropy is a Python Package Manager interface created to provide an "easy-to-use" visual and also a command-line interface for Pythonist
 48 Dec 16, 2022
48 Dec 16, 2022
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021

ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python)
ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python) 日本語は以下に続きます (Japanese follows) English: This book is written in Japanese and primaril
 189 Dec 29, 2022
189 Dec 29, 2022

Dual languaged (rus+eng) tool for packing and unpacking archives of Silky Engine.
SilkyArcTool English Dual languaged (rus+eng) GUI tool for packing and unpacking archives of Silky Engine. It is not the same arc as used in Ai6WIN. I
5 Sep 15, 2022
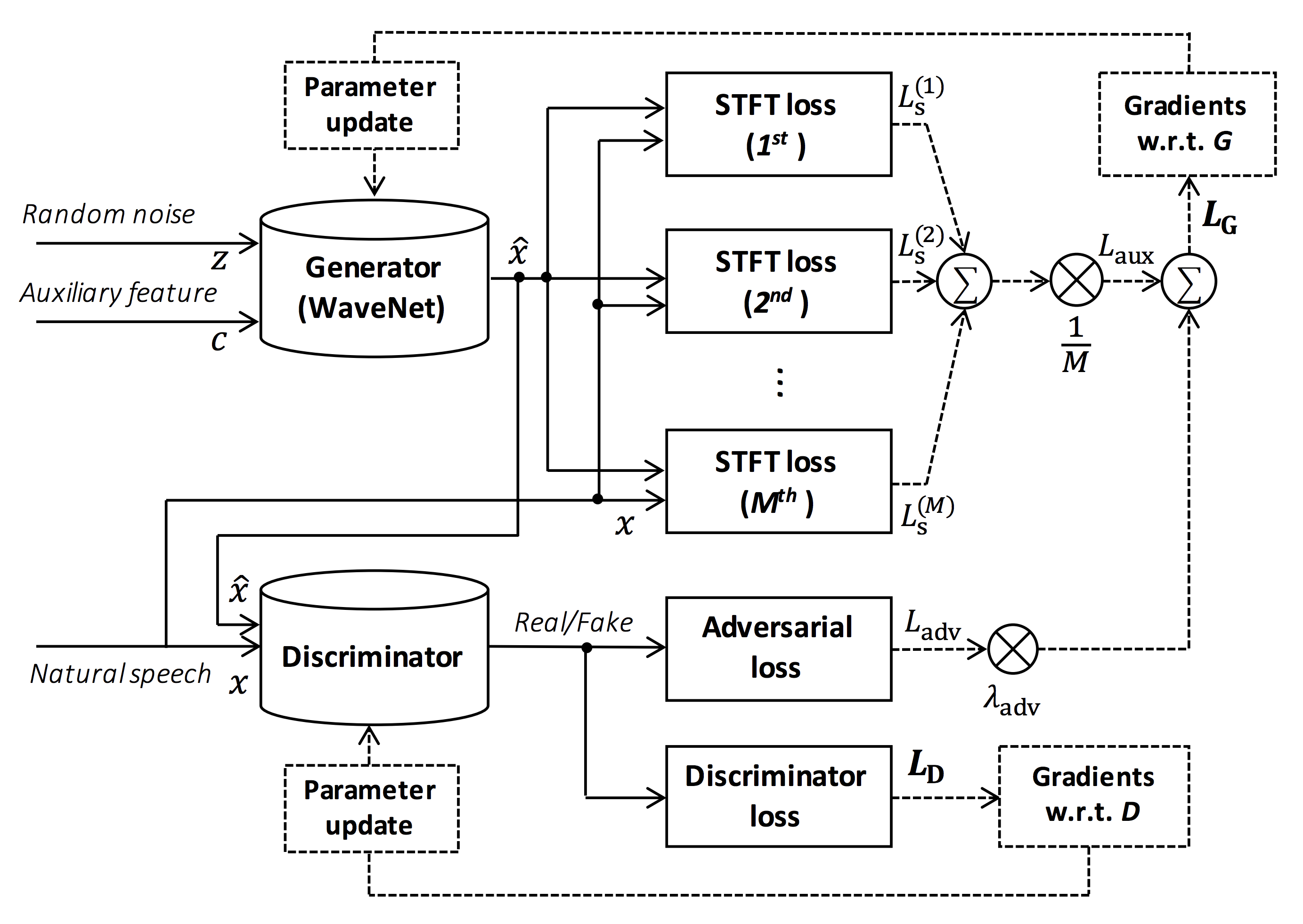
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022

This repository provides data for the VAW dataset as described in the CVPR 2021 paper titled "Learning to Predict Visual Attributes in the Wild"
Visual Attributes in the Wild (VAW) This repository provides data for the VAW dataset as described in the CVPR 2021 Paper: Learning to Predict Visual
 36 Dec 30, 2022
36 Dec 30, 2022
[AAAI-2022] Official implementations of MCL: Mutual Contrastive Learning for Visual Representation Learning
Mutual Contrastive Learning for Visual Representation Learning This project provides source code for our Mutual Contrastive Learning for Visual Repres
 48 Jan 2, 2023
48 Jan 2, 2023