166 Repositories
Python scientific-documents Libraries
Docbarcodes extracts 1D and 2D barcodes from scanned PDF documents or images. It can be used to automate extraction and processing of all kind of documents.
Intro Barcodes are being used in many documents or forms to enable machine reading capabilities and reduce manual processing effort. Simple 1D barcode
 3 Jun 18, 2022
3 Jun 18, 2022
Scientific Computation Methods in C and Python (Open for Hacktoberfest 2021)
Sci - cpy README is a stub. Do expand it. Objective This repository is meant to be a ready reference for scientific computation methods. Do ⭐ it if yo
 7 Oct 12, 2022
7 Oct 12, 2022
SCICO is a Python package for solving the inverse problems that arise in scientific imaging applications.
Scientific Computational Imaging COde (SCICO) SCICO is a Python package for solving the inverse problems that arise in scientific imaging applications
 37 Dec 21, 2022
37 Dec 21, 2022

x-ray is a Python library for finding bad redactions in PDF documents.
A tool to detect whether a PDF has a bad redaction
 73 Dec 19, 2022
73 Dec 19, 2022

Download YOUR files, documents from vk.
vk-documents-downloader Кароч эта симпл херня качает все ВАШИ документы с вк. Или я еблан, но в гх и тмб гугле я подобного не нашел. py main.py Login:
 4 Jun 10, 2022
4 Jun 10, 2022

Scitizen - Help scientific research for the benefit of mankind and humanity 🔬
Scitizen - Help scientific research for the benefit of mankind and humanity 🔬 Scitizen has been built from the ground up to give everyone the possibi
 21 Mar 8, 2022
21 Mar 8, 2022
WeasyPrint is a smart solution helping web developers to create PDF documents.
WeasyPrint is a smart solution helping web developers to create PDF documents. It turns simple HTML pages into gorgeous statistical reports, invoices, tickets…
 5.4k Jan 8, 2023
5.4k Jan 8, 2023
Generate YARA rules for OOXML documents using ZIP local header metadata.
apooxml Generate YARA rules for OOXML documents using ZIP local header metadata. To learn more about this tool and the methodology behind it, check ou
 34 Jan 26, 2022
34 Jan 26, 2022

Official Pytorch implementation of ICLR 2018 paper Deep Learning for Physical Processes: Integrating Prior Scientific Knowledge.
Deep Learning for Physical Processes: Integrating Prior Scientific Knowledge: Official Pytorch implementation of ICLR 2018 paper Deep Learning for Phy
 47 Nov 6, 2022
47 Nov 6, 2022

2nd solution of ICDAR 2021 Competition on Scientific Literature Parsing, Task B.
TableMASTER-mmocr Contents About The Project Method Description Dependency Getting Started Prerequisites Installation Usage Data preprocess Train Infe
 298 Dec 21, 2022
298 Dec 21, 2022
IDRLnet, a Python toolbox for modeling and solving problems through Physics-Informed Neural Network (PINN) systematically.
IDRLnet IDRLnet is a machine learning library on top of PyTorch. Use IDRLnet if you need a machine learning library that solves both forward and inver
 105 Dec 17, 2022
105 Dec 17, 2022
Command line program to download documents from web portals.
command line document download made easy Highlights list available documents in json format or download them filter documents using string matching re
 16 Dec 26, 2022
16 Dec 26, 2022
DRIFT is a tool for Diachronic Analysis of Scientific Literature.
About DRIFT is a tool for Diachronic Analysis of Scientific Literature. The application offers user-friendly and customizable utilities for two modes:
 108 Dec 12, 2022
108 Dec 12, 2022
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
 152 Oct 29, 2022
152 Oct 29, 2022
Extracting Summary Knowledge Graphs from Long Documents
GraphSum This repo contains the data and code for the G2G model in the paper: Extracting Summary Knowledge Graphs from Long Documents. The other basel
 10 Oct 21, 2022
10 Oct 21, 2022
Scientific color maps and standardization tools
Scicomap is a package that provides scientific color maps and tools to standardize your favourite color maps if you don't like the built-in ones. Scicomap currently provides sequential, bi-sequential, diverging, circular, qualitative and miscellaneous color maps. You can easily draw examples, compare the rendering, see how colorblind people will perceive the color maps. I will illustrate the scicomap capabilities below.
 14 Nov 30, 2022
14 Nov 30, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022

PyMuPDF is a Python binding with support for MuPDF
PyMuPDF is a Python binding with support for MuPDF (current version 1.18.*), a lightweight PDF, XPS, and E-book viewer, renderer, and toolkit, which is maintained and developed by Artifex Software, Inc.
 1.9k Jan 3, 2023
1.9k Jan 3, 2023
A scientific and useful toolbox, which contains practical and effective long-tail related tricks with extensive experimental results
Bag of tricks for long-tailed visual recognition with deep convolutional neural networks This repository is the official PyTorch implementation of AAA
 181 Dec 28, 2022
181 Dec 28, 2022
This is a script to forward forward large number of documents to another telegram channel.
ChannelForward 😇 This is a Script to Forward Large Number of Documents to Another Telegram Channel. If You Try to Forward Very Large Number of Files
 10 Jun 8, 2021
10 Jun 8, 2021
Telegram Bot to store Posts and Documents and it can Access by Special Links.
File-sharing-Bot Telegram Bot to store Posts and Documents and it can Access by Special Links. I Guess This Will Be Usefull For Many People..... 😇 .
 1.2k Jan 8, 2023
1.2k Jan 8, 2023
Python with the scientific stack, compiled to WebAssembly.
Pyodide may be used in any context where you want to run Python inside a web browser.
 9.5k Jan 9, 2023
9.5k Jan 9, 2023

SkipGNN: Predicting Molecular Interactions with Skip-Graph Networks (Scientific Reports)
SkipGNN: Predicting Molecular Interactions with Skip-Graph Networks Molecular interaction networks are powerful resources for the discovery. While dee
 49 Oct 15, 2022
49 Oct 15, 2022
xitorch: differentiable scientific computing library
xitorch is a PyTorch-based library of differentiable functions and functionals that can be widely used in scientific computing applications as well as deep learning.
 24 Apr 15, 2021
24 Apr 15, 2021
monolish: MONOlithic Liner equation Solvers for Highly-parallel architecture
monolish is a linear equation solver library that monolithically fuses variable data type, matrix structures, matrix data format, vendor specific data transfer APIs, and vendor specific numerical algebra libraries.
 179 Dec 21, 2022
179 Dec 21, 2022
ArrayFire: a general purpose GPU library.
ArrayFire is a general-purpose library that simplifies the process of developing software that targets parallel and massively-parallel architectures i
 4k Dec 29, 2022
4k Dec 29, 2022
CUDA integration for Python, plus shiny features
PyCUDA lets you access Nvidia's CUDA parallel computation API from Python. Several wrappers of the CUDA API already exist-so what's so special about P
 1.4k Jan 2, 2023
1.4k Jan 2, 2023
ScanTailor Advanced is the version that merges the features of the ScanTailor Featured and ScanTailor Enhanced versions, brings new ones and fixes.
ScanTailor Advanced The ScanTailor version that merges the features of the ScanTailor Featured and ScanTailor Enhanced versions, brings new ones and f
 952 Dec 31, 2022
952 Dec 31, 2022
A machine learning software for extracting information from scholarly documents
GROBID GROBID documentation Visit the GROBID documentation for more detailed information. Summary GROBID (or Grobid, but not GroBid nor GroBiD) means
 1.9k Jan 8, 2023
1.9k Jan 8, 2023
A tool for extracting text from scanned documents (via OCR), with user-defined post-processing.
The project is based on older versions of tesseract and other tools, and is now superseded by another project which allows for more granular control o
 32 Jul 24, 2022
32 Jul 24, 2022
Deskew is a command line tool for deskewing scanned text documents. It uses Hough transform to detect "text lines" in the image. As an output, you get an image rotated so that the lines are horizontal.
Deskew by Marek Mauder https://galfar.vevb.net/deskew https://github.com/galfar/deskew v1.30 2019-06-07 Overview Deskew is a command line tool for des
 127 Dec 3, 2022
127 Dec 3, 2022
An application of high resolution GANs to dewarp images of perturbed documents
Docuwarp This project is focused on dewarping document images through the usage of pix2pixHD, a GAN that is useful for general image to image translat
 97 Dec 25, 2022
97 Dec 25, 2022
A flexible package manager that supports multiple versions, configurations, platforms, and compilers.
Spack Spack is a multi-platform package manager that builds and installs multiple versions and configurations of software. It works on Linux, macOS, a
 3.1k Jan 9, 2023
3.1k Jan 9, 2023

Render reMarkable documents to PDF
rmrl: reMarkable Rendering Library rmrl is a Python library for rendering reMarkable documents to PDF files. It takes the original PDF document and th
 95 Dec 25, 2022
95 Dec 25, 2022

Sequential model-based optimization with a `scipy.optimize` interface
Scikit-Optimize Scikit-Optimize, or skopt, is a simple and efficient library to minimize (very) expensive and noisy black-box functions. It implements
 2.5k Jan 4, 2023
2.5k Jan 4, 2023
![[HELP REQUESTED] Generalized Additive Models in Python](https://github.com/dswah/pyGAM/raw/master/imgs/pygam_tensor.png)
[HELP REQUESTED] Generalized Additive Models in Python
pyGAM Generalized Additive Models in Python. Documentation Official pyGAM Documentation: Read the Docs Building interpretable models with Generalized
 747 Jan 5, 2023
747 Jan 5, 2023
Veusz scientific plotting application
Veusz 3.3.1 Veusz is a scientific plotting package. It is designed to produce publication-ready PDF or SVG output. Graphs are built-up by combining pl
 613 Dec 16, 2022
613 Dec 16, 2022
A flexible package manager that supports multiple versions, configurations, platforms, and compilers.
Spack Spack is a multi-platform package manager that builds and installs multiple versions and configurations of software. It works on Linux, macOS, a
3.1k Dec 31, 2022
ReproZip is a tool that simplifies the process of creating reproducible experiments from command-line executions, a frequently-used common denominator in computational science.
ReproZip ReproZip is a tool aimed at simplifying the process of creating reproducible experiments from command-line executions, a frequently-used comm
 267 Jan 1, 2023
267 Jan 1, 2023
3D visualization of scientific data in Python
Mayavi: 3D visualization of scientific data in Python Mayavi docs: http://docs.enthought.com/mayavi/mayavi/ TVTK docs: http://docs.enthought.com/mayav
 1.1k Jan 6, 2023
1.1k Jan 6, 2023
An interactive explorer for single-cell transcriptomics data
an interactive explorer for single-cell transcriptomics data cellxgene (pronounced "cell-by-gene") is an interactive data explorer for single-cell tra
 424 Dec 15, 2022
424 Dec 15, 2022
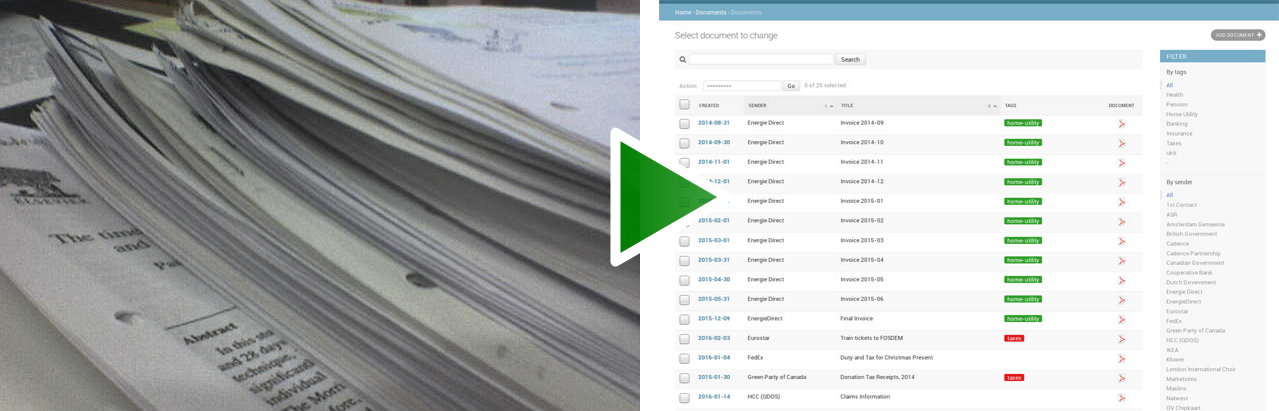
Scan, index, and archive all of your paper documents
[ en | de | el ] Important news about the future of this project It's been more than 5 years since I started this project on a whim as an effort to tr
 7.8k Jan 6, 2023
7.8k Jan 6, 2023
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
 831 Feb 17, 2021
831 Feb 17, 2021

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
 1.4k Feb 17, 2021
1.4k Feb 17, 2021
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
 2.5k Feb 17, 2021
2.5k Feb 17, 2021

3D plotting and mesh analysis through a streamlined interface for the Visualization Toolkit (VTK)
PyVista Deployment Build Status Metrics Citation License Community 3D plotting and mesh analysis through a streamlined interface for the Visualization
 692 Feb 18, 2021
692 Feb 18, 2021
Fast data visualization and GUI tools for scientific / engineering applications
PyQtGraph A pure-Python graphics library for PyQt5/PyQt6/PySide2/PySide6 Copyright 2020 Luke Campagnola, University of North Carolina at Chapel Hill h
 2.3k Feb 17, 2021
2.3k Feb 17, 2021
A fast MDCT implementation using SciPy and FFTs
MDCT A fast MDCT implementation using SciPy and FFTs Installation As usual pip install mdct Dependencies NumPy SciPy STFT Usage import mdct spectrum
 43 Sep 2, 2022
43 Sep 2, 2022
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
1.3k Jan 3, 2023

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
1.9k Jan 6, 2023
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
3k Jan 8, 2023
3D plotting and mesh analysis through a streamlined interface for the Visualization Toolkit (VTK)
PyVista Deployment Build Status Metrics Citation License Community 3D plotting and mesh analysis through a streamlined interface for the Visualization
1.6k Jan 8, 2023
Fast data visualization and GUI tools for scientific / engineering applications
PyQtGraph A pure-Python graphics library for PyQt5/PyQt6/PySide2/PySide6 Copyright 2020 Luke Campagnola, University of North Carolina at Chapel Hill h
2.3k Feb 13, 2021
Parsel lets you extract data from XML/HTML documents using XPath or CSS selectors
Parsel Parsel is a BSD-licensed Python library to extract and remove data from HTML and XML using XPath and CSS selectors, optionally combined with re
 859 Dec 29, 2022
859 Dec 29, 2022
Provides syntax for Python-Markdown which allows for the inclusion of the contents of other Markdown documents.
Markdown-Include This is an extension to Python-Markdown which provides an "include" function, similar to that found in LaTeX (and also the C pre-proc
 85 Dec 30, 2022
85 Dec 30, 2022

Spyder - The Scientific Python Development Environment
Spyder is a powerful scientific environment written in Python, for Python, and designed by and for scientists, engineers and data analysts. It offers a unique combination of the advanced editing, analysis, debugging, and profiling functionality of a comprehensive development tool with the data exploration, interactive execution, deep inspection, and beautiful visualization capabilities of a scientific package.
 7.3k Jan 8, 2023
7.3k Jan 8, 2023
On Generating Extended Summaries of Long Documents
ExtendedSumm This repository contains the implementation details and datasets used in On Generating Extended Summaries of Long Documents paper at the
 76 Sep 5, 2022
76 Sep 5, 2022
texlive expressions for documents
tex2nix Generate Texlive environment containing all dependencies for your document rather than downloading gigabytes of texlive packages. Installation
 70 Dec 26, 2022
70 Dec 26, 2022
Search for documents in a domain through Google. The objective is to extract metadata
MetaFinder - Metadata search through Google _____ __ ___________ .__ .___ / \
 85 Dec 16, 2022
85 Dec 16, 2022
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
3k Jan 3, 2023
Create Open XML PowerPoint documents in Python
python-pptx is a Python library for creating and updating PowerPoint (.pptx) files. A typical use would be generating a customized PowerPoint presenta
 1.7k Jan 5, 2023
1.7k Jan 5, 2023
Fast data visualization and GUI tools for scientific / engineering applications
PyQtGraph A pure-Python graphics library for PyQt5/PyQt6/PySide2/PySide6 Copyright 2020 Luke Campagnola, University of North Carolina at Chapel Hill h
3.1k Jan 8, 2023
Crab is a flexible, fast recommender engine for Python that integrates classic information filtering recommendation algorithms in the world of scientific Python packages (numpy, scipy, matplotlib).
Crab - A Recommendation Engine library for Python Crab is a flexible, fast recommender engine for Python that integrates classic information filtering r
 1.2k Dec 21, 2022
1.2k Dec 21, 2022
Standards-compliant library for parsing and serializing HTML documents and fragments in Python
html5lib html5lib is a pure-python library for parsing HTML. It is designed to conform to the WHATWG HTML specification, as is implemented by all majo
 1k Dec 27, 2022
1k Dec 27, 2022
pyglet is a cross-platform windowing and multimedia library for Python, for developing games and other visually rich applications.
pyglet pyglet is a cross-platform windowing and multimedia library for Python, intended for developing games and other visually rich applications. It
 1.3k Jan 1, 2023
1.3k Jan 1, 2023
Official repository for Spyder - The Scientific Python Development Environment
Copyright © 2009–2021 Spyder Project Contributors Some source files and icons may be under other authorship/licenses; see NOTICE.txt. Project status B
7.3k Dec 31, 2022