1179 Repositories
Python scripting-language Libraries

Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition The official code of ABINet (CVPR 2021, Oral).
 334 Dec 31, 2022
334 Dec 31, 2022

UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus
UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus General info This is
 71 Oct 25, 2022
71 Oct 25, 2022
Using pretrained language models for biomedical knowledge graph completion.
LMs for biomedical KG completion This repository contains code to run the experiments described in: Scientific Language Models for Biomedical Knowledg
 41 Nov 30, 2022
41 Nov 30, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022

This repository contains all the source code that is needed for the project : An Efficient Pipeline For Bloom’s Taxonomy Using Natural Language Processing and Deep Learning
Pipeline For NLP with Bloom's Taxonomy Using Improved Question Classification and Question Generation using Deep Learning This repository contains all
 9 Jul 17, 2021
9 Jul 17, 2021
NL-Augmenter 🦎 → 🐍 A Collaborative Repository of Natural Language Transformations
NL-Augmenter 🦎 → 🐍 The NL-Augmenter is a collaborative effort intended to add transformations of datasets dealing with natural language. Transformat
 684 Jan 9, 2023
684 Jan 9, 2023

Code for "LoRA: Low-Rank Adaptation of Large Language Models"
LoRA: Low-Rank Adaptation of Large Language Models This repo contains the implementation of LoRA in GPT-2 and steps to replicate the results in our re
 394 Jan 8, 2023
394 Jan 8, 2023
A Regex based linter tool that works for any language and works exclusively with custom linting rules.
renag Documentation Available Here Short for Regex (re) Nag (like "one who complains"). Now also PEGs (Parsing Expression Grammars) compatible with py
 12 Oct 20, 2022
12 Oct 20, 2022

A task-agnostic vision-language architecture as a step towards General Purpose Vision
Towards General Purpose Vision Systems By Tanmay Gupta, Amita Kamath, Aniruddha Kembhavi, and Derek Hoiem Overview Welcome to the official code base f
 79 Dec 23, 2022
79 Dec 23, 2022
The official implementation for ACL 2021 "Challenges in Information Seeking QA: Unanswerable Questions and Paragraph Retrieval".
Code for "Challenges in Information Seeking QA: Unanswerable Questions and Paragraph Retrieval" (ACL 2021, Long) This is the repository for baseline m
 25 Oct 30, 2022
25 Oct 30, 2022
✨ Udemy Coupon Finder For Discord. Supports Turkish & English Language.
Udemy Course Finder Bot | Udemy Kupon Bulucu Botu This bot finds new udemy coupons and sends to the channel. Before Setup You must have python = 3.6
 4 May 4, 2022
4 May 4, 2022
2021海华AI挑战赛·中文阅读理解·技术组·第三名
文字是人类用以记录和表达的最基本工具,也是信息传播的重要媒介。透过文字与符号,我们可以追寻人类文明的起源,可以传播知识与经验,读懂文字是认识与了解的第一步。对于人工智能而言,它的核心问题之一就是认知,而认知的核心则是语义理解。
 21 Dec 26, 2022
21 Dec 26, 2022
Code for our paper "Transfer Learning for Sequence Generation: from Single-source to Multi-source" in ACL 2021.
TRICE: a task-agnostic transferring framework for multi-source sequence generation This is the source code of our work Transfer Learning for Sequence
 9 Jun 27, 2022
9 Jun 27, 2022

A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/casual, active/passive, and many more. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Styleformer A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/cas
 431 Dec 19, 2022
431 Dec 19, 2022
Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning".
ERICA Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive L
 75 Nov 2, 2022
75 Nov 2, 2022

PyTorch implementation of Pay Attention to MLPs
gMLP PyTorch implementation of Pay Attention to MLPs. Quickstart Clone this repository. git clone https://github.com/jaketae/g-mlp.git Navigate to th
 34 Dec 13, 2022
34 Dec 13, 2022
![[ICML 2021, Long Talk] Delving into Deep Imbalanced Regression](https://github.com/YyzHarry/imbalanced-regression/raw/main/teaser/overview.gif)
[ICML 2021, Long Talk] Delving into Deep Imbalanced Regression
Delving into Deep Imbalanced Regression This repository contains the implementation code for paper: Delving into Deep Imbalanced Regression Yuzhe Yang
 568 Dec 30, 2022
568 Dec 30, 2022
Ecommerce product title recognition package
revizor This package solves task of splitting product title string into components, like type, brand, model and article (or SKU or product code or you
 16 Mar 3, 2022
16 Mar 3, 2022

An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C.
vizh An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C. Overview Her
 228 Dec 17, 2022
228 Dec 17, 2022
A simple programming language for manipulating images.
f-stop A simple programming language for manipulating images. Examples OPEN "image.png" AS image RESIZE image (300, 300) SAVE image "out.jpg" CLOSE im
 6 Oct 27, 2022
6 Oct 27, 2022
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022
Enjoyable scripting experience with Python
Enjoyable scripting experience with Python
 8 Jun 8, 2022
8 Jun 8, 2022
sawa (ꦱꦮ) is an open source programming language, an interpreter to be precise, where you can write python code using javanese character.
ꦱꦮ sawa (ꦱꦮ) is an open source programming language, an interpreter to be precise, where you can write python code using javanese character. sawa iku
 307 Jan 7, 2023
307 Jan 7, 2023

Kestrel Threat Hunting Language
Kestrel Threat Hunting Language What is Kestrel? Why we need it? How to hunt with XDR support? What is the science behind it? You can find all the ans
 201 Dec 16, 2022
201 Dec 16, 2022

A framework for detecting, highlighting and correcting grammatical errors on natural language text.
Gramformer Human and machine generated text often suffer from grammatical and/or typographical errors. It can be spelling, punctuation, grammatical or
1.3k Jan 8, 2023
Protein Language Model
ProteinLM We pretrain protein language model based on Megatron-LM framework, and then evaluate the pretrained model results on TAPE (Tasks Assessing P
 77 Dec 27, 2022
77 Dec 27, 2022
PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World [ACL 2021]
piglet PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World [ACL 2021] This repo contains code and data for PIGLeT. If you like
 51 Oct 8, 2022
51 Oct 8, 2022
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions (CVPR2021)
NExT-QA We reproduce some SOTA VideoQA methods to provide benchmark results for our NExT-QA dataset accepted to CVPR2021 (with 1 'Strong Accept' and 2
 50 Nov 24, 2022
50 Nov 24, 2022

This project provides an unsupervised framework for mining and tagging quality phrases on text corpora with pretrained language models (KDD'21).
UCPhrase: Unsupervised Context-aware Quality Phrase Tagging To appear on KDD'21...[pdf] This project provides an unsupervised framework for mining and
 146 Dec 22, 2022
146 Dec 22, 2022
Rick Astley Language is a rick roll oriented, dynamic, strong, esoteric programming language.
Rick Roll Language / Rick Astley Language A rick roll oriented, dynamic, strong, esoteric programming language. Prolegomenon The reasons that I made t
 658 Jan 9, 2023
658 Jan 9, 2023
A lightweight (serverless) native python parallel processing framework based on simple decorators and call graphs.
A lightweight (serverless) native python parallel processing framework based on simple decorators and call graphs, supporting both control flow and dataflow execution paradigms as well as de-centralized CPU & GPU scheduling.
 102 Jan 6, 2023
102 Jan 6, 2023
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset.
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset. Through its Python API, the pretrained model can be fine-tuned on any protein-related task in a matter of minutes. Based on our experiments with a wide range of benchmarks, ProteinBERT usually achieves state-of-the-art performance. ProteinBERT is built on TenforFlow/Keras.
 241 Jan 4, 2023
241 Jan 4, 2023

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 248 Dec 4, 2022
248 Dec 4, 2022
True Few-Shot Learning with Language Models
This codebase supports using language models (LMs) for true few-shot learning: learning to perform a task using a limited number of examples from a single task distribution.
 124 Jan 4, 2023
124 Jan 4, 2023
VMD Audio/Text control with natural language
This repository is a proof of principle for performing Molecular Dynamics analysis, in this case with the program VMD, via natural language commands.
 13 Jun 9, 2022
13 Jun 9, 2022
Code for the paper "Adapting Monolingual Models: Data can be Scarce when Language Similarity is High"
Wietse de Vries • Martijn Bartelds • Malvina Nissim • Martijn Wieling Adapting Monolingual Models: Data can be Scarce when Language Similarity is High
 5 Aug 2, 2021
5 Aug 2, 2021
![[CVPR'21 Oral] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning](https://github.com/researchmm/soho/raw/master/resources/soho.png)
[CVPR'21 Oral] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning [CVPR'21, Oral] By Zhicheng Huang*, Zhaoyang Zeng*, Yupan H
 196 Dec 13, 2022
196 Dec 13, 2022
A GPT, made only of MLPs, in Jax
MLP GPT - Jax (wip) A GPT, made only of MLPs, in Jax. The specific MLP to be used are gMLPs with the Spatial Gating Units. Working Pytorch implementat
 53 Sep 27, 2022
53 Sep 27, 2022

This project demonstrates the use of neural networks and computer vision to create a classifier that interprets the Brazilian Sign Language.
LIBRAS-Image-Classifier This project demonstrates the use of neural networks and computer vision to create a classifier that interprets the Brazilian
 26 Oct 14, 2022
26 Oct 14, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 44 Jan 6, 2023
44 Jan 6, 2023
Train 🤗transformers with DeepSpeed: ZeRO-2, ZeRO-3
Fork from https://github.com/huggingface/transformers/tree/86d5fb0b360e68de46d40265e7c707fe68c8015b/examples/pytorch/language-modeling at 2021.05.17.
 12 Oct 26, 2022
12 Oct 26, 2022
Application that instantly translates sign-language to letters.
Sign Language Translator Project Description The main purpose of project is translating sign-language to letters. In accordance with this purpose we d
 3 Sep 29, 2022
3 Sep 29, 2022
Language models are open knowledge graphs ( non official implementation )
language-models-are-knowledge-graphs-pytorch Language models are open knowledge graphs ( work in progress ) A non official reimplementation of Languag
 132 Dec 18, 2022
132 Dec 18, 2022
Python for .NET is a package that gives Python programmers nearly seamless integration with the .NET Common Language Runtime (CLR) and provides a powerful application scripting tool for .NET developers.
pythonnet - Python.NET Python.NET is a package that gives Python programmers nearly seamless integration with the .NET Common Language Runtime (CLR) a
 3.5k Jan 6, 2023
3.5k Jan 6, 2023
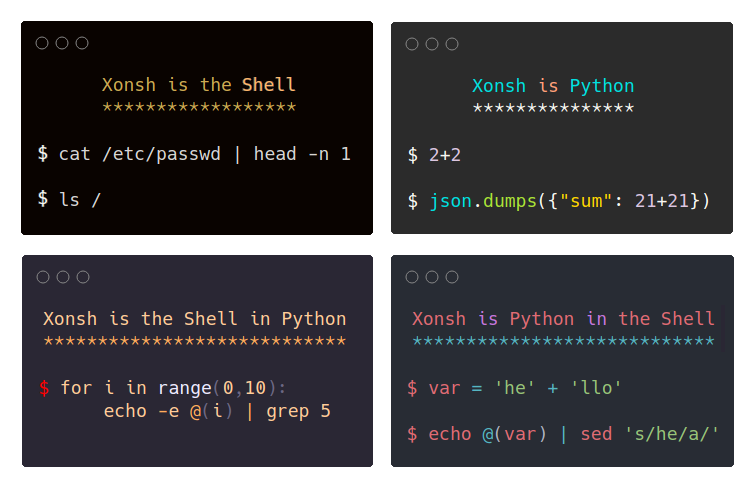
xonsh is a Python-powered, cross-platform, Unix-gazing shell language and command prompt.
xonsh xonsh is a Python-powered, cross-platform, Unix-gazing shell language and command prompt. The language is a superset of Python 3.6+ with additio
 6.7k Jan 8, 2023
6.7k Jan 8, 2023

Unofficial implementation of Google's FNet: Mixing Tokens with Fourier Transforms
FNet: Mixing Tokens with Fourier Transforms Pytorch implementation of Fnet : Mixing Tokens with Fourier Transforms. Citation: @misc{leethorp2021fnet,
 218 Jan 5, 2023
218 Jan 5, 2023
![[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.](https://github.com/cambridgeltl/sapbert/raw/main/sapbert_front_graphs_v6.png?raw=true)
[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.
SapBERT: Self-alignment pretraining for BERT This repo holds code for the SapBERT model presented in our NAACL 2021 paper: Self-Alignment Pretraining
 104 Dec 7, 2022
104 Dec 7, 2022
A framework for cleaning Chinese dialog data
A framework for cleaning Chinese dialog data
 136 Dec 20, 2022
136 Dec 20, 2022

FactSumm: Factual Consistency Scorer for Abstractive Summarization
FactSumm: Factual Consistency Scorer for Abstractive Summarization FactSumm is a toolkit that scores Factualy Consistency for Abstract Summarization W
 83 Jan 9, 2023
83 Jan 9, 2023

Code for the ICML 2021 paper: "ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision"
ViLT Code for the paper: "ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision" Install pip install -r requirements.txt pip
 922 Jan 1, 2023
922 Jan 1, 2023
Lightning fast and portable programming language!
Photon Documentation in English Lightning fast and portable programming language! What is Photon? Photon is a programming language aimed at filling th
 58 Dec 27, 2022
58 Dec 27, 2022

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022
Repository for XLM-T, a framework for evaluating multilingual language models on Twitter data
This is the XLM-T repository, which includes data, code and pre-trained multilingual language models for Twitter. XLM-T - A Multilingual Language Mode
 112 Dec 27, 2022
112 Dec 27, 2022
Code for the ICML 2021 paper: "ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision"
ViLT Code for the paper: "ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision" Install pip install -r requirements.txt pip
922 Jan 1, 2023
Integrating the Best of TF into PyTorch, for Machine Learning, Natural Language Processing, and Text Generation. This is part of the CASL project: http://casl-project.ai/
Texar-PyTorch is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar
 726 Dec 30, 2022
726 Dec 30, 2022
Google AI 2018 BERT pytorch implementation
BERT-pytorch Pytorch implementation of Google AI's 2018 BERT, with simple annotation BERT 2018 BERT: Pre-training of Deep Bidirectional Transformers f
 5.3k Jan 7, 2023
5.3k Jan 7, 2023
A modular framework for vision & language multimodal research from Facebook AI Research (FAIR)
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains reference implementations of state-of-t
 5.1k Dec 26, 2022
5.1k Dec 26, 2022
Language-Agnostic SEntence Representations
LASER Language-Agnostic SEntence Representations LASER is a library to calculate and use multilingual sentence embeddings. NEWS 2019/11/08 CCMatrix is
3.2k Jan 4, 2023

Unsupervised Language Modeling at scale for robust sentiment classification
** DEPRECATED ** This repo has been deprecated. Please visit Megatron-LM for our up to date Large-scale unsupervised pretraining and finetuning code.
 1k Nov 17, 2022
1k Nov 17, 2022
[EMNLP 2020] Keep CALM and Explore: Language Models for Action Generation in Text-based Games
Contextual Action Language Model (CALM) and the ClubFloyd Dataset Code and data for paper Keep CALM and Explore: Language Models for Action Generation
 43 Dec 16, 2022
43 Dec 16, 2022
Codes for our paper "SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge" (EMNLP 2020)
SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge Introduction SentiLARE is a sentiment-aware pre-trained language
 74 Dec 30, 2022
74 Dec 30, 2022
Meta Language-Specific Layers in Multilingual Language Models
Meta Language-Specific Layers in Multilingual Language Models This repo contains the source codes for our paper On Negative Interference in Multilingu
 20 Feb 13, 2022
20 Feb 13, 2022

Django queries
Djaq Djaq - pronounced “Jack” - provides an instant remote API to your Django models data with a powerful query language. No server-side code beyond t
 53 Dec 12, 2022
53 Dec 12, 2022
One Stop Anomaly Shop: Anomaly detection using two-phase approach: (a) pre-labeling using statistics, Natural Language Processing and static rules; (b) anomaly scoring using supervised and unsupervised machine learning.
One Stop Anomaly Shop (OSAS) Quick start guide Step 1: Get/build the docker image Option 1: Use precompiled image (might not reflect latest changes):
 148 Dec 26, 2022
148 Dec 26, 2022

TorchFlare is a simple, beginner-friendly, and easy-to-use PyTorch Framework train your models effortlessly.
TorchFlare TorchFlare is a simple, beginner-friendly and an easy-to-use PyTorch Framework train your models without much effort. It provides an almost
 85 Dec 26, 2022
85 Dec 26, 2022
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
 15k Jan 2, 2023
15k Jan 2, 2023

🏆 The 1st Place Submission to AICity Challenge 2021 Natural Language-Based Vehicle Retrieval Track (Alibaba-UTS submission)
🏆 The 1st Place Submission to AICity Challenge 2021 Natural Language-Based Vehicle Retrieval Track (Alibaba-UTS submission)
 26 Apr 29, 2021
26 Apr 29, 2021
🏆 The 1st Place Submission to AICity Challenge 2021 Natural Language-Based Vehicle Retrieval Track (Alibaba-UTS submission)
AI City 2021: Connecting Language and Vision for Natural Language-Based Vehicle Retrieval 🏆 The 1st Place Submission to AICity Challenge 2021 Natural
82 Dec 29, 2022
Contrastive Language-Audio Pretraining
CLAP Contrastive Language-Audio Pretraining In due time this repo will be full of lovely things, I hope. Feel free to check out the Issues if you're i
 83 Dec 1, 2022
83 Dec 1, 2022
Code and data of the Fine-Grained R2R Dataset proposed in paper Sub-Instruction Aware Vision-and-Language Navigation
Fine-Grained R2R Code and data of the Fine-Grained R2R Dataset proposed in the EMNLP2020 paper Sub-Instruction Aware Vision-and-Language Navigation. C
 34 Nov 15, 2022
34 Nov 15, 2022
Code for the paper "Improving Vision-and-Language Navigation with Image-Text Pairs from the Web" (ECCV 2020)
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Devi Parikh
 44 Dec 14, 2022
44 Dec 14, 2022
Reimplementation of the paper `Human Attention Maps for Text Classification: Do Humans and Neural Networks Focus on the Same Words? (ACL2020)`
Human Attention for Text Classification Re-implementation of the paper Human Attention Maps for Text Classification: Do Humans and Neural Networks Foc
 15 Dec 13, 2021
15 Dec 13, 2021

This repo contains the official code of our work SAM-SLR which won the CVPR 2021 Challenge on Large Scale Signer Independent Isolated Sign Language Recognition.
Skeleton Aware Multi-modal Sign Language Recognition By Songyao Jiang, Bin Sun, Lichen Wang, Yue Bai, Kunpeng Li and Yun Fu. Smile Lab @ Northeastern
 128 Dec 8, 2022
128 Dec 8, 2022
Code for "Learning the Best Pooling Strategy for Visual Semantic Embedding", CVPR 2021
Learning the Best Pooling Strategy for Visual Semantic Embedding Official PyTorch implementation of the paper Learning the Best Pooling Strategy for V
 106 Jan 6, 2023
106 Jan 6, 2023
OCTIS: Comparing Topic Models is Simple! A python package to optimize and evaluate topic models (accepted at EACL2021 demo track)
OCTIS : Optimizing and Comparing Topic Models is Simple! OCTIS (Optimizing and Comparing Topic models Is Simple) aims at training, analyzing and compa
 478 Jan 1, 2023
478 Jan 1, 2023
skweak: A software toolkit for weak supervision applied to NLP tasks
Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels without pre-existing datasets. The only available option is often to collect and annotate texts by hand, which is expensive and time-consuming.
 850 Dec 28, 2022
850 Dec 28, 2022
This repository contains the code for "Generating Datasets with Pretrained Language Models".
Datasets from Instructions (DINO 🦕 ) This repository contains the code for Generating Datasets with Pretrained Language Models. The paper introduces
 154 Jan 1, 2023
154 Jan 1, 2023

An advanced multi-threaded, multi-client python reverse shell for hacking linux systems. There's still more work to do so feel free to help out with the development. Disclaimer: This reverse shell should only be used in the lawful, remote administration of authorized systems. Accessing a computer network without authorization or permission is illegal.
PwnLnX An advanced multi-threaded, multi-client python reverse shell for hacking linux systems. There's still more work to do so feel free to help out
 212 Dec 24, 2022
212 Dec 24, 2022
Source code for AAAI20 "Generating Persona Consistent Dialogues by Exploiting Natural Language Inference".
Generating Persona Consistent Dialogues by Exploiting Natural Language Inference Source code for RCDG model in AAAI20 Generating Persona Consistent Di
 16 Oct 8, 2022
16 Oct 8, 2022

FedNLP: A Benchmarking Framework for Federated Learning in Natural Language Processing
FedNLP is a research-oriented benchmarking framework for advancing federated learning (FL) in natural language processing (NLP). It uses FedML repository as the git submodule. In other words, FedNLP only focuses on adavanced models and dataset, while FedML supports various federated optimizers (e.g., FedAvg) and platforms (Distributed Computing, IoT/Mobile, Standalone).
 216 Nov 27, 2022
216 Nov 27, 2022

GrammarTagger — A Neural Multilingual Grammar Profiler for Language Learning
GrammarTagger — A Neural Multilingual Grammar Profiler for Language Learning GrammarTagger is an open-source toolkit for grammatical profiling for lan
 27 Jan 5, 2023
27 Jan 5, 2023
GLM (General Language Model)
GLM GLM is a General Language Model pretrained with an autoregressive blank-filling objective and can be finetuned on various natural language underst
421 Jan 4, 2023
Awesome-NLP-Research (ANLP)
Awesome-NLP-Research (ANLP)
 72 Dec 19, 2022
72 Dec 19, 2022
Changing the Mind of Transformers for Topically-Controllable Language Generation
We will first introduce the how to run the IPython notebook demo by downloading our pretrained models. Then, we will introduce how to run our training and evaluation code.
 20 Dec 6, 2022
20 Dec 6, 2022

QA-GNN: Question Answering using Language Models and Knowledge Graphs
QA-GNN: Question Answering using Language Models and Knowledge Graphs This repo provides the source code & data of our paper: QA-GNN: Reasoning with L
 434 Jan 4, 2023
434 Jan 4, 2023

I-BERT: Integer-only BERT Quantization
I-BERT: Integer-only BERT Quantization HuggingFace Implementation I-BERT is also available in the master branch of HuggingFace! Visit the following li
 139 Dec 27, 2022
139 Dec 27, 2022
PClean: A Domain-Specific Probabilistic Programming Language for Bayesian Data Cleaning
PClean: A Domain-Specific Probabilistic Programming Language for Bayesian Data Cleaning Warning: This is a rapidly evolving research prototype.
 190 Dec 27, 2022
190 Dec 27, 2022
A fast and easy implementation of Transformer with PyTorch.
FasySeq FasySeq is a shorthand as a Fast and easy sequential modeling toolkit. It aims to provide a seq2seq model to researchers and developers, which
 7 Jul 18, 2022
7 Jul 18, 2022

Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
 4.7k Jan 1, 2023
4.7k Jan 1, 2023
CLASP - Contrastive Language-Aminoacid Sequence Pretraining
CLASP - Contrastive Language-Aminoacid Sequence Pretraining Repository for creating models pretrained on language and aminoacid sequences similar to C
 133 Dec 29, 2022
133 Dec 29, 2022
A collection of scripts to preprocess ASR datasets and finetune language-specific Wav2Vec2 XLSR models
wav2vec-toolkit A collection of scripts to preprocess ASR datasets and finetune language-specific Wav2Vec2 XLSR models This repository accompanies the
 29 Oct 23, 2022
29 Oct 23, 2022

⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
 11.2k Jan 9, 2023
11.2k Jan 9, 2023
The source code for the Cutoff data augmentation approach proposed in this paper: "A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation".
Cutoff: A Simple Data Augmentation Approach for Natural Language This repository contains source code necessary to reproduce the results presented in
 49 Dec 22, 2022
49 Dec 22, 2022

Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT CheXbert is an accurate, automated dee
 51 Dec 8, 2022
51 Dec 8, 2022
Code, Data and Demo for Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting
InversePrompting Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting Code: The code is provided in the "chinese_ip"
101 Dec 16, 2022
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
 226 Dec 29, 2022
226 Dec 29, 2022
TextFlint is a multilingual robustness evaluation platform for natural language processing tasks,
TextFlint is a multilingual robustness evaluation platform for natural language processing tasks, which unifies general text transformation, task-specific transformation, adversarial attack, sub-population, and their combinations to provide a comprehensive robustness analysis.
 587 Dec 20, 2022
587 Dec 20, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
This project is part of Eleuther AI's quest to create a massive repository of high quality text data for training language models.
This project is part of Eleuther AI's quest to create a massive repository of high quality text data for training language models.
 42 Dec 13, 2022
42 Dec 13, 2022

A novel method to tune language models. Codes and datasets for paper ``GPT understands, too''.
P-tuning A novel method to tune language models. Codes and datasets for paper ``GPT understands, too''. How to use our code We have released the code
562 Dec 27, 2022