201 Repositories
Python spark-sql Libraries

Splitgraph command line client and python library
Splitgraph Overview Splitgraph is a tool for building, versioning and querying reproducible datasets. It's inspired by Docker and Git, so it feels fam
 313 Dec 24, 2022
313 Dec 24, 2022
All in One CRACKER911181's Tool. This Tool For Hacking and Pentesting. 🎭
All in One CRACKER911181's Tool. This Tool For Hacking and Pentesting. 🎭
 331 Jan 1, 2023
331 Jan 1, 2023

A web application made with Flask that works with a weather service API to get the current weather from all over the world.
Weather App A web application made with Flask that works with a weather service API to get the current weather from all over the world. Uses data from
 19 Dec 2, 2022
19 Dec 2, 2022
🟥This is an overview of how to set up and use DataStore3 in your Roblox experiences
Welcome to DataStore3 👋 This is an overview of how to set up and use DataStore3 in your Roblox experiences What is it? 🤔 DataStore3 is a service tha
 7 Aug 19, 2022
7 Aug 19, 2022
A Powerful, Smart And Advance Group Manager ... Written with AioGram , Pyrogram and Telethon...
❤️ Shadow ❤️ A Powerful, Smart And Advance Group Manager ... Written with AioGram , Pyrogram and Telethon... ⭐️ Thanks to everyone who starred Shadow,
 17 Oct 21, 2022
17 Oct 21, 2022

iot-dashboard: Fully integrated architecture platform with a dashboard for Logistics Monitoring, Internet of Things.
Fully integrated architecture platform with a dashboard for Logistics Monitoring, Internet of Things. Written in Python. Flask applicati
 2 Jul 29, 2022
2 Jul 29, 2022
Transforme rapidamente seu arquivo CSV (de qualquer tamanho) para SQL de forma rápida.
Transformador de CSV para SQL Transforme rapidamente seu arquivo CSV (de qualquer tamanho) para SQL de forma rápida, e com isso insira seus dados usan
 4 Oct 17, 2022
4 Oct 17, 2022
A script based on sqlmap that uses sql injection vulnerabilities to traverse the existence of a file
A script based on sqlmap that uses sql injection vulnerabilities to traverse the existence o
 2 Nov 9, 2022
2 Nov 9, 2022
program to store and update pokemons using SQL and Flask
Pokemon SQL and Flask Pokemons api in python. Technologies flask pymysql Description PokeCorp is a company that tracks pokemon and their trainers arou
 1 Oct 20, 2021
1 Oct 20, 2021
SQL queries to collections
SQC SQL Queries to Collections Examples from sqc import sqc data = [ {"a": 1, "b": 1}, {"a": 2, "b": 1}, {"a": 3, "b": 2}, ] Simple filte
 0 Jul 6, 2022
0 Jul 6, 2022
SQL Alchemy dialect for Neo4j
SQL Alchemy dialect for Neo4j This package provides the SQL dialect for Neo4j, using the official JDBC driver (the Neo4j "BI Connector" ) Installation
 8 Jan 2, 2023
8 Jan 2, 2023
Simple to use image handler for python sqlite3.
SQLite Image Handler Simple to use image handler for python sqlite3. Functions Function Name Parameters Returns init databasePath : str tableName : st
 7 Sep 16, 2022
7 Sep 16, 2022

A collection of neat and practical data science and machine learning projects
Data Science A collection of neat and practical data science and machine learning projects Explore the docs » Report Bug · Request Feature Table of Co
 2 Dec 10, 2021
2 Dec 10, 2021
A simple python package that perform SQL Server Source Control and Auto Deployment.
deploydb Deploy your database objects automatically when the git branch is updated. Production-ready! ⚙️ Easy-to-use 🔨 Customizable 🔧 Installation I
 10 Dec 7, 2022
10 Dec 7, 2022
PyRemoteSQL is a python SQL client that allows you to connect to your remote server with phpMyAdmin installed.
PyRemoteSQL Python MySQL remote client Basically this is a python SQL client that allows you to connect to your remote server with phpMyAdmin installe
 3 Nov 4, 2022
3 Nov 4, 2022
A Flask web application that manages student entries in a SQL database
Student Database App This is a Flask web application that manages student entries in a SQL database. Users can upload a CSV into the SQL database, mak
 1 Oct 20, 2021
1 Oct 20, 2021

A web scraping pipeline project that retrieves TV and movie data from two sources, then transforms and stores data in a MySQL database.
New to Streaming Scraper An in-progress web scraping project built with Python, R, and SQL. The scraped data are movie and TV show information. The go
 1 Mar 28, 2022
1 Mar 28, 2022

A collection of learning outcomes data analysis using Python and SQL, from DQLab.
Data Analyst with PYTHON Data Analyst berperan dalam menghasilkan analisa data serta mempresentasikan insight untuk membantu proses pengambilan keputu
 6 Oct 11, 2022
6 Oct 11, 2022
Spark development environment for k8s
Local Spark Dev Env with Docker Development environment for k8s. Using the spark-operator image to ensure it will be the same environment. Start conta
 18 Jan 4, 2022
18 Jan 4, 2022
TensorFlowOnSpark brings TensorFlow programs to Apache Spark clusters.
TensorFlowOnSpark TensorFlowOnSpark brings scalable deep learning to Apache Hadoop and Apache Spark clusters. By combining salient features from the T
 3.8k Jan 4, 2023
3.8k Jan 4, 2023

PySpark Cheat Sheet - learn PySpark and develop apps faster
This cheat sheet will help you learn PySpark and write PySpark apps faster. Everything in here is fully functional PySpark code you can run or adapt to your programs.
 168 Jan 1, 2023
168 Jan 1, 2023
This repo in the implementation of EMNLP'21 paper "SPARQLing Database Queries from Intermediate Question Decompositions" by Irina Saparina, Anton Osokin
SPARQLing Database Queries from Intermediate Question Decompositions This repo is the implementation of the following paper: SPARQLing Database Querie
 20 Dec 19, 2022
20 Dec 19, 2022
Simple DDL Parser to parse SQL (HQL, TSQL, AWS Redshift, Snowflake and other dialects) ddl files to json/python dict with full information about columns: types, defaults, primary keys, etc.
Simple DDL Parser Build with ply (lex & yacc in python). A lot of samples in 'tests/. Is it Stable? Yes, library already has about 5000+ usage per day
 95 Jan 5, 2023
95 Jan 5, 2023
Django package to log request values such as device, IP address, user CPU time, system CPU time, No of queries, SQL time, no of cache calls, missing, setting data cache calls for a particular URL with a basic UI.
django-web-profiler's documentation: Introduction: django-web-profiler is a django profiling tool which logs, stores debug toolbar statistics and also
 77 Oct 29, 2022
77 Oct 29, 2022
Custom bot I've made to host events on my personal Discord server.
discord_events Custom bot I've made to host events on my personal Discord server. You can try the bot out in my personal server here: https://discord.
 5 Mar 16, 2022
5 Mar 16, 2022

Linux, Jenkins, AWS, SRE, Prometheus, Docker, Python, Ansible, Git, Kubernetes, Terraform, OpenStack, SQL, NoSQL, Azure, GCP, DNS, Elastic, Network, Virtualization. DevOps Interview Questions
Linux, Jenkins, AWS, SRE, Prometheus, Docker, Python, Ansible, Git, Kubernetes, Terraform, OpenStack, SQL, NoSQL, Azure, GCP, DNS, Elastic, Network, Virtualization. DevOps Interview Questions
 35.1k Jan 2, 2023
35.1k Jan 2, 2023

Visions provides an extensible suite of tools to support common data analysis operations
Visions And these visions of data types, they kept us up past the dawn. Visions provides an extensible suite of tools to support common data analysis
 168 Dec 28, 2022
168 Dec 28, 2022

WebScan is a web vulnerability Scanning tool, which scans sites for SQL injection and XSS vulnerabilities
WebScan is a web vulnerability Scanning tool, which scans sites for SQL injection and XSS vulnerabilities Which is a great tool for web pentesters. Coded in python3, CLI. WebScan is capable of scanning and detecting sql injection vulnerabilities across HTTP and HTTP sites.
 12 Dec 2, 2022
12 Dec 2, 2022
TAPEX: Table Pre-training via Learning a Neural SQL Executor
TAPEX: Table Pre-training via Learning a Neural SQL Executor The official repository which contains the code and pre-trained models for our paper TAPE
 157 Dec 28, 2022
157 Dec 28, 2022
Async ORM based on PyPika
PyPika-ORM - ORM for PyPika SQL Query Builder The package gives you ORM for PyPika with asycio support for a range of databases (SQLite, PostgreSQL, M
 7 Jun 4, 2022
7 Jun 4, 2022

Evidence enables analysts to deliver a polished business intelligence system using SQL and markdown.
Evidence enables analysts to deliver a polished business intelligence system using SQL and markdown
 915 Dec 26, 2022
915 Dec 26, 2022
SQLModel is a library for interacting with SQL databases from Python code, with Python objects.
SQLModel is a library for interacting with SQL databases from Python code, with Python objects. It is designed to be intuitive, easy to use, highly compatible, and robust.
 9.1k Dec 31, 2022
9.1k Dec 31, 2022
Airflow Operator for running Soda SQL scans
Airflow Operator for running Soda SQL scans
 7 Oct 18, 2022
7 Oct 18, 2022
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022

Anomaly detection on SQL data warehouses and databases
With CueObserve, you can run anomaly detection on data in your SQL data warehouses and databases. Getting Started Install via Docker docker run -p 300
 171 Dec 18, 2022
171 Dec 18, 2022

The MLOps platform for innovators 🚀
DS2.ai is an integrated AI operation solution that supports all stages from custom AI development to deployment. It is an AI-specialized platform service that collects data, builds a training dataset through data labeling, and enables automatic development of artificial intelligence and easy deployment and operation.
 9 Jan 3, 2023
9 Jan 3, 2023
A fun hangman style game to guess random movie names with a short summary about the movie.
hang-movie-man Hangman but for movies 😉 This is a fun hangman style game to guess random movie names from the local database and show some summary ab
 10 Sep 7, 2022
10 Sep 7, 2022
Bearsql allows you to query pandas dataframe with sql syntax.
Bearsql adds sql syntax on pandas dataframe. It uses duckdb to speedup the pandas processing and as the sql engine
 14 Jun 22, 2022
14 Jun 22, 2022
a url shortener with fastapi and tortoise-orm
fastapi-tortoise-orm-url-shortener a url shortener with fastapi and tortoise-orm
 19 Aug 12, 2022
19 Aug 12, 2022

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022
Migrate data from SQL to NoSQL easily
Migrate data from SQL to NoSQL easily Installation 💯 pip install sql2nosql --upgrade Dependencies 📢 For the package to work, it first needs "clients
 43 Mar 26, 2022
43 Mar 26, 2022

dask-sql is a distributed SQL query engine in python using Dask
dask-sql is a distributed SQL query engine in Python. It allows you to query and transform your data using a mixture of common SQL operations and Python code and also scale up the calculation easily if you need it.
 271 Dec 30, 2022
271 Dec 30, 2022

An IVR Chatbot which can exponentially reduce the burden of companies as well as can improve the consumer/end user experience.
IVR-Chatbot Achievements 🏆 Team Uhtred won the Maverick 2.0 Bot-a-thon 2021 organized by AbInbev India. ❓ Problem Statement As we all know that, lot
 9 Dec 8, 2022
9 Dec 8, 2022
Hue Editor: Open source SQL Query Assistant for Databases/Warehouses
Hue Editor: Open source SQL Query Assistant for Databases/Warehouses
 759 Jan 7, 2023
759 Jan 7, 2023
Ethereum ETL lets you convert blockchain data into convenient formats like CSVs and relational databases.
Python scripts for ETL (extract, transform and load) jobs for Ethereum blocks, transactions, ERC20 / ERC721 tokens, transfers, receipts, logs, contracts, internal transactions.
 2.3k Jan 1, 2023
2.3k Jan 1, 2023
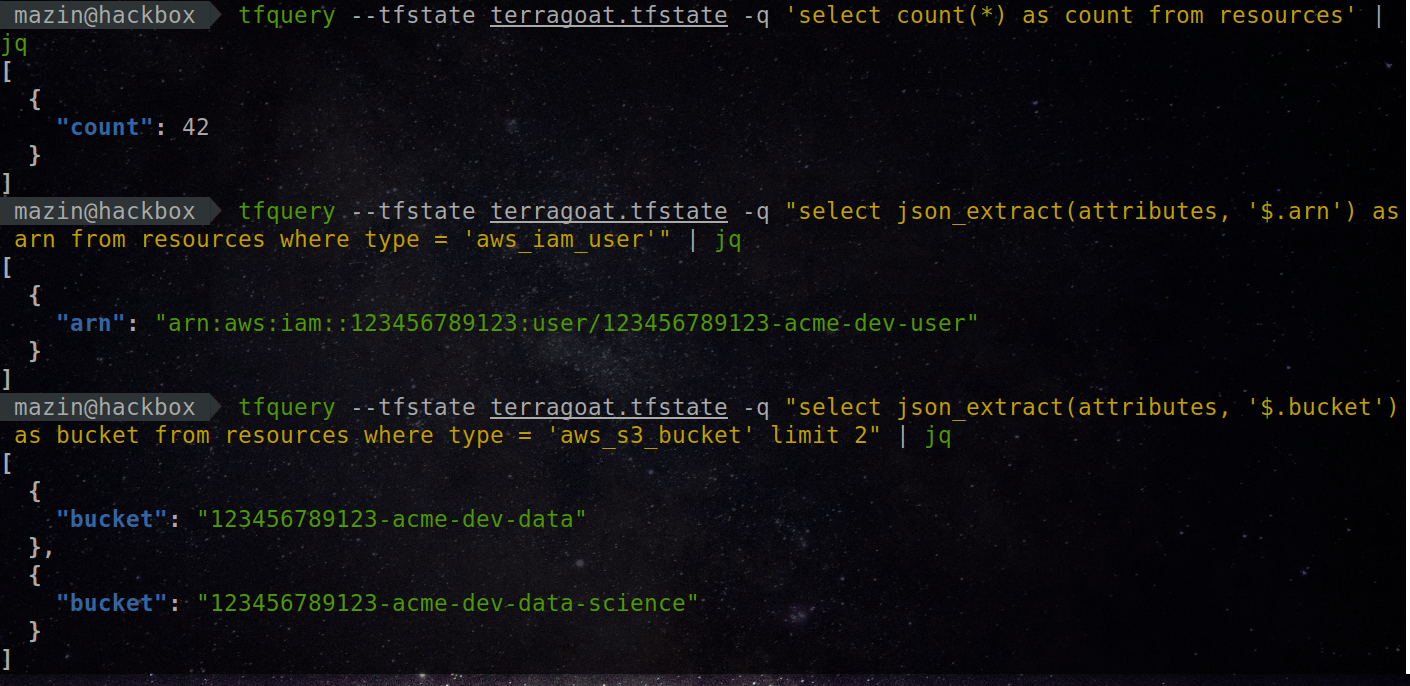
tfquery: Run SQL queries on your Terraform infrastructure. Query resources and analyze its configuration using a SQL-powered framework.
🌩️ tfquery 🌩️ Run SQL queries on your Terraform infrastructure. Ask questions that are hard to answer 🚀 What is tfquery? tfquery is a framework tha
 311 Dec 21, 2022
311 Dec 21, 2022
“ HOLA HUMANS 👋 I'M DAISYX 2.0 ❤️ „ LATEST VERSION OF DAISYX.. Source Code of @Daisyxbot
❤️ DaisyX 2.0 ❤️ A Powerful, Smart And Simple Group Manager ... Written with AioGram , Pyrogram and Telethon... ⭐️ Thanks to everyone who starred Dais
 153 Dec 6, 2022
153 Dec 6, 2022

Mongita is to MongoDB as SQLite is to SQL
Mongita is a lightweight embedded document database that implements a commonly-used subset of the MongoDB/PyMongo interface. Mongita differs from MongoDB in that instead of being a server, Mongita is a self-contained Python library. Mongita can be configured to store its documents either on disk or in memory.
 809 Jan 7, 2023
809 Jan 7, 2023

Apache Superset is a Data Visualization and Data Exploration Platform
Apache Superset is a Data Visualization and Data Exploration Platform
 49.9k Jan 2, 2023
49.9k Jan 2, 2023
This tool extracts Credit card numbers, NTLM(DCE-RPC, HTTP, SQL, LDAP, etc), Kerberos (AS-REQ Pre-Auth etype 23), HTTP Basic, SNMP, POP, SMTP, FTP, IMAP, etc from a pcap file or from a live interface.
This tool extracts Credit card numbers, NTLM(DCE-RPC, HTTP, SQL, LDAP, etc), Kerberos (AS-REQ Pre-Auth etype 23), HTTP Basic, SNMP, POP, SMTP, FTP, IMAP, etc from a pcap file or from a live interface.
 1.6k Jan 1, 2023
1.6k Jan 1, 2023
BlazingSQL is a lightweight, GPU accelerated, SQL engine for Python. Built on RAPIDS cuDF.
A lightweight, GPU accelerated, SQL engine built on the RAPIDS.ai ecosystem. Get Started on app.blazingsql.com Getting Started | Documentation | Examp
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
[DEPRECATED] Tensorflow wrapper for DataFrames on Apache Spark
TensorFrames (Deprecated) Note: TensorFrames is deprecated. You can use pandas UDF instead. Experimental TensorFlow binding for Scala and Apache Spark
 757 Dec 31, 2022
757 Dec 31, 2022

Distributed scikit-learn meta-estimators in PySpark
sk-dist: Distributed scikit-learn meta-estimators in PySpark What is it? sk-dist is a Python package for machine learning built on top of scikit-learn
 282 Dec 9, 2022
282 Dec 9, 2022
Distributed Tensorflow, Keras and PyTorch on Apache Spark/Flink & Ray
A unified Data Analytics and AI platform for distributed TensorFlow, Keras and PyTorch on Apache Spark/Flink & Ray What is Analytics Zoo? Analytics Zo
 2.5k Dec 28, 2022
2.5k Dec 28, 2022
Microsoft Machine Learning for Apache Spark
Microsoft Machine Learning for Apache Spark MMLSpark is an ecosystem of tools aimed towards expanding the distributed computing framework Apache Spark
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
TensorFlowOnSpark brings TensorFlow programs to Apache Spark clusters.
TensorFlowOnSpark TensorFlowOnSpark brings scalable deep learning to Apache Hadoop and Apache Spark clusters. By combining salient features from the T
3.8k Jan 4, 2023
Distributed Deep learning with Keras & Spark
Elephas: Distributed Deep Learning with Keras & Spark Elephas is an extension of Keras, which allows you to run distributed deep learning models at sc
 1.6k Dec 29, 2022
1.6k Dec 29, 2022
BigDL: Distributed Deep Learning Framework for Apache Spark
BigDL: Distributed Deep Learning on Apache Spark What is BigDL? BigDL is a distributed deep learning library for Apache Spark; with BigDL, users can w
4.1k Jan 9, 2023

Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
Horovod Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make dis
 12.9k Jan 7, 2023
12.9k Jan 7, 2023

Release of SPLASH: Dataset for semantic parse correction with natural language feedback in the context of text-to-SQL parsing
SPLASH: Semantic Parsing with Language Assistance from Humans SPLASH is dataset for the task of semantic parse correction with natural language feedba
 35 Oct 31, 2022
35 Oct 31, 2022
SQL for Humans™
Records: SQL for Humans™ Records is a very simple, but powerful, library for making raw SQL queries to most relational databases. Just write SQL. No b
 6.9k Jan 3, 2023
6.9k Jan 3, 2023
Automatic SQL injection and database takeover tool
sqlmap sqlmap is an open source penetration testing tool that automates the process of detecting and exploiting SQL injection flaws and taking over of
 25.7k Jan 2, 2023
25.7k Jan 2, 2023
An open source multi-tool for exploring and publishing data
Datasette An open source multi-tool for exploring and publishing data Datasette is a tool for exploring and publishing data. It helps people take data
 6.8k Jan 1, 2023
6.8k Jan 1, 2023

Django app for building dashboards using raw SQL queries
django-sql-dashboard Django app for building dashboards using raw SQL queries Brings a useful subset of Datasette to Django. Currently only works with
383 Jan 6, 2023
Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
Horovod Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make dis
12.9k Dec 29, 2022

Modin: Speed up your Pandas workflows by changing a single line of code
Scale your pandas workflows by changing one line of code To use Modin, replace the pandas import: # import pandas as pd import modin.pandas as pd Inst
 8.2k Jan 1, 2023
8.2k Jan 1, 2023
Koalas: pandas API on Apache Spark
pandas API on Apache Spark Explore Koalas docs » Live notebook · Issues · Mailing list Help Thirsty Koalas Devastated by Recent Fires The Koalas proje
3.2k Jan 4, 2023
A pure Python implementation of Apache Spark's RDD and DStream interfaces.
pysparkling Pysparkling provides a faster, more responsive way to develop programs for PySpark. It enables code intended for Spark applications to exe
 254 Dec 6, 2022
254 Dec 6, 2022
Distributed Deep learning with Keras & Spark
Elephas: Distributed Deep Learning with Keras & Spark Elephas is an extension of Keras, which allows you to run distributed deep learning models at sc
1.6k Jan 5, 2023
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
eXtreme Gradient Boosting Community | Documentation | Resources | Contributors | Release Notes XGBoost is an optimized distributed gradient boosting l
 23.6k Jan 3, 2023
23.6k Jan 3, 2023
PySpark + Scikit-learn = Sparkit-learn
Sparkit-learn PySpark + Scikit-learn = Sparkit-learn GitHub: https://github.com/lensacom/sparkit-learn About Sparkit-learn aims to provide scikit-lear
 1.1k Jan 4, 2023
1.1k Jan 4, 2023
Streamlit dashboard examples - Twitter cashtags, StockTwits, WSB, Charts, SQL Pattern Scanner
streamlit-dashboards Streamlit dashboard examples - Twitter cashtags, StockTwits, WSB, Charts, SQL Pattern Scanner Tutorial Video https://ww
 122 Dec 21, 2022
122 Dec 21, 2022
Open source platform for the machine learning lifecycle
MLflow: A Machine Learning Lifecycle Platform MLflow is a platform to streamline machine learning development, including tracking experiments, packagi
 13.3k Jan 4, 2023
13.3k Jan 4, 2023

:fishing_pole_and_fish: List of `pre-commit` hooks to ensure the quality of your `dbt` projects.
pre-commit-dbt List of pre-commit hooks to ensure the quality of your dbt projects. BETA NOTICE: This tool is still BETA and may have some bugs, so pl
 262 Nov 25, 2022
262 Nov 25, 2022
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
 1.9k Feb 18, 2021
1.9k Feb 18, 2021
A dynamic FastAPI router that automatically creates CRUD routes for your models
⚡ Create CRUD routes with lighting speed ⚡ A dynamic FastAPI router that automatically creates CRUD routes for your models Documentation: https://fast
 130 Feb 13, 2021
130 Feb 13, 2021

 578 Dec 30, 2022
578 Dec 30, 2022
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
3k Jan 5, 2023
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
eXtreme Gradient Boosting Community | Documentation | Resources | Contributors | Release Notes XGBoost is an optimized distributed gradient boosting l
20.6k Feb 13, 2021
Apache Spark - A unified analytics engine for large-scale data processing
Apache Spark Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an op
34.7k Jan 4, 2023
A dynamic FastAPI router that automatically creates CRUD routes for your models
⚡ Create CRUD routes with lighting speed ⚡ A dynamic FastAPI router that automatically creates CRUD routes for your models Documentation: https://fast
943 Jan 1, 2023
Automatic SQL injection and database takeover tool
sqlmap sqlmap is an open source penetration testing tool that automates the process of detecting and exploiting SQL injection flaws and taking over of
25.7k Jan 8, 2023
PyPika is a python SQL query builder that exposes the full richness of the SQL language using a syntax that reflects the resulting query. PyPika excels at all sorts of SQL queries but is especially useful for data analysis.
PyPika - Python Query Builder Abstract What is PyPika? PyPika is a Python API for building SQL queries. The motivation behind PyPika is to provide a s
 1.9k Jan 4, 2023
1.9k Jan 4, 2023
Easy-to-use data handling for SQL data stores with support for implicit table creation, bulk loading, and transactions.
dataset: databases for lazy people In short, dataset makes reading and writing data in databases as simple as reading and writing JSON files. Read the
 4.2k Jan 2, 2023
4.2k Jan 2, 2023
SQL for Humans™
Records: SQL for Humans™ Records is a very simple, but powerful, library for making raw SQL queries to most relational databases. Just write SQL. No b
6.9k Jan 7, 2023
A pandas-like deferred expression system, with first-class SQL support
Ibis: Python data analysis framework for Hadoop and SQL engines Service Status Documentation Conda packages PyPI Azure Coverage Ibis is a toolbox to b
 2.3k Jan 6, 2023
2.3k Jan 6, 2023
The Database Toolkit for Python
SQLAlchemy The Python SQL Toolkit and Object Relational Mapper Introduction SQLAlchemy is the Python SQL toolkit and Object Relational Mapper that giv
 6.5k Jan 1, 2023
6.5k Jan 1, 2023
Easily share data across your company via SQL queries. From Grove Collab.
SQL Explorer SQL Explorer aims to make the flow of data between people fast, simple, and confusion-free. It is a Django-based application that you can
 2.1k Dec 30, 2022
2.1k Dec 30, 2022
IMDbPY is a Python package useful to retrieve and manage the data of the IMDb movie database about movies, people, characters and companies
IMDbPY is a Python package for retrieving and managing the data of the IMDb movie database about movies, people and companies. Revamp notice Starting
 1.1k Jan 2, 2023
1.1k Jan 2, 2023
Simple and rapid application development framework, built on top of Flask. includes detailed security, auto CRUD generation for your models, google charts and much more. Demo (login with guest/welcome) - http://flaskappbuilder.pythonanywhere.com/
Flask App Builder Simple and rapid application development framework, built on top of Flask. includes detailed security, auto CRUD generation for your
 4k Jan 8, 2023
4k Jan 8, 2023
A dynamic FastAPI router that automatically creates CRUD routes for your models
⚡ Create CRUD routes with lighting speed ⚡ A dynamic FastAPI router that automatically creates CRUD routes for your models
950 Jan 8, 2023
Soda SQL Data testing, monitoring and profiling for SQL accessible data.
Soda SQL Data testing, monitoring and profiling for SQL accessible data. What does Soda SQL do? Soda SQL allows you to Stop your pipeline when bad dat
 51 Jan 1, 2023
51 Jan 1, 2023
Automatic SQL injection and database takeover tool
sqlmap sqlmap is an open source penetration testing tool that automates the process of detecting and exploiting SQL injection flaws and taking over of
25.7k Jan 4, 2023
A non-validating SQL parser module for Python
python-sqlparse - Parse SQL statements sqlparse is a non-validating SQL parser for Python. It provides support for parsing, splitting and formatting S
 3.1k Jan 4, 2023
3.1k Jan 4, 2023
Easy-to-use data handling for SQL data stores with support for implicit table creation, bulk loading, and transactions.
dataset: databases for lazy people In short, dataset makes reading and writing data in databases as simple as reading and writing JSON files. Read the
4.2k Dec 26, 2022
Apache Superset is a Data Visualization and Data Exploration Platform
Superset A modern, enterprise-ready business intelligence web application. Why Superset? | Supported Databases | Installation and Configuration | Rele
50k Jan 6, 2023
Serverless proxy for Spark cluster
Hydrosphere Mist Hydrosphere Mist is a serverless proxy for Spark cluster. Mist provides a new functional programming framework and deployment model f
 317 Dec 1, 2022
317 Dec 1, 2022
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
eXtreme Gradient Boosting Community | Documentation | Resources | Contributors | Release Notes XGBoost is an optimized distributed gradient boosting l
23.6k Dec 31, 2022
H2O is an Open Source, Distributed, Fast & Scalable Machine Learning Platform: Deep Learning, Gradient Boosting (GBM) & XGBoost, Random Forest, Generalized Linear Modeling (GLM with Elastic Net), K-Means, PCA, Generalized Additive Models (GAM), RuleFit, Support Vector Machine (SVM), Stacked Ensembles, Automatic Machine Learning (AutoML), etc.
H2O H2O is an in-memory platform for distributed, scalable machine learning. H2O uses familiar interfaces like R, Python, Scala, Java, JSON and the Fl
 6.1k Jan 5, 2023
6.1k Jan 5, 2023

:truck: Agile Data Preparation Workflows made easy with dask, cudf, dask_cudf and pyspark
To launch a live notebook server to test optimus using binder or Colab, click on one of the following badges: Optimus is the missing framework to prof
 1.3k Dec 30, 2022
1.3k Dec 30, 2022