282 Repositories
Python sklearn-pipeline Libraries

A PyTorch Implementation of "SINE: Scalable Incomplete Network Embedding" (ICDM 2018).
Scalable Incomplete Network Embedding ⠀⠀ A PyTorch implementation of Scalable Incomplete Network Embedding (ICDM 2018). Abstract Attributed network em
 69 Sep 22, 2022
69 Sep 22, 2022

A PyTorch implementation of "Graph Classification Using Structural Attention" (KDD 2018).
GAM ⠀⠀ A PyTorch implementation of Graph Classification Using Structural Attention (KDD 2018). Abstract Graph classification is a problem with practic
259 Dec 5, 2022

A PyTorch implementation of "SimGNN: A Neural Network Approach to Fast Graph Similarity Computation" (WSDM 2019).
SimGNN ⠀⠀⠀ A PyTorch implementation of SimGNN: A Neural Network Approach to Fast Graph Similarity Computation (WSDM 2019). Abstract Graph similarity s
534 Dec 25, 2022

A PyTorch implementation of "Capsule Graph Neural Network" (ICLR 2019).
CapsGNN ⠀⠀ A PyTorch implementation of Capsule Graph Neural Network (ICLR 2019). Abstract The high-quality node embeddings learned from the Graph Neur
1.2k Jan 2, 2023
MachineLearningStocks is designed to be an intuitive and highly extensible template project applying machine learning to making stock predictions.
Using python and scikit-learn to make stock predictions
 1.3k Jan 3, 2023
1.3k Jan 3, 2023

An AI Assistant More Than a Toolkit
tymon An AI Assistant More Than a Toolkit The reason for creating framework tymon is simple. making AI more like an assistant, helping us to complete
 46 Oct 24, 2022
46 Oct 24, 2022

Distributed DataLoader For Pytorch Based On Ray
Dpex——用户无感知分布式数据预处理组件 一、前言 随着GPU与CPU的算力差距越来越大以及模型训练时的预处理Pipeline变得越来越复杂,CPU部分的数据预处理已经逐渐成为了模型训练的瓶颈所在,这导致单机的GPU配置的提升并不能带来期望的线性加速。预处理性能瓶颈的本质在于每个GPU能够使用的C
 23 Nov 2, 2022
23 Nov 2, 2022

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
TorchX is a library containing standard DSLs for authoring and running PyTorch related components for an E2E production ML pipeline.
TorchX is a library containing standard DSLs for authoring and running PyTorch related components for an E2E production ML pipeline
 193 Dec 22, 2022
193 Dec 22, 2022

This repository contains the code for our fast polygonal building extraction from overhead images pipeline.
Polygonal Building Segmentation by Frame Field Learning We add a frame field output to an image segmentation neural network to improve segmentation qu
 186 Jan 4, 2023
186 Jan 4, 2023
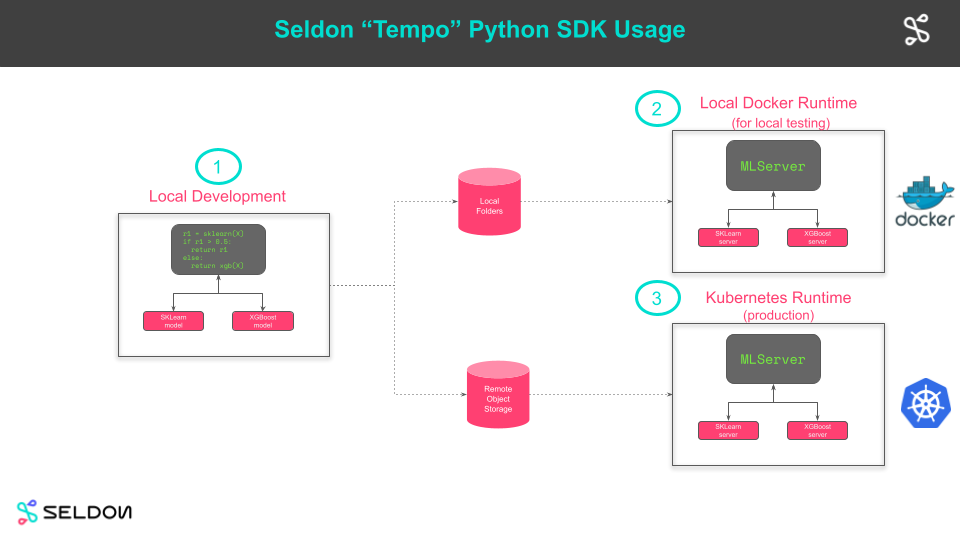
⏳ Tempo: The MLOps Software Development Kit
Tempo provides a unified interface to multiple MLOps projects that enable data scientists to deploy and productionise machine learning systems.
 36 Jun 20, 2021
36 Jun 20, 2021

This repository contains all the source code that is needed for the project : An Efficient Pipeline For Bloom’s Taxonomy Using Natural Language Processing and Deep Learning
Pipeline For NLP with Bloom's Taxonomy Using Improved Question Classification and Question Generation using Deep Learning This repository contains all
 9 Jul 17, 2021
9 Jul 17, 2021
Pipeline for chemical image-to-text competition
BMS-Molecular-Translation Introduction This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got
 7 Sep 20, 2022
7 Sep 20, 2022
Evaluation Pipeline for our ECCV2020: Journey Towards Tiny Perceptual Super-Resolution.
Journey Towards Tiny Perceptual Super-Resolution Test code for our ECCV2020 paper: https://arxiv.org/abs/2007.04356 Our x4 upscaling pre-trained model
 6 Mar 30, 2022
6 Mar 30, 2022

Clairvoyance: a Unified, End-to-End AutoML Pipeline for Medical Time Series
Clairvoyance: A Pipeline Toolkit for Medical Time Series Authors: van der Schaar Lab This repository contains implementations of Clairvoyance: A Pipel
 89 Dec 7, 2022
89 Dec 7, 2022
Guide & Examples to create deeplearning gstreamer plugins and use them in your pipeline
upai-gst-dl-plugins Guide & Examples to create deeplearning gstreamer plugins and use them in your pipeline Introduction Thanks to the work done by @j
 11 Dec 11, 2022
11 Dec 11, 2022

A declarative Kubeflow Management Tool inspired by Terraform
🍭 KRSH is Alpha version, so many bugs can be reported. If you find a bug, please write an Issue and grow the project together! A declarative Kubeflow
 128 Oct 18, 2022
128 Oct 18, 2022

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022
![[CVPR-2021] UnrealPerson: An adaptive pipeline for costless person re-identification](https://github.com/FlyHighest/UnrealPerson/raw/main/imgs/unrealperson.jpg)
[CVPR-2021] UnrealPerson: An adaptive pipeline for costless person re-identification
UnrealPerson: An Adaptive Pipeline for Costless Person Re-identification In our paper (arxiv), we propose a novel pipeline, UnrealPerson, that decreas
 70 Oct 10, 2022
70 Oct 10, 2022

This is a repository for the Duke University Cloud Computing course project on Serveless Data Engineering Pipeline. For this project, I recreated the below pipeline.
AWS Data Engineering Pipeline This is a repository for the Duke University Cloud Computing course project on Serverless Data Engineering Pipeline. For
 15 Jul 28, 2021
15 Jul 28, 2021

Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs (CIKM 2020)
Karate Club is an unsupervised machine learning extension library for NetworkX. Please look at the Documentation, relevant Paper, Promo Video, and Ext
1.8k Dec 31, 2022

Implementation of different ML Algorithms from scratch, written in Python 3.x
Implementation of different ML Algorithms from scratch, written in Python 3.x
 393 Nov 29, 2022
393 Nov 29, 2022

A scikit-learn-compatible module for estimating prediction intervals.
|Anaconda|_ MAPIE - Model Agnostic Prediction Interval Estimator MAPIE allows you to easily estimate prediction intervals using your favourite sklearn
 584 Dec 27, 2022
584 Dec 27, 2022
Focus on Algorithm Design, Not on Data Wrangling
The dataTap Python library is the primary interface for using dataTap's rich data management tools. Create datasets, stream annotations, and analyze model performance all with one library.
 37 Nov 25, 2022
37 Nov 25, 2022

Educational project on how to build an ETL (Extract, Transform, Load) data pipeline, orchestrated with Airflow.
ETL Pipeline with Airflow, Spark, s3, MongoDB and Amazon Redshift
 214 Jan 2, 2023
214 Jan 2, 2023
Using python and scikit-learn to make stock predictions
MachineLearningStocks in python: a starter project and guide EDIT as of Feb 2021: MachineLearningStocks is no longer actively maintained MachineLearni
1.3k Dec 29, 2022
Socorro is the Mozilla crash ingestion pipeline. It accepts and processes Breakpad-style crash reports. It provides analysis tools.
Socorro Socorro is a Mozilla-centric ingestion pipeline and analysis tools for crash reports using the Breakpad libraries. Support This is a Mozilla-s
 552 Dec 19, 2022
552 Dec 19, 2022
![git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]](https://github.com/happycaoyue/Pseudo-ISP/raw/main/img/3.png)
git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]
Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser Abstract The success of deep denoisers on real-world colo
 51 Nov 22, 2022
51 Nov 22, 2022

Automated Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning
The mljar-supervised is an Automated Machine Learning Python package that works with tabular data. I
 2.4k Jan 2, 2023
2.4k Jan 2, 2023
scikit-learn inspired API for CRFsuite
sklearn-crfsuite sklearn-crfsuite is a thin CRFsuite (python-crfsuite) wrapper which provides interface simlar to scikit-learn. sklearn_crfsuite.CRF i
 418 Jan 9, 2023
418 Jan 9, 2023
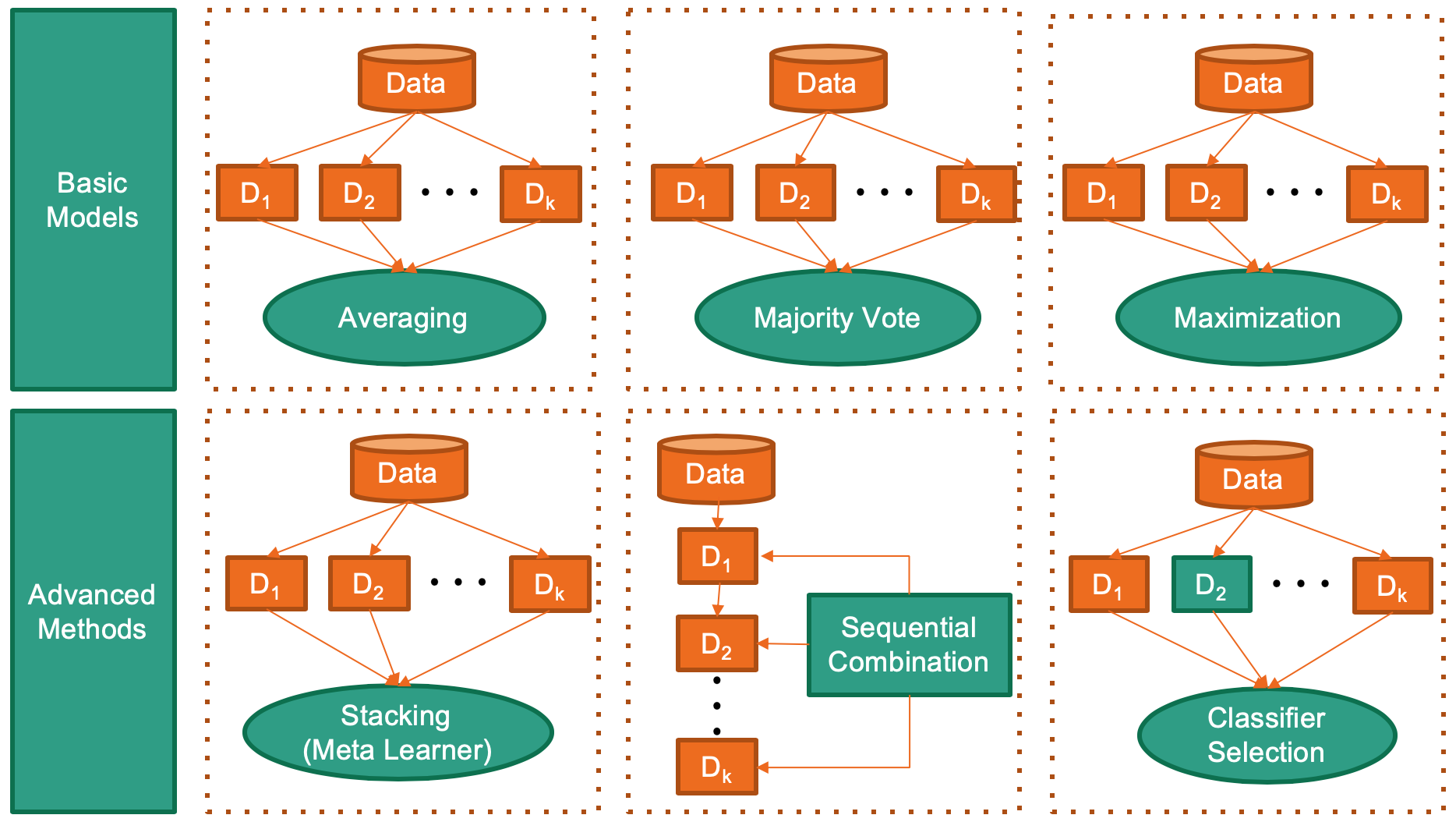
(AAAI' 20) A Python Toolbox for Machine Learning Model Combination
combo: A Python Toolbox for Machine Learning Model Combination Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License
 606 Dec 21, 2022
606 Dec 21, 2022
A library of sklearn compatible categorical variable encoders
Categorical Encoding Methods A set of scikit-learn-style transformers for encoding categorical variables into numeric by means of different techniques
 2.1k Jan 2, 2023
2.1k Jan 2, 2023
PyTorch extensions for fast R&D prototyping and Kaggle farming
Pytorch-toolbelt A pytorch-toolbelt is a Python library with a set of bells and whistles for PyTorch for fast R&D prototyping and Kaggle farming: What
 1.3k Jan 5, 2023
1.3k Jan 5, 2023

A GPU-accelerated library containing highly optimized building blocks and an execution engine for data processing to accelerate deep learning training and inference applications.
NVIDIA DALI The NVIDIA Data Loading Library (DALI) is a library for data loading and pre-processing to accelerate deep learning applications. It provi
 4.2k Jan 8, 2023
4.2k Jan 8, 2023
Automatically build ARIMA, SARIMAX, VAR, FB Prophet and XGBoost Models on Time Series data sets with a Single Line of Code. Now updated with Dask to handle millions of rows.
Auto_TS: Auto_TimeSeries Automatically build multiple Time Series models using a Single Line of Code. Now updated with Dask. Auto_timeseries is a comp
 519 Jan 3, 2023
519 Jan 3, 2023
We have implemented shaDow-GNN as a general and powerful pipeline for graph representation learning. For more details, please find our paper titled Deep Graph Neural Networks with Shallow Subgraph Samplers, available on arXiv (https//arxiv.org/abs/2012.01380).
Deep GNN, Shallow Sampling Hanqing Zeng, Muhan Zhang, Yinglong Xia, Ajitesh Srivastava, Andrey Malevich, Rajgopal Kannan, Viktor Prasanna, Long Jin, R
 117 Dec 20, 2022
117 Dec 20, 2022
An expandable and scalable OCR pipeline
Overview Nidaba is the central controller for the entire OGL OCR pipeline. It oversees and automates the process of converting raw images into citable
 81 Jan 4, 2023
81 Jan 4, 2023

This is a c++ project deploying a deep scene text reading pipeline with tensorflow. It reads text from natural scene images. It uses frozen tensorflow graphs. The detector detect scene text locations. The recognizer reads word from each detected bounding box.
DeepSceneTextReader This is a c++ project deploying a deep scene text reading pipeline. It reads text from natural scene images. Prerequsites The proj
 49 Sep 10, 2022
49 Sep 10, 2022

End-to-end pipeline for real-time scene text detection and recognition.
Real-time-Scene-Text-Detection-and-Recognition-System End-to-end pipeline for real-time scene text detection and recognition. The detection model use
 89 Aug 4, 2022
89 Aug 4, 2022
Toy example of an applied ML pipeline for me to experiment with MLOps tools.
Toy Machine Learning Pipeline Table of Contents About Getting Started ML task description and evaluation procedure Dataset description Repository stru
 190 Dec 21, 2022
190 Dec 21, 2022
SigOpt wrappers for scikit-learn methods
SigOpt + scikit-learn Interfacing This package implements useful interfaces and wrappers for using SigOpt and scikit-learn together Getting Started In
 73 Sep 30, 2022
73 Sep 30, 2022
Use evolutionary algorithms instead of gridsearch in scikit-learn
sklearn-deap Use evolutionary algorithms instead of gridsearch in scikit-learn. This allows you to reduce the time required to find the best parameter
 709 Jan 3, 2023
709 Jan 3, 2023
Hyper-parameter optimization for sklearn
hyperopt-sklearn Hyperopt-sklearn is Hyperopt-based model selection among machine learning algorithms in scikit-learn. See how to use hyperopt-sklearn
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
Genetic feature selection module for scikit-learn
sklearn-genetic Genetic feature selection module for scikit-learn Genetic algorithms mimic the process of natural selection to search for optimal valu
 260 Dec 14, 2022
260 Dec 14, 2022
scikit-learn inspired API for CRFsuite
sklearn-crfsuite sklearn-crfsuite is a thin CRFsuite (python-crfsuite) wrapper which provides interface simlar to scikit-learn. sklearn_crfsuite.CRF i
417 Dec 20, 2022
Supervised domain-agnostic prediction framework for probabilistic modelling
A supervised domain-agnostic framework that allows for probabilistic modelling, namely the prediction of probability distributions for individual data
 112 Oct 23, 2022
112 Oct 23, 2022
A sklearn-compatible Python implementation of Multifactor Dimensionality Reduction (MDR) for feature construction.
Master status: Development status: Package information: MDR A scikit-learn-compatible Python implementation of Multifactor Dimensionality Reduction (M
 122 Jul 6, 2022
122 Jul 6, 2022
a feature engineering wrapper for sklearn
Few Few is a Feature Engineering Wrapper for scikit-learn. Few looks for a set of feature transformations that work best with a specified machine lear
 47 Nov 18, 2022
47 Nov 18, 2022
BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflows even for datasets that do not fit into memory.
BatchFlow BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflo
 185 Dec 20, 2022
185 Dec 20, 2022
Pandas integration with sklearn
Sklearn-pandas This module provides a bridge between Scikit-Learn's machine learning methods and pandas-style Data Frames. In particular, it provides
2.7k Dec 27, 2022
Easy pipelines for pandas DataFrames.
pdpipe ˨ Easy pipelines for pandas DataFrames (learn how!). Website: https://pdpipe.github.io/pdpipe/ Documentation: https://pdpipe.github.io/pdpipe/d
 694 Jan 5, 2023
694 Jan 5, 2023
Universal 1d/2d data containers with Transformers functionality for data analysis.
XPandas (extended Pandas) implements 1D and 2D data containers for storing type-heterogeneous tabular data of any type, and encapsulates feature extra
25 Mar 14, 2022
MLBox is a powerful Automated Machine Learning python library.
MLBox is a powerful Automated Machine Learning python library. It provides the following features: Fast reading and distributed data preprocessing/cle
 1.4k Jan 6, 2023
1.4k Jan 6, 2023
Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs (CIKM 2020)
Karate Club is an unsupervised machine learning extension library for NetworkX. Please look at the Documentation, relevant Paper, Promo Video, and Ext
1.8k Jan 3, 2023
Highly interpretable classifiers for scikit learn, producing easily understood decision rules instead of black box models
Highly interpretable, sklearn-compatible classifier based on decision rules This is a scikit-learn compatible wrapper for the Bayesian Rule List class
 482 Nov 19, 2022
482 Nov 19, 2022
50% faster, 50% less RAM Machine Learning. Numba rewritten Sklearn. SVD, NNMF, PCA, LinearReg, RidgeReg, Randomized, Truncated SVD/PCA, CSR Matrices all 50+% faster
[Due to the time taken @ uni, work + hell breaking loose in my life, since things have calmed down a bit, will continue commiting!!!] [By the way, I'm
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
DaCy: The State of the Art Danish NLP pipeline using SpaCy
DaCy: A SpaCy NLP Pipeline for Danish DaCy is a Danish preprocessing pipeline trained in SpaCy. At the time of writing it has achieved State-of-the-Ar
 71 Jan 6, 2023
71 Jan 6, 2023
Data intensive science for everyone.
The latest information about Galaxy can be found on the Galaxy Community Hub. Community support is available at Galaxy Help. Galaxy Quickstart Galaxy
 1k Jan 8, 2023
1k Jan 8, 2023
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
 2.1k Feb 13, 2021
2.1k Feb 13, 2021
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
 831 Feb 17, 2021
831 Feb 17, 2021
🛸 Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy
spacy-transformers: Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy This package provides spaCy components and architectures to use tr
 903 Feb 17, 2021
903 Feb 17, 2021
✨Fast Coreference Resolution in spaCy with Neural Networks
✨ NeuralCoref 4.0: Coreference Resolution in spaCy with Neural Networks. NeuralCoref is a pipeline extension for spaCy 2.1+ which annotates and resolv
 2.2k Feb 18, 2021
2.2k Feb 18, 2021
Automatically Visualize any dataset, any size with a single line of code. Created by Ram Seshadri. Collaborators Welcome. Permission Granted upon Request.
AutoViz Automatically Visualize any dataset, any size with a single line of code. AutoViz performs automatic visualization of any dataset with one lin
299 Feb 13, 2021
An audio digital processing toolbox based on a workflow/pipeline principle
AudioTK Audio ToolKit is a set of audio filters. It helps assembling workflows for specific audio processing workloads. The audio workflow is split in
 238 Oct 18, 2022
238 Oct 18, 2022
PipeLayer is a lightweight Python pipeline framework
PipeLayer is a lightweight Python pipeline framework. Define a series of steps, and chain them together to create modular applications
 64 Jul 21, 2022
64 Jul 21, 2022
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
2.7k Jan 8, 2023
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
1.3k Jan 3, 2023
🛸 Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy
spacy-transformers: Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy This package provides spaCy components and architectures to use tr
1.2k Jan 8, 2023
✨Fast Coreference Resolution in spaCy with Neural Networks
✨ NeuralCoref 4.0: Coreference Resolution in spaCy with Neural Networks. NeuralCoref is a pipeline extension for spaCy 2.1+ which annotates and resolv
2.6k Jan 4, 2023
:mag: Transformers at scale for question answering & neural search. Using NLP via a modular Retriever-Reader-Pipeline. Supporting DPR, Elasticsearch, HuggingFace's Modelhub...
Haystack is an end-to-end framework for Question Answering & Neural search that enables you to ... ... ask questions in natural language and find gran
 6.4k Jan 9, 2023
6.4k Jan 9, 2023
Automatically Visualize any dataset, any size with a single line of code. Created by Ram Seshadri. Collaborators Welcome. Permission Granted upon Request.
AutoViz Automatically Visualize any dataset, any size with a single line of code. AutoViz performs automatic visualization of any dataset with one lin
1k Jan 2, 2023
MongoDB data stream pipeline tools by YouGov (adopted from MongoDB)
mongo-connector The mongo-connector project originated as a MongoDB mongo-labs project and is now community-maintained under the custody of YouGov, Pl
 1.9k Jan 4, 2023
1.9k Jan 4, 2023
Pipeline is an asset packaging library for Django.
Pipeline Pipeline is an asset packaging library for Django, providing both CSS and JavaScript concatenation and compression, built-in JavaScript templ
 1.4k Jan 3, 2023
1.4k Jan 3, 2023
Soda SQL Data testing, monitoring and profiling for SQL accessible data.
Soda SQL Data testing, monitoring and profiling for SQL accessible data. What does Soda SQL do? Soda SQL allows you to Stop your pipeline when bad dat
 51 Jan 1, 2023
51 Jan 1, 2023
Pipeline is an asset packaging library for Django.
Pipeline Pipeline is an asset packaging library for Django, providing both CSS and JavaScript concatenation and compression, built-in JavaScript templ
1.4k Dec 26, 2022
Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs (CIKM 2020)
Karate Club is an unsupervised machine learning extension library for NetworkX. Please look at the Documentation, relevant Paper, Promo Video, and Ext
1.8k Jan 9, 2023
The windML framework provides an easy-to-use access to wind data sources within the Python world, building upon numpy, scipy, sklearn, and matplotlib. Renewable Wind Energy, Forecasting, Prediction
windml Build status : The importance of wind in smart grids with a large number of renewable energy resources is increasing. With the growing infrastr
 125 Dec 24, 2022
125 Dec 24, 2022

Automates Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning :rocket:
MLJAR Automated Machine Learning Documentation: https://supervised.mljar.com/ Source Code: https://github.com/mljar/mljar-supervised Table of Contents
2.4k Dec 31, 2022
A Sklearn-like Framework for Hyperparameter Tuning and AutoML in Deep Learning projects. Finally have the right abstractions and design patterns to properly do AutoML. Let your pipeline steps have hyperparameter spaces. Enable checkpoints to cut duplicate calculations. Go from research to production environment easily.
Neuraxle Pipelines Code Machine Learning Pipelines - The Right Way. Neuraxle is a Machine Learning (ML) library for building machine learning pipeline
 555 Dec 24, 2022
555 Dec 24, 2022
Lightweight, Python library for fast and reproducible experimentation :microscope:
Steppy What is Steppy? Steppy is a lightweight, open-source, Python 3 library for fast and reproducible experimentation. Steppy lets data scientist fo
 134 Jul 10, 2022
134 Jul 10, 2022
Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs (CIKM 2020)
Karate Club is an unsupervised machine learning extension library for NetworkX. Please look at the Documentation, relevant Paper, Promo Video, and Ext
1.8k Jan 7, 2023
a delightful machine learning tool that allows you to train, test and use models without writing code
igel A delightful machine learning tool that allows you to train/fit, test and use models without writing code Note I'm also working on a GUI desktop
 3k Jan 5, 2023
3k Jan 5, 2023