103 Repositories
Python sentence-tokenizer Libraries

This repository consists of a complete guide on natural language processing (NLP) in Python where we'll learn various techniques for implementing NLP including parsing & text processing and understand how to use NLP for text feature engineering.
Python_Natural_Language_Processing This repository contains tutorials on important topics related to Natural Language Processing (NPL). No. Name 01 01
 170 Dec 13, 2022
170 Dec 13, 2022

Process text, including tokenizing and representing sentences as vectors and Applying some concepts like RNN, LSTM and GRU to create a classifier can detect the language in which a sentence is written from among 17 languages.
Language Identifier What is this ? The goal of this project is to create a model that is able to predict a given sentence language through text proces
 9 Dec 15, 2022
9 Dec 15, 2022
NAACL 2022: MCSE: Multimodal Contrastive Learning of Sentence Embeddings
MCSE: Multimodal Contrastive Learning of Sentence Embeddings This repository contains code and pre-trained models for our NAACL-2022 paper MCSE: Multi
 39 Nov 15, 2022
39 Nov 15, 2022
Estimation of the CEFR complexity score of a given word, sentence or text.
NLP-Swedish … allows to estimate CEFR (Common European Framework of References) complexity score of a given word, sentence or text. CEFR scores come f
 3 Apr 30, 2022
3 Apr 30, 2022
Bpe algorithm can finetune tokenizer - Bpe algorithm can finetune tokenizer
"# bpe_algorithm_can_finetune_tokenizer" this is an implyment for https://github
 1 Feb 2, 2022
1 Feb 2, 2022

SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples
SNCSE SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples This is the repository for SNCSE. SNCSE aims to allev
 59 Jan 2, 2023
59 Jan 2, 2023
BERTopic is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions
BERTopic BERTopic is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable
 3.6k Jan 7, 2023
3.6k Jan 7, 2023
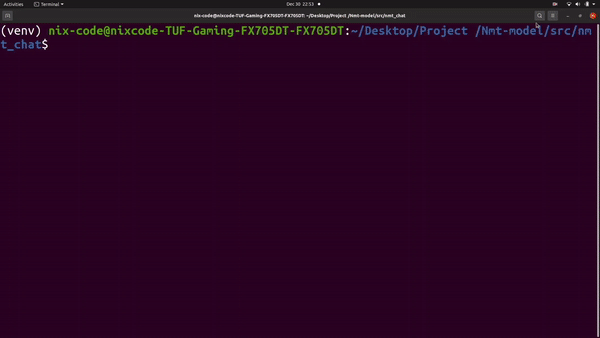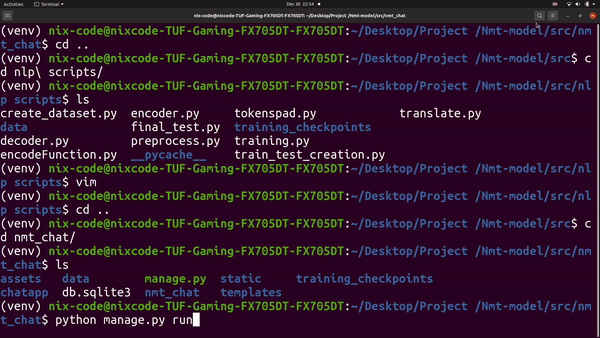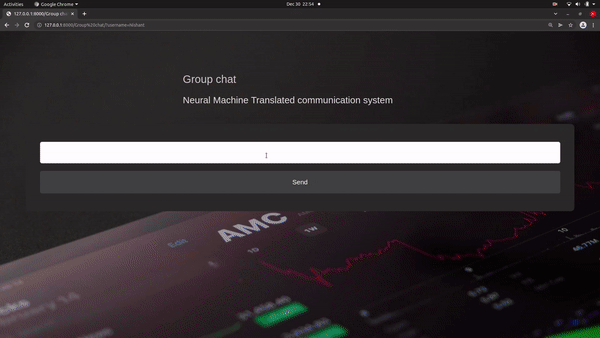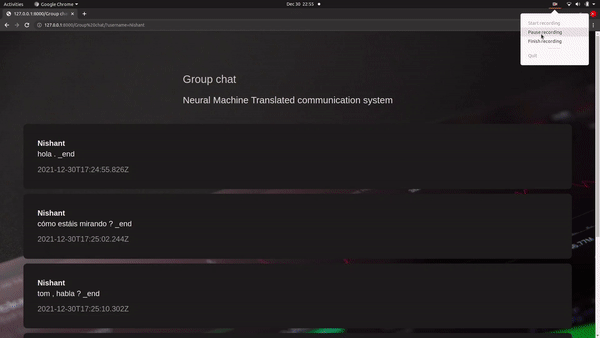
The model is designed to train a single and large neural network in order to predict correct translation by reading the given sentence.
Neural Machine Translation communication system The model is basically direct to convert one source language to another targeted language using encode
 7 Sep 22, 2022
7 Sep 22, 2022
A natural language processing model for sequential sentence classification in medical abstracts.
NLP PubMed Medical Research Paper Abstract (Randomized Controlled Trial) A natural language processing model for sequential sentence classification in
 1 Jan 17, 2022
1 Jan 17, 2022
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
 847 Dec 19, 2022
847 Dec 19, 2022
Prompt-BERT: Prompt makes BERT Better at Sentence Embeddings
Prompt-BERT: Prompt makes BERT Better at Sentence Embeddings Results on STS Tasks Model STS12 STS13 STS14 STS15 STS16 STSb SICK-R Avg. unsup-prompt-be
 196 Jan 8, 2023
196 Jan 8, 2023
Mapping a variable-length sentence to a fixed-length vector using BERT model
Are you looking for X-as-service? Try the Cloud-Native Neural Search Framework for Any Kind of Data bert-as-service Using BERT model as a sentence enc
 11.1k Jan 1, 2023
11.1k Jan 1, 2023

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023
Convolutional Neural Networks for Sentence Classification
Convolutional Neural Networks for Sentence Classification Code for the paper Convolutional Neural Networks for Sentence Classification (EMNLP 2014). R
 2k Jan 2, 2023
2k Jan 2, 2023
Tokenizer - Module python d'analyse syntaxique et de grammaire, tokenization
Tokenizer Le Tokenizer est un analyseur lexicale, il permet, comme Flex and Yacc par exemple, de tokenizer du code, c'est à dire transformer du code e
 1 Aug 15, 2022
1 Aug 15, 2022

Deep-Learning-Image-Captioning - Implementing convolutional and recurrent neural networks in Keras to generate sentence descriptions of images
Deep Learning - Image Captioning with Convolutional and Recurrent Neural Nets ========================================================================
 23 Apr 6, 2022
23 Apr 6, 2022
LSTM based Sentiment Classification using Tensorflow - Amazon Reviews Rating
LSTM based Sentiment Classification using Tensorflow - Amazon Reviews Rating (Dataset) The dataset is from Amazon Review Data (2018)
 1 Jan 16, 2022
1 Jan 16, 2022
The model is designed to train a single and large neural network in order to predict correct translation by reading the given sentence.
Neural Machine Translation communication system The model is basically direct to convert one source language to another targeted language using encode
7 Sep 22, 2022
Self-Guided Contrastive Learning for BERT Sentence Representations
Self-Guided Contrastive Learning for BERT Sentence Representations This repository is dedicated for releasing the implementation of the models utilize
 16 Dec 4, 2022
16 Dec 4, 2022
Utilize Korean BERT model in sentence-transformers library
ko-sentence-transformers 이 프로젝트는 KoBERT 모델을 sentence-transformers 에서 보다 쉽게 사용하기 위해 만들어졌습니다. Ko-Sentence-BERT-SKTBERT 프로젝트에서는 KoBERT 모델을 sentence-trans
 40 Dec 20, 2022
40 Dec 20, 2022
jiant is an NLP toolkit
🚨 Update 🚨 : As of 2021/10/17, the jiant project is no longer being actively maintained. This means there will be no plans to add new models, tasks,
 1.5k Dec 28, 2022
1.5k Dec 28, 2022
Korean Sentence Embedding Repository
Korean-Sentence-Embedding 🍭 Korean sentence embedding repository. You can download the pre-trained models and inference right away, also it provides
 80 Jan 2, 2023
80 Jan 2, 2023
SEOVER: Sentence-level Emotion Orientation Vector based Conversation Emotion Recognition Model
SEOVER-Master This code is the implementation of paper: SEOVER: Sentence-level Emotion Orientation Vector based Conversation Emotion Recognition Model
 4 Feb 24, 2022
4 Feb 24, 2022
Train BPE with fastBPE, and load to Huggingface Tokenizer.
BPEer Train BPE with fastBPE, and load to Huggingface Tokenizer. Description The BPETrainer of Huggingface consumes a lot of memory when I am training
 1 Dec 23, 2021
1 Dec 23, 2021
A Japanese tokenizer based on recurrent neural networks
Nagisa is a python module for Japanese word segmentation/POS-tagging. It is designed to be a simple and easy-to-use tool. This tool has the following
 325 Jan 5, 2023
325 Jan 5, 2023
Article Reranking by Memory-enhanced Key Sentence Matching for Detecting Previously Fact-checked Claims.
MTM This is the official repository of the paper: Article Reranking by Memory-enhanced Key Sentence Matching for Detecting Previously Fact-checked Cla
 13 Sep 17, 2022
13 Sep 17, 2022
Malware-Related Sentence Classification
Malware-Related Sentence Classification This repo contains the code for the ICTAI 2021 paper "Enrichment of Features for Malware-Related Sentence Clas
 1 Mar 26, 2022
1 Mar 26, 2022
Using Bert as the backbone model for lime, designed for NLP task explanation (sentence pair text classification task)
Lime Comparing deep contextualized model for sentences highlighting task. In addition, take the classic explanation model "LIME" with bert-base model
 2 Jan 18, 2022
2 Jan 18, 2022

iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
 435 Jan 6, 2023
435 Jan 6, 2023
iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
435 Jan 6, 2023

Code for the paper "Controllable Video Captioning with an Exemplar Sentence"
SMCG Code for the paper "Controllable Video Captioning with an Exemplar Sentence" Introduction We investigate a novel and challenging task, namely con
 10 Dec 4, 2022
10 Dec 4, 2022
Evaluating Cross-lingual Sentence Representations
XNLI: The Cross-Lingual NLI Corpus XNLI is an evaluation corpus for language transfer and cross-lingual sentence classification in 15 languages. New:
 395 Dec 19, 2022
395 Dec 19, 2022
Research code for the paper "How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models"
Introduction This repository contains research code for the ACL 2021 paper "How Good is Your Tokenizer? On the Monolingual Performance of Multilingual
 20 Aug 4, 2022
20 Aug 4, 2022
Code for the paper "Controllable Video Captioning with an Exemplar Sentence"
SMCG Code for the paper "Controllable Video Captioning with an Exemplar Sentence" Introduction We investigate a novel and challenging task, namely con
10 Dec 4, 2022
Implementation of the paper 'Sentence Bottleneck Autoencoders from Transformer Language Models'
Introduction This repository contains the code for the paper Sentence Bottleneck Autoencoders from Transformer Language Models by Ivan Montero, Nikola
 14 Dec 28, 2022
14 Dec 28, 2022
Code for the AAAI 2022 paper "Zero-Shot Cross-Lingual Machine Reading Comprehension via Inter-Sentence Dependency Graph".
multilingual-mrc-isdg Code for the AAAI 2022 paper "Zero-Shot Cross-Lingual Machine Reading Comprehension via Inter-Sentence Dependency Graph". This r
 5 Dec 7, 2022
5 Dec 7, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
🧪 Cutting-edge experimental spaCy components and features
spacy-experimental: Cutting-edge experimental spaCy components and features This package includes experimental components and features for spaCy v3.x,
 65 Dec 30, 2022
65 Dec 30, 2022
Trans-Encoder: Unsupervised sentence-pair modelling through self- and mutual-distillations
Trans-Encoder: Unsupervised sentence-pair modelling through self- and mutual-distillations Code repo for paper Trans-Encoder: Unsupervised sentence-pa
 101 Dec 29, 2022
101 Dec 29, 2022

Weakly Supervised Dense Event Captioning in Videos, i.e. generating multiple sentence descriptions for a video in a weakly-supervised manner.
WSDEC This is the official repo for our NeurIPS paper Weakly Supervised Dense Event Captioning in Videos. Description Repo directories ./: global conf
 96 Nov 1, 2022
96 Nov 1, 2022
Code for the paper "A Simple but Tough-to-Beat Baseline for Sentence Embeddings".
Code for the paper "A Simple but Tough-to-Beat Baseline for Sentence Embeddings".
 1.1k Dec 27, 2022
1.1k Dec 27, 2022
Japanese Long-Unit-Word Tokenizer with RemBertTokenizerFast of Transformers
Japanese-LUW-Tokenizer Japanese Long-Unit-Word (国語研長単位) Tokenizer for Transformers based on 青空文庫 Basic Usage from transformers import RemBertToken
 3 Dec 22, 2021
3 Dec 22, 2021
A PyTorch implementation of unsupervised SimCSE
A PyTorch implementation of unsupervised SimCSE
 99 Dec 23, 2022
99 Dec 23, 2022
Trains an OpenNMT PyTorch model and SentencePiece tokenizer.
Trains an OpenNMT PyTorch model and SentencePiece tokenizer. Designed for use with Argos Translate and LibreTranslate.
 61 Dec 13, 2022
61 Dec 13, 2022
A sentence search engine that fetches examples from trusted news/media organisations. Great for writing better English.
A sentence search engine that fetches examples from trusted news/media websites. Great for improving writing & speaking better English.
 1 Apr 4, 2022
1 Apr 4, 2022
Bootstrapped Unsupervised Sentence Representation Learning (ACL 2021)
Install first pip3 install -e . Training python3 training/unsupervised_tuning.py python3 training/supervised_tuning.py python3 training/multilingual_
 26 Jul 22, 2022
26 Jul 22, 2022
A Word Level Transformer layer based on PyTorch and 🤗 Transformers.
Transformer Embedder A Word Level Transformer layer based on PyTorch and 🤗 Transformers. How to use Install the library from PyPI: pip install transf
 27 Nov 20, 2022
27 Nov 20, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
 114 Jan 6, 2023
114 Jan 6, 2023

EMNLP'2021: SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
 2.5k Dec 29, 2022
2.5k Dec 29, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
111 Dec 18, 2022

Transformer Based Korean Sentence Spacing Corrector
TKOrrector Transformer Based Korean Sentence Spacing Corrector License Summary This solution is made available under Apache 2 license. See the LICENSE
 3 Apr 18, 2022
3 Apr 18, 2022
utoken is a multilingual tokenizer that divides text into words, punctuation and special tokens such as numbers, URLs, XML tags, email-addresses and hashtags.
utoken utoken is a multilingual tokenizer that divides text into words, punctuation and special tokens such as numbers, URLs, XML tags, email-addresse
 11 Jan 5, 2023
11 Jan 5, 2023

A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
 488 Nov 28, 2022
488 Nov 28, 2022
CNNs for Sentence Classification in PyTorch
Introduction This is the implementation of Kim's Convolutional Neural Networks for Sentence Classification paper in PyTorch. Kim's implementation of t
 956 Dec 19, 2022
956 Dec 19, 2022
Applying "Load What You Need: Smaller Versions of Multilingual BERT" to LaBSE
smaller-LaBSE LaBSE(Language-agnostic BERT Sentence Embedding) is a very good method to get sentence embeddings across languages. But it is hard to fi
 13 Sep 2, 2022
13 Sep 2, 2022

Search Git commits in natural language
NaLCoS - NAtural Language COmmit Search Search commit messages in your repository in natural language. NaLCoS (NAtural Language COmmit Search) is a co
 50 Mar 22, 2022
50 Mar 22, 2022

Line as a Visual Sentence: Context-aware Line Descriptor for Visual Localization
Line as a Visual Sentence with LineTR This repository contains the inference code, pretrained model, and demo scripts of the following paper. It suppo
 158 Dec 27, 2022
158 Dec 27, 2022

This repository contains the PyTorch implementation of the paper STaCK: Sentence Ordering with Temporal Commonsense Knowledge appearing at EMNLP 2021.
STaCK: Sentence Ordering with Temporal Commonsense Knowledge This repository contains the pytorch implementation of the paper STaCK: Sentence Ordering
 23 Dec 16, 2022
23 Dec 16, 2022
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
Huggingface package for the discrete VAE used for DALL-E.
DALL-E-Tokenizer Huggingface package for the discrete VAE used for DALL-E.
 5 Sep 1, 2021
5 Sep 1, 2021

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
34 Nov 24, 2022
Code for technical report "An Improved Baseline for Sentence-level Relation Extraction".
RE_improved_baseline Code for technical report "An Improved Baseline for Sentence-level Relation Extraction". Requirements torch = 1.8.1 transformers
 74 Nov 29, 2022
74 Nov 29, 2022

This project is a sample demo of Arxiv search related to AI/ML Papers built using Streamlit, sentence-transformers and Faiss.
This project is a sample demo of Arxiv search related to AI/ML Papers built using Streamlit, sentence-transformers and Faiss.
 49 Oct 30, 2022
49 Oct 30, 2022
A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
488 Nov 28, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022
[ACL 20] Probing Linguistic Features of Sentence-level Representations in Neural Relation Extraction
REval Table of Contents Introduction Overview Requirements Installation Probing Usage Citation License 🎓 Introduction REval is a simple framework for
 13 Jan 6, 2023
13 Jan 6, 2023
Shared code for training sentence embeddings with Flax / JAX
flax-sentence-embeddings This repository will be used to share code for the Flax / JAX community event to train sentence embeddings on 1B+ training pa
 23 Dec 30, 2022
23 Dec 30, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
99 Dec 23, 2022
A versatile token stream for handwritten parsers.
Writing recursive-descent parsers by hand can be quite elegant but it's often a bit more verbose than expected, especially when it comes to handling indentation and reporting proper syntax errors. This package provides a powerful general-purpose token stream that addresses these issues and more.
 8 Nov 30, 2022
8 Nov 30, 2022
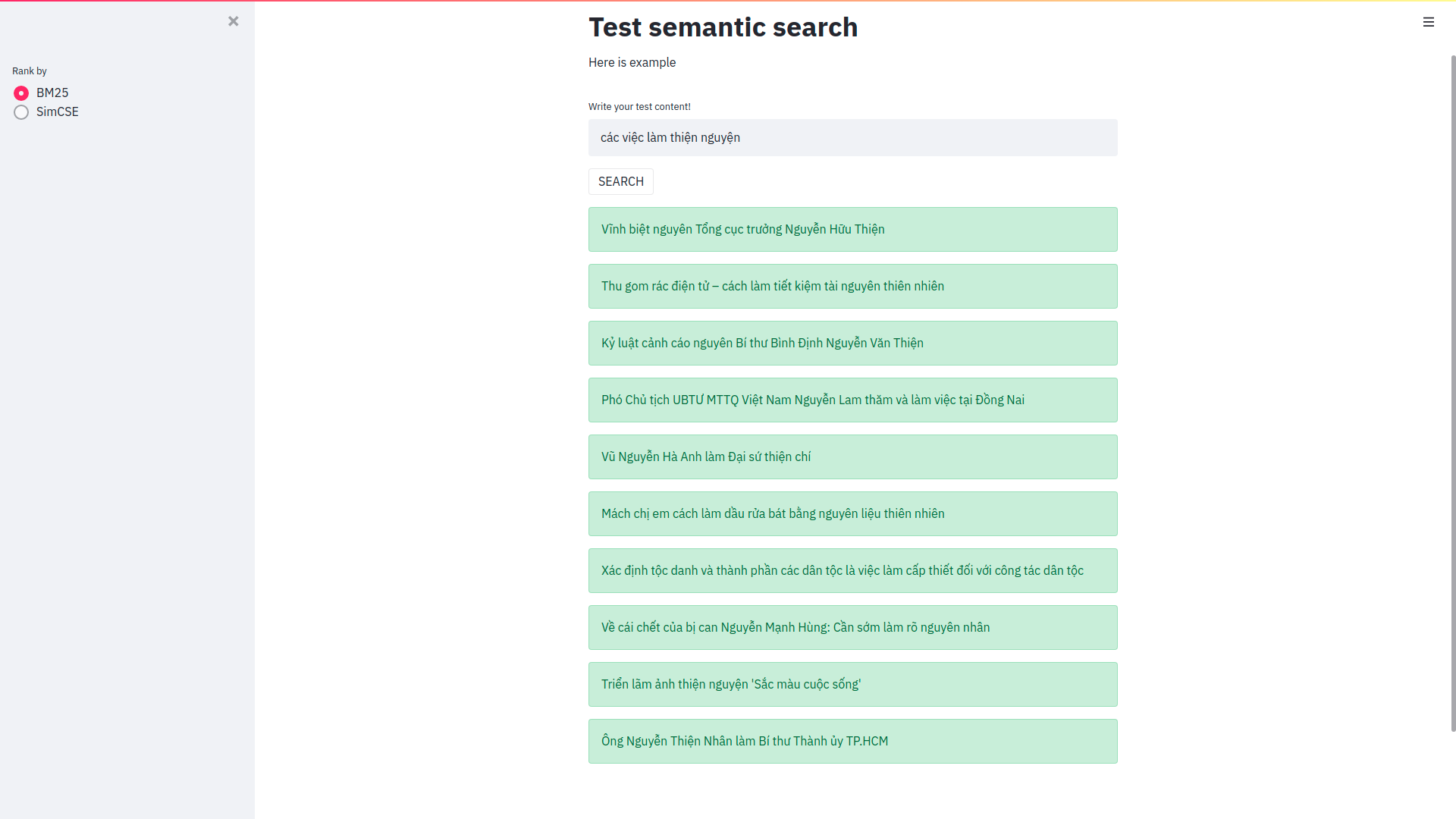
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings Trong bài viết này mình sẽ sử dụng pretrain model SimCS
 18 Nov 25, 2022
18 Nov 25, 2022
Scalable Attentive Sentence-Pair Modeling via Distilled Sentence Embedding (AAAI 2020) - PyTorch Implementation
Scalable Attentive Sentence-Pair Modeling via Distilled Sentence Embedding PyTorch implementation for the Scalable Attentive Sentence-Pair Modeling vi
 25 Dec 2, 2022
25 Dec 2, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
What is MUSE? MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (16 languages) of Universal Sentence Encoder (USE). MUS
47 Sep 5, 2022
Using context-free grammar formalism to parse English sentences to determine their structure to help computer to better understand the meaning of the sentence.
Sentance Parser Executing the Program Make sure Python 3.6+ is installed. Install requirements $ pip install requirements.txt Run the program:
 12 Sep 28, 2022
12 Sep 28, 2022
Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
ConSERT Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer Requirements torch==1.6.0
 478 Dec 25, 2022
478 Dec 25, 2022
Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
ConSERT Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer Requirements torch==1.6.0
478 Dec 25, 2022
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
 224 Jan 4, 2023
224 Jan 4, 2023
source code for paper: WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach.
WhiteningBERT Source code and data for paper WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach. Preparation git clone https://github.com
 49 Dec 17, 2022
49 Dec 17, 2022
Code and models used in "MUSS Multilingual Unsupervised Sentence Simplification by Mining Paraphrases".
Multilingual Unsupervised Sentence Simplification Code and pretrained models to reproduce experiments in "MUSS: Multilingual Unsupervised Sentence Sim
81 Dec 29, 2022
InferSent sentence embeddings
InferSent InferSent is a sentence embeddings method that provides semantic representations for English sentences. It is trained on natural language in
2.2k Dec 27, 2022
jiant is an NLP toolkit
jiant is an NLP toolkit The multitask and transfer learning toolkit for natural language processing research Why should I use jiant? jiant supports mu
1.5k Jan 4, 2023
Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning
GenSen Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning Sandeep Subramanian, Adam Trischler, Yoshua B
 309 Oct 19, 2022
309 Oct 19, 2022
Language-Agnostic SEntence Representations
LASER Language-Agnostic SEntence Representations LASER is a library to calculate and use multilingual sentence embeddings. NEWS 2019/11/08 CCMatrix is
3.2k Jan 4, 2023
SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
2.5k Jan 7, 2023
Sentence boundary disambiguation tool for Japanese texts (日本語文境界判定器)
Bunkai Bunkai is a sentence boundary (SB) disambiguation tool for Japanese texts. Quick Start $ pip install bunkai $ echo -e '宿を予約しました♪!まだ2ヶ月も先だけど。早すぎ
 160 Dec 23, 2022
160 Dec 23, 2022
SpikeX - SpaCy Pipes for Knowledge Extraction
SpikeX is a collection of pipes ready to be plugged in a spaCy pipeline. It aims to help in building knowledge extraction tools with almost-zero effort.
 384 Dec 12, 2022
384 Dec 12, 2022
State of the art Semantic Sentence Embeddings
Contrastive Tension State of the art Semantic Sentence Embeddings Published Paper · Huggingface Models · Report Bug Overview This is the official code
 88 Dec 30, 2022
88 Dec 30, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
718 Feb 18, 2021
🐍💯pySBD (Python Sentence Boundary Disambiguation) is a rule-based sentence boundary detection that works out-of-the-box.
pySBD: Python Sentence Boundary Disambiguation (SBD) pySBD - python Sentence Boundary Disambiguation (SBD) - is a rule-based sentence boundary detecti
 277 Feb 18, 2021
277 Feb 18, 2021

Extract Keywords from sentence or Replace keywords in sentences.
FlashText This module can be used to replace keywords in sentences or extract keywords from sentences. It is based on the FlashText algorithm. Install
 4.7k Feb 17, 2021
4.7k Feb 17, 2021
Sentence Embeddings with BERT & XLNet
Sentence Transformers: Multilingual Sentence Embeddings using BERT / RoBERTa / XLM-RoBERTa & Co. with PyTorch This framework provides an easy method t
 4.2k Feb 18, 2021
4.2k Feb 18, 2021
Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabu
 4.8k Feb 18, 2021
4.8k Feb 18, 2021
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
847 Dec 19, 2022
🐍💯pySBD (Python Sentence Boundary Disambiguation) is a rule-based sentence boundary detection that works out-of-the-box.
pySBD: Python Sentence Boundary Disambiguation (SBD) pySBD - python Sentence Boundary Disambiguation (SBD) - is a rule-based sentence boundary detecti
549 Jan 6, 2023
Extract Keywords from sentence or Replace keywords in sentences.
FlashText This module can be used to replace keywords in sentences or extract keywords from sentences. It is based on the FlashText algorithm. Install
5.3k Jan 1, 2023
Sentence Embeddings with BERT & XLNet
Sentence Transformers: Multilingual Sentence Embeddings using BERT / RoBERTa / XLM-RoBERTa & Co. with PyTorch This framework provides an easy method t
9.1k Jan 2, 2023
Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabu
6.4k Jan 1, 2023

Trankit is a Light-Weight Transformer-based Python Toolkit for Multilingual Natural Language Processing
Trankit: A Light-Weight Transformer-based Python Toolkit for Multilingual Natural Language Processing Trankit is a light-weight Transformer-based Pyth
 652 Jan 6, 2023
652 Jan 6, 2023
Yet Another Sequence Encoder - Encode sequences to vector of vector in python !
Yase Yet Another Sequence Encoder - encode sequences to vector of vectors in python ! Why Yase ? Yase enable you to encode any sequence which can be r
 12 Aug 19, 2021
12 Aug 19, 2021