201 Repositories
Python spark-sql Libraries

A data engineering project with Kafka, Spark Streaming, dbt, Docker, Airflow, Terraform, GCP and much more!
Streamify A data pipeline with Kafka, Spark Streaming, dbt, Docker, Airflow, Terraform, GCP and much more! Description Objective The project will stre
 206 Dec 30, 2022
206 Dec 30, 2022

Free Data Engineering course!
Data Engineering Zoomcamp Register in DataTalks.Club's Slack Join the #course-data-engineering channel The videos are published to DataTalks.Club's Yo
 7.3k Dec 30, 2022
7.3k Dec 30, 2022

This repository contains the best Data Science free hand-picked resources to equip you with all the industry-driven skills and interview preparation kit.
Best Data Science Resources Hey, Data Enthusiasts out there! Finally, after lots of requests from the community I finally came up with the best free D
 415 Dec 31, 2022
415 Dec 31, 2022
Write python locally, execute SQL in your data warehouse
RasgoQL Write python locally, execute SQL in your data warehouse ≪ Read the Docs · Join Our Slack » RasgoQL is a Python package that enables you to ea
 265 Nov 21, 2022
265 Nov 21, 2022
Databricks Certified Associate Spark Developer preparation toolkit to setup single node Standalone Spark Cluster along with material in the form of Jupyter Notebooks.
Databricks Certification Spark Databricks Certified Associate Spark Developer preparation toolkit to setup single node Standalone Spark Cluster along
 19 Dec 13, 2022
19 Dec 13, 2022
Containerized Demo of Apache Spark MLlib on a Data Lakehouse (2022)
Spark-DeltaLake-Demo Reliable, Scalable Machine Learning (2022) This project was completed in an attempt to become better acquainted with the latest b
 8 Mar 21, 2022
8 Mar 21, 2022
Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogramas anuais com spark, em pyspark e SQL!
Olá! Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogr
 10 Apr 4, 2022
10 Apr 4, 2022
Weakly Supervised Text-to-SQL Parsing through Question Decomposition
Weakly Supervised Text-to-SQL Parsing through Question Decomposition The official repository for the paper "Weakly Supervised Text-to-SQL Parsing thro
 14 Dec 19, 2022
14 Dec 19, 2022
Makes it easier to write raw SQL in Python.
CoolSQL Makes it easier to write raw SQL in Python. Usage Quick Start from coolsql import Field name = Field("name") age = Field("age") condition =
 7 Aug 21, 2022
7 Aug 21, 2022
An extension package of 🤗 Datasets that provides support for executing arbitrary SQL queries on HF datasets
datasets_sql A 🤗 Datasets extension package that provides support for executing arbitrary SQL queries on HF datasets. It uses DuckDB as a SQL engine
 19 Dec 15, 2022
19 Dec 15, 2022
Dark Finix: All in one hacking framework with almost 100 tools
Dark Finix - Hacking Framework. Dark Finix is a all in one hacking framework wit
 2 Feb 18, 2022
2 Feb 18, 2022

CVE-2022-23046 - SQL Injection Vulnerability on PhpIPAM v1.4.4
CVE-2022-23046 PhpIPAM v1.4.4 allows an authenticated admin user to inject SQL s
 2 Feb 15, 2022
2 Feb 15, 2022

🏅 Top 5% in 제2회 연구개발특구 인공지능 경진대회 AI SPARK 챌린지
AI_SPARK_CHALLENG_Object_Detection 제2회 연구개발특구 인공지능 경진대회 AI SPARK 챌린지 🏅 Top 5% in mAP(0.75) (443명 중 13등, mAP: 0.98116) 대회 설명 Edge 환경에서의 가축 Object Dete
 3 Sep 19, 2022
3 Sep 19, 2022
Definitive Guide to Creating a SQL Database on Cloud with AWS and Python
Definitive Guide to Creating a SQL Database on Cloud with AWS and Python An easy-to-follow comprehensive guide on integrating Amazon RDS, MySQL Workbe
 6 Aug 17, 2022
6 Aug 17, 2022

Generate database table diagram from SQL data definition.
sql2diagram Generate database table diagram from SQL data definition. e.g. "CREATE TABLE ..." See Example below How does it works? Analyze the SQL to
 1 Feb 8, 2022
1 Feb 8, 2022
A data structure that extends pyspark.sql.DataFrame with metadata information.
MetaFrame A data structure that extends pyspark.sql.DataFrame with metadata info
 8 Feb 15, 2022
8 Feb 15, 2022
Projeto de análise de dados com SQL
Project-Analizyng-International-Debt-Statistics- Projeto de análise de dados com SQL - Plataforma Data Camp Descrição do Projeto : Não é que nós human
 1 Feb 1, 2022
1 Feb 1, 2022

PySpark Structured Streaming ROS Kafka ApacheSpark Cassandra
PySpark-Structured-Streaming-ROS-Kafka-ApacheSpark-Cassandra The purpose of this project is to demonstrate a structured streaming pipeline with Apache
 5 Nov 13, 2022
5 Nov 13, 2022
SpyQL - SQL with Python in the middle
SpyQL SQL with Python in the middle Concept SpyQL is a query language that combines: the simplicity and structure of SQL with the power and readabilit
 853 Dec 30, 2022
853 Dec 30, 2022
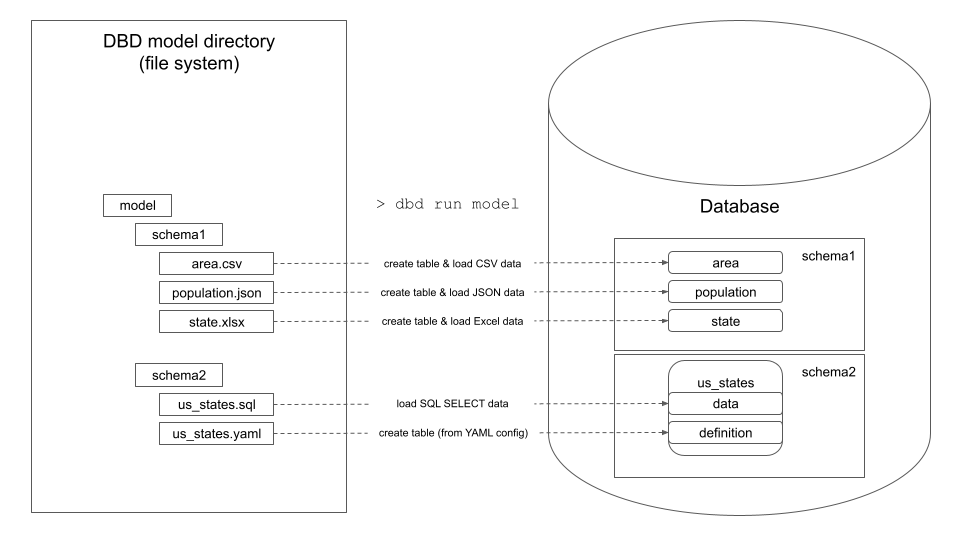
dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL databases.
dbd: database prototyping tool dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL d
 47 Dec 7, 2022
47 Dec 7, 2022
Use SQL query in a jupyter notebook!
SQL-query Use SQL query in a jupyter notebook! The table I used can be found on UN Data. Or you can just click the link and download the file undata_s
 2 Oct 5, 2022
2 Oct 5, 2022
SynapseML - an open source library to simplify the creation of scalable machine learning pipelines
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022

Pizza Orders Data Pipeline Usecase Solved by SQL, Sqoop, HDFS, Hive, Airflow.
PizzaOrders_DataPipeline There is a Tony who is owning a New Pizza shop. He knew that pizza alone was not going to help him get seed funding to expand
 4 Jun 5, 2022
4 Jun 5, 2022

This project is related to a No-SQL database, whose data are referred to autoctone botanic species
This project is related to a No-SQL database, whose data are referred to autoctone botanic species. The final goal is creating a function that performs the estimation of the ornamental value, given the specific characteristics of a single species.
 2 Mar 8, 2022
2 Mar 8, 2022

KivyPassword - A password generator using both Kivy framework and SQL in order to create a local database for users to generate strong passwords and store them
KivyPassword A password generator using both Kivy framework and SQL in order t
 1 Jan 14, 2022
1 Jan 14, 2022
All in One CRACKER911181's Tool. This Tool For Hacking and Pentesting.🎭
This is A Python & Bash Programming Based Termux-Tool Created By CRACKER911181. This Tool Created For Hacking and Pentesting. If You Use This Tool To Evil Purpose,The Owner Will Never be Responsible For That.
 1 Jan 10, 2022
1 Jan 10, 2022

macOS development environment setup: Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process.
dev-setup Motivation Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process. dev-setup aims to simplify the process w
 5.9k Jan 2, 2023
5.9k Jan 2, 2023
A Time Series Library for Apache Spark
Flint: A Time Series Library for Apache Spark The ability to analyze time series data at scale is critical for the success of finance and IoT applicat
 970 Jan 4, 2023
970 Jan 4, 2023
Import entity definition document into SQLie3. Manage the entity. Also, create a "Create Table SQL file".
EntityDocumentMaker Version 1.00 After importing the entity definition (Excel file), store the data in sqlite3. エンティティ定義(Excelファイル)をインポートした後、データをsqlit
 1 Jan 9, 2022
1 Jan 9, 2022
SQL centered, docker process running game
REQUIREMENTS Linux Docker Python/bash set up image "docker build -t game ." create db container "run my_whatever/game_docker/pdb create" # creating po
 1 Jan 11, 2022
1 Jan 11, 2022
Apache Spark & Python (pySpark) tutorials for Big Data Analysis and Machine Learning as IPython / Jupyter notebooks
Spark Python Notebooks This is a collection of IPython notebook/Jupyter notebooks intended to train the reader on different Apache Spark concepts, fro
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Logica is a logic programming language that compiles to StandardSQL and runs on Google BigQuery.
Logica: language of Big Data Logica is an open source declarative logic programming language for data manipulation. Logica is a successor to Yedalog,
 1.5k Dec 30, 2022
1.5k Dec 30, 2022
Distributed deep learning on Hadoop and Spark clusters.
Note: we're lovingly marking this project as Archived since we're no longer supporting it. You are welcome to read the code and fork your own version
 1.3k Dec 28, 2022
1.3k Dec 28, 2022

A SQL linter and auto-formatter for Humans
The SQL Linter for Humans SQLFluff is a dialect-flexible and configurable SQL linter. Designed with ELT applications in mind, SQLFluff also works with
 5.5k Jan 8, 2023
5.5k Jan 8, 2023
MongoDB-Injection - This challenge-script is custom-made for web-server running MongoDB which is vulnerable to No-SQL injection
MongoDB-Injection Cheesy Multi-threaded script for NoSQL Injection This challeng
 2 Jun 6, 2022
2 Jun 6, 2022
GroupMenter : New Telegram Group Manager Bot🔸Fast 🔸Python🔸Pyrogram 🔸
GroupMenter An PowerFull Group Manager Bot. Written In Pytelethon. Info • A modular Telegram Python bot running on python3. • Can be found on telegram
 24 Jun 28, 2022
24 Jun 28, 2022

BigDL - Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems
Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems.
 1 Jan 6, 2022
1 Jan 6, 2022
aiosql - Simple SQL in Python
aiosql - Simple SQL in Python SQL is code. Write it, version control it, comment it, and run it using files. Writing your SQL code in Python programs
 1.1k Jan 8, 2023
1.1k Jan 8, 2023
Simplest SQL mapper in Python, probably
SQL MAPPER Basically what it does is: it executes some SQL thru a database connector you fed it, maps it to some model and gives to u. Also it can cre
 2 Nov 7, 2022
2 Nov 7, 2022

Catalogue CRUD Application
This Python program creates a relational SQL database hosted on the Snowflake platform, then opens a CRUD GUI to manipulate and view the data. In this application, it is used as a book catalogue. CURRENTLY WIP
 0 Dec 13, 2022
0 Dec 13, 2022
Spark-movie-lens - An on-line movie recommender using Spark, Python Flask, and the MovieLens dataset
A scalable on-line movie recommender using Spark and Flask This Apache Spark tutorial will guide you step-by-step into how to use the MovieLens datase
794 Dec 23, 2022

Use Jupyter Notebooks to demonstrate how to build a Recommender with Apache Spark & Elasticsearch
Recommendation engines are one of the most well known, widely used and highest value use cases for applying machine learning. Despite this, while there are many resources available for the basics of training a recommendation model, there are relatively few that explain how to actually deploy these models to create a large-scale recommender system.
 793 Dec 18, 2022
793 Dec 18, 2022
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
 5 Sep 28, 2022
5 Sep 28, 2022
The Python SQL Toolkit and Object Relational Mapper
SQLAlchemy The Python SQL Toolkit and Object Relational Mapper Introduction SQLAlchemy is the Python SQL toolkit and Object Relational Mapper that giv
 3.5k Dec 29, 2022
3.5k Dec 29, 2022

Faza - Faza terminal, Faza help to beginners for pen testing
Faza terminal simple tool for pen testers Use small letter only for commands Don't use space after command 'help' for more information Installation gi
 5 Feb 20, 2022
5 Feb 20, 2022
RestApi_flask_sql.alchemy - Product REST API With Flask & SQL Alchemy
REST API With Flask & SQL Alchemy Products API using Python Flask, SQL Alchemy and Marshmallow Quick Start Using Pipenv # Activate venv $ pipenv shell
 1 Jan 1, 2022
1 Jan 1, 2022
City-seeds - A random generator of cultural characteristics intended to spark ideas and help draw threads
City Seeds This is a random generator of cultural characteristics intended to sp
 2 Mar 12, 2022
2 Mar 12, 2022

Second version of SQL-PYTHON-Practicas
SQLite-Python Acerca de | Autor Sobre el repositorio Segunda version de SQL-PYTHON-Practicas 💻 Tecnologias Visual Studio Code Python SQLite3 📖 Requi
 1 Jan 6, 2022
1 Jan 6, 2022
A quick reference guide to the most commonly used patterns and functions in PySpark SQL
Using PySpark we can process data from Hadoop HDFS, AWS S3, and many file systems. PySpark also is used to process real-time data using Streaming and
 53 Dec 21, 2022
53 Dec 21, 2022
A blind SQL injection script that uses binary search aka bisection method to dump datas from database.
Blind SQL Injection I wrote this script to solve PortSwigger Web Security Academy's particular Blind SQL injection with conditional responses lab. Bec
 2 Oct 29, 2022
2 Oct 29, 2022

This mini project showcase how to build and debug Apache Spark application using Python
Spark app can't be debugged using normal procedure. This mini project showcase how to build and debug Apache Spark application using Python programming language. There are also options to run Spark application on Spark container
 1 Dec 29, 2021
1 Dec 29, 2021
Automate SQL Jobs Monitoring with python
Automate_SQLJobsMonitoring_python Using python 3rd party modules we can automate
 1 Dec 27, 2021
1 Dec 27, 2021
Pandas and Spark DataFrame comparison for humans
DataComPy DataComPy is a package to compare two Pandas DataFrames. Originally started to be something of a replacement for SAS's PROC COMPARE for Pand
 259 Dec 24, 2022
259 Dec 24, 2022
A collection of awesome sqlite tools, scripts, books, etc
Awesome Series @ Planet Open Data World (Countries, Cities, Codes, ...) • Football (Clubs, Players, Stadiums, ...) • SQLite (Tools, Books, Schemas, ..
 205 Dec 16, 2022
205 Dec 16, 2022
Make Your Company Data Driven. Connect to any data source, easily visualize, dashboard and share your data.
Redash is designed to enable anyone, regardless of the level of technical sophistication, to harness the power of data big and small. SQL users levera
 22.4k Dec 30, 2022
22.4k Dec 30, 2022
Monitor the stability of a pandas or spark dataframe ⚙︎
Population Shift Monitoring popmon is a package that allows one to check the stability of a dataset. popmon works with both pandas and spark datasets.
 403 Dec 7, 2022
403 Dec 7, 2022
blind SQLIpy sebuah alat injeksi sql yang menggunakan waktu sql untuk mendapatkan sebuah server database.
blind SQLIpy Alat blind SQLIpy ini merupakan alat injeksi sql yang menggunakan metode time based blind sql injection metode tersebut membutuhkan waktu
 4 Feb 24, 2022
4 Feb 24, 2022
Implementation of K-Nearest Neighbors Algorithm Using PySpark
KNN With Spark Implementation of KNN using PySpark. The KNN was used on two separate datasets (https://archive.ics.uci.edu/ml/datasets/iris and https:
 4 Dec 30, 2022
4 Dec 30, 2022

That is a example of a Book app on Python, made with support of all JS libraries on React framework
React+Python Books App You can use this repository whenever you want Used for a video Create the database: python -m dbutils Start the web server: pyt
 1 Apr 20, 2022
1 Apr 20, 2022
Apache (Py)Spark type annotations (stub files).
PySpark Stubs A collection of the Apache Spark stub files. These files were generated by stubgen and manually edited to include accurate type hints. T
 114 Nov 22, 2022
114 Nov 22, 2022
Mypy plugin and stubs for SQLAlchemy
Mypy plugin and stubs for SQLAlchemy This package contains type stubs and a mypy plugin to provide more precise static types and type inference for SQ
 521 Dec 29, 2022
521 Dec 29, 2022

Estoult - a Python toolkit for data mapping with an integrated query builder for SQL databases
Estoult Estoult is a Python toolkit for data mapping with an integrated query builder for SQL databases. It currently supports MySQL, PostgreSQL, and
![halcyon[nouveau]](https://avatars.githubusercontent.com/u/49960726?v=4&s=60) 15 Dec 29, 2022
15 Dec 29, 2022
Pyspark project that able to do joins on the spark data frames.
SPARK JOINS This project is to perform inner, all outer joins and semi joins. create_df.py: load_data.py : helps to put data into Spark data frames. d
 1 Dec 14, 2021
1 Dec 14, 2021
Making it easy to query APIs via SQL
Shillelagh Shillelagh (ʃɪˈleɪlɪ) is an implementation of the Python DB API 2.0 based on SQLite (using the APSW library): from shillelagh.backends.apsw
 207 Dec 30, 2022
207 Dec 30, 2022

Delta Sharing: An Open Protocol for Secure Data Sharing
Delta Sharing: An Open Protocol for Secure Data Sharing Delta Sharing is an open protocol for secure real-time exchange of large datasets, which enabl
 497 Jan 2, 2023
497 Jan 2, 2023
Microsoft Azure provides a wide number of services for managing and storing data
Microsoft Azure provides a wide number of services for managing and storing data. One product is Microsoft Azure SQL. Which gives us the capability to create and manage instances of SQL Servers hosted in the cloud. This project, demonstrates how to use these services to manage data we collect from different sources.
 1 Dec 12, 2021
1 Dec 12, 2021
A database migrations tool for SQLAlchemy.
Alembic is a database migrations tool written by the author of SQLAlchemy. A migrations tool offers the following functionality: Can emit ALTER statem
 1.7k Jan 1, 2023
1.7k Jan 1, 2023
Records is a very simple, but powerful, library for making raw SQL queries to most relational databases.
Records: SQL for Humans™ Records is a very simple, but powerful, library for making raw SQL queries to most relational databases. Just write SQL. No b
 6.9k Jan 3, 2023
6.9k Jan 3, 2023
A Python DB-API and SQLAlchemy dialect to Google Spreasheets
Note: shillelagh is a drop-in replacement for gsheets-db-api, with many additional features. You should use it instead. If you're using SQLAlchemy all
185 Jan 1, 2023

FollowSpot is a comprehensive audition tracking fullstack web application for entertainment industry professionals.
FollowSpot is a comprehensive audition tracking fullstack web application for entertainment industry professionals. This app allows users to store information/media for all of their auditions while also compiling data and displaying statistics to help track progress.
 9 Jul 12, 2022
9 Jul 12, 2022
The Spark Challenge Student Check-In/Out Tracking Script
The Spark Challenge Student Check-In/Out Tracking Script This Python Script uses the Student ID Database to match the entries with the ID Card Swipe a
 1 Dec 9, 2021
1 Dec 9, 2021

Reading streams of Twitter data, save them to Kafka, then process with Kafka Stream API and Spark Streaming
Using Streaming Twitter Data with Kafka and Spark Reading streams of Twitter data, publishing them to Kafka topic, process message using Kafka Stream
 1 Dec 6, 2021
1 Dec 6, 2021
Script to generate a massive volume of data in sql, csv, json or xml format
DataGenerator Made with Python Open for pull requests 1. Dependencies To install required dependencies run pip install -r requirements.txt 2. Executi
 3 Sep 20, 2022
3 Sep 20, 2022

Bancos de Dados Relacionais (SQL) na AWS com Amazon RDS.
Bancos de Dados Relacionais (SQL) na AWS com Amazon RDS Explorando o Amazon RDS, um serviço de provisionamente e gerenciamento de banco de dados relac
 1 Dec 5, 2021
1 Dec 5, 2021
Given a metadata file with relevant schema, an SQL Engine can be run for a subset of SQL queries.
Mini-SQL-Engine Given a metadata file with relevant schema, an SQL Engine can be run for a subset of SQL queries. The query engine supports Project, A
 1 Dec 3, 2021
1 Dec 3, 2021

Some scripts for microsoft SQL server in old version.
MSSQL_Stuff Some scripts for microsoft SQL server which is in old version. Table of content Overview Usage References Overview These script works when
 5 Dec 29, 2022
5 Dec 29, 2022
Databank is an easy-to-use Python library for making raw SQL queries in a multi-threaded environment.
Databank Databank is an easy-to-use Python library for making raw SQL queries in a multi-threaded environment. No ORM, no frills. Thread-safe. Only ra
 4 Apr 4, 2022
4 Apr 4, 2022
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
3.9k Dec 30, 2022

Just another script for automatize boolean-based blind SQL injections.
SQL Blind Injection Tool A script for automatize boolean-based blind SQL injections. Works with SQLite at least, supports using cookies. It uses bitwi
 51 Dec 15, 2022
51 Dec 15, 2022
Deep Learning Pipelines for Apache Spark
Deep Learning Pipelines for Apache Spark The repo only contains HorovodRunner code for local CI and API docs. To use HorovodRunner for distributed tra
 2k Jan 8, 2023
2k Jan 8, 2023

Blinder is a tool that will help you simplify the exploitation of blind SQL injection
Blinder Have you found a blind SQL injection? Great! Now you need to export it, but are you too lazy to sort through the values? Most likely,
 10 Dec 6, 2022
10 Dec 6, 2022
Python script to clone SQL dashboard from one workspace to another
Databricks dashboard clone Unofficial project to allow Databricks SQL dashboard copy from one workspace to another. Resource clone Setup: Create a fil
 12 Jan 1, 2023
12 Jan 1, 2023
Bancos de Dados Relacionais (SQL) na AWS com Amazon RDS
Bancos de Dados Relacionais (SQL) na AWS com Amazon RDS Repositório para o Live Coding DIO do dia 24/11/2021 Serviços utilizados Amazon RDS AWS Lambda
 4 Jul 30, 2022
4 Jul 30, 2022
Code base of KU AIRS: SPARK Autonomous Vehicle Team
KU AIRS: SPARK Autonomous Vehicle Project Check this link for the blog post describing this project and the video of SPARK in simulation and on parkou
 1 Nov 23, 2021
1 Nov 23, 2021

 17 Nov 30, 2022
17 Nov 30, 2022
Building house price data pipelines with Apache Beam and Spark on GCP
This project contains the process from building a web crawler to extract the raw data of house price to create ETL pipelines using Google Could Platform services.
 1 Nov 22, 2021
1 Nov 22, 2021
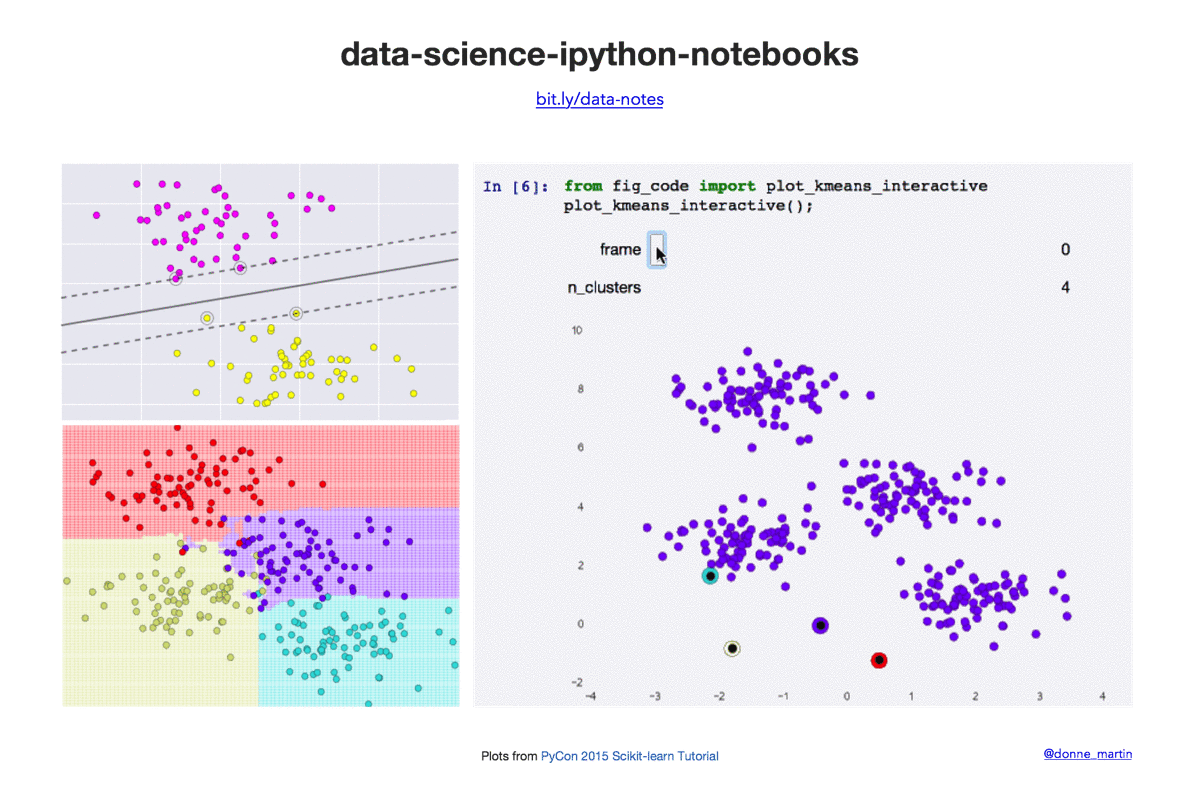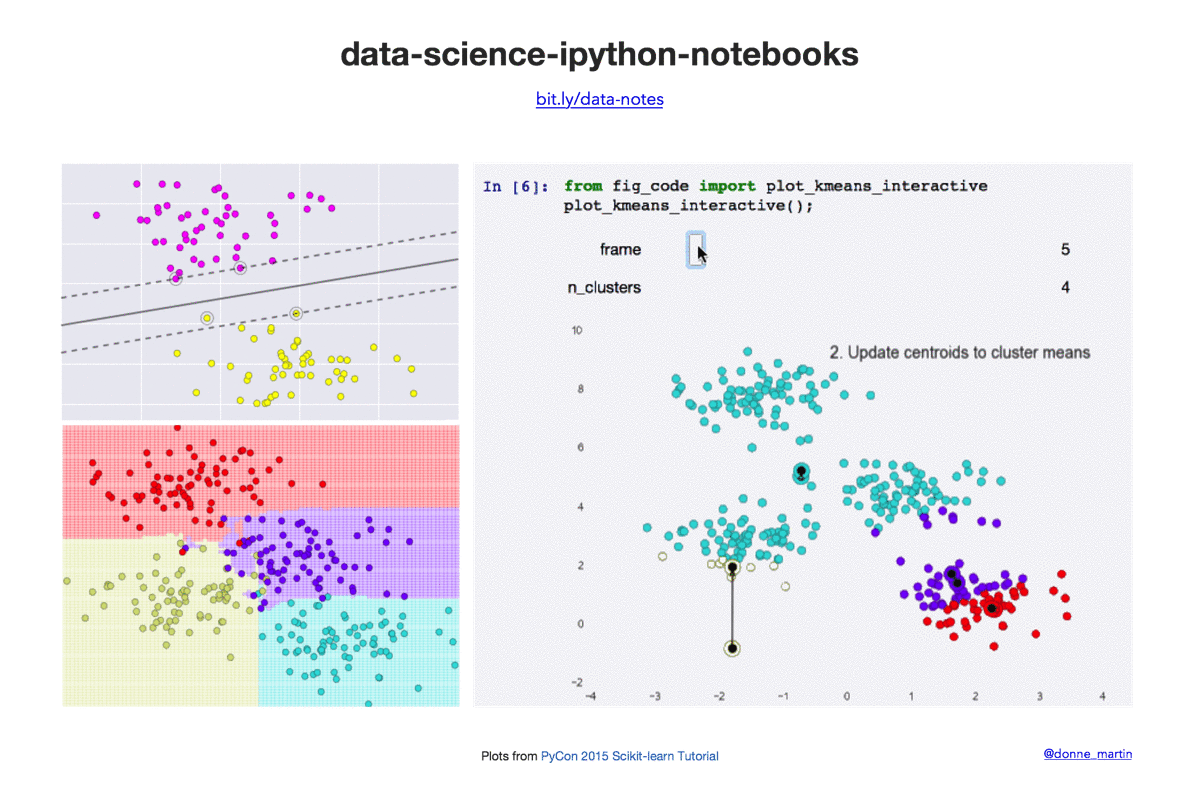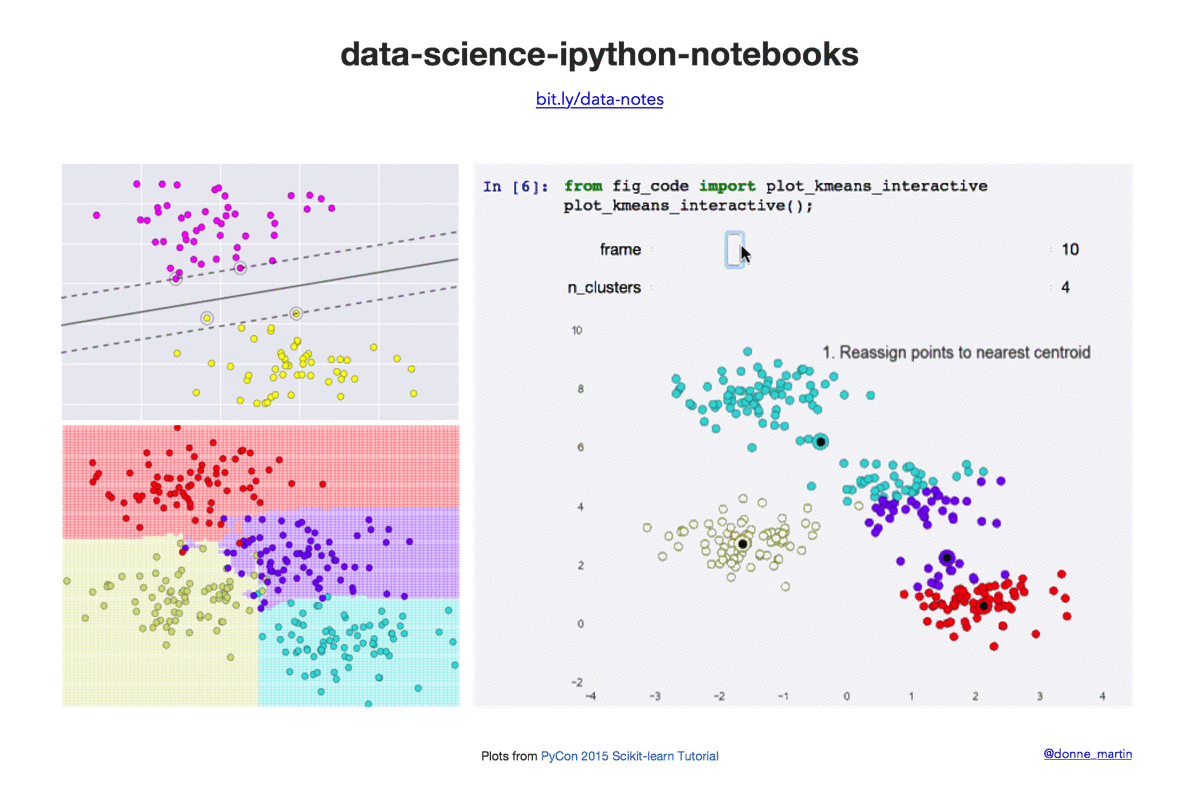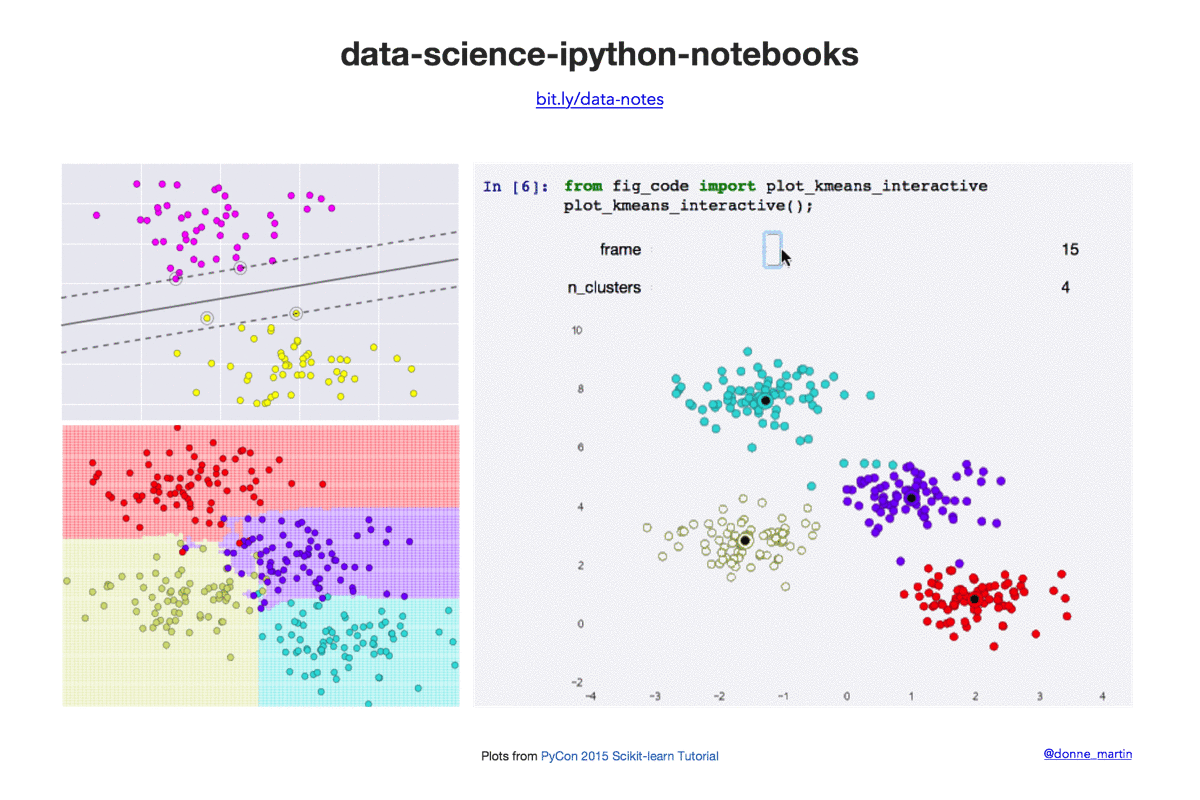
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
24.5k Jan 9, 2023

List of Data Science Cheatsheets to rule the world
Data Science Cheatsheets List of Data Science Cheatsheets to rule the world. Table of Contents Business Science Business Science Problem Framework Dat
 11.7k Dec 30, 2022
11.7k Dec 30, 2022

Sentiment analysis on streaming twitter data using Spark Structured Streaming & Python
Sentiment analysis on streaming twitter data using Spark Structured Streaming & Python This project is a good starting point for those who have little
 2 Dec 4, 2021
2 Dec 4, 2021
REST API with FastAPI and PostgreSQL
REST API with FastAPI and PostgreSQL To have the same data in db: create table CLIENT_DATA (id SERIAL PRIMARY KEY, fullname VARCHAR(50) NOT NULL,email
 1 Nov 11, 2021
1 Nov 11, 2021

 3 Dec 16, 2022
3 Dec 16, 2022
Introduction to Databases Coursework 2 (SQL) - dataset generator
Introduction to Databases Coursework 2 (SQL) - dataset generator This is python script generates a text file with insert queries for the schema.sql fi
 1 Nov 8, 2021
1 Nov 8, 2021
edaSQL is a library to link SQL to Exploratory Data Analysis and further more in the Data Engineering.
edaSQL is a python library to bridge the SQL with Exploratory Data Analysis where you can connect to the Database and insert the queries. The query results can be passed to the EDA tool which can give greater insights to the user.
 8 Dec 12, 2022
8 Dec 12, 2022
Sqli-Scanner is a python3 script written to scan websites for SQL injection vulnerabilities
Sqli-Scanner is a python3 script written to scan websites for SQL injection vulnerabilities Features 1 Scan one website 2 Scan multiple websites Insta
 9 Dec 30, 2022
9 Dec 30, 2022
A GUI love Calculator which saves all the User Data in text file(sql based script will be uploaded soon). Interative GUI. Even For Admin Panel
Love-Calculator A GUI love Calculator which saves all the User Data in text file(sql based script will be uploaded soon). Interative GUI, even For Adm
 1 Mar 22, 2022
1 Mar 22, 2022

This creates a ohlc timeseries from downloaded CSV files from NSE India website and makes a SQLite database for your research.
NSE-timeseries-form-CSV-file-creator-and-SQL-appender- This creates a ohlc timeseries from downloaded CSV files from National Stock Exchange India (NS
 1 Oct 2, 2022
1 Oct 2, 2022
The Timescale NFT Starter Kit is a step-by-step guide to get up and running with collecting, storing, analyzing and visualizing NFT data from OpenSea, using PostgreSQL and TimescaleDB.
Timescale NFT Starter Kit The Timescale NFT Starter Kit is a step-by-step guide to get up and running with collecting, storing, analyzing and visualiz
 102 Dec 24, 2022
102 Dec 24, 2022
A selection of SQLite3 databases to practice querying from.
Dummy SQL Databases This is a collection of dummy SQLite3 databases, for learning and practicing SQL querying, generated with the VS Code extension Ge
 1 Feb 26, 2022
1 Feb 26, 2022
Instant search for and access to many datasets in Pyspark.
SparkDataset Provides instant access to many datasets right from Pyspark (in Spark DataFrame structure). Drop a star if you like the project. 😃 Motiv
 31 Dec 16, 2022
31 Dec 16, 2022