2732 Repositories
Python series-data Libraries
Books, Presentations, Workshops, Notebook Labs, and Model Zoo for Software Engineers and Data Scientists wanting to learn the TF.Keras Machine Learning framework
Books, Presentations, Workshops, Notebook Labs, and Model Zoo for Software Engineers and Data Scientists wanting to learn the TF.Keras Machine Learning framework
 792 Dec 28, 2022
792 Dec 28, 2022
Spin-off Notice: the modules and functions used by our research notebooks have been refactored into another repository
Fecon235 - Notebooks for financial economics. Keywords: Jupyter notebook pandas Federal Reserve FRED Ferbus GDP CPI PCE inflation unemployment wage income debt Case-Shiller housing asset portfolio equities SPX bonds TIPS rates currency FX euro EUR USD JPY yen XAU gold Brent WTI oil Holt-Winters time-series forecasting statistics econometrics
 825 Dec 27, 2022
825 Dec 27, 2022

Lolviz - A simple Python data-structure visualization tool for lists of lists, lists, dictionaries; primarily for use in Jupyter notebooks / presentations
lolviz By Terence Parr. See Explained.ai for more stuff. A very nice looking javascript lolviz port with improvements by Adnan M.Sagar. A simple Pytho
 785 Dec 30, 2022
785 Dec 30, 2022
Kaggle-titanic - A tutorial for Kaggle's Titanic: Machine Learning from Disaster competition. Demonstrates basic data munging, analysis, and visualization techniques. Shows examples of supervised machine learning techniques.
Kaggle-titanic This is a tutorial in an IPython Notebook for the Kaggle competition, Titanic Machine Learning From Disaster. The goal of this reposito
 800 Dec 15, 2022
800 Dec 15, 2022
Statistical-Rethinking-with-Python-and-PyMC3 - Python/PyMC3 port of the examples in " Statistical Rethinking A Bayesian Course with Examples in R and Stan" by Richard McElreath
Statistical Rethinking with Python and PyMC3 This repository has been deprecated in favour of this one, please check that repository for updates, for
 786 Dec 29, 2022
786 Dec 29, 2022
Orbivator AI - To Determine which features of data (measurements) are most important for diagnosing breast cancer and find out if breast cancer occurs or not.
Orbivator_AI Breast Cancer Wisconsin (Diagnostic) GOAL To Determine which features of data (measurements) are most important for diagnosing breast can
 1 Jan 2, 2022
1 Jan 2, 2022
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
 5 Sep 28, 2022
5 Sep 28, 2022
Numerical-computing-is-fun - Learning numerical computing with notebooks for all ages.
As much as this series is to educate aspiring computer programmers and data scientists of all ages and all backgrounds, it is also a reminder to mysel
 758 Dec 25, 2022
758 Dec 25, 2022

50-days-of-Statistics-for-Data-Science - This repository consist of a 50-day program
50-days-of-Statistics-for-Data-Science - This repository consist of a 50-day program. All the statistics required for the complete understanding of data science will be uploaded in this repository.
 22 Dec 9, 2022
22 Dec 9, 2022
The Master's in Data Science Program run by the Faculty of Mathematics and Information Science
The Master's in Data Science Program run by the Faculty of Mathematics and Information Science is among the first European programs in Data Science and is fully focused on data engineering and data analytics.
 2 Jun 17, 2022
2 Jun 17, 2022

UltraGraphQL - a GraphQL interface for querying and modifying RDF data on the Web.
UltraGraphQL - cloned from https://git.rwth-aachen.de/i5/ultragraphql Updated or extended files: build.gradle: updated maven to use maven {url "https:
 1 Jan 7, 2023
1 Jan 7, 2023

Linescanning - Package for (pre)processing of anatomical and (linescanning) fMRI data
line scanning repository This repository contains all of the tools used during the acquisition and postprocessing of line scanning data at the Spinoza
 4 Sep 14, 2022
4 Sep 14, 2022
Mortgage-loan-prediction - Show how to perform advanced Analytics and Machine Learning in Python using a full complement of PyData utilities
Mortgage-loan-prediction - Show how to perform advanced Analytics and Machine Learning in Python using a full complement of PyData utilities. This is aimed at those looking to get into the field of Data Science or those who are already in the field and looking to solve a real-world project with python.
 1 Dec 26, 2021
1 Dec 26, 2021
Using SQLite within Python to create database and analyze Starcraft 2 units data (Pandas also used)
SQLite python Starcraft 2 English This project shows the usage of SQLite with python. To create, modify and communicate with the SQLite database from
 1 Dec 30, 2021
1 Dec 30, 2021

Time-series-deep-learning - Developing Deep learning LSTM, BiLSTM models, and NeuralProphet for multi-step time-series forecasting of stock price.
Stock Price Prediction Using Deep Learning Univariate Time Series Predicting stock price using historical data of a company using Neural networks for
 7 Nov 27, 2022
7 Nov 27, 2022
Python-Course-V1 - This Repo contains a series of Python Jupyter Notebooks and assignments
This Repo contains a series of Python Jupyter Notebooks and assignments. The assignments are taken from Python Crash Course book by Eric Matthes.
 2 Nov 15, 2022
2 Nov 15, 2022
Codeflare - Scale complex AI/ML pipelines anywhere
Scale complex AI/ML pipelines anywhere CodeFlare is a framework to simplify the integration, scaling and acceleration of complex multi-step analytics
 169 Nov 29, 2022
169 Nov 29, 2022
A project consists in a set of assignements corresponding to a BI process: data integration, construction of an OLAP cube, qurying of a OPLAP cube and reporting.
TennisBusinessIntelligenceProject - A project consists in a set of assignements corresponding to a BI process: data integration, construction of an OLAP cube, qurying of a OPLAP cube and reporting.
 1 Jan 2, 2022
1 Jan 2, 2022

2019 Data Science Bowl
Kaggle-2019-Data-Science-Bowl-Solution - Here i present my solution to kaggle 2019 data science bowl and how i improved it to win a silver medal in that competition.
 1 Jan 1, 2022
1 Jan 1, 2022

Flask app to predict daily radiation from the time series of Solcast from Islamabad, Pakistan
Solar-radiation-ISB-MLOps - Flask app to predict daily radiation from the time series of Solcast from Islamabad, Pakistan.
 1 Dec 31, 2021
1 Dec 31, 2021

Team nan solution repository for FPT data-centric competition. Data augmentation, Albumentation, Mosaic, Visualization, KNN application
FPT_data_centric_competition - Team nan solution repository for FPT data-centric competition. Data augmentation, Albumentation, Mosaic, Visualization, KNN application
 2 Oct 30, 2022
2 Oct 30, 2022
TwitterDataStreaming - Twitter data streaming using APIs
Twitter_Data_Streaming Twitter data streaming using APIs Use Case 1: Streaming r
 1 Jan 21, 2022
1 Jan 21, 2022

SpecAugmentPyTorch - A Pytorch (support batch and channel) implementation of GoogleBrain's SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
SpecAugment An implementation of SpecAugment for Pytorch How to use Install pytorch, version=1.9.0 (new feature (torch.Tensor.take_along_dim) is used
 3 Oct 11, 2022
3 Oct 11, 2022
Resmed_myair_sensors - This is a Home Assistant custom component to pull daily CPAP data from ResMed's myAir service using an undocumented API
resmed_myair This component will set up the following platforms. Platform Description sensor Show info from the myAir API. Installation Using the tool
 17 Dec 29, 2022
17 Dec 29, 2022
Genshin-assets - 👧 Public documentation & static assets for Genshin Impact data.
genshin-assets This repo provides easy access to the Genshin Impact assets, primarily for use on static sites. Sources Genshin Optimizer - An Artifact
 5 Nov 22, 2022
5 Nov 22, 2022
Class-imbalanced / Long-tailed ensemble learning in Python. Modular, flexible, and extensible
IMBENS: Class-imbalanced Ensemble Learning in Python Language: English | Chinese/中文 Links: Documentation | Gallery | PyPI | Changelog | Source | Downl
 176 Jan 4, 2023
176 Jan 4, 2023

The codebase for Data-driven general-purpose voice activity detection.
Data driven GPVAD Repository for the work in TASLP 2021 Voice activity detection in the wild: A data-driven approach using teacher-student training. S
 75 Nov 27, 2022
75 Nov 27, 2022

WaveFake: A Data Set to Facilitate Audio DeepFake Detection
WaveFake: A Data Set to Facilitate Audio DeepFake Detection This is the code repository for our NeurIPS 2021 (Track on Datasets and Benchmarks) paper
 27 Dec 22, 2022
27 Dec 22, 2022

If Google News had a Python library
pygooglenews If Google News had a Python library Created by Artem from newscatcherapi.com but you do not need anything from us or from anyone else to
 1.1k Jan 8, 2023
1.1k Jan 8, 2023
Pytorch implementation of paper Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data
Pytorch implementation of paper Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data
 31 Nov 20, 2022
31 Nov 20, 2022
Code used for the results in the paper "ClassMix: Segmentation-Based Data Augmentation for Semi-Supervised Learning"
Code used for the results in the paper "ClassMix: Segmentation-Based Data Augmentation for Semi-Supervised Learning" Getting started Prerequisites CUD
 70 Dec 2, 2022
70 Dec 2, 2022
Reduce end to end training time from days to hours (or hours to minutes), and energy requirements/costs by an order of magnitude using coresets and data selection.
COResets and Data Subset selection Reduce end to end training time from days to hours (or hours to minutes), and energy requirements/costs by an order
 244 Jan 9, 2023
244 Jan 9, 2023
[CVPR'2020] DeepDeform: Learning Non-rigid RGB-D Reconstruction with Semi-supervised Data
DeepDeform (CVPR'2020) DeepDeform is an RGB-D video dataset containing over 390,000 RGB-D frames in 400 videos, with 5,533 optical and scene flow imag
 165 Jan 9, 2023
165 Jan 9, 2023
Code that accompanies the paper Semi-supervised Deep Kernel Learning: Regression with Unlabeled Data by Minimizing Predictive Variance
Semi-supervised Deep Kernel Learning This is the code that accompanies the paper Semi-supervised Deep Kernel Learning: Regression with Unlabeled Data
 58 Oct 26, 2022
58 Oct 26, 2022

CCCL: Contrastive Cascade Graph Learning.
CCGL: Contrastive Cascade Graph Learning This repo provides a reference implementation of Contrastive Cascade Graph Learning (CCGL) framework as descr
 19 Dec 5, 2022
19 Dec 5, 2022
This is a scalable system that reads messages from public Telegram channels using Telethon and stores the data in a PostgreSQL database.
This is a scalable system that reads messages from public Telegram channels using Telethon and stores the data in a PostgreSQL database. Its original intention is to monitor cryptocurrency related channels, but it can be configured to read any Telegram data that is accessible through the API.
 3 Jun 7, 2022
3 Jun 7, 2022

Serverless function for replicating weather underground data to an influxDB database
Weather Underground → Influx DB 🌤 Serverless function for replicating Weather U
 1 Dec 30, 2021
1 Dec 30, 2021

Generate and Visualize Data Lineage from query history
Tokern Lineage Engine Tokern Lineage Engine is fast and easy to use application to collect, visualize and analyze column-level data lineage in databas
 237 Dec 29, 2022
237 Dec 29, 2022

Analysing poker data from home games with friends
Poker Game Analysis Analysing poker data from home games with friends. Not a lot of data is collected, so this project is primarily focussed on descri
 1 Oct 15, 2022
1 Oct 15, 2022
eXPeditious Data Transfer
xpdt: eXPeditious Data Transfer About xpdt is (yet another) language for defining data-types and generating code for serializing and deserializing the
 3 Jan 6, 2022
3 Jan 6, 2022
Numerical Methods with Python, Numpy and Matplotlib
Numerical Bric-a-Brac Collections of numerical techniques with Python and standard computational packages (Numpy, SciPy, Numba, Matplotlib ...). Diffe
 10 Dec 20, 2021
10 Dec 20, 2021
This Jupyter notebook shows one way to implement a simple first-order low-pass filter on sampled data in discrete time.
How to Implement a First-Order Low-Pass Filter in Discrete Time We often teach or learn about filters in continuous time, but then need to implement t
 4 Aug 24, 2022
4 Aug 24, 2022
A module to get data about anime characters, news, info, lyrics and more.
Animec A module to get data about anime characters, news, info, lyrics and more. The module scrapes myanimelist to parse requested data. If you wish t
 31 Aug 31, 2022
31 Aug 31, 2022

A library to generate synthetic time series data by easy-to-use factors and generator
timeseries-generator This repository consists of a python packages that generates synthetic time series dataset in a generic way (under /timeseries_ge
 87 Dec 20, 2022
87 Dec 20, 2022
Data reduction pipeline for KOALA on the AAT.
KOALA KOALA, the Kilofibre Optical AAT Lenslet Array, is a wide-field, high efficiency, integral field unit used by the AAOmega spectrograph on the 3.
 4 Sep 26, 2022
4 Sep 26, 2022
A Python reference implementation of the CF data model
cfdm A Python reference implementation of the CF data model. References Compliance with FAIR principles Documentation https://ncas-cms.github.io/cfdm
 25 Dec 13, 2022
25 Dec 13, 2022
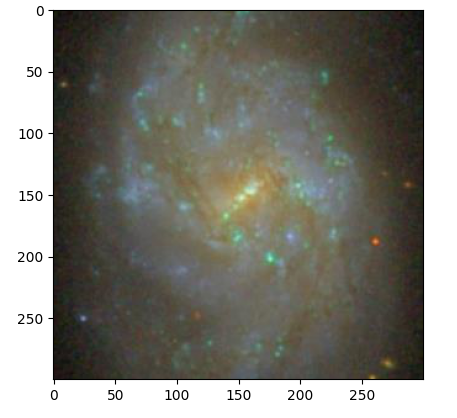
Retrieve and analysis data from SDSS (Sloan Digital Sky Survey)
Author: Behrouz Safari License: MIT sdss A python package for retrieving and analysing data from SDSS (Sloan Digital Sky Survey) Installation Install
 3 Oct 28, 2022
3 Oct 28, 2022
Datapane is the easiest way to create data science reports from Python.
Datapane Teams | Documentation | API Docs | Changelog | Twitter | Blog Share interactive plots and data in 3 lines of Python. Datapane is a Python lib
 744 Jan 6, 2023
744 Jan 6, 2023

Python Practicum - prepare for your Data Science interview or get a refresher.
Python-Practicum Python Practicum - prepare for your Data Science interview or get a refresher. Data Data visualization using data on births from the
 1 Jul 27, 2021
1 Jul 27, 2021
Yahoo! Finance next gen python 3 / pandas market data downloader
Yahoo! Finance-ng python3 / pandas market data downloader Ever since Yahoo! finance decommissioned their historical data API, many programs that relie
 7 Dec 9, 2022
7 Dec 9, 2022
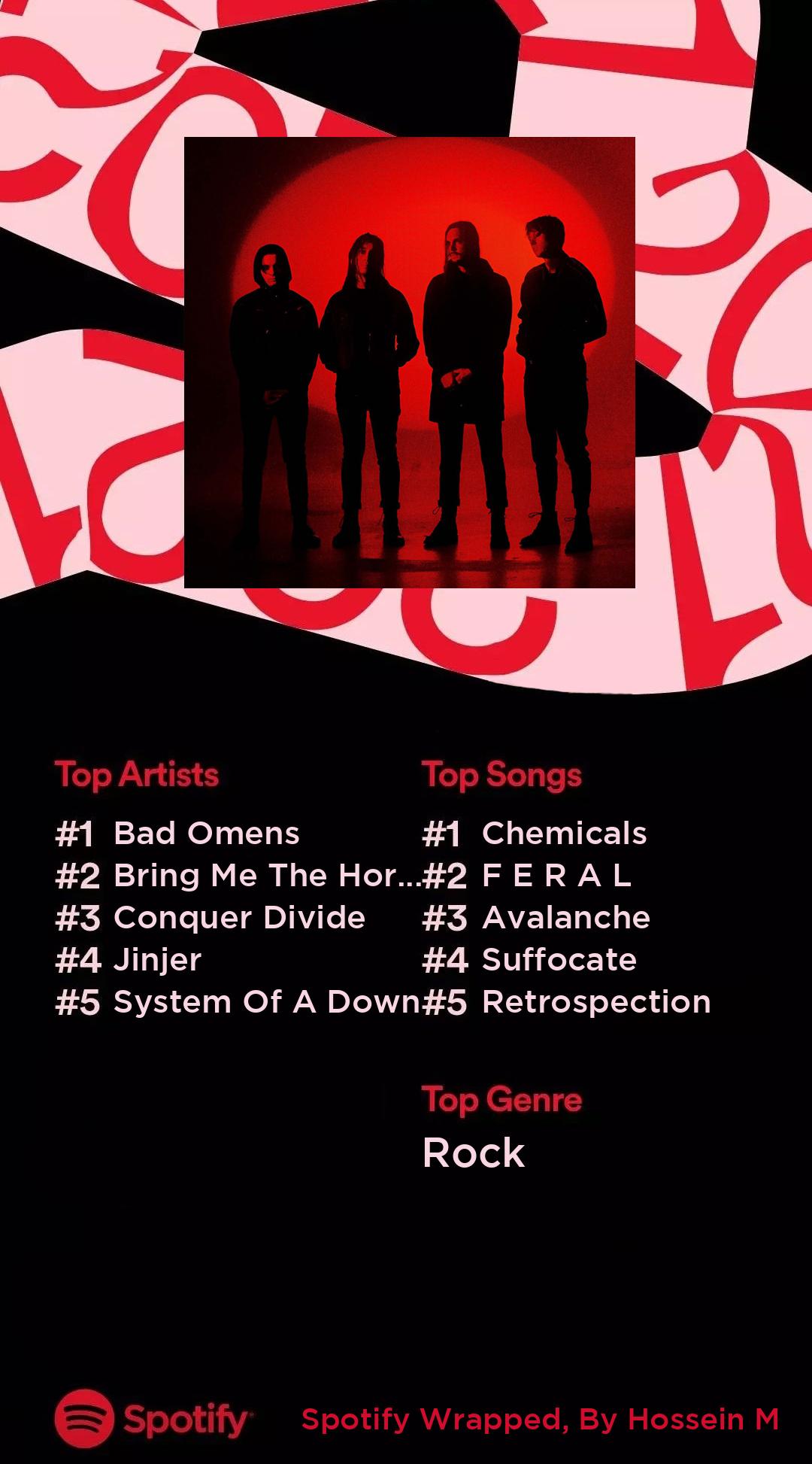
A project in order to analyze user's favorite musics, artists and genre
Spotify-Wrapped This is a project about Spotify Wrapped (which is an extra option for premium accounts, but you don't need to be premium here) This pr
 19 Jan 4, 2023
19 Jan 4, 2023
Quickly download, clean up, and install public datasets into a database management system
Finding data is one thing. Getting it ready for analysis is another. Acquiring, cleaning, standardizing and importing publicly available data is time
 274 Jan 4, 2023
274 Jan 4, 2023

Manage your XYZ Hub or HERE Data Hub spaces from Python.
XYZ Spaces for Python Manage your XYZ Hub or HERE Data Hub spaces and Interactive Map Layer from Python. FEATURED IN: Online Python Machine Learning C
 30 Oct 18, 2022
30 Oct 18, 2022

This is a student data management application developed in Python and TKinter. It utilizes the TKinter pillow library to include images to buttons. I've separated TKinter elements into their own individual classes. The user can change the smilely face color for each button individually or by entire row.
Smiley Face Cube Display Table of Contents Project Description Getting Started Prerequisites Installation & Deployment Additional Documentation Projec
 0 Aug 4, 2021
0 Aug 4, 2021
Python wrapper for Synoptic Data API. Retrieve data from thousands of mesonet stations and networks. Returns JSON from Synoptic as Pandas DataFrame
☁ Synoptic API for Python (unofficial) The Synoptic Mesonet API (formerly MesoWest) gives you access to real-time and historical surface-based weather
 23 Jan 6, 2023
23 Jan 6, 2023

Visualize data of Vietnam's regions with interactive maps.
Plotting Vietnam Development Map This is my personal project that I use plotly to analyse and visualize data of Vietnam's regions with interactive map
 1 Jun 26, 2022
1 Jun 26, 2022
Updates redisearch instance with igdb data used for kimosabe
igdb-pdt Update RediSearch with IGDB games data in the following Format: { "game_slug": { "name": "game_name", "cover": "igdb_coverart_url",
 0 Jul 30, 2021
0 Jul 30, 2021
3D extension built off of shapely to make working with geospatial/trajectory data easier in python.
PyGeoShape 3D extension to shapely and pyproj to make working with geospatial/trajectory data easier in python. Getting Started Installation pip The e
 5 Dec 27, 2022
5 Dec 27, 2022
Code for "Intra-hour Photovoltaic Generation Forecasting based on Multi-source Data and Deep Learning Methods."
pv_predict_unet-lstm Code for "Intra-hour Photovoltaic Generation Forecasting based on Multi-source Data and Deep Learning Methods." IEEE Transactions
 8 Oct 8, 2022
8 Oct 8, 2022
A collection of resources, problems, explanations and concepts that are/were important during my Data Science journey
Data Science Gurukul List of resources, interview questions, concepts I use for my Data Science work. Topics: Basics of Programming with Python + Unde
 10 Oct 25, 2022
10 Oct 25, 2022
Aggregate real-time market data from cryptocurrency exchanges, filter, sort and format as TradingView watchlists.
tvbuddy Aggregate real-time market data from cryptocurrency exchanges, filter, sort and format as TradingView watchlists. Developed and tested on Pyth
 2 Jan 7, 2022
2 Jan 7, 2022
Python wrapper for Xeno-canto API 2.0. Enables downloading bird data with one command line
Python wrapper for Xeno-canto API 2.0. Enables downloading bird data with one command line. Supports multithreading
 9 Dec 10, 2022
9 Dec 10, 2022
Code and training data for our ECCV 2016 paper on Unsupervised Learning
Shuffle and Learn (Shuffle Tuple) Created by Ishan Misra Based on the ECCV 2016 Paper - "Shuffle and Learn: Unsupervised Learning using Temporal Order
 44 Dec 8, 2021
44 Dec 8, 2021
Visualization of the World Religion Data dataset by Correlates of War Project.
World Religion Data Visualization Visualization of the World Religion Data dataset by Correlates of War Project. Mostly personal project to famirializ
 1 Oct 15, 2022
1 Oct 15, 2022

Cleaning and analysing aggregated UK political polling data.
Analysing aggregated UK polling data The tweet collection & storage pipeline used in email-service is used to also collect tweets from @britainelects.
 0 Dec 22, 2021
0 Dec 22, 2021
MeerKAT radio telescope simulation package. Built to simulate multibeam antenna data.
MeerKATgen MeerKAT radio telescope simulation package. Designed with performance in mind and utilizes Just in time compile (JIT) and XLA backed vectro
 6 Jan 23, 2022
6 Jan 23, 2022
Simple, minimal conversion of Bus Open Data Service SIRI-VM data to JSON
Simple, minimal conversion of Bus Open Data Service SIRI-VM data to JSON
 0 Jan 22, 2022
0 Jan 22, 2022

Official repository of the paper Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
Official repository of the paper Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
 689 Dec 25, 2022
689 Dec 25, 2022
Data-FX is an addon for Blender (2.9) that allows for the visualization of data with different charts
Data-FX Data-FX is an addon for Blender (2.9) that allows for the visualization of data with different charts Currently, there are only 2 chart option
 20 Nov 21, 2022
20 Nov 21, 2022
whylogs: A Data and Machine Learning Logging Standard
whylogs: A Data and Machine Learning Logging Standard whylogs is an open source standard for data and ML logging whylogs logging agent is the easiest
 2k Jan 6, 2023
2k Jan 6, 2023

TE-dependent analysis (tedana) is a Python library for denoising multi-echo functional magnetic resonance imaging (fMRI) data
tedana: TE Dependent ANAlysis TE-dependent analysis (tedana) is a Python library for denoising multi-echo functional magnetic resonance imaging (fMRI)
 136 Dec 22, 2022
136 Dec 22, 2022
Mycodo is open source software for the Raspberry Pi that couples inputs and outputs in interesting ways to sense and manipulate the environment.
Mycodo Environmental Regulation System Latest version: 8.12.9 Mycodo is open source software for the Raspberry Pi that couples inputs and outputs in i
 2.3k Dec 29, 2022
2.3k Dec 29, 2022

Time series visualizer is a flexible extension that provides filling world map by country from real data.
Time-series-visualizer Time series visualizer is a flexible extension that provides filling world map by country from csv or json file. You can know d
 3 Jul 9, 2021
3 Jul 9, 2021

ETL pipeline on movie data using Python and postgreSQL
Movies-ETL ETL pipeline on movie data using Python and postgreSQL Overview This project consisted on a automated Extraction, Transformation and Load p
 0 Jul 7, 2021
0 Jul 7, 2021
MetaMove is written in Python3 and aims at easing batch renaming operations based on file meta data.
MetaMove MetaMove is written in Python3 and aims at easing batch renaming operations based on file meta data. MetaMove abuses eval combined with f-str
 2 Dec 28, 2021
2 Dec 28, 2021
An extensive UI tool built using new data scraped from BBC News
BBC-News-Analyzer An extensive UI tool built using new data scraped from BBC New
 1 Dec 31, 2021
1 Dec 31, 2021

Micro Data Lake based on Docker Compose
Micro Data Lake based on Docker Compose This is the implementation of a Minimum Data Lake
 15 Jan 7, 2023
15 Jan 7, 2023
Data portal client and server for NMDC.
NMDC Server and Client Portal Getting started with Docker install ldc install submodules via git submodule update --init --recursive In order to popul
 7 Dec 14, 2022
7 Dec 14, 2022
A simple web to serve data table. It is built with Vuetify, Vue, FastApi.
simple-report-data-table-vuetify A simple web to serve data table. It is built with Vuetify, Vue, FastApi. The main features: RBAC with casbin simple
 11 Dec 22, 2022
11 Dec 22, 2022
Tools, guides, and resources for blockchain analysts to interface with data on the Ergo platform.
Ergo Intelligence Objective Provide a suite of easy-to-use toolkits, guides, and resources for blockchain analysts and data scientists to quickly unde
 5 Mar 15, 2022
5 Mar 15, 2022
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size.
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size. The hub data layout enables rapid transformations and streaming of data while training models at scale. Hub is used by Google, Waymo, Red Cross, Oxford University, and Omdena.
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
Slight modification to one of the Facebook Salina examples, to test the A2C algorithm on financial series.
Facebook Salina - Gym_AnyTrading Slight modification of Facebook Salina Reinforcement Learning - A2C GPU example for financial series. The gym FOREX d
 5 Mar 14, 2022
5 Mar 14, 2022
Utilize data analytics skills to solve real-world business problems using Humana’s big data
Humana-Mays-2021-HealthCare-Analytics-Case-Competition- The goal of the project is to utilize data analytics skills to solve real-world business probl
 1 Dec 27, 2021
1 Dec 27, 2021
Data Model built using Logistic Regression Algorithm on Python.
Logistic-Regression Problem Statement: Your client is a retail banking institution. Term deposits are a major source of income for a bank. A term depo
 0 Dec 25, 2021
0 Dec 25, 2021
A simply dashboard to view commodities position data based on CFTC reports
commodities-dashboard A simply dashboard to view commodities position data based on CFTC reports This is a python project using Dash and plotly to con
 71 Dec 19, 2022
71 Dec 19, 2022
A Python package to request and process seismic waveform data from Hi-net.
HinetPy is a Python package to simplify tedious data request, download and format conversion tasks related to NIED Hi-net. NIED Hi-net | Source Code |
 65 Dec 9, 2022
65 Dec 9, 2022
🍋 A Python package to process food
Pyfood is a simple Python package to process food, in different languages. Pyfood's ambition is to be the go-to library to deal with food, recipes, on
 8 Apr 4, 2022
8 Apr 4, 2022

Sequence lineage information extracted from RKI sequence data repo
Pango lineage information for German SARS-CoV-2 sequences This repository contains a join of the metadata and pango lineage tables of all German SARS-
 24 Oct 26, 2022
24 Oct 26, 2022
Python Steganography data hiding in image
Python-Steganography Python Steganography data hiding in image data encryption and decryption im here you have to import stepic module 1.open CMD 2.ty
 10 Jul 13, 2022
10 Jul 13, 2022
Pandas and Spark DataFrame comparison for humans
DataComPy DataComPy is a package to compare two Pandas DataFrames. Originally started to be something of a replacement for SAS's PROC COMPARE for Pand
 259 Dec 24, 2022
259 Dec 24, 2022

BisQue is a web-based platform designed to provide researchers with organizational and quantitative analysis tools for 5D image data. Users can extend BisQue by implementing containerized ML workflows.
Overview BisQue is a web-based platform specifically designed to provide researchers with organizational and quantitative analysis tools for up to 5D
 26 Nov 29, 2022
26 Nov 29, 2022
Python package to transfer data in a fast, reliable, and packetized form.
pySerialTransfer Python package to transfer data in a fast, reliable, and packetized form.
 101 Dec 7, 2022
101 Dec 7, 2022
Run python scripts and pass data between multiple python and node processes using this npm module
Run python scripts and pass data between multiple python and node processes using this npm module. process-communication has a event based architecture for interacting with python data and errors inside nodejs.
 2 Aug 6, 2021
2 Aug 6, 2021
Python package for analyzing behavioral data for Brain Observatory: Visual Behavior
Allen Institute Visual Behavior Analysis package This repository contains code for analyzing behavioral data from the Allen Brain Observatory: Visual
 16 Nov 4, 2022
16 Nov 4, 2022
Brownant is a web data extracting framework.
Brownant Brownant is a lightweight web data extracting framework. Who uses it? At the moment, dongxi.douban.com (a.k.a. Douban Dongxi) uses Brownant i
 157 Jan 6, 2022
157 Jan 6, 2022
Neptune client library - integrate your Python scripts with Neptune
Lightweight experiment tracking tool for AI/ML individuals and teams. Fits any workflow. Neptune is a lightweight experiment logging/tracking tool tha
 353 Jan 4, 2023
353 Jan 4, 2023
PYGA: Python Google Analytics (ga.js) - Data Collection API
PYGA: Python Google Analytics - Data Collection API pyga is an implementation of Google Analytics (ga.js) in Python; so that it can be used at server
 136 Sep 19, 2022
136 Sep 19, 2022
A Lightweight NLP Data Loader for All Deep Learning Frameworks in Python
LineFlow: Framework-Agnostic NLP Data Loader in Python LineFlow is a simple text dataset loader for NLP deep learning tasks. LineFlow was designed to
 177 Jan 4, 2023
177 Jan 4, 2023
Object-data mapper and advanced query manager for non relational databases
Object data mapper and advanced query manager for non relational databases. The data is owned by different, configurable back-end databases and it is
 121 Aug 11, 2022
121 Aug 11, 2022
A Pytorch Implementation of Source Data-free Domain Adaptation for a Faster R-CNN
A Pytorch Implementation of Source Data-free Domain Adaptation for a Faster R-CNN Please follow Faster R-CNN and DAF to complete the environment confi
 2 Jan 12, 2022
2 Jan 12, 2022