60 Repositories
Python ranked-pages-collector Libraries

JupyterLite demo deployed to GitHub Pages 🚀
JupyterLite Demo JupyterLite deployed as a static site to GitHub Pages, for demo purposes. ✨ Try it in your browser ✨ ➡️ https://jupyterlite.github.io
 223 Jan 4, 2023
223 Jan 4, 2023
✔👉A Centralized WebApp to Ensure Road Safety by checking on with the activities of the driver and activating label generator using NLP.
AI-For-Road-Safety Challenge hosted by Omdena Hyderabad Chapter Original Repo Link : https://github.com/OmdenaAI/omdena-india-roadsafety Final Present
 7 Nov 29, 2022
7 Nov 29, 2022
Fully-automated scripts for collecting AI-related papers
AI-Paper-Collector Web demo: https://ai-paper-collector.vercel.app/ (recommended) Colab notebook: here Motivation Fully-automated scripts for collecti
 772 Dec 30, 2022
772 Dec 30, 2022

EmailAll - a powerful Email Collect tool
EmailAll A powerful Email Collect tool 0x1 介绍 😲 EmailAll is a powerful Email Co
 473 Dec 22, 2022
473 Dec 22, 2022
split-manga-pages: a command line utility written in Python that converts your double-page layout manga to single-page layout.
split-manga-pages split-manga-pages is a command line utility written in Python that converts your double-page layout manga (or any images in double p
 3 May 24, 2022
3 May 24, 2022
The Sue Gray Alert System was a 5 minute project that just beeps every time a new article is updated or published on Gov.UK's news pages.
The Sue Gray Alert System was a 5 minute project that just beeps every time a new article is updated or published on Gov.UK's news pages.
 1 Jan 31, 2022
1 Jan 31, 2022
A simple web application built using python flask. It can be used to scan SMEVai accounts for broken pages.
smescan A simple web application built using python flask. It can be used to scan SMEVai accounts for broken pages. Development Process Step 0: Clone
 1 Jan 30, 2022
1 Jan 30, 2022
SickNerd aims to slowly enumerate Google Dorks via the googlesearch API then requests found pages for metadata
CLI tool for making Google Dorking a passive recon experience. With the ability to fetch and filter dorks from GHDB.
 21 Jan 2, 2023
21 Jan 2, 2023
Bootstraparse is a personal project started with a specific goal in mind: creating static html pages for direct display from a markdown-like file
Bootstraparse is a personal project started with a specific goal in mind: creating static html pages for direct display from a markdown-like file
 1 Jun 15, 2022
1 Jun 15, 2022
Video Games Web Scraper is a project that crawls websites and APIs and extracts video game related data from their pages.
Video Games Web Scraper Video Games Web Scraper is a project that crawls websites and APIs and extracts video game related data from their pages. This
 1 Jan 12, 2022
1 Jan 12, 2022
A Python package that can be used to download post and comment data from Reddit.
Reddit Data Collector Reddit Data Collector is a Python package that allows a user to collect post and comment data from Reddit. It is built on top of
 3 Jul 26, 2022
3 Jul 26, 2022

A site that displays up to date COVID-19 stats, powered by fastpages.
https://covid19dashboards.com This project was built with fastpages Background This project showcases how you can use fastpages to create a static das
 1.6k Jan 7, 2023
1.6k Jan 7, 2023
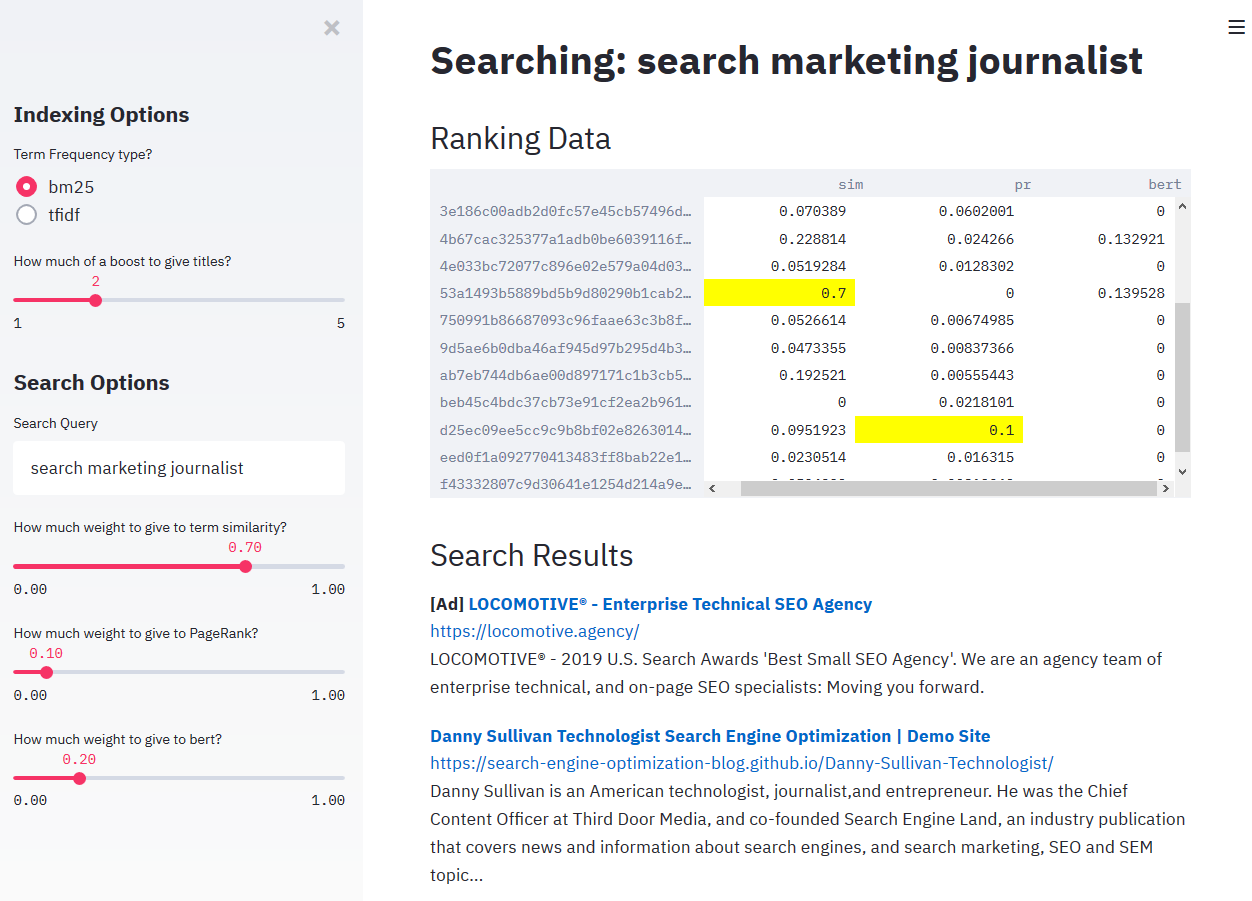
Build a small, 3 domain internet using Github pages and Wikipedia and construct a crawler to crawl, render, and index.
TechSEO Crawler Build a small, 3 domain internet using Github pages and Wikipedia and construct a crawler to crawl, render, and index. Play with the r
 57 Nov 24, 2022
57 Nov 24, 2022
Boamp-extractor - Script d'extraction des AOs publiés au BOAMP
BOAMP Extractor BOAMP-Extractor permet d'extraire les offres de marchés publics publiées au bulletin officiel des annonces des marchés publics (BOAMP)
 3 Dec 9, 2022
3 Dec 9, 2022
Fake news detector filters - Smart filter project allow to classify the quality of information and web pages
fake-news-detector-1.0 Lists, lists and more lists... Spam filter list, quality keyword list, stoplist list, top-domains urls list, news agencies webs
 1 Jan 4, 2022
1 Jan 4, 2022

Fast and robust date extraction from web pages, with Python or on the command-line
Find original and updated publication dates of any web page. From the command-line or within Python, all the steps needed from web page download to HTML parsing, scraping, and text analysis are included.
 60 Dec 14, 2022
60 Dec 14, 2022

A small Python app to create Notion pages from Jira issues
Jira to Notion This little program will capture a Jira issue and create a corresponding Notion subpage. Mac users can fetch the current issue from the
 12 Oct 27, 2022
12 Oct 27, 2022
A bot framework for Reddit to manage threads, wiki pages, widgets, menus and more.
Sub Manager Sub Manager is a bot framework for Reddit to automate a variety of tasks on one or more subreddits, and can be configured and run without
 3 Aug 26, 2022
3 Aug 26, 2022
Python script to tamper with pages to test for Log4J Shell vulnerability.
log4jShell Scanner This shell script scans a vulnerable web application that is using a version of apache-log4j 2.15.0. This application is a static
 8 Oct 20, 2022
8 Oct 20, 2022
Create highly interactive web pages purely in Python
A package for building highly interactive user interfaces in pure Python inspired by ReactJS.
 701 Jan 3, 2023
701 Jan 3, 2023
Just imagine normal bancho, but you can have multiple profiles and funorange speed up maps ranked
Local osu! server Just imagine normal bancho, but you can have multiple profiles and funorange speed up maps ranked (coming soon)! Windows Setup Insta
 25 Nov 15, 2022
25 Nov 15, 2022

A spider for Universal Online Judge(UOJ) system, converting problem pages to PDFs.
Universal Online Judge Spider Introduction This is a spider for Universal Online Judge (UOJ) system (https://uoj.ac/). It also works for all other Onl
 1 Dec 7, 2021
1 Dec 7, 2021
Telegram bot + Flask API ( Make Introduction pages )
Introduction-Page-Maker Setup the api Upload the flask api on your host Setup requirements Make pages file on your host and upload the css and js and
 9 Feb 11, 2022
9 Feb 11, 2022
Inverted index creation and query search mechanism on Wikipedia pages.
WikiPedia Search Engine Step 1 : Installing Requirements Install "stemming" module for python using pip. Step 2 : Parsing the Data To parse the data,
 1 Nov 27, 2021
1 Nov 27, 2021
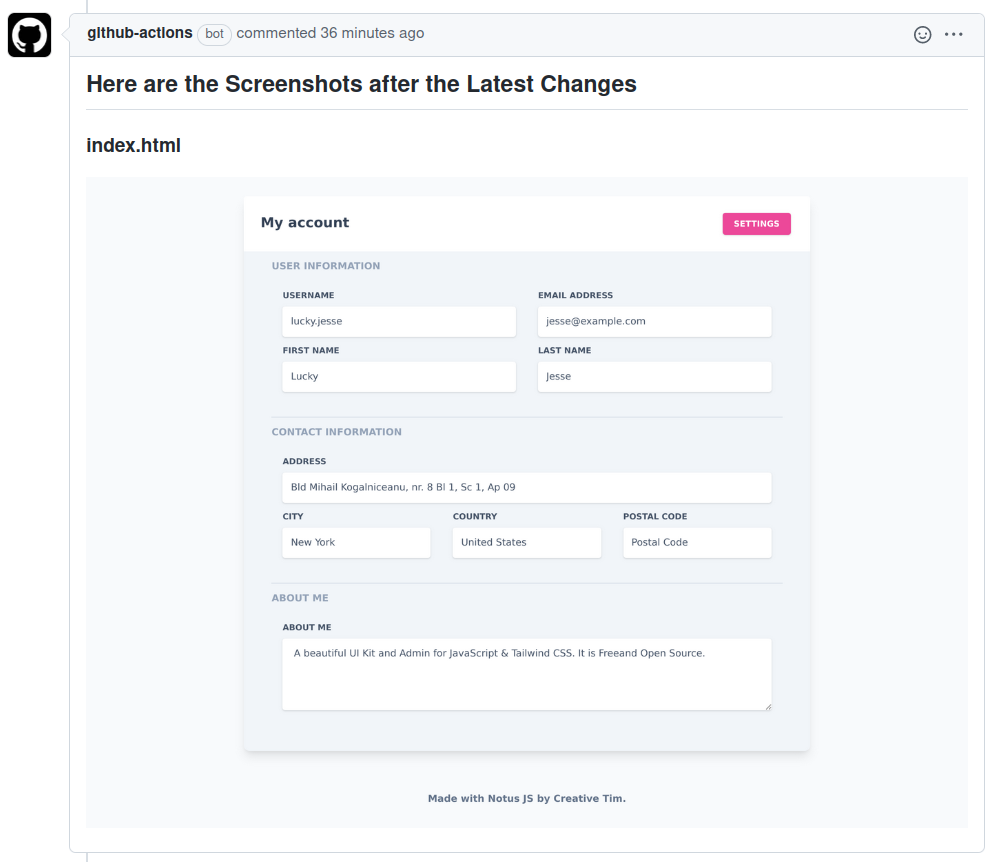
Comment Webpage Screenshot is a GitHub Action that captures screenshots of web pages and HTML files located in the repository
Comment Webpage Screenshot is a GitHub Action that helps maintainers visually review HTML file changes introduced on a Pull Request by adding comments with the screenshots of the latest HTML file changes on the Pull Request
 21 Sep 29, 2022
21 Sep 29, 2022
Use Flask API to wrap Facebook data. Grab the wapper of Facebook public pages without an API key.
Facebook Scraper Use Flask API to wrap Facebook data. Grab the wapper of Facebook public pages without an API key. (Currently working 2021) Setup Befo
 2 Dec 27, 2021
2 Dec 27, 2021
Fully-automated scripts for collecting AI-related papers
AI-Paper-collector Fully-automated scripts for collecting AI-related papers List of Conferences to crawel ACL: 21-19 (including findings) EMNLP: 21-19
 776 Jan 8, 2023
776 Jan 8, 2023
Hobby Project. A Python Library to create and generate static web pages using just python.
PyWeb 🕸️ 🐍 Current Release: 0.1 A Hobby Project 🤓 PyWeb is a small Library to generate customized static web pages using python. Aimed for new deve
 2 Nov 18, 2021
2 Nov 18, 2021
OpenConnect auth creditials collector.
OCSERV AUTH CREDS COLLECTOR V1.0 Зачем Изначально было написано чтобы мониторить какие данные вводятся в интерфейс ханипота в виде OpenConnect server.
 0 Sep 23, 2022
0 Sep 23, 2022
Tools for analyzing Java JVM gc log files
gc_log This package consists of two separate utilities useful for : gc_log_visualizer.py regionsize.py GC Log Visualizer This was updated to run under
 0 Jan 4, 2022
0 Jan 4, 2022
App to get data from popular polish pages with job offers
Job board parser I written simple app to get me data from popular pages with job offers, because I wanted to knew immidietly if there is some new offe
 0 Jan 4, 2022
0 Jan 4, 2022

Small python-gtk application, which helps the user to merge or split pdf documents and rotate, crop and rearrange their pages using an interactive and intuitive graphical interface
Small python-gtk application, which helps the user to merge or split pdf documents and rotate, crop and rearrange their pages using an interactive and intuitive graphical interface
 1.8k Dec 29, 2022
1.8k Dec 29, 2022

Home solar infrastructure (with Peimar Inverter) monitoring based on Raspberry Pi 3 B+ using Grafana, InfluxDB, Custom Python Collector and Shelly EM.
raspberry-solar-mon Home solar infrastructure (with Peimar Inverter) monitoring based on Raspberry Pi 3 B+ using Grafana, InfluxDB, Custom Python Coll
 10 Dec 23, 2022
10 Dec 23, 2022
Scraping web pages to get data
Scraping Data Get public data and save in database This is project use Python How to run a project 1 - Clone the repository 2 - Install beautifulsoup4
 2 Nov 1, 2021
2 Nov 1, 2021
1st ranked 'driver careless behavior detection' for AI Online Competition 2021, hosted by MSIT Korea.
2021AICompetition-03 본 repo 는 mAy-I Inc. 팀으로 참가한 2021 인공지능 온라인 경진대회 중 [이미지] 운전 사고 예방을 위한 운전자 부주의 행동 검출 모델] 태스크 수행을 위한 레포지토리입니다. mAy-I 는 과학기술정보통신부가 주최하
 9 Dec 1, 2022
9 Dec 1, 2022

Easily report Instagram pages and close the page
Program Features - 📌 Delete target post on Instagram. - 📌 Delete Media Target post on Instagram - 📌 Complete deletion of the target account on Inst
 11 Nov 25, 2022
11 Nov 25, 2022
Speed up Sphinx builds by selectively removing toctrees from some pages
Remove toctrees from Sphinx pages Improve your Sphinx build time by selectively removing TocTree objects from pages. This is useful if your documentat
 8 Jan 4, 2023
8 Jan 4, 2023
Token-gate Notion pages
This is a Next.js project bootstrapped with create-next-app. Getting Started First, run the development server: npm run dev # or yarn dev Open http://
 8 Oct 13, 2022
8 Oct 13, 2022

A stock information collector and parser for Taiwan and US market. Automatically send LINE message if the pre-defined rules are triggered.
agastock 開發動機 就在海運飆漲的2021年7月,差點跪在地上喜迎財富自由的當下,EPS超高好消息不斷的長榮竟然套在202元一去不回,有圖有真相(哭) 忽然體會到追高殺低不是辦法,魯蛇我得靠邏輯分析也能出頭天,經過三個月無數個不出門的周末,產出簡單的爬蟲和分析工具。 上過金融研訓院的量化交易
 12 Nov 16, 2022
12 Nov 16, 2022
Fully configurable automated python script to collect most visted pages based on google dork
Ranked pages collector Fully configurable automated python script to collect most visted pages based on google dork Usage This project is still under
 9 Sep 10, 2022
9 Sep 10, 2022
Google Search Engine Results Pages (SERP) in locally, no API key, no signup required
Local SERP Google Search Engine Results Pages (SERP) in locally, no API key, no signup required Make sure the chromedriver and required package are in
 4 Jun 29, 2021
4 Jun 29, 2021

mlscraper: Scrape data from HTML pages automatically with Machine Learning
🤖 Scrape data from HTML websites automatically with Machine Learning
 798 Dec 29, 2022
798 Dec 29, 2022
Unsafe Twig processing of static pages leading to RCE in Grav CMS 1.7.10
CVE-2021-29440 Unsafe Twig processing of static pages leading to RCE in Grav CMS 1.7.10 Grav is a file based Web-platform. Twig processing of static p
 6 Oct 10, 2022
6 Oct 10, 2022
PyPDF2 is a pure-python PDF library capable of splitting, merging together, cropping, and transforming the pages of PDF files.
PyPDF2 is a pure-python PDF library capable of splitting, merging together, cropping, and transforming the pages of PDF files. It can also add custom data, viewing options, and passwords to PDF files. It can retrieve text and metadata from PDFs as well as merge entire files together.
 5k Jan 4, 2023
5k Jan 4, 2023
🏆 A ranked list of awesome python libraries for web development. Updated weekly.
Best-of Web Development with Python 🏆 A ranked list of awesome python libraries for web development. Updated weekly. This curated list contains 540 a
 1.8k Dec 26, 2022
1.8k Dec 26, 2022

~1000 book pages + OpenCV + python = page regions identified as paragraphs, lines, images, captions, etc.
cosc428-structor I had an open-ended Computer Vision assignment to complete, and an out-of-copyright book that I wanted to turn into an ebook. Convent
 45 Dec 6, 2022
45 Dec 6, 2022
scantailor - Scan Tailor is an interactive post-processing tool for scanned pages.
Scan Tailor - scantailor.org This project is no longer maintained, and has not been maintained for a while. About Scan Tailor is an interactive post-p
 1.5k Dec 28, 2022
1.5k Dec 28, 2022
Some bits of javascript to transcribe scanned pages using PageXML
nashi (nasḫī) Some bits of javascript to transcribe scanned pages using PageXML. Both ltr and rtl languages are supported. Try it! But wait, there's m
 15 Nov 9, 2022
15 Nov 9, 2022
Generate a roam research like Network Graph view from your Notion pages.
Notion Graph View Export Notion pages to a Roam Research like graph view.
 214 Jan 7, 2023
214 Jan 7, 2023
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
 2.5k Feb 17, 2021
2.5k Feb 17, 2021
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
3k Jan 8, 2023
An MkDocs plugin to export content pages as PDF files
MkDocs PDF Export Plugin An MkDocs plugin to export content pages as PDF files The pdf-export plugin will export all markdown pages in your MkDocs rep
 266 Dec 13, 2022
266 Dec 13, 2022
🏆 A ranked list of awesome python libraries for web development. Updated weekly.
Best-of Web Development with Python 🏆 A ranked list of awesome python libraries for web development. Updated weekly. This curated list contains 540 a
1.8k Jan 3, 2023
Library to scrape and clean web pages to create massive datasets.
lazynlp A straightforward library that allows you to crawl, clean up, and deduplicate webpages to create massive monolingual datasets. Using this libr
 2.1k Jan 6, 2023
2.1k Jan 6, 2023
🏆 A ranked list of awesome machine learning Python libraries. Updated weekly.
Best-of Machine Learning with Python 🏆 A ranked list of awesome machine learning Python libraries. Updated weekly. This curated list contains 840 awe
12.2k Jan 4, 2023
🏆 A ranked list of awesome Python open-source libraries and tools. Updated weekly.
Best-of Python 🏆 A ranked list of awesome Python open-source libraries & tools. Updated weekly. This curated list contains 230 awesome open-source pr
2.7k Jan 3, 2023
🏆 A ranked list of awesome python libraries for web development. Updated weekly.
Best-of Web Development with Python 🏆 A ranked list of awesome python libraries for web development. Updated weekly. This curated list contains 540 a
1.8k Jan 4, 2023
🏆 A ranked list of awesome python developer tools and libraries. Updated weekly.
Best-of Python Developer Tools 🏆 A ranked list of awesome python developer tools and libraries. Updated weekly. This curated list contains 250 awesom
646 Jan 7, 2023

Discover hidden deepweb pages
DeepWeb Scapper Att: Demo version An simple script to scrappe deepweb to find pages. Will return if any of those exists and will save on a file. You s
 77 Oct 2, 2022
77 Oct 2, 2022
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
3k Jan 3, 2023