99 Repositories
Python spark-cassandra-connector Libraries

A data engineering project with Kafka, Spark Streaming, dbt, Docker, Airflow, Terraform, GCP and much more!
Streamify A data pipeline with Kafka, Spark Streaming, dbt, Docker, Airflow, Terraform, GCP and much more! Description Objective The project will stre
 206 Dec 30, 2022
206 Dec 30, 2022

All materials of Cassandra Event, Udyam'22
Cassandra 2022 Workspace Workshop Materials Workshop-1 Workshop-2 Workshop-3 Workshop-4 Assignments Assignment-1 Assignment-2 Assignment-3 Resources P
 36 Dec 31, 2022
36 Dec 31, 2022

Free Data Engineering course!
Data Engineering Zoomcamp Register in DataTalks.Club's Slack Join the #course-data-engineering channel The videos are published to DataTalks.Club's Yo
 7.3k Dec 30, 2022
7.3k Dec 30, 2022

Python library to receive live stream events like comments and gifts in realtime from TikTok LIVE.
TikTokLive A python library to connect to and read events from TikTok's LIVE service A python library to receive and decode livestream events such as
 277 Dec 23, 2022
277 Dec 23, 2022
Databricks Certified Associate Spark Developer preparation toolkit to setup single node Standalone Spark Cluster along with material in the form of Jupyter Notebooks.
Databricks Certification Spark Databricks Certified Associate Spark Developer preparation toolkit to setup single node Standalone Spark Cluster along
 19 Dec 13, 2022
19 Dec 13, 2022
Containerized Demo of Apache Spark MLlib on a Data Lakehouse (2022)
Spark-DeltaLake-Demo Reliable, Scalable Machine Learning (2022) This project was completed in an attempt to become better acquainted with the latest b
 8 Mar 21, 2022
8 Mar 21, 2022
Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogramas anuais com spark, em pyspark e SQL!
Olá! Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogr
 10 Apr 4, 2022
10 Apr 4, 2022
We’re releasing an open-source tool you can use now, which we developed as a homemade Just-In-Time database access control tool for our sensitive database. This tool syncs with our directory service, slack, SIEM, and finally, our Apache Cassandra database.
Cassandra Access Control By Aner Izraeli - Intezer Security Manager ([email protected]) We’re releasing an open-source tool you can use now, which
 6 Mar 31, 2022
6 Mar 31, 2022

🏅 Top 5% in 제2회 연구개발특구 인공지능 경진대회 AI SPARK 챌린지
AI_SPARK_CHALLENG_Object_Detection 제2회 연구개발특구 인공지능 경진대회 AI SPARK 챌린지 🏅 Top 5% in mAP(0.75) (443명 중 13등, mAP: 0.98116) 대회 설명 Edge 환경에서의 가축 Object Dete
 3 Sep 19, 2022
3 Sep 19, 2022
Web3 Solidity Connector
With this project, you can compile your sol files and create new transactions including creating contract and calling the state changer functions. You can integrate integrate your sol files with Python and you can call functions with using Python.
 3 Oct 9, 2022
3 Oct 9, 2022
A data structure that extends pyspark.sql.DataFrame with metadata information.
MetaFrame A data structure that extends pyspark.sql.DataFrame with metadata info
 8 Feb 15, 2022
8 Feb 15, 2022

PySpark Structured Streaming ROS Kafka ApacheSpark Cassandra
PySpark-Structured-Streaming-ROS-Kafka-ApacheSpark-Cassandra The purpose of this project is to demonstrate a structured streaming pipeline with Apache
 5 Nov 13, 2022
5 Nov 13, 2022

HA-Edge-Connector - HA Edge Connector For Python
HA-Edge-Connector 1. Required a. Smartthings Hub & Homeassistant must be in same
 21 Dec 29, 2022
21 Dec 29, 2022
SynapseML - an open source library to simplify the creation of scalable machine learning pipelines
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
MariaDB connector using python and flask
MariaDB connector using python and flask This should work with flask and to be deployed on docker. Setting up stuff 1. Docker build and run docker bui
 1 Jan 11, 2022
1 Jan 11, 2022

macOS development environment setup: Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process.
dev-setup Motivation Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process. dev-setup aims to simplify the process w
 5.9k Jan 2, 2023
5.9k Jan 2, 2023
A Time Series Library for Apache Spark
Flint: A Time Series Library for Apache Spark The ability to analyze time series data at scale is critical for the success of finance and IoT applicat
 970 Jan 4, 2023
970 Jan 4, 2023
Apache Spark & Python (pySpark) tutorials for Big Data Analysis and Machine Learning as IPython / Jupyter notebooks
Spark Python Notebooks This is a collection of IPython notebook/Jupyter notebooks intended to train the reader on different Apache Spark concepts, fro
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Distributed deep learning on Hadoop and Spark clusters.
Note: we're lovingly marking this project as Archived since we're no longer supporting it. You are welcome to read the code and fork your own version
 1.3k Dec 28, 2022
1.3k Dec 28, 2022

BigDL - Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems
Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems.
 1 Jan 6, 2022
1 Jan 6, 2022
Spark-movie-lens - An on-line movie recommender using Spark, Python Flask, and the MovieLens dataset
A scalable on-line movie recommender using Spark and Flask This Apache Spark tutorial will guide you step-by-step into how to use the MovieLens datase
794 Dec 23, 2022

Use Jupyter Notebooks to demonstrate how to build a Recommender with Apache Spark & Elasticsearch
Recommendation engines are one of the most well known, widely used and highest value use cases for applying machine learning. Despite this, while there are many resources available for the basics of training a recommendation model, there are relatively few that explain how to actually deploy these models to create a large-scale recommender system.
 793 Dec 18, 2022
793 Dec 18, 2022
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
 5 Sep 28, 2022
5 Sep 28, 2022
City-seeds - A random generator of cultural characteristics intended to spark ideas and help draw threads
City Seeds This is a random generator of cultural characteristics intended to sp
 2 Mar 12, 2022
2 Mar 12, 2022
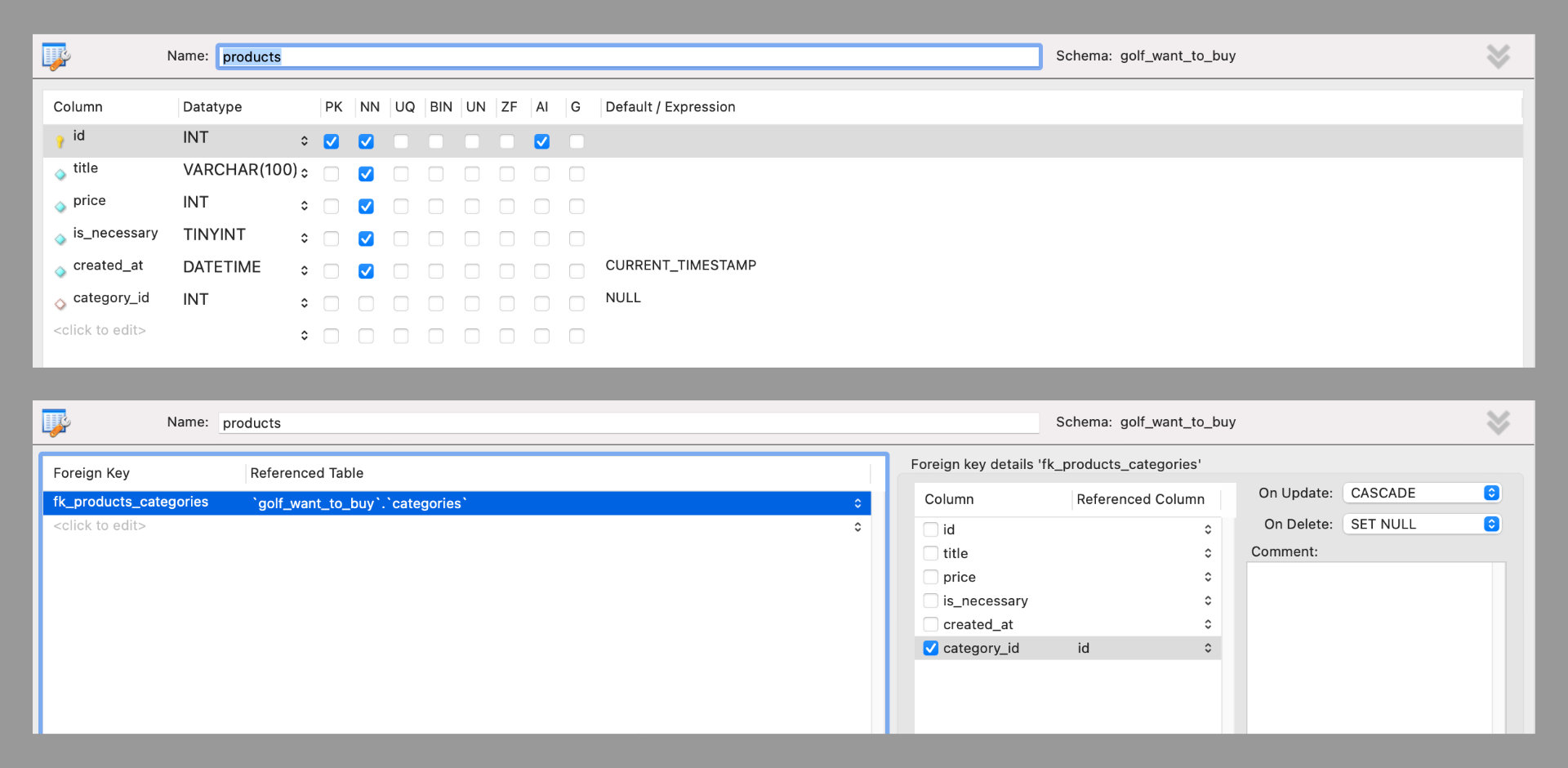
Example Python codes that works with MySQL and Excel files (.xlsx)
Python x MySQL x Excel by Zinglecode Example Python codes that do the processes between MySQL database and Excel spreadsheet files. YouTube videos MyS
 1 Feb 7, 2022
1 Feb 7, 2022

This mini project showcase how to build and debug Apache Spark application using Python
Spark app can't be debugged using normal procedure. This mini project showcase how to build and debug Apache Spark application using Python programming language. There are also options to run Spark application on Spark container
 1 Dec 29, 2021
1 Dec 29, 2021
A simple api written in python/fastapi that serves movies from a cassandra table.
A simple api written in python/fastapi that serves movies from a cassandra table. 1)clone the repo 2)rename sample_global_config_.py to global_config.
 1 Aug 26, 2021
1 Aug 26, 2021
Pandas and Spark DataFrame comparison for humans
DataComPy DataComPy is a package to compare two Pandas DataFrames. Originally started to be something of a replacement for SAS's PROC COMPARE for Pand
 259 Dec 24, 2022
259 Dec 24, 2022
Telephus is a connection pooled, low-level client API for Cassandra in Twisted python.
Telephus Son of Heracles who loved Cassandra. He went a little crazy, at one point. One might almost say he was twisted. Description Telephus is a con
 93 Apr 29, 2021
93 Apr 29, 2021
Create a Video Membership app using FastAPI & NoSQL
Video Membership Create a Video Membership app using FastAPI & NoSQL. In this series, we're going to explore building a membership application using F
 69 Dec 25, 2022
69 Dec 25, 2022
Make Your Company Data Driven. Connect to any data source, easily visualize, dashboard and share your data.
Redash is designed to enable anyone, regardless of the level of technical sophistication, to harness the power of data big and small. SQL users levera
 22.4k Dec 30, 2022
22.4k Dec 30, 2022
Monitor the stability of a pandas or spark dataframe ⚙︎
Population Shift Monitoring popmon is a package that allows one to check the stability of a dataset. popmon works with both pandas and spark datasets.
 403 Dec 7, 2022
403 Dec 7, 2022
Implementation of K-Nearest Neighbors Algorithm Using PySpark
KNN With Spark Implementation of KNN using PySpark. The KNN was used on two separate datasets (https://archive.ics.uci.edu/ml/datasets/iris and https:
 4 Dec 30, 2022
4 Dec 30, 2022

A web application (with multiple API project options) that uses MariaDB HTAP!
Bookings Bookings is a web application that, backed by the power of the MariaDB Connectors and the MariaDB X4 Platform, unleashes the power of smart t
 4 Dec 28, 2022
4 Dec 28, 2022

Travis CI testing a Dockerfile based on Palantir's remix of Apache Cassandra, testing IaC, and testing integration health of Debian
Testing Palantir's remix of Apache Cassandra with Snyk & Travis CI This repository is to show Travis CI testing a Dockerfile based on Palantir's remix
 1 Dec 20, 2021
1 Dec 20, 2021
Apache (Py)Spark type annotations (stub files).
PySpark Stubs A collection of the Apache Spark stub files. These files were generated by stubgen and manually edited to include accurate type hints. T
 114 Nov 22, 2022
114 Nov 22, 2022

A real-time financial data streaming pipeline and visualization platform using Apache Kafka, Cassandra, and Bokeh.
Realtime Financial Market Data Visualization and Analysis Introduction This repo shows my project about real-time stock data pipeline. All the code is
 6 Sep 7, 2022
6 Sep 7, 2022
Pyspark project that able to do joins on the spark data frames.
SPARK JOINS This project is to perform inner, all outer joins and semi joins. create_df.py: load_data.py : helps to put data into Spark data frames. d
 1 Dec 14, 2021
1 Dec 14, 2021

Delta Sharing: An Open Protocol for Secure Data Sharing
Delta Sharing: An Open Protocol for Secure Data Sharing Delta Sharing is an open protocol for secure real-time exchange of large datasets, which enabl
 497 Jan 2, 2023
497 Jan 2, 2023
SAP HANA Connector in pure Python
SAP HANA Database Client for Python Important Notice This public repository is read-only and no longer maintained. The active maintained alternative i
 299 Nov 20, 2022
299 Nov 20, 2022

🔥 Campus-Run Django Server🔥
🏫 Campus-Run Campus-Run is a 3D racing game set on a college campus. Designed this service to comfort university students who are unable to visit the
 1 Feb 8, 2022
1 Feb 8, 2022
Logo DYS (Doküman Yönetim Sitemi) API Python Implementation
dys-connector Logo DYS (Dokuman Yonetim Sistemi) API Python Implementation Python Package: https://pypi.org/project/dys-connector Quick Start from dys
 8 Mar 19, 2022
8 Mar 19, 2022
The Spark Challenge Student Check-In/Out Tracking Script
The Spark Challenge Student Check-In/Out Tracking Script This Python Script uses the Student ID Database to match the entries with the ID Card Swipe a
 1 Dec 9, 2021
1 Dec 9, 2021

Reading streams of Twitter data, save them to Kafka, then process with Kafka Stream API and Spark Streaming
Using Streaming Twitter Data with Kafka and Spark Reading streams of Twitter data, publishing them to Kafka topic, process message using Kafka Stream
 1 Dec 6, 2021
1 Dec 6, 2021
FHEM Connector for FHT Heating devices
home-assistant-fht from: https://github.com/Rsclub22 FHEM Connector for FHT Heating devices (connected via FHEM) Requires FHEM to work You can find FH
 5 Dec 1, 2022
5 Dec 1, 2022
A robust, low-level connector for the Discord API
Bauxite Bauxite is a robust, low-level connector for the Discord API. What is Bauxite for? Bauxite is made for two main purposes: Creating higher-leve
 1 Dec 4, 2021
1 Dec 4, 2021
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
3.9k Dec 30, 2022
Deep Learning Pipelines for Apache Spark
Deep Learning Pipelines for Apache Spark The repo only contains HorovodRunner code for local CI and API docs. To use HorovodRunner for distributed tra
 2k Jan 8, 2023
2k Jan 8, 2023
Code base of KU AIRS: SPARK Autonomous Vehicle Team
KU AIRS: SPARK Autonomous Vehicle Project Check this link for the blog post describing this project and the video of SPARK in simulation and on parkou
 1 Nov 23, 2021
1 Nov 23, 2021
Building house price data pipelines with Apache Beam and Spark on GCP
This project contains the process from building a web crawler to extract the raw data of house price to create ETL pipelines using Google Could Platform services.
 1 Nov 22, 2021
1 Nov 22, 2021
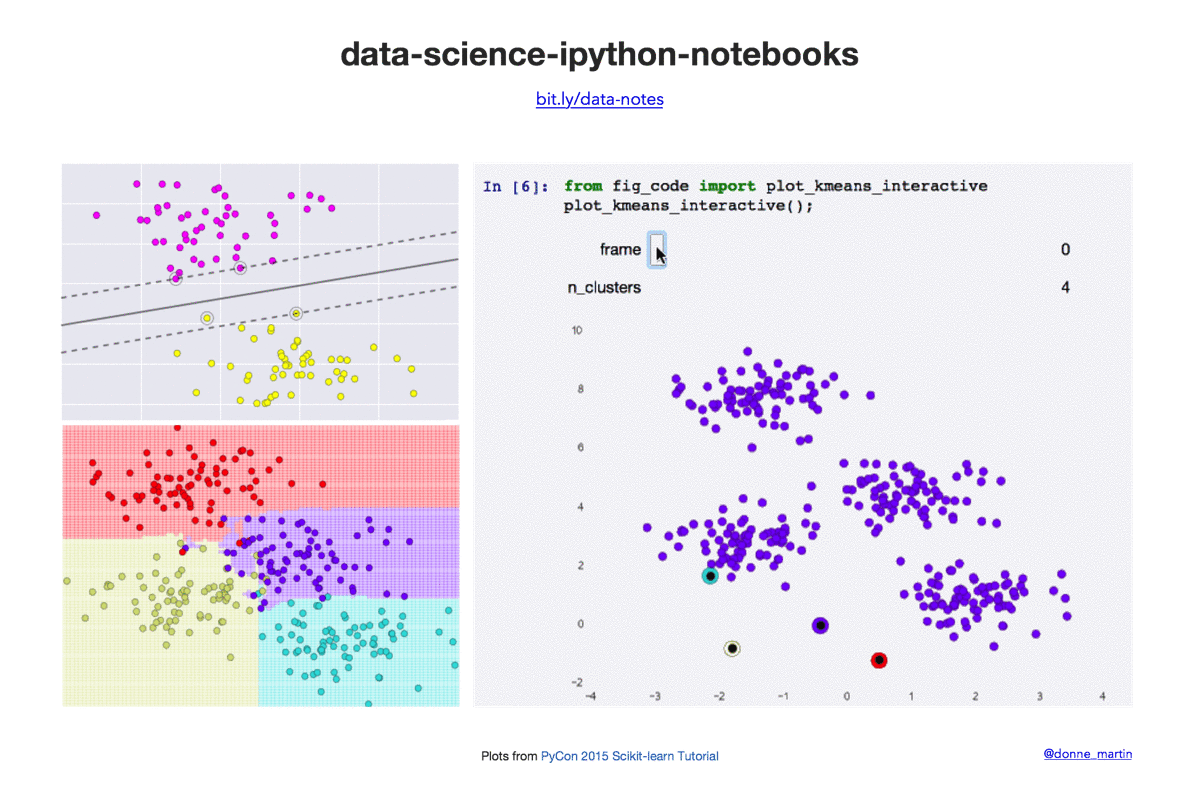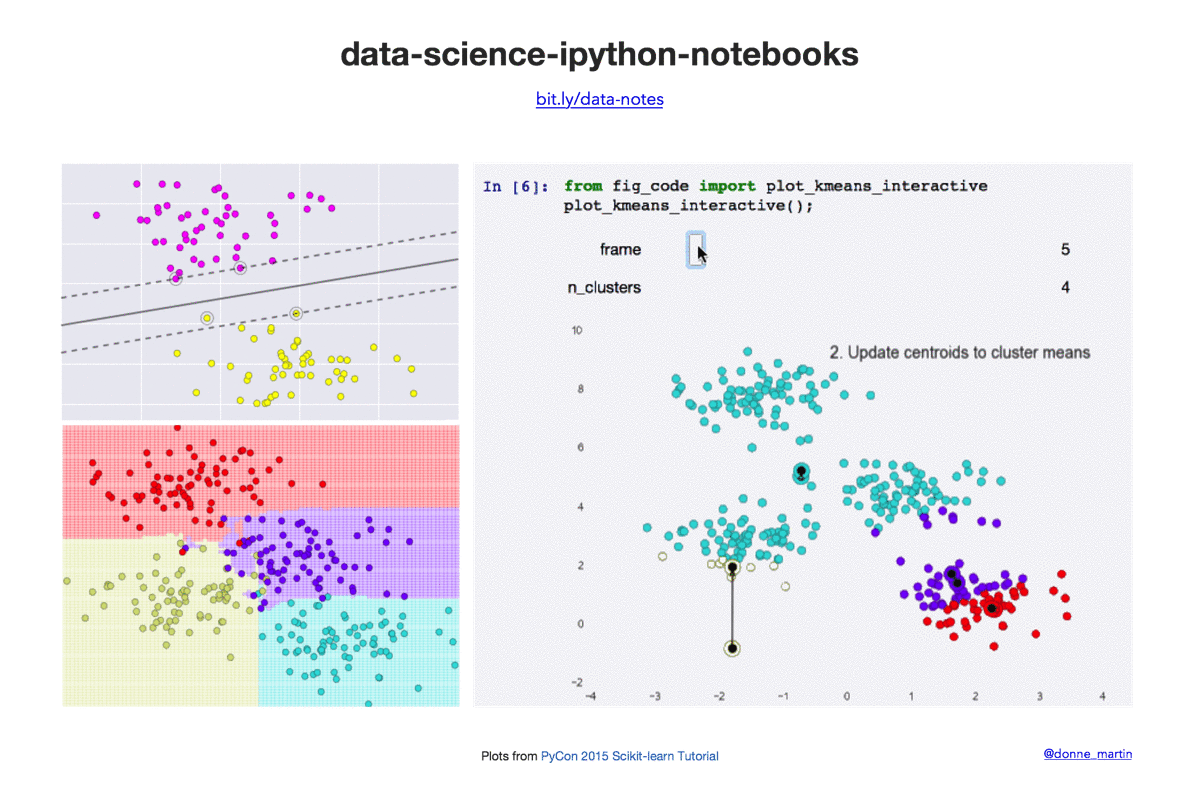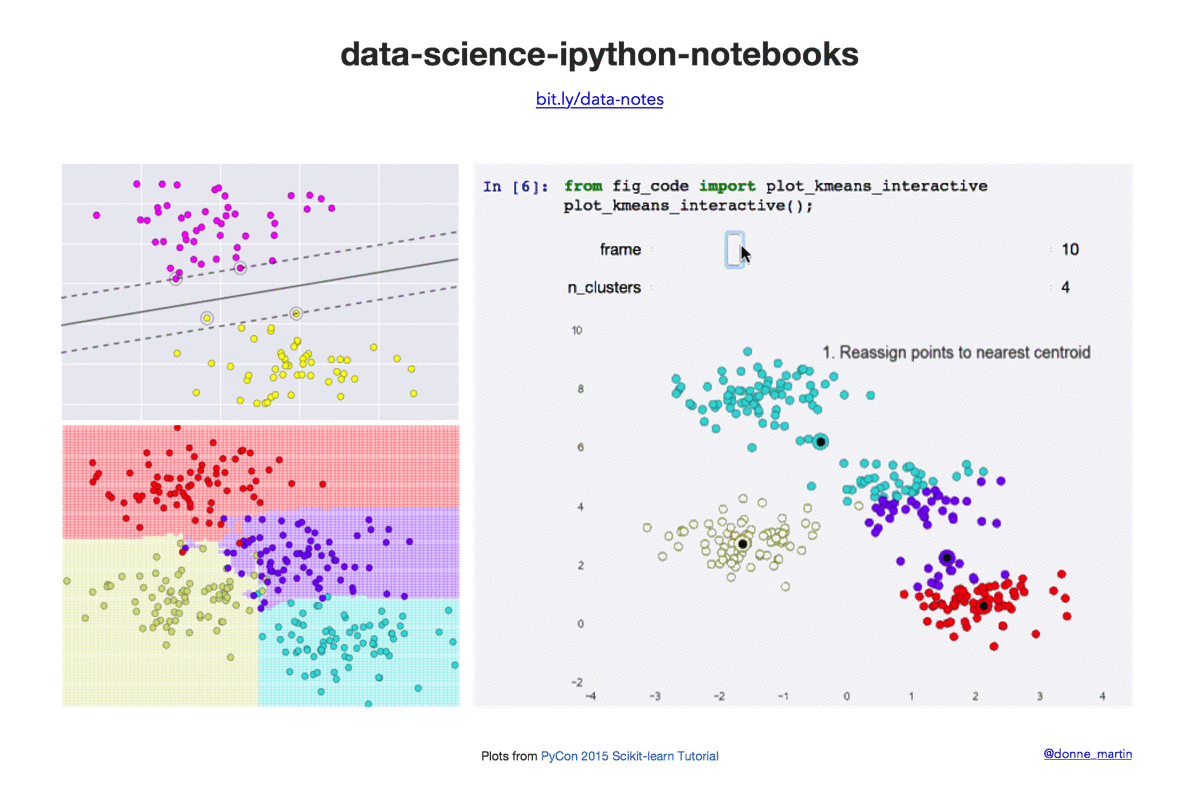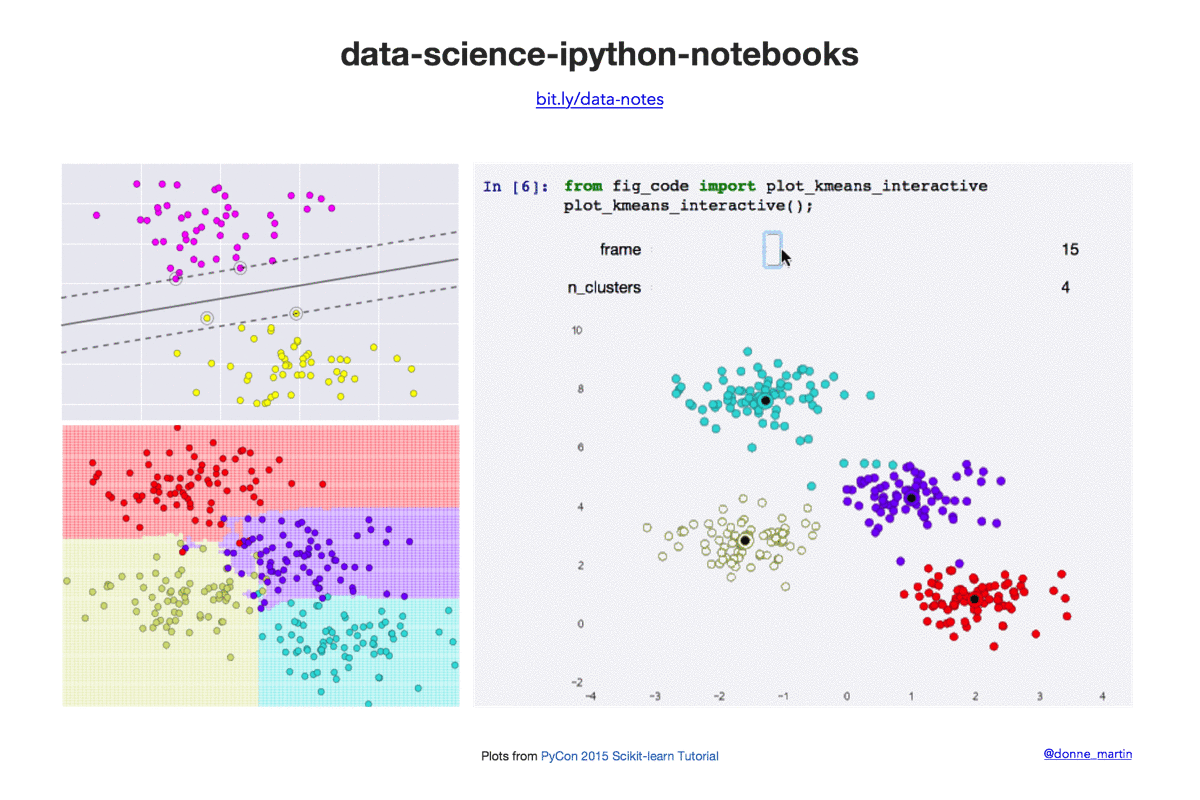
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
24.5k Jan 9, 2023

List of Data Science Cheatsheets to rule the world
Data Science Cheatsheets List of Data Science Cheatsheets to rule the world. Table of Contents Business Science Business Science Problem Framework Dat
 11.7k Dec 30, 2022
11.7k Dec 30, 2022

Sentiment analysis on streaming twitter data using Spark Structured Streaming & Python
Sentiment analysis on streaming twitter data using Spark Structured Streaming & Python This project is a good starting point for those who have little
 2 Dec 4, 2021
2 Dec 4, 2021
University of Missouri - Kansas City: CS451R: Capstone
CS451RC University of Missouri - Kansas City: CS451R: Capstone Installation cd git clone https://github.com/ala2q6/CS451RC.git cd CS451RC pip3 instal
 1 Nov 17, 2021
1 Nov 17, 2021
Instant search for and access to many datasets in Pyspark.
SparkDataset Provides instant access to many datasets right from Pyspark (in Spark DataFrame structure). Drop a star if you like the project. 😃 Motiv
 31 Dec 16, 2022
31 Dec 16, 2022
Polypheny Connector for Python
Polypheny Connector for Python This enables Python programs to access Polypheny databases, using an API that is compliant with the Python Database API
 3 Jan 3, 2022
3 Jan 3, 2022
This OctoPrint plugin will make the initial connection to 3D Hub a breeze
3D Hub Connector This OctoPrint plugin will make the initial connection to 3D Hub a breeze. In future it will help in setting up a tunnel connection a
 2 Aug 3, 2022
2 Aug 3, 2022

A collection of neat and practical data science and machine learning projects
Data Science A collection of neat and practical data science and machine learning projects Explore the docs » Report Bug · Request Feature Table of Co
 2 Dec 10, 2021
2 Dec 10, 2021
DataPrep — The easiest way to prepare data in Python
DataPrep — The easiest way to prepare data in Python
 1.5k Dec 27, 2022
1.5k Dec 27, 2022
Spark development environment for k8s
Local Spark Dev Env with Docker Development environment for k8s. Using the spark-operator image to ensure it will be the same environment. Start conta
 18 Jan 4, 2022
18 Jan 4, 2022
Open source guides/codes for mastering deep learning to deploying deep learning in production in PyTorch, Python, C++ and more.
Deep Learning Materials by Deep Learning Wizard Start Learning Now Please head to www.deeplearningwizard.com to start learning! It is mobile/tablet fr
 572 Dec 28, 2022
572 Dec 28, 2022
TensorFlowOnSpark brings TensorFlow programs to Apache Spark clusters.
TensorFlowOnSpark TensorFlowOnSpark brings scalable deep learning to Apache Hadoop and Apache Spark clusters. By combining salient features from the T
3.8k Jan 4, 2023

PySpark Cheat Sheet - learn PySpark and develop apps faster
This cheat sheet will help you learn PySpark and write PySpark apps faster. Everything in here is fully functional PySpark code you can run or adapt to your programs.
 168 Jan 1, 2023
168 Jan 1, 2023

Visions provides an extensible suite of tools to support common data analysis operations
Visions And these visions of data types, they kept us up past the dawn. Visions provides an extensible suite of tools to support common data analysis
 168 Dec 28, 2022
168 Dec 28, 2022
RabbitMQ asynchronous connector library for Python with built in RPC support
About RabbitMQ connector library for Python that is fully integrated with the aio-pika framework. Introduction BunnyStorm is here to simplify working
 22 Sep 11, 2022
22 Sep 11, 2022

Advance Image Downloader/Extractor (Job) is a Python-Flask web-based app, which will help the user download the any kind of Images at any date and time over the internet. These images will get downloaded as a job and then let user know that the images have been downloaded by sending them a link over an email.
Advance Image Downloader/Extractor(Job) Advance Image Downloader/Extractor (Job) is a Python-Flask web-based app, which will help the user download th
 13 Aug 27, 2022
13 Aug 27, 2022

The MLOps platform for innovators 🚀
DS2.ai is an integrated AI operation solution that supports all stages from custom AI development to deployment. It is an AI-specialized platform service that collects data, builds a training dataset through data labeling, and enables automatic development of artificial intelligence and easy deployment and operation.
 9 Jan 3, 2023
9 Jan 3, 2023
A python to scratch API connector. Can fetch data from the API and send it back in cloud variables.
Scratch2py Scratch2py or S2py is a easy to use, versatile tool to communicate with the Scratch API Based of scratchclient by Raihan142857 Installation
 20 Jun 18, 2022
20 Jun 18, 2022
Stream Framework is a Python library, which allows you to build news feed, activity streams and notification systems using Cassandra and/or Redis. The authors of Stream-Framework also provide a cloud service for feed technology:
Stream Framework Activity Streams & Newsfeeds Stream Framework is a Python library which allows you to build activity streams & newsfeeds using Cassan
 4.7k Jan 2, 2023
4.7k Jan 2, 2023
[DEPRECATED] Tensorflow wrapper for DataFrames on Apache Spark
TensorFrames (Deprecated) Note: TensorFrames is deprecated. You can use pandas UDF instead. Experimental TensorFlow binding for Scala and Apache Spark
757 Dec 31, 2022

Distributed scikit-learn meta-estimators in PySpark
sk-dist: Distributed scikit-learn meta-estimators in PySpark What is it? sk-dist is a Python package for machine learning built on top of scikit-learn
 282 Dec 9, 2022
282 Dec 9, 2022
Distributed Tensorflow, Keras and PyTorch on Apache Spark/Flink & Ray
A unified Data Analytics and AI platform for distributed TensorFlow, Keras and PyTorch on Apache Spark/Flink & Ray What is Analytics Zoo? Analytics Zo
 2.5k Dec 28, 2022
2.5k Dec 28, 2022
Microsoft Machine Learning for Apache Spark
Microsoft Machine Learning for Apache Spark MMLSpark is an ecosystem of tools aimed towards expanding the distributed computing framework Apache Spark
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
TensorFlowOnSpark brings TensorFlow programs to Apache Spark clusters.
TensorFlowOnSpark TensorFlowOnSpark brings scalable deep learning to Apache Hadoop and Apache Spark clusters. By combining salient features from the T
3.8k Jan 4, 2023
Distributed Deep learning with Keras & Spark
Elephas: Distributed Deep Learning with Keras & Spark Elephas is an extension of Keras, which allows you to run distributed deep learning models at sc
 1.6k Dec 29, 2022
1.6k Dec 29, 2022
BigDL: Distributed Deep Learning Framework for Apache Spark
BigDL: Distributed Deep Learning on Apache Spark What is BigDL? BigDL is a distributed deep learning library for Apache Spark; with BigDL, users can w
4.1k Jan 9, 2023

Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
Horovod Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make dis
 12.9k Jan 7, 2023
12.9k Jan 7, 2023
Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
Horovod Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make dis
12.9k Dec 29, 2022
Koalas: pandas API on Apache Spark
pandas API on Apache Spark Explore Koalas docs » Live notebook · Issues · Mailing list Help Thirsty Koalas Devastated by Recent Fires The Koalas proje
3.2k Jan 4, 2023
A pure Python implementation of Apache Spark's RDD and DStream interfaces.
pysparkling Pysparkling provides a faster, more responsive way to develop programs for PySpark. It enables code intended for Spark applications to exe
 254 Dec 6, 2022
254 Dec 6, 2022
Distributed Deep learning with Keras & Spark
Elephas: Distributed Deep Learning with Keras & Spark Elephas is an extension of Keras, which allows you to run distributed deep learning models at sc
1.6k Jan 5, 2023
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
eXtreme Gradient Boosting Community | Documentation | Resources | Contributors | Release Notes XGBoost is an optimized distributed gradient boosting l
 23.6k Jan 3, 2023
23.6k Jan 3, 2023
PySpark + Scikit-learn = Sparkit-learn
Sparkit-learn PySpark + Scikit-learn = Sparkit-learn GitHub: https://github.com/lensacom/sparkit-learn About Sparkit-learn aims to provide scikit-lear
 1.1k Jan 4, 2023
1.1k Jan 4, 2023
Open source platform for the machine learning lifecycle
MLflow: A Machine Learning Lifecycle Platform MLflow is a platform to streamline machine learning development, including tracking experiments, packagi
 13.3k Jan 4, 2023
13.3k Jan 4, 2023
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
 1.9k Feb 18, 2021
1.9k Feb 18, 2021

 578 Dec 30, 2022
578 Dec 30, 2022
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
3k Jan 5, 2023
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
eXtreme Gradient Boosting Community | Documentation | Resources | Contributors | Release Notes XGBoost is an optimized distributed gradient boosting l
20.6k Feb 13, 2021
Apache Spark - A unified analytics engine for large-scale data processing
Apache Spark Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an op
 34.7k Jan 4, 2023
34.7k Jan 4, 2023
SAP HANA Connector in pure Python
SAP HANA Database Client for Python A pure Python client for the SAP HANA Database based on the SAP HANA Database SQL Command Network Protocol. pyhdb
 299 Nov 20, 2022
299 Nov 20, 2022
MongoDB data stream pipeline tools by YouGov (adopted from MongoDB)
mongo-connector The mongo-connector project originated as a MongoDB mongo-labs project and is now community-maintained under the custody of YouGov, Pl
 1.9k Jan 4, 2023
1.9k Jan 4, 2023
Python interface to Oracle Database conforming to the Python DB API 2.0 specification.
cx_Oracle version 8.2 (Development) cx_Oracle is a Python extension module that enables access to Oracle Database. It conforms to the Python database
 841 Dec 21, 2022
841 Dec 21, 2022
MySQL database connector for Python (with Python 3 support)
mysqlclient This project is a fork of MySQLdb1. This project adds Python 3 support and fixed many bugs. PyPI: https://pypi.org/project/mysqlclient/ Gi
 2.2k Dec 25, 2022
2.2k Dec 25, 2022
Serverless proxy for Spark cluster
Hydrosphere Mist Hydrosphere Mist is a serverless proxy for Spark cluster. Mist provides a new functional programming framework and deployment model f
 317 Dec 1, 2022
317 Dec 1, 2022
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
eXtreme Gradient Boosting Community | Documentation | Resources | Contributors | Release Notes XGBoost is an optimized distributed gradient boosting l
23.6k Dec 31, 2022
H2O is an Open Source, Distributed, Fast & Scalable Machine Learning Platform: Deep Learning, Gradient Boosting (GBM) & XGBoost, Random Forest, Generalized Linear Modeling (GLM with Elastic Net), K-Means, PCA, Generalized Additive Models (GAM), RuleFit, Support Vector Machine (SVM), Stacked Ensembles, Automatic Machine Learning (AutoML), etc.
H2O H2O is an in-memory platform for distributed, scalable machine learning. H2O uses familiar interfaces like R, Python, Scala, Java, JSON and the Fl
 6.1k Jan 5, 2023
6.1k Jan 5, 2023
DataStax Python Driver for Apache Cassandra
DataStax Driver for Apache Cassandra A modern, feature-rich and highly-tunable Python client library for Apache Cassandra (2.1+) and DataStax Enterpri
 1.3k Dec 25, 2022
1.3k Dec 25, 2022
MySQL database connector for Python (with Python 3 support)
mysqlclient This project is a fork of MySQLdb1. This project adds Python 3 support and fixed many bugs. PyPI: https://pypi.org/project/mysqlclient/ Gi
2.2k Dec 25, 2022

:truck: Agile Data Preparation Workflows made easy with dask, cudf, dask_cudf and pyspark
To launch a live notebook server to test optimus using binder or Colab, click on one of the following badges: Optimus is the missing framework to prof
 1.3k Dec 30, 2022
1.3k Dec 30, 2022