789 Repositories
Python pseudo-visual-speech-denoising Libraries
VoiceFixer VoiceFixer is a framework for general speech restoration.
VoiceFixer VoiceFixer is a framework for general speech restoration. We aim at the restoration of severly degraded speech and historical speech. Paper
 174 Jan 6, 2023
174 Jan 6, 2023

A 10000+ hours dataset for Chinese speech recognition
A 10000+ hours dataset for Chinese speech recognition
 309 Dec 16, 2022
309 Dec 16, 2022
Voicefixer aims at the restoration of human speech regardless how serious its degraded.
Voicefixer aims at the restoration of human speech regardless how serious its degraded.
324 Dec 26, 2022
A Fast and Accurate One-Stage Approach to Visual Grounding, ICCV 2019 (Oral)
One-Stage Visual Grounding ***** New: Our recent work on One-stage VG is available at ReSC.***** A Fast and Accurate One-Stage Approach to Visual Grou
 118 Dec 5, 2022
118 Dec 5, 2022

Unofficial Implementation of Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration This repo contains only model Implementation of Zero-Shot Text-to-Speech for Text
 33 Sep 22, 2022
33 Sep 22, 2022

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
 237 Jan 2, 2023
237 Jan 2, 2023
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
 2.7k Jan 5, 2023
2.7k Jan 5, 2023

Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation (SIGGRAPH Asia 2021)
Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation This repository contains the implementation of the following paper: Live Speech
 575 Dec 31, 2022
575 Dec 31, 2022

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
 883 Jan 7, 2023
883 Jan 7, 2023
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
 204 Jul 14, 2022
204 Jul 14, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 2, 2023
77.2k Jan 2, 2023

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Jan 8, 2023
1.8k Jan 8, 2023
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
279 Dec 9, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
 166 Dec 11, 2022
166 Dec 11, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Labelling platform for text using distant supervision
With DataQA, you can label unstructured text documents using rule-based distant supervision.
 245 Aug 5, 2022
245 Aug 5, 2022
Speech Recognition using DeepSpeech2.
deepspeech.pytorch Implementation of DeepSpeech2 for PyTorch using PyTorch Lightning. The repo supports training/testing and inference using the DeepS
 2k Jan 4, 2023
2k Jan 4, 2023
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022

Neural network models for joint POS tagging and dependency parsing (CoNLL 2017-2018)
Neural Network Models for Joint POS Tagging and Dependency Parsing Implementations of joint models for POS tagging and dependency parsing, as describe
 152 Sep 2, 2022
152 Sep 2, 2022

Towards Flexible Blind JPEG Artifacts Removal (FBCNN, ICCV 2021)
Towards Flexible Blind JPEG Artifacts Removal (FBCNN, ICCV 2021)
 282 Jan 2, 2023
282 Jan 2, 2023
This project converts your human voice input to its text transcript and to an automated voice too.
Human Voice to Automated Voice & Text Introduction: In this project, whenever you'll speak, it will turn your voice into a robot voice and furthermore
 3 Oct 15, 2021
3 Oct 15, 2021
Codename generator using WordNet parts of speech database
codenames Codename generator using WordNet parts of speech database References: https://possiblywrong.wordpress.com/2021/09/13/code-name-generator/ ht
 27 Oct 30, 2022
27 Oct 30, 2022

DSAC* for Visual Camera Re-Localization (RGB or RGB-D)
DSAC* for Visual Camera Re-Localization (RGB or RGB-D) Introduction Installation Data Structure Supported Datasets 7Scenes 12Scenes Cambridge Landmark
 143 Dec 22, 2022
143 Dec 22, 2022

Image Restoration Toolbox (PyTorch). Training and testing codes for DPIR, USRNet, DnCNN, FFDNet, SRMD, DPSR, BSRGAN, SwinIR
Image Restoration Toolbox (PyTorch). Training and testing codes for DPIR, USRNet, DnCNN, FFDNet, SRMD, DPSR, BSRGAN, SwinIR
 2k Dec 31, 2022
2k Dec 31, 2022

Line as a Visual Sentence: Context-aware Line Descriptor for Visual Localization
Line as a Visual Sentence with LineTR This repository contains the inference code, pretrained model, and demo scripts of the following paper. It suppo
 158 Dec 27, 2022
158 Dec 27, 2022
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022

ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models (ICCV 2021 Oral)
ILVR + ADM This is the implementation of ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models (ICCV 2021 Oral). This repository is h
 225 Dec 28, 2022
225 Dec 28, 2022
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
 18 Dec 9, 2022
18 Dec 9, 2022
![[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification](https://github.com/raoyongming/CAL/raw/master/figs/intro.png)
[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Counterfactual Attention Learning Created by Yongming Rao*, Guangyi Chen*, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for ICCV
 90 Dec 31, 2022
90 Dec 31, 2022

Code and data for "Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning" (EMNLP 2021).
GD-VCR Code for Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning (EMNLP 2021). Research Questions and Aims: How well can a model perform o
 24 Oct 13, 2022
24 Oct 13, 2022
Implementation of Common Image Evaluation Metrics by Sayed Nadim (sayednadim.github.io). The repo is built based on full reference image quality metrics such as L1, L2, PSNR, SSIM, LPIPS. and feature-level quality metrics such as FID, IS. It can be used for evaluating image denoising, colorization, inpainting, deraining, dehazing etc. where we have access to ground truth.
Image Quality Evaluation Metrics Implementation of some common full reference image quality metrics. The repo is built based on full reference image q
 10 Jan 1, 2023
10 Jan 1, 2023

A two-stage U-Net for high-fidelity denoising of historical recordings
A two-stage U-Net for high-fidelity denoising of historical recordings Official repository of the paper (not submitted yet): E. Moliner and V. Välimäk
 57 Jan 5, 2023
57 Jan 5, 2023
Official Implementation of Few-shot Visual Relationship Co-localization
VRC Official implementation of the Few-shot Visual Relationship Co-localization (ICCV 2021) paper project page | paper Requirements Use python = 3.8.
 22 Oct 13, 2022
22 Oct 13, 2022
[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Counterfactual Attention Learning Created by Yongming Rao*, Guangyi Chen*, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for ICCV
89 Dec 18, 2022

Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition
Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition Official implementation of the Efficient Conforme
 145 Dec 30, 2022
145 Dec 30, 2022

Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library.
GI-Pi Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library. The SP0
 8 Dec 15, 2021
8 Dec 15, 2021
Implementation of "A Deep Learning Loss Function based on Auditory Power Compression for Speech Enhancement" by pytorch
This repository is used to suspend the results of our paper "A Deep Learning Loss Function based on Auditory Power Compression for Speech Enhancement"
 19 Sep 30, 2022
19 Sep 30, 2022
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
 1.7k Dec 28, 2022
1.7k Dec 28, 2022
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022

Cockpit is a visual and statistical debugger specifically designed for deep learning.
Cockpit: A Practical Debugging Tool for Training Deep Neural Networks
 421 Dec 29, 2022
421 Dec 29, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
[ICCV 2021] Released code for Causal Attention for Unbiased Visual Recognition
CaaM This repo contains the codes of training our CaaM on NICO/ImageNet9 dataset. Due to my recent limited bandwidth, this codebase is still messy, wh
 66 Dec 31, 2022
66 Dec 31, 2022
Code for the ICASSP-2021 paper: Continuous Speech Separation with Conformer.
Continuous Speech Separation with Conformer Introduction We examine the use of the Conformer architecture for continuous speech separation. Conformer
 81 Nov 28, 2022
81 Nov 28, 2022

This repo implements a Topological SLAM: Deep Visual Odometry with Long Term Place Recognition (Loop Closure Detection)
This repo implements a topological SLAM system. Deep Visual Odometry (DF-VO) and Visual Place Recognition are combined to form the topological SLAM system.
 32 Jun 23, 2022
32 Jun 23, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
54 Aug 30, 2021
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
 24 Sep 7, 2022
24 Sep 7, 2022

The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation
PointNav-VO The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation Project Page | Paper Table of Contents Setup
 41 Dec 15, 2022
41 Dec 15, 2022

SwinIR: Image Restoration Using Swin Transformer
SwinIR: Image Restoration Using Swin Transformer This repository is the official PyTorch implementation of SwinIR: Image Restoration Using Shifted Win
 2.4k Jan 8, 2023
2.4k Jan 8, 2023
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion Yinghao Aaron Li, Ali Zare, Nima Mesgarani We pres
 282 Jan 1, 2023
282 Jan 1, 2023

GSoC'2021 | TensorFlow implementation of Wav2Vec2
GSoC'2021 | TensorFlow implementation of Wav2Vec2
 73 Nov 28, 2022
73 Nov 28, 2022
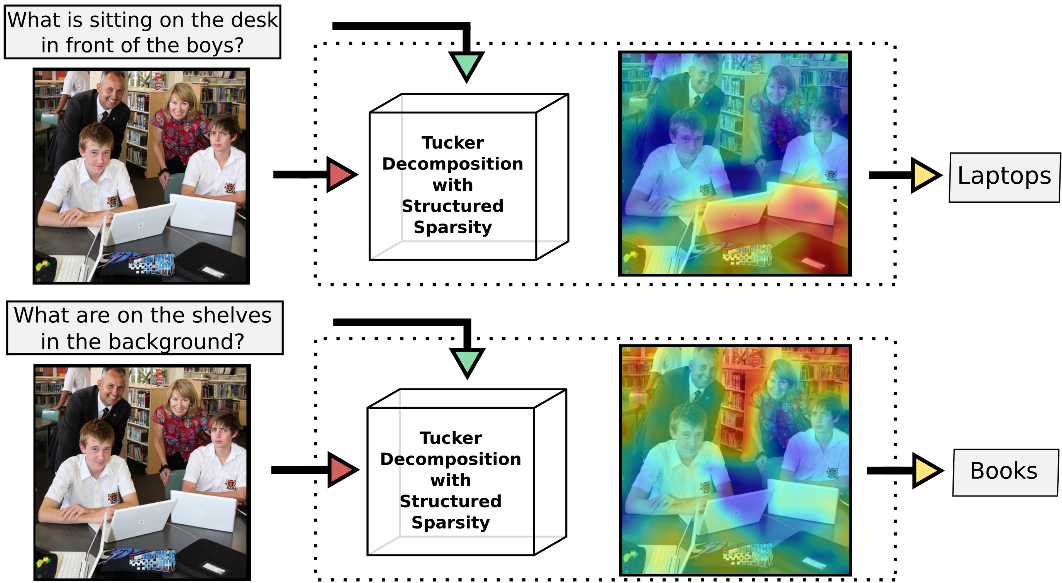
Visual Question Answering in Pytorch
Visual Question Answering in pytorch /!\ New version of pytorch for VQA available here: https://github.com/Cadene/block.bootstrap.pytorch This repo wa
 672 Jan 1, 2023
672 Jan 1, 2023
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
166 Dec 11, 2022
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
279 Dec 9, 2022
This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab.
Speech-Backbones This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab. Grad-TTS Official implementation of the Grad-
 295 Jan 7, 2023
295 Jan 7, 2023
Experiments on Flood Segmentation on Sentinel-1 SAR Imagery with Cyclical Pseudo Labeling and Noisy Student Training
Flood Detection Challenge This repository contains code for our submission to the ETCI 2021 Competition on Flood Detection (Winning Solution #2). Acco
 108 Dec 28, 2022
108 Dec 28, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023
A management system designed for the employees of MIRAS (Art Gallery). It is used to sell/cancel tickets, book/cancel events and keeps track of all upcoming events.
Art-Galleria-Management-System Its a management system designed for the employees of MIRAS (Art Gallery). Backend : Python Frontend : Django Database
 8 Nov 30, 2022
8 Nov 30, 2022

A weakly-supervised scene graph generation codebase. The implementation of our CVPR2021 paper ``Linguistic Structures as Weak Supervision for Visual Scene Graph Generation''
README.md shall be finished soon. WSSGG 0 Overview 1 Installation 1.1 Faster-RCNN 1.2 Language Parser 1.3 GloVe Embeddings 2 Settings 2.1 VG-GT-Graph
 35 Nov 20, 2022
35 Nov 20, 2022
![[NeurIPS 2020] Official repository for the project](https://github.com/henryxrl/Listening-to-Sound-of-Silence-for-Speech-Denoising/raw/main/assets/network.png)
[NeurIPS 2020] Official repository for the project "Listening to Sound of Silence for Speech Denoising"
Listening to Sounds of Silence for Speech Denoising Introduction This is the repository of the "Listening to Sounds of Silence for Speech Denoising" p
 40 Dec 20, 2022
40 Dec 20, 2022
ExKaldi-RT: An Online Speech Recognition Extension Toolkit of Kaldi
ExKaldi-RT is an online ASR toolkit for Python language. It reads realtime streaming audio and do online feature extraction, probability computation, and online decoding.
 31 Aug 16, 2021
31 Aug 16, 2021
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 169 Jan 5, 2023
169 Jan 5, 2023
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
 41 Jan 3, 2023
41 Jan 3, 2023

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
47 Dec 18, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023
StarGAN-ZSVC: Unofficial PyTorch Implementation
This repository is an unofficial PyTorch implementation of StarGAN-ZSVC by Matthew Baas and Herman Kamper. This repository provides both model architectures and the code to inference or train them.
 11 Aug 28, 2022
11 Aug 28, 2022
Video Visual Relation Detection (VidVRD) tracklets generation. also for ACM MM Visual Relation Understanding Grand Challenge
VidVRD-tracklets This repository contains codes for Video Visual Relation Detection (VidVRD) tracklets generation based on MEGA and deepSORT. These tr
 25 Dec 21, 2022
25 Dec 21, 2022

End-to-end text to speech system using gruut and onnx. There are 40 voices available across 8 languages.
End to end text to speech system using gruut and onnx
 673 Dec 28, 2022
673 Dec 28, 2022
Data from "HateCheck: Functional Tests for Hate Speech Detection Models" (Röttger et al., ACL 2021)
In this repo, you can find the data from our ACL 2021 paper "HateCheck: Functional Tests for Hate Speech Detection Models". "test_suite_cases.csv" con
 43 Nov 11, 2022
43 Nov 11, 2022

Clone a voice in 5 seconds to generate arbitrary speech in real-time
This repository is forked from Real-Time-Voice-Cloning which only support English. English | 中文 Features 🌍 Chinese supported mandarin and tested with
 25.6k Jan 6, 2023
25.6k Jan 6, 2023

Official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers
Visual Parser (ViP) This is the official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers. Key Feature
 117 Dec 11, 2022
117 Dec 11, 2022
This repository contains data used in the NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Proteno This is the data release associated with the corresponding NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deploymen
37 Dec 4, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022
DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021)
DPT This repo is the official implementation of DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021). We provide code and model
 111 Dec 21, 2022
111 Dec 21, 2022
This is the code for CVPR 2021 oral paper: Jigsaw Clustering for Unsupervised Visual Representation Learning
JigsawClustering Jigsaw Clustering for Unsupervised Visual Representation Learning Pengguang Chen, Shu Liu, Jiaya Jia Introduction This project provid
 73 Sep 18, 2022
73 Sep 18, 2022

Dataset used in "PlantDoc: A Dataset for Visual Plant Disease Detection" accepted in CODS-COMAD 2020
PlantDoc: A Dataset for Visual Plant Disease Detection This repository contains the Cropped-PlantDoc dataset used for benchmarking classification mode
 109 Dec 29, 2022
109 Dec 29, 2022
Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
170 Jan 4, 2023

Chinese real time voice cloning (VC) and Chinese text to speech (TTS).
Chinese real time voice cloning (VC) and Chinese text to speech (TTS). 好用的中文语音克隆兼中文语音合成系统,包含语音编码器、语音合成器、声码器和可视化模块。
 6 Nov 8, 2022
6 Nov 8, 2022

This's an implementation of deepmind Visual Interaction Networks paper using pytorch
Visual-Interaction-Networks An implementation of Deepmind visual interaction networks in Pytorch. Introduction For the purpose of understanding the ch
 166 Dec 6, 2022
166 Dec 6, 2022

PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs
PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs This code aims to reproduce results obtained in the paper "Visual F
 93 Aug 17, 2022
93 Aug 17, 2022
PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
1.8k Dec 30, 2022

Bilinear attention networks for visual question answering
Bilinear Attention Networks This repository is the implementation of Bilinear Attention Networks for the visual question answering and Flickr30k Entit
 506 Nov 29, 2022
506 Nov 29, 2022

source code of “Visual Saliency Transformer” (ICCV2021)
Visual Saliency Transformer (VST) source code for our ICCV 2021 paper “Visual Saliency Transformer” by Nian Liu, Ni Zhang, Kaiyuan Wan, Junwei Han, an
 89 Dec 21, 2022
89 Dec 21, 2022

🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
 7.7k Jan 5, 2023
7.7k Jan 5, 2023
Open-Source Toolkit for End-to-End Speech Recognition leveraging PyTorch-Lightning and Hydra.
🤗 Contributing to OpenSpeech 🤗 OpenSpeech provides reference implementations of various ASR modeling papers and three languages recipe to perform ta
 513 Jan 3, 2023
513 Jan 3, 2023

ICML 21 - Voice2Series: Reprogramming Acoustic Models for Time Series Classification
Voice2Series-Reprogramming Voice2Series: Reprogramming Acoustic Models for Time Series Classification International Conference on Machine Learning (IC
 49 Jan 3, 2023
49 Jan 3, 2023

Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
 193 Dec 30, 2022
193 Dec 30, 2022

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022

PyTorch implementation of "Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning"
Transparency-by-Design networks (TbD-nets) This repository contains code for replicating the experiments and visualizations from the paper Transparenc
 351 Nov 18, 2022
351 Nov 18, 2022
A Flow-based Generative Network for Speech Synthesis
WaveGlow: a Flow-based Generative Network for Speech Synthesis Ryan Prenger, Rafael Valle, and Bryan Catanzaro In our recent paper, we propose WaveGlo
 2k Dec 26, 2022
2k Dec 26, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
77.2k Jan 3, 2023
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
204 Jul 14, 2022
A Python library to utilize AWS API Gateway's large IP pool as a proxy to generate pseudo-infinite IPs for web scraping and brute forcing.
A Python library to utilize AWS API Gateway's large IP pool as a proxy to generate pseudo-infinite IPs for web scraping and brute forcing.
 929 Jan 1, 2023
929 Jan 1, 2023
Athena is an open-source implementation of end-to-end speech processing engine.
Athena is an open-source implementation of end-to-end speech processing engine. Our vision is to empower both industrial application and academic research on end-to-end models for speech processing. To make speech processing available to everyone, we're also releasing example implementation and recipe on some opensource dataset for various tasks (Automatic Speech Recognition, Speech Synthesis, Voice Conversion, Speaker Recognition, etc).
 34 Sep 8, 2022
34 Sep 8, 2022
Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
193 Dec 30, 2022