193 Repositories
Python sentence-embeddings Libraries
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
 111 Dec 18, 2022
111 Dec 18, 2022

Transformer Based Korean Sentence Spacing Corrector
TKOrrector Transformer Based Korean Sentence Spacing Corrector License Summary This solution is made available under Apache 2 license. See the LICENSE
 3 Apr 18, 2022
3 Apr 18, 2022
Code for ICML2019 Paper "Compositional Invariance Constraints for Graph Embeddings"
Dependencies NOTE: This code has been updated, if you were using this repo earlier and experienced issues that was due to an outaded codebase. Please
 43 Nov 25, 2022
43 Nov 25, 2022
Using contrastive learning and OpenAI's CLIP to find good embeddings for images with lossy transformations
Creating Robust Representations from Pre-Trained Image Encoders using Contrastive Learning Sriram Ravula, Georgios Smyrnis This is the code for our pr
 26 Dec 10, 2022
26 Dec 10, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022

Implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTorch
Neural Distance Embeddings for Biological Sequences Official implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTo
 56 Dec 23, 2022
56 Dec 23, 2022

A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
 488 Nov 28, 2022
488 Nov 28, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
 586 Dec 24, 2022
586 Dec 24, 2022

PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
 1.6k Dec 25, 2022
1.6k Dec 25, 2022
Original implementation of the pooling method introduced in "Speaker embeddings by modeling channel-wise correlations"
Speaker-Embeddings-Correlation-Pooling This is the original implementation of the pooling method introduced in "Speaker embeddings by modeling channel
 10 Apr 30, 2022
10 Apr 30, 2022
CNNs for Sentence Classification in PyTorch
Introduction This is the implementation of Kim's Convolutional Neural Networks for Sentence Classification paper in PyTorch. Kim's implementation of t
 956 Dec 19, 2022
956 Dec 19, 2022
Applying "Load What You Need: Smaller Versions of Multilingual BERT" to LaBSE
smaller-LaBSE LaBSE(Language-agnostic BERT Sentence Embedding) is a very good method to get sentence embeddings across languages. But it is hard to fi
 13 Sep 2, 2022
13 Sep 2, 2022

Search Git commits in natural language
NaLCoS - NAtural Language COmmit Search Search commit messages in your repository in natural language. NaLCoS (NAtural Language COmmit Search) is a co
 50 Mar 22, 2022
50 Mar 22, 2022

Line as a Visual Sentence: Context-aware Line Descriptor for Visual Localization
Line as a Visual Sentence with LineTR This repository contains the inference code, pretrained model, and demo scripts of the following paper. It suppo
 158 Dec 27, 2022
158 Dec 27, 2022

Embeddinghub is a database built for machine learning embeddings.
Embeddinghub is a database built for machine learning embeddings.
 1.2k Jan 1, 2023
1.2k Jan 1, 2023

This repository contains the PyTorch implementation of the paper STaCK: Sentence Ordering with Temporal Commonsense Knowledge appearing at EMNLP 2021.
STaCK: Sentence Ordering with Temporal Commonsense Knowledge This repository contains the pytorch implementation of the paper STaCK: Sentence Ordering
 23 Dec 16, 2022
23 Dec 16, 2022
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

Learning Compatible Embeddings, ICCV 2021
LCE Learning Compatible Embeddings, ICCV 2021 by Qiang Meng, Chixiang Zhang, Xiaoqiang Xu and Feng Zhou Paper: Arxiv We cannot release source codes pu
 25 Dec 17, 2022
25 Dec 17, 2022
Large scale embeddings on a single machine.
Marius Marius is a system under active development for training embeddings for large-scale graphs on a single machine. Training on large scale graphs
 107 Jan 3, 2023
107 Jan 3, 2023
Code for technical report "An Improved Baseline for Sentence-level Relation Extraction".
RE_improved_baseline Code for technical report "An Improved Baseline for Sentence-level Relation Extraction". Requirements torch = 1.8.1 transformers
 74 Nov 29, 2022
74 Nov 29, 2022
Versatile Generative Language Model
Versatile Generative Language Model This is the implementation of the paper: Exploring Versatile Generative Language Model Via Parameter-Efficient Tra
 17 Dec 2, 2022
17 Dec 2, 2022

This project is a sample demo of Arxiv search related to AI/ML Papers built using Streamlit, sentence-transformers and Faiss.
This project is a sample demo of Arxiv search related to AI/ML Papers built using Streamlit, sentence-transformers and Faiss.
 49 Oct 30, 2022
49 Oct 30, 2022
PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
1.6k Dec 29, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
586 Dec 24, 2022
A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
488 Nov 28, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022

A PyTorch Implementation of "Watch Your Step: Learning Node Embeddings via Graph Attention" (NeurIPS 2018).
Attention Walk ⠀⠀ A PyTorch Implementation of Watch Your Step: Learning Node Embeddings via Graph Attention (NIPS 2018). Abstract Graph embedding meth
 303 Dec 9, 2022
303 Dec 9, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
 203 Dec 20, 2022
203 Dec 20, 2022
DRIFT is a tool for Diachronic Analysis of Scientific Literature.
About DRIFT is a tool for Diachronic Analysis of Scientific Literature. The application offers user-friendly and customizable utilities for two modes:
 108 Dec 12, 2022
108 Dec 12, 2022
Implementation of Rotary Embeddings, from the Roformer paper, in Pytorch
Rotary Embeddings - Pytorch A standalone library for adding rotary embeddings to transformers in Pytorch, following its success as relative positional
 110 Dec 30, 2022
110 Dec 30, 2022
🤖 A Python library for learning and evaluating knowledge graph embeddings
PyKEEN PyKEEN (Python KnowlEdge EmbeddiNgs) is a Python package designed to train and evaluate knowledge graph embedding models (incorporating multi-m
 1.1k Jan 9, 2023
1.1k Jan 9, 2023
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022
[ACL 20] Probing Linguistic Features of Sentence-level Representations in Neural Relation Extraction
REval Table of Contents Introduction Overview Requirements Installation Probing Usage Citation License 🎓 Introduction REval is a simple framework for
 13 Jan 6, 2023
13 Jan 6, 2023
Shared code for training sentence embeddings with Flax / JAX
flax-sentence-embeddings This repository will be used to share code for the Flax / JAX community event to train sentence embeddings on 1B+ training pa
 23 Dec 30, 2022
23 Dec 30, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
 99 Dec 23, 2022
99 Dec 23, 2022

UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus
UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus General info This is
 71 Oct 25, 2022
71 Oct 25, 2022

Reliable probability face embeddings
ProbFace, arxiv This is a demo code of training and testing [ProbFace] using Tensorflow. ProbFace is a reliable Probabilistic Face Embeddging (PFE) me
 34 Dec 31, 2022
34 Dec 31, 2022
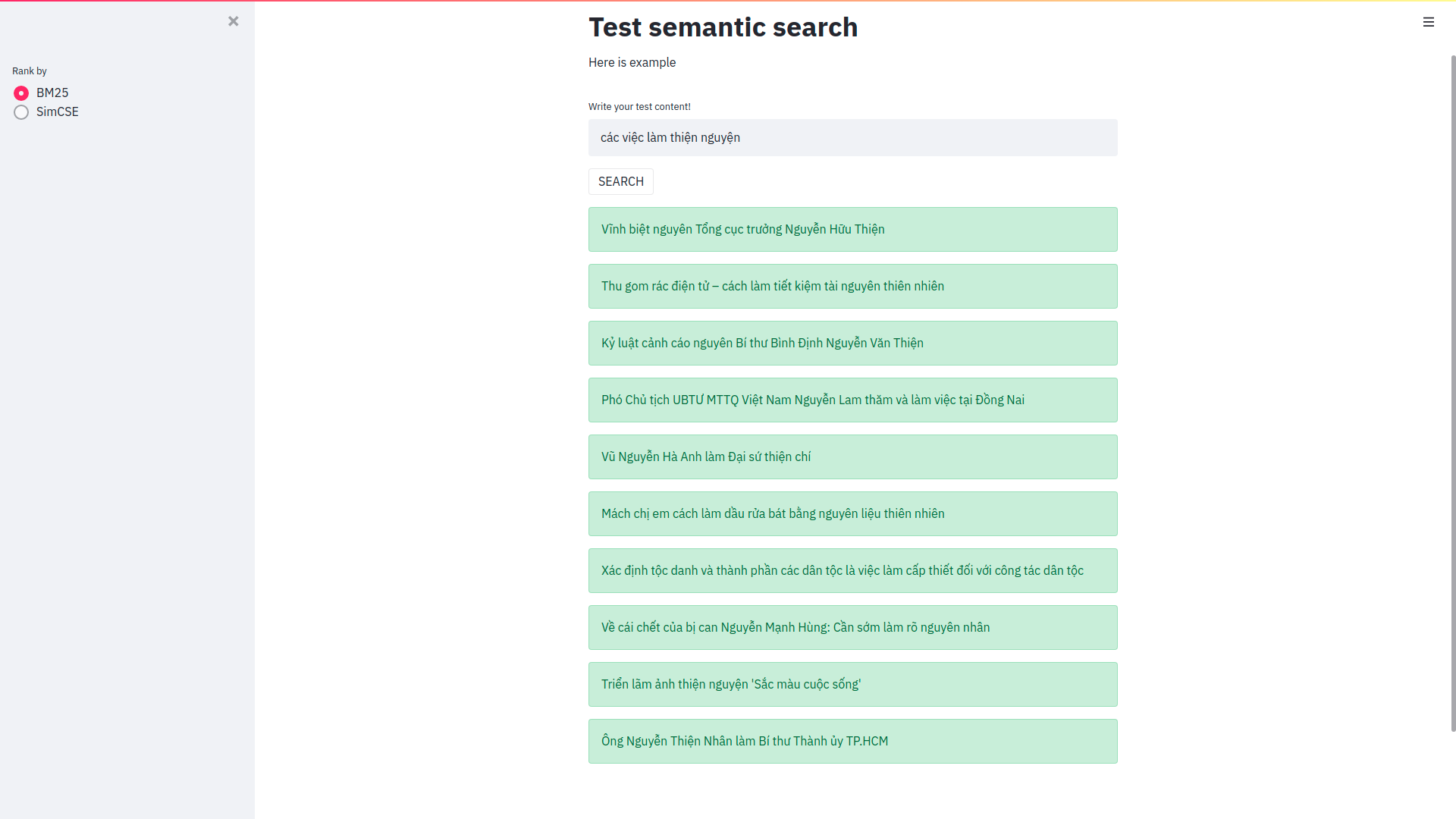
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings Trong bài viết này mình sẽ sử dụng pretrain model SimCS
 18 Nov 25, 2022
18 Nov 25, 2022
Scalable Attentive Sentence-Pair Modeling via Distilled Sentence Embedding (AAAI 2020) - PyTorch Implementation
Scalable Attentive Sentence-Pair Modeling via Distilled Sentence Embedding PyTorch implementation for the Scalable Attentive Sentence-Pair Modeling vi
 25 Dec 2, 2022
25 Dec 2, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
What is MUSE? MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (16 languages) of Universal Sentence Encoder (USE). MUS
47 Sep 5, 2022
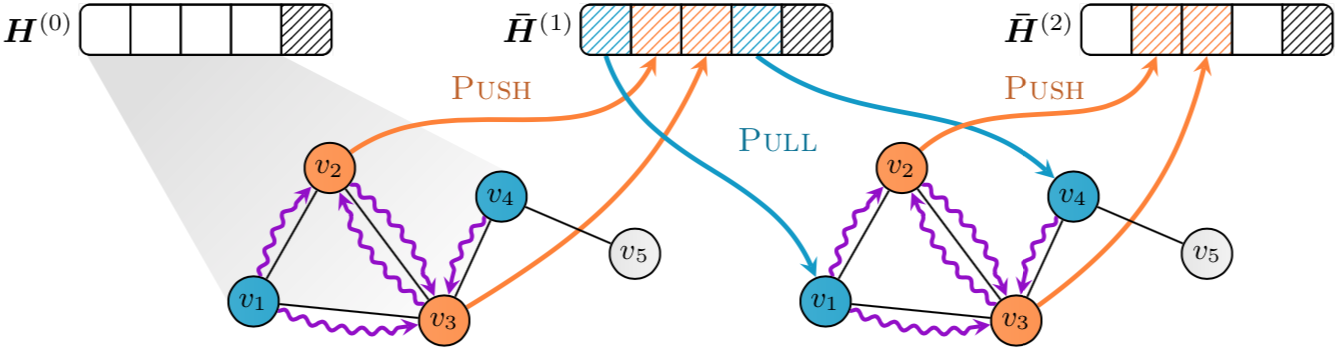
Implementation of "GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings" in PyTorch
PyGAS: Auto-Scaling GNNs in PyG PyGAS is the practical realization of our G NN A uto S cale (GAS) framework, which scales arbitrary message-passing GN
 139 Dec 25, 2022
139 Dec 25, 2022
Using context-free grammar formalism to parse English sentences to determine their structure to help computer to better understand the meaning of the sentence.
Sentance Parser Executing the Program Make sure Python 3.6+ is installed. Install requirements $ pip install requirements.txt Run the program:
 12 Sep 28, 2022
12 Sep 28, 2022
Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
ConSERT Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer Requirements torch==1.6.0
 478 Dec 25, 2022
478 Dec 25, 2022
Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
ConSERT Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer Requirements torch==1.6.0
478 Dec 25, 2022
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
 224 Jan 4, 2023
224 Jan 4, 2023
source code for paper: WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach.
WhiteningBERT Source code and data for paper WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach. Preparation git clone https://github.com
 49 Dec 17, 2022
49 Dec 17, 2022
Code and models used in "MUSS Multilingual Unsupervised Sentence Simplification by Mining Paraphrases".
Multilingual Unsupervised Sentence Simplification Code and pretrained models to reproduce experiments in "MUSS: Multilingual Unsupervised Sentence Sim
81 Dec 29, 2022
Code for paper PairRE: Knowledge Graph Embeddings via Paired Relation Vectors.
PairRE Code for paper PairRE: Knowledge Graph Embeddings via Paired Relation Vectors. This implementation of PairRE for Open Graph Benchmak datasets (
 65 Dec 19, 2022
65 Dec 19, 2022
InferSent sentence embeddings
InferSent InferSent is a sentence embeddings method that provides semantic representations for English sentences. It is trained on natural language in
2.2k Dec 27, 2022
jiant is an NLP toolkit
jiant is an NLP toolkit The multitask and transfer learning toolkit for natural language processing research Why should I use jiant? jiant supports mu
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning
GenSen Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning Sandeep Subramanian, Adam Trischler, Yoshua B
 309 Oct 19, 2022
309 Oct 19, 2022
Language-Agnostic SEntence Representations
LASER Language-Agnostic SEntence Representations LASER is a library to calculate and use multilingual sentence embeddings. NEWS 2019/11/08 CCMatrix is
3.2k Jan 4, 2023

A library for Multilingual Unsupervised or Supervised word Embeddings
MUSE: Multilingual Unsupervised and Supervised Embeddings MUSE is a Python library for multilingual word embeddings, whose goal is to provide the comm
3k Jan 6, 2023

SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
 2.5k Jan 7, 2023
2.5k Jan 7, 2023
Sentence boundary disambiguation tool for Japanese texts (日本語文境界判定器)
Bunkai Bunkai is a sentence boundary (SB) disambiguation tool for Japanese texts. Quick Start $ pip install bunkai $ echo -e '宿を予約しました♪!まだ2ヶ月も先だけど。早すぎ
 160 Dec 23, 2022
160 Dec 23, 2022
SpikeX - SpaCy Pipes for Knowledge Extraction
SpikeX is a collection of pipes ready to be plugged in a spaCy pipeline. It aims to help in building knowledge extraction tools with almost-zero effort.
 384 Dec 12, 2022
384 Dec 12, 2022
State of the art Semantic Sentence Embeddings
Contrastive Tension State of the art Semantic Sentence Embeddings Published Paper · Huggingface Models · Report Bug Overview This is the official code
 88 Dec 30, 2022
88 Dec 30, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
Library for faster pinned CPU - GPU transfer in Pytorch
SpeedTorch Faster pinned CPU tensor - GPU Pytorch variabe transfer and GPU tensor - GPU Pytorch variable transfer, in certain cases. Update 9-29-1
 657 Dec 19, 2022
657 Dec 19, 2022
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. Flair is: A powerful NLP library. Flair allo
 12.3k Jan 2, 2023
12.3k Jan 2, 2023

Improving XGBoost survival analysis with embeddings and debiased estimators
xgbse: XGBoost Survival Embeddings "There are two cultures in the use of statistical modeling to reach conclusions from data
 242 Dec 30, 2022
242 Dec 30, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 11.7k Feb 18, 2021
11.7k Feb 18, 2021
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
 2.1k Feb 13, 2021
2.1k Feb 13, 2021

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 1.5k Feb 17, 2021
1.5k Feb 17, 2021
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
 1.9k Feb 18, 2021
1.9k Feb 18, 2021
🐍💯pySBD (Python Sentence Boundary Disambiguation) is a rule-based sentence boundary detection that works out-of-the-box.
pySBD: Python Sentence Boundary Disambiguation (SBD) pySBD - python Sentence Boundary Disambiguation (SBD) - is a rule-based sentence boundary detecti
 277 Feb 18, 2021
277 Feb 18, 2021

Extract Keywords from sentence or Replace keywords in sentences.
FlashText This module can be used to replace keywords in sentences or extract keywords from sentences. It is based on the FlashText algorithm. Install
 4.7k Feb 17, 2021
4.7k Feb 17, 2021
Sentence Embeddings with BERT & XLNet
Sentence Transformers: Multilingual Sentence Embeddings using BERT / RoBERTa / XLM-RoBERTa & Co. with PyTorch This framework provides an easy method t
 4.2k Feb 18, 2021
4.2k Feb 18, 2021
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. IMPORTANT: (30.08.2020) We moved our models
10k Feb 18, 2021

Learning RGB-D Feature Embeddings for Unseen Object Instance Segmentation
Unseen Object Clustering: Learning RGB-D Feature Embeddings for Unseen Object Instance Segmentation Introduction In this work, we propose a new method
 132 Dec 13, 2022
132 Dec 13, 2022
the code used for the preprint Embedding-based Instance Segmentation of Microscopy Images.
EmbedSeg Introduction This repository hosts the version of the code used for the preprint Embedding-based Instance Segmentation of Microscopy Images.
 88 Dec 25, 2022
88 Dec 25, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
11.7k Feb 12, 2021
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
2.7k Jan 8, 2023
Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
2k Dec 27, 2022
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
1.9k Feb 3, 2021
🐍💯pySBD (Python Sentence Boundary Disambiguation) is a rule-based sentence boundary detection that works out-of-the-box.
pySBD: Python Sentence Boundary Disambiguation (SBD) pySBD - python Sentence Boundary Disambiguation (SBD) - is a rule-based sentence boundary detecti
549 Jan 6, 2023
Extract Keywords from sentence or Replace keywords in sentences.
FlashText This module can be used to replace keywords in sentences or extract keywords from sentences. It is based on the FlashText algorithm. Install
5.3k Jan 1, 2023
Sentence Embeddings with BERT & XLNet
Sentence Transformers: Multilingual Sentence Embeddings using BERT / RoBERTa / XLM-RoBERTa & Co. with PyTorch This framework provides an easy method t
9.1k Jan 2, 2023
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. IMPORTANT: (30.08.2020) We moved our models
12.3k Dec 31, 2022

Learning embeddings for classification, retrieval and ranking.
StarSpace StarSpace is a general-purpose neural model for efficient learning of entity embeddings for solving a wide variety of problems: Learning wor
3.8k Dec 22, 2022

Trankit is a Light-Weight Transformer-based Python Toolkit for Multilingual Natural Language Processing
Trankit: A Light-Weight Transformer-based Python Toolkit for Multilingual Natural Language Processing Trankit is a light-weight Transformer-based Pyth
 652 Jan 6, 2023
652 Jan 6, 2023

Joint detection and tracking model named DEFT, or ``Detection Embeddings for Tracking.
DEFT: Detection Embeddings for Tracking DEFT: Detection Embeddings for Tracking, Mohamed Chaabane, Peter Zhang, J. Ross Beveridge, Stephen O'Hara
 253 Dec 18, 2022
253 Dec 18, 2022
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
2.1k Jan 1, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 2, 2023
Yet Another Sequence Encoder - Encode sequences to vector of vector in python !
Yase Yet Another Sequence Encoder - encode sequences to vector of vectors in python ! Why Yase ? Yase enable you to encode any sequence which can be r
 12 Aug 19, 2021
12 Aug 19, 2021
A Python package implementing a new model for text classification with visualization tools for Explainable AI :octocat:
A Python package implementing a new model for text classification with visualization tools for Explainable AI 🍣 Online live demos: http://tworld.io/s
 285 Jan 2, 2023
285 Jan 2, 2023
A sentence aligner for comparable corpora
About Yalign is a tool for extracting parallel sentences from comparable corpora. Statistical Machine Translation relies on parallel corpora (eg.. eur
 128 Aug 24, 2022
128 Aug 24, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 3, 2023
A python library for self-supervised learning on images.
Lightly is a computer vision framework for self-supervised learning. We, at Lightly, are passionate engineers who want to make deep learning more effi
 2k Jan 8, 2023
2k Jan 8, 2023