1138 Repositories
Python speech-processing Libraries
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
A Multilingual Latent Dirichlet Allocation (LDA) Pipeline with Stop Words Removal, n-gram features, and Inverse Stemming, in Python.
Multilingual Latent Dirichlet Allocation (LDA) Pipeline This project is for text clustering using the Latent Dirichlet Allocation (LDA) algorithm. It
 74 Oct 7, 2022
74 Oct 7, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022

Neural network models for joint POS tagging and dependency parsing (CoNLL 2017-2018)
Neural Network Models for Joint POS Tagging and Dependency Parsing Implementations of joint models for POS tagging and dependency parsing, as describe
 152 Sep 2, 2022
152 Sep 2, 2022

TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP
TextAttack 🐙 Generating adversarial examples for NLP models [TextAttack Documentation on ReadTheDocs] About • Setup • Usage • Design About TextAttack
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
The friendly PIL fork (Python Imaging Library)
Pillow Python Imaging Library (Fork) Pillow is the friendly PIL fork by Alex Clark and Contributors. PIL is the Python Imaging Library by Fredrik Lund
 10.4k Jan 3, 2023
10.4k Jan 3, 2023

Kornia is a open source differentiable computer vision library for PyTorch.
Open Source Differentiable Computer Vision Library
 7.6k Jan 6, 2023
7.6k Jan 6, 2023
Django library to simplify payment processing with pin
Maintainer Wanted I no longer have any side projects that use django-pinpayments and I don't have the time or headspace to maintain an important proje
 25 May 25, 2022
25 May 25, 2022

Towards Flexible Blind JPEG Artifacts Removal (FBCNN, ICCV 2021)
Towards Flexible Blind JPEG Artifacts Removal (FBCNN, ICCV 2021)
 282 Jan 2, 2023
282 Jan 2, 2023
The code for the NSDI'21 paper "BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing".
BMC The code for the NSDI'21 paper "BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing". BibTex entry available here. B
 383 Dec 16, 2022
383 Dec 16, 2022
This project converts your human voice input to its text transcript and to an automated voice too.
Human Voice to Automated Voice & Text Introduction: In this project, whenever you'll speak, it will turn your voice into a robot voice and furthermore
 3 Oct 15, 2021
3 Oct 15, 2021
Automated image processing for Django. Currently v4.0
ImageKit is a Django app for processing images. Need a thumbnail? A black-and-white version of a user-uploaded image? ImageKit will make them for you.
 2.1k Jan 4, 2023
2.1k Jan 4, 2023
Codename generator using WordNet parts of speech database
codenames Codename generator using WordNet parts of speech database References: https://possiblywrong.wordpress.com/2021/09/13/code-name-generator/ ht
 27 Oct 30, 2022
27 Oct 30, 2022
Natural Language Processing with transformers
we want to create a repo to illustrate usage of transformers in chinese
 763 Dec 27, 2022
763 Dec 27, 2022

Abstractive opinion summarization system (SelSum) and the largest dataset of Amazon product summaries (AmaSum). EMNLP 2021 conference paper.
Learning Opinion Summarizers by Selecting Informative Reviews This repository contains the codebase and the dataset for the corresponding EMNLP 2021
 39 Jan 1, 2023
39 Jan 1, 2023

Vehicle Detection Using Deep Learning and YOLO Algorithm
VehicleDetection Vehicle Detection Using Deep Learning and YOLO Algorithm Dataset take or find vehicle images for create a special dataset for fine-tu
 96 Jan 5, 2023
96 Jan 5, 2023
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
Code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
This repository contains the code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
 28 Nov 10, 2022
28 Nov 10, 2022
Point cloud processing tool library.
Point Cloud ToolBox This point cloud processing tool library can be used to process point clouds, 3d meshes, and voxels. Environment python 3.7.5 Dep
 40 Dec 9, 2022
40 Dec 9, 2022
Learn how to responsibly deliver value with ML.
Made With ML Applied ML · MLOps · Production Join 30K+ developers in learning how to responsibly deliver value with ML. 🔥 Among the top MLOps reposit
 32k Dec 30, 2022
32k Dec 30, 2022
Augmenty is an augmentation library based on spaCy for augmenting texts.
Augmenty: The cherry on top of your NLP pipeline Augmenty is an augmentation library based on spaCy for augmenting texts. Besides a wide array of high
 124 Dec 29, 2022
124 Dec 29, 2022
Implementation of Common Image Evaluation Metrics by Sayed Nadim (sayednadim.github.io). The repo is built based on full reference image quality metrics such as L1, L2, PSNR, SSIM, LPIPS. and feature-level quality metrics such as FID, IS. It can be used for evaluating image denoising, colorization, inpainting, deraining, dehazing etc. where we have access to ground truth.
Image Quality Evaluation Metrics Implementation of some common full reference image quality metrics. The repo is built based on full reference image q
 10 Jan 1, 2023
10 Jan 1, 2023

🌌 A Python script to generate blog banners from command line.
Auto Blog Banner Generator A Python script to generate blog banners. This script is used at RavSam. The following image is an example of the blog bann
 10 Sep 20, 2022
10 Sep 20, 2022

Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition
Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition Official implementation of the Efficient Conforme
 145 Dec 30, 2022
145 Dec 30, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022

Document processing using transformers
Doc Transformers Document processing using transformers. This is still in developmental phase, currently supports only extraction of form data i.e (ke
 13 Dec 21, 2022
13 Dec 21, 2022
Knock your images before these make you painful.
image-knocker Knock your images before these make you painful. Background One day, I had run my deep learning model training program and got off work
 9 Jul 25, 2022
9 Jul 25, 2022

Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library.
GI-Pi Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library. The SP0
 8 Dec 15, 2021
8 Dec 15, 2021
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
23 Nov 30, 2022
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022
📷 Python package and CLI utility to create photo mosaics.
📷 Python package and CLI utility to create photo mosaics.
 7 Oct 29, 2022
7 Oct 29, 2022
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Reading list for research topics in sound event detection
Sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene.
 64 Jan 5, 2023
64 Jan 5, 2023

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023
Implementation of "A Deep Learning Loss Function based on Auditory Power Compression for Speech Enhancement" by pytorch
This repository is used to suspend the results of our paper "A Deep Learning Loss Function based on Auditory Power Compression for Speech Enhancement"
 19 Sep 30, 2022
19 Sep 30, 2022
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022

pedalboard is a Python library for adding effects to audio.
pedalboard is a Python library for adding effects to audio. It supports a number of common audio effects out of the box, and also allows the use of VST3® and Audio Unit plugin formats for third-party effects.
 3.9k Jan 2, 2023
3.9k Jan 2, 2023

fishington.io bot with OpenCV and NumPy
fishington.io-bot fishington.io bot with using OpenCV and NumPy bot can continue to fishing fully automatically how to use Open cmd in fishington.io-b
 77 Jan 2, 2023
77 Jan 2, 2023
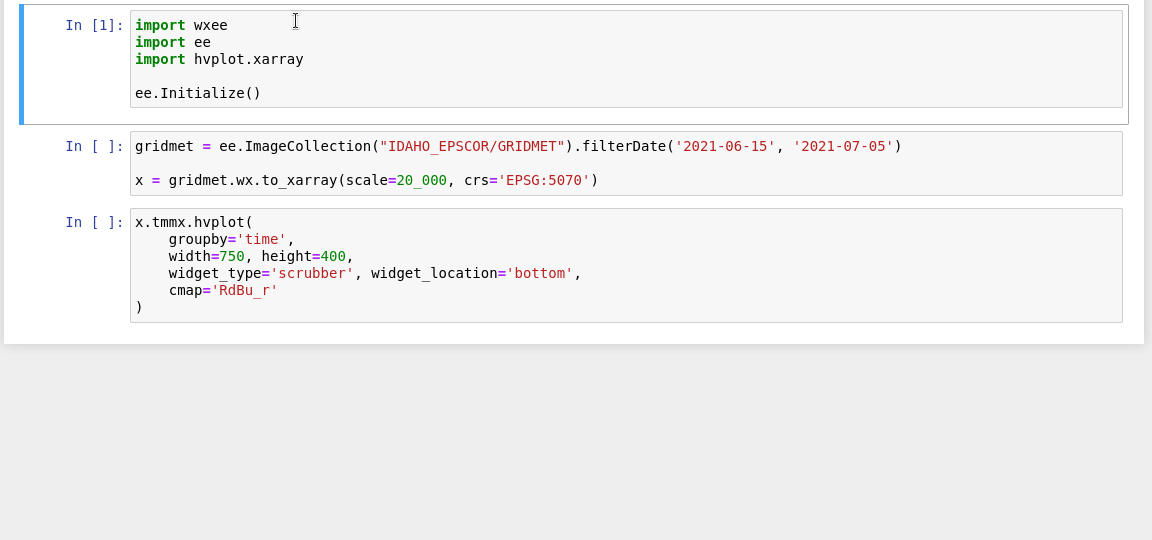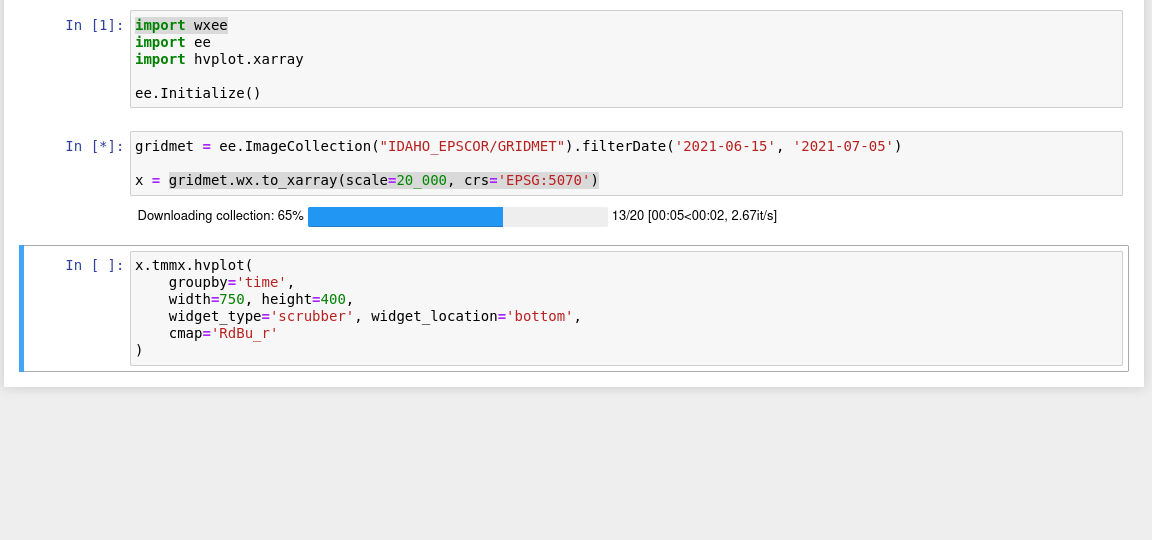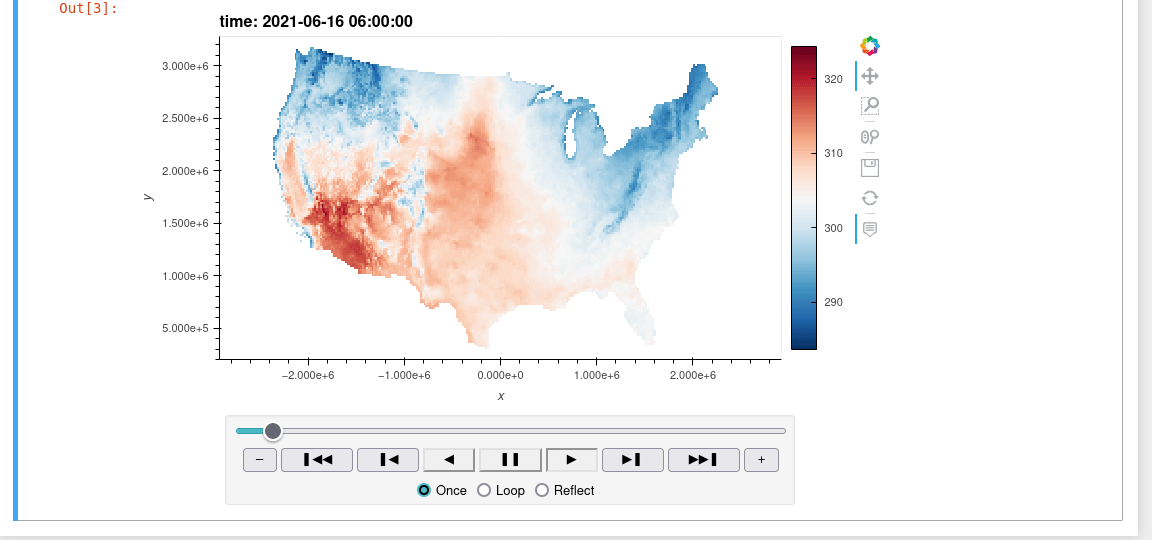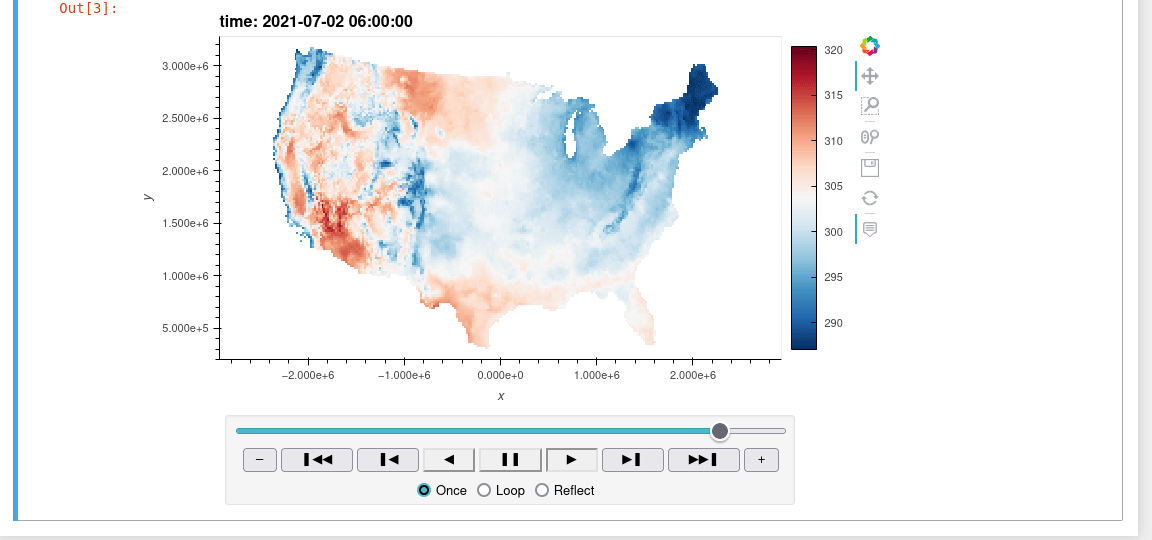
A Python interface between Earth Engine and xarray for processing weather and climate data
wxee What is wxee? wxee was built to make processing gridded, mesoscale time series weather and climate data quick and easy by integrating the data ca
 160 Dec 31, 2022
160 Dec 31, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022
Framework for creating efficient data processing pipelines
Aqueduct Framework for creating efficient data processing pipelines. Contact Feel free to ask questions in telegram t.me/avito-ml Key Features Increas
 137 Dec 29, 2022
137 Dec 29, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
Add filters (background blur, etc) to your webcam on Linux.
webcam-filters Add filters (background blur, etc) to your webcam on Linux. Video conferencing applications tend to either lack video effects altogethe
 480 Dec 14, 2022
480 Dec 14, 2022
Code for the ICASSP-2021 paper: Continuous Speech Separation with Conformer.
Continuous Speech Separation with Conformer Introduction We examine the use of the Conformer architecture for continuous speech separation. Conformer
 81 Nov 28, 2022
81 Nov 28, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 54 Aug 30, 2021
54 Aug 30, 2021
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
 24 Sep 7, 2022
24 Sep 7, 2022

The source code of CVPR 2019 paper "Deep Exemplar-based Video Colorization".
Deep Exemplar-based Video Colorization (Pytorch Implementation) Paper | Pretrained Model | Youtube video 🔥 | Colab demo Deep Exemplar-based Video Col
 253 Dec 27, 2022
253 Dec 27, 2022

CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
100 Dec 28, 2022
CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
100 Dec 28, 2022
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion Yinghao Aaron Li, Ali Zare, Nima Mesgarani We pres
 282 Jan 1, 2023
282 Jan 1, 2023

GSoC'2021 | TensorFlow implementation of Wav2Vec2
GSoC'2021 | TensorFlow implementation of Wav2Vec2
 73 Nov 28, 2022
73 Nov 28, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 5, 2023
7.1k Jan 5, 2023
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
 279 Dec 9, 2022
279 Dec 9, 2022
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023

Using a raspberry pi, we listen to the coffee machine and count the number of coffee consumption
A typical datarootsian consumes high-quality fresh coffee in their office environment. The board of dataroots had a very critical decision by the end of 2021-Q2 regarding coffee consumption.
 51 Nov 21, 2022
51 Nov 21, 2022
This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab.
Speech-Backbones This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab. Grad-TTS Official implementation of the Grad-
 295 Jan 7, 2023
295 Jan 7, 2023
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

Data Preparation, Processing, and Visualization for MoVi Data
MoVi-Toolbox Data Preparation, Processing, and Visualization for MoVi Data, https://www.biomotionlab.ca/movi/ MoVi is a large multipurpose dataset of
 51 Nov 27, 2022
51 Nov 27, 2022
![[NeurIPS 2020] Official repository for the project](https://github.com/henryxrl/Listening-to-Sound-of-Silence-for-Speech-Denoising/raw/main/assets/network.png)
[NeurIPS 2020] Official repository for the project "Listening to Sound of Silence for Speech Denoising"
Listening to Sounds of Silence for Speech Denoising Introduction This is the repository of the "Listening to Sounds of Silence for Speech Denoising" p
 40 Dec 20, 2022
40 Dec 20, 2022
Library for processing molecules and reactions in python way
Chython [ˈkʌɪθ(ə)n] Library for processing molecules and reactions in python way. Features: Read/write/convert formats: MDL .RDF (.RXN) and .SDF (.MOL
 16 Dec 1, 2022
16 Dec 1, 2022

3D position tracking for soccer players with multi-camera videos
This repo contains a full pipeline to support 3D position tracking of soccer players, with multi-view calibrated moving/fixed video sequences as inputs.
 72 Dec 27, 2022
72 Dec 27, 2022
ExKaldi-RT: An Online Speech Recognition Extension Toolkit of Kaldi
ExKaldi-RT is an online ASR toolkit for Python language. It reads realtime streaming audio and do online feature extraction, probability computation, and online decoding.
 31 Aug 16, 2021
31 Aug 16, 2021
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 169 Jan 5, 2023
169 Jan 5, 2023
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022
😇A pyTorch implementation of the DeepMoji model: state-of-the-art deep learning model for analyzing sentiment, emotion, sarcasm etc
------ Update September 2018 ------ It's been a year since TorchMoji and DeepMoji were released. We're trying to understand how it's being used such t
 865 Dec 24, 2022
865 Dec 24, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
 47 Dec 18, 2022
47 Dec 18, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
65 Sep 13, 2022

Pre-Trained Image Processing Transformer (IPT)
Pre-Trained Image Processing Transformer (IPT) By Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Cha
332 Dec 18, 2022
StarGAN-ZSVC: Unofficial PyTorch Implementation
This repository is an unofficial PyTorch implementation of StarGAN-ZSVC by Matthew Baas and Herman Kamper. This repository provides both model architectures and the code to inference or train them.
 11 Aug 28, 2022
11 Aug 28, 2022
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023

End-to-end text to speech system using gruut and onnx. There are 40 voices available across 8 languages.
End to end text to speech system using gruut and onnx
 673 Dec 28, 2022
673 Dec 28, 2022
Data from "HateCheck: Functional Tests for Hate Speech Detection Models" (Röttger et al., ACL 2021)
In this repo, you can find the data from our ACL 2021 paper "HateCheck: Functional Tests for Hate Speech Detection Models". "test_suite_cases.csv" con
 43 Nov 11, 2022
43 Nov 11, 2022

Codes for processing meeting summarization datasets AMI and ICSI.
Meeting Summarization Dataset Meeting plays an essential part in our daily life, which allows us to share information and collaborate with others. Wit
 39 Dec 14, 2022
39 Dec 14, 2022

esguard provides a Python decorator that waits for processing while monitoring the load of Elasticsearch.
esguard esguard provides a Python decorator that waits for processing while monitoring the load of Elasticsearch. Quick Start You need to launch elast
 5 Dec 8, 2021
5 Dec 8, 2021

Clone a voice in 5 seconds to generate arbitrary speech in real-time
This repository is forked from Real-Time-Voice-Cloning which only support English. English | 中文 Features 🌍 Chinese supported mandarin and tested with
 25.6k Jan 6, 2023
25.6k Jan 6, 2023

Implementation for our ICCV2021 paper: Internal Video Inpainting by Implicit Long-range Propagation
Implicit Internal Video Inpainting Implementation for our ICCV2021 paper: Internal Video Inpainting by Implicit Long-range Propagation paper | project
 202 Dec 30, 2022
202 Dec 30, 2022
This repository is home to the Optimus data transformation plugins for various data processing needs.
Transformers Optimus's transformation plugins are implementations of Task and Hook interfaces that allows execution of arbitrary jobs in optimus. To i
 37 Dec 14, 2022
37 Dec 14, 2022
[ICCV, 2021] Cloud Transformers: A Universal Approach To Point Cloud Processing Tasks
Cloud Transformers: A Universal Approach To Point Cloud Processing Tasks This is an official PyTorch code repository of the paper "Cloud Transformers:
 27 Dec 15, 2022
27 Dec 15, 2022
This repository contains data used in the NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Proteno This is the data release associated with the corresponding NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deploymen
37 Dec 4, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022
A PyTorch implementation of Radio Transformer Networks from the paper "An Introduction to Deep Learning for the Physical Layer".
An Introduction to Deep Learning for the Physical Layer An usable PyTorch implementation of the noisy autoencoder infrastructure in the paper "An Intr
 120 Nov 21, 2022
120 Nov 21, 2022

performing moving objects segmentation using image processing techniques with opencv and numpy
Moving Objects Segmentation On this project I tried to perform moving objects segmentation using background subtraction technique. the introduced meth
 15 Dec 12, 2022
15 Dec 12, 2022
Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
170 Jan 4, 2023

Chinese real time voice cloning (VC) and Chinese text to speech (TTS).
Chinese real time voice cloning (VC) and Chinese text to speech (TTS). 好用的中文语音克隆兼中文语音合成系统,包含语音编码器、语音合成器、声码器和可视化模块。
 6 Nov 8, 2022
6 Nov 8, 2022
Active learning for text classification in Python
Active Learning allows you to efficiently label training data in a small-data scenario.
 375 Dec 28, 2022
375 Dec 28, 2022

meProp: Sparsified Back Propagation for Accelerated Deep Learning
meProp The codes were used for the paper meProp: Sparsified Back Propagation for Accelerated Deep Learning with Reduced Overfitting (ICML 2017) [pdf]
 107 Nov 18, 2022
107 Nov 18, 2022

Image Deblurring using Generative Adversarial Networks
DeblurGAN arXiv Paper Version Pytorch implementation of the paper DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. Our netwo
 2.2k Jan 1, 2023
2.2k Jan 1, 2023

PyTorch implementation of the wavelet analysis from Torrence & Compo
Continuous Wavelet Transforms in PyTorch This is a PyTorch implementation for the wavelet analysis outlined in Torrence and Compo (BAMS, 1998). The co
 262 Dec 21, 2022
262 Dec 21, 2022

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
1.8k Dec 30, 2022

NLPShala , the best IDE for all Natural language processing tasks.
The revolutionary IDE for all NLP (Natural language processing) stuffs on the internet.
 3 Aug 8, 2021
3 Aug 8, 2021
Write reproducible code for getting and processing ChEMBL
chembl_downloader Don't worry about downloading/extracting ChEMBL or versioning - just use chembl_downloader to write code that knows how to download
 34 Dec 25, 2022
34 Dec 25, 2022
MoviePy is a Python library for video editing, can read and write all the most common audio and video formats
MoviePy is a Python library for video editing: cutting, concatenations, title insertions, video compositing (a.k.a. non-linear editing), video processing, and creation of custom effects. See the gallery for some examples of use.
 10k Jan 8, 2023
10k Jan 8, 2023
Open-Source Toolkit for End-to-End Speech Recognition leveraging PyTorch-Lightning and Hydra.
🤗 Contributing to OpenSpeech 🤗 OpenSpeech provides reference implementations of various ASR modeling papers and three languages recipe to perform ta
 513 Jan 3, 2023
513 Jan 3, 2023

Learned Token Pruning for Transformers
LTP: Learned Token Pruning for Transformers Check our paper for more details. Installation We follow the same installation procedure as the original H
 52 Dec 29, 2022
52 Dec 29, 2022

ICML 21 - Voice2Series: Reprogramming Acoustic Models for Time Series Classification
Voice2Series-Reprogramming Voice2Series: Reprogramming Acoustic Models for Time Series Classification International Conference on Machine Learning (IC
 49 Jan 3, 2023
49 Jan 3, 2023