455 Repositories
Python single-speaker-tts Libraries

G-NIA model from "Single Node Injection Attack against Graph Neural Networks" (CIKM 2021)
Single Node Injection Attack against Graph Neural Networks This repository is our Pytorch implementation of our paper: Single Node Injection Attack ag
 18 Nov 21, 2022
18 Nov 21, 2022

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022

"3D Human Texture Estimation from a Single Image with Transformers", ICCV 2021
Texformer: 3D Human Texture Estimation from a Single Image with Transformers This is the official implementation of "3D Human Texture Estimation from
 193 Dec 5, 2022
193 Dec 5, 2022
Implementation of fast algorithms for Maximum Spanning Tree (MST) parsing that includes fast ArcMax+Reweighting+Tarjan algorithm for single-root dependency parsing.
Fast MST Algorithm Implementation of fast algorithms for (Maximum Spanning Tree) MST parsing that includes fast ArcMax+Reweighting+Tarjan algorithm fo
 11 Oct 14, 2022
11 Oct 14, 2022
No-dependency, single file NNTP server library for developing modern, rfc3977-compliant (bridge) NNTP servers.
nntpserver.py No-dependency, single file NNTP server library for developing modern, rfc3977-compliant (bridge) NNTP servers for python =3.7. Develope
 44 Nov 14, 2022
44 Nov 14, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Tool to create 3D printable terrain with integrated path/road part files (Single material 3d printer)
BACKGROUND This has been an ongoing project of mine for a few months now. I run trails a lot and original the goal was to create a function to combine
 9 Apr 26, 2022
9 Apr 26, 2022
![[CVPR 2021] Official PyTorch Implementation for](https://github.com/codeslake/IFAN/raw/main/assets/IFAN_network.jpg)
[CVPR 2021] Official PyTorch Implementation for "Iterative Filter Adaptive Network for Single Image Defocus Deblurring"
IFAN: Iterative Filter Adaptive Network for Single Image Defocus Deblurring Checkout for the demo (GUI/Google Colab)! The GUI version might occasional
 173 Dec 30, 2022
173 Dec 30, 2022
Finds price floor for every single attribute in a given collection
Solana Solanart Scanner Enjoy the Free Code Steps to run Download VS Code
 19 Oct 20, 2022
19 Oct 20, 2022
forward several ports into a single port
port forwarding Multi-Input-Single-Output forward several ports into a single one this tool forwards packets from several ports into one single port.
 3 Sep 11, 2021
3 Sep 11, 2021

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 54 Aug 30, 2021
54 Aug 30, 2021
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
 24 Sep 7, 2022
24 Sep 7, 2022
Build reusable components in Django without writing a single line of Python.
Build reusable components in Django without writing a single line of Python. {% #quote %} {% quote_photo src="/project-hail-mary.jpg" %} {% #quot
 277 Jan 2, 2023
277 Jan 2, 2023
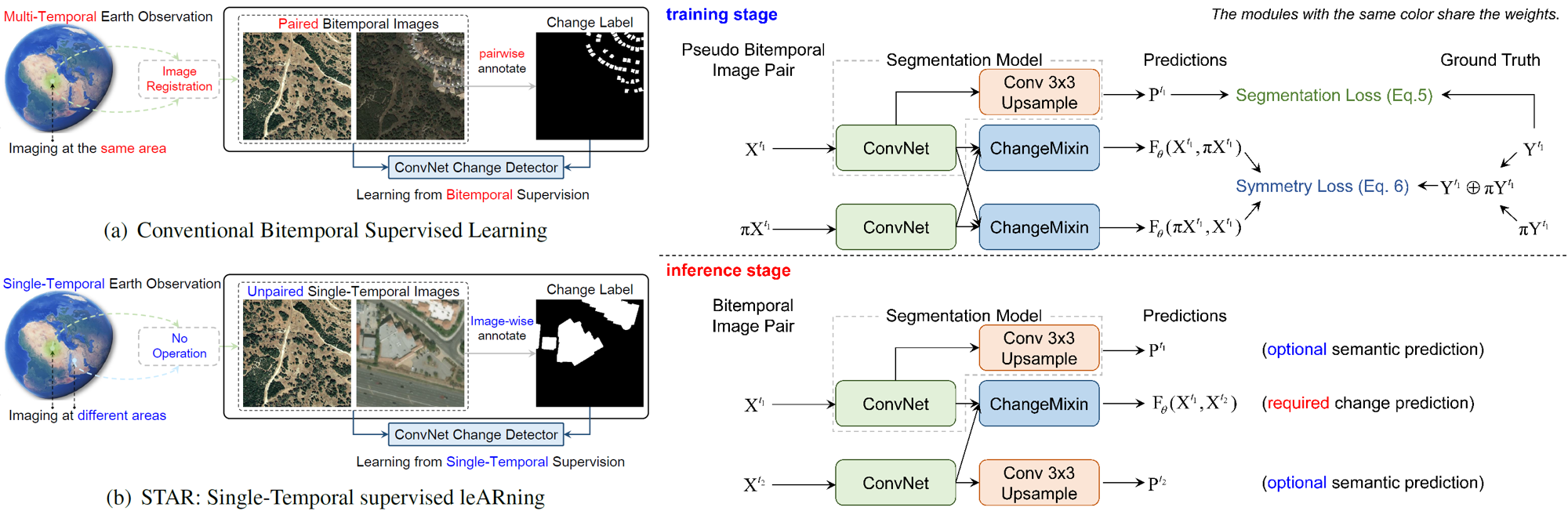
Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery (ICCV 2021)
Change is Everywhere Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery by Zhuo Zheng, Ailong Ma, Liangpei Zhang and Yanfei
 125 Dec 13, 2022
125 Dec 13, 2022
Make your AirPlay devices as TTS speakers
Apple AirPlayer Home Assistant integration component, make your AirPlay devices as TTS speakers. Before Use 2021.6.X or earlier Apple Airplayer compon
 117 Dec 15, 2022
117 Dec 15, 2022

pytorch implementation for Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network arXiv:1609.04802
PyTorch SRResNet Implementation of Paper: "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network"(https://arxiv.org/abs
 436 Jan 9, 2023
436 Jan 9, 2023

The official implementation of ICCV paper "Box-Aware Feature Enhancement for Single Object Tracking on Point Clouds".
Box-Aware Tracker (BAT) Pytorch-Lightning implementation of the Box-Aware Tracker. Box-Aware Feature Enhancement for Single Object Tracking on Point C
 5 Mar 26, 2022
5 Mar 26, 2022
Look Who’s Talking: Active Speaker Detection in the Wild
Look Who's Talking: Active Speaker Detection in the Wild Dependencies pip install -r requirements.txt In addition to the Python dependencies, ffmpeg
 60 Dec 8, 2022
60 Dec 8, 2022

PyTorch version of the paper 'Enhanced Deep Residual Networks for Single Image Super-Resolution' (CVPRW 2017)
About PyTorch 1.2.0 Now the master branch supports PyTorch 1.2.0 by default. Due to the serious version problem (especially torch.utils.data.dataloade
 2.1k Jan 1, 2023
2.1k Jan 1, 2023

Let Xiao Ai speakers control third-party devices
A stupid way to extend miot/xiaoai. Demo for Panasonic Bath Bully FV-RB20VL1 逆向 Panasonic Smart China,获得控制浴霸的请求信息(HTTP 请求),详见 apps/panasonic.py; 2. 通过
 14 Jul 7, 2022
14 Jul 7, 2022

Official Repository for the ICCV 2021 paper "PixelSynth: Generating a 3D-Consistent Experience from a Single Image"
PixelSynth: Generating a 3D-Consistent Experience from a Single Image (ICCV 2021) Chris Rockwell, David F. Fouhey, and Justin Johnson [Project Website
 95 Nov 22, 2022
95 Nov 22, 2022
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 169 Jan 5, 2023
169 Jan 5, 2023
This code is an implementation for Singing TTS.
MLP Singer This code is an implementation for Singing TTS. The algorithm is based on the following papers: Tae, J., Kim, H., & Lee, Y. (2021). MLP Sin
 22 Dec 23, 2022
22 Dec 23, 2022

Practical Single-Image Super-Resolution Using Look-Up Table
Practical Single-Image Super-Resolution Using Look-Up Table [Paper] Dependency Python 3.6 PyTorch glob numpy pillow tqdm tensorboardx 1. Training deep
 116 Dec 23, 2022
116 Dec 23, 2022

We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering Papers with code | Paper Nikola Zubić Pietro Lio University
 213 Dec 27, 2022
213 Dec 27, 2022

Contrastive Learning for Compact Single Image Dehazing, CVPR2021
AECR-Net Contrastive Learning for Compact Single Image Dehazing, CVPR2021. Official Pytorch based implementation. Paper arxiv Pytorch Version TODO: mo
 253 Jan 1, 2023
253 Jan 1, 2023
Large scale embeddings on a single machine.
Marius Marius is a system under active development for training embeddings for large-scale graphs on a single machine. Training on large scale graphs
 107 Jan 3, 2023
107 Jan 3, 2023

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
 47 Dec 18, 2022
47 Dec 18, 2022
This app makes it extremely easy to build Django powered SPA's (Single Page App) or Mobile apps exposing all registration and authentication related functionality as CBV's (Class Base View) and REST (JSON)
Welcome to django-rest-auth Repository is unmaintained at the moment (on pause). More info can be found on this issue page: https://github.com/Tivix/d
 2.4k Jan 3, 2023
2.4k Jan 3, 2023
Discord ToolBox is a discord bot developed by DJD320 created for the purpose of having some convenient tools in the form of a single bot.
Discord ToolBox Discord ToolBox is a discord bot developed by DJD320 created for the purpose of having some convenient tools in the form of a single b
 3 Aug 7, 2021
3 Aug 7, 2021
neural network based speaker embedder
Content What is deepaudio-speaker? Installation Get Started Model Architecture How to contribute to deepaudio-speaker? Acknowledge What is deepaudio-s
 20 Dec 29, 2022
20 Dec 29, 2022

Implementation of the paper: "SinGAN: Learning a Generative Model from a Single Natural Image"
SinGAN This is an unofficial implementation of SinGAN from someone who's been sitting right next to SinGAN's creator for almost five years. Please ref
 35 Nov 10, 2022
35 Nov 10, 2022

Code for generating a single image pretraining dataset
Single Image Pretraining of Visual Representations As shown in the paper A critical analysis of self-supervision, or what we can learn from a single i
 12 Dec 19, 2022
12 Dec 19, 2022

Minimal Ethereum fee data viewer for the terminal, contained in a single python script.
Minimal Ethereum fee data viewer for the terminal, contained in a single python script. Connects to your node and displays some metrics in real-time.
 48 Dec 5, 2022
48 Dec 5, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022

SymmetryNet: Learning to Predict Reflectional and Rotational Symmetries of 3D Shapes from Single-View RGB-D Images
SymmetryNet SymmetryNet: Learning to Predict Reflectional and Rotational Symmetries of 3D Shapes from Single-View RGB-D Images ACM Transactions on Gra
 26 Dec 5, 2022
26 Dec 5, 2022

Code associated with the paper "Deep Optics for Single-shot High-dynamic-range Imaging"
Deep Optics for Single-shot High-dynamic-range Imaging Code associated with the paper "Deep Optics for Single-shot High-dynamic-range Imaging" CVPR, 2
 40 Dec 12, 2022
40 Dec 12, 2022
Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
170 Jan 4, 2023

Chinese real time voice cloning (VC) and Chinese text to speech (TTS).
Chinese real time voice cloning (VC) and Chinese text to speech (TTS). 好用的中文语音克隆兼中文语音合成系统,包含语音编码器、语音合成器、声码器和可视化模块。
 6 Nov 8, 2022
6 Nov 8, 2022

A PyTorch Implementation of Single Shot Scale-invariant Face Detector.
S³FD: Single Shot Scale-invariant Face Detector A PyTorch Implementation of Single Shot Scale-invariant Face Detector. Eval python wider_eval_pytorch.
 235 Jan 7, 2023
235 Jan 7, 2023
Code for PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning
PackNet: https://arxiv.org/abs/1711.05769 Pretrained models are available here: https://uofi.box.com/s/zap2p03tnst9dfisad4u0sfupc0y1fxt Datasets in Py
 216 Jan 5, 2023
216 Jan 5, 2023

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
Easily turn single threaded command line applications into a fast, multi-threaded application with CIDR and glob support.
Easily turn single threaded command line applications into a fast, multi-threaded application with CIDR and glob support.
 1k Jan 7, 2023
1k Jan 7, 2023

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022

Single-Stage 6D Object Pose Estimation, CVPR 2020
Overview This repository contains the code for the paper Single-Stage 6D Object Pose Estimation. Yinlin Hu, Pascal Fua, Wei Wang and Mathieu Salzmann.
 89 Dec 26, 2022
89 Dec 26, 2022

Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single Image to Image Set (CVPRW 2019). A PyTorch implementation.
Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single Image to Image Set —— PyTorch implementation This is an unofficial offici
 833 Dec 28, 2022
833 Dec 28, 2022
Code for Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights
Piggyback: https://arxiv.org/abs/1801.06519 Pretrained masks and backbones are available here: https://uofi.box.com/s/c5kixsvtrghu9yj51yb1oe853ltdfz4q
165 Nov 22, 2022
PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022
PyTorch code for our ECCV 2020 paper "Single Image Super-Resolution via a Holistic Attention Network"
HAN PyTorch code for our ECCV 2020 paper "Single Image Super-Resolution via a Holistic Attention Network" This repository is for HAN introduced in the
 140 Nov 23, 2022
140 Nov 23, 2022

Unofficial Pytorch Implementation of WaveGrad2
WaveGrad 2 — Unofficial PyTorch Implementation WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis Unofficial PyTorch+Lightning Implementati
104 Nov 29, 2022
Pytorch implementation of "Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech"
GradTTS Unofficial Pytorch implementation of "Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech" (arxiv) About this repo This is an unoffic
 103 Dec 23, 2022
103 Dec 23, 2022
Kaggle | 9th place single model solution for TGS Salt Identification Challenge
UNet for segmenting salt deposits from seismic images with PyTorch. General We, tugstugi and xuyuan, have participated in the Kaggle competition TGS S
 276 Dec 20, 2022
276 Dec 20, 2022

PyTorch implementation of Densely Connected Time Delay Neural Network
Densely Connected Time Delay Neural Network PyTorch implementation of Densely Connected Time Delay Neural Network (D-TDNN) in our paper "Densely Conne
 64 Oct 11, 2022
64 Oct 11, 2022
The official implementation of VAENAR-TTS, a VAE based non-autoregressive TTS model.
VAENAR-TTS This repo contains code accompanying the paper "VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis". Sa
 138 Oct 28, 2022
138 Oct 28, 2022
The official implementation of VAENAR-TTS, a VAE based non-autoregressive TTS model.
VAENAR-TTS This repo contains code accompanying the paper "VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis". Sa
138 Oct 28, 2022
Selective Wavelet Attention Learning for Single Image Deraining
SWAL Code for Paper "Selective Wavelet Attention Learning for Single Image Deraining" Prerequisites Python 3 PyTorch Models We provide the models trai
 9 Jun 17, 2022
9 Jun 17, 2022

Command Line Text-To-Speech using Google TTS
cli-tts Thanks to gTTS by @pndurette! This is an interactive command line text-to-speech tool using Google TTS. Just type text and the voice will be p
 3 Nov 11, 2022
3 Nov 11, 2022

Official implementation of FCL-taco2: Fast, Controllable and Lightweight version of Tacotron2 @ ICASSP 2021
FCL-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech synthesis (ICASSP 2021) Paper | Demo Block diagram of FCL-taco2, where the decode
 39 Sep 28, 2022
39 Sep 28, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
 93 Dec 17, 2022
93 Dec 17, 2022

PyTorch Implementation of NCSOFT's FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
FastPitchFormant - PyTorch Implementation PyTorch Implementation of FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis. Qu
63 Jan 2, 2023

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
This is a template for the Non-autoregressive Deep Learning-Based TTS model (in PyTorch).
Non-autoregressive Deep Learning-Based TTS Template This is a template for the Non-autoregressive TTS model. It contains Data Preprocessing Pipeline D
13 Dec 5, 2022

A scanpy extension to analyse single-cell TCR and BCR data.
Scirpy: A Scanpy extension for analyzing single-cell immune-cell receptor sequencing data Scirpy is a scalable python-toolkit to analyse T cell recept
 145 Jan 3, 2023
145 Jan 3, 2023
Use android as mic/speaker for ubuntu
Pulse Audio Control Panel Platforms Requirements sudo apt install ffmpeg pactl (already installed) Download Download the AppImage from release page ch
 19 Dec 1, 2022
19 Dec 1, 2022
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
 38.5k Jan 3, 2023
38.5k Jan 3, 2023
A tool that ensures consistent string quotes in your Python code.
pyquotes Single quotes are superior. And if you disagree, there's an option for this as well. In any case, quotes should be consistent throughout the
 9 Sep 13, 2022
9 Sep 13, 2022
Craxk is a SINGLE AND NON-REPLICABLE Hash that uses data from the hardware where it is executed to form a hash that can only be reproduced by a single machine.
What is Craxk ? Craxk is a UNIQUE AND NON-REPLICABLE Hash that uses data from the hardware where it is executed to form a hash that can only be reprod
 5 Jun 19, 2021
5 Jun 19, 2021

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
59 Dec 6, 2022
Unified tracking framework with a single appearance model
Paper: Do different tracking tasks require different appearance model? [ArXiv] (comming soon) [Project Page] (comming soon) UniTrack is a simple and U
 300 Dec 24, 2022
300 Dec 24, 2022

Learning to Reconstruct 3D Non-Cuboid Room Layout from a Single RGB Image
NonCuboidRoom Paper Learning to Reconstruct 3D Non-Cuboid Room Layout from a Single RGB Image Cheng Yang*, Jia Zheng*, Xili Dai, Rui Tang, Yi Ma, Xiao
 67 Dec 15, 2022
67 Dec 15, 2022

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022

MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera
MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera
 494 Jan 6, 2023
494 Jan 6, 2023
7th place solution of Human Protein Atlas - Single Cell Classification on Kaggle
kaggle-hpa-2021-7th-place-solution Code for 7th place solution of Human Protein Atlas - Single Cell Classification on Kaggle. A description of the met
 8 Jul 9, 2021
8 Jul 9, 2021
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. Training python train.py --c
55 Dec 26, 2022
Official implementation of "SinIR: Efficient General Image Manipulation with Single Image Reconstruction" (ICML 2021)
SinIR (Official Implementation) Requirements To install requirements: pip install -r requirements.txt We used Python 3.7.4 and f-strings which are in
 47 Oct 11, 2022
47 Oct 11, 2022
Code for our paper "Transfer Learning for Sequence Generation: from Single-source to Multi-source" in ACL 2021.
TRICE: a task-agnostic transferring framework for multi-source sequence generation This is the source code of our work Transfer Learning for Sequence
 9 Jun 27, 2022
9 Jun 27, 2022
Generate product descriptions, blogs, ads and more using GPT architecture with a single request to TextCortex API a.k.a Hemingwai
TextCortex - HemingwAI Generate product descriptions, blogs, ads and more using GPT architecture with a single request to TextCortex API a.k.a Hemingw
 27 Nov 28, 2022
27 Nov 28, 2022
Build tensorflow keras model pipelines in a single line of code. Created by Ram Seshadri. Collaborators welcome. Permission granted upon request.
deep_autoviml Build keras pipelines and models in a single line of code! Table of Contents Motivation How it works Technology Install Usage API Image
 102 Dec 17, 2022
102 Dec 17, 2022
Code for weakly supervised segmentation of a single class
SingleClassRL Implementation of weak single object segmentation from paper "Regularized Loss for Weakly Supervised Single Class Semantic Segmentation"
 16 Nov 14, 2022
16 Nov 14, 2022

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
140 Dec 21, 2022
Aerial Single-View Depth Completion with Image-Guided Uncertainty Estimation (RA-L/ICRA 2020)
Aerial Depth Completion This work is described in the letter "Aerial Single-View Depth Completion with Image-Guided Uncertainty Estimation", by Lucas
 70 Dec 22, 2022
70 Dec 22, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
31 Dec 8, 2022
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 6, 2023

Shortcut-Maker - It is a tool that can be set to run any tool with a single command
Shortcut-Maker It is a tool that can be set to run any tool with a single command Coded by Dave Smith(Owner of Sl Cyber Warriors) Command list 👇 pkg
 10 Sep 14, 2022
10 Sep 14, 2022
Simple software that can send WhatsApp message to a single or multiple users (including unsaved number**)
wp-automation Info: this is a simple automation software that sends WhatsApp message to single or multiple users. Key feature: -Sends message to multi
 3 Jan 31, 2022
3 Jan 31, 2022

Pytorch Implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension)
DiffSinger - PyTorch Implementation PyTorch implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension). Status
152 Jan 2, 2023
Interpretation of T cell states using reference single-cell atlases
Interpretation of T cell states using reference single-cell atlases ProjecTILs is a computational method to project scRNA-seq data into reference sing
 139 Jan 3, 2023
139 Jan 3, 2023

Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
 12.6k Jan 9, 2023
12.6k Jan 9, 2023
A single Python file with some tools for visualizing machine learning in the terminal.
Machine Learning Visualization Tools A single Python file with some tools for visualizing machine learning in the terminal. This demo is composed of t
 35 Dec 29, 2022
35 Dec 29, 2022

MoveNet Single Pose on DepthAI
MoveNet Single Pose tracking on DepthAI Running Google MoveNet Single Pose models on DepthAI hardware (OAK-1, OAK-D,...). A convolutional neural netwo
 64 Dec 29, 2022
64 Dec 29, 2022

MoveNet Single Pose on OpenVINO
MoveNet Single Pose tracking on OpenVINO Running Google MoveNet Single Pose models on OpenVINO. A convolutional neural network model that runs on RGB
35 Nov 11, 2022

ERISHA is a mulitilingual multispeaker expressive speech synthesis framework. It can transfer the expressivity to the speaker's voice for which no expressive speech corpus is available.
ERISHA: Multilingual Multispeaker Expressive Text-to-Speech Library ERISHA is a multilingual multispeaker expressive speech synthesis framework. It ca
 43 Nov 27, 2022
43 Nov 27, 2022

Create single line SVG illustrations from your pictures
Create single line SVG illustrations from your pictures
 326 May 23, 2021
326 May 23, 2021
Create single line SVG illustrations from your pictures
Create single line SVG illustrations from your pictures
686 Dec 26, 2022

Learning to Reconstruct 3D Manhattan Wireframes from a Single Image
Learning to Reconstruct 3D Manhattan Wireframes From a Single Image This repository contains the PyTorch implementation of the paper: Yichao Zhou, Hao
 50 Dec 27, 2022
50 Dec 27, 2022

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
170 Dec 27, 2022
A fast Text-to-Speech (TTS) model. Work well for English, Mandarin/Chinese, Japanese, Korean, Russian and Tibetan (so far). 快速语音合成模型,适用于英语、普通话/中文、日语、韩语、俄语和藏语(当前已测试)。
简体中文 | English 并行语音合成 [TOC] 新进展 2021/04/20 合并 wavegan 分支到 main 主分支,删除 wavegan 分支! 2021/04/13 创建 encoder 分支用于开发语音风格迁移模块! 2021/04/13 softdtw 分支 支持使用 Sof
 161 Dec 19, 2022
161 Dec 19, 2022
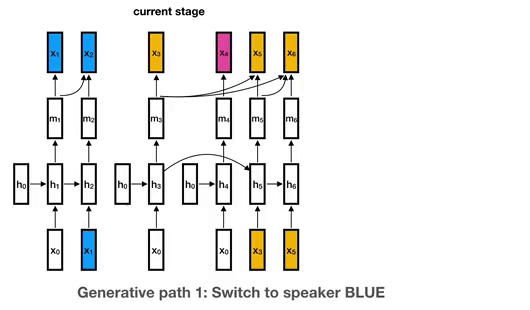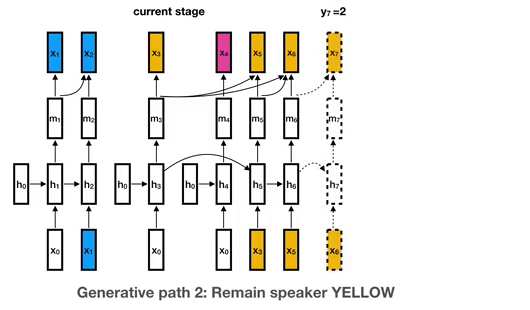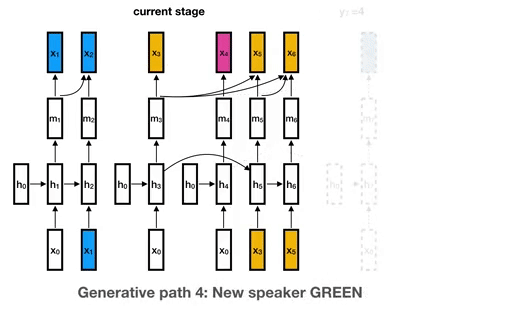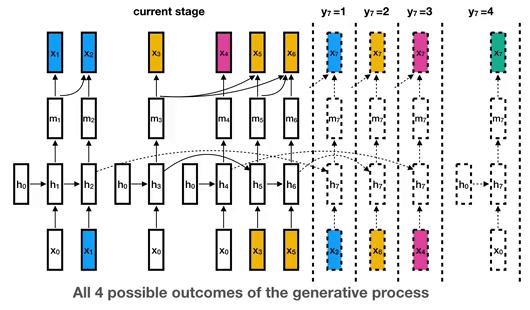
This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization.
UIS-RNN Overview This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm. UIS-RNN solves the problem of s
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
 2.2k Jan 9, 2023
2.2k Jan 9, 2023